1. Introduction
The point cloud is a popular 3D shape representation. The 3D point analysis has many important applications in the Metaverse, such as classifying [
1] and completing [
2] the acquired 3D models to be used. With the rapid development of the Metaverse, a large number of new 3D point cloud models are generated and acquired. Many models are novel, have never been seen before, or come unlabeled. Such limited information brings challenges to data-driven 3D point cloud analyses, such as classification, because they strongly rely on sufficiently labeled training data [
3,
4]. To tackle this problem, we propose a convolution neural network, GN-CNN, with a few-shot learning approach by utilizing a generative adversarial network GN-GAN to extract prior knowledge for augmenting the information.
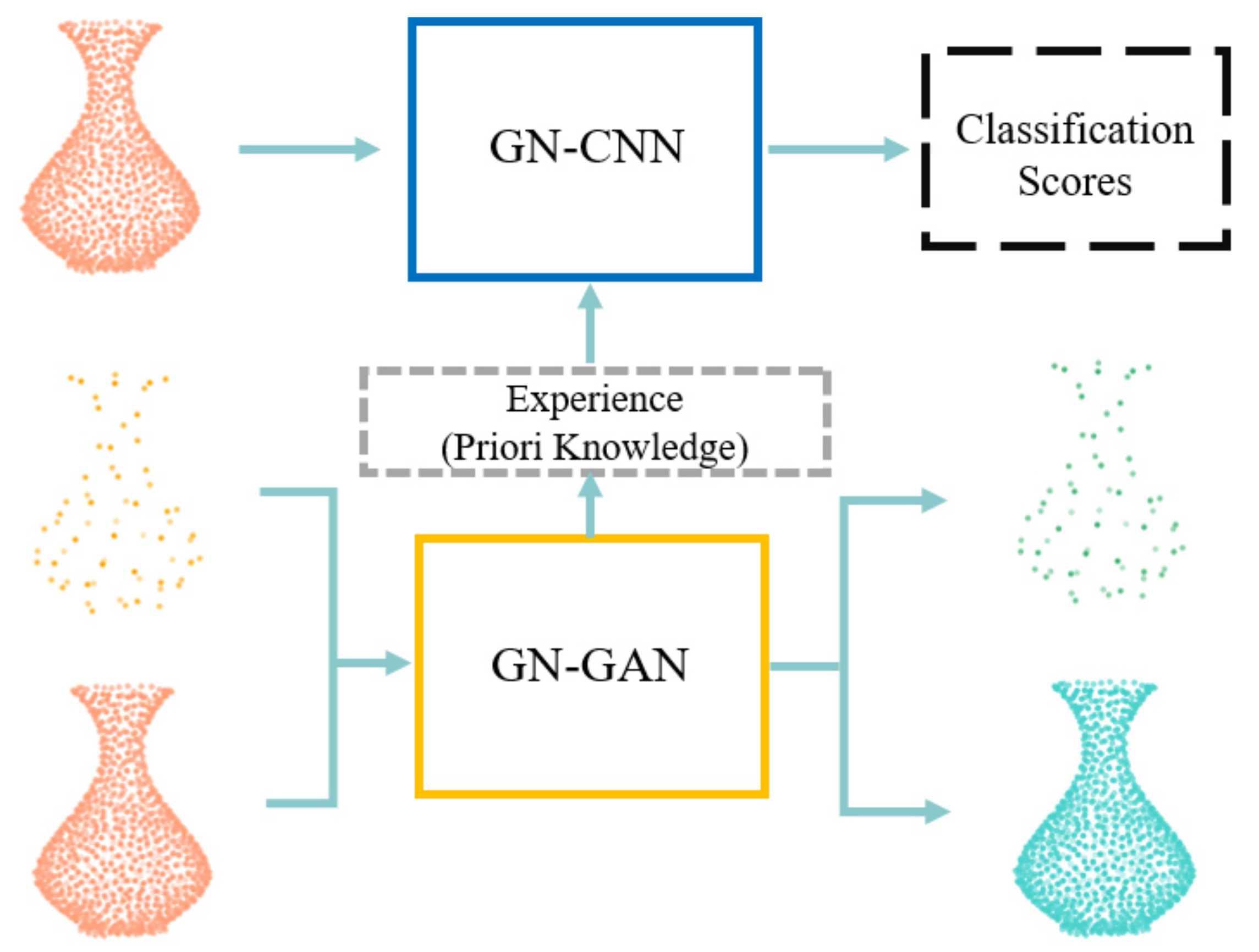
As shown in
Figure 1, we pre-trained the GN-GAN to a warm start [
5,
6] GN-CNN, which is the 3D point cloud analysis network. GN-GAN obtains the global point cloud feature (experience) vector. Then the vector is plugged in as prior knowledge into the backbone network of GNConv, which is used as the convolution-like operation in GN-CNN. Using the original and downsampled input helps to learn multi-scale point cloud features.
Furthermore, the 3D models in the Metaverse are usually acquired with a focus on the model’s visual appearances instead of the exact point positions, for example, for driving [
7] and indoor navigation [
8], more attention is usually paid to the model’s appearance to make sure the models look good, instead of the model actual accuracy, which is usually the focus of computer-aided design (CAD). Based on this, unlike existing (few-shot) learning methods [
9,
10], we propose unleashing the model appearance to further augment the information. The model’s local surface variance and normal information determine how light is reflected, and how the model’s appearance is perceived by the viewers. Therefore, they are utilized in the proposed pipeline: First, in the encoder of the encoder/decoder framework of the GN-GAN generator, we introduced a graph convolution-enhanced combined multilayer perceptron operation (CMLP [
11]), namely GCMLP, by adding several graph convolution layers. Second, in GN-CNN, we utilize local neighborhood normal information.
Different from the existing graph convolution-based methods, such as DGCNN [
12] and GeoConv [
13], we used graph convolution to enhance CMLP [
11], which does not handle geometric relationships well. By integrating the capability of CMLP in learning different levels of feature information and the capability of graph convolution in learning local spatial connection relationships, the local surface variance information can be better learned. Together with the normal information, the appearance of the model can be better captured.
In this paper, we focus on classification and few-shot learning (GN-CNN) as well as reconstruction (GU-GAN) tasks of 3D point cloud analysis. Our contributions are summarized as the following:
- (1)
We propose a convolution neural network framework GN-CNN that is suitable for Metaverse applications. We propose a few-shot learning approach using an unsupervised generative adversarial network GU-GAN to warm start GN-CNN by generating prior knowledge.
- (2)
We propose the graph-enhanced combined multilayer perceptron operation (GCMLP) in the GN-GAN encoder and normal-aware graph convolution operation GNConv to better capture the model appearance information.
- (3)
Based on evaluations, state-of-the-art 3D point cloud classification accuracy and few-shot learning accuracy on ModelNet40 and ModelNet10 are achieved.
Please refer to the table of abbreviations for the main abbreviations used in this paper.
3. Method
This section presents the proposed GN-CNN and GN-GAN and the core operations in the two networks. We will first introduce our overall architecture, GN-CNN, and warm start strategy, then describe the structure of GCMLP and GN-GAN.
3.1. The Overall Architecture and GN-CNN
The overall network architecture includes GN-CNN, which is the backbone network for point cloud classification and few-shot learning tasks, as well as GN-GAN, which aims at warm starting GN-CNN. GN-GAN can also be used for point cloud reconstruction tasks.
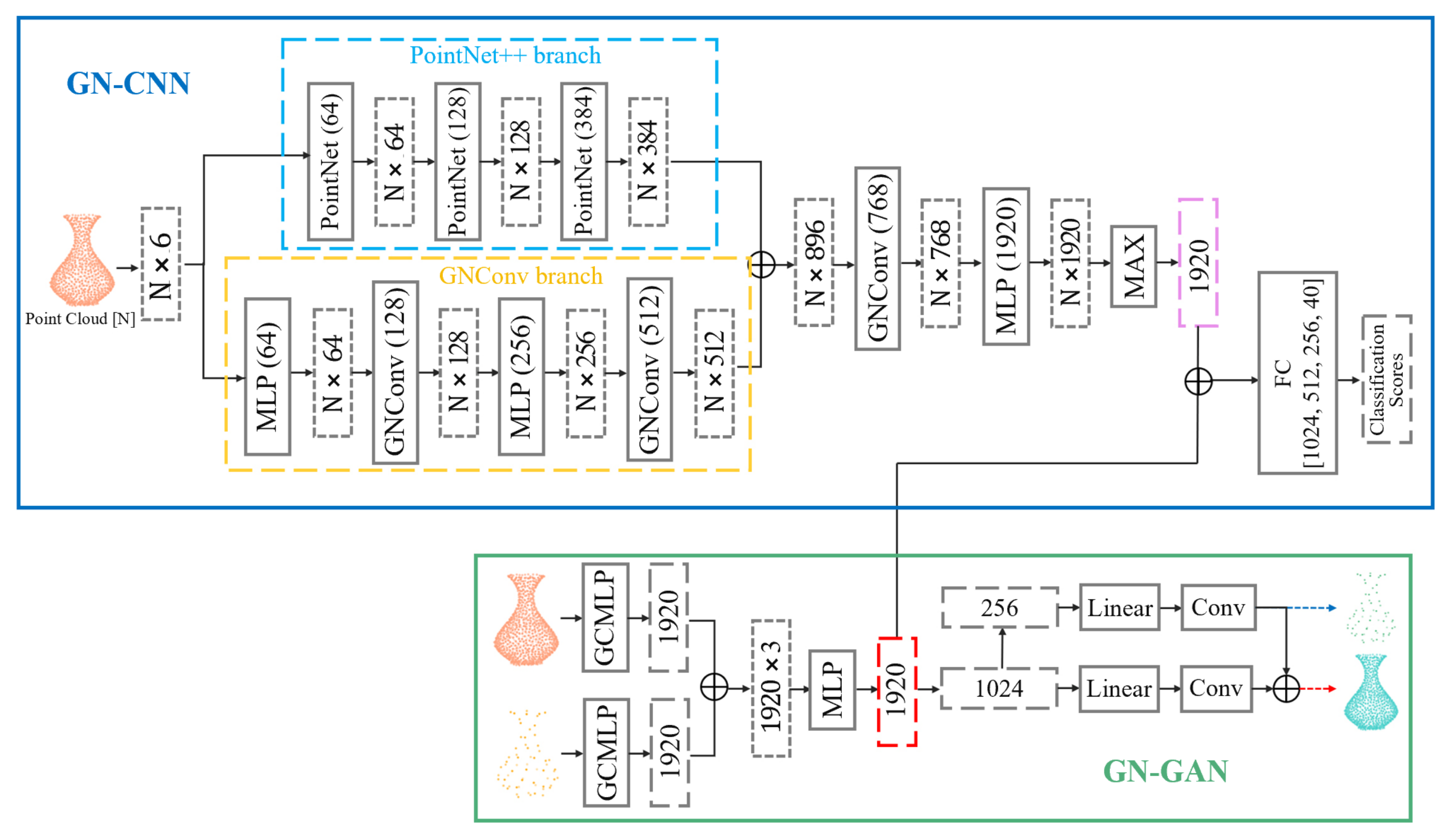
Our GN-CNN pipeline is inspired by Geo-CNN [
11], and the network structure is also divided into two branches, as shown in
Figure 2. The first branch of GN-CNN is PointNet++, using PointNet to extract features layer by layer. Each layer uses multilayer perceptron (MLP) and max pooling to abstract features to high dimensions, and the three layers of PointNet encode features into dimensions [64, 128, 384], and finally, we obtain a feature size of
, where
N is the number of points.
In the second branch of GN-CNN, the input is the same as the first branch. First, the input point cloud feature with a size of into an MLP to map the size of the feature to , and then pass a layer of GNConv to obtain the feature with a size of , and then pass an MLP to obtain the feature with a size of and follow a layer of GNConv to obtain the feature with a size of . The feature obtained by the first branch is connected to obtain a feature of size , and then input into a layer of GNConv to obtain a feature of size , and finally passes through an MLP to obtain a feature of size . Next, we use max pooling to obtain a vector with length [1920]. The vector with length [1920] is the point cloud global feature representation vector.
Next, we use the prior knowledge extracted by the GN-GAN encoder with the same length of [1920] for feature aggregation with the point cloud global feature vector extracted by GN-CNN encoder, and GN-CNN is warm-started. The aggregation function adopts an element-wise sum. The GN-CNN decoder consists of four FC layers with the vectors of output lengths [1024, 512, 256, C], where C is the number of classes in the point cloud classification tasks.
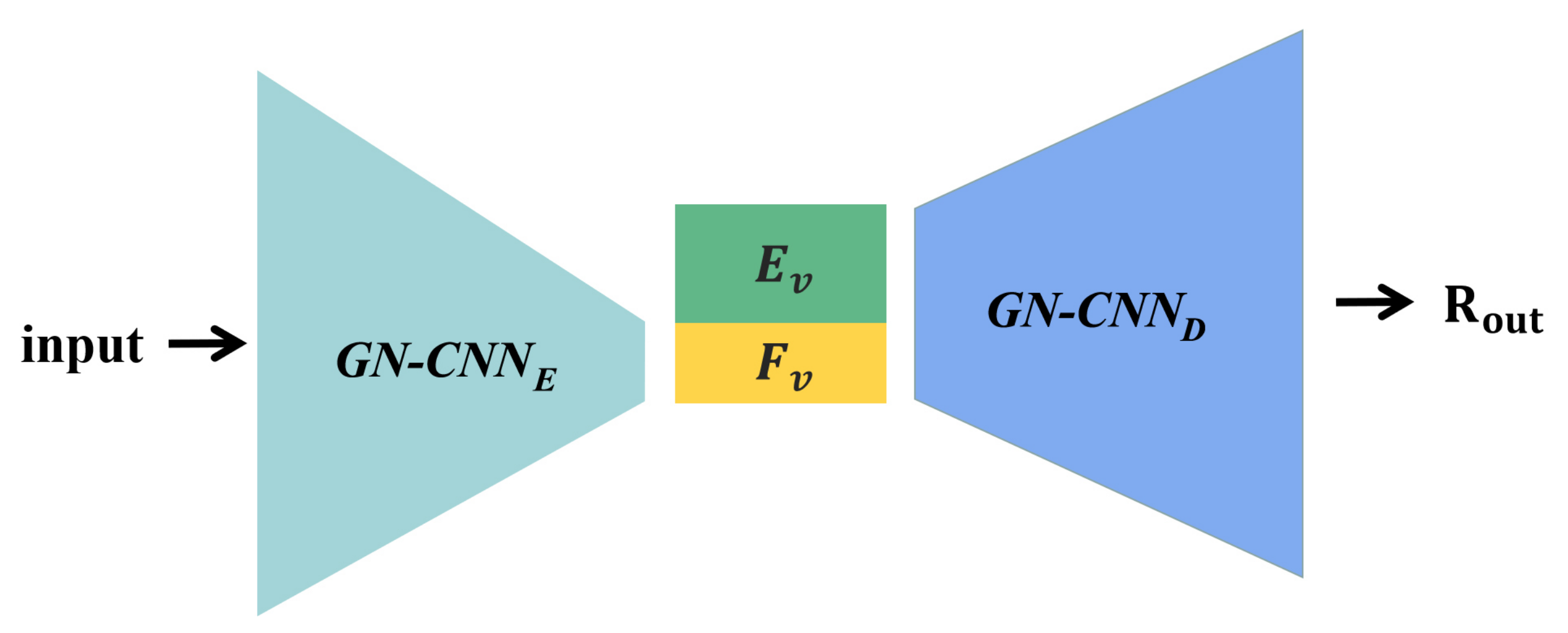
3.2. Warm Start
The warm start techniques are often used in the field of deep learning [
5,
6,
34] and reinforcement learning. The warm start is to initialize the network parameters to make networks have a particular experience at the beginning of training. This method can accelerate the convergence of the neural network. When the data size is limited, the neural network can make corresponding judgments based on the experience knowledge to obtain better few-shot learning results. Our warm start strategy is shown in
Figure 3.
is the encoder of GN-CNN,
is the decoder of GN-CNN,
is the global feature representation extracted by the GN-CNN encoder, and
is the experience knowledge. We aggregate
and
, and then input them into the decoder of GN-CNN.
is the output of the GN-CNN decoder. The output
of the GN-CNN decoder is defined as:
where
represents the encoder of GN-GAN,
P is a point cloud,
is the aggregation function, we use element-wise add as the aggregation function.
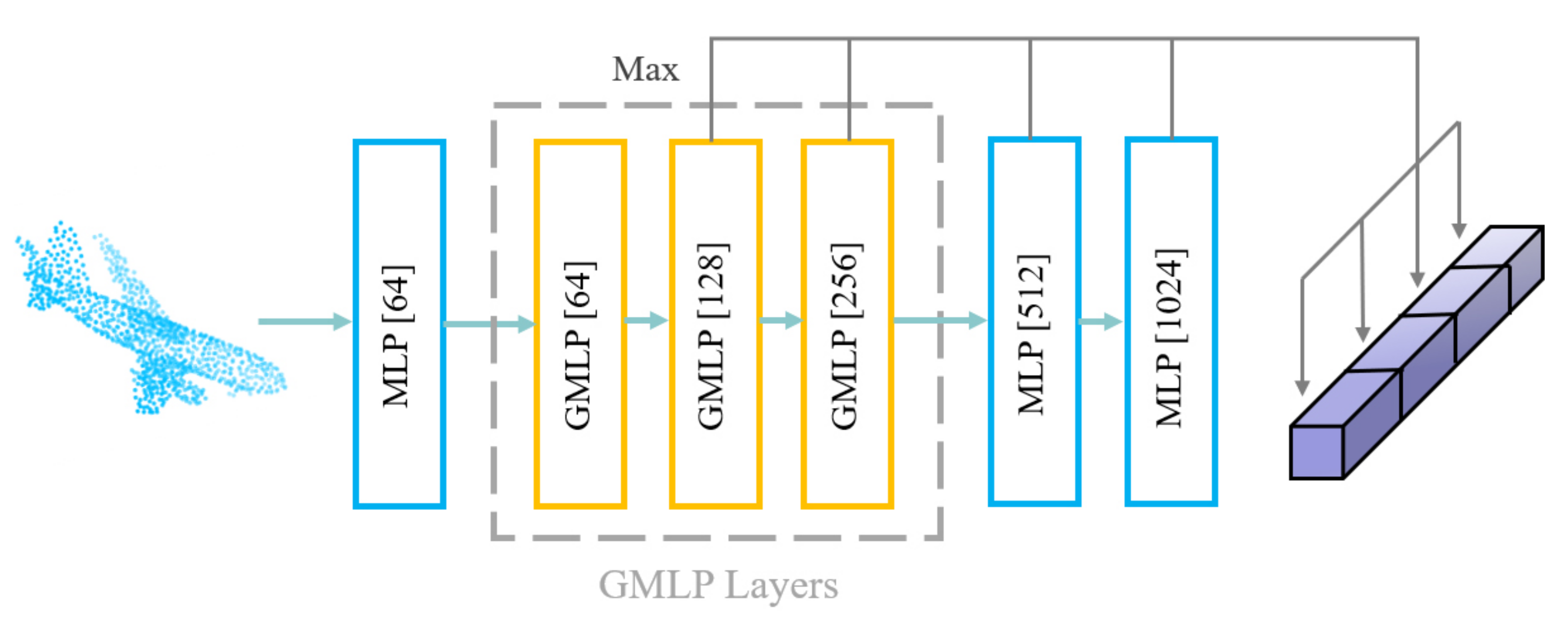
3.3. GCMLP
CMLP [
11] takes the maximum value in each channel on low-level and high-level through MLP and then concatenates the vector after the max pooling. CMLP can integrate low-level and high-level features to learn multi-level information better, but it does not handle the geometric relationship information among points.
Since graph convolution can handle geometric relationships among points, especially for the local neighborhood learning of point clouds, we propose GCMLP, as shown in
Figure 4, to improve CMLP performance by using a graph convolution layer named GMLP. In GCMLP, three MLP layers in CMLP are replaced with GMLP layers, while still concatenating the low-level and high-level feature vectors after max pooling. For a GMLP layer, we first use k-NN for each point
within
N points to find the
k nearest neighbors
and take
k neighboring points
as source points and
as target points and construct an edge
(including the self-loop from
to
). Finally, we concatenate
, and then go through the MLP layer.
GCMLP first uses an MLP to encode the dimensions of the original point cloud to [64], then uses three GMLP layers to encode the dimensions to [64, 128, 256], and finally is followed by two MLP layers to encode the dimensions to [512, 1024]. We max pool the output of the last four layers and concatenate the four vectors. The lengths of the four vectors are [128, 256, 512, 1024].
3.4. GN-GAN and Loss Function
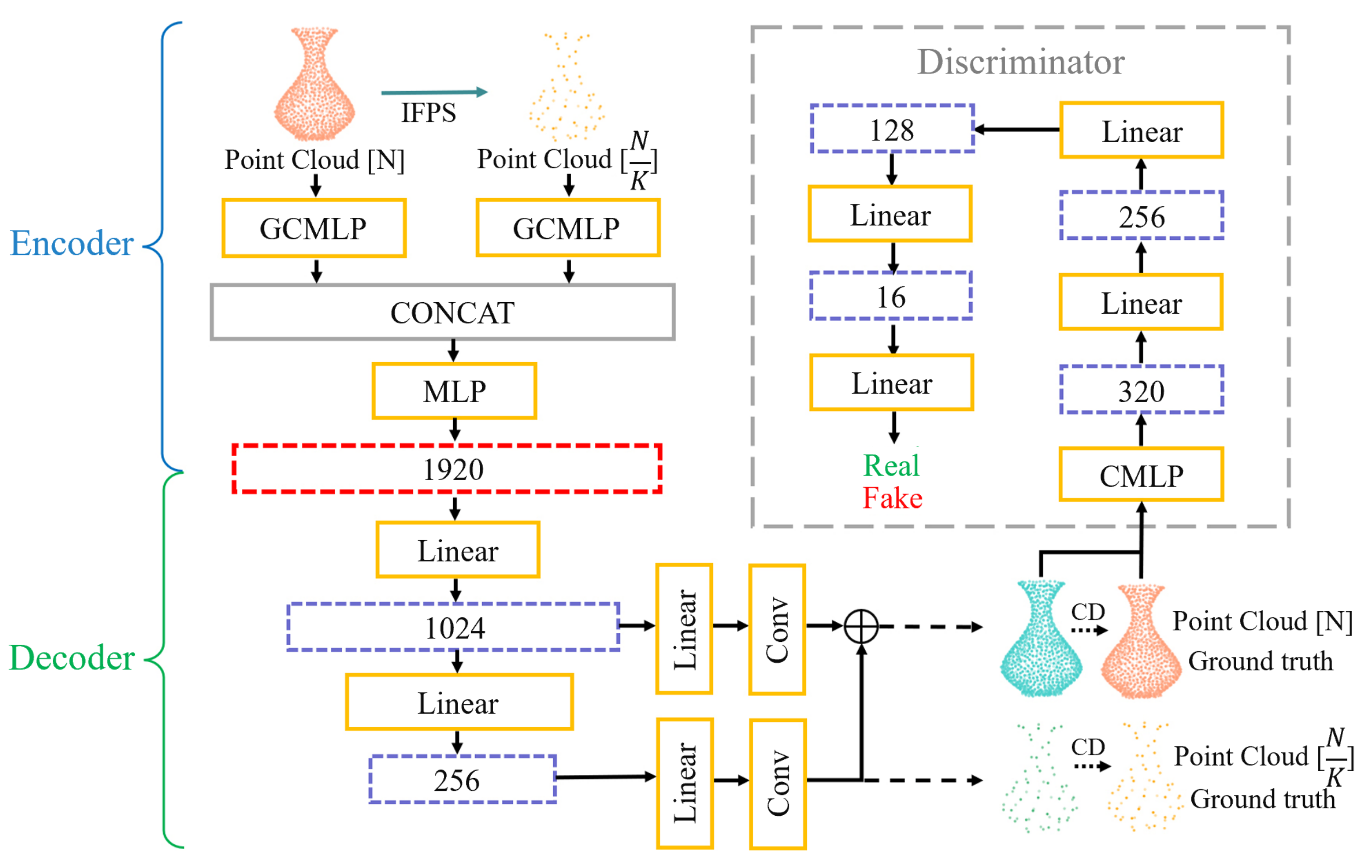
The overall structure of GN-GAN is shown in
Figure 5. We use iterative farthest point sampling (IFPS) to downsample the input point cloud to obtain two resolutions of the point cloud. The encoder of the GN-GAN generator takes both two resolutions as input. The number of points in the high-resolution point cloud is
N, and the number in the low-resolution point cloud after down-sampling is
. The point clouds with two resolutions are passed through two GCMLPs, respectively, and the generator reconstructs two point clouds with the same resolutions as respective inputs. We concatenate the two feature vectors obtained through GCMLP and input them into an MLP to encode the dimensions of the global feature vector
to 1920. CD is the Chamfer distance to evaluate the difference between the reconstructed point cloud and ground truth.
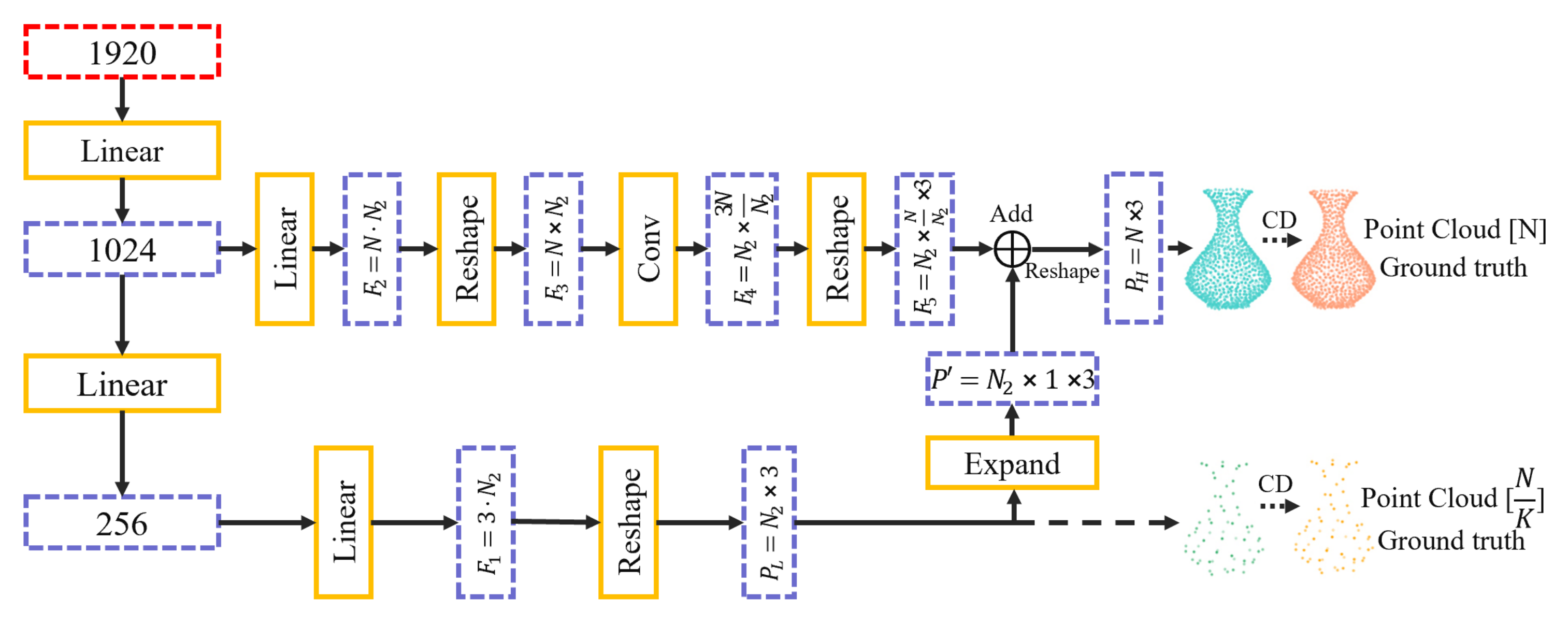
The structure of the decoder in the GN-GAN generator is shown in
Figure 6, where
is inputted into the decoder. The red box in
Figure 6 is
. We first use two fully connected (FC) layers to encode the dimensions of
to [1024, 256]. The [256] vector is used to obtain the vector
with the size of
through an FC layer, and
is reshaped to the size
to obtain
, which is the low-resolution reconstructed point cloud. Next, we use the [1024] vector to obtain
which size is
through the FC layer, reshape
into
of size
, and input
into a convolution layer to obtain
of size
. We reshape
to
of size
. At this point, we expand
to
, and add it to
. Finally, we reshape it to obtain the high-resolution reconstructed point clouds
of size
.
The reconstruction loss of GN-GAN is defined using the Chamfer distance. Chamfer distance is the average nearest squared distance between two point clouds. Define the ground truth point cloud as
, and the reconstructed point cloud is
, then Chamfer distance
between
and
is divided into two parts
and
:
Finally,
is defined as:
The reconstruction loss of GN-GAN is defined as:
where
is the Chamfer distance between the high-resolution reconstructed point cloud and the ground truth, and
is the Chamfer distance between the low-resolution reconstructed point cloud and the corresponding ground truth, and
is a hyperparameter.
The structure of the discriminator is shown in
Figure 5, and we divide the adversarial loss of the GN-GAN discriminator into two parts, which correspond to inputting the ground truth point cloud into the discriminator and inputting the reconstructed point cloud into the discriminator, respectively. The generator mapping process is defined as
and the discriminator mapping process is defined as
, then the adversarial loss is defined as:
where
,
. The joint loss of GN-GAN is defined as:
where
and
are weights to balance two parts of joint loss, which satisfy:
3.5. GNConv
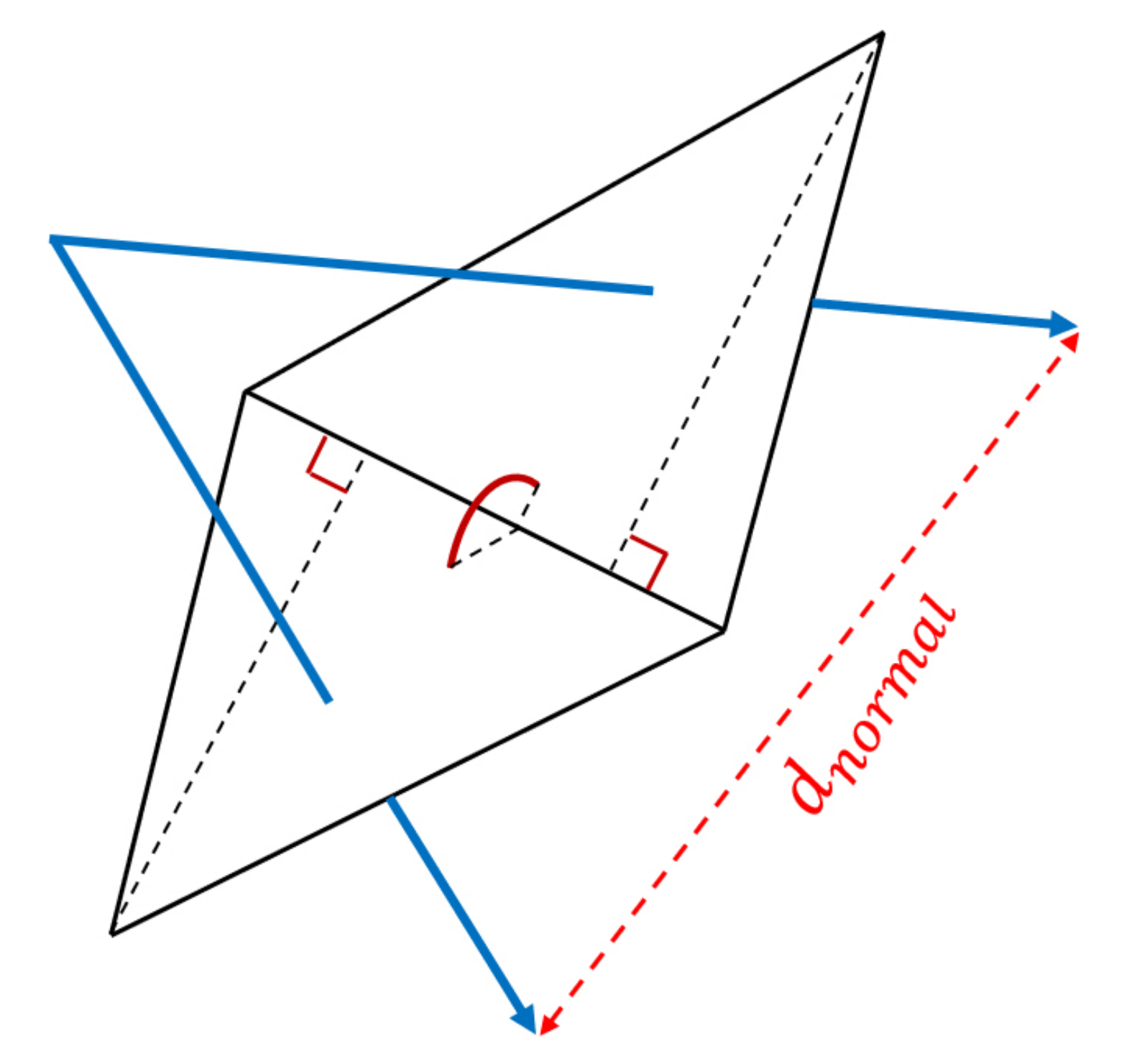
GNConv is designed to capture the visual variance of the local surface formed by the point cloud and augment the information with it. Since the normal of a point can depict the information and appearance of the local neighborhood, so we use normals. As shown in
Figure 7,
represents the distance between the two normals, reflecting the visual variance of the surface. Conceptually, when
is large, the local surface appearances vary violently, which means there are more features (important information).
Inspired by GeoConv [
13], GNConv includes the distance of normals between the center point and the neighboring points on the local neighborhood graph in each iteration. Define the point cloud as
, where
. Taking each point of
P as the center point, take the spherical neighborhood
with radius
r, and the normal set is
. As the iteration progresses, gradually increase r to obtain a larger receptive field. Define
as the feature of
obtained after the
lth iteration of GNConv, then the definition of GNConv is as follows:
As shown in Equation (
9), the feature of
on the
lth layer has two parts. The first part is the output of the previous layer
multiplied by the center point weight
to extract the center point feature, and the second part is the edge property between the center point and neighboring points in the spherical neighborhood. The corresponding feature is multiplied by the weight
and
to enlarge the feature dimension to be the same as the dimension of the first part. In the second part,
is defined as:
Before each iteration, we take each point
as the center of the local spherical neighborhood and determine the neighborhood
with a radius of
r. The normal edge feature
between the center point and the neighboring points in the spherical neighborhood is defined as:
where
,
is the weight of normal edge features. The edge feature
is defined as:
For each spherical neighborhood, we construct an orthogonal basis with
as the origin and decompose the edge features along with the orthogonal basis, and
is the cosine between each component and the corresponding orthogonal basis.
is the weight for feature extraction of the components along with three orthogonal bases. After the feature components of the three edges are mapped to the high-dimensional feature space, we aggregate the components by
. Finally, we aggregate the edge feature
and the normal edge feature
as shown in Equation (
10).
In Equation (
9),
is the weight function, and the weight is dynamically changed according to the distance between
and
, which is defined as:
4. Experiments
4.1. Implementation Details
In our experiments, the GPU used in the classification experiment and the ablation experiment was NVIDIA GeForce GTX 2080ti; the GPU used in the few-shot learning experiment and the visualization of GN-GAN reconstruction results was NVIDIA GeForce GTX 1070.
In the 3D point cloud classification experiment and the few-shot learning experiment, the input 3D point cloud of GN-CNN contained 1024 points. The radii for three GNConv layers were 0.15, 0.3, and 0.6. The first branch and the second branch both used the Adam optimizer and the cosine annealing strategy. The training batch_size was 10, and the test batch_size was 8.
When pre-training GN-GAN, the input point cloud resolution was 1024 points and 64 points after IFPS downsampling with K = 16. The generator used the Adam optimizer and StepLR to update the parameters every 40 epochs. The discriminator also used the Adam optimizer and StepLR to update the parameters every 40 epochs. The training batch_size was 16, and the test batch_size was 8.
4.2. Dataset
Our experiments used ModelNet40 [
20] and ModelNet10 [
20]. For classification, we carried out experiments on both ModelNet10 and ModelNet40. The input point cloud resolution was 1024 points, and we used all samples from the training and test sets. For few-shot learning, we used ModelNet40 and randomly reduced 50%, 70%, 90%, and 95% of the total number of training samples; that is, using 50%, 30%, 10%, and 5% of the total number of training samples. We kept the number of testing samples unchanged, so the few-shot learning experiment used five training set sizes, including the original training set. We used ModelNet40 to pre-train GN-GAN for experience knowledge.
4.3. Classification
We used warm-start GN-CNN to perform classification experiments on ModelNet40 and ModelNet10. The experiment’s results are shown in
Table 2 and
Table 3, where MA is the mean per-class accuracy and OA is the overall accuracy.
The results on ModelNet40 are shown in
Table 2. Using our method, MA is 90.5% and OA is 93.0%; OA increased by 3.8% compared with PointNet [
1], and 2.3% compared with PointNet++ [
25]. Through a warm start strategy, the OA of our method increased by 0.1% compared to the milestone work DGCNN [
12] in the field of graph convolution. Note that our result did not reach the reported OA of 93.4% in the original Geo-CNN [
13] when training 200 epochs using the same network structure and parameter settings, but it is slightly better than the OA of the reproduced Geo-CNN, which is 92.9% (the same as DGCNN). In our opinion, there are two main reasons: first, the reproduction process is different from the original paper, which causes a different training result, and second, the hardware and the number of epochs are different. Using more epochs, similar results as in the original paper should be achieved.
The OA of our method on ModelNet10 can reach 95.9%. As shown in
Table 3, the OA increased by 12.4% compared with 3DShapeNets [
20], and increased by 1.5% compared with KCNet. Compared with some work proposed in recent years, such as LP-3DCNN, 3DCapsule, VIPGAN, Point2Sequence, and MHBN, our result on ModelNet10 is the best. Moreover, on the official website of Princeton ModelNet, the overall accuracy ranking of the work performed on ModelNet10 for classification tasks is provided as the ModelNet benchmark leaderboard, and the performance of GN-CNN is ranked fifth.
4.4. Few-Shot Learning
Our few-shot learning experiment uses ModelNet40 and the results are shown in
Table 4. Moreover, 100%, 50%, 30%, 10%, and 5% represent the five training set sizes after random sampling. Since the other four methods did not conduct few-shot learning, we used the other four methods to perform few-shot learning under the same conditions as the GN-CNN experimental environment.
We can see from
Table 4 that our GN-CNN on the original training set can achieve similar results as DGCNN and Geo-CNN, but after the size of the training set is reduced, the OA and MA of GN-CNN are better than Geo-CNN. When the training set size reduces to 30%, the OA of GN-CNN classification increases by 2.5% compared with Geo-CNN, and the MA increases by 3.1%. Moreover, since the number of samples in the ModelNet40 training set is 9843, and the number of samples in the test set is 2468, there are only about 500 samples in the training set when we reduce the size to 5% of the original training set, and the number of training samples only accounts for about 20% of the number of samples in the test set. In this case, compared with DGCNN, the OA of GN-CNN increased by 3.3%, and the MA increased by 4.6%.
4.5. Reconstruction Results of GN-GAN
To justify the prior knowledge extracted by the GN-GAN containing useful point cloud information, we compare the point cloud reconstructed by the decoder with the ground truth. We use the heatmap to visualize the comparison results, as shown in
Figure 8. When the point is closer to blue, the difference between the reconstructed and real points is smaller.
As shown in
Figure 8, although the reconstructed points deviate from the real points in areas with more details of the 3D point clouds, such as the tips of airplane wings, the neck of bottles, and the plant leaves, GN-GAN can reconstruct point clouds that are very close to the ground truth on the whole, which shows that the prior knowledge extracted by the encoder in the GN-GAN generator is helpful.
4.6. Ablation Study
The ablation study was conducted using ModelNet40. The training set size was 5% of the original. The results are shown in
Table 5. Since our GN-CNN and GNConv are inspired by Geo-CNN and GeoConv, the Geo-CNN is chosen as the “Baseline”. To compare the performance of GNConv and GeoConv, in “Baseline (GNConv)”, the GeoConv is replaced with GNConv. Compared with “Baseline”, GN-CNN not only uses GNConv to extract features but also includes prior knowledge from the GN-GAN generator. The encoder of the generator in GN-GAN relies on GCMLP to extract features. To compare the performance of GCMLP and CMLP, in “Baseline (GNConv) + CMLP”, the GCMLP of GN-GAN is replaced with CMLP, and the prior knowledge extracted by CMLP is plugged into “Baseline (GNConv)”. In “Baseline + GCMLP”, the prior knowledge obtained through GN-GAN is plugged into Geo-CNN.
Comparing the OA of “Baseline” and “Baseline (GNConv)”, it is shown that GNConv has a stronger extracting ability than GeoConv. Comparing “Baseline (GNConv)” and “Baseline (GNConv) + CMLP”, as well as “Baseline” and “Baseline + GCMLP”, it is shown that prior knowledge helps improve the accuracy of few-shot learning. Comparing “Baseline (GNConv) + CMLP” and our GN-CNN, it is shown that GCMLP has a stronger feature-extracting ability than CMLP.
To further compare the performance of GCMLP and CMLP, two layers of GCMLP in GN-GAN are replaced with CMLP and named GN-GAN (CMLP). As shown in
Table 6, we use ground truth and predicted (GT-pred) error to evaluate the performance. GT-pred error computes the average squared distance from each point in the ground truth to its closest in the reconstructed point cloud. We observed that when using GCMLP to extract features, the result is smaller, which means that the reconstruction result of GN-GAN is better than that of GN-GAN (CMLP). This indicts that GCMLP has a stronger feature-extracting ability.
5. Conclusions
In this paper, we propose a convolutional neural network framework GN-CNN with normal-aware convolution operation GNConv, which is suitable for Metaverse applications. To solve the problem of few-shot learning of point clouds, we propose an unsupervised generative adversarial network GN-GAN, based on graph convolution-enhanced multilayer perceptron operation GCMLP for point cloud reconstruction (for extracting experience knowledge to warm start GN-CNN). The performance was evaluated on ModelNet40 and ModelNet10.
It is still challenging to reconstruct all local detailed features and the accuracy still has room to improve. In the future, we plan to study more geometric characteristics of the point cloud to improve the feature extraction performance and explore more prior knowledge of point cloud geometric information to promote the learning of the backbone network.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}