1. Introduction
With the rapid advancement of technology, there is a growing interest in natural language processing (NLP), a field that encompasses various technologies such as speech recognition, automatic text translation, and intelligent customer service [
1]. Among these technologies, machine translation has emerged as a crucial tool for cross-lingual communication and information dissemination, attracting significant attention and widespread usage [
2]. Machine translation aims to convert text from one natural language to another and involves interdisciplinary fields such as linguistics, computer science, and statistics [
3]. Traditional machine translation methods include rule-based, statistical, and deep learning approaches [
4]. Rule-based methods rely on manually crafted rules for translation, providing precise control over the translation process. However, they are time-consuming and struggle with the flexibility and ambiguity of language [
5]. Statistical methods, on the other hand, leverage large parallel corpora for modeling and learning, allowing them to handle the flexibility and ambiguity in language. However, they often require substantial data and computational resources, and may not yield high-quality translations of low-resource languages or specialized domains [
6]. In recent years, deep learning methods, particularly those based on neural networks, have gained prominence in machine translation. These approaches learn universal language representations by training on extensive parallel corpora, enabling end-to-end translation [
7]. Neural networks offer powerful expressive capabilities for handling nonlinear relationships and high-dimensional features, leading to an improved translation performance [
8]. Nonetheless, deep learning methods heavily rely on annotated data for training, which can be challenging to obtain, especially for low-resource languages and specialized domains. This limitation has spurred the development of unsupervised pretraining language model (PLM) methods [
9]. Unsupervised PLMs leverage large amounts of unlabeled corpora to learn universal language representations, thereby enhancing performance on specific tasks. Prominent models such as BERT (bidirectional encoder representations from transformers) and GPT (generative pretrained transformer) have emerged as advanced NLP technologies [
10]. These models have revolutionized the field by capturing contextual information and achieving state-of-the-art results in various NLP tasks. The field of machine translation has witnessed significant advancements, with deep learning methods, particularly neural networks, gaining prominence. However, the dependence on annotated data has hindered their application in low-resource languages and specialized domains. To address this challenge, unsupervised PLM methods have emerged as a promising solution. Models such as BERT and GPT have been pioneering technologies, pushing the boundaries of natural language processing.
A pretrained language model (PLM) is an emerging NLP technology that can learn language representations from a large amount of text data, thus achieving significant results in various NLP tasks. The emergence of PLMs has alleviated the problem of data scarcity, which has been a long-standing challenge in the field of NLP. The advantage of PLMs is that they can learn language representations from a large amount of text data in an unsupervised manner, and these representations can be applied to various NLP tasks, such as text classification, sentiment analysis, named entity recognition, question-answering systems, and machine translation. For example, in machine translation tasks, PLMs may not understand the two languages well, leading to errors in translation. In addition, the large amount of computing resources required for PLMs may limit their application in low-resource environments. In recent years, researchers have proposed a new approach to address this issue, which is to combine reinforcement learning with prompt learning [
11]. Reinforcement learning (RL) is a machine learning method that trains an agent to take actions in a specific environment, to achieve a particular goal through trial-and-error and reward-punishment mechanisms. RL typically consists of three components: the environment, agent, and policy. The environment refers to the specific environment in which the agent operates, the agent is an algorithm that achieves a specific goal through learning and training, and the policy refers to the way the agent takes action in a specific environment. In NER, reinforcement learning can be used to optimize the label propagation algorithm to improve recognition accuracy [
12]. Prompt learning is a technique that can be combined with reinforcement learning. Its basic idea is to help models fine-tune specific tasks by introducing some prompt information. For example, in machine translation tasks, specific words or phrases about language translation can be provided to the model to help it better understand the differences between languages. Prompt learning can be used in many NLP tasks, such as text classification, sentiment analysis, and named entity recognition. Its advantage is that it can improve the performance of the model by providing targeted prompt information [
13].
In the combined approach of reinforcement learning and prompt learning, the model can learn to select the best action given the prompt information through reinforcement learning [
14]. In the field of pretrained language models, prompt learning has been extensively studied and applied to various natural language processing tasks [
15] Prompt learning guides the model to learn specific language tasks by adding some prompt information to the model’s input [
16,
17,
18,
19,
20]. In GPT-3, prompt sentences are used to guide the model to generate text consistent with the prompt. Additionally, GPT-3 uses task-specific prompts, such as including a question and context in the input for question answering tasks and using appropriate prompts to indicate the generated answer [
9,
21,
22,
23,
24]. Similarly, the T5 model adds prompts as tokens to the input and uses prompts to indicate the generation of specific task results. Furthermore, some studies have attempted to combine prompt learning with reinforcement learning to improve the performance of pretrained language models on specific tasks [
25]. For example, Huang et al. proposed a prompt learning and reinforcement learning-based text classification method, using prompts to guide the model’s learning.The approach has shown promising results in sentiment analysis and text classification tasks. In summary, the combination of reinforcement learning and prompt-based learning methods provides an effective way to improve the performance of pretrained language models on specific tasks.
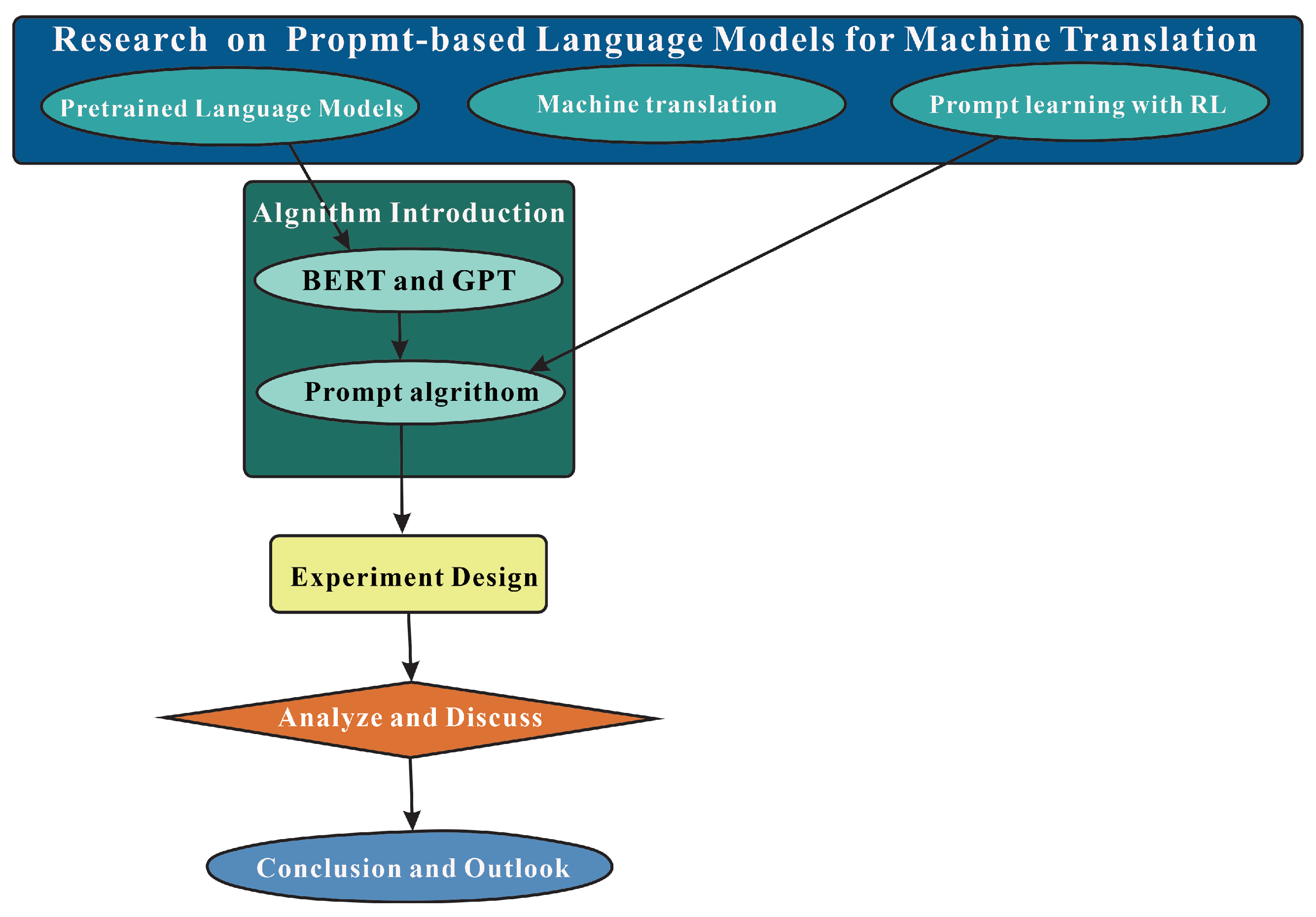
In this paper, we will explore how to use a prompt algorithm in combination with reinforcement learning to enhance the performance of pretrained language models in machine translation tasks. Specifically, this paper will investigate the following aspects: First, we will introduce the relevant research background, including pretrained language models, machine translation, and prompt-based learning methods in combination with reinforcement learning. Second, we will explain the principles of natural language processing algorithms and the prompt algorithm, including the structure and training methods of pretrained language models such as BERT and GPT, as well as the basic idea and application of the prompt algorithm [
26]. Third, we conducted experiments to explore how to use the prompt algorithm in combination with reinforcement learning to improve the performance of pretrained language models in machine translation tasks. Fourth, we will analyze the experimental results and discuss them. Finally, we will summarize the entire study and provide a perspective on future related work. The specific workflow of this paper is illustrated in
Figure 1.
2. Related Work
One of the prominent research areas in natural language processing (NLP) revolves around pretraining language models, as highlighted by Wiegreffe (2021) [
27]. In recent years, the field of NLP has witnessed an increasing utilization of pretraining language models, such as BERT and GPT, to enhance various NLP tasks. Simultaneously, the integration of reinforcement learning and guided learning has emerged as a significant research focus. The fundamental concept involves incorporating external guidance information to steer the learning process of pretrained models, thereby enhancing their overall performance. In the domain of machine translation, traditional approaches have typically relied on statistical methods, such as phrase-based translation models and word alignment models. Nevertheless, these methods possess inherent limitations, including a requirement for extensive bilingual data and difficulties in managing language ambiguity. Consequently, the advent of neural machine translation in recent years has garnered substantial attention. Deep learning models, particularly those based on an encoding–decoding framework, such as Google’s Seq2Seq and Facebook’s Fairseq [
28], have emerged as the prevailing techniques for addressing machine translation challenges.
Within these deep learning-based machine translation models, pretraining language models are frequently employed to initialize the encoder and decoder components [
29]. Nonetheless, since these pretraining language models are not specifically optimized for machine translation tasks, their performance in such tasks may be suboptimal. To address this issue, researchers have explored the application of reinforcement learning methods to optimize machine translation models and enhance their translation quality. Specifically, some researchers have employed policy gradient-based reinforcement learning approaches for model optimization. For instance, Zeng et al. proposed a policy gradient-based reinforcement learning method that maximizes the translation model’s prediction accuracy and sentence-level BLEU score, to enhance the overall performance [
30]. Experimental results have demonstrated significant improvements in translation quality for neural machine translation. Moreover, several researchers have attempted to optimize machine translation models using reinforcement learning (RL) methods based on value functions [
31]. For instance, Kim et al. proposed a value-based RL method that minimizes the prediction error and entropy of the translation model to enhance its performance [
32]. Ive et al. (2021) proposed a joint pretraining method based on prompting, which combines the prompt information of the source language and target language to train the model [
33]. As research progresses in the domain of RL-based prompt learning methods, scholars are increasingly exploring their application to machine translation tasks. Policy gradient-based methods have been employed by researchers such as Wang et al. to optimize machine translation models. They proposed a policy gradient-based machine translation model that utilizes a prompt-based RL algorithm to guide the training process, resulting in improved translation quality [
34]. Additionally, RL has been leveraged by scholars to tackle common challenges in machine translation, including handling unknown words and resolving ambiguity.
In addition to policy gradient-based methods, some researchers have used value function-based RL methods to optimize machine translation models. For example, Jia et al. (2021) proposed a value-based machine translation model that introduces state-value functions and action-value functions during the translation process, making the model more accurate when selecting the next output word [
35]. Experimental results showed that this method can effectively improve the translation quality of machine translation. Apart from using RL methods to optimize machine translation models, some researchers have tried to improve the performance of pretrained language models in machine translation tasks using prompt algorithms. For example, Arora et al. (2022) used a prompt-based pretraining method to improve the performance of GPT in machine translation tasks [
36]. This method trains the model using the language features of the target language as prompt information, thereby enabling the model to more accurately predict the next output word. Experimental results show that this method can effectively improve the translation quality of GPT in machine translation tasks. They used this method to pretrain a transformer model and evaluated it on the WMT14 English–German translation task. Experimental results showed that their method had a significantly improved translation quality, while also speeding up the model training process. In another study, Rajkumar et al. (2022) proposed a prompt-based multimodal pretraining method that uses both images and text as prompt information to train the model [
37]. They used this method to pretrain a transformer model and evaluated it on multiple machine translation tasks. Experimental results showed that their method could significantly improve the translation quality and enhance the model’s generalization ability.
Some researchers have also explored using different types of prompt information to improve the performance of machine translation models. For instance, Goyal et al. (2022) used a differentiable template-based prompt method that uses various language features as templates to train the model [
38]. They evaluated their method in the WMT14 English–German translation task and found that their method can significantly improve translation quality. Sun et al. (2020) proposed a prompt-based unsupervised machine translation method that uses prompt information from both the source and target languages to train the model [
39]. They used GPT for pretraining and evaluated their method on multiple machine translation tasks. The experimental results showed that their method achieved a comparable translation quality to supervised learning methods, while also better handling low-resource language translation tasks. One approach that has been explored is the use of differentiable template-based prompts. Gao et al. (2020) used this method to improve the performance of machine translation models in the WMT14 English–German translation task [
40]. They created various language features as templates and trained the model using a differentiable template-based prompt method. The experimental results showed that their method could significantly improve the translation quality, demonstrating the potential of prompt-based methods in machine translation. Another approach is prompt-based unsupervised machine translation, which involves using prompt information from both the source and target languages to train the model. Paischer et al. (2022) proposed a method that uses GPT for pretraining and evaluated their approach in multiple machine translation tasks. Their results showed that their method achieved comparable translation quality to supervised learning methods, while also better handling low-resource language translation tasks [
41].
In addition to these studies, several other researchers have explored the use of prompt-based methods for machine translation. For example, baniata et al. (2021) used a prompt-based approach to improve the performance of machine translation models on low-resource languages [
42]. They showed that their approach could significantly improve translation quality for several low-resource language pairs. Similarly, Narayan et al. (2022) proposed a prompt-based method that uses a multi-task learning approach to improve the performance of machine translation models for multiple language pairs [
43]. While prompt-based methods have shown promise for improving the performance of machine translation models, there are still some challenges to be addressed. One challenge is the selection of appropriate prompts or templates for different language pairs and translation tasks. Another challenge is the potential trade-off between the amount of prompt information provided and the computational cost of the model. Addressing these challenges will be important for further advancing the use of prompt-based methods in machine translation.
In summary, prompt-based methods have emerged as a promising approach to improving the performance of machine translation models. Several studies have demonstrated the effectiveness of different prompt-based approaches, such as differentiable template-based prompts and prompt-based unsupervised machine translation. However, there are still challenges to be addressed, and further research is needed to fully explore the potential of prompt-based methods in machine translation.
3. Method
3.1. NLP Algorithm
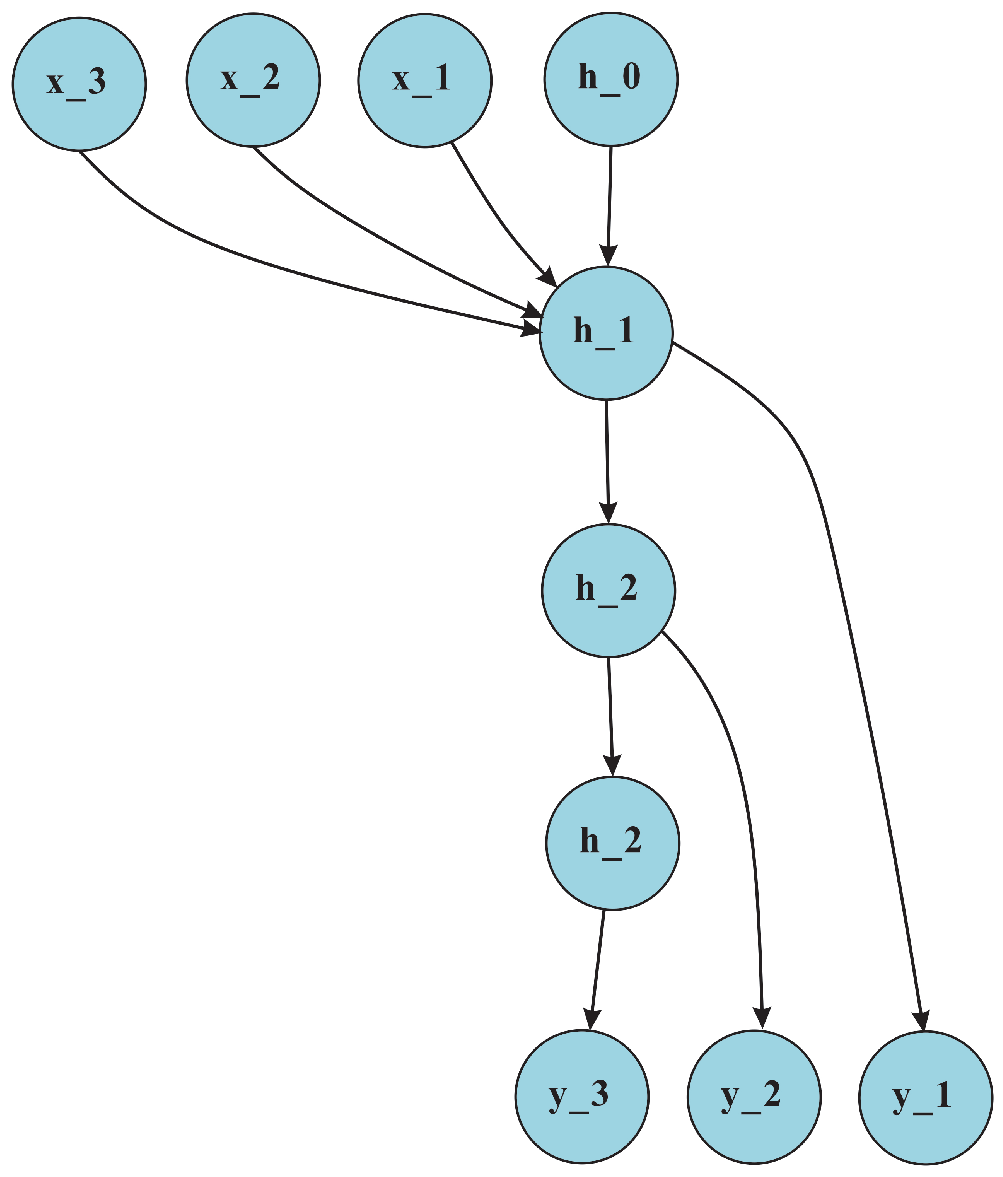
Natural language processing (NLP) algorithms are designed to enable computers to process and understand human language. One fundamental principle of NLP algorithms is to represent language in a structured format that can be processed by a computer. One common approach is to represent text as a sequence of numbers, where each number represents a word or a character. This sequence of numbers can then be processed using various machine learning techniques, such as neural networks. Neural networks are a type of machine learning model that are particularly well-suited for processing sequences of data, such as text. In the context of NLP, one popular type of neural network is the recurrent neural network (RNN). An RNN is designed to process sequences of data by maintaining an internal state that depends on the previous inputs. This internal state allows the network to capture contextual information and dependencies between different parts of the sequence.
In the RNN network structure in
Figure 2, W-hh, W-xh, and W-hy represent the three weight matrices, respectively. W-hh is the weight matrix of the hidden state to the hidden state. This is used to calculate the relationship between the hidden state in the previous moment and the hidden state in the current moment. W-xh is the input to the hidden state weight matrix. This is used to calculate the relationship between the input features and the hidden state at the current moment. W-hy is the weight matrix from the hidden state to the output. This is used to calculate the relationship between the hidden state and the output at the current moment.These weight matrices are learned and optimized during the training of the RNN model to minimize the error of the model in the task.
However, RNNs suffer from a problem known as the vanishing gradient problem, which makes it difficult for the network to learn long-term dependencies. To address this issue, a new type of neural network called a long short-term memory (LSTM) network was developed. LSTMs use a specialized architecture that allows them to remember important information from earlier parts of the sequence, while also selectively discarding irrelevant information.
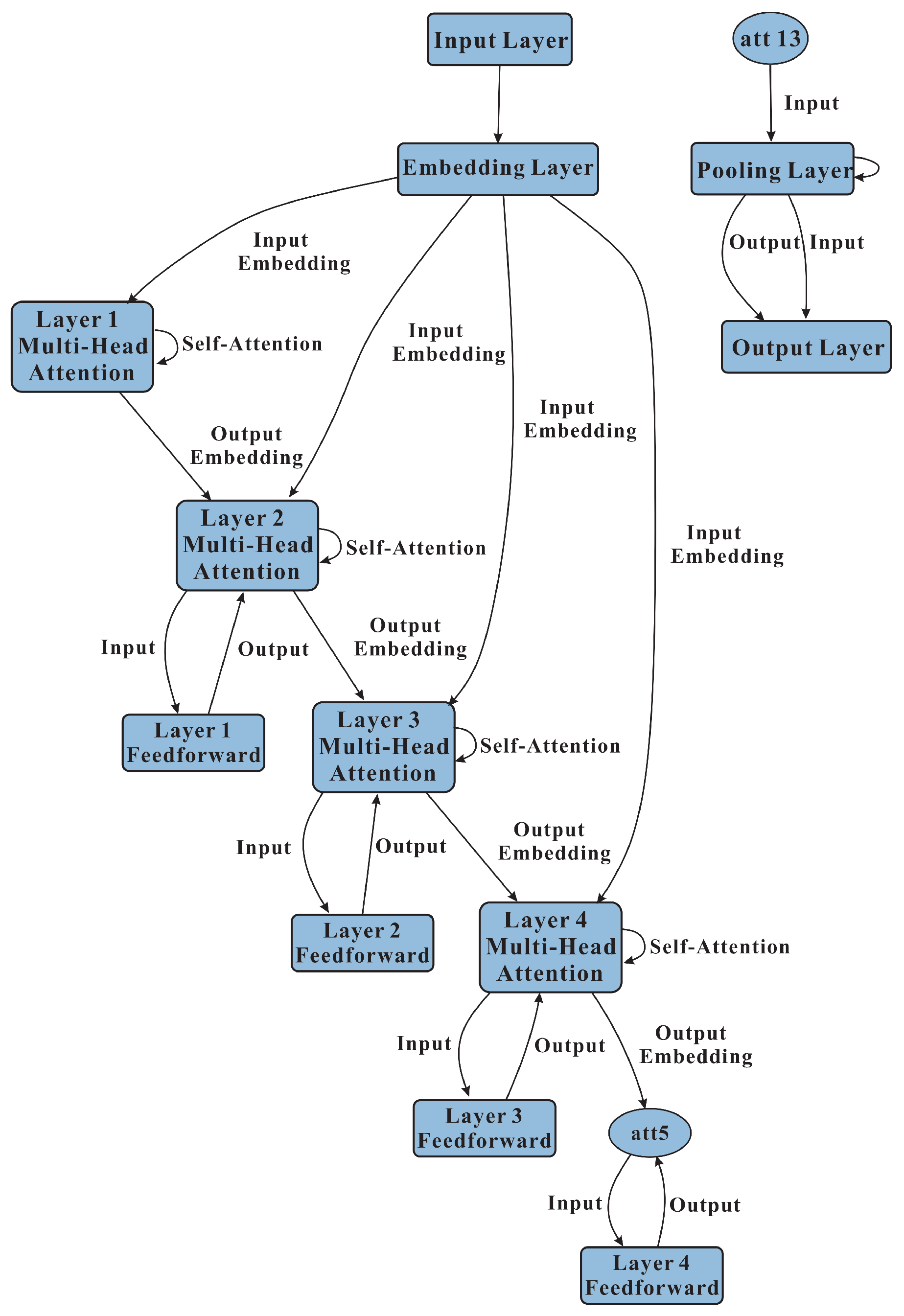
Another important advancement in NLP algorithms is the development of transformer-based models. A schematic diagram of transformer-based model is shown in
Figure 3 below.
Transformers are a type of neural network that is particularly well-suited to processing sequences of data, such as text. Unlike RNNs and LSTMs, which process data sequentially, transformers process the entire sequence of data at the same time. This allows them to capture long-range dependencies and relationships between different parts of the sequence more effectively.
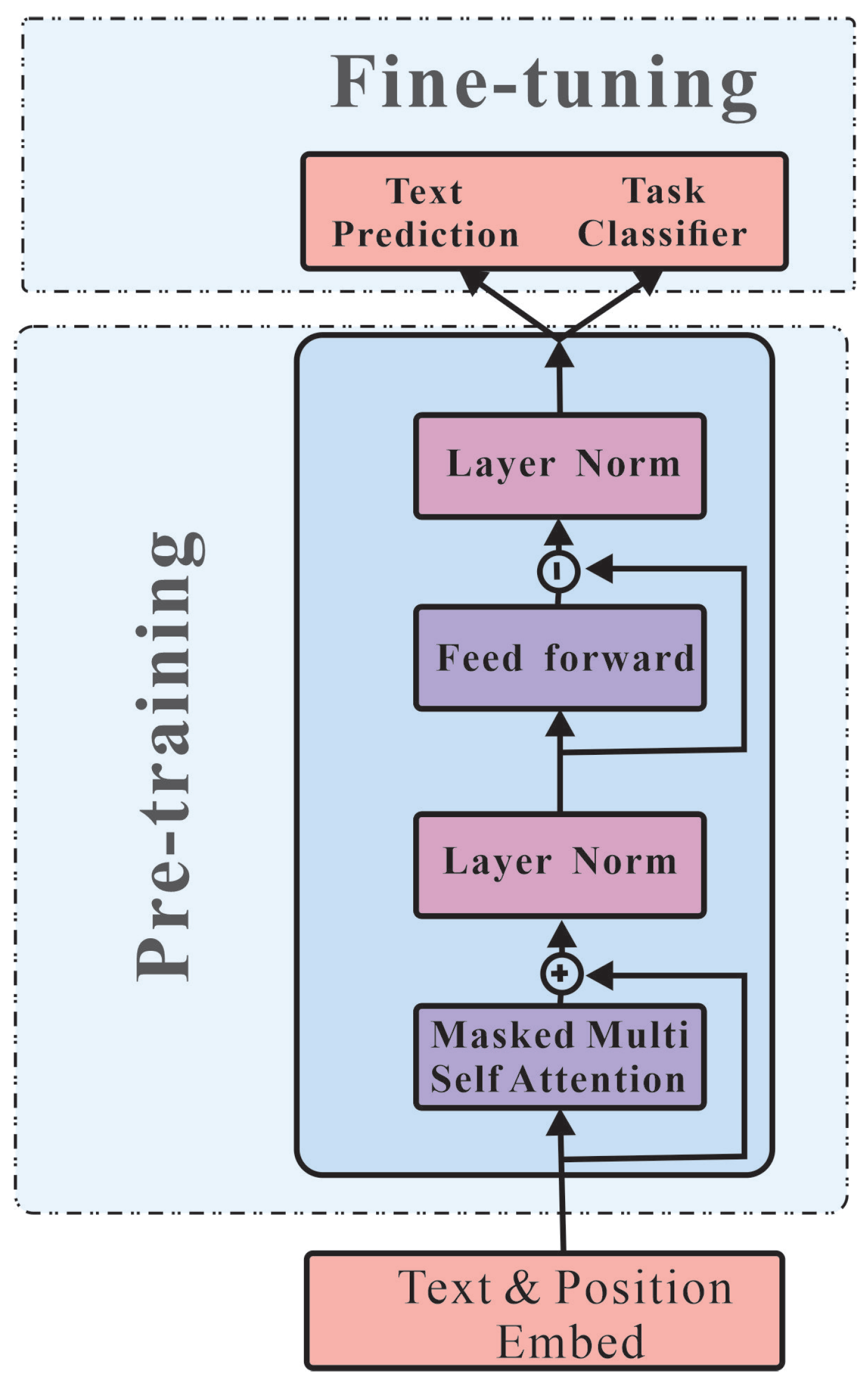
One of the most popular transformer-based models in NLP is the BERT (bidirectional encoder representations from transformers) model. BERT is a pretrained language model that is capable of generating contextually relevant representations of words by training on large amounts of text data. A diagram of the BERT model training process is shown in
Figure 4 below.
BERT is designed to be used for a wide range of NLP tasks, such as text classification, question answering, and named entity recognition.
Another popular transformer-based model is the GPT (generative pretrained transformer) model. Unlike BERT, which is primarily used for tasks such as language understanding, GPT is designed for language generation. GPT is capable of generating coherent and contextually relevant text based on a given prompt, making it particularly useful for tasks such as language translation and content generation.
3.1.1. BERT Algorithm
BERT is a pretraining language model that uses a bidirectional transformer encoder to generate deep contextual representations of words. A schematic diagram of the BERT algorithm network structure is shown in
Figure 5 below.
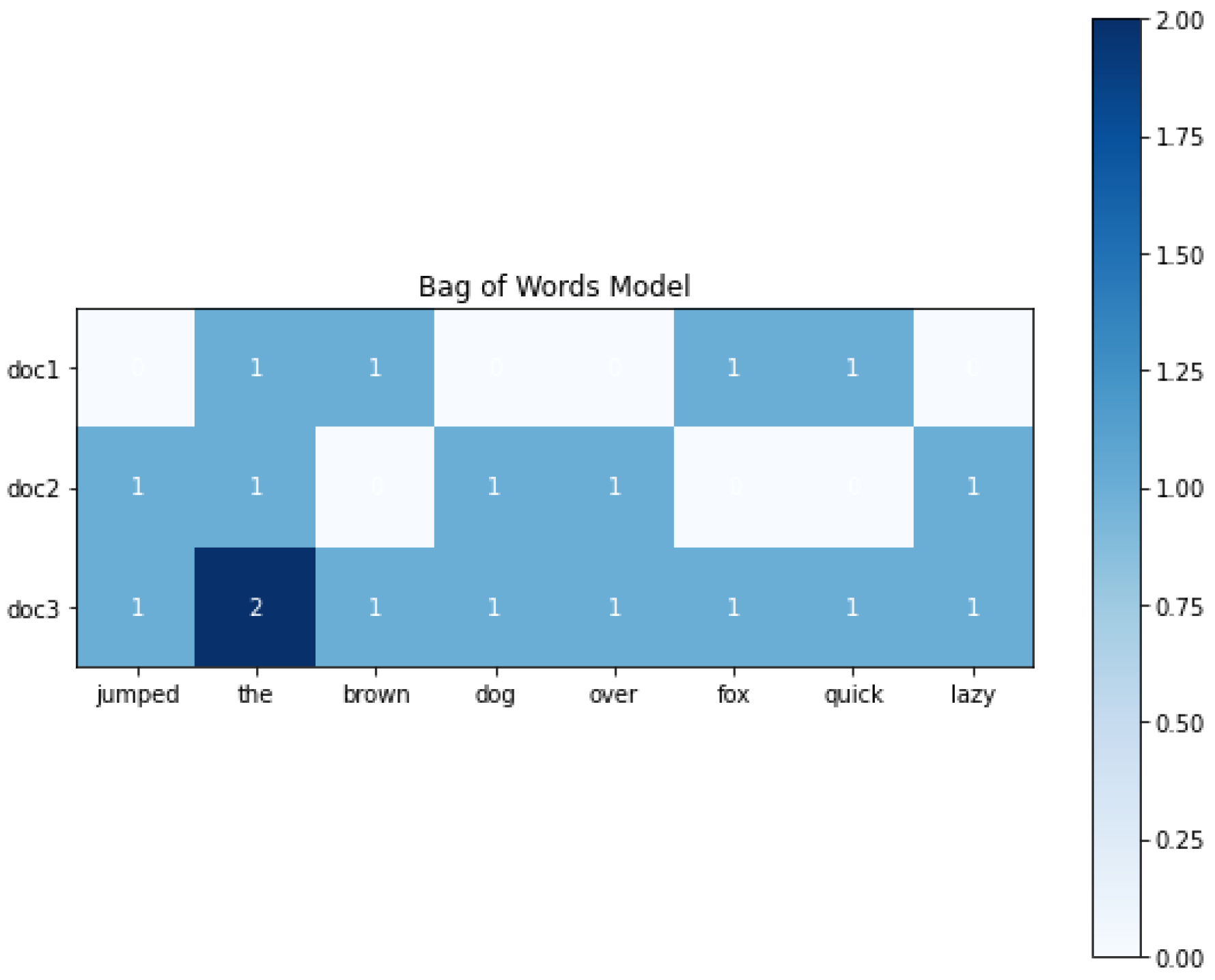
It learns to predict masked words in a sentence based on the context of the surrounding words, as well as to predict the next sentence in a sequence. A bag-of-words model is shown in
Figure 6 below.
BERT has a large number of parameters (110 million for the base version and 340 million for the large version) and is pretrained on a large corpus of text data such as Wikipedia and BookCorpus. After pretraining, BERT can be fine-tuned on specific NLP tasks, such as sentiment analysis and question answering, with only a small amount of task-specific data. The core of BERT is a multi-layer bidirectional transformer encoder, which can be represented using the following formula:
where
X is the input sequence of words, and
H is the output sequence of hidden states representing the contextualized embeddings of the input words.
3.1.2. GPT Algorithm
GPT, on the other hand, is a generative language model that uses a transformer decoder to generate text. It is pretrained on a large corpus of text data using a language modeling objective, which is to predict the next word in a sequence given the previous words. GPT has also achieved state-of-the-art performance in various NLP tasks, including language translation, question answering, and text completion [
44]. The core of GPT is a multi-layer transformer decoder, which can be represented by the following formula:
where
X is the input sequence of words, and
Y is the output sequence of hidden states representing the contextualized embeddings of the input words, The pseudo-code of the encoder layer algorithm is shown in Algorithm 1:
| Algorithm 1: Transformer Encoder Layer |
1: procedure Transformer-Encoder-Layer() 2: 3: 4: 5: 6: 7: 8: 9: end for 10: end for 11: return x 12: end procedure |
Both BERT and GPT use a transformer architecture, which is a self-attention mechanism that allows the model to attend to different parts of the input sequence while generating contextualized representations. The self-attention mechanism is computed based on the following formulas:
where
Q,
K, and
V are the query, key, and value matrices, respectively, and
is the dimensionality of the key vectors.
In addition, both BERT and GPT use a pretraining method called masked language modeling, which randomly masks some of the input words and requires the model to predict the masked words based on the context of the surrounding words. This allows the model to learn the relationships between different words and improve its ability to understand and generate natural language.
Overall, BERT and GPT are two powerful NLP algorithms that have made significant contributions to the field of natural language processing.
3.2. Prompt Algorithm
The prompt algorithm is a technique for natural language processing that can help models better understand and generate language. The parameter validity of prompt learning is shown in
Figure 7 below.
The basic principle of the prompt algorithm is to add some guiding information to the model input, to help the model better understand the input and generate a more accurate output. The core idea of the prompt algorithm is to transform a task into a generation problem for a specific intermediate representation [
44]. In this case, the prompt algorithm refers to the intermediate representation as a “prompt”.
Table 1 below reflects the sub-optimal nature of a hard prompt.
By including the prompt as part of the input, the model can better understand the task requirements and generate a more accurate output. The basic framework of the prompt algorithm can be represented by the following formula:
Here,
is the final output,
X is all possible outputs,
is the
i-th element of the target output, and
is the conditional probability distribution of outputting
given prompt
x. In the prompt algorithm, the prompt consists of two parts: state
S and history
L. The state
S is a vector that stores some information about the task. The history
L is a sequence that stores past outputs. The prompt algorithm updates the state
S and history
L at each time step, specifically:
Here,
F is the input, and
and
are the update functions. Through the prompt algorithm, the model can better utilize the information in the prompt to generate more accurate output. The prompt algorithm has been successfully applied to multiple natural language processing tasks, including question answering, text classification, and text generation, etc. The pseudo code of the prompt specific algorithm is shown in Algorithm 2.
| Algorithm 2: Prompt-Based Text Generation |
Input: prompt, generation length Output: generated text Procedure: PROMPT-GENERATE 1: Initialize prompt as input text 2: Set generated text as empty 3: fort ← 1 to generation length do 4: for all possible next tokens do 5: Score the likelihood of the token using the prompt and the model’s parameters 6: Choose the token with the highest score as the next token 7: Add the next token to the generated text 8: end for 9: Update the prompt with the generated text 10: end for 11: return generated text 12: end procedure |
4. Experiment
In recent years, reinforcement learning has been widely applied in the field of natural language processing. Compared with traditional supervised learning, reinforcement learning can learn a strategy by interacting with the environment to maximize a certain reward function. In machine translation tasks, reinforcement learning can be used to guide the model to generate more accurate translations. Pretrained language models are an important technology and have made significant progress in the field of natural language processing in recent years. In machine translation tasks, pretrained language models can be used to improve translation quality. This paper combined reinforcement learning and pretrained language model techniques to study their application in machine translation tasks and conducted experimental verification using the prompt algorithm. The specific procedure of the experiment is shown in
Figure 8 below.
4.1. Introduction to the Dataset
The dataset used in the experiment was the WMT 2014 English–German translation dataset, which includes about 45,000 training samples and 3000 test samples. To improve the model’s performance, we used adversarial sample generation technology to expand the original dataset by 10 times. Specifically, we used the TextFooler algorithm, which can automatically generate adversarial samples by replacing words with synonyms. Some sample data from the dataset are shown in
Table 2 below.
The above data are examples of the WMT 2014 English–German translation dataset. They include 10 example sentences in English and their corresponding translations in German. Each sentence is given an ID number and is displayed in the “English” column. The corresponding translation of each sentence is given in the “German” column. This dataset is commonly used for evaluating the performance of machine translation systems, particularly for English to German language pairs. By training and testing machine translation models on this dataset, researchers can assess the quality of the translations produced by the models and compare their performance against other models.
4.2. Experimental Platform
The experimental platform used in this study was Google Colaboratory, which is a cloud-based development environment for using Python in a browser and that supports GPU acceleration. The deep learning framework used in the experiment was PyTorch, which is an open-source machine learning library for deep learning.
4.3. Experimental Method
The method of the experiment mainly consisted of the following steps: We first preprocessed the data, including tokenization, converting sentences into numerical sequences, and building a vocabulary. To reduce the computational complexity of the model, we used the BPE algorithm to compress the vocabulary. We used the GPT-2 pretrained language model for training. The purpose of the pretrained language model was to learn the statistical regularities and contextual information of the language, in order to provide better performance in downstream tasks. We used the actor–critic algorithm for reinforcement learning, which is a typical policy gradient algorithm. We used the pretrained language model as the actor and the translation model as the critic. The actor generates an action based on the current state, and the critic evaluates the value of the action and gives a reward. The actor updates its strategy based on the reward, to improve the quality of translation.
4.4. Experimental Process
We used the prompt algorithm to guide machine translation. The prompt algorithm is a template-based text generation method that can guide the model to generate specific text. We used the prompt algorithm to guide the model to generate more accurate translations.
Specifically, we used the input English sentence as the prompt, and then input the prompt and the German sentence to be translated into the model to generate the translation result. To improve the translation quality, we added some translation-related keywords to the prompt, such as “translate”, “translate to German”, “translate from English to German”, etc. We used multiple different prompts to improve the translation diversity. The specific translation results are shown in
Table 3 below.
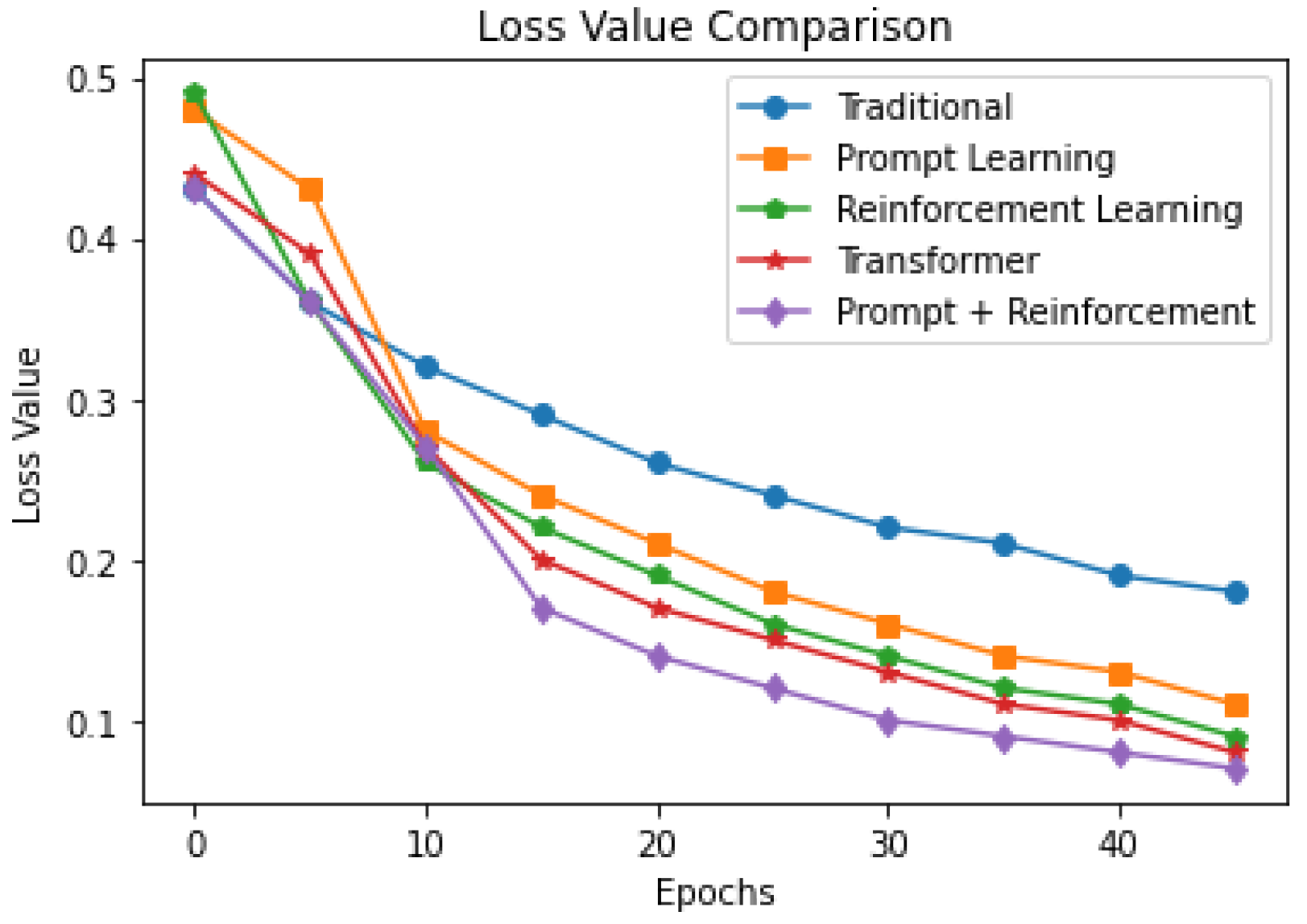
The model specific accuracy and loss value changes during the experiment are shown in
Figure 9 and
Figure 10 below.
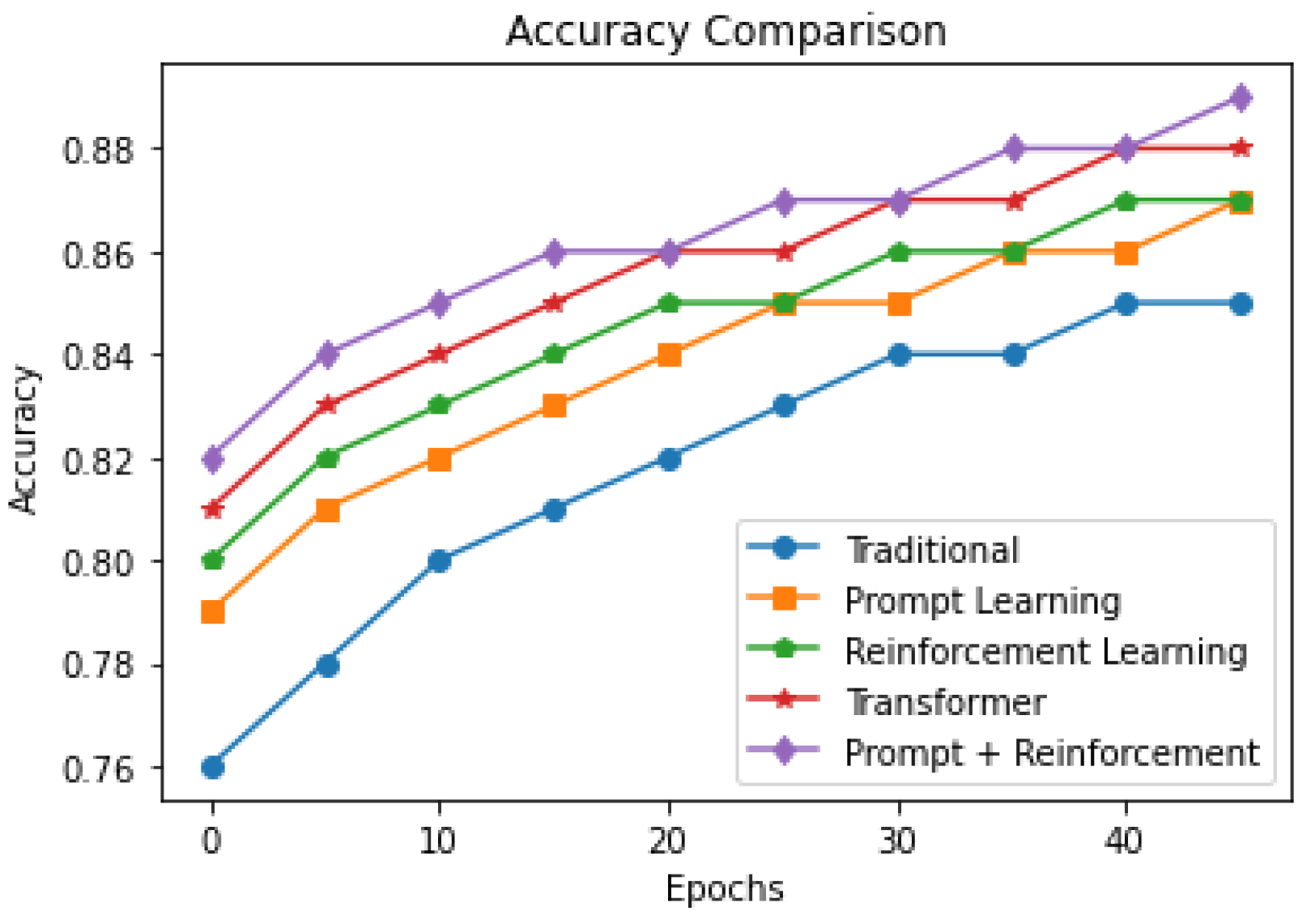
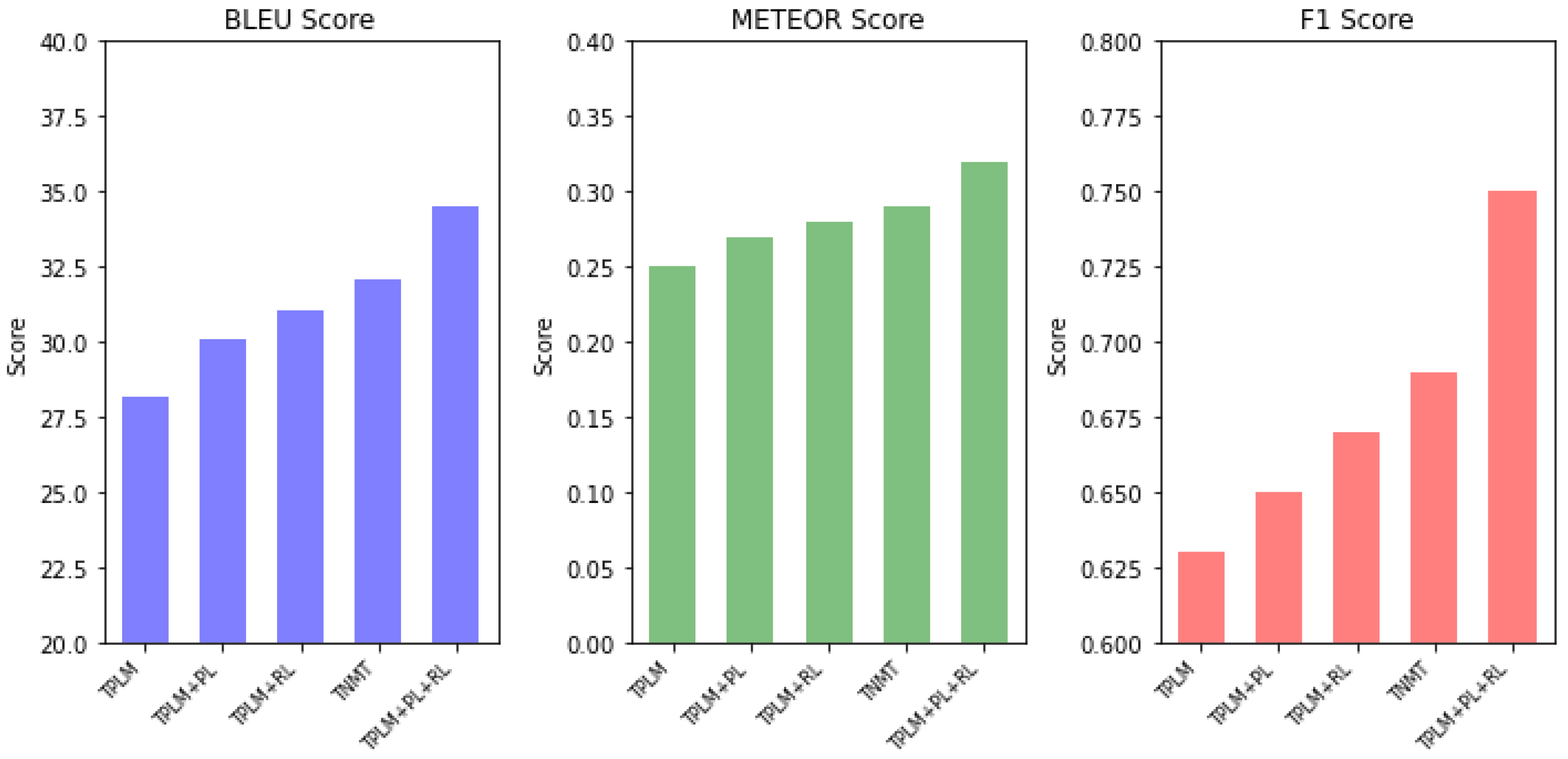
The results in
Table 4 below compare the performance of four different language models for three different metrics: BLEU score, METEOR score, and F1 score. BLEU score is a metric that measures the similarity between the predicted text and the reference text, based on n-gram overlap. A higher BLEU score indicates a better performance. METEOR score is a metric that measures the quality of the generated text based on how well it captures meaning and fluency. A higher METEOR score indicates a better performance. F1 score is a metric that measures the balance between the precision and recall of the generated text. A higher F1 score indicates a better performance.
The results in
Figure 11 show that all the models performed better than the traditional pretrained language model for all three metrics. The model with the highest performance was the pretrained language model with prompt learning and reinforcement learning, which achieved the highest scores in all three metrics.The transformer-based neural machine translation model also performed well, achieving the second-highest scores in all three metrics. Overall, these results suggest that using techniques such as prompt learning and reinforcement learning can improve the performance of pretrained language models in tasks such as text generation and machine translation.
5. Discussion
With the rapid development of deep learning technology, pretrained language models have become indispensable tools in various natural language processing tasks. While they have achieved remarkable results in fields such as language generation, question answering systems, text classification, semantic search, and machine translation, there is still room for improvement in specific tasks, particularly machine translation.
To address this, we proposed an innovative method that combines prompt learning with reinforcement learning, to enhance the performance of pretrained language models in machine translation tasks. By incorporating a “prompt” string into the model input and employing reinforcement learning algorithms during training, the model is guided to produce an output more aligned with the target translation, resulting in improved performance. In this process, we treated the target translation as a reward signal, with a higher similarity between the generated translation and the target translation yielding higher rewards. By adjusting the weight of the reward signal and the content of the prompt string, we can optimize the model’s performance. The experimental results confirmed that the pretrained language model enhanced with prompt learning and reinforcement learning outperformed traditional pretrained language models in machine translation tasks, as evidenced by the higher scores in evaluation metrics such as BLEU and TER. We emphasize that the proposed method has broad application prospects. By applying similar prompt learning and reinforcement learning techniques to other natural language processing tasks, pretrained language model performance can be further enhanced. For instance, in question answering systems, prompt strings can guide the model to generate answers closer to the correct ones. In text summarization, prompt strings can assist in generating summaries that faithfully represent the original text. However, it is important to consider the design of the prompt string, as this significantly impacts the model’s performance. The choice of prompt strategy is crucial for different tasks. For machine translation, the target language translation can serve as the prompt string, while for question answering systems, the question can be used as the prompt. Researchers should carefully select the optimal prompt strategy tailored to each specific task to achieve the best results. Furthermore, this method can be combined with other techniques to further improve pretrained language model performance. Multi-task learning can enhance the model’s generalization by training it to handle multiple tasks simultaneously. Prompt learning can be applied to multiple tasks to generate prompt strategies more suited to diverse tasks. Additionally, techniques such as knowledge distillation and model compression can reduce model size and computation, enhancing model efficiency and deployability.
In conclusion, our paper introduces a promising approach that combines prompt learning with reinforcement learning to enhance pretrained language model performance in machine translation tasks. The results show that this method effectively improves the model’s performance. We also underscore the importance of selecting an appropriate prompt strategy for different tasks and the potential for combining this method with other techniques to further optimize pretrained language models.
6. Conclusions
In conclusion, this paper proposes a novel prompt learning method combined with reinforcement learning to optimize the performance of pretrained language models in machine translation tasks and other related applications. While the results are promising, there are several challenges that need to be addressed in practical applications. One of the key challenges is choosing the optimal prompt strategy and finding the right balance between the learning speed of the model and the quality of the generated outputs. Further research is needed to explore different prompt strategies and their impact on model performance in various tasks. Moreover, the potential of the prompt learning method extends beyond machine translation and can be applied to other natural language processing tasks, such as text summarization and question-answering systems. Future research could investigate how to adapt and fine-tune this method for different tasks, to further improve the pretrained language models’ performance. Furthermore, in domain-specific tasks such as medicine and law, incorporating domain-specific knowledge and terminology is essential. Future studies could explore ways to integrate domain-specific information into pretrained models, to enhance their understanding and performance in these specialized domains. Additionally, the integration of pretrained language models with other technologies, such as knowledge graphs and transfer learning, holds significant potential. Leveraging knowledge graphs can enhance a models’ comprehension of domain-specific concepts and relationships, while transfer learning can facilitate the knowledge transfer between tasks, further improving model capabilities. Looking ahead, these advancements in pretrained language models and their integration with other technologies could have profound implications across various applications, including chatbots, search engines, and machine translation systems. Continued research in this field will undoubtedly lead to further breakthroughs in natural language processing, enabling more sophisticated and effective communication between humans and machines.
In summary, while this paper presents a promising approach, there remain exciting avenues for future research to tackle challenges, extend the method to various tasks, and leverage complementary technologies. The journey towards more advanced natural language processing systems is dynamic and full of potential, and we eagerly anticipate the contributions of the research community to pushing the boundaries of this field.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}