1. Introduction
The annual ring is the concentric ring pattern on the transverse section of a woody plant stem, along with the growth of the wood cambium year by year. The annual ring is an important basis for recording the growth years of trees [
1,
2]. It contains a wealth of information on climate [
3,
4,
5], history [
6,
7,
8], environment [
9,
10], and medicine [
11]. Accurate segmentation is a prerequisite for recording, statistics, and analysis of annual rings, so an intelligent method for accurate segmentation should be proposed as an important research topic in forestry science.
The traditional method of annual rings segmentation requires a specialized equipment consisting of a stereoscope, a mobile table, and a data logger. The advantage of this method is the accuracy of the results, and the disadvantage is that it is time-consuming and has low efficiency [
12]. With the application of computer vision and image processing technology in the field of wood science, researchers have proposed a series of methods for wood annual rings segmentation. Ning Xiao et al. (2018) [
13] constructed a pixel classifier, which is based on a random forest algorithm, for early wood and late wood segmentation of red pine, and the segmentation results meet the needs of annual rings counting and spacing measurements. Since the transverse section of the wood used in the experiment is free of defects such as knots and wormholes, the anti-interference ability of the method is to be verified. Cheng Yuzhu et al. (2018) [
14] proposed an algorithm for wood annual rings image detection based on texture features. The algorithm removes the noise from the grayscale image of texture features and extracts the boundary target of annual rings by the Total Variation (TV) filtering algorithm as well as the Fuzzy Region Competition (FRC) model. Although the method has good noise immunity, it is not suitable for boundary locating of annual rings and extracting texture features for different tree species or gradient directions.
Since the AlexNet deep learning network model proposed by Krizhevsky et al. won the ImageNet competition in 2012 [
15], convolutional neural networks (CNNs) have gradually gained significant attention in the field of computer vision. Classical network models have been improved and optimized by researchers and applied to different fields. Long et al. (2014) [
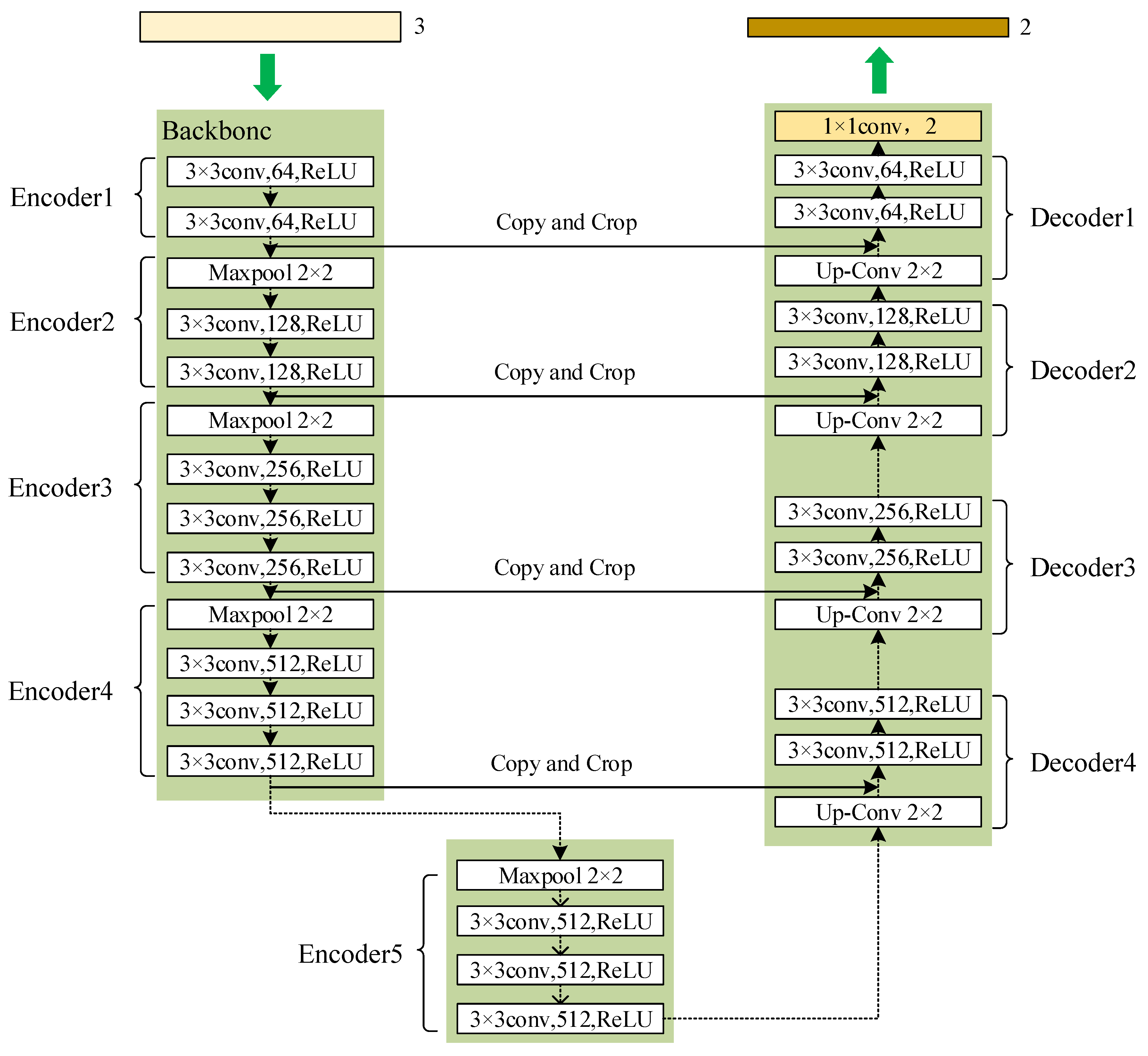
16] proposed fully convolutional networks (FCNs), which improve CNNs by replacing the fully connected layer with a convolutional layer, but this model lacks the utilization of holistic information. Ronneberger et al. (2016) proposed the U-Net model based on the improved FCN [
17]. The model achieves good segmentation performance through a small number of labeled images and is widely applied in biomedical fields [
18,
19] such as retinal vessel segmentation [
20] and cell boundary segmentation [
21]. Zhou et al. (2018) [
22] redesigned the jump path based on U-Net for reducing the semantic gap between the feature mapping of encoder and decoder. U-Net++ with deep supervision was obtained and tested in the field of medical image segmentation, such as chest nodules and liver segmentation, and the segmentation performance was better than U-Net. Zhijun Gao et al. (2020) [
23] redesigned convolutional blocks based on U-Net++ and used Deep Residual Nets (ResNet) as the backbone to segment the retinal macular edema region. The round holes as well as the cracked voids located around the segmentation target are very similar to the wormholes and cracks in computed tomography (CT) images of wood. Huang Hong et al. (2021) [
24] proposed an adaptive weighted aggregation method based on U-Net++ in order to solve the boundary segmentation problem of lung CT images in complex scenes. This method provides the basis for the application of U-Net series networks for wood CT images.
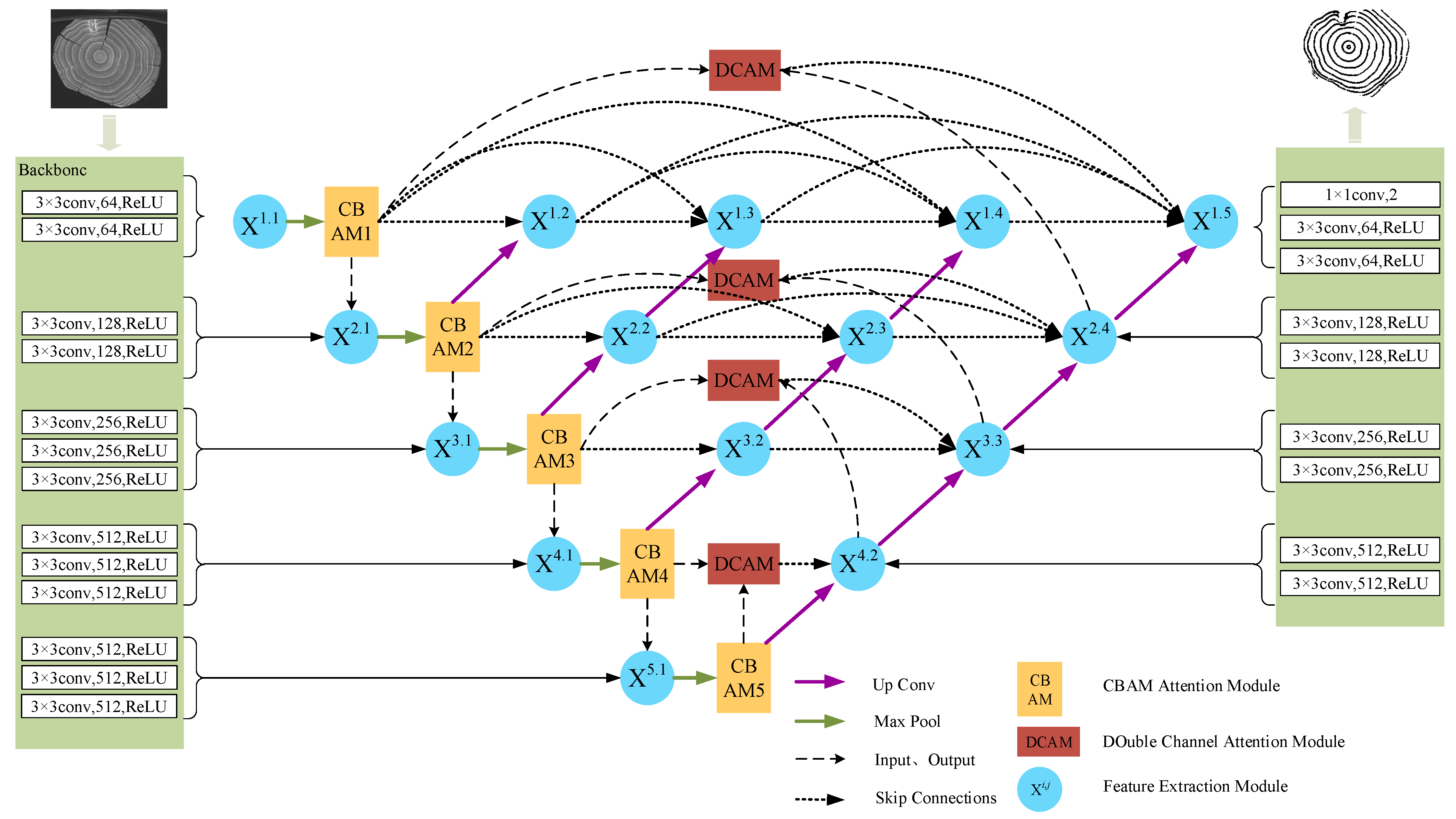
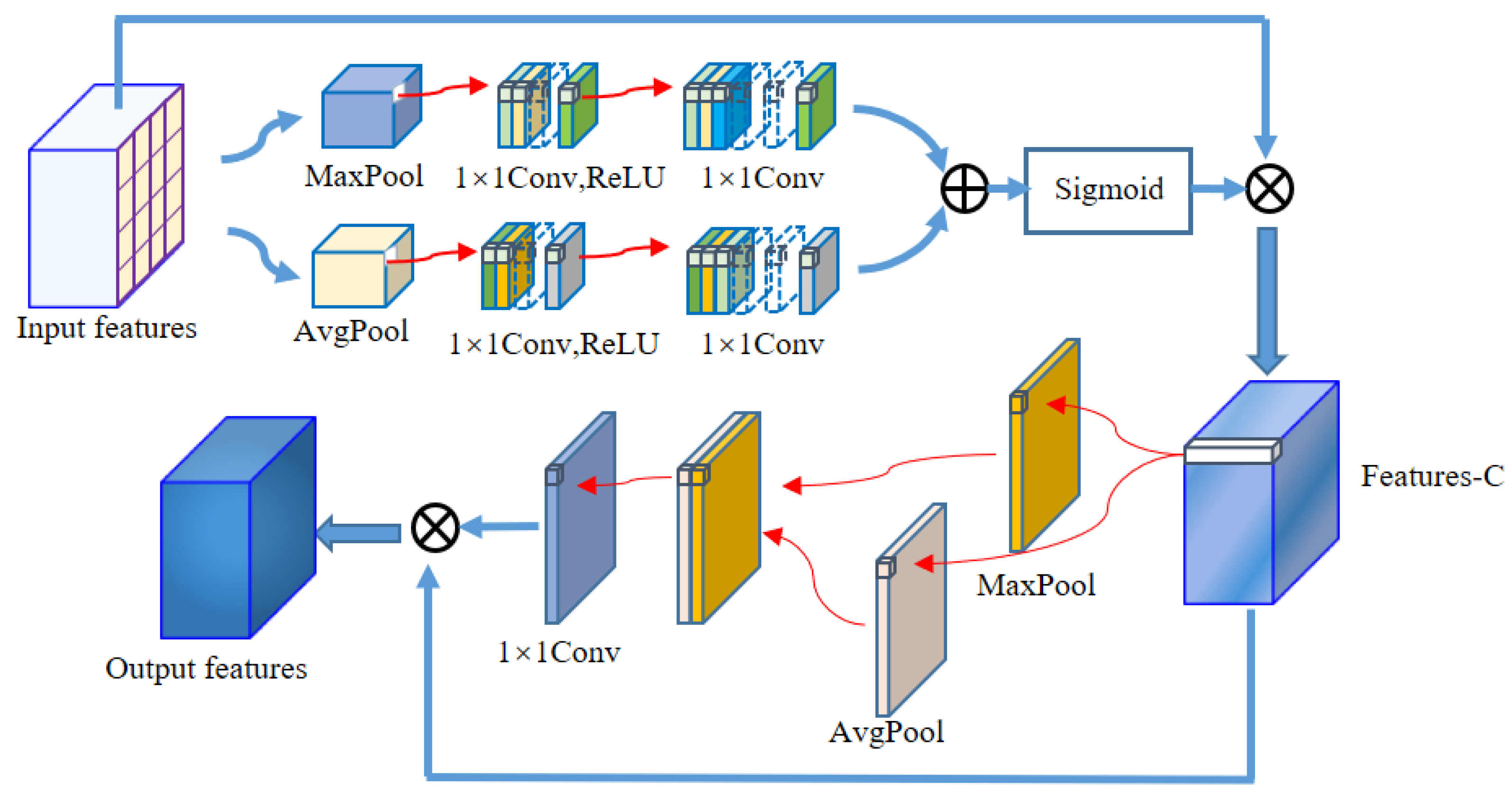
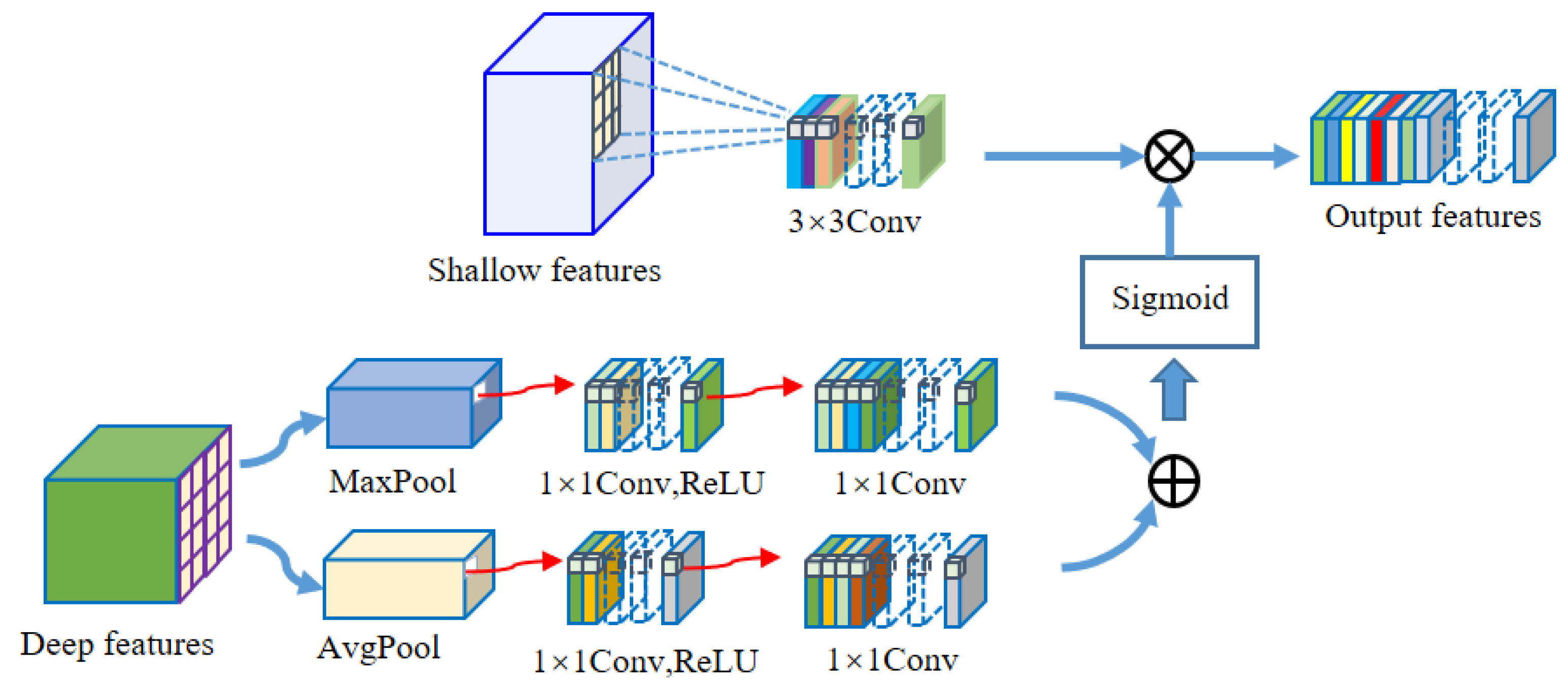
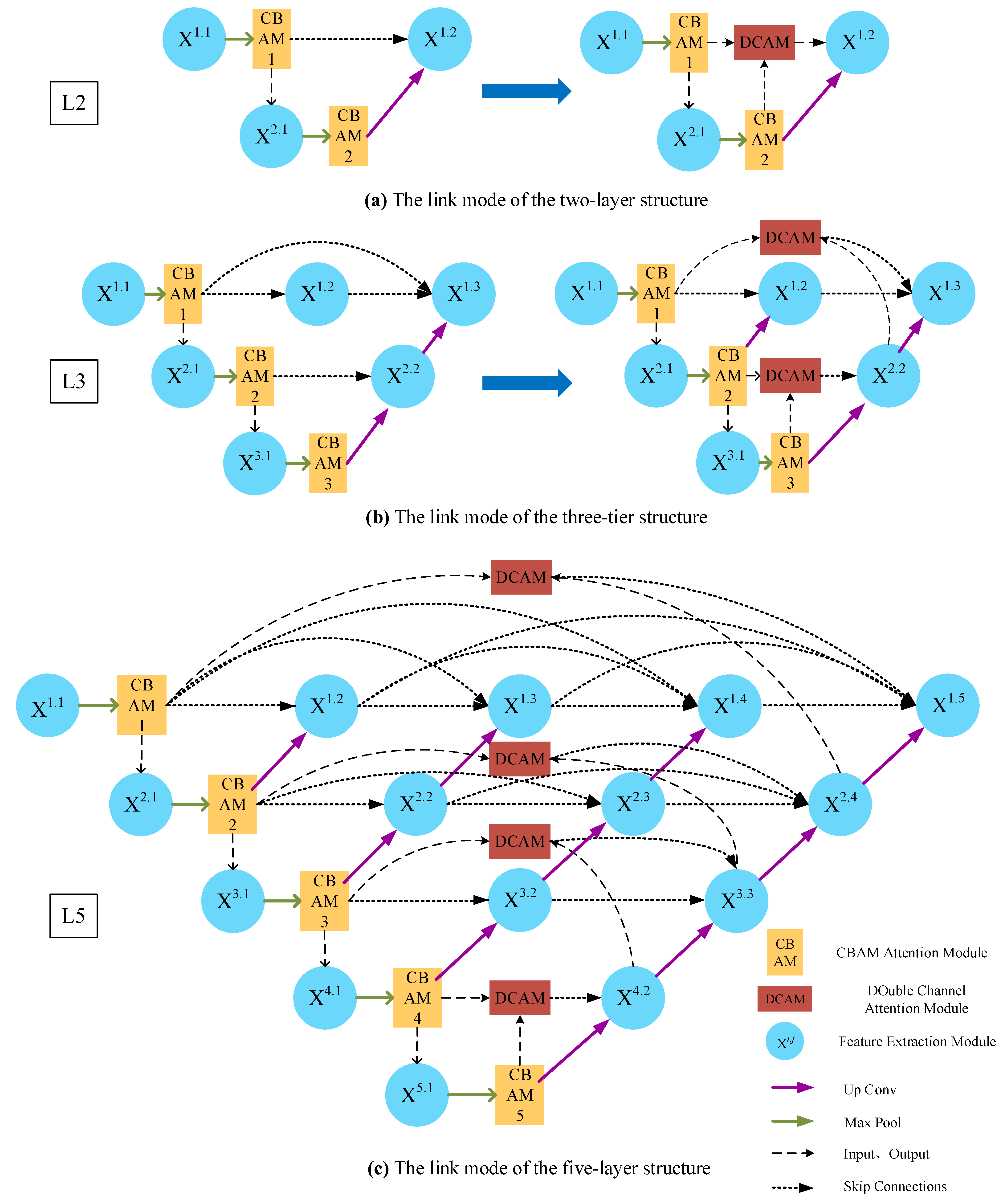
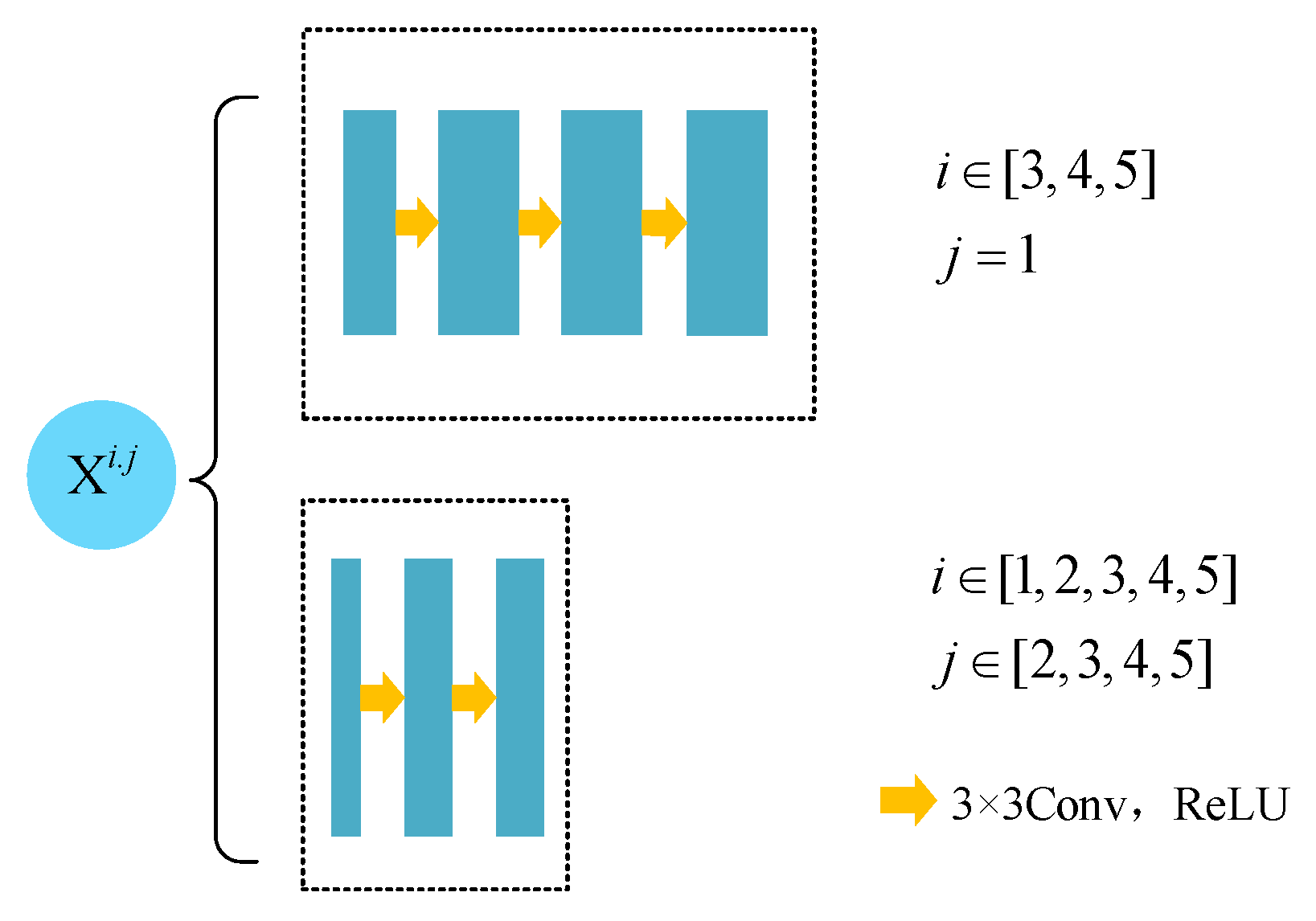
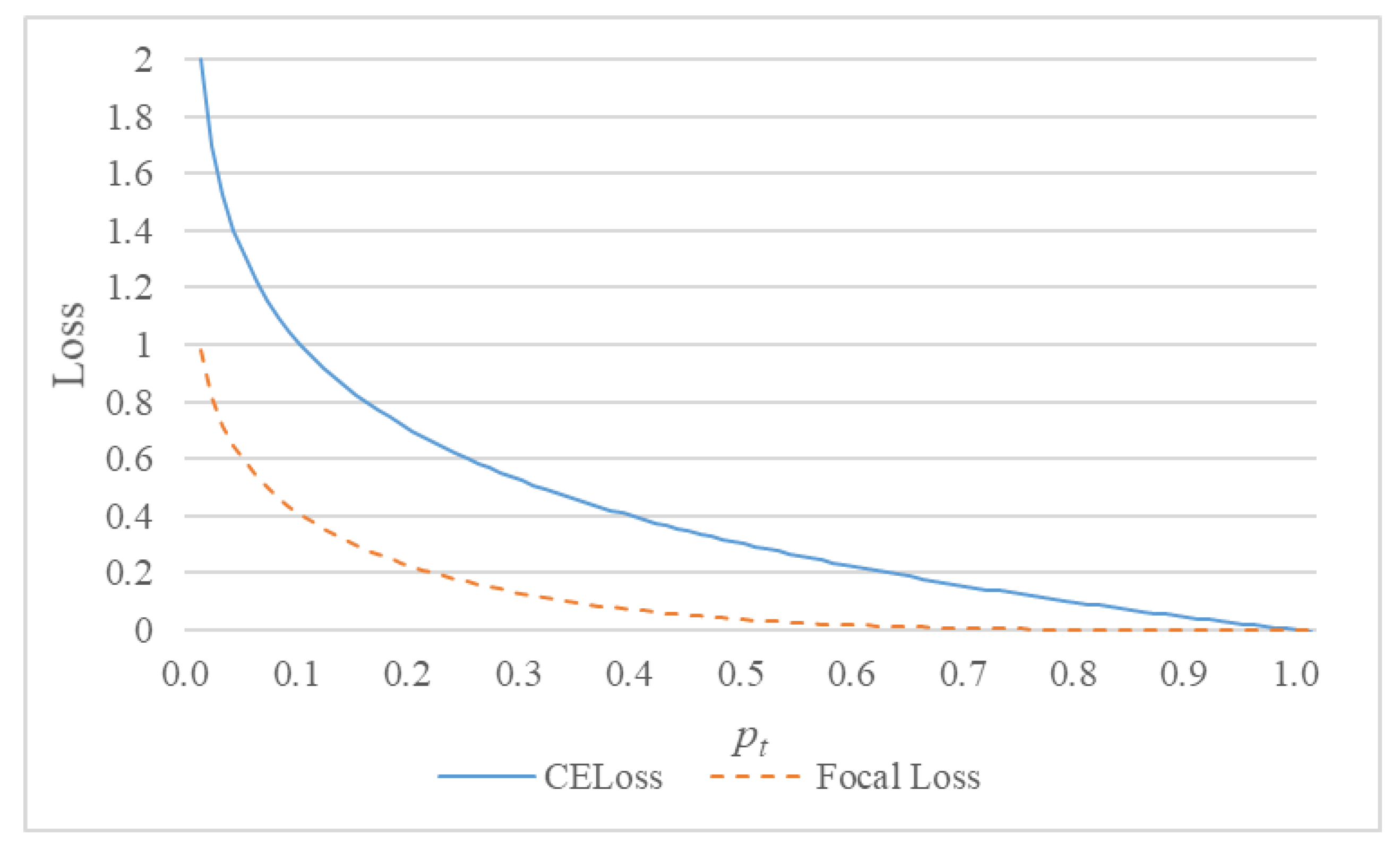
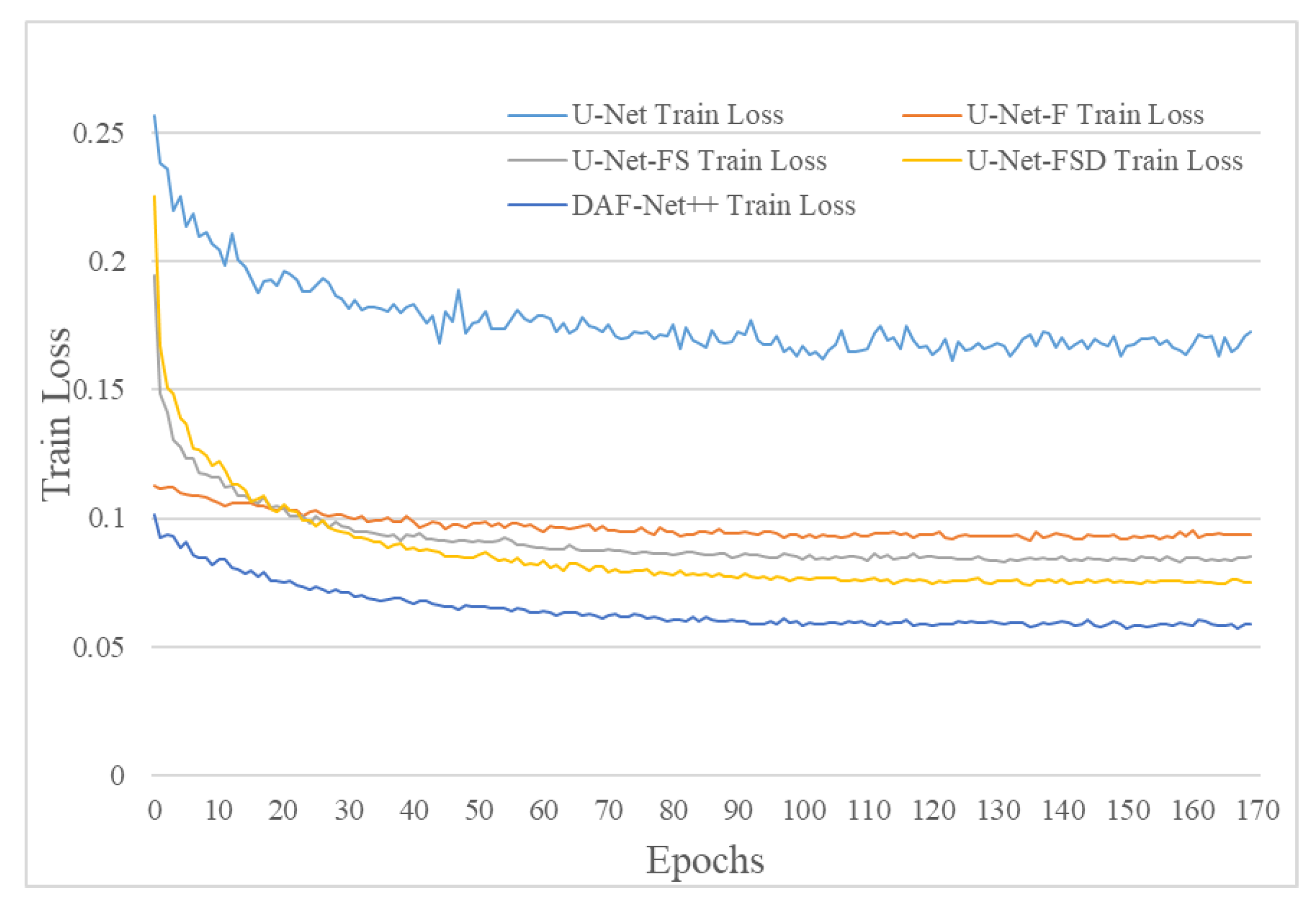
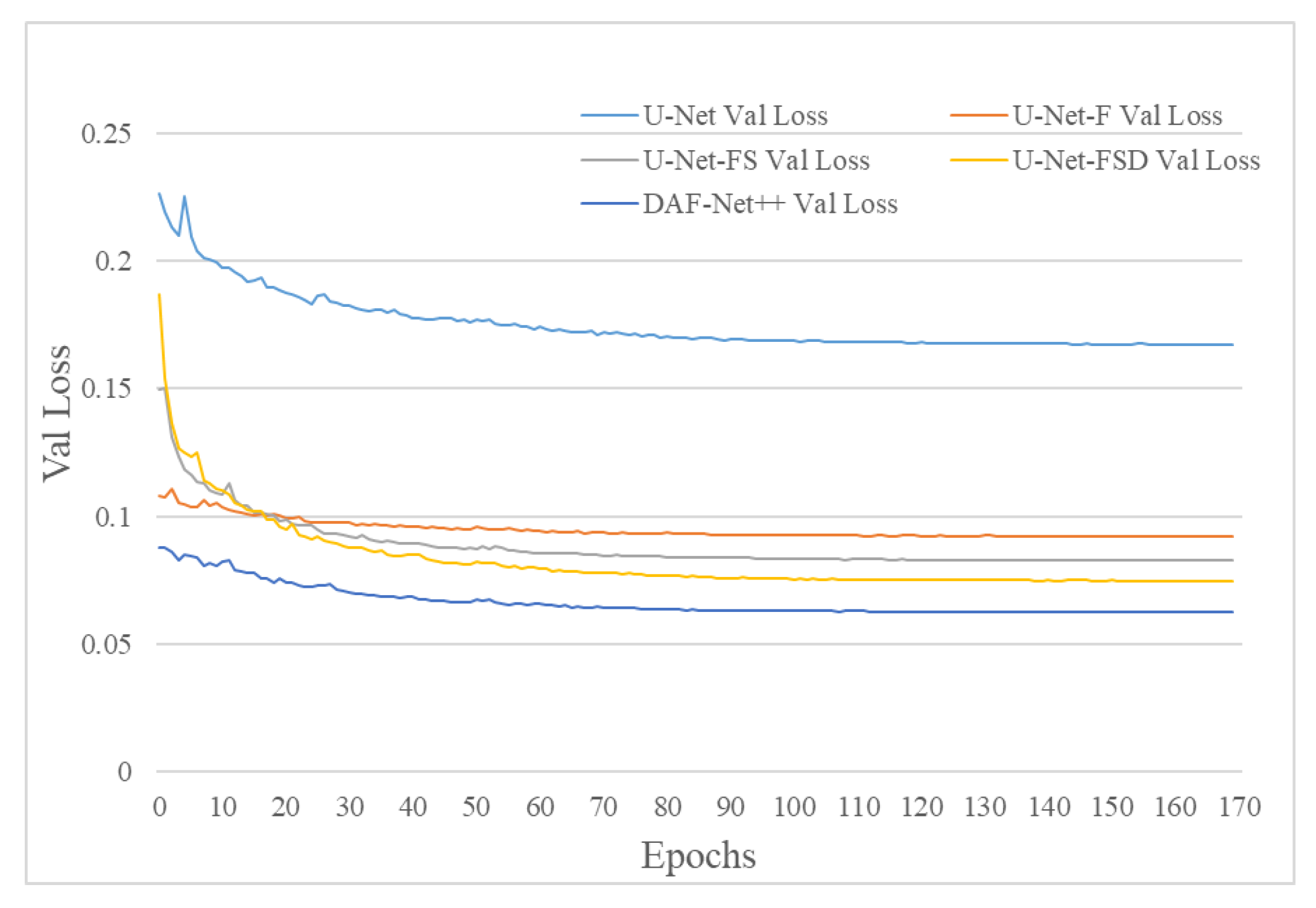
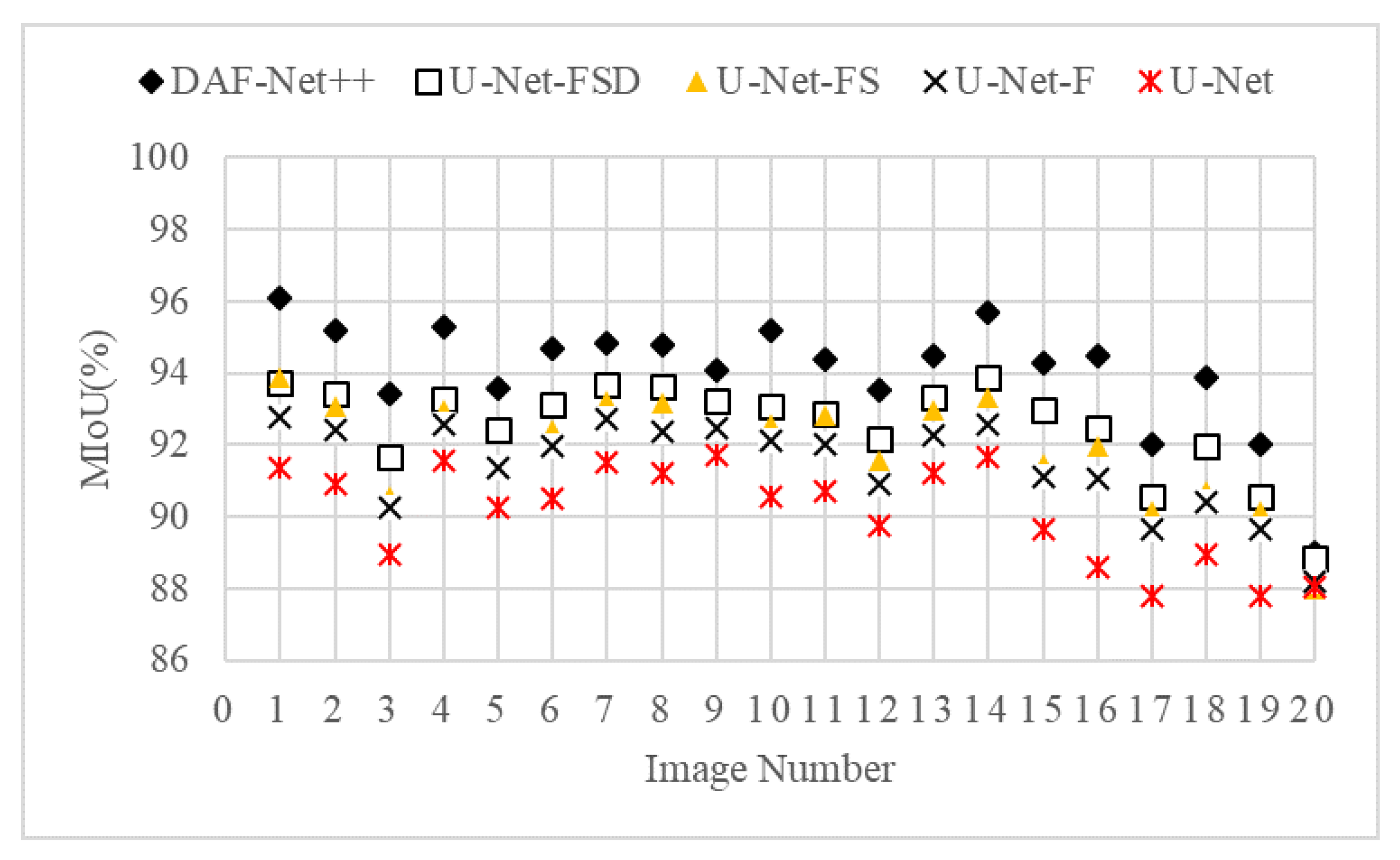
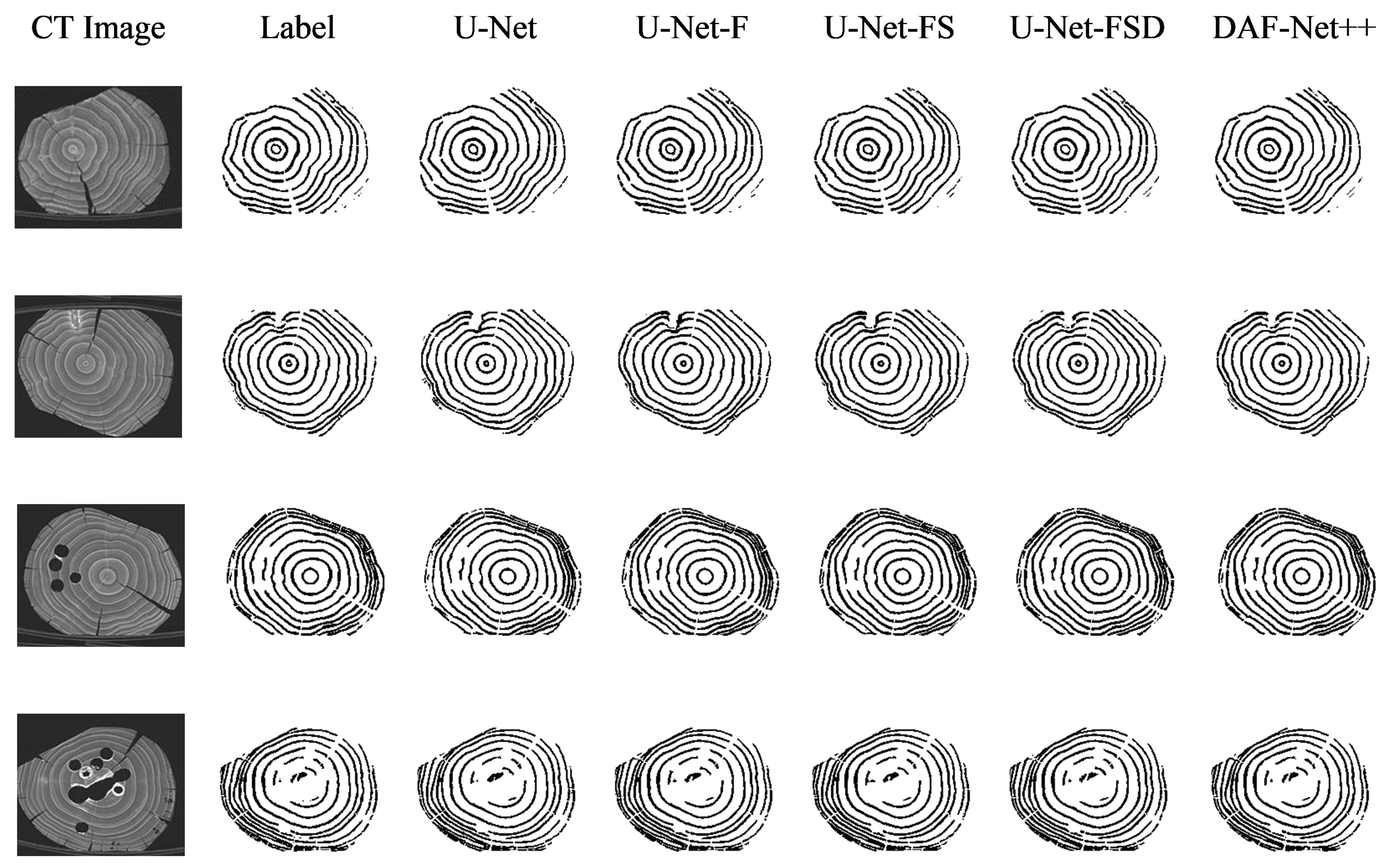
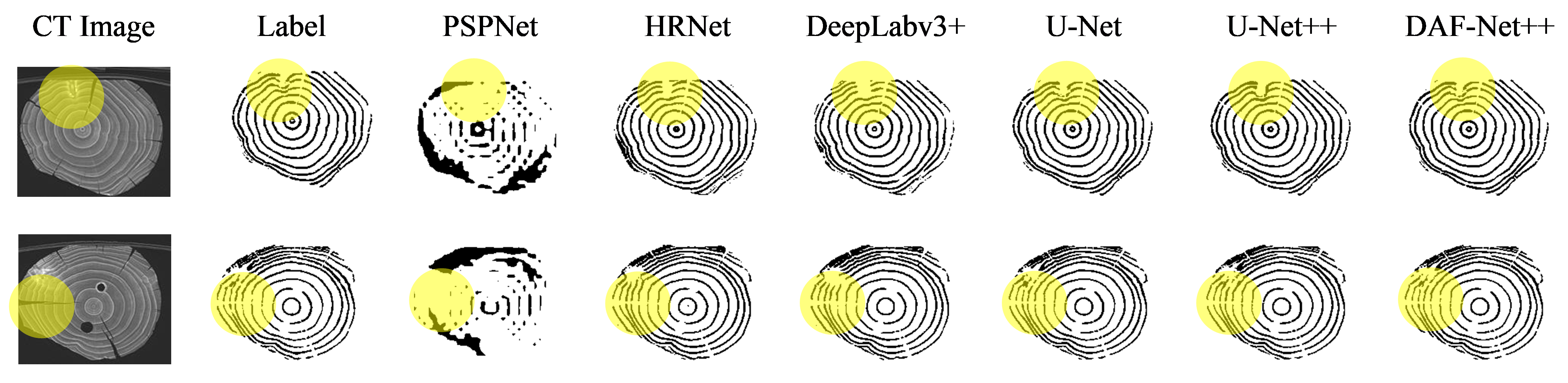
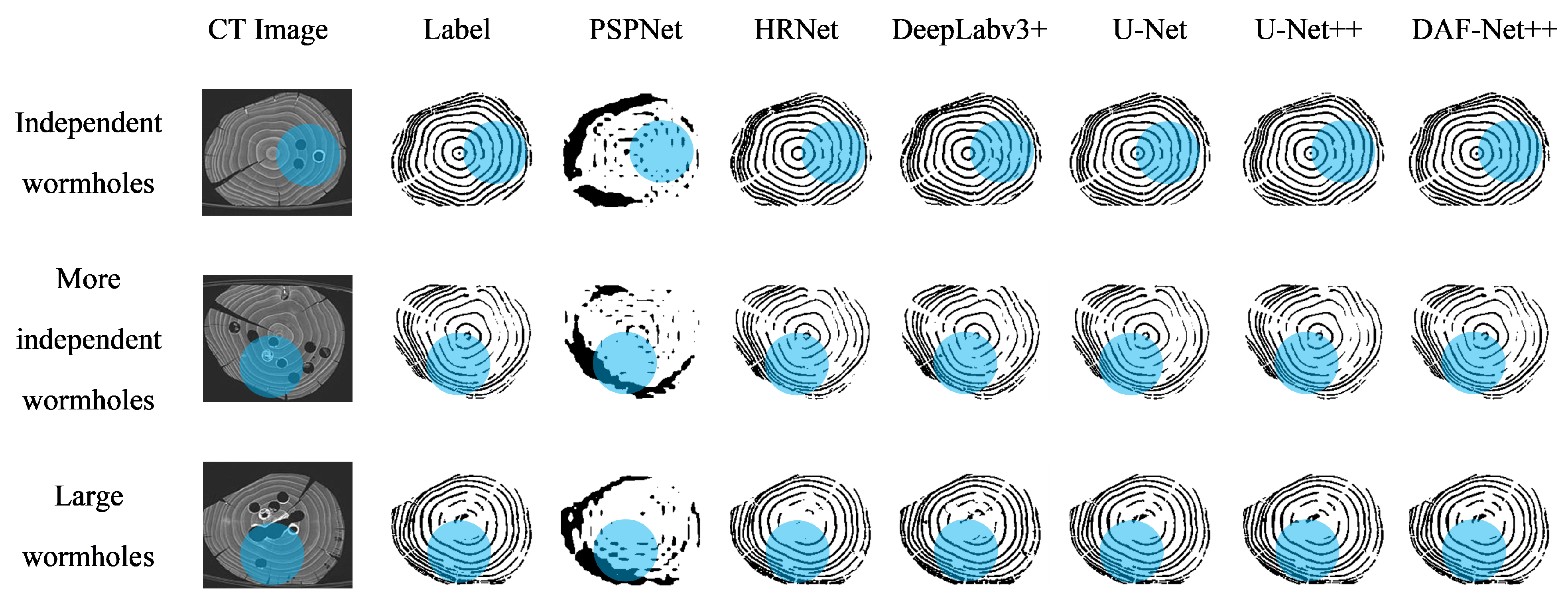
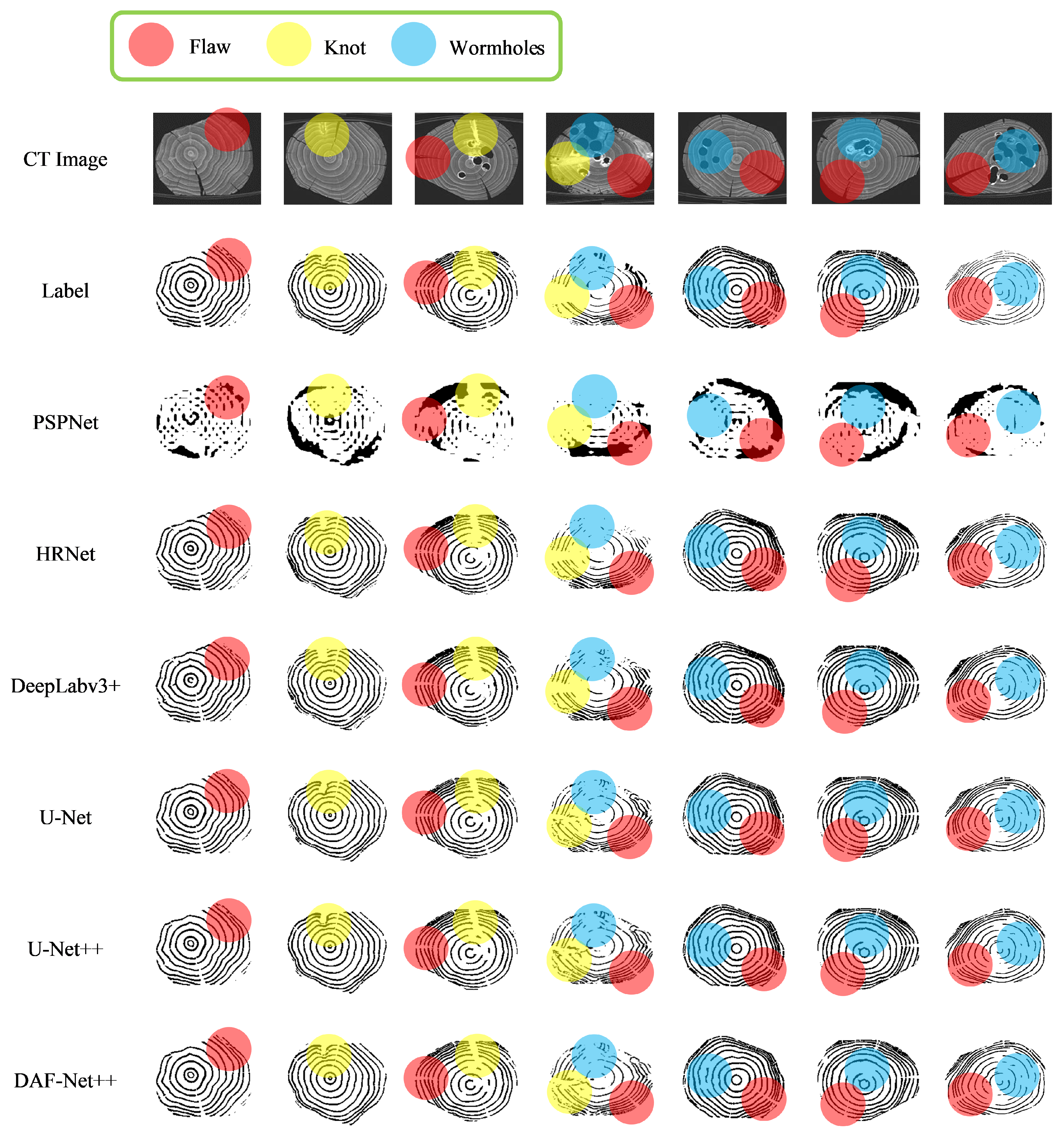
For the imbalance of positive and negative samples, we propose a model which uses dense jump links, attention mechanism, and Focal Loss (DAF-Net++). The model is constructed on U-Net with VGG16 (Visual Geometry Group, VGGNet with 16 layers) as the backbone network [
25]. Dense jump links are redesigned in order to effectively fuse feature information and reduce the semantic divide. Deep and shallow features are fused by two different attention mechanisms. In addition to this, the Focal Loss [
26] method is introduced to the calculation of loss values. Training and test images of transverse sections of fir trees were compared with those of classical semantic segmentation models such as U-Net, UNet++, and DeepLabv3+. The Mean Intersection over Union (MIOU), Mean Pixel Accuracy (MPA), Pixel Accuracy (PA), and Recall of the segmented images using DAF-Net++ were higher than the classical semantic segmentation models. The results show that the DAF-Net++ proposed in this paper can effectively overcome the interference such as wormholes, nodes, cracks, etc., and is more suitable for binary classification problems with large positive and negative sample bias such as annual rings segmentation.
2. Related Work
Currently, semantic segmentation algorithms are widely used in various fields, such as medicine and geology. Related researchers have proposed different improvements for semantic segmentation algorithms. Wang Wenguan et al. (2021) [
27] proposed a pixel comparison algorithm for semantic segmentation in a fully supervised environment. The method investigates the global semantic relations between pixels and has the complementary advantages of unary classification as well as structured metric learning. Available semantic segmentation algorithms are easily applied. It is a paradigm for pixel-by-pixel metric learning, which has a wide range of application prospects. However, because there are fewer pixels in the annual rings and more pixels in the background, this method is not applicable to the task of segmenting annual rings. Zhou Tianfei et al. (2022) [
28] proposed a regional semantic comparison as well as aggregation (RCA) method with a regional memory library, whose superiority lies in its ability to obtain rich contextual semantic information using a large amount of weakly labeled training data. Excellent results were achieved in experiments on several public datasets. But the method requires a large number of datasets and is not suitable for the segmentation task of annual rings. Zhou Tianfei et al. (2022) [
29] proposes a nonparametric alternative based on a non-learnable prototype. The method is able to directly shape pixels and embed them into corresponding positions to complete segmentation. Using such a nonparametric alternative means that the method has excellent generalization ability and breaks the limitation of parametric learning of traditional semantic segmentation models. However, this method is not applicable to this study due to the morphological characteristics of wood annual rings.
Although there are abundant studies on semantic segmentation algorithms, there are relatively few studies on semantic segmentation of CT images of wood annual rings and the segmentation results are mostly unsatisfactory. Fabijańska et al. (2018) [
30] successfully used the U-Net network model to detect annual rings of different widths, structures, and orientations from the heartwood of three ring-hole wood species (
Quercus sp.,
Fraxinus excelsior L., and
Ulmus sp.); it is the beginning of annual rings segmentation by using U-Net networks. However, its segmentation accuracy is low. Ning Xiao et al. (2019) [
31] proposed an image segmentation algorithm based on U-Net. This algorithm effectively segmented early wood, late wood, and bark, but poorly segmented at the pith and nodal scars. Pixels of localized regions were missing. The reason for this problem is that the U-Net model does not make full use of the global information. Liu Shuai et al. (2023) [
32] improved U-Net++ by extending the model depth and adding an attention mechanism. Taking 1000 CT images of Chinese fir as the training set and 25 images as the test set, the PA was 95.9% and the MIoU was 79.4%, but the segmentation of the morphology and detail pixels of the annual rings remains to be solved. The main reasons for this are the loss of semantic information in the downsampling process and the lack of attention to the annual rings in the model training process.
Therefore, an intelligent, automated, and high-precision segmentation algorithm for wood annual rings is urgently needed. In this paper, the DAF-Net++ model is proposed to address the technical challenges in the field of wood annual rings segmentation by using wood CT images as experimental samples.
6. Conclusions
For the wood annual rings, this paper proposes the DAF-Net++ model on the basis of improvement of the U-Net model. This model processes the deep and shallow feature maps with different attention mechanisms, respectively. DCAM uses deep semantic information for weighting guidance of shallow feature maps, and CBAM solves the problem of losing semantic information in downsampling. Deep and shallow features are fused by dense jump links to improve the gradient disappearance as well as the gradient explosion problem and to reduce the semantic divide. Obtaining more semantic information by increasing the number of channels in the feature maps allows the network to focus more on difficult classification objectives such as the annual rings during the training process. The feature maps of the CT images of each wood transverse section incorporate more semantic information and expand the sensory field. Therefore, the segmentation accuracy and optimization of the segmentation effect on annual rings mixed with cracks, knots, and the pith position of the wood are improved. The segmentation effect of DAF-Net++ is further enhanced by the introduction of Focal Loss at the back end of the network. The proposed DAF-Net++ model has 93.67% MIoU, 96.76% MPA, 96.63% Precision, and 96.76% Recall, and has better segmentation results compared with classical semantic segmentation models such as U-Net, U-Net++, DeepLabv3+, etc. However, it is very difficult to establish datasets and labels. On the one hand, wood samples with internal cracks, knots, and holes are needed to obtain transverse sectional images. On the other hand, to extract the annual rings from the complex background by image processing software is a huge workload. This led to an adequate experiment in this study only for fir trees. The DAF-Net++ model is fully applicable to a wide range of woods in terms of theoretical analysis. However, the experimental validation has not yet been performed because it is very difficult to obtain other wood species that meet the experimental conditions. The species diversity will be gradually enriched in future studies. In addition, the method increases the computation while increasing the semantic information, so it still needs to be improved in optimizing the training time. For example, updating hardware devices or making improvements in model structure. Chen Bing et al. [
48] used the shallow ResNet-18 (Residual Network with 18 layers) network to replace the original deep backbone network of DeepLabv3+ to improve the segmentation speed. Zhu Lixue et al. [
49] improved the model structure based on multi-scale serial dilated convolution to reduce the model computation. These studies provide inspiration for the team’s future research, which is of course a long process of exploration.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










