
CAS-UNet: A Retinal Segmentation Method Based on Attention

Abstract
:1. Introduction
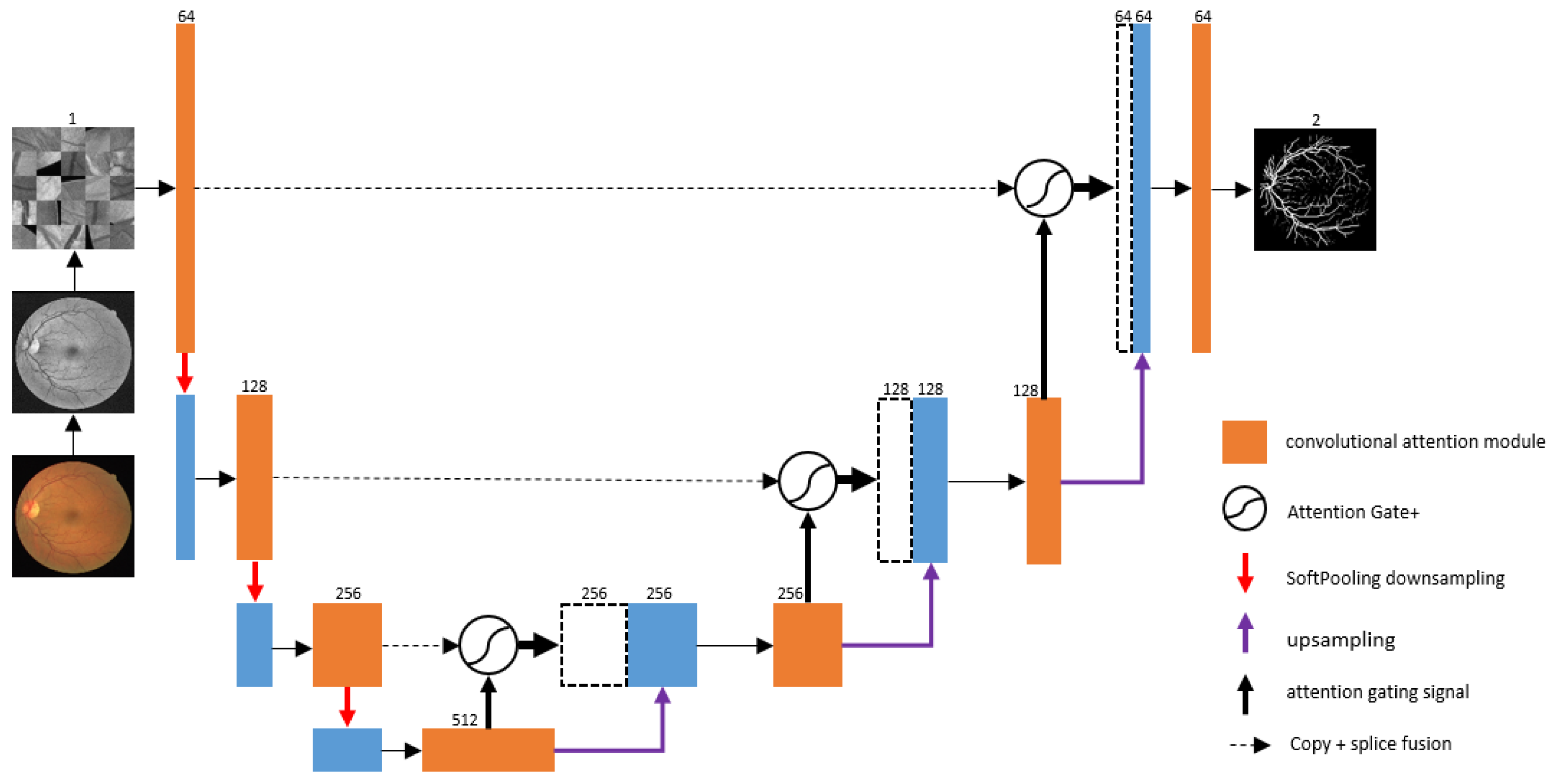
- A Structured Convolutional Attention module (DC-Conv) is used in the encoding and decoding stages of the network to enhance the channel features of retinal vessels.
- An Additive Attention Gate (AG+) module is introduced at the skip connection of the network to enhance the spatial features of retinal vessels.
- A SoftPool pooling method is added to reduce information loss during downsampling.
2. Related Work
3. The Algorithm Principle
3.1. CAS-UNet Network Model
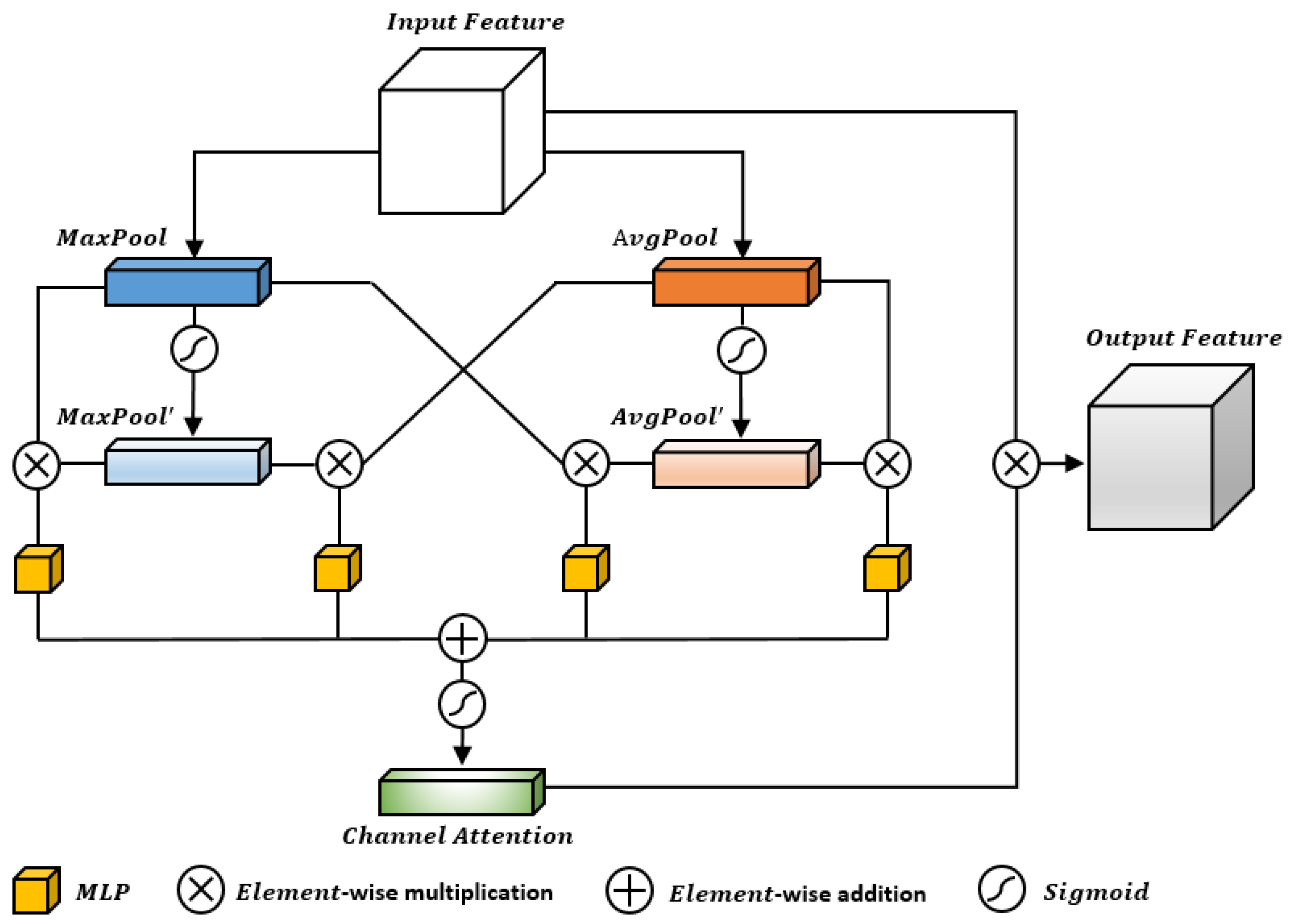
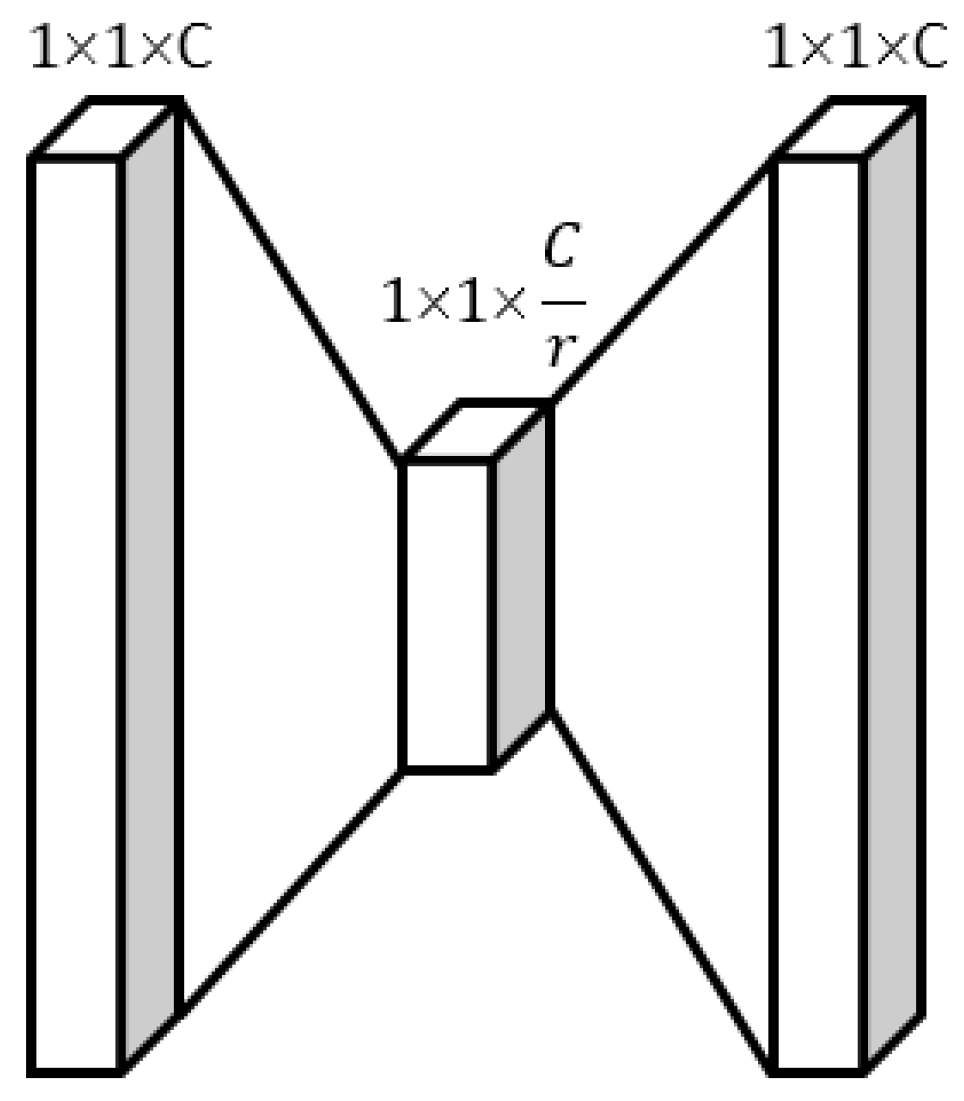
3.2. The Cross-Fusion Channel Attention Model
- Step 1: Squeeze
- Step 2: Cross
- Step 3: Excitation
- Step 4: Feature Weighted Summation
- Step 5: Re-calibration
3.3. The DC-Conv Module
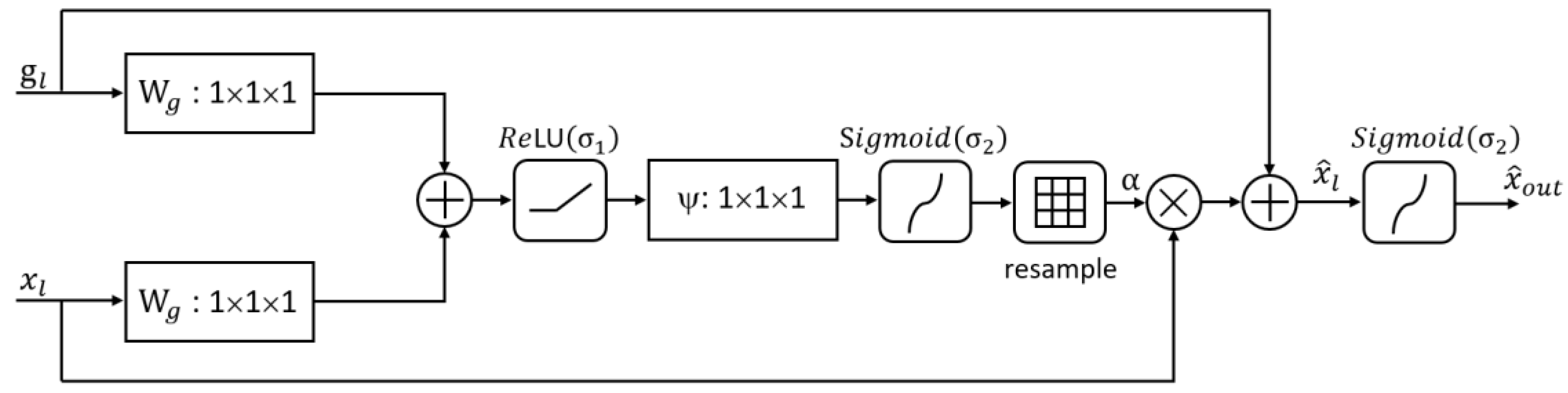
3.4. The Additive Attention Gate Module
3.5. SoftPool Pooling
4. Experiments
4.1. Datasets and Preprocessing
4.1.1. Datasets
4.1.2. Preprocessing
- extract the green channel of the retinal vessel image and convert it to grayscale;
- normalize the image;
- apply Contrast Limited Adaptive Histogram Equalization (CLAHE);
- apply Gamma correction.
4.1.3. Data Augmentation
4.2. Experimental Parameter Settings
4.3. Evaluation Metrics
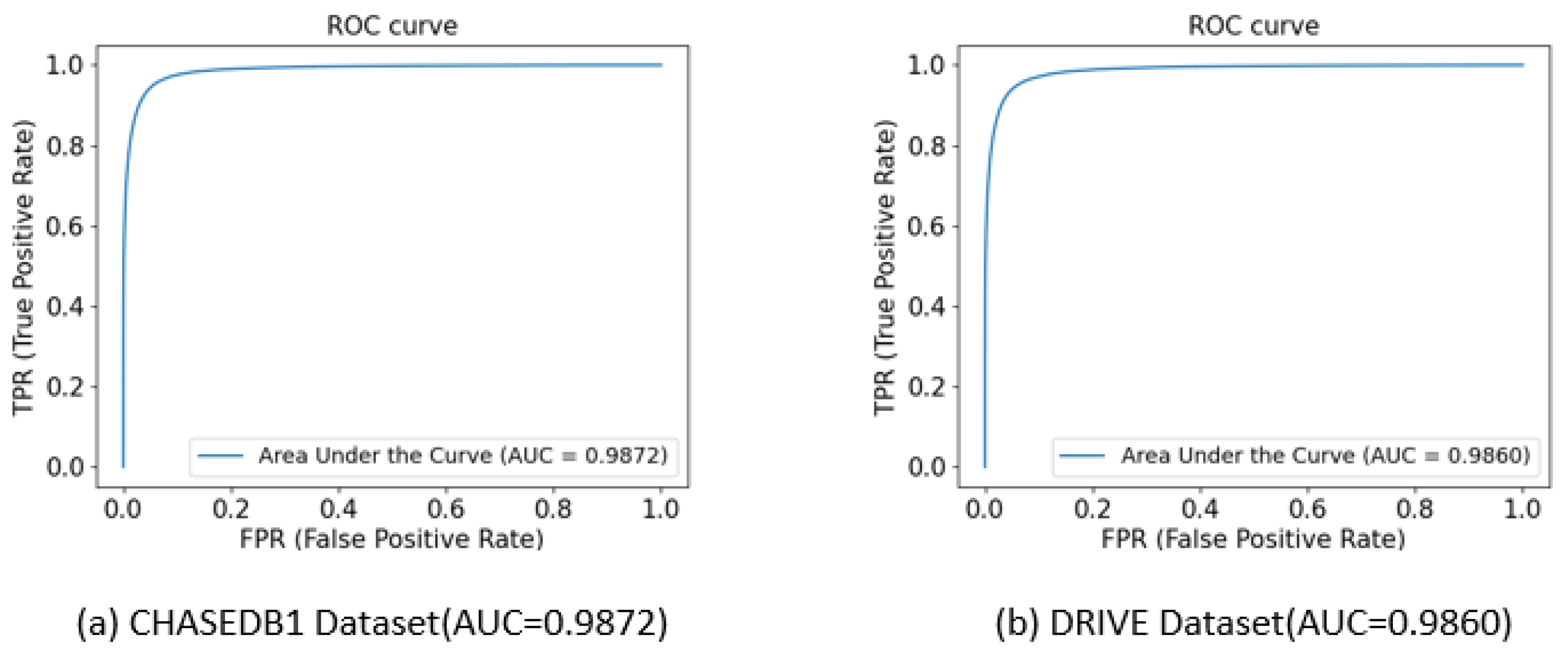
4.4. Analysis of Experimental Results
4.4.1. Comparison of the Overall Segmentation Results
4.4.2. Objective Data Comparison
4.4.3. Comparison with Other Algorithms
4.4.4. Comparison of Ablation Experiments
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Saroj, S.K.; Kumar, R.; Singh, N.P. Frechet PDF based matched filter approach for retinal blood vessels segmentation. Comput. Methods Programs Biomed. 2020, 194, 105490. [Google Scholar] [CrossRef]
- Chaudhuri, S.; Chatterjee, S.; Katz, N.; Nelson, M.; Goldbaum, M. Detection of blood vessels in retinal images using two-dimensional matched filters. IEEE Trans. Med. Imaging 1989, 8, 263–269. [Google Scholar] [CrossRef] [Green Version]
- Yin, Y.; Adel, M.; Bourennane, S. Retinal vessel segmentation using a probabilistic tracking method. Pattern Recognit. 2012, 45, 1235–1244. [Google Scholar] [CrossRef]
- Zana, F.; Klein, J.C. Segmentation of vessel-like patterns using mathematical morphology and curvature evaluation. IEEE Trans. Image Process. 2001, 10, 1010–1019. [Google Scholar] [CrossRef] [Green Version]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Ricci, E.; Perfetti, R. Retinal blood vessel segmentation using line operators and support vector classification. IEEE Trans. Med. Imaging 2007, 26, 1357–1365. [Google Scholar] [CrossRef]
- Marín, D.; Aquino, A.; Gegúndez-Arias, M.E.; Bravo, J.M. A new supervised method for blood vessel segmentation in retinal images by using gray-level and moment invariants-based features. IEEE Trans. Med. Imaging 2010, 30, 146–158. [Google Scholar] [CrossRef] [Green Version]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; Van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef]
- Fraz, M.M.; Remagnino, P.; Hoppe, A.; Uyyanonvara, B.; Rudnicka, A.R.; Owen, C.G.; Barman, S.A. An ensemble classification-based approach applied to retinal blood vessel segmentation. IEEE Trans. Biomed. Eng. 2012, 59, 2538–2548. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Shankaranarayana, S.M.; Ram, K.; Mitra, K.; Sivaprakasam, M. Joint optic disc and cup segmentation using fully convolutional and adversarial networks. In Fetal, Infant and Ophthalmic Medical Image Analysis; Springer: Cham, Switzerland, 2017; pp. 168–176. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, J.; Jin, Y.; Xu, J.; Xu, X.; Zhang, Y. Mdu-net: Multi-scale densely connected u-net for biomedical image segmentation. arXiv 2018, arXiv:1812.00352. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-net: Context encoder network for 2d medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef]
- Alom, M.Z.; Yakopcic, C.; Hasan, M.; Taha, T.M.; Asari, V.K. Recurrent residual U-Net for medical image segmentation. J. Med. Imaging 2019, 6, 014006. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Jafari, M.; Auer, D.; Francis, S.; Garibaldi, J.; Chen, X. DRU-Net: An efficient deep convolutional neural network for medical image segmentation. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1144–1148. [Google Scholar]
- Ma, J.; Zhang, H.; Yi, P.; Wang, Z. SCSCN: A separated channel-spatial convolution net with attention for single-view reconstruction. IEEE Trans. Ind. Electron. 2019, 67, 8649–8658. [Google Scholar] [CrossRef]
- Shahreza, H.O.; Hahn, V.K.; Marcel, S. MLP-Hash: Protecting Face Templates via Hashing of Randomized Multi-Layer Perceptron. arXiv 2022, arXiv:2204.11054. [Google Scholar]
- Guo, C.; Szemenyei, M.; Pei, Y.; Yi, Y.; Zhou, W. SD-UNet: A structured dropout U-Net for retinal vessel segmentation. In Proceedings of the 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE), Athens, Greece, 28–30 October 2019; pp. 439–444. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 2–8 December 2018; pp. 10727–10737. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Stergiou, A.; Poppe, R.; Kalliatakis, G. Refining activation downsampling with SoftPool. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10357–10366. [Google Scholar]
- Deng, X.; Ye, J. A retinal blood vessel segmentation based on improved D-MNet and pulse-coupled neural network. Biomed. Signal Process. Control 2022, 73, 103467. [Google Scholar] [CrossRef]
- Mo, J.; Zhang, L. Multi-level deep supervised networks for retinal vessel segmentation. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 2181–2193. [Google Scholar] [CrossRef]
- Yan, Z.; Yang, X.; Cheng, K.T. Joint segment-level and pixel-wise losses for deep learning based retinal vessel segmentation. IEEE Trans. Biomed. Eng. 2018, 65, 1912–1923. [Google Scholar] [CrossRef]
- Guo, S.; Wang, K.; Kang, H.; Zhang, Y.; Gao, Y.; Li, T. BTS-DSN: Deeply supervised neural network with short connections for retinal vessel segmentation. Int. J. Med. Inform. 2019, 126, 105–113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, L.; Verma, M.; Nakashima, Y.; Nagahara, H.; Kawasaki, R. Iternet: Retinal image segmentation utilizing structural redundancy in vessel networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 3656–3665. [Google Scholar]
- Gu, R.; Wang, G.; Song, T.; Huang, R.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T.; Zhang, S. CA-Net: Comprehensive attention convolutional neural networks for explainable medical image segmentation. IEEE Trans. Med. Imaging 2020, 40, 699–711. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Chen, Z.; Shen, H.; Zheng, X.; Zhao, R.; Duan, X. A refined equilibrium generative adversarial network for retinal vessel segmentation. Neurocomputing 2021, 437, 118–130. [Google Scholar] [CrossRef]
- Rahman, M.M.; Marculescu, R. Medical image segmentation via cascaded attention decoding. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 6222–6231. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Original Image | Gold Standard Image | Mask Image |
|---|---|---|---|
| CHASEDB1 |  |  |  |
| DRIVE |  |  |  |
| Datasets | Original Image | G Channel | Normalization | Equalization | Gamma Adjustment |
|---|---|---|---|---|---|
| CHASEDB1 |  |  |  |  |  |
| DRIVE |  |  |  |  |  |
| True Value | Predicted Positive Class (Vessel) | Predict Negative Class (Background) |
|---|---|---|
| Positive class label (blood vessels) | ||
| Negative class label (background) |
| Dataset | Method | ||||
|---|---|---|---|---|---|
| CHASEDB1 | U-Net | 0.9566 | 0.8183 | 0.9716 | 0.8191 |
| U-Net++ | 0.9592 | 0.8210 | 0.9812 | 0.8170 | |
| CAS-UNet | 0.9668 | 0.8321 | 0.9896 | 0.8390 | |
| DRIVE | U-Net | 0.9528 | 0.7936 | 0.9821 | 0.8141 |
| U-Net++ | 0.9536 | 0.8104 | 0.9805 | 0.8156 | |
| CAS-UNet | 0.9586 | 0.8375 | 0.9828 | 0.8207 |
| Method | Year | CHASEDB1 | DRIVE | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Mo [28] | 2017 | 0.9599 | 0.7661 | 0.9816 | 0.7812 | 0.9521 | 0.7779 | 0.9780 | 0.7782 |
| Yan [29] | 2018 | 0.9610 | 0.7633 | 0.9809 | 0.7781 | 0.9542 | 0.7653 | 0.9818 | 0.7752 |
| Guo [30] | 2019 | 0.9627 | 0.7888 | 0.9801 | 0.7940 | 0.9551 | 0.7800 | 0.9806 | 0.7796 |
| Li [31] | 2020 | 0.9655 | 0.7970 | 0.9823 | 0.8051 | 0.9573 | 0.7735 | 0.9838 | 0.7816 |
| Gu [32] | 2020 | 0.9653 | 0.8121 | 0.9769 | 0.8012 | 0.9561 | 0.8143 | 0.9758 | 0.8103 |
| Zhou [33] | 2021 | 0.9630 | 0.8315 | 0.9782 | 0.8172 | 0.9563 | 0.8294 | 0.9812 | 0.8030 |
| Deng [27] | 2022 | 0.9587 | 0.8543 | 0.9693 | 0.7906 | 0.9539 | 0.8368 | 0.9712 | 0.8112 |
| Rahman [34] | 2023 | 0.9658 | 0.8216 | 0.9710 | 0.8145 | 0.9566 | 0.8362 | 0.9803 | 0.8034 |
| CAS-UNet | 2022 | 0.9668 | 0.8321 | 0.9896 | 0.8390 | 0.9586 | 0.8375 | 0.9828 | 0.8207 |
| Method | CHASEDB1 | DRIVE | ||||||
|---|---|---|---|---|---|---|---|---|
| U-Net | 0.9566 | 0.8183 | 0.9716 | 0.8101 | 0.9528 | 0.7936 | 0.9821 | 0.8141 |
| U-Net+ ① | 0.9631 | 0.8275 | 0.9820 | 0.8305 | 0.9562 | 0.8292 | 0.9825 | 0.8195 |
| U-Net+ ② | 0.9612 | 0.8224 | 0.9756 | 0.8210 | 0.9537 | 0.8160 | 0.9823 | 0.8156 |
| U-Net+ ③ | 0.9623 | 0.8231 | 0.9760 | 0.8274 | 0.9540 | 0.8106 | 0.9823 | 0.8170 |
| U-Net+ ① + ② | 0.9648 | 0.8290 | 0.9836 | 0.8365 | 0.9573 | 0.8305 | 0.9826 | 0.8201 |
| U-Net+ ① + ③ | 0.9651 | 0.8305 | 0.9841 | 0.8354 | 0.9570 | 0.8320 | 0.9826 | 0.8198 |
| U-Net+ ② + ③ | 0.9630 | 0.8286 | 0.9803 | 0.8302 | 0.9548 | 0.8240 | 0.9825 | 0.8183 |
| CAS-UNet | 0.9668 | 0.8321 | 0.9896 | 0.8390 | 0.9586 | 0.8375 | 0.9828 | 0.8207 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, Z.; Yu, H.; Xiao, Z.; Peng, T.; Wei, Y. CAS-UNet: A Retinal Segmentation Method Based on Attention. Electronics 2023, 12, 3359. https://doi.org/10.3390/electronics12153359
You Z, Yu H, Xiao Z, Peng T, Wei Y. CAS-UNet: A Retinal Segmentation Method Based on Attention. Electronics. 2023; 12(15):3359. https://doi.org/10.3390/electronics12153359
Chicago/Turabian StyleYou, Zeyu, Haiping Yu, Zhuohan Xiao, Tao Peng, and Yinzhen Wei. 2023. "CAS-UNet: A Retinal Segmentation Method Based on Attention" Electronics 12, no. 15: 3359. https://doi.org/10.3390/electronics12153359