
Reduction of False Positives for Runtime Errors in C/C++ Software: A Comparative Study

Abstract
:1. Introduction
- (1)
- It demonstrates the detection of runtime errors in static analysis, focusing on certain defects. It analyzes the types of defects detected in runtime over the last 20 years as indicated by published studies. The findings reveal that most reported static analyses focused on defects such as memory buffer errors and incorrect memory release.
- (2)
- It analyzes the latest static analysis techniques to decrease false positives by categorizing them into those that apply ML/DL and those that do not. A comparative analysis of the defect detection effects of each technique shows that the application of ML/DL affects the reduction in false positives in static analysis.
- (3)
- It measures the time taken to apply the latest static analysis techniques to the test data, identifying whether ML/DL can be applied to actually defect detection.
- (4)
- It demonstrates that measures to reduce false positives in static analysis focus on limited types of vulnerabilities/defects; it thus emphasizes the necessity for approaches in static analysis that accurately detect a wide range of vulnerabilities/defects.
2. Related Studies
3. Runtime Error Types and Dataset
4. Comparison of Techniques for Reducing False Positives in Static Analysis Tools
4.1. Experimental Environment
- (1)
- Experimental Environment
- (2)
- Techniques for Comparison
- (3)
- Measurement Metrics
- (4)
- Experimental Methods
4.2. Experimental Results and Analyses
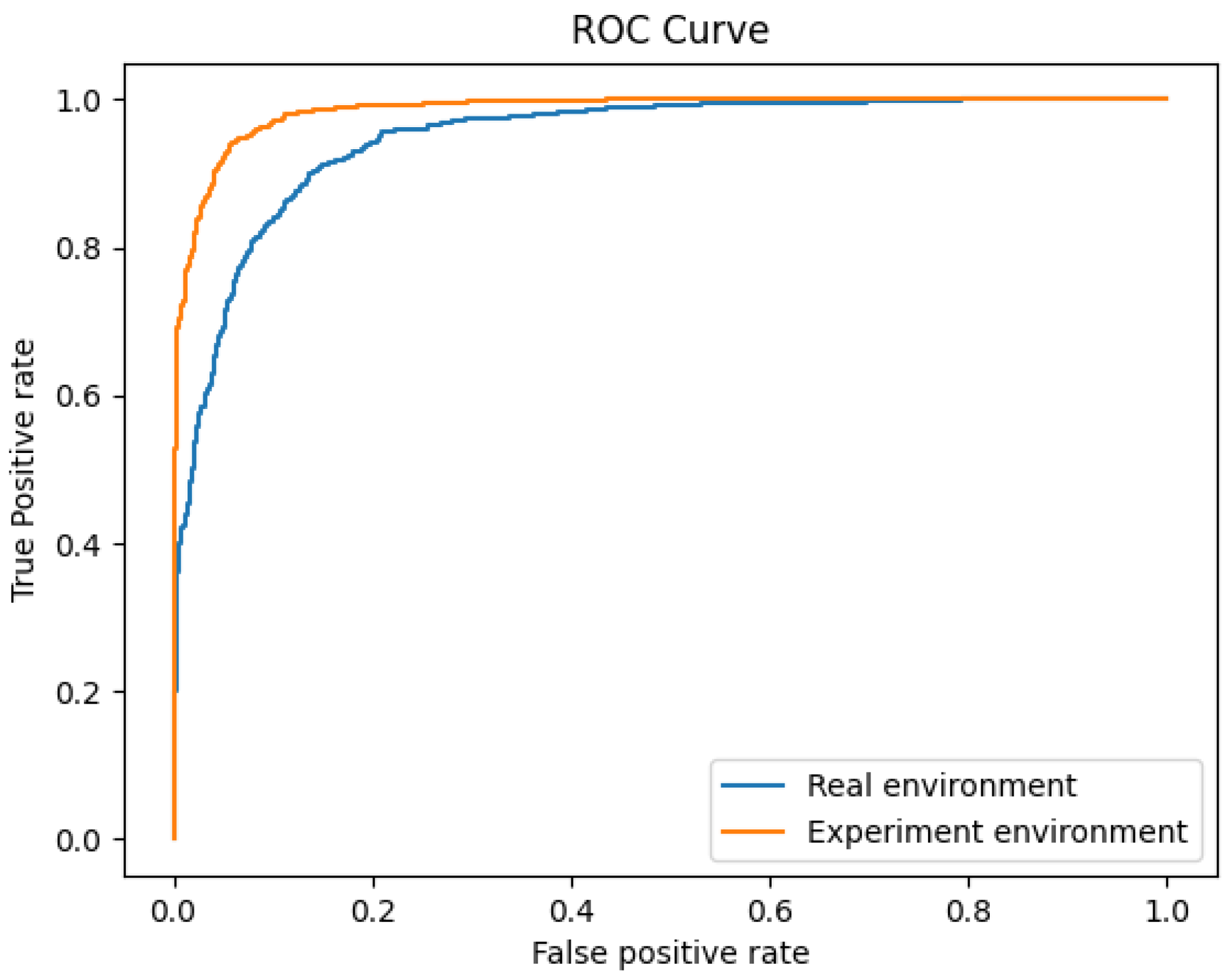
4.2.1. RQ1. Is It Effective to Apply Machine Learning/Deep Learning to Detect Vulnerabilities with Static Analysis?
4.2.2. RQ2. Can Vulnerability Detection Techniques Applying Machine Learning/Deep Learning Be Applied to Vulnerability Detection of Real-World Software?
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khaleel, S.I.; Anan, R. A review paper: Optimal test cases for regression testing using artificial intelligent techniques. Int. J. Electr. Comput. Eng. 2023, 13, 1803–1816. [Google Scholar] [CrossRef]
- Coverity. Available online: https://scan.coverity.com/ (accessed on 6 July 2023).
- CodeSonar. Available online: https://www.grammatech.com/our-products/codesonar/ (accessed on 6 July 2023).
- Infer. Available online: https://github.com/facebook/infer (accessed on 6 July 2023).
- Splint. Available online: https://splint.org/ (accessed on 6 July 2023).
- Johnson, B.; Song, Y.; Murphy-Hill, E.; Bowdidge, R. Why don’t software developers use static analysis tools to find bugs? In Proceedings of the International Conference on Software Engineering, San Francisco, CA, USA, 18–26 May 2013; pp. 672–681. [Google Scholar]
- Christakis, M.; Bird, C. What developers want and need from program analysis: An empirical study. In Proceedings of the International Conference on Automated Software Engineering, Singapore, 3–7 September 2016; pp. 332–343. [Google Scholar]
- Beller, M.; Bholanath, R.; McIntosh, S.; Zaidman, A. Analyzing the state of static analysis: A large-scale evaluation in open source software. In Proceedings of the International Conference on Software Analysis, Evolution, and Reengineering, Osaka, Japan, 14–18 March 2016; pp. 470–481. [Google Scholar]
- Heckman, S.; Williams, L. A systematic literature review of actionable alert identification techniques for automated static code analysis. Inf. Softw. Technol. 2011, 53, 363–387. [Google Scholar] [CrossRef]
- Flawfinder. Available online: https://dwheeler.com/flawfinder/ (accessed on 6 July 2023).
- Shahriar, H.; Zulkernine, M. Classification of Static Analysis-Based Buffer Overflow Detectors. In Proceedings of the 2010 Fourth International Conference on Secure Software Integration and Reliability Improvement Companion, Singapore, 9–11 June 2010; pp. 94–101. [Google Scholar] [CrossRef]
- Cppcheck. Available online: https://cppcheck.sourceforge.io/ (accessed on 6 July 2023).
- Frama-C. Available online: https://frama-c.com/ (accessed on 6 July 2023).
- Kremenek, T. Finding Software Bugs with the Clang Static Analyzer; Apple Inc.: Cupertino, CA, USA, 2008. [Google Scholar]
- Rahimi, S.; Zargham, M. Vulnerability scrying method for software vulnerability discovery prediction without a vulnerability database. IEEE Trans. Reliab. 2013, 62, 395–407. [Google Scholar] [CrossRef]
- Hovsepyan, A.; Scandariato, R.; Joosen, W.; Walden, J. Software vulnerability prediction using text analysis techniques. In Proceedings of the 4th International Workshop on Security Measurements and Metrics, Lund, Sweden, 21 September 2012; pp. 7–10. [Google Scholar]
- Pang, Y.; Xue, X.; Namin, A.S. Predicting vulnerable software components through n-gram analysis and statistical feature selection. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 543–548. [Google Scholar]
- Mou, L.; Li, G.; Jin, Z.; Zhang, L.; Wang, T. TBCNN: A tree-based convolutional neural network for programming language processing. arXiv 2014, arXiv:1409.5718. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. Vuldeepecker: A deep learning-based system for vulnerability detection. arXiv 2018, arXiv:1801.01681. [Google Scholar]
- Zou, D.; Wang, S.; Xu, S.; Li, Z.; Jin, H. μVulDeePecker: A Deep Learning-Based System for Multiclass Vulnerability Detection. IEEE Trans. Dependable Secur. Comput. 2019, 18, 2224–2236. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Zhu, Y.; Chen, Z. Sysevr: A framework for using deep learning to detect software vulnerabilities. IEEE Trans. Dependable Secur. Comput. 2021, 19, 2244–2258. [Google Scholar] [CrossRef]
- Russell, R.; Kim, L.; Hamilton, L.; Lazovich, T.; Harer, J.; Ozdemir, O.; Ellingwood, P.; McConley, M. Automated vulnerability detection in source code using deep representation learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 757–762. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Chen, Z.; Zhu, Y.; Jin, H. Vuldeelocator: A deep learning-based fine-grained vulnerability detector. IEEE Trans. Dependable Secur. Comput. 2021, 19, 2821–2837. [Google Scholar] [CrossRef]
- Kim, S.; Choi, J.; Ahmed, M.E.; Nepal, S.; Kim, H. VulDeBERT: A Vulnerability Detection System Using BERT. In Proceedings of the 2022 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Charlotte, NC, USA, 31 October–3 November 2022; pp. 69–74. [Google Scholar]



{kind=link}
{kind=link}
| Defect | Static Analysis Tools | |||||
|---|---|---|---|---|---|---|
| Flawfinder | Cppcheck | RATS | Infer | Frama-C | Coverity (Commercial) | |
| Dead pointers | O | O | ||||
| Division by zero | O | O | O | |||
| Integer overflows | O | O | O | O | ||
| Invalid bit shift operands | O | O | ||||
| Invalid conversions | O | O | ||||
| Invalid usage of STL | O | O | ||||
| Memory management | O | O | O | |||
| Null pointer dereferences | O | O | O | |||
| Out of bounds checking | O | O | O | |||
| Uninitialized variables | O | O | ||||
| Writing const data | O | O | ||||
| Coding conventions | O | O | ||||
| Unavailable API’s | O | O | ||||
| Memory out-of-bound read/write | O | O | O | O | O | |
| Race Condition within a Thread | O | O | ||||
| Memory leakage | O | O | O | |||
| Use of Potentially Dangerous Function | O | O | ||||
| CWE-ID | CWE Title | Defect Type |
|---|---|---|
| 404 | Improper resource shutdown or release | Improper synchronization |
| 476 | NULL pointer dereference | use after free |
| 119 | Improper restriction of operations within the bounds of memory | Memory buffer error Out-of-bound read Out-of-bound write |
| Tool | CWE ID | Remark | |||
|---|---|---|---|---|---|
| 404 | 476 | 119 | |||
| Without ML/DL | Flawfinder | O | O | O | |
| Cppcheck | O | O | O | ||
| Frama-C | O | O | O | ||
| Clang static analyzer | O | O | O | ||
| Vulnerability detection using ML/DL | VulDeePecker | X | X | O | |
| μVulDeePecker | X | X | O | ||
| SySeVR | X | X | O | ||
| VUDDY | O | O | O | Network security | |
| HyVulDect | O | O | O | Network security | |
| False positive reduction using ML/DL | VulDeeLocator | X | X | O | |
| VulDeBERT | X | X | O | ||
| Dataset Source | No. of Samples |
|---|---|
| SARD | 4927 |
| NVD | 1164 |
| Total | 6091 |
| Dataset Source | No. of Samples |
|---|---|
| FFMpeg | 637 |
| GNU Grep | 380 |
| Total | 1017 |
| Name | Target Language | Open Source | Selection for Comparison |
|---|---|---|---|
| Flawfinder | C/C++ | O | O |
| Cppcheck | C/C++ | O | O |
| Frama-C | C | O | X |
| Clang static analyzer | C/C++/Objective C | O | X |
| VulDeePecker | C/C++ | O | O |
| μVulDeePecker | C/C++ | O | X |
| SySeVR | C/C++ | O | O |
| VUDDY | C/C++ | O | X |
| HyVulDect | C/C++ | O | X |
| VulDeeLocator | C/C++ | O | O |
| VulDeBERT | C/C++ | O | O |
| Tools | Precision | Recall | F1-Score | Accuracy | FPR | FNR |
|---|---|---|---|---|---|---|
| flawfinder | 47.39 | 32.83 | 37.99 | 55.49 | 26.64 | 70.95 |
| cppcheck | 58.05 | 57.07 | 57.56 | 46.06 | 41.95 | 57.07 |
| VulDeePecker | 81.17 | 62.14 | 67.54 | 69.9 | 14.77 | 33.13 |
| SySeVR | 79.05 | 78.38 | 78.63 | 82.45 | 14.15 | 22.1 |
| VulDeeLocator | 90.28 | 86.86 | 88.52 | 90.08 | 6.25 | 15.9 |
| VulDeBERT | 95.51 | 90.38 | 91.95 | 99.15 | 0.28 | 9.62 |
| Case | Source Code |
|---|---|
| 1 | static void copyset(const int src[((1 << 8) + 8 * sizeof(int) − 1)/(8 * sizeof(int))],charclass dst) { memcpy(dst,src,sizeof(charclass)); } |
| 2 | else { /* Defer to the system regex library about the meaning of range expressions. */ regex_t re; char pattern[6] = {(‘[’), (0), (‘-’), (0), (‘]’), (0)};//line 1294 char subject[2] = {(0), (0)}; … pattern[7] = c1; //line 1301 … } |
| Tools | Precision | Recall | F1-Score | Accuracy | FPR | FNR |
|---|---|---|---|---|---|---|
| VulDeePecker | 50.65 (6.54) | 72.3 (11.3) | 50.4 (3.57) | 63.25 (10.16) | 38.46 (11.81) | 32.33 (8.25) |
| SySeVR | 57.6 (11.21) | 78.91 (8.07) | 63.7 (9.55) | 57.52 (12.17) | 55.41 (25.86) | 27.8 (3.91) |
| VulDeeLocator | 78.41 (2.15) | 80.37 (1.68) | 79.26 (0.28) | 76.68 (2.73) | 36.98 (15.8) | 19.63 (5.29) |
| VulDeBERT | 90.08 (3.28) | 53.43 (23.67) | 59.97 (20.9) | 85.48 (8.66) | 0.83 (0.34) | 46.57 (23.67) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Shin, J.; Choi, B. Reduction of False Positives for Runtime Errors in C/C++ Software: A Comparative Study. Electronics 2023, 12, 3518. https://doi.org/10.3390/electronics12163518
Park J, Shin J, Choi B. Reduction of False Positives for Runtime Errors in C/C++ Software: A Comparative Study. Electronics. 2023; 12(16):3518. https://doi.org/10.3390/electronics12163518
Chicago/Turabian StylePark, Jihyun, Jaeyoung Shin, and Byoungju Choi. 2023. "Reduction of False Positives for Runtime Errors in C/C++ Software: A Comparative Study" Electronics 12, no. 16: 3518. https://doi.org/10.3390/electronics12163518