

Rule-Based Embedded HMMs Phoneme Classification to Improve Qur’anic Recitation Recognition
 , ,
, ,  , ,
, ,  and
and
Abstract
:1. Introduction
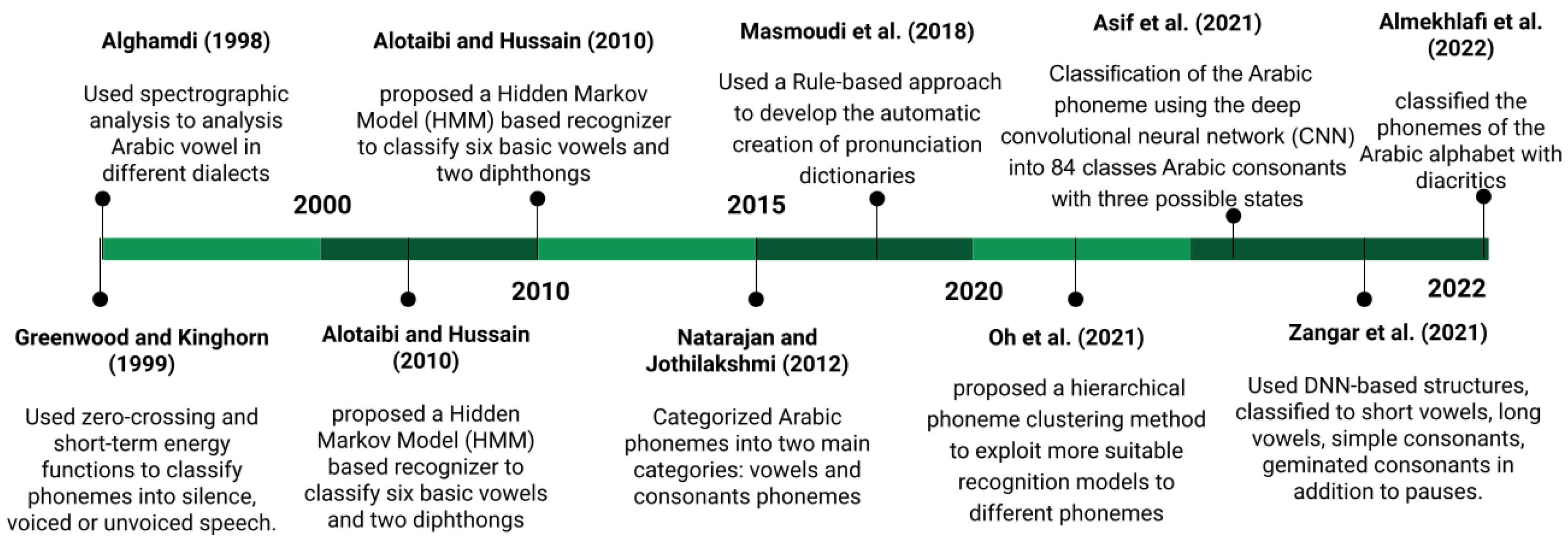
2. Literature Review
2.1. Motivation for Phonemes Classification Based on Their Duration
2.2. Arabic Phonemes Classification
2.3. Rule-Based Classification Approach
2.4. Trends and Research Directions
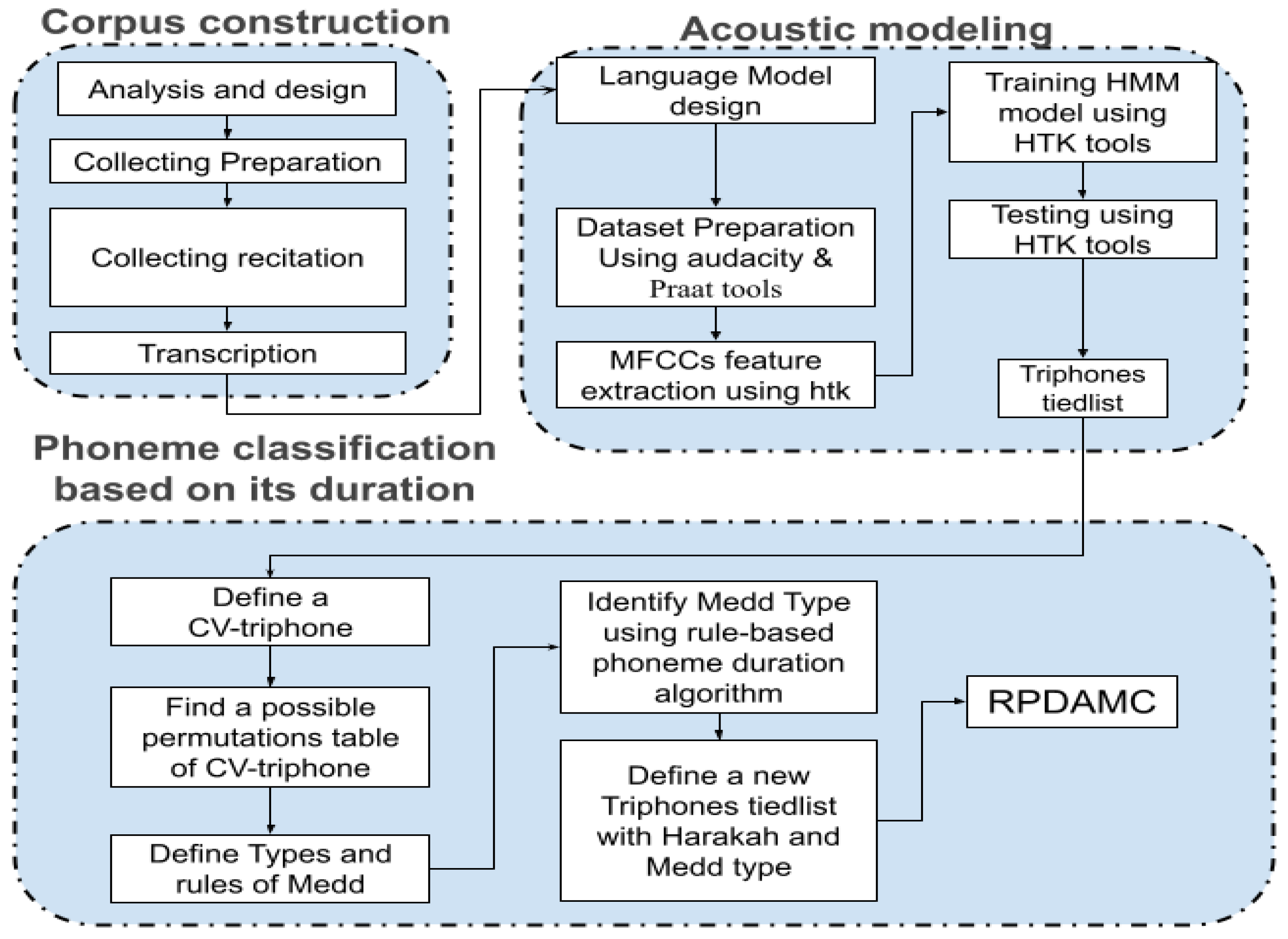
3. Procedures and Methods
3.1. Corpus Construction (Collect and Design Dataset)
3.1.1. Analysis and Design
3.1.2. Collecting Preparation
3.1.3. Collecting Recitation and Preprocessing
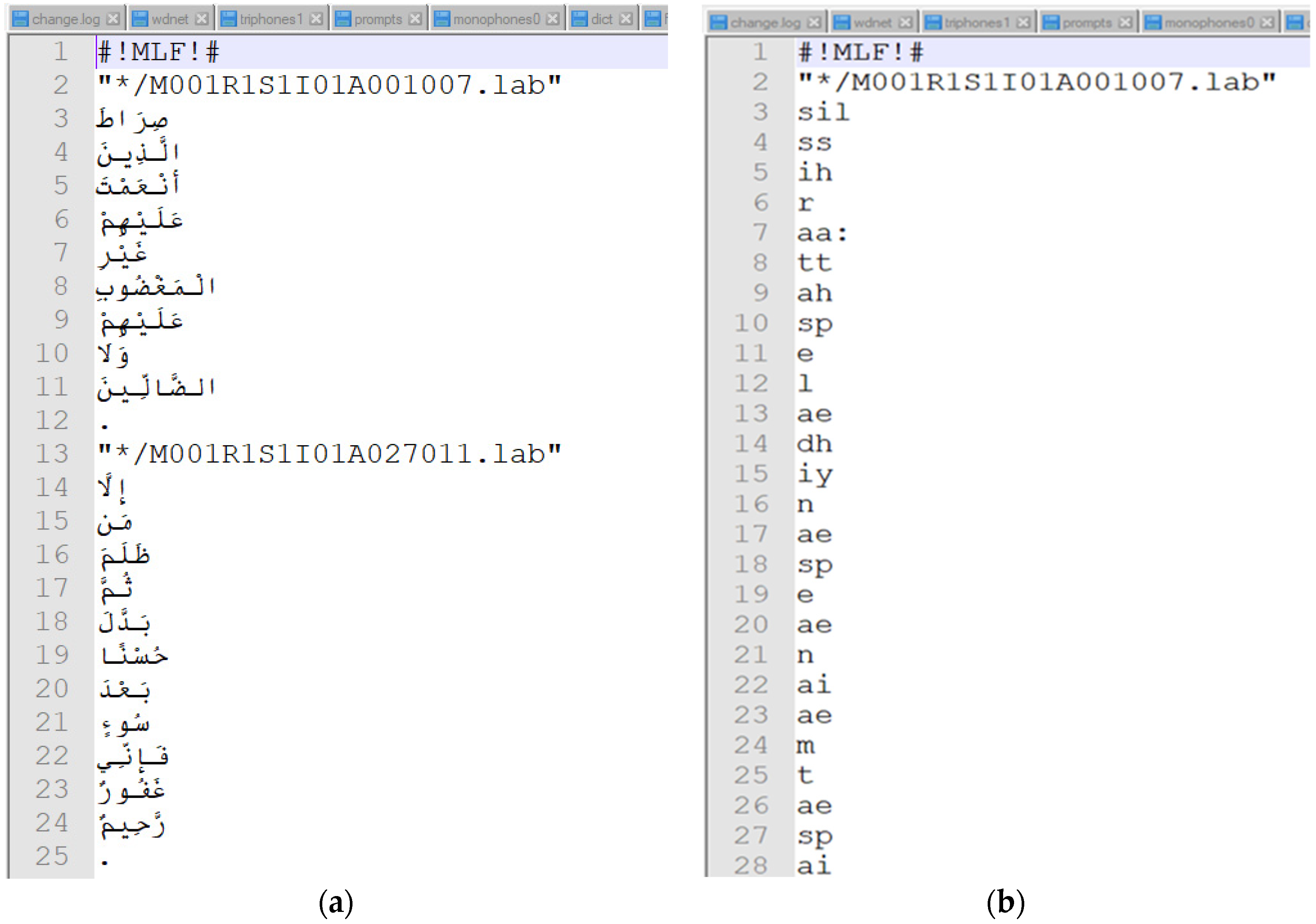
3.1.4. Transcription
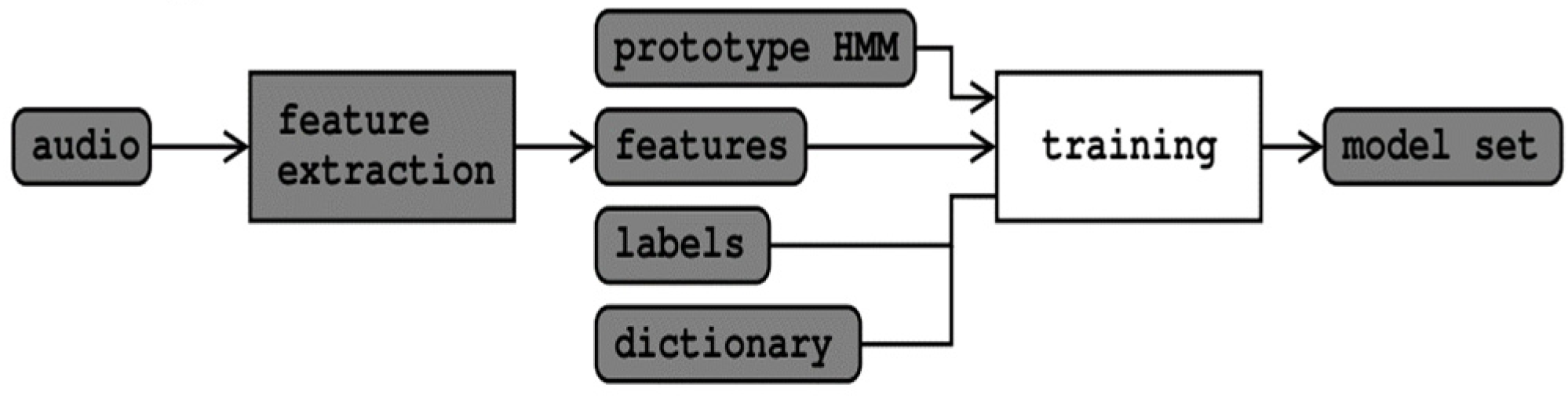
3.2. Acoustic HMM Model Using HTK Toolkit
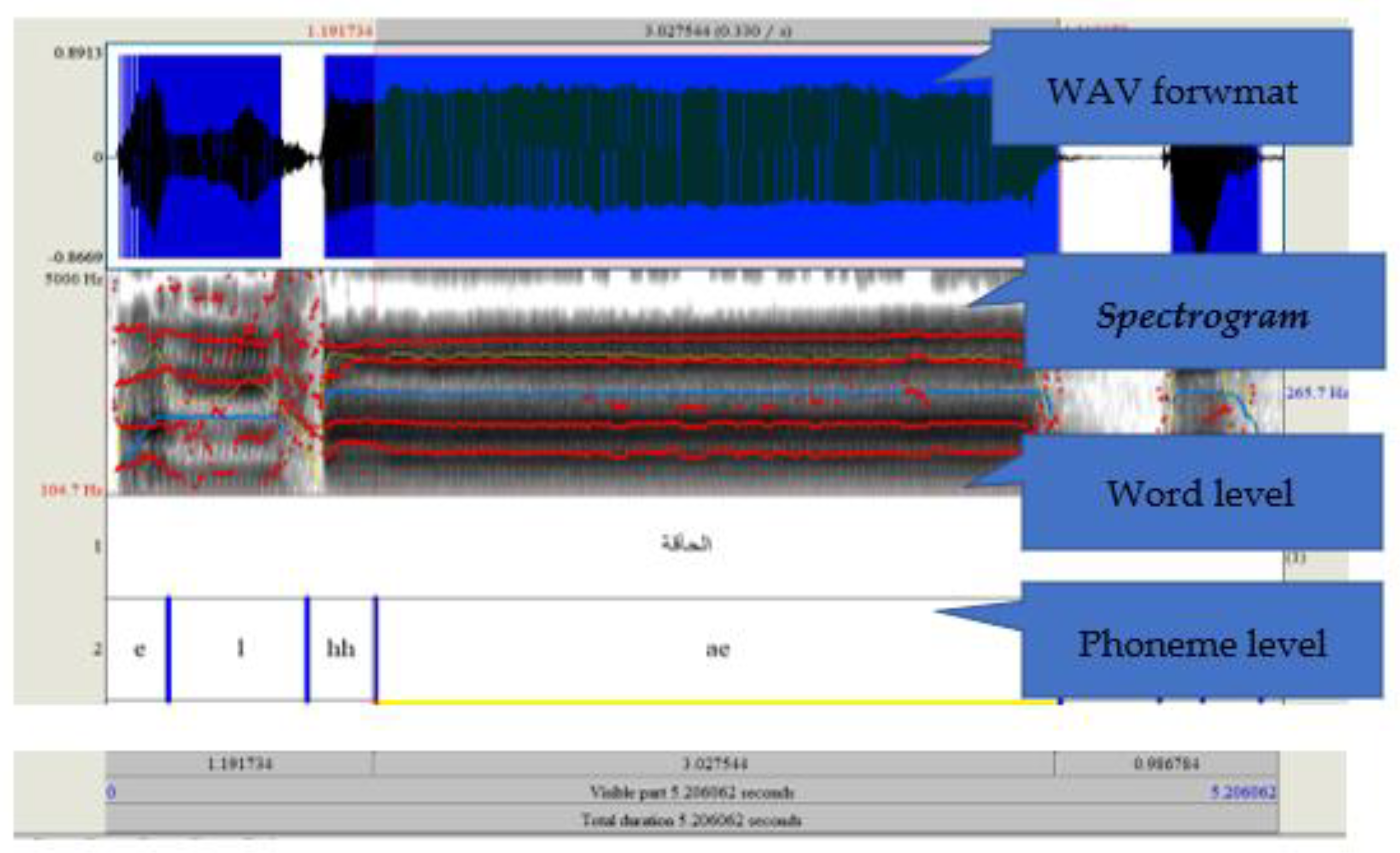
3.2.1. Language Model Design and Dataset Preparation Using Audacity and Praat Tool
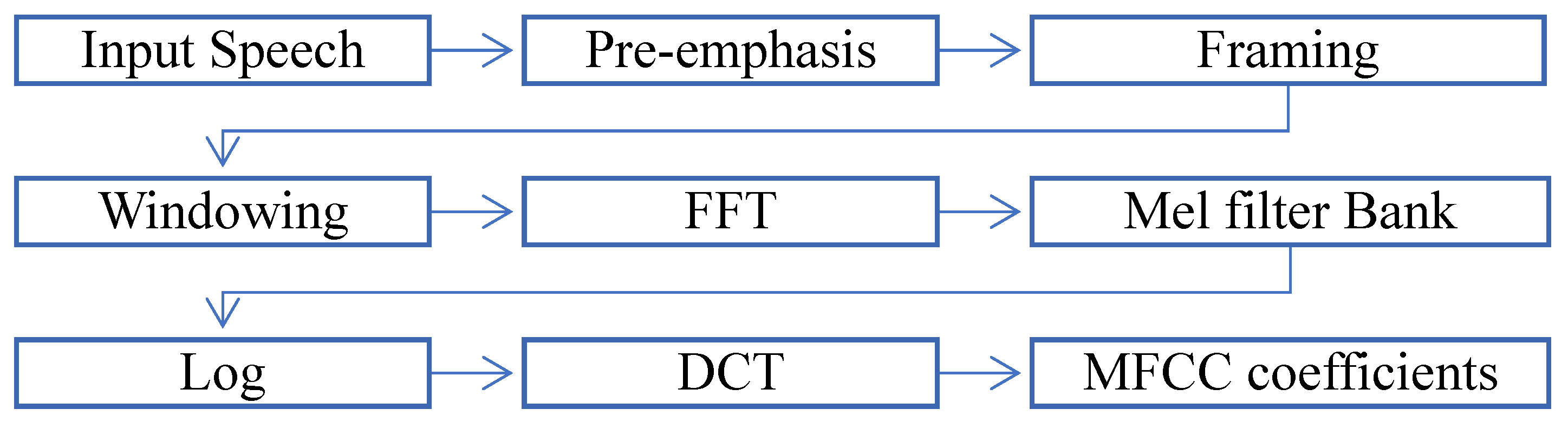
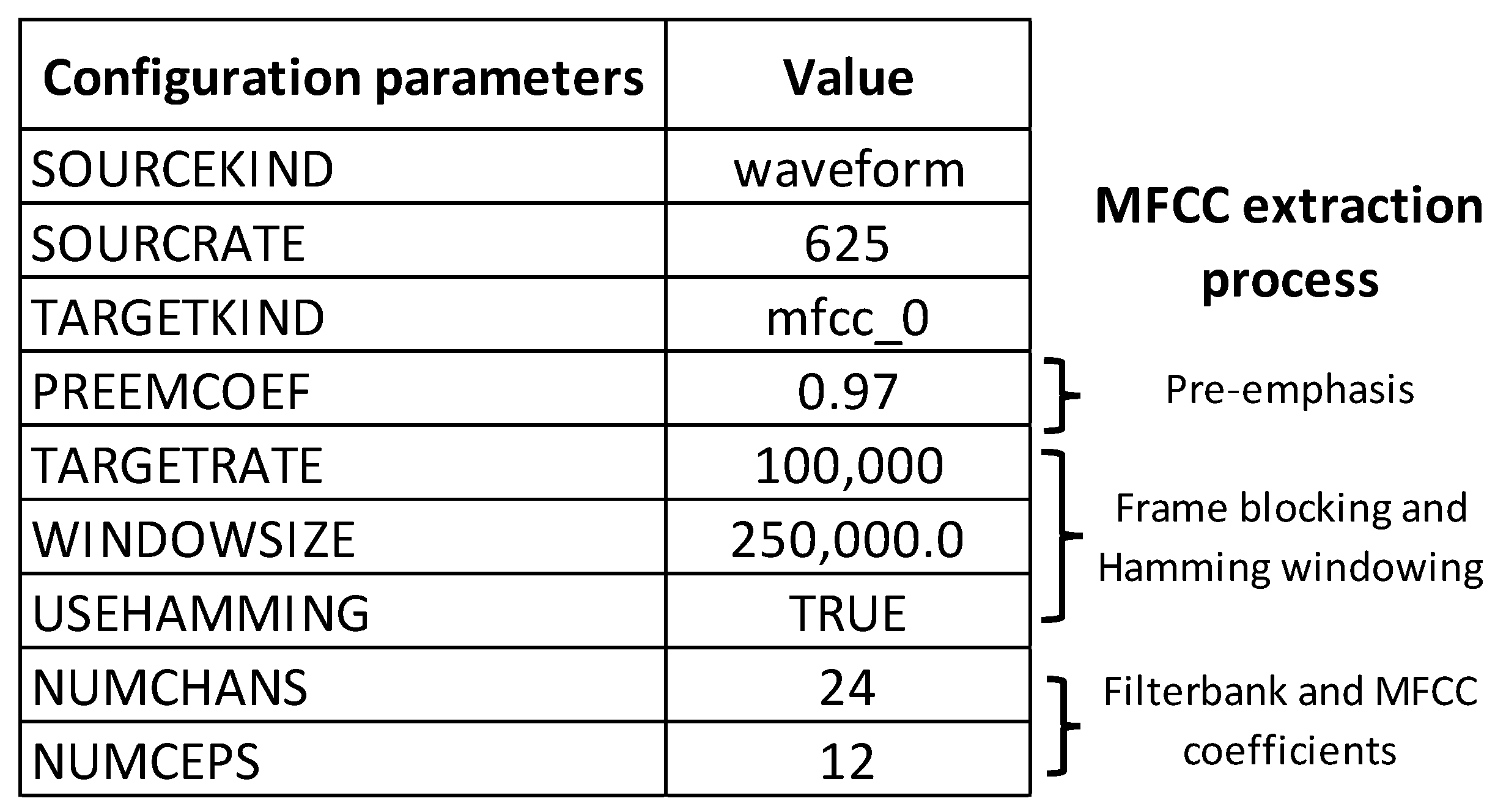
3.2.2. Features Extraction
3.2.3. Training and Testing the HMM Model
3.2.4. Creating Tied-State Triphones
3.3. Phoneme Classification Based on Its Duration Phase
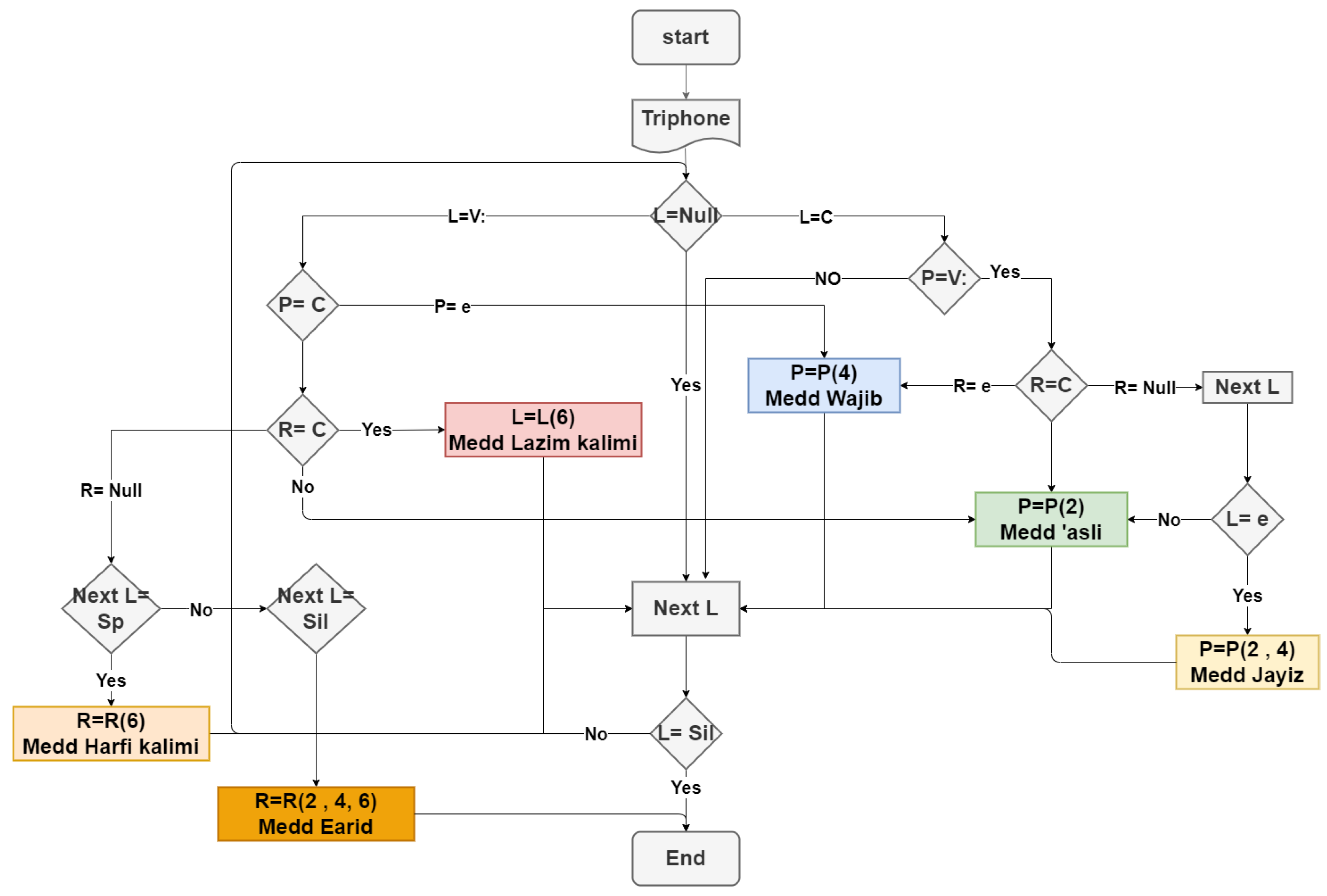
3.3.1. CV-Triphone and Possible Permutations Table
- ▪
- The maximum number of words concerned to extract the Medd rule for any Medd letter is two, and there are at most four phonemes concerned by the Medd rules that are either preceding or following the letter itself. Thus, it is necessary to take into account all the permutations for LPR, Next L where “P” means the phoneme treated, “L” represents the phoneme preceding the phoneme treated, “R” represents the phoneme immediately following the phoneme treated, “Next L” represents the first phoneme in next word following the phoneme treated;
- ▪
- The beginning of the word consists of P and R parts only, and the end of the word also consists of L and P parts only;
- ▪
- Hamza phoneme (e) influences the classification of the Medd if it comes directly after the Medd letter or at the beginning of the next word; therefore, it is separated from the rest of the consonants;
- ▪
- The letters that have Shaddah were taken into consideration because of their effect on the Medd rules;
- ▪
- Since the rules of Medd are either in one word or in two words, and the Medd letter is in one word, either it is within the word in the middle of the recitation or at the end of the last word before stopping reciting (silence). Thus, it can be divided into three categories: Medd cases within one word, Medd cases at the end of the last word, and Medd cases within two words.
- ▪
- First classification: the number of possible states of the triple phoneme within one word. In this category, the cases of L can be (V, V:, C, e, or blank), possible cases of P are (V, V:, C, or e), possible cases of R are (V, V:, C, or e), and Next L can be only (*), hence the number of possible Permutations = 5 × 4 × 4 × 1 = 80;
- ▪
- Second classification: the number of possible states of the triple phoneme at the end of the last word. In this category, the cases of L can be (V, V:, C, or e), possible cases of P are (V, V:, C, or e), possible cases of R are (V, V:, C, e, or blank), and Next L can be only (sil). Hence the number of possible Permutations = 4 × 4 × 5 × 1 = 80;
- ▪
- Third classification: the number of possible cases of the triple phoneme within two words. In this category, the cases of L can be (V, V:, C, or e), possible cases of P are (V, V:, C, or e), possible cases of R can be only (blank), and Next L can be only (C or e). Hence the number of possible Permutations = 4 × 4 × 1 × 2 = 32. In addition, sil and sp are special cases in the triphone tree.
3.3.2. Identify Medd Type
3.3.3. Rule-Based Phoneme Duration Algorithm for Medd Classification
- D = 0;
- For i = 1 To MaxP // MaxP is no. of last phoneme.
- if (Medd_type = Jayiz Or Earid) // Medd type in CV-triphone then
- Medd_Duration = D; // Medd_Duration the required duration.
- if (duration = 2 Or 4 Or 6) // Duration can get from ANN-PDEM
- if (D = 0) then
- D = duration;
- Medd_Duration = D;
3.3.4. Scientific Formulation of Medd Based on Tajweed Rules
- ▪
- “P” means the phoneme treated, “L” represents the phoneme preceding the phoneme treated, “R” represents the phoneme immediately following the phoneme treated, and “Next L” represents the first phoneme of the next word following the phoneme treated;
- ▪
- “C” indicates consonants, “V“ indicates short vowels, “V:“ indicates long vowels, “e“ indicates Hamza letter, and “*” is used as a wildcard character to replace any phoneme. These letters affect the rules of the Medd;
- ▪
- “sp” represents a space character (between two words);
- ▪
- The symbol “Sil” means silence;
- ▪
- “Phoneme duration” means the required duration according to the type of Medd base in Tajweed rules;
- ▪
- “D” indicates the chosen duration required for some types of Medd that depend on the choice of the reciter at the beginning of his recitation, such as Medd Asli Earid LilSukoon, where the reciter chooses to prolong the Medd letter by two, four, or six movements, and then he must adhere to what he chose;
- ▪
- Finally, “Ruling” means the rule and type of Medd;
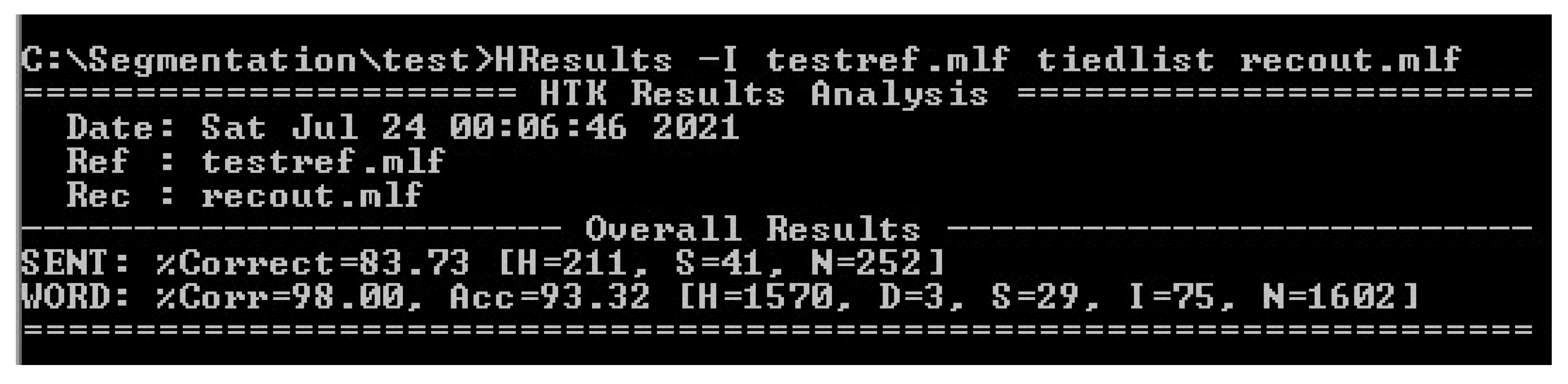
4. Result and Discussion
- The dictionary was checked manually, and errors in translating some words into phonemes were corrected, especially vowels and long vowels;
- Errors in the positions of Shaddah were observed in the dictionary, which led to a weakness in the accuracy of Medd Lazim Kalimi recognition. These errors have been corrected;
- Some Qur’an words were added to the dictionary, which are three letters representing the Medd Lazim Harfi: حم, ق, and ن. This is because the automatic generation of the dictionary regards it as normal letters, but it is recited as words in the Qur’an recitation;
- Alif, which does not pronounce, was considered as Fathah in the dictionary. This means that the phoneme /aa:/ has been modified to /aa / and phoneme /ae:/ to /ae/ in all words that are not pronounced as Medd, such as “وَالْقُرْآنِ” it was like “w ae: l q ux r e ae: n ih sp” and modified to “w ae l q ux r e ae: n ih sp”;
- The appropriate conditions and restrictions were added for each Medd type according to the cases.
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Nazir, F.; Majeed, M.N.; Ghazanfar, M.A.; Maqsood, M. A computer-aided speech analytics approach for pronunciation feedback using deep feature clustering. Multimed. Syst. 2021, 1–17. [Google Scholar] [CrossRef]
- Samir, A.; Abdou, S.M.; Khalil, A.H.; Rashwan, M. Enhancing usability of CAPL system for qur’an recitation learning. In Proceedings of the INTERSPEECH, Antwerp, Belgium, 27–31 August 2007; pp. 214–217. [Google Scholar]
- Metwalli, S.E.H.M. Computer Aided Pronunciation Learning System Using Statistical Based Automatic Speech Recognition Techniques; Cairo University: Giza Governorate, Egypt, 2005. [Google Scholar]
- Hassan, S.S.B.; Zailaini, M.A.B. Analysis of tajweed errors in Quranic recitation. In Proceedings of the Procedia-Social and Behavioral Sciences, Barcelona, Spain, 27–29 October 2013; pp. 136–145. [Google Scholar]
- Almisreb, A.A.; Abidin, A.F.; Tahir, N.M. An acoustic investigation of Arabic vowels pronounced by Malay speakers. J. King Saud Univ. Comput. Inf. Sci. 2016, 28, 148–156. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, N.J.; Razak, Z.; Mohd Yusoff, Z.; Idris, M.Y.I.; Mohd Tamil, E.; Mohamed Noor, N.; Rahman, A.; Naemah, N. Quranic Verse recitation recognition module for support in J-QAF learning: A Review. Int. J. Comput. Sci. Netw. Secur. 2008, 8, 207–216. [Google Scholar]
- Tabbal, H.; El Falou, W.; Monla, B. Analysis and implementation of a “Quranic” verses delimitation system in audio files using speech recognition techniques. In Proceedings of the Information and Communication Technologies, 2006 ICTTA’06, 2nd, Berkeley, CA, USA, 25–26 May 2006; pp. 2979–2984. [Google Scholar]
- Hassan, T.; Wassim, A.-F.; Bassem, M. Analysis and Implementation of an Automated Delimiter of “Quranic” Verses in Audio Files using Speech Recognition Techniques. In Robust Speech Recognition and Understanding; BoD–Books on Demand: Paris, France, 2007; Volume 351. [Google Scholar]
- Hanna, S.; El-Farahaty, H.; Khalifa, A.-W. The Routledge Handbook of Arabic Translation; Routledge: London, UK, 2019. [Google Scholar]
- Kirchhoff, K.; Bilmes, J.; Das, S.; Duta, N.; Egan, M.; Ji, G.; He, F.; Henderson, J.; Liu, D.; Noamany, M. Novel approaches to Arabic speech recognition: Report from the 2002 Johns-Hopkins summer workshop. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003, ICASSP’03, Hong Kong, China, 6–10 April 2003; pp. 344–347. [Google Scholar]
- Rushdi, A.; Swayd; Karul, K. Tajweed Rules in the Holy Quran; Dar Al-Khair Islamic Books Publisher: Syria-Damascus, Syria, 2000. [Google Scholar]
- Ramteke, P.B.; Koolagudi, S.G. Phoneme boundary detection from speech: A rule based approach. Speech Commun. 2019, 107, 1–17. [Google Scholar] [CrossRef]
- Maqsood, M. Quranic Recitation Pronunciation Modeling and Analysis; University of Engineering and Technology: Taxila, Pakistan, 2017. [Google Scholar]
- Abro, B.; Naqvi, A.B.; Hussain, A. Qur’an Recognition for the Purpose of Memorisation Using Speech Recognition Technique. In Proceedings of the 2012 15th International Multitopic Conference (INMIC), Islamabad, Pakistan, 13–15 December 2012; pp. 30–34. [Google Scholar]
- Ahmad, S.; Badruddin, S.N.; Hashim, N.N.; Embong, A.H.; Altalmas, T.M.; Hasan, S.S. The Modeling of the Quranic Alphabets’ Correct Pronunciation for Adults and Children Experts. In Proceedings of the 2019 2nd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 1–3 May 2019; pp. 1–6. [Google Scholar]
- Putra, B.; Atmaja, B.; Prananto, D. Developing Speech Recognition System for Quranic Verse Recitation Learning Software. Int. J. Inform. Dev. 2012, 1, 14–21. [Google Scholar] [CrossRef] [Green Version]
- Pal, S.K.; Datta, A.; Majumder, D.D. A self-supervised vowel recognition system. Pattern Recognit. 1980, 12, 27–34. [Google Scholar] [CrossRef]
- Alghamdi, M.M. A spectrographic analysis of Arabic vowels: A cross-dialect study. J. King Saud Univ. 1998, 10, 3–24. [Google Scholar]
- Natarajan, V.A.; Jothilakshmi, S. Segmentation of continuous speech into consonant and vowel units using formant frequencies. Int. J. Comput. Appl. 2012, 56, 24–27. [Google Scholar] [CrossRef] [Green Version]
- Greenwood, M.; Kinghorn, A. SUVing: Automatic silence/unvoiced/voiced classification of speech. In Undergraduate Coursework; Department of Computer Science, The University of Sheffield: Sheffield, UK, 1999. [Google Scholar]
- Almekhlafi, E.; Moeen, A.-M.; Zhang, E.; Wang, J.; Peng, J. A classification benchmark for Arabic alphabet phonemes with diacritics in deep neural networks. Comput. Speech Lang. 2022, 71, 101274. [Google Scholar] [CrossRef]
- Oh, D.; Park, J.-S.; Kim, J.-H.; Jang, G.-J. Hierarchical phoneme classification for improved speech recognition. Appl. Sci. 2021, 11, 428. [Google Scholar] [CrossRef]
- Zangar, I.; Mnasri, Z.; Colotte, V.; Jouvet, D. Duration modelling and evaluation for Arabic statistical parametric speech synthesis. Multimed. Tools Appl. 2021, 80, 8331–8353. [Google Scholar] [CrossRef]
- Ircio, J.; Lojo, A.; Mori, U.; Lozano, J.A. Mutual information based feature subset selection in multivariate time series classification. Pattern Recognit. 2020, 108, 107525. [Google Scholar] [CrossRef]
- Nazir, F.; Majeed, M.N.; Ghazanfar, M.A.; Maqsood, M. Mispronunciation detection using deep convolutional neural network features and transfer learning-based model for Arabic phonemes. IEEE Access 2019, 7, 52589–52608. [Google Scholar] [CrossRef]
- Akhtar, S.; Hussain, F.; Raja, F.R.; Ehatisham-ul-haq, M.; Baloch, N.K.; Ishmanov, F.; Zikria, Y.B. Improving mispronunciation detection of arabic words for non-native learners using deep convolutional neural network features. Electronics 2020, 9, 963. [Google Scholar] [CrossRef]
- Asif, A.; Mukhtar, H.; Alqadheeb, F.; Ahmad, H.F.; Alhumam, A. An approach for pronunciation classification of classical arabic phonemes using deep learning. Appl. Sci. 2021, 12, 238. [Google Scholar] [CrossRef]
- Luke, R.; Wouters, J. Kalman filter based estimation of auditory steady state response parameters. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 25, 196–204. [Google Scholar] [CrossRef] [PubMed]
- Masmoudi, A.; Bougares, F.; Ellouze, M.; Estève, Y.; Belguith, L. Automatic speech recognition system for Tunisian dialect. Lang. Resour. Eval. 2018, 52, 249–267. [Google Scholar] [CrossRef]
- Newman, D.; Verhoeven, J. Frequency analysis of Arabic vowels in connected speech. Antwerp Pap. Linguist. 2002, 100, 77–86. [Google Scholar]
- Iqbal, H.R.; Awais, M.M.; Masud, S.; Shamail, S. On vowels segmentation and identification using formant transitions in continuous recitation of Quranic Arabic. In New Challenges in Applied Intelligence Technologies; Springer: Berlin/Heidelberg, Germany, 2008; pp. 155–162. [Google Scholar]
- Alotaibi, Y.A.; Hussain, A. Comparative analysis of Arabic vowels using formants and an automatic speech recognition system. Int. J. Signal Process. Image Process. Pattern Recognit. 2010, 3, 11–22. [Google Scholar]
- Tolba, M.; Nazmy, T.; Abdelhamid, A.; Gadallah, M. A novel method for Arabic consonant/vowel segmentation using wavelet transform. Int. J. Intell. Coop. Inf. Syst. 2005, 5, 353–364. [Google Scholar]
- Sarma, M.; Sarma, K.K. An ANN based approach to recognize initial phonemes of spoken words of Assamese language. Appl. Soft Comput. 2013, 13, 2281–2291. [Google Scholar] [CrossRef]
- Ibrahim, A.B.; Seddiq, Y.M.; Meftah, A.H.; Alghamdi, M.; Selouani, S.-A.; Qamhan, M.A.; Alotaibi, Y.A.; Alshebeili, S.A. Optimizing arabic speech distinctive phonetic features and phoneme recognition using genetic algorithm. IEEE Access 2020, 8, 200395–200411. [Google Scholar] [CrossRef]
- Awadalla, M.; Chadi, F.A.; Soliman, H. Development of an Arabic speech database. In Proceedings of the 2005 International Conference on Information and Communication Technology, London, UK, 13–16 December 2005; pp. 89–100. [Google Scholar]
- Wk Lo, T.L.; Ching, P. Development of Cantonese spoken language corpora for speech applications. In Proceedings of the 1998 International Symposium on Chinese Spoken Language Processing, Singapore, 7–9 December 1998; pp. 102–107. [Google Scholar]
- Ali, M.; Elshafei, M.; Al-Ghamdi, M.; Al-Muhtaseb, H.; Al-Najjar, A. Generation of Arabic phonetic dictionaries for speech recognition. In Proceedings of the 2008 International Conference on Innovations in Information Technology, Al Ain, United Arab Emirates, 16–18 December 2008; pp. 59–63. [Google Scholar]
- Ramesh, V.M. Exploring Data Analysis in Music using tool praat. In Proceedings of the 2008 First International Conference on Emerging Trends in Engineering and Technology, Nagpur, India, 16–18 July 2008; pp. 508–509. [Google Scholar]
- Mohammed, A.; Sunar, M.S.; Salam, M.S.H. Quranic Verses Verification using Speech Recognition Techniques. Jurnal Teknologi 2015, 73, 99–106. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, A.; Sunar, M. Verification of Quranic Verses in Audio Files using Speech Recognition Techniques. In Proceedings of the International Conference of Recent Trends in Information and Communication Technologies (IRICT), Chandigarh, India, 21 March 2014. [Google Scholar]
- Desai, N.; Dhameliya, K.; Desai, V. Feature extraction and classification techniques for speech recognition: A review. Int. J. Emerg. Technol. Adv. Eng. 2013, 3, 367–371. [Google Scholar]
- Dave, N. Feature extraction methods LPC, PLP and MFCC in speech recognition. Int. J. Adv. Res. Eng. Technol. 2013, 1, 1–4. [Google Scholar]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.; Moore, G.; Odell, J.; Ollason, D.; Povey, D. The HTK Book; Cambridge University Engineering Department: Cambridge, UK, 2006; Volume 3, p. 75. [Google Scholar]
- Friedman-Hill, E. Jess in Action: Rule-Based Systems in Java; Simon and Schuster: New York, NY, USA, 2003. [Google Scholar]
- Pihlqvist, F.; Mulongo, B. Using Rule-Based Methods and Machine Learning for Short Answer Scoring; Kth Royal Institute of Technology: Stockholm, Sweden, 2018. [Google Scholar]
- Czerepinski, K.C.; Swayd, A.R. Tajweed Rules of the Qur'an; Dar Al-Khair Islamic Books Publisher: Damascus, Syria, 2006; Volume 1. [Google Scholar]
- Elhadj, Y.O.M.; Aoun-Allah, M.; Alsughaiyer, I.A.; Alansari, A. A New Scientific Formulation of Tajweed Rules for E-Learning of Quran Phonological Rules. In E-Learning - Engineering, On-Job Training and Interactive Teaching; Silva, A., Pontes, E., Guelfi, A., Kofuji, T.K., Eds.; BoD—Books on Demand: Rijeka, Croatia, 2012; pp. 197–212. [Google Scholar]
- Wang, Y.; Wang, P.; Ding, K.; Li, H.; Zhang, J.; Liu, X.; Bai, Q.; Wang, D.; Jin, B. Pattern recognition using relevant vector machine in optical fiber vibration sensing system. IEEE Access 2019, 7, 5886–5895. [Google Scholar] [CrossRef]
- Baratloo, A.; Hosseini, M.; Negida, A.; El Ashal, G. Part 1: Simple Definition and Calculation of Accuracy, Sensitivity and Specificity; Spring: Tehran, Iran, 2015; Volume 3, pp. 48–49. [Google Scholar]
- Wahyuni, E.S. Arabic speech recognition using MFCC feature extraction and ANN classification. In Proceedings of the 2017 2nd International conferences on Information Technology, Information Systems and Electrical Engineering (ICITISEE), IEEE, Yogyakarta, Indonesia, 1–3 November 2017; pp. 22–25. [Google Scholar]
- Hamed, T.; Dara, R.; Kremer, S.C. Intrusion Detection in Contemporary Environments. In Computer and Information Security Handbook; Elsevier: Amsterdam, The Netherlands, 2017; pp. 109–130. [Google Scholar]
- Markham, K. Simple Guide to Confusion Matrix Terminology; Data School: London, UK, 2014; p. 25. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Medd | Name of Medd | Hokom | Example |
|---|---|---|---|
| The Natural Lengthening | Medd ‘asli | Normal prolongation of 2 vowels. | قَالَ |
| Lesser Connecting Medd | Normal prolongation of 2 vowels. | إِنَّهُ كَانَ | |
| The Substitute Medd | Normal prolongation of 2 vowels. | شَكُورَاً | |
| The Secondary Medd | Medd Wajib Mutasil | Prolongation of 4 vowels. | السَّمـاءِ |
| Medd Jayiz Munfasil | Prolongation of 4 vowels. | يَا أَيُّها | |
| The Exchange Medd | Normal prolongation of 2 vowels. | ءَادَمُ | |
| Greater Connection Medd | Prolongation of 4 vowels. | يَرَهُ أَحَدٌ | |
| Medd Earid LilSukoon | Prolongation of 2 or 4 or 6 vowels. | العَالَمًيـــنَ | |
| The Leen Medd | Prolongation of 2 or 4 or 6 vowels. | خَــوفٍ | |
| Medd Lazim Kalimi | Prolongation of 6 vowels. | الطَّامَّةُ | |
| Medd Lazim Harfi | Prolongation of 6 vowels. | حـــم |
| Ayah | ||
|---|---|---|
| النَّجْمُ الثَّاقِبُ | الْحَـاقَّـةُ | الَّذِي أَطْعَمَهُم مِّن جُوعٍ وَآمَنَهُم مِّنْ خَوْفٍ |
| إِنْ كُلُّ نَفْسٍ لَمَّا عَلَيْهَا حَافِظٌ | قُلْ أَفَغَيْرَ اللَّهِ تَأْمُرُونِّي أَعْبُدُ أَيُّهَا الْجَاهِلُونَ | فَإِذَا جَاءَتِ الطَّامَّةُ الْكُبْرَى |
| اقْرَأْ وَرَبُّكَ الْأَكْرَمُ | وَالسَّمَاءِ ذَاتِ الرَّجْعِ | فَإِذَا جَاءَتِ الصَّاخَّةُ |
| فَصَلِّ لِرَبِّكَ وَانْحَرْ | وَجِيءَ يَوْمَئِذٍ بِجَهَنَّمَ | قُلْ هُوَ اللَّهُ أَحَدٌ |
| إِنَّ شَانِئَكَ هُوَ الْأَبْتَرُ | انطَلِقُوا إِلَى مَا كُنتُم بِهِ تُكَذِّبُونَ | حم |
| جَزَاءً مِنْ رَبِّكَ عَطَاءً حِسَابًا | إِنَّا أَعْطَيْنَاكَ الْكَوْثَرَ | ق وَالْقُرْآنِ الْمَجِيد |
| L | P | R | Next L | Medd Type | Rule | L | P | R | Next L | Medd Type | Rule |
|---|---|---|---|---|---|---|---|---|---|---|---|
| C | V: | C | * | Medd ’asli | 2 | blank | V: | V | * | No Med | 1 |
| V: | C | V | * | Medd ’asli | 2 | blank | V: | V: | * | No Med | 1 |
| e | V: | C | * | Medd ’asli | 2 | blank | e | C | * | No Med | 1 |
| C | V: | C | Sil | Medd ’asli | 2 | blank | e | e | * | No Med | 1 |
| e | V: | C | Sil | Medd ’asli | 2 | blank | V | V | * | No Med | 1 |
| C | V: | blank | Sil | Medd ’asli | 2 | blank | V | V: | * | No Med | 1 |
| e | V: | blank | Sil | Medd ’asli | 2 | C | C | C | * | No Med | 1 |
| C | V: | blank | C | Medd ’asli | 2 | C | V | e | * | No Med | 1 |
| V: | C | blank | e | Medd ’asli | 2 | V | V | C | * | No Med | 1 |
| V: | C | blank | C | Medd ’asli | 2 | e | V | C | * | No Med | 1 |
| e | V: | blank | C | Medd ’asli | 2 | e | V | e | * | No Med | 1 |
| V: | C | V | Sil | Medd Eaeid LilSkoon | 2,4,6 | C | C | C | Sil | No Med | 1 |
| C | V: | blank | e | Med Jayaz | 2,4 | C | V | e | Sil | No Med | 1 |
| e | V: | blank | e | Med Jayaz | 2,4 | V | V | C | Sil | No Med | 1 |
| V: | C | blank | Sil | Med Lazim harfi | 6 | e | V | C | Sil | No Med | 1 |
| V: | C | C | * | Med Lazim Kalmi | 6 | e | V | e | Sil | No Med | 1 |
| V: | C | C | Sil | Med Lazim Kalmi | 6 | C | V | blank | Sil | No Med | 1 |
| C | V: | e | * | Med Wajib | 4 | e | V | blank | Sil | No Med | 1 |
| V: | e | V | * | Med Wajib | 4 | C | C | blank | e | No Med | 1 |
| e | V: | e | * | Med Wajib | 4 | C | C | blank | C | No Med | 1 |
| C | V: | e | Sil | Med Wajib | 4 | V | e | blank | e | No Med | 1 |
| V: | e | V | Sil | Med Wajib | 4 | V | e | blank | C | No Med | 1 |
| e | V: | e | Sil | Med Wajib | 4 | V | V | blank | e | No Med | 1 |
| V: | e | blank | Sil | Med Wajib | 4 | V | V | blank | C | No Med | 1 |
| V: | e | blank | e | Med Wajib | 4 | e | e | blank | e | No Med | 1 |
| V: | e | blank | C | Med Wajib | 4 | e | e | blank | C | No Med | 1 |
| Medd Type | Real Statistics | Proposed Algorithm (RPDAMC) Results | ||||
|---|---|---|---|---|---|---|
| TP | TN | TP | FP | TN | FN | |
| Medd ‘asli | 26 | 722 | 25 | 0 | 722 | 1 |
| Medd Wajib Mutasil | 7 | 741 | 7 | 0 | 741 | 0 |
| Medd Jayiz Munfasil | 4 | 744 | 4 | 0 | 744 | 0 |
| Medd Lazim Kalimi | 5 | 743 | 5 | 0 | 743 | 0 |
| Medd Lazim Harifi | 3 | 745 | 3 | 0 | 745 | 0 |
| Med Earid LilSukoon | 6 | 742 | 6 | 0 | 742 | 0 |
| Medd Type | Confusion Matrix Rates % | ||||||
|---|---|---|---|---|---|---|---|
| ACC | TPR | TNR | FPR | FNR | P | ERR | |
| Medd ‘asli | 99.87 | 96.51 | 100 | 0 | 3.85 | 100 | |
| Medd Wajib Mutasil | 100 | 100 | 100 | 0 | 0 | 100 | 0 |
| Medd Jayiz Munfasil | 100 | 100 | 100 | 0 | 0 | 100 | 0 |
| Medd Lazim Kalimi | 100 | 100 | 100 | 0 | 0 | 100 | 0 |
| Medd Lazim Harifi | 100 | 100 | 100 | 0 | 0 | 100 | 0 |
| Med Earid LilSukoon | 100 | 100 | 100 | 0 | 0 | 100 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alqadasi, A.M.A.; Sunar, M.S.; Turaev, S.; Abdulghafor, R.; Hj Salam, M.S.; Alashbi, A.A.S.; Salem, A.A.; Ali, M.A.H. Rule-Based Embedded HMMs Phoneme Classification to Improve Qur’anic Recitation Recognition. Electronics 2023, 12, 176. https://doi.org/10.3390/electronics12010176
Alqadasi AMA, Sunar MS, Turaev S, Abdulghafor R, Hj Salam MS, Alashbi AAS, Salem AA, Ali MAH. Rule-Based Embedded HMMs Phoneme Classification to Improve Qur’anic Recitation Recognition. Electronics. 2023; 12(1):176. https://doi.org/10.3390/electronics12010176
Chicago/Turabian StyleAlqadasi, Ammar Mohammed Ali, Mohd Shahrizal Sunar, Sherzod Turaev, Rawad Abdulghafor, Md Sah Hj Salam, Abdulaziz Ali Saleh Alashbi, Ali Ahmed Salem, and Mohammed A. H. Ali. 2023. "Rule-Based Embedded HMMs Phoneme Classification to Improve Qur’anic Recitation Recognition" Electronics 12, no. 1: 176. https://doi.org/10.3390/electronics12010176