
FRIMFL: A Fair and Reliable Incentive Mechanism in Federated Learning

Abstract
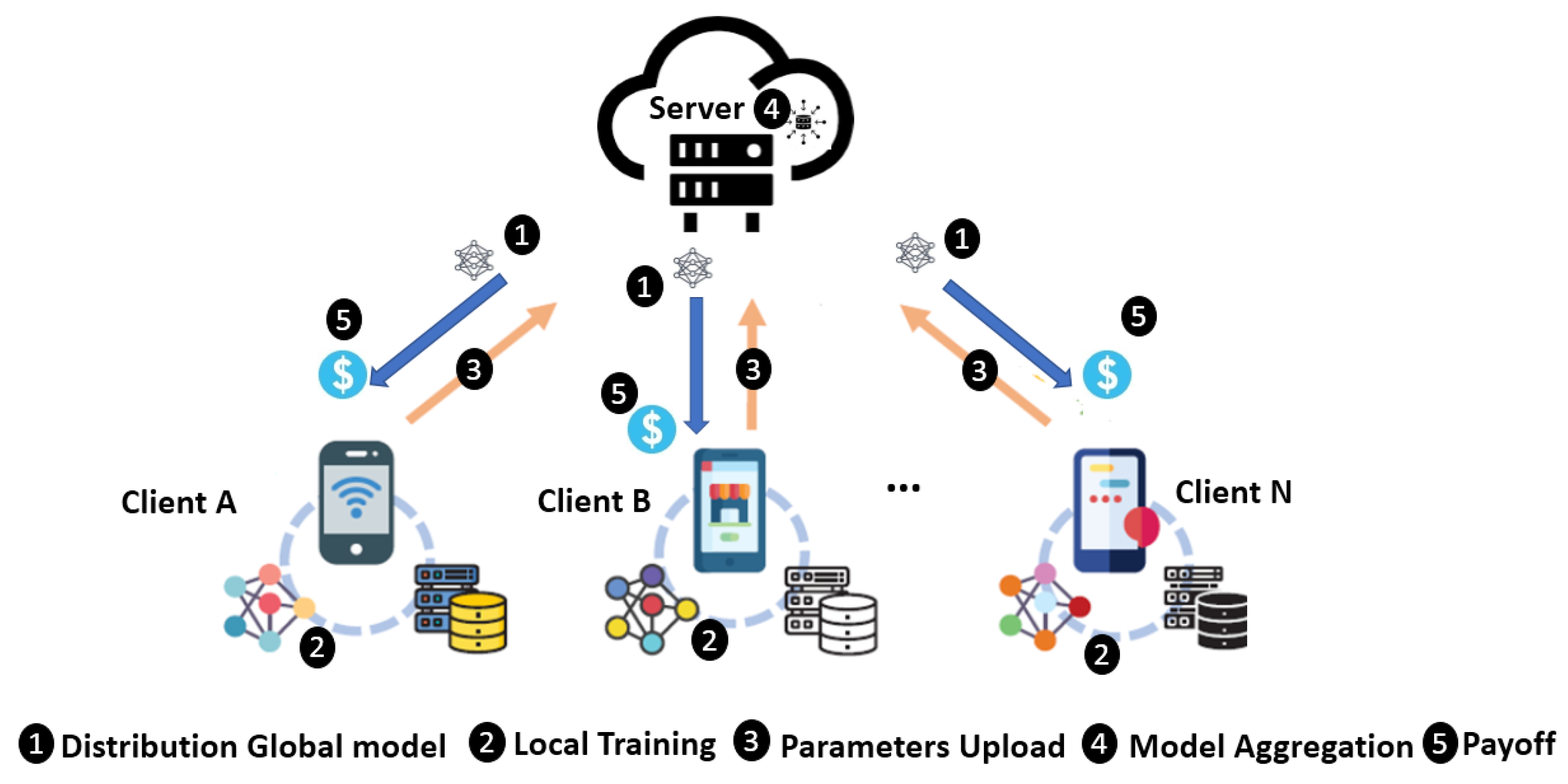
:1. Introduction
- We proposed a reliable FL incentive scheme (FRIMFL) that combines reverse auction and reputation to incentivize clients.
- We constructed a weighted trust assessment method to reflect clients’ reliability considering the quality of model updates.
- We introduced Shapley method to derive the per-round marginal contributions of participants. FRIMFL incorporates reputation (computed from trust and contribution measures) in fair reward allocation to participants.
- The simulation analysis regarding social welfare, contribution fairness, and accuracy shows that our proposed mechanism is compatible, individually rational, and budget feasible.
2. Related Work
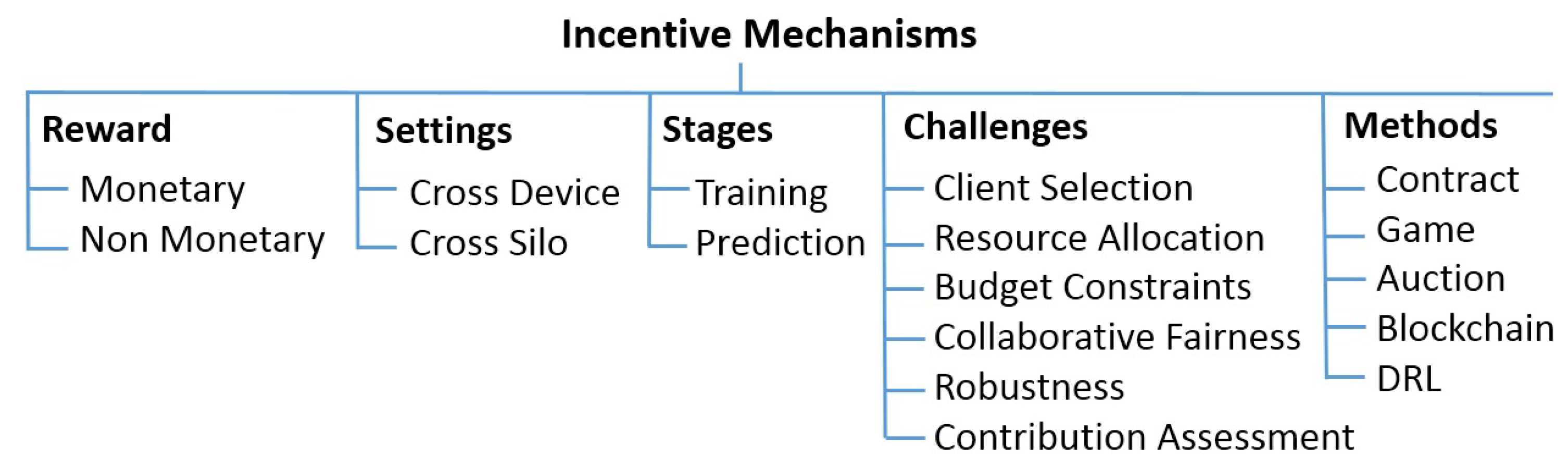
3. Taxonomy of Incentive Mechanisms
3.1. Reward
3.1.1. Monetary Incentives
3.1.2. Non-Monetary Incentives
3.2. Settings
3.3. Stages
3.4. Challenges
- Client management to select qualified workers to join and remain in the training process.
- Resource allocation for clients based on the amount of work and data quality.
- Contribution evaluation to measure the contribution of each participant.
- Budget constraints due to the time-consuming commercialization and training of models or unavailability.
- Collaborative fairness corresponding to participant rewards should fairly reflect different levels of contributions.
- Robustness to targeted and untargeted attacks by malicious workers.
3.5. Methods
3.5.1. Contract Theory
3.5.2. Game Theory
3.5.3. Blockchain
3.5.4. Auction Theory
3.5.5. Deep Reinforcement Learning
4. Materials and Methods
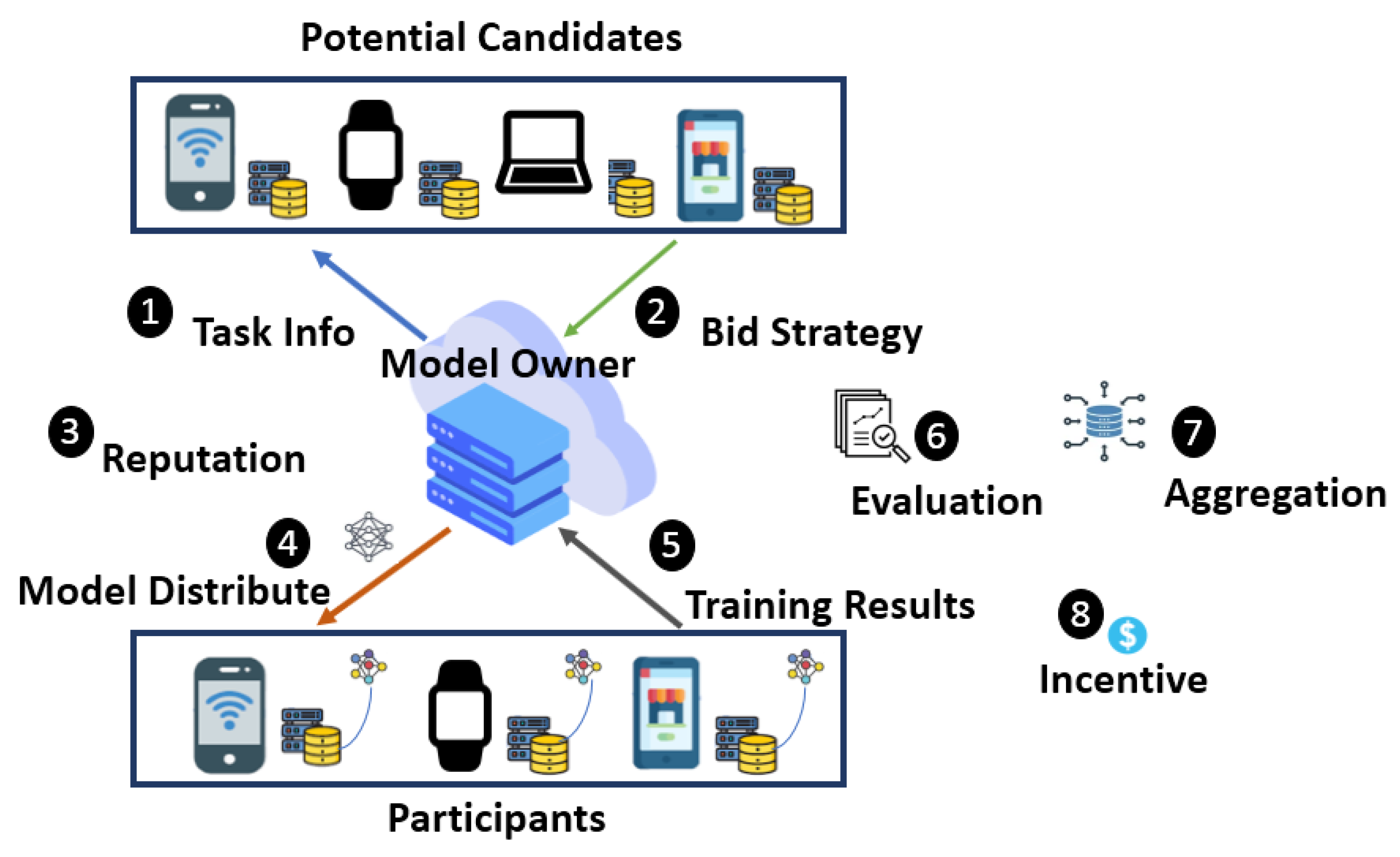
4.1. Proposed Mechanism (FRIMFL)
- 1.
- The server broadcasts the task information to N candidates, describing the budget and model requirements.
- 2.
- Interested candidates devise their bidding strategy based on data quantity or computational resources and submit their bid prices to the server.
- 3.
- The server examines the candidates’ reputation in all associated tasks and applies reverse auctions for global model distribution.
- 4.
- Selected participants from the candidates receive the initial global model and train local models iteratively on their local dataset.
- 5.
- The participants send their training results to the server.
- 6.
- The model owner collects training results, receives gradients, and executes quality detection through marginal loss evaluation.
- 7.
- The server aggregates quality models corresponding quality weights and measures participant contribution via a federated Shapley assessment and reputation to distribute payoffs.
- 8.
- Finally, participants are rewarded as per their level of reputation.
4.2. Reverse Auction-Based Optimal Client Selection
4.3. Design Properties
- Incentive Compatibility (IC): The auction process satisfies incentive compatibility when all the participants obtain a maximum payoff by reporting bids truthfully.
- Individual Rationality (IR): When the participating users receive positive utility, the mechanism achieves incentive rationality.
- Budget Feasibility: The total incentive amount paid to participants does not exceed the model owners’ budget.
- Computational Efficiency: The scheme can be computationally efficient if the winner determination and incentive distribution are computed within polynomial time.
- Aggregation Fairness: Each participant’s aggregated weight shall correspond to its performance quality.
- Reward Fairness: Each participant shall be fairly rewarded, corresponding to their contribution levels for the task.
4.4. Quality Trust Assessment
- Positive Clients: These clients participate honestly, provide reliable model updates without malicious activity, and bid truthful data to complete training tasks.
| Algorithm 1 FRIMFL quality detection |
|
4.5. Contribution Assessment
- Fairness: Participants with similar models or updates shall receive similar contribution values. The contribution scale is correlated with the reward.
- Availability: The contribution value by negative clients shall be 0, as they have no impact on the global model in the current round.
- Additivity: With each cycle of global updates, both long- and short-term contributions are additive to the overall FL process.
4.6. Reputation Measurement
4.7. Client Selection Reward Module
| Algorithm 2 FRIMFL incentive allocation. |
|
5. Theoretical Analysis
6. Results
6.1. Experimental Settings
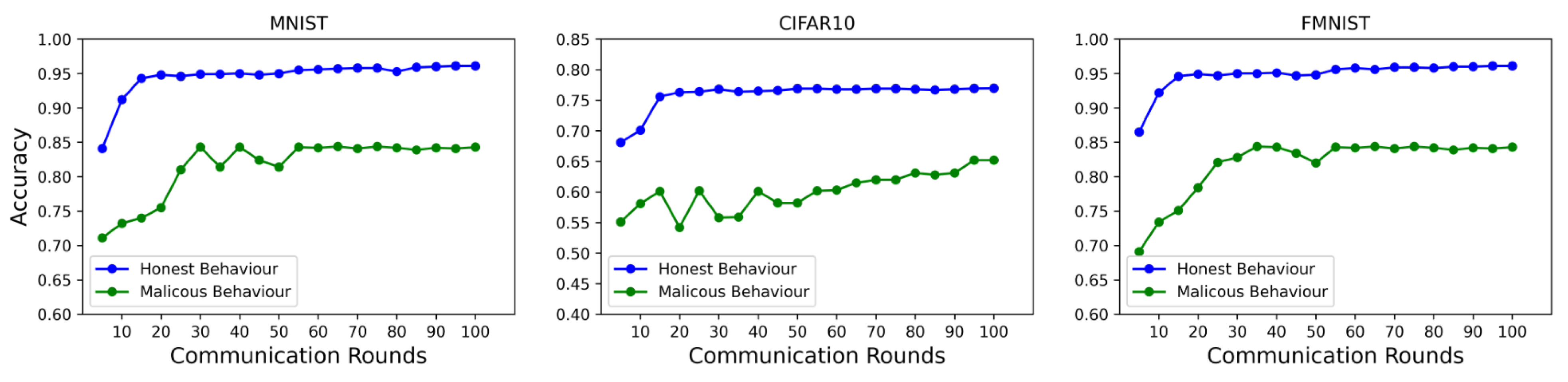
- Poison clients [42]: They perform training with some percentage of incorrect noisy labels to represent a degree of unreliability.
- Sign-flip clients [48]: They perform training with some percentage of flip labels to represent a degree of unreliability.
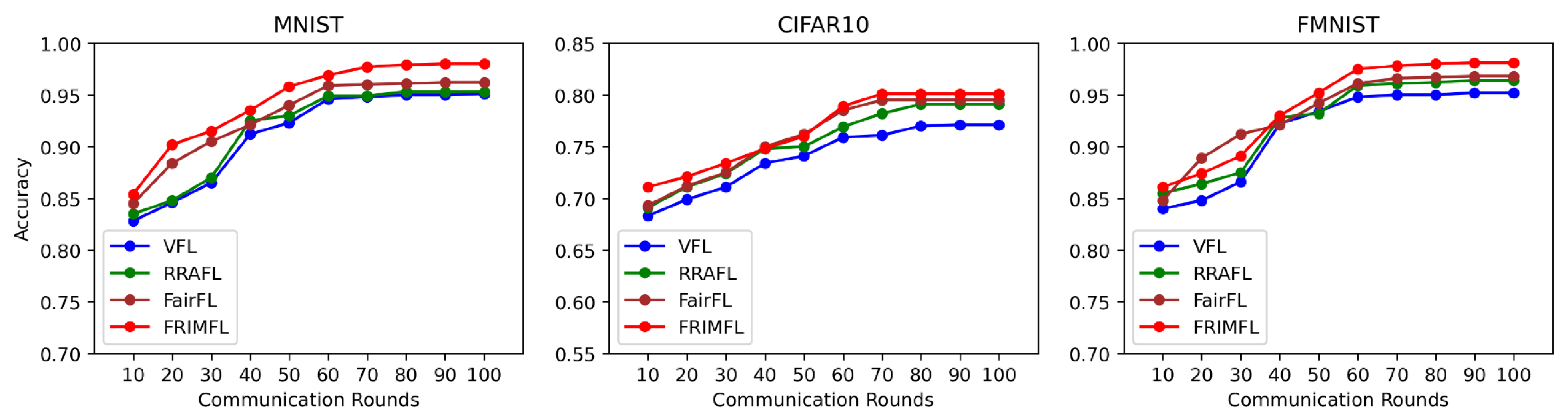
- VFL [1]: It performs standard vanilla FL to randomly select fraction n individuals and calculates aggregation weights based on local dataset sizes.
- FairFL [16]: It gives equal weights to all clients for aggregating local models.
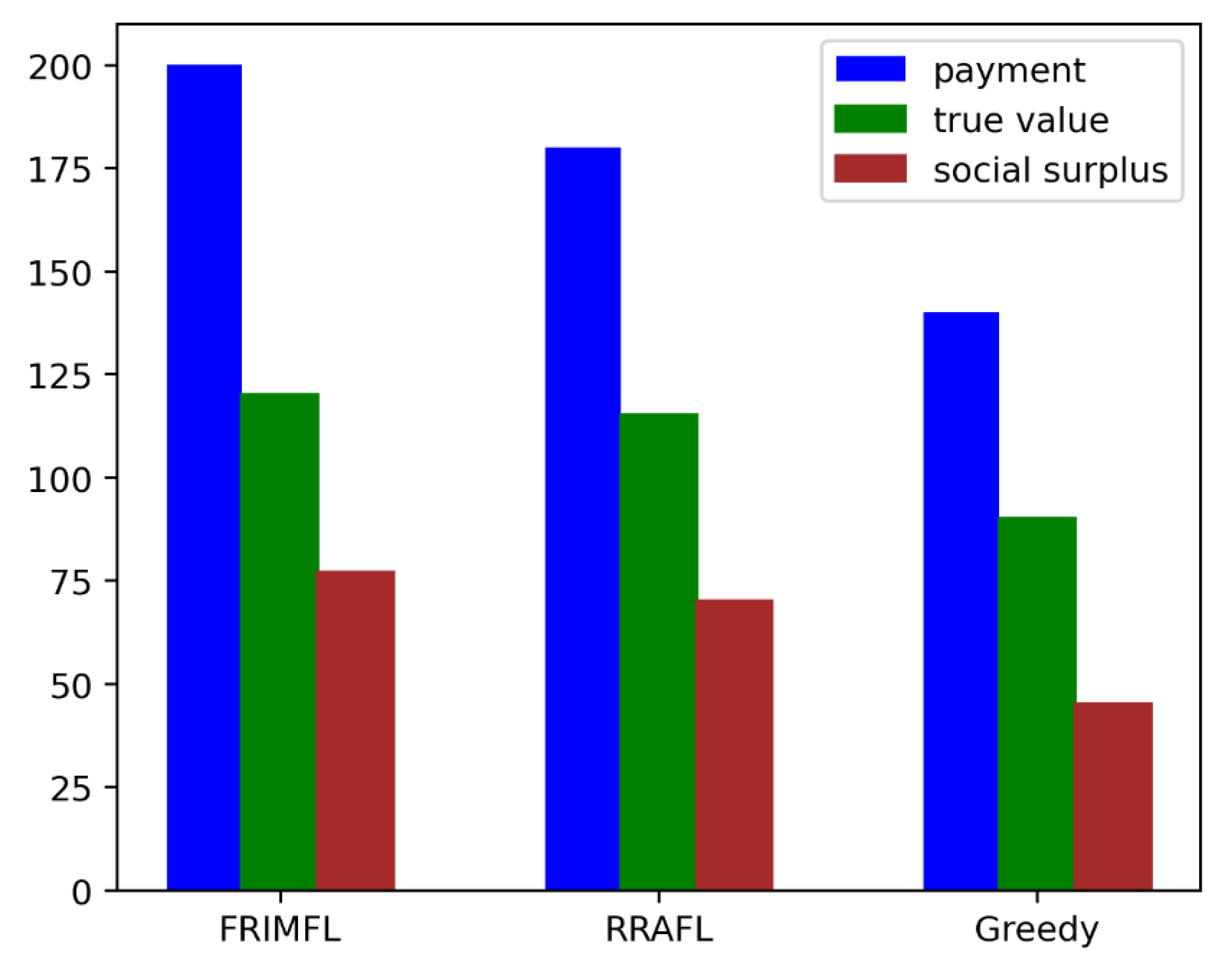
- Greedy: A mechanism always prefers candidates with lower bid prices only. It does not contain reputation and contribution assessment methods.
- RRAFL [17]: An auction and reputation (RRAFL)-based incentive scheme, primarily suited to uniform settings only. The reputation, quality-detection, and reward distributions are different from FRIMFL.
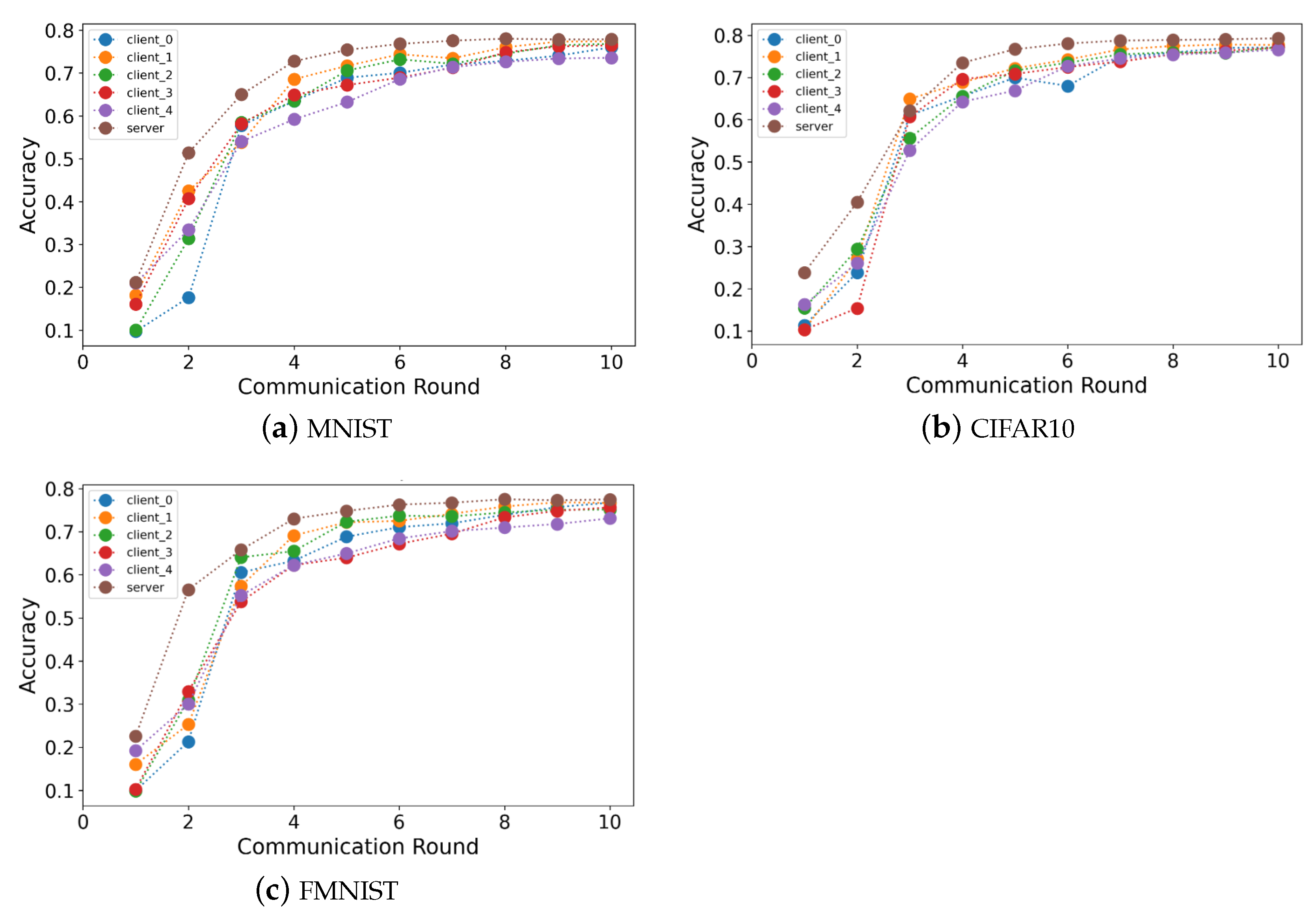
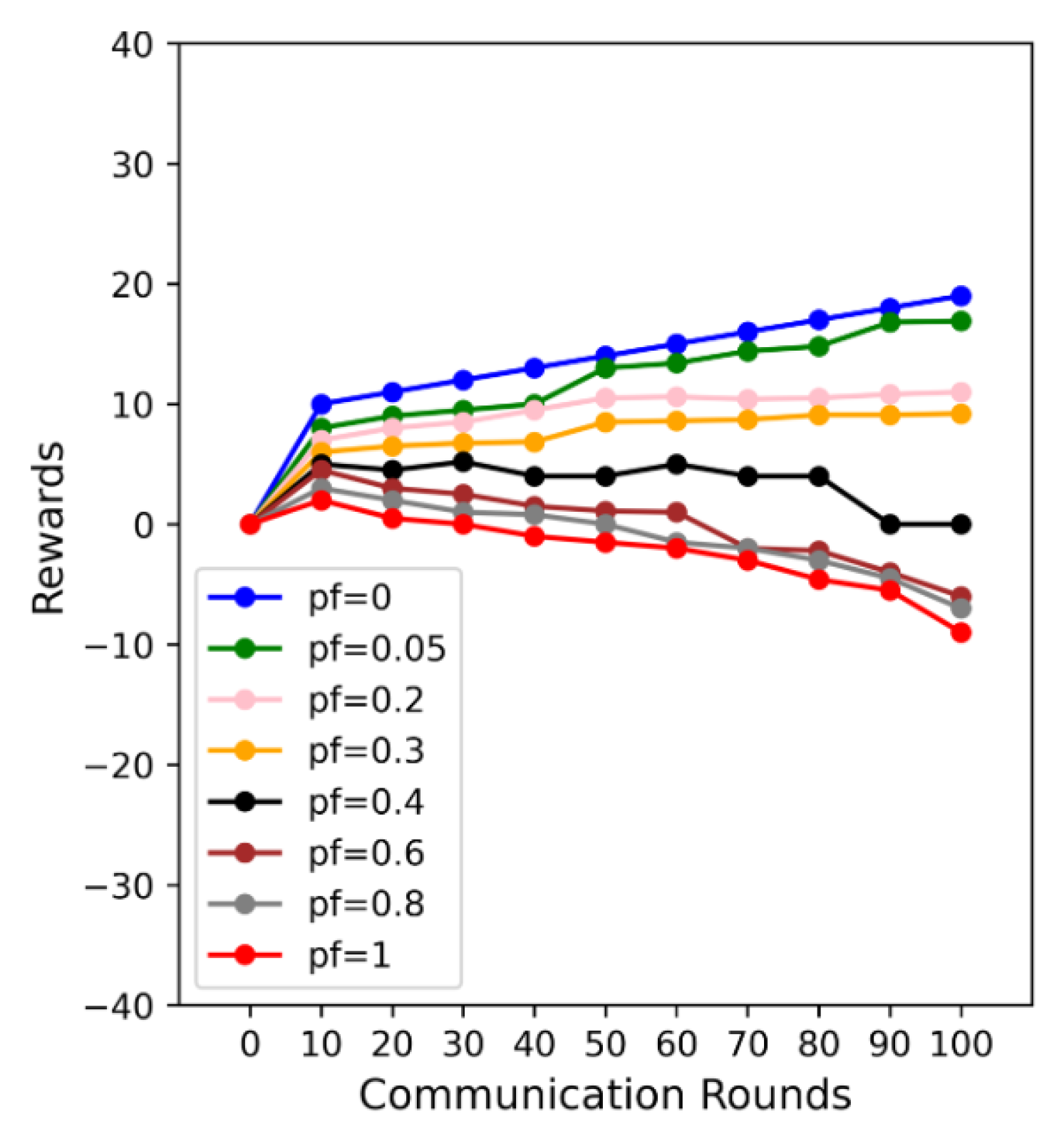
6.2. Performance of Reverse Auction
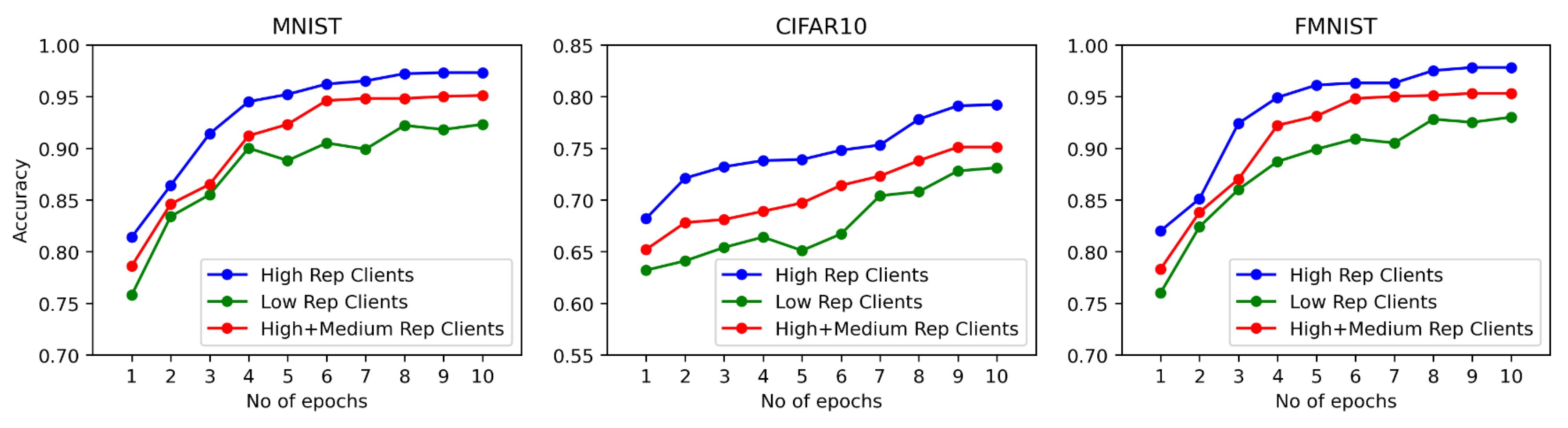
6.3. Performance of Reputation-Based Selection
6.4. Performance of Model Accuracy
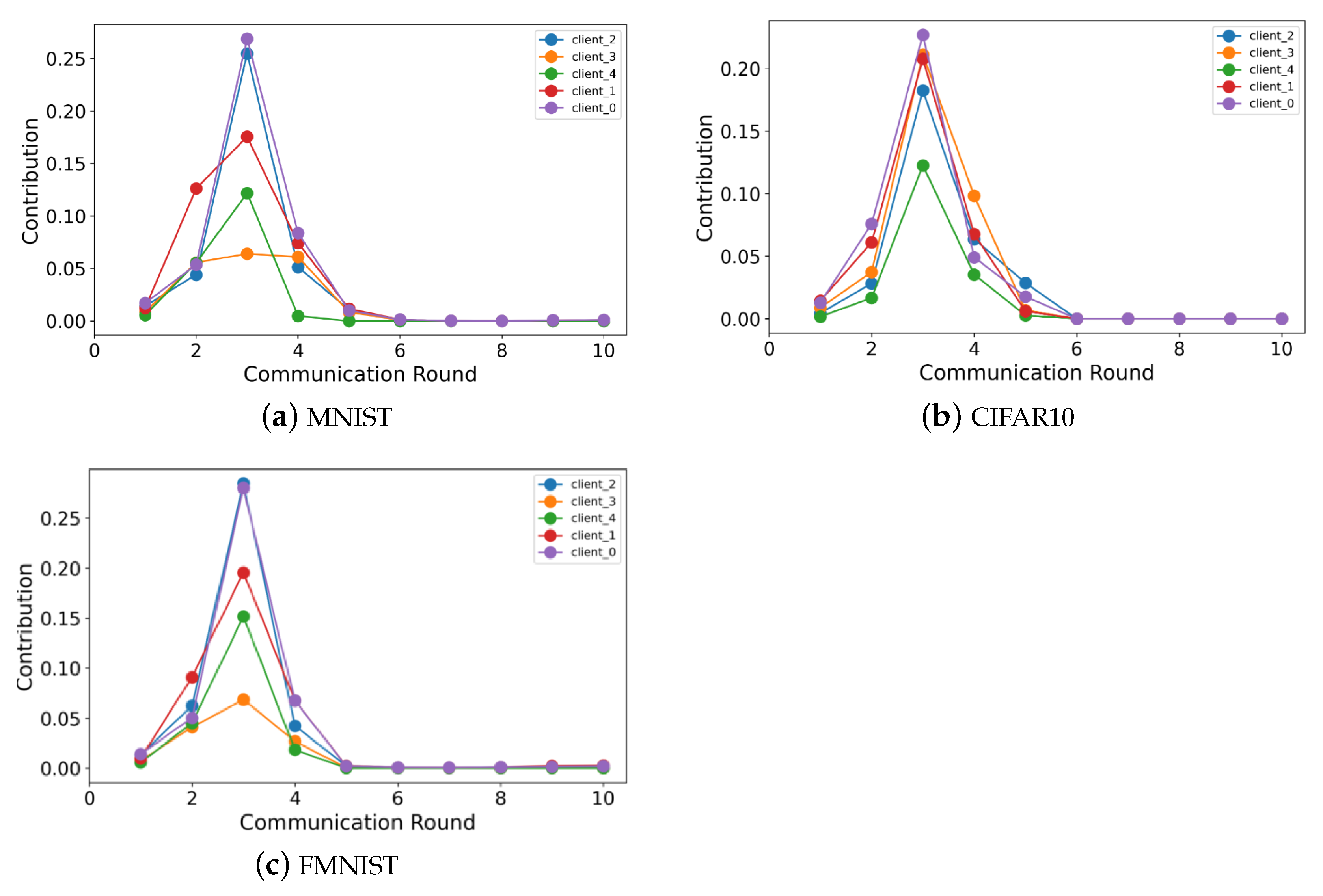
6.5. Performance of Contribution Fairness
7. Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Local model weight by participant i | |
| B | Federation budget |
| Bid price of participant i | |
| Contribution of participant i | |
| CNN | Convolutional neural network |
| DRL | Deep reinforcement learning |
| Fairness correlation coefficient | |
| FL | Federated learning |
| IC | Incentive compatibility |
| IR | Individual rationality |
| Loss of model with participant i | |
| Loss of model without participant i | |
| Number of passing detections for participant i | |
| Number of failing detections for participant i | |
| p | Data quality rate |
| Payoff of participant i | |
| Utility of participant i | |
| Record of quality detection | |
| Reward density of participant i | |
| Reputation of participant i | |
| Server i utility | |
| Social surplus | |
| Shapley value | |
| Trust on participant i | |
| Selection flag for participant i |
References
- McMahan, H.B.; Moore, E.; Ramage, D.; Arcas, B.A.Y. Federated Learning of Deep Networks using Model Averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Zhan, Y.; Zhang, J.; Hong, Z.; Wu, L.; Li, P.; Guo, S. A Survey of Incentive Mechanism Design for Federated Learning. IEEE Trans. Emerg. Top. Comput. 2022, 10, 1035–1044. [Google Scholar] [CrossRef]
- Yang, T.; Andrew, G.; Eichner, H.; Sun, H.; Li, W.; Kong, N.; Ramage, D.; Beaufays, F. Applied Federated Learning: Improving Google Keyboard Query Suggestions. arXiv 2018, arXiv:1812.02903. [Google Scholar]
- Shayan, M.; Fung, C.; Yoon, C.J.M.; Beschastnikh, I. Biscotti: A Ledger for Private and Secure Peer-to-Peer Machine Learning. arXiv 2018, arXiv:1811.09904. [Google Scholar]
- Yu, H.; Liu, Z.; Liu, Y.; Chen, T.; Cong, M.; Weng, X.; Niyato, D.T.; Yang, Q. A Fairness-aware Incentive Scheme for Federated Learning. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–8 February 2020. [Google Scholar]
- Zhou, Z.; Liu, P.; Feng, J.; Zhang, Y.; Mumtaz, S.; Rodriguez, J. Computation Resource Allocation and Task Assignment Optimization in Vehicular Fog Computing: A Contract-Matching Approach. IEEE Trans. Veh. Technol. 2019, 68, 3113–3125. [Google Scholar] [CrossRef]
- Dinh, C.T.; Tran, N.H.; Nguyen, M.N.H.; Hong, C.S.; Bao, W.; Zomaya, A.Y.; Gramoli, V. Federated Learning Over Wireless Networks: Convergence Analysis and Resource Allocation. IEEE/ACM Trans. Netw. 2021, 29, 398–409. [Google Scholar] [CrossRef]
- Yang, D.; Xue, G.; Fang, X.; Tang, J. Incentive Mechanisms for Crowdsensing: Crowdsourcing With Smartphones. IEEE/ACM Trans. Netw. 2016, 24, 1732–1744. [Google Scholar] [CrossRef]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning Attacks against Support Vector Machines. In Proceedings of the ICML, Edinburgh, UK, 26 June–1 July 2012. [Google Scholar]
- Lin, J.; Du, M.; Liu, J. Free-riders in Federated Learning: Attacks and Defenses. arXiv 2019, arXiv:1911.12560. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Nitin Bhagoji, A.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Zhang, J.; Shu, Y.; Yu, H. Fairness in Design: A Framework for Facilitating Ethical Artificial Intelligence Designs. Int. J. Crowd Sci. 2023, 7, 32–39. [Google Scholar] [CrossRef]
- Nishio, T.; Yonetani, R. Client Selection for Federated Learning with Heterogeneous Resources in Mobile Edge. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Hu, S.; Beirami, A.; Smith, V. Ditto: Fair and Robust Federated Learning Through Personalization. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020. [Google Scholar]
- Michieli, U.; Ozay, M. Are All Users Treated Fairly in Federated Learning Systems? In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 2318–2322. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, Y.; Pan, R. Incentive Mechanism for Horizontal Federated Learning Based on Reputation and Reverse Auction. In Proceedings of the Web Conference 2021 (WWW ’21), Ljubljana, Slovenia, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 947–956. [Google Scholar] [CrossRef]
- Shi, Y.; Yu, H.; Leung, C. A Survey of Fairness-Aware Federated Learning. arXiv 2021, arXiv:2111.01872. [Google Scholar]
- Zeng, R.; Zeng, C.; Wang, X.; Li, B.; Chu, X. A Comprehensive Survey of Incentive Mechanism for Federated Learning. arXiv 2021, arXiv:2106.15406. [Google Scholar]
- Kang, J.; Xiong, Z.; Niyato, D.T.; Xie, S.; Zhang, J. Incentive Mechanism for Reliable Federated Learning: A Joint Optimization Approach to Combining Reputation and Contract Theory. IEEE Internet Things J. 2019, 6, 10700–10714. [Google Scholar]
- Kang, J.; Xiong, Z.; Niyato, D.; Yu, H.; Liang, Y.C.; Kim, D.I. Incentive Design for Efficient Federated Learning in Mobile Networks: A Contract Theory Approach. In Proceedings of the 2019 IEEE VTS Asia Pacific Wireless Communications Symposium (APWCS), Singapore, 28–30 August 2019; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Ye, D.; Yu, R.; Pan, M.; Han, Z. Federated Learning in Vehicular Edge Computing: A Selective Model Aggregation Approach. IEEE Access 2020, 8, 23920–23935. [Google Scholar] [CrossRef]
- Ezzeldin, Y.H.; Yan, S.; He, C.; Ferrara, E.; Avestimehr, A.S. FairFed: Enabling Group Fairness in Federated Learning. Proc. AAAI Conf. Artif. Intell. 2023, 37, 7494–7502. [Google Scholar] [CrossRef]
- Horváth, S.; Laskaridis, S.; Almeida, M.; Leontiadis, I.; Venieris, S.; Lane, N. FjORD: Fair and Accurate Federated Learning under heterogeneous targets with Ordered Dropout. In Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 12876–12889. [Google Scholar]
- Zhang, J.; Li, C.; Robles-Kelly, A.; Kankanhalli, M. Hierarchically Fair Federated Learning. arXiv 2020, arXiv:2004.10386. [Google Scholar]
- Lyu, L.; Yu, J.; Nandakumar, K.; Li, Y.; Ma, X.; Jin, J.; Yu, H.; Ng, K.S. Towards Fair and Privacy-Preserving Federated Deep Models. IEEE Trans. Parallel Distrib. Syst. 2019, 31, 2524–2541. [Google Scholar] [CrossRef]
- Thi Le, T.H.; Tran, N.H.; Tun, Y.K.; Nguyen, M.N.H.; Pandey, S.R.; Han, Z.; Hong, C.S. An Incentive Mechanism for Federated Learning in Wireless Cellular Networks: An Auction Approach. IEEE Trans. Wirel. Commun. 2021, 20, 4874–4887. [Google Scholar] [CrossRef]
- Cong, M.; Yu, H.; Weng, X.; Qu, J.; Liu, Y.; Yiu, S.M. A VCG-based Fair Incentive Mechanism for Federated Learning. arXiv 2020, arXiv:2008.06680. [Google Scholar]
- Zeng, R.; Zhang, S.; Wang, J.; Chu, X. FMore: An Incentive Scheme of Multi-dimensional Auction for Federated Learning in MEC. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 278–288. [Google Scholar] [CrossRef]
- Rehman, M.H.; Salah, K.; Damiani, E.; Svetinovic, D. Towards Blockchain-Based Reputation-Aware Federated Learning. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 183–188. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.S.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Pandey, S.R.; Nguyen, L.D.; Popovski, P. FedToken: Tokenized Incentives for Data Contribution in Federated Learning. arXiv 2022, arXiv:2209.09775. [Google Scholar] [CrossRef]
- Deng, Y.; Lyu, F.; Ren, J.; Chen, Y.C.; Yang, P.; Zhou, Y.; Zhang, Y. FAIR: Quality-Aware Federated Learning with Precise User Incentive and Model Aggregation. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–12 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Ding, N.; Fang, Z.; Huang, J. Incentive Mechanism Design for Federated Learning with Multi-Dimensional Private Information. In Proceedings of the 2020 18th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOPT), Volos, Greece, 15–19 June 2020; pp. 1–8. [Google Scholar]
- Feng, S.; Niyato, D.T.; Wang, P.; Kim, D.I.; Liang, Y.C. Joint Service Pricing and Cooperative Relay Communication for Federated Learning. In Proceedings of the 2019 International Conference on Internet of Things (Things) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Halifax, NS, Canada, 30 July–3 August 2018; pp. 815–820. [Google Scholar]
- Weng, J.; Weng, J.; Zhang, J.; Li, M.; Zhang, Y.; Luo, W. DeepChain: Auditable and Privacy-Preserving Deep Learning with Blockchain-Based Incentive. IEEE Trans. Dependable Secur. Comput. 2021, 18, 2438–2455. [Google Scholar] [CrossRef]
- Bao, X.; Su, C.; Xiong, Y.; Huang, W.; Hu, Y. FLChain: A Blockchain for Auditable Federated Learning with Trust and Incentive. In Proceedings of the 2019 5th International Conference on Big Data Computing and Communications (BIGCOM), Qingdao, China, 9–11 August 2019; pp. 151–159. [Google Scholar] [CrossRef]
- Le, T.H.T.; Tran, N.H.; Tun, Y.K.; Han, Z.; Hong, C.S. Auction based Incentive Design for Efficient Federated Learning in Cellular Wireless Networks. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Republic of Korea, 25–28 May 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Qi, J.; Zhou, Q.; Lei, L.; Zheng, K. Federated Reinforcement Learning: Techniques, Applications, and Open Challenges. arXiv 2021, arXiv:2108.11887. [Google Scholar] [CrossRef]
- Zhan, Y.; Li, P.; Qu, Z.; Zeng, D.; Guo, S. A Learning-Based Incentive Mechanism for Federated Learning. IEEE Internet Things J. 2020, 7, 6360–6368. [Google Scholar] [CrossRef]
- Zhan, Y.; Zhang, J. An Incentive Mechanism Design for Efficient Edge Learning by Deep Reinforcement Learning Approach. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 2489–2498. [Google Scholar] [CrossRef]
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data Poisoning Attacks Against Federated Learning Systems. In Proceedings of the ESORICS, Guildford, UK, 14–18 September 2020. [Google Scholar]
- Shejwalkar, V.; Houmansadr, A. Manipulating the Byzantine: Optimizing Model Poisoning Attacks and Defenses for Federated Learning. In Proceedings of the NDSS, Virtually, 21–25 February 2021. [Google Scholar]
- Wang, G.; Dang, C.X.; Zhou, Z. Measure Contribution of Participants in Federated Learning. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2597–2604. [Google Scholar] [CrossRef] [Green Version]
- Deng, L. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Fung, C.; Yoon, C.J.M.; Beschastnikh, I. The Limitations of Federated Learning in Sybil Settings. In Proceedings of the International Symposium on Recent Advances in Intrusion Detection, San Sebastian, Spain, 14–18 October 2020. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Client | 1-2-3 | 1-3-2 | 2-1-3 | 2-3-1 | 3-1-2 | 3-2-1 | SV |
|---|---|---|---|---|---|---|---|
| 1 | 40 | 40 | 10 | 5 | 0 | 5 | 16.67 |
| 2 | 30 | 15 | 60 | 60 | 10 | 5 | 30 |
| 3 | 20 | 35 | 20 | 25 | 80 | 80 | 20 |
| Parameter | Value |
|---|---|
| Number of participants (n) | 5–20 |
| Bid price () | 5–10 |
| Budget (B) | 100–300 |
| Learning rate () | 0.05 |
| Batch size () | 100 |
| Loss quality threshold () | −0.03 |
| 1 | 0.8 | 0.7 | 0.6 | |||||
|---|---|---|---|---|---|---|---|---|
| Dataset | RRAFL | FRIMFL | RRAFL | FRIMFL | RRAFL | FRIMFL | RRAFL | FRIMFL |
| MNIST | 0.965 | 0.974 | 0.698 | 0.742 | 0.588 | 0.635 | 0.431 | 0.508 |
| CIFAR10 | 0.951 | 0.959 | 0.638 | 0.711 | 0.504 | 0.601 | 0.416 | 0.494 |
| FMNIST | 0.962 | 0.970 | 0.664 | 0.737 | 0.581 | 0.640 | 0.425 | 0.510 |
| Dataset | VFL | Greedy | RRAFL | FRIMFL |
|---|---|---|---|---|
| MNIST | 0.61 | 0.41 | 0.93 | 0.95 |
| CIFAR10 | 0.62 | 0.40 | 0.92 | 0.94 |
| FMNIST | 0.61 | 0.41 | 0.92 | 0.95 |
| MNIST | CIFAR10 | FMNIST | ||||
|---|---|---|---|---|---|---|
| Scheme | UNI | IMB | UNI | IMB | UNI | IMB |
| RRAFL | 0.989 | 0.972 | 0.979 | 0.960 | 0.987 | 0.973 |
| FRIMFL | 0.992 | 0.988 | 0.985 | 0.973 | 0.993 | 0.986 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed , A.; Choi , B.J. FRIMFL: A Fair and Reliable Incentive Mechanism in Federated Learning. Electronics 2023, 12, 3259. https://doi.org/10.3390/electronics12153259
Ahmed A, Choi BJ. FRIMFL: A Fair and Reliable Incentive Mechanism in Federated Learning. Electronics. 2023; 12(15):3259. https://doi.org/10.3390/electronics12153259
Chicago/Turabian StyleAhmed , Abrar, and Bong Jun Choi . 2023. "FRIMFL: A Fair and Reliable Incentive Mechanism in Federated Learning" Electronics 12, no. 15: 3259. https://doi.org/10.3390/electronics12153259