





Multi-Vehicle Trajectory Tracking towards Digital Twin Intersections for Internet of Vehicles

Abstract
:1. Introduction
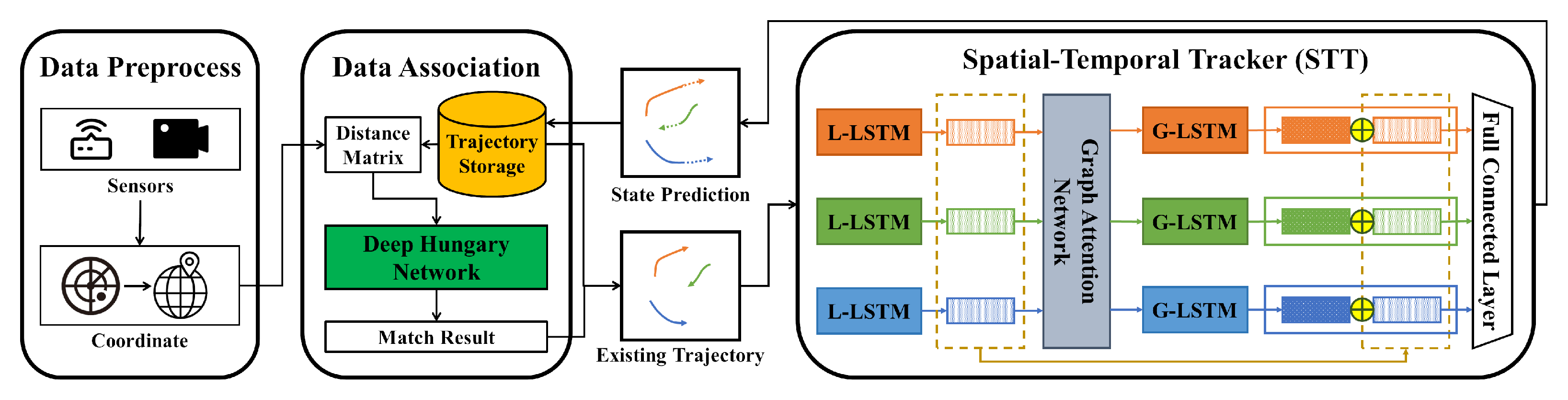
- A multi-vehicle trajectory tracking framework for DT intersections (MVT2DTI) is proposed. It uses the proposed spatial–temporal tracker (STT) to model the interactions between the vehicles and their global motion patterns in IoV.
- We utilize an improved tracking loss to back-propagate tracking errors. The tracking loss captures the impact of offset and loss in measurements to resolve the ID inconsistency of DT trajectories.
- We generate four scene datasets on the trajectory data of Hangzhou city. Based on this, we validate the performance of the framework and further reveal the effectiveness of STT.
2. Related Work
2.1. Data Association
2.2. Tracker
3. Preliminary
4. Methodology
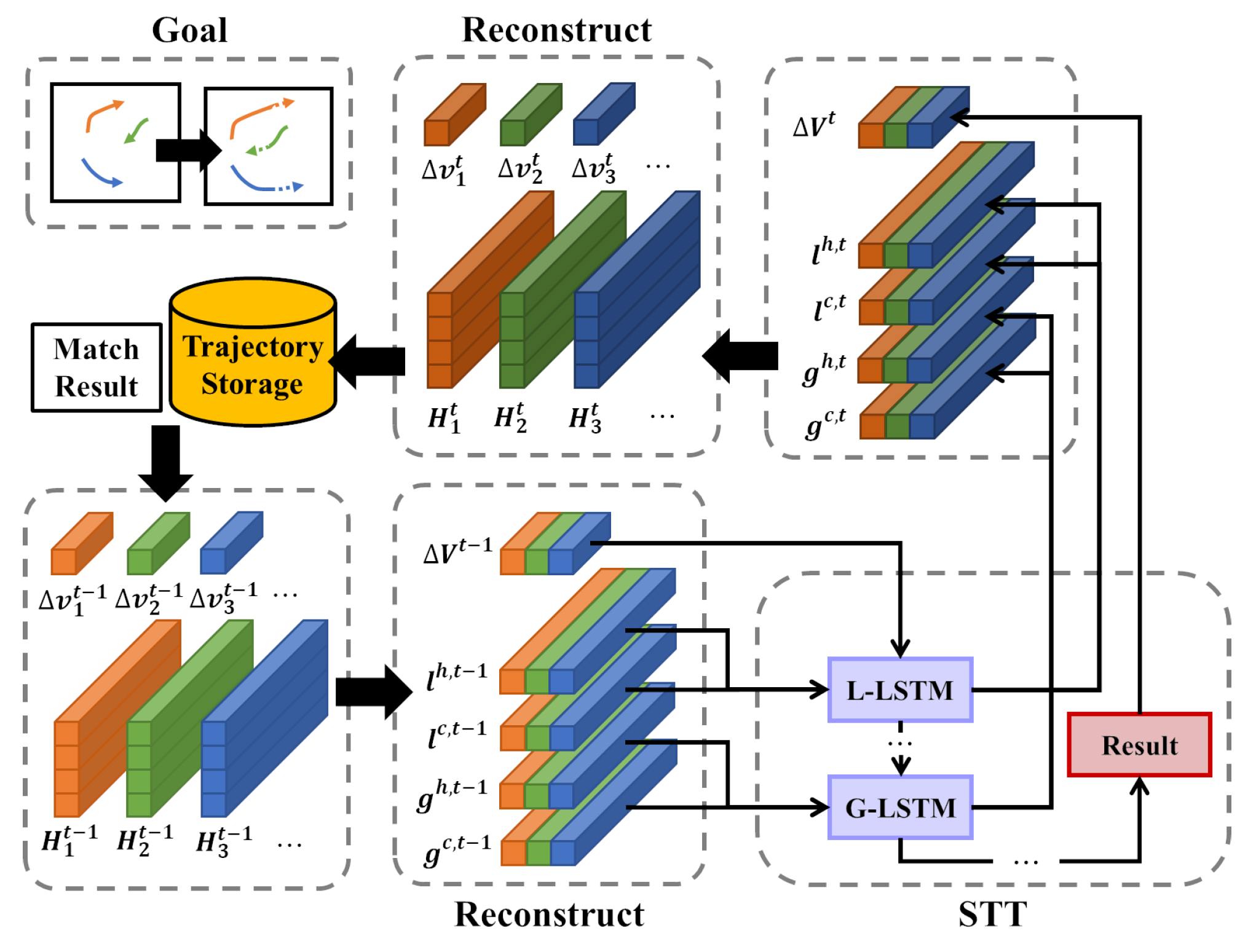
4.1. Spatial-Temporal Tracker (STT)
4.1.1. Local Temporal Encoding
4.1.2. Spatial Encoding
4.1.3. Global Temporal Encoding and Output
4.1.4. Overall Process
4.2. Loss
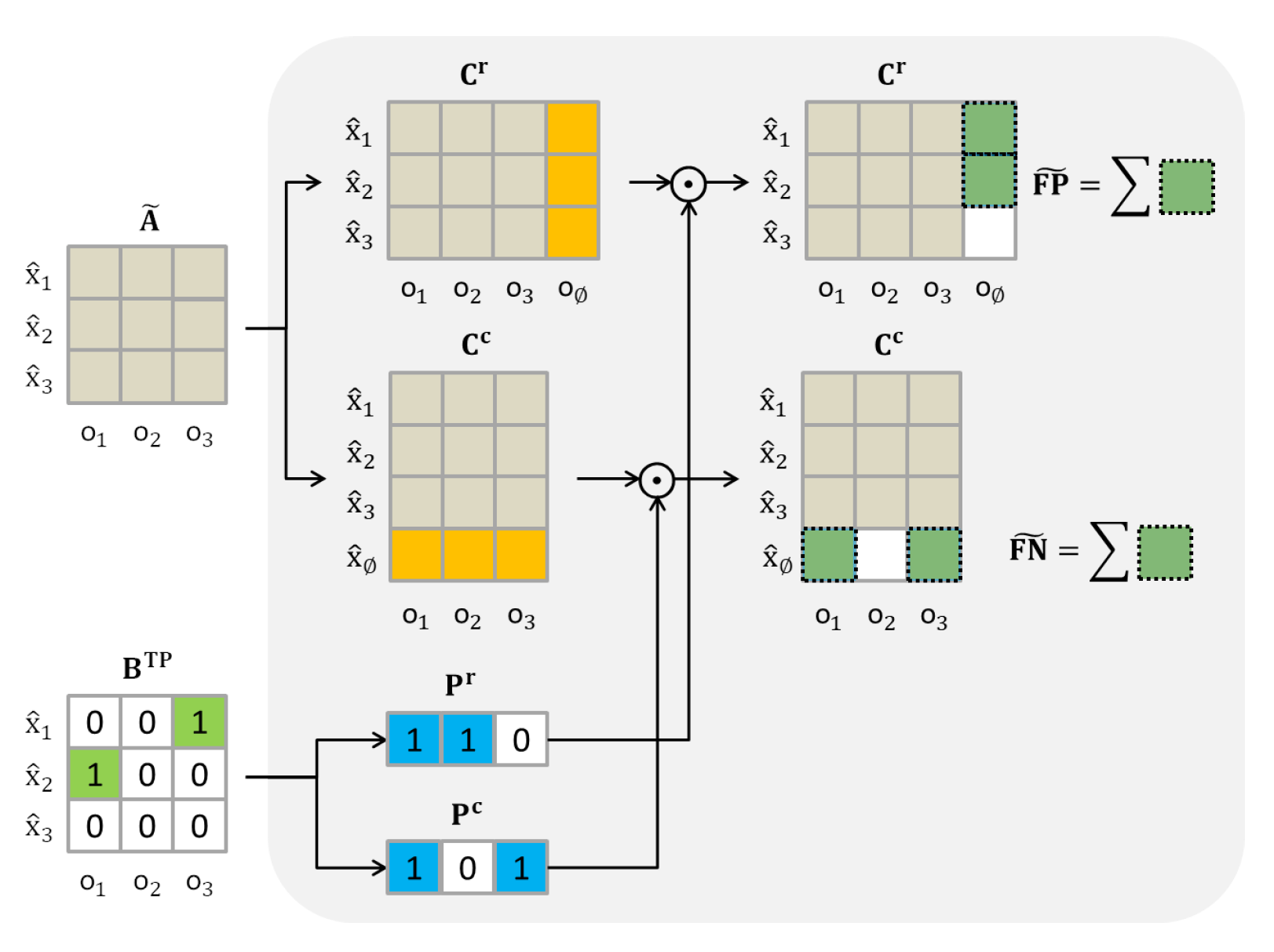
4.2.1. Distance Matrix
4.2.2. Improved FP and FN
4.3. Example
5. Experiments
5.1. Hardware and Software Environments
5.2. Dataset Description
- 1.
- Offset: So far in original datasets, vehicle trajectories are lowly biased. However, in the real world, the sensor may have coordinate offset due to its own hardware defects or the influence of external factors. We mimic this phenomenon by offsetting the original dataset with a Gaussian distribution with mean 0 and variance under the world coordinates system.
- 2.
- Miss: Sensor signal loss occurs when the vehicle is occluded or the signal is attenuated in a complex environment. We mimic this phenomenon by randomly dropping observations with a 10% probability in the original dataset and generating a missing dataset.
5.3. Experiment Settings
- 1.
- Multiple Object Tracking Accuracy (MOTA): The measure combines three error sources: false positives, false negatives, and ID switch errors. The more the model is disturbed by errors, the worse the metric will be. It is one of the contributions that this paper needs to validate.
- 2.
- Multiple Object Tracking Precision (MOTP): Due to the coordinate dataset, the experiments use the MOTP metric defined by [39], i.e., the average error in predicted positions for matched observation pairs over all frames. Through the metric, we will reveal that MOTP is not necessarily positively correlated with MOTA, thus validating the significance of the proposed tracking loss.
- 3.
- ID F1 Score (IDF1): The ratio of correctly identified observations over the average number of ground truth and predicted positions. It is similar to MOTA as a combined metric, but differs in that it focuses on the continuous consistency of DT trajectory ID with the ground truth ID. It is also one of the contributions that need to be verified.
- 1.
- Linear Regression (LR): an LR with no other additional mechanisms, all trajectories are considered independent.
- 2.
- Non-linear Motion (NLM) [29]: An extension to LR that considers motion patterns such as velocity, acceleration, etc.
- 3.
- Group Behavior Model (GBM) [12]: It models the traffic force between vehicles and embeds the force in a Kalman filter to estimate the state of the target.
- 4.
- RNN_LSTM [22]: It models an RNN-based architecture for state prediction, state update, and target existence probability estimation, and an LSTM-based model for data association.
- 5.
- Multi Attention Module (MAM) [11]: It proposes a promoting tracking strategy that utilizes observations to generate a series of candidate targets to explore more possibilities.
5.4. Quantitative Evaluation
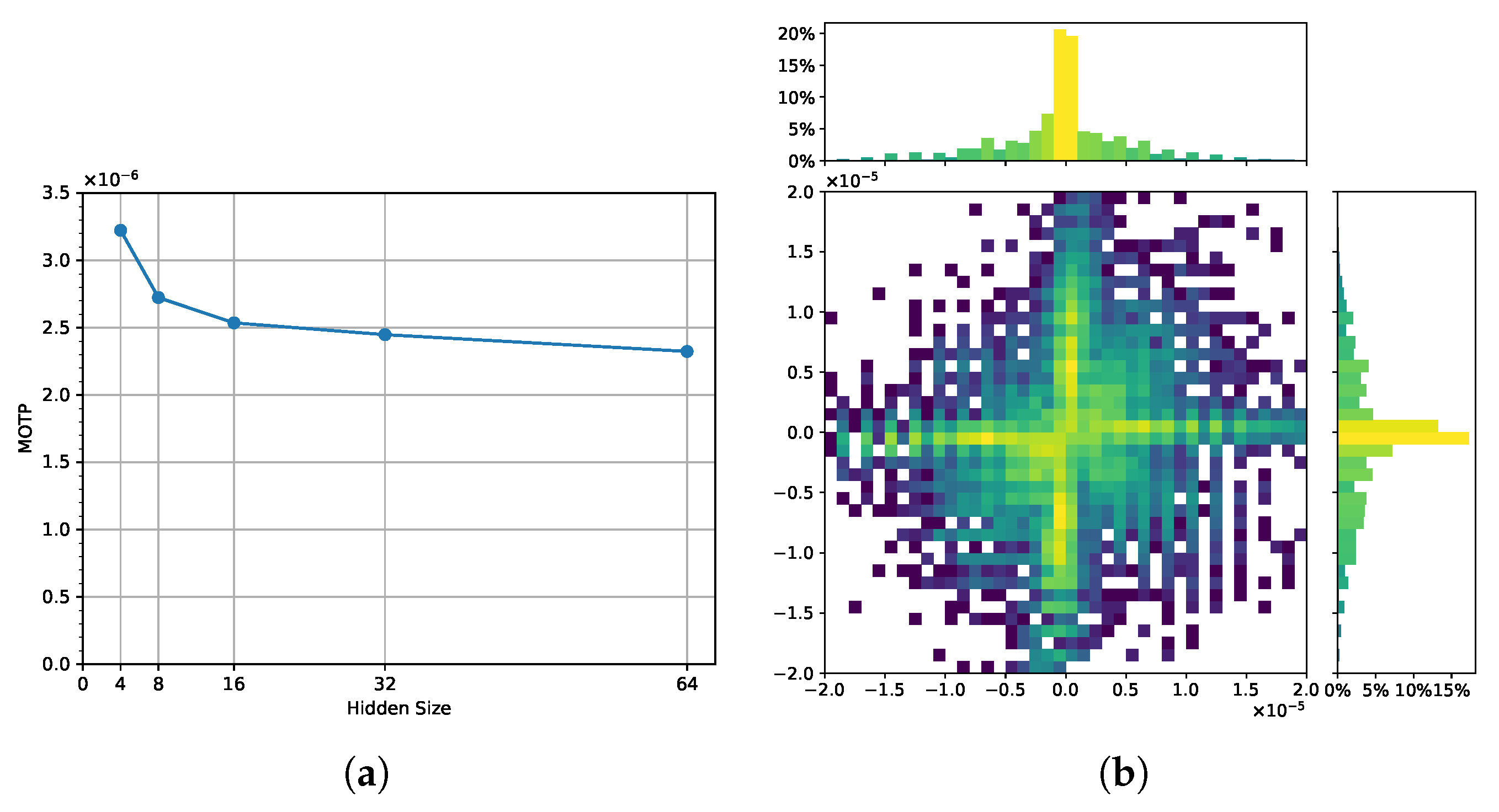
5.5. Component Analysis
5.6. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kong, X.; Zhu, B.; Shen, G.; Workneh, T.C.; Ji, Z.; Chen, Y.; Liu, Z. Spatial-Temporal-Cost Combination Based Taxi Driving Fraud Detection for Collaborative Internet of Vehicles. IEEE Trans. Ind. Inform. 2022, 18, 3426–3436. [Google Scholar] [CrossRef]
- Javed, A.R.; Faheem, R.; Asim, M.; Baker, T.; Beg, M.O. A smartphone sensors-based personalized human activity recognition system for sustainable smart cities. Sustain. Cities Soc. 2021, 71, 102970. [Google Scholar] [CrossRef]
- Javed, A.R.; Shahzad, F.; ur Rehman, S.; Zikria, Y.B.; Razzak, I.; Jalil, Z.; Xu, G. Future smart cities: Requirements, emerging technologies, applications, challenges, and future aspects. Cities 2022, 129, 103794. [Google Scholar] [CrossRef]
- Kong, X.; Duan, G.; Hou, M.; Shen, G.; Wang, H.; Yan, X.; Collotta, M. Deep Reinforcement Learning-Based Energy-Efficient Edge Computing for Internet of Vehicles. IEEE Trans. Ind. Inform. 2022, 18, 6308–6316. [Google Scholar] [CrossRef]
- Kong, X.; Wu, Y.; Wang, H.; Xia, F. Edge Computing for Internet of Everything: A Survey. IEEE Internet Things J. 2022, 9, 23472–23485. [Google Scholar] [CrossRef]
- Sun, W.; Lei, S.; Wang, L.; Liu, Z.; Zhang, Y. Adaptive Federated Learning and Digital Twin for Industrial Internet of Things. IEEE Trans. Ind. Inform. 2021, 17, 5605–5614. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, K.; Zhang, Y. Digital Twin Networks: A Survey. IEEE Internet Things J. 2021, 8, 13789–13804. [Google Scholar] [CrossRef]
- Kong, X.; Chen, Q.; Hou, M.; Rahim, A.; Ma, K.; Xia, F. RMGen: A Tri-Layer Vehicular Trajectory Data Generation Model Exploring Urban Region Division and Mobility Pattern. IEEE Trans. Veh. Technol. 2022, 71, 9225–9238. [Google Scholar] [CrossRef]
- Wang, J.; Fu, T.; Xue, J.; Li, C.; Song, H.; Xu, W.; Shangguan, Q. Realtime wide-area vehicle trajectory tracking using millimeter-wave radar sensors and the open TJRD TS dataset. Int. J. Transp. Sci. Technol. 2022. [Google Scholar] [CrossRef]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Chen, B.; Li, P.; Sun, C.; Wang, D.; Yang, G.; Lu, H. Multi attention module for visual tracking. Pattern Recognit. 2019, 87, 80–93. [Google Scholar] [CrossRef]
- Yuan, Y.; Lu, Y.; Wang, Q. Tracking as a whole: Multi-target tracking by modeling group behavior with sequential detection. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3339–3349. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Gu, R.; Liu, Z.; Hu, W.; Song, M.; Hwang, J.N. Track without Appearance: Learn Box and Tracklet Embedding with Local and Global Motion Patterns for Vehicle Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 9876–9886. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Lu, Z.; Rathod, V.; Votel, R.; Huang, J. Retinatrack: Online single stage joint detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 14668–14678. [Google Scholar]
- Kong, X.; Wang, K.; Hou, M.; Hao, X.; Shen, G.; Chen, X.; Xia, F. A Federated Learning-Based License Plate Recognition Scheme for 5G-Enabled Internet of Vehicles. IEEE Trans. Ind. Inform. 2021, 17, 8523–8530. [Google Scholar] [CrossRef]
- Kong, X.; Wang, K.; Wang, S.; Wang, X.; Jiang, X.; Guo, Y.; Shen, G.; Chen, X.; Ni, Q. Real-time mask identification for COVID-19: An edge-computing-based deep learning framework. IEEE Internet Things J. 2021, 8, 15929–15938. [Google Scholar] [CrossRef] [PubMed]
- Butt, A.A.; Collins, R.T. Multi-target tracking by lagrangian relaxation to min-cost network flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1846–1853. [Google Scholar]
- Schulter, S.; Vernaza, P.; Choi, W.; Chandraker, M. Deep network flow for multi-object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6951–6960. [Google Scholar]
- Choi, W. Near-Online Multi-Target Tracking With Aggregated Local Flow Descriptor. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ban, Y.; Ba, S.; Alameda-Pineda, X.; Horaud, R. Tracking multiple persons based on a variational bayesian model. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 52–67. [Google Scholar]
- Milan, A.; Rezatofighi, S.H.; Dick, A.; Reid, I.; Schindler, K. Online multi-target tracking using recurrent neural networks. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Sun, S.; Akhtar, N.; Song, H.; Mian, A.; Shah, M. Deep Affinity Network for Multiple Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 104–119. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Osep, A.; Ban, Y.; Horaud, R.; Leal-Taixé, L.; Alameda-Pineda, X. How to train your deep multi-object tracker. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6787–6796. [Google Scholar]
- Martija, M.A.M.; Naval, P.C. SynDHN: Multi-Object Fish Tracker Trained on Synthetic Underwater Videos. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8841–8848. [Google Scholar]
- Breitenstein, M.D.; Reichlin, F.; Leibe, B.; Koller-Meier, E.; Van Gool, L. Robust tracking-by-detection using a detector confidence particle filter. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1515–1522. [Google Scholar]
- Milan, A.; Roth, S.; Schindler, K. Continuous Energy Minimization for Multitarget Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 58–72. [Google Scholar] [CrossRef]
- Kuo, C.H.; Nevatia, R. How does person identity recognition help multi-person tracking? In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1217–1224. [Google Scholar]
- Yang, B.; Nevatia, R. Multi-target tracking by online learning of non-linear motion patterns and robust appearance models. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1918–1925. [Google Scholar]
- Helbing, D.; Molnár, P. Social force model for pedestrian dynamics. Phys. Rev. E 1995, 51, 4282–4286. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Li, Y.; Cen, M.; Zhu, H. Multi-vehicle tracking using an environment interaction potential force model. IEEE Sens. J. 2020, 20, 12282–12294. [Google Scholar] [CrossRef]
- Kim, C.; Li, F.; Rehg, J.M. Multi-object tracking with neural gating using bilinear lstm. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 200–215. [Google Scholar]
- Reid, D. An algorithm for tracking multiple targets. IEEE Trans. Autom. Control 1979, 24, 843–854. [Google Scholar] [CrossRef]
- Babaee, M.; Li, Z.; Rigoll, G. Occlusion handling in tracking multiple people using RNN. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2715–2719. [Google Scholar]
- Huang, Y.; Bi, H.; Li, Z.; Mao, T.; Wang, Z. STGAT: Modeling Spatial-Temporal Interactions for Human Trajectory Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6272–6281. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 17–35. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Approach | Limitations | Similarity/Dis-Similarity with Our Approach |
|---|---|---|---|
| [11] | They implemented an attention network with LSTM units, making full use of historical and current information during tracking. | It is unaware of the surrounding influences. The data association algorithm is independent of the tracker. | Both use LSTM to capture temporal information. |
| [12] | They manually modeled a group behavior model (GBM) as the inter-vehicle traffic force and applied the GBM to Kalman filtering to predict the state of the vehicles. | It is difficult to finalize the parameters for excellent performance. The data association algorithm is independent of the tracker. | Both consider inter-vehicle interactions. |
| [13] | They proposed LGM, which gains more knowledge by looking ahead to future observations. | Cannot be applied in the online stream. High computational consumption. | Both combined the tracker and the data association algorithm, but in very different ways. |
| [21] | They propose an online variational Bayesian model for multi-person tracking, which yields a variational expectation-maximization (VEM) algorithm. | The data association algorithm is independent of the tracker. Deep learning methods were not used. | Both are online algorithms. |
| [23] | They proposed DAN, which detects multiple representations of objects by pre-learning so that the representations of the same object are as similar as possible, realizing deep learning-based affinity estimation across arbitrary frames. | The representations of the tracked objects need to be prepared in advance for training data association components. | Both combined the tracker and the data association algorithm, but the two components are trained in opposite directions. |
| Model | Original | Original-O | Original-M | Original-OM | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MOTA | MOTP | IDF1 | MOTA | MOTP | IDF1 | MOTA | MOTP | IDF1 | MOTA | MOTP | IDF1 | |
| LR | 92.40 | 0.570 | 85.51 | 85.38 | 1.806 | 68.45 | 71.58 | 0.574 | 64.39 | 58.32 | 1.863 | 47.54 |
| NLM | 95.04 | 0.297 | 93.49 | 59.48 | 2.132 | 47.21 | 76.10 | 0.322 | 76.57 | 16.34 | 2.257 | 30.89 |
| GBM | 95.01 | 0.358 | 94.38 | 92.24 | 1.336 | 84.82 | 75.27 | 0.407 | 77.09 | 72.98 | 1.384 | 65.67 |
| RNN_LSTM | 93.71 | 0.362 | 94.14 | 89.40 | 1.348 | 70.32 | 70.26 | 0.412 | 71.66 | 65.97 | 1.395 | 57.11 |
| MAM | 95.34 | 0.294 | 93.93 | 89.98 | 1.625 | 75.53 | 77.98 | 0.316 | 78.40 | 69.18 | 1.644 | 58.10 |
| MVT2DTI | 95.57 | 0.245 | 94.90 | 90.12 | 0.957 | 86.21 | 81.09 | 0.297 | 80.19 | 73.36 | 1.053 | 72.71 |
| Metrics | LR | GBM | RNN_LSTM | MAM | LGM | MVT2DTI |
|---|---|---|---|---|---|---|
| Total | 28.42 | 65.05 | 31.41 | 153.65 | 351.25 | 68.66 |
| Time Usage | 1× | 2.29× | 1.11× | 5.41× | 12.36× | 2.42× |
| FPS | 175.9 | 76.9 | 159.2 | 32.5 | 14.2 | 72.8 |
| Model | Original | Original-O | ||||
|---|---|---|---|---|---|---|
| MOTA | MOTP | IDF1 | MOTA | MOTP | IDF1 | |
| STT + | 94.96% | 0.212 | 93.14% | 89.82% | 0.893 | 84.83% |
| STT + | 95.33% | 0.263 | 94.25% | 87.81% | 1.361 | 77.40% |
| STT + | 95.81% | 0.231 | 95.24% | 90.03% | 0.949 | 85.59% |
| STT + | 95.57% | 0.245 | 94.90% | 90.12% | 0.957 | 86.21% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, Z.; Shen, G.; Wang, J.; Collotta, M.; Liu, Z.; Kong, X. Multi-Vehicle Trajectory Tracking towards Digital Twin Intersections for Internet of Vehicles. Electronics 2023, 12, 275. https://doi.org/10.3390/electronics12020275
Ji Z, Shen G, Wang J, Collotta M, Liu Z, Kong X. Multi-Vehicle Trajectory Tracking towards Digital Twin Intersections for Internet of Vehicles. Electronics. 2023; 12(2):275. https://doi.org/10.3390/electronics12020275
Chicago/Turabian StyleJi, Zhanhao, Guojiang Shen, Juntao Wang, Mario Collotta, Zhi Liu, and Xiangjie Kong. 2023. "Multi-Vehicle Trajectory Tracking towards Digital Twin Intersections for Internet of Vehicles" Electronics 12, no. 2: 275. https://doi.org/10.3390/electronics12020275