
Better Safe Than Sorry: Constructing Byzantine-Robust Federated Learning with Synthesized Trust
Abstract
:1. Introduction
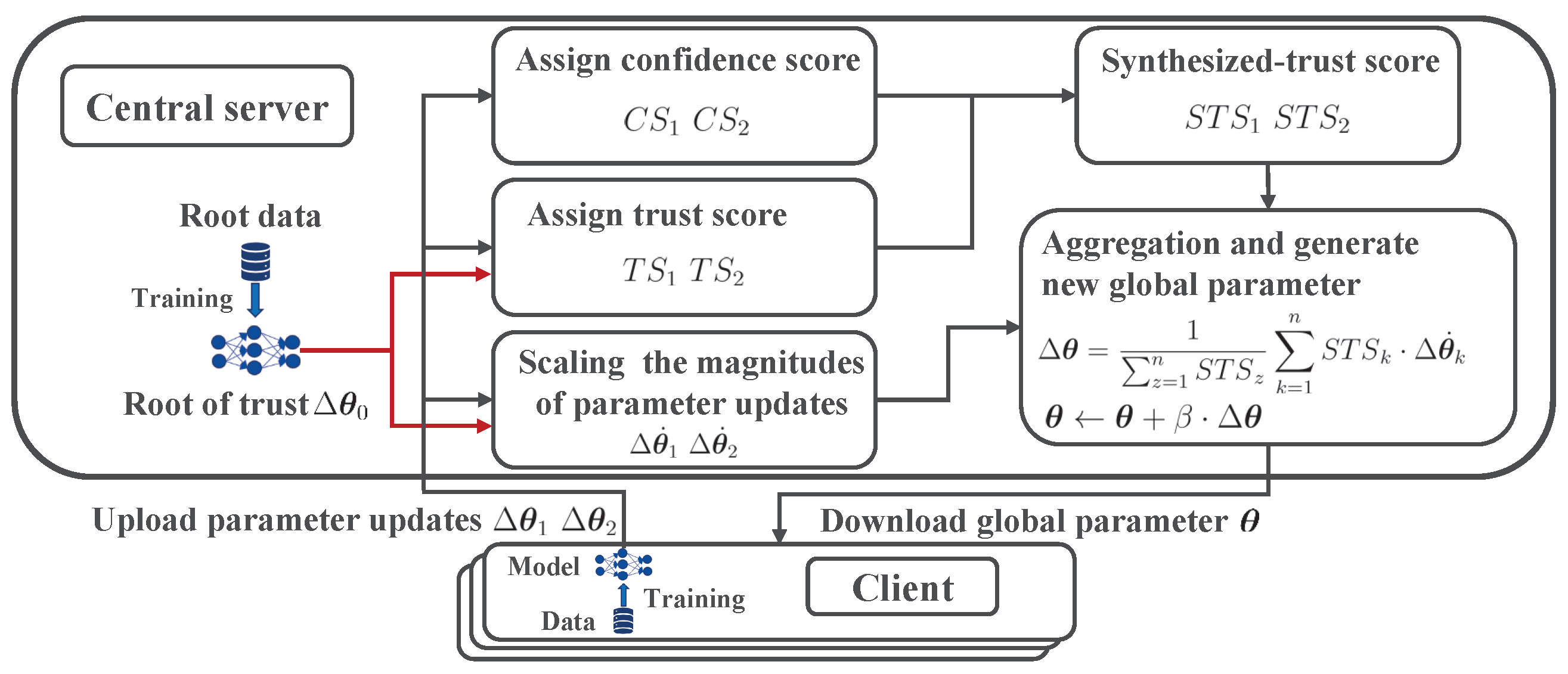
- Our work. To address the above problems, we propose a Byzantine-robust FL method called FLEST. In FLEST, the server itself bootstraps both trust and anomaly detection. From the above description, it is apparent that introducing anomaly detection methods, or only relying on the trust bootstraps of the server itself, will create its own challenges: we believe that these two methods can solve their problems in a complementary way; therefore, we devised a complementary process named the trust synthesizing mechanism. The purpose of this mechanism is to integrate the trust score (TS) and the confidence score (CS) of local parameter updating in various proportions. The central server assigns a TS and a CS to each local parameter update, based on the root of trust and anomaly detection, respectively. In order to realize this mechanism, we designed a synthesized trust score (STS), which is composed of a TS, a CS, and . The parameter controls the influence of bias in the root of trust, which is called the dynamic trust ratio. Our proposed dynamic trust ratio can be computed adaptively, based on the results of each round of TSs and CSs, thus aggregating them into the STS according to the appropriate ratio. Therefore, during the federation learning training process, the central server, after receiving the local parameter updates from clients, first obtains the TS for each local parameter update based on the root of trust, and then, using the anomaly detection method, obtains their CS. Next, the central server uses the TS and the CS to dynamically compute the STS, by synthesizing the trust mechanism. Finally, the server aggregates each local parameter update, using the STS as the weight. In our experiments, we used four datasets and three different attacks to verify the effectiveness of FLEST. And we compared FLEST to the current state-of-the-art methods. Moreover, we analyzed the effectiveness of the dynamic trust ratio . Our main contributions can be summarized as follows:
- New federated learning method FLEST. The proposed FLEST bootstraps both trust and anomaly detection, in order to be resilient against Byzantine attackers;
- Initial method to tolerate biases at the root of trust. Experiments show that FLEST works well, even when the root dataset acquired by the central server is distributed differently from the distribution of clients’ local datasets: for example, when the bias probability of mnist-0.5 was 0.8, the testing accuracy of FLEST under Trim attacks was 0.94, which was only 0.01 lower than that when the bias probability was 0.1;
- FLEST can effectively defend against existing attacks. We evaluated FLEST using existing attacks. Our experimental results showed that FLEST can effectively defend against existing attacks while training a high-performance global model: for example, the testing accuracy of FLEST under LF attack was the same as that of FedAvg under no attacks on mnist-0.1, both of which were 0.97; on fashion-mnist, the testing accuracy of FLEST under Trim attack was best; on cifar-10, the testing accuracy of FLEST under adaptive attack was best.
2. Background and Related Work
2.1. Aggregation Rules
- FedAvg. FedAvg [2] adopts FedAverage as an aggregation rule. FedAverage is a weighted average of local parameter (gradient or weight) updates, based on the size of the clients’ local datasets. Suppose an FL has n clients with local datasets , where . We use d to denote the overall local dataset. Formally, the global parameter update , where is the size of the k-th client’s local dataset. FedAverage is normally used as the state-of-the-art baseline solution, due to its high performance without attackers; however, FedAverage is vulnerable to poisoning attacks: specifically, it is not Byzantine-robust.
- Byzantine-robust aggregation rules. Distance statistical aggregation (DSA) [18,21,24,25,28] and contribution statistical aggregation (CSA) [26,27] are used in the majority of Byzantine-robust aggregation methods. DSA-based schemes discard statistical outliers, by analyzing the distribution of poisoning and benign local parameter updates, before aggregating them into a global parameter update. In CSA-enabled schemes, local parameter updates of clients are labeled with priorities, in terms of their contributions to the performance of the global model. Essentially, these schemes evaluate local parameter updates and delete statistical outliers before aggregating a global parameter update: for example, the Krum method proposed by Blanchard et al. [21] can resist up to 33% of attackers’ poisoning attacks, utilizing Euclidean distance to decide which local parameter updates should be dropped. As Krum removes outliers by analyzing the Euclidean distance, it does not remove the parameter updates of the coordinate direction anomaly. To improve Krum, Yin et al. [18] proposed two new FL schemes called Trim-Mean and Median, which are based on the trimmed mean of coordinate directions and the median of coordinate directions, respectively. Each of the techniques mentioned above suffers a common drawback: the absence of a trusted root for the central server to authenticate which local parameter updates from clients are potentially dubious.
2.2. Poisoning Attacks
3. Threat Model and Security Goals
3.1. Threat Model
- The attackers can create and control many clients in the FL system: such clients are therefore malicious, and can train local models using poisoned local datasets, or directly upload poisoned local parameter (gradient or weight) updates. The proportion of malicious clients, however, is less than half of the total;
- The attackers can collude with each other (e.g., by exchanging poisoned local datasets or local parameter updates);
- The attackers have full knowledge of the target FL system, including the aggregation rule of the FL system, the learning rates, and all clients’ local datasets and local parameter updates during the whole learning process;
- Server’s knowledge and capability. As in [22], we assumed that the central server had no access to the local datasets of the clients, and did not know the exact number of malicious clients; however, it was fully aware of the global parameters and local parameter updates for each iteration for all clients. Additionally, a trustworthy, small, and clean dataset for the root of trust had to be acquired and tagged by the central server. Due to the small number of data samples in the root dataset, its construction process would not bring too much time overhead to the server; however, without any prior knowledge of the local datasets of the clients, the distribution of the root dataset might deviate from that of clients’ datasets with a non-small bias.
3.2. Security Goals
- Fidelity. The target method ought not to lose the testing accuracy of the global model in a benign setting without attackers: that is, fidelity required that the target FL method would have no accuracy loss compared to the baseline method FedAvg without attacks;
- Robustness. The FL method could generate a global model providing classification accuracy (in comparison with FedAvg in the no-attack scenario) in the Byzantine client setting, as mentioned in the attack model (i.e., < malicious clients). To achieve robustness, we did not assume that the central server could establish, in advance, a training dataset that was unbiased towards all classes of clients’ local data;
- Efficiency. Compared to the FedAvg without attacks, the designed method should not introduce many additional computation and communication overheads, especially for clients who might be resource constrained.
4. FLEST: A Federated Learning with Synthesized Trust Method
4.1. Overview of FLEST
4.2. Detailed Design of FLEST
- Cosine. Cosine similarity is very useful in the Byzantine-robust rule. Given two vectors, and , their cosine similarity is
- Trust score. In FLEST, the central server uses the model parameter update, trained from an uncontaminated root dataset, as the root of trust: we considered it to be more trustworthy if the local parameter update had a similar direction to the root of trust, and we computed the directional similarity between them, using the cosine function.
- Confidence score. As the central server does not have access to clients’ local datasets, there will be a deviation in the distribution between the root dataset and local datasets, and such a deviation can degrade the accuracy of the final global model. To reduce the side effect of a biased root dataset, we introduced anomaly detection techniques. Specifically, the central server used the K-means clustering algorithm to cluster the local parameter updates into several clusters. We could also have used other clustering algorithms to aggregate the local parameter updates, and we will consider more advanced clustering algorithms in future work. We considered the largest cluster as the cluster of benign local parameter updates. The central server measured the similarity between each local parameter update and the mean of the benign cluster, and assigned a CS to each local parameter update. A local parameter update would receive a higher CS if it was closer to the mean of the benign cluster. Specifically, we computed the directional similarity between each local parameter update and the mean of the benign local parameter updates, using the cosine function.
- Trust synthesizing mechanism. Although using either the TS or the CS has deficiencies in FL, we noted that these two kinds of scores could be complementary to each other in the training procedure; therefore, we designed a complementary mechanism called the trust synthesizing mechanism. The idea of this mechanism was to proportionally combine the TS and the CS of each local parameter update, without completely relying on either of them: when there was a large bias in the root of trust, the trust synthesizing mechanism would automatically reduce the weight of the TS, thus reducing its negative impact. In order to realize this mechanism, we designed a synthesized trust score (STS), which was composed of the TS and the CS, using a dynamic trust ratio . Formally, we defined the synthesized trust score STSk of the kth local parameter update :where was used to determine the proportion of the TS and the CS in the STS.
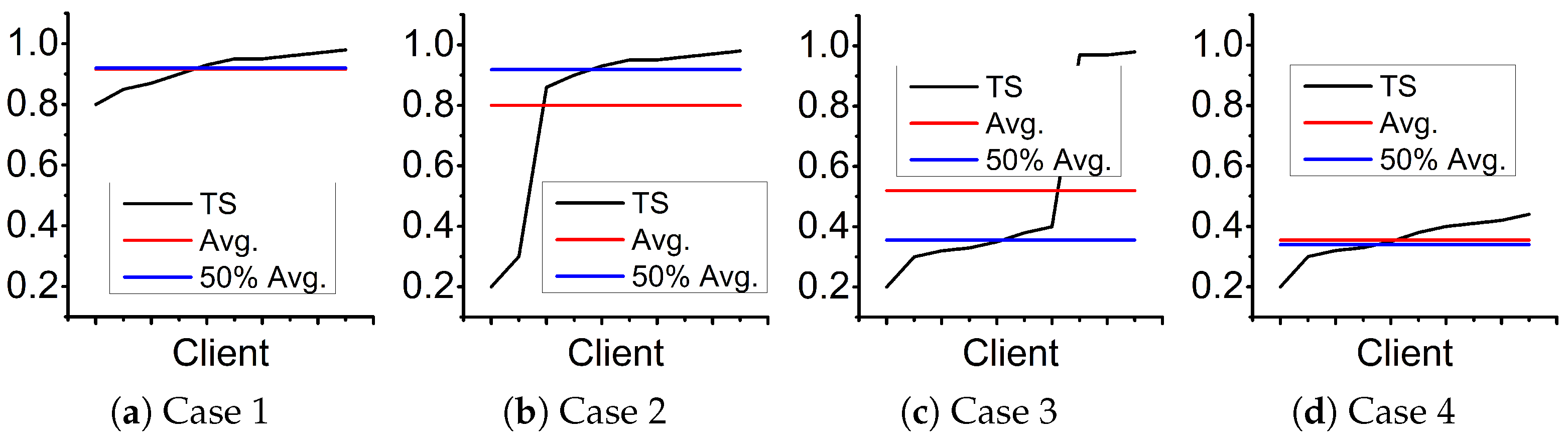
- Case 1: All TSs were high;
- Case 2: Most of the TSs were high, and the rest were low;
- Case 3: Most of the TSs were low, and the rest were high;
- Case 4: All the TSs were low.
- Analysis of Case 1 and Case 2: As the more trusted local parameter updates were assigned higher TS according to the rules of the TS calculation, we deduced that Case 1 occurred when there was no bias in the root of trust, and when there were no malicious clients. By analogy, Case 2 occurred when the trust root bias was small, or when there was a small number of malicious clients. These two cases indicate that the TS is not invalid, and thus, should account for a larger proportion of the STS, which means that should be higher.
- Analysis of Case 3 and Case 4: As it was assumed that there were fewer than 50% of malicious clients, Case 3 occurred when there was a large deviation in the root of trust, in which case the TS was close to failure. Case 4, on the other hand, showed that the TS had failed completely. Therefore, in these two cases, the TS should have accounted for a smaller proportion of the STS, and should have been lower.
- Scaling the magnitudes of local parameter updates. The attackers can modify the magnitudes of local parameter updates, and transmit them to the central server, so that they can manipulate the global parameter update. To weaken the contribution of poisoned local parameter updates, we needed to uniformly scale the magnitudes of the local parameter updates. Without a root of trust, it was difficult to determine how much we should scale, and the mean of the benign local parameter updates was not trusted for the server. As the central server had introduced a root of trust through the root dataset, we used the root of trust to determine how much scaling was needed. As a result, each local parameter update was normalized, so that it had the same magnitude as the root of trust. Formally, the scaling of the magnitudes of the local parameter updates of the kth client was defined as follows:where denoted the modulo operation of the vector.
- Aggregation of local parameter updates. We then calculated global parameter update as the mean of the scaled local parameter updates with their weight STSs as follows:Finally, we changed the global parameter with the rate of global learning as:
4.3. Algorithm of FLEST
- In Step I, the central server transmits the current parameter to selected partial clients;
- In Step II, based on the global parameter and their local datasets, the clients compute local parameter updates, which are subsequently transmitted to the central server. Using the root dataset and the global parameter, the central server determines the root of trust. After receiving the local parameter updates, the server uses K-means clustering to cluster them, in order to obtain the largest cluster (the benign local parameter updates cluster). The server computes this benign cluster’s average value. The function ParameterUpdate in Algorithm 2 uses gradient descent via iterations to determine the local parameter updates and the root of trust;
- In Step III, in order to obtain the global parameter update, and to use it to change the global parameter with , the central server of FLEST does a weighted mean of the received parameter updates of clients with STSs.
| Algorithm 1 FLEST |
|
| Algorithm 2 ParameterUpdate () |
|
5. Security Analysis
6. Performance Evaluation
6.1. Experimental Setting
6.1.1. Datasets
- Dataset mnist. There are 10,000 testing data and 60,000 training data in the mnist [42]. We set in the mnist-0.1 dataset, and set in the mnist-0.5 dataset.
- Dataset fashion-mnist. There are 10,000 testing data and 60,000 training data in the 10-class fashion picture dataset known as fashion-mnist [44]. We set in the fashion-mnist dataset.
- Dataset cifar-10. 10,000 testing data and 50,000 training data make up the 10-class color image classification dataset known as cifar-10 [43]. We set in the cifar-10 dataset.
6.1.2. Evaluated Attacks
6.1.3. FL System Settings
- Selection of global model. For the selection of the global model, we employed a convolutional neural network (CNN) for mnist and fashion-mnist. For the CNN, we used a convolutional layer with , a convolutional layer with , a fully connected layer with 100, two max-pooling layers with , and an output layer with a softmax function. The widely utilized ResNet20 [45] architecture was taken into account as the global model for cifar-10. Our experiments focused on the performance of other aggregation rules and the FLEST in the face of attacks, rather than on the best global model; therefore, we did not need to use an overly complex neural network model.
- Parameter settings. We compared FLEST to the works FedAvg [1,2], Trim-Mean [18], and FLTrust [22]. As they obeyed a workflow similar to Algorithm 1, they also used the parameters , , , , , and x. For comparison, we made use of the similar FL settings in [22]. Specifically, we set all clients to be selected in each iteration, i.e., , and we set . We considered the product of the local learning rate and the global learning rate as a combined learning rate. Specifically, for mnist-0.1 and mnist-0.5, for fashion-mnist, and for cifar-10. With the exception of cifar-10, we set the batch size to instead of for the other three datasets. We determined the total iterations for mnist-0.1, for mnist-0.5, for fashion-mnist, and for cifar-10.
- Generation of root dataset. We built a root dataset with only 100 data, following [22]; however, the root dataset in our experiments was biased towards one class of data. Specifically, we drew a portion of data in the root dataset from a specific kind of local dataset, and sampled the remaining portion evenly and randomly from the other classes: this is known as the bias probability (BP). When each class of the root dataset had the same number of samples, the BP was 0.1, which meant that the distribution of the root dataset was identical to the distribution of the local datasets. Whenever the amount of data in the root dataset that was extracted from one class of local datasets was more than that of other classes, the BP would be larger. Unless otherwise mentioned, we set the BP to 0.1 by default.
6.2. Experimental Results
- Evaluation Metric. As this work focused on defending against untargeted attacks, which were designed to reduce the global classification accuracy of the model, we used the accuracy of the model as an evaluation metric: the higher the accuracy of the global model, the more effective the corresponding defense method.
- Goal 1: Fidelity. As shown in Table 2, when there was no attack, the testing accuracies of FLEST were similar to that of FedAvg, which is the baseline FL method. Unfortunately, the testing accuracies of current FL approaches can be lower, because, while aggregating local parameter updates, the current FL approach discards part of them, whereas FLEST considers all local parameter updates: for example, in Table 2, under the fashion-mnist, the testing accuracies of FedAvg, FLTrust, and FLEST are 0.90, 0.89, and 0.90, respectively, while the testing accuracy of Trim-mean is 0.86.
- Goal 2: Robustness. The testing accuracies of FLEST under three different attacks were, at most, 0.04 lower than those of FedAvg under no attacks on the mnist and fashion-mnist datasets. In particular, as shown in Table 2, the testing accuracy of FLEST under LF attack was the same as that of FedAvg under no attacks on mnist-0.1, both of which were 0.97. The testing accuracies of the presently used FL techniques under three different attacks on the four datasets were much lower: for example, the Trim attack reduced the testing accuracy of Trim-mean by 0.11 on mnist-0.5, and the Adaptive attack reduced the testing accuracy of Trim-mean by 0.35 on fashion-mnist.
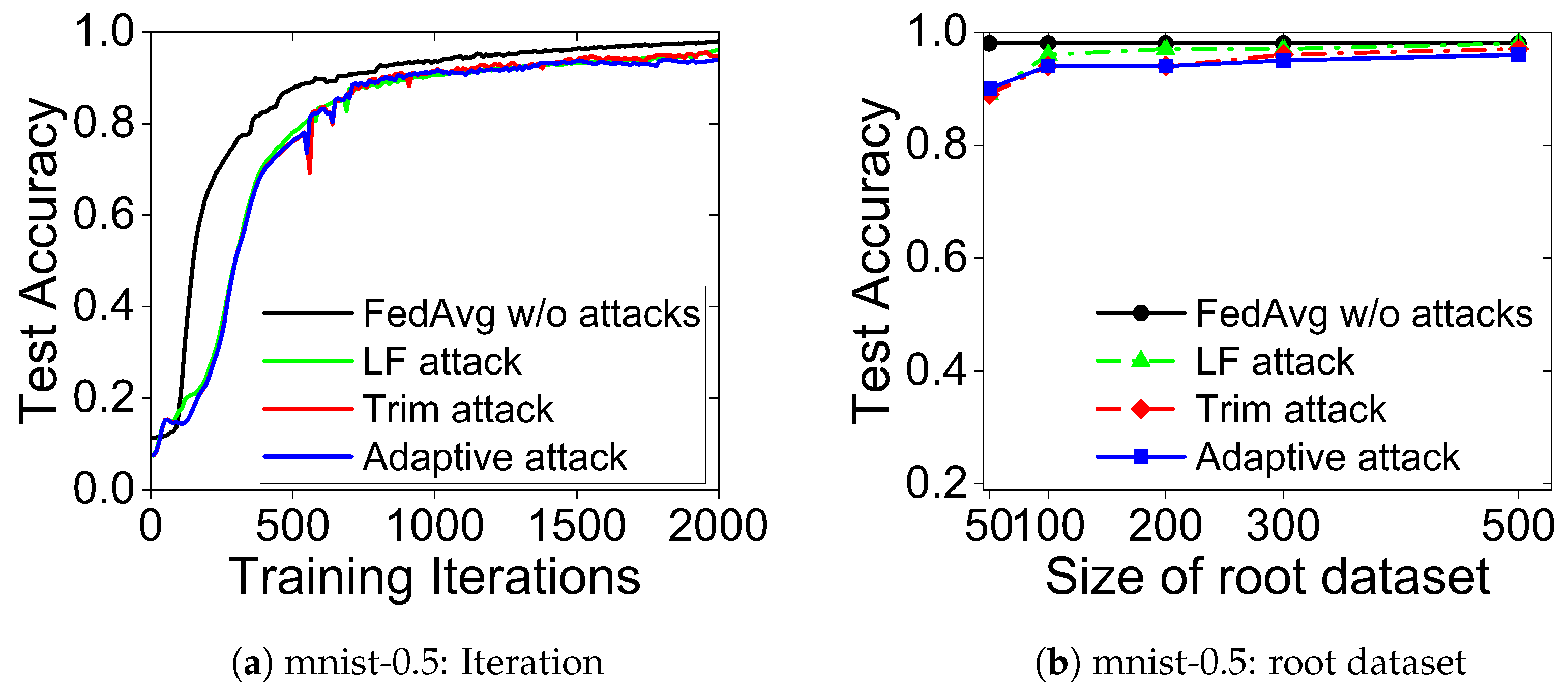
- Goal 3: Efficiency. Like FedAvg, FLEST does not cause additional computation to the clients in each iteration. In addition, Figure 3a shows the testing accuracy of FLEST, during the training process, under different attacks, and of the baseline (the testing accuracy of FedAvg under no attack). The experimental results show that FLEST converges at a similar rate as FedAvg, which indicates that FLEST does not introduce much communication overhead between the central server and the clients. Compared to FedAvg, FLEST introduces some computation overhead to the central server, including computing the root of trust, computing STS, and scaling all local parameter updates; however, a powerful server requires only a negligible time overhead.
- Evaluation of dynamic trust ratio . To verify the validity of the dynamic trust ratio , we evaluated the performance of the global model, using different fixed gamma, thus verifying whether the dynamic adaptively adjusted to the appropriate range. Table 4 records the accuracy of the model after fixing different values of for different deviation probabilities and different attacks, as well as the average value of the dynamic . As shown in Table 4a, when the deviation probability was small, the average value of gamma was around 60–80%; however, when the deviation probability was very high, as shown in Table 4c, the average value of dropped to about 20–50%, and the accuracy of FLEST, by applying the dynamic , was also at a high level. Thus, these results demonstrate that the trust synthesizing mechanism can mitigate the degradation of model accuracy due to root dataset bias.
- Impact of the root dataset. The effect of the root dataset sizes on FLEST, under various assaults, is depicted in Figure 3b. We note that FLEST could fight against various assaults with a root dataset of only 100 training data. In particular, the testing accuracy of FLEST under assaults was comparable to that of FedAvg under no attacks when the root dataset contained 100 training data. When the number of training data in the root dataset exceeded 100, FLEST’s testing accuracy increased slightly.
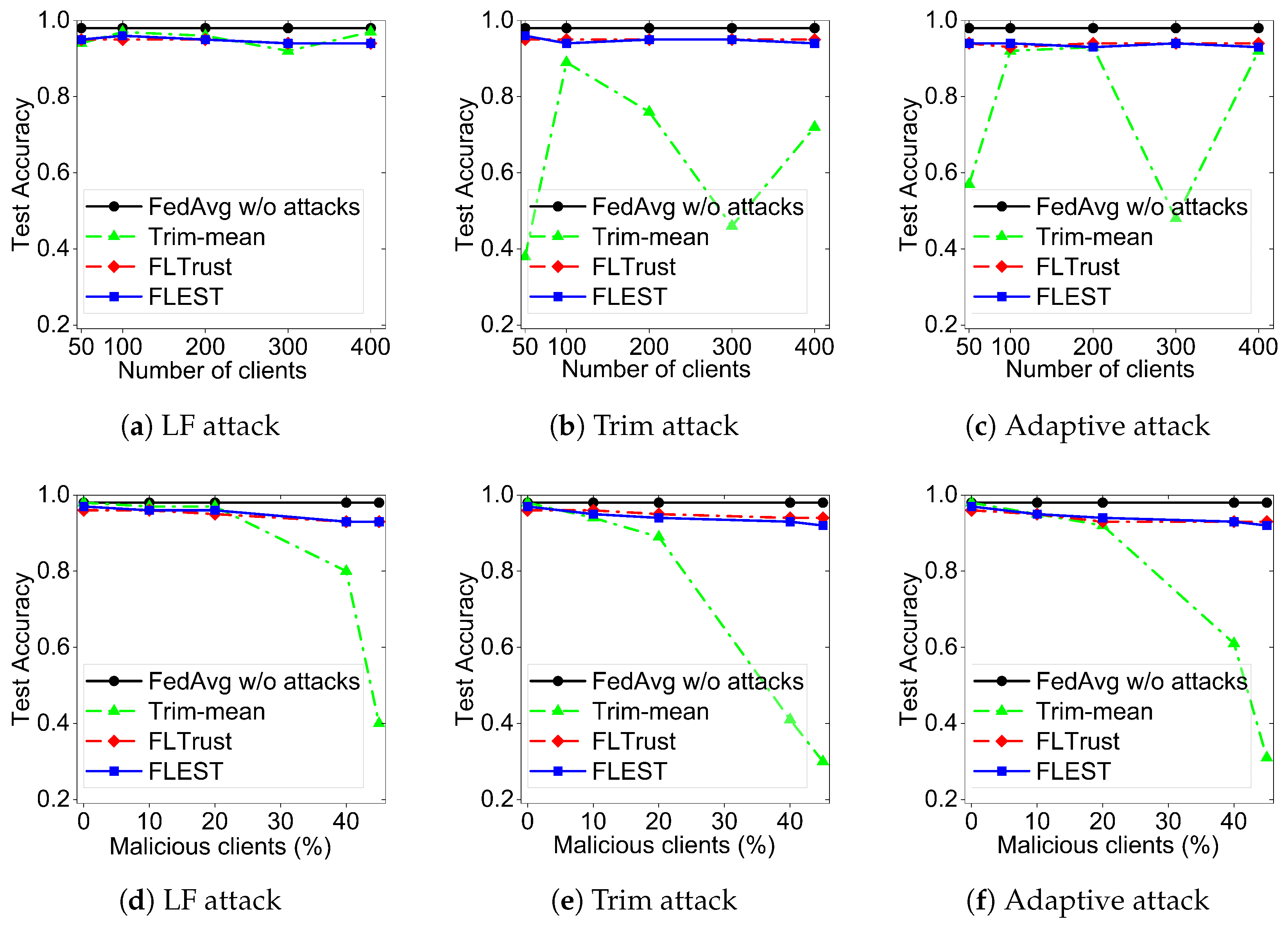
- Impact of the number of clients. The effect of the total clients on each FL method under attacks is shown in Figure 4a–c. The findings of the trial indicate that the impact of the total clients on FLTrust and FLEST was small, while Trim-mean was greatly affected: for example, when there were 300 clients, the global model taught by Trim had a testing accuracy of 0.46 under the Trim attack, whereas FLTrust and FLEST trained global models to have a testing accuracy of 0.95.
- Impact of the percentage of malicious clients. Figure 4d–f show the effect of the percentage of malicious clients on each FL method under attacks. We observed that the effect of the percentage of malicious clients on FLTrust and FLEST was small, while Trim-mean was greatly affected: for example, when there was 20% malicious clients, the global model learned by Trim had a testing accuracy of 0.89 under the Trim attack, whereas the testing accuracies of the global model learned by both FLTrust and FLEST were 0.95 and 0.94, respectively.
7. Discussion and Limitations
- FLEST vs. existing works. Prior research has exclusively focused on examining the direction between either local parameter updates or the root of trust and each local parameter update. By contrast, our novel FLEST extends this approach, by taking into account not just the direction between the local parameter updates and the root of trust, but also the direction between each individual local parameter update.
- Poisoned root dataset. Our FLEST does not require a root dataset with all data samples pollution-free, as FLTrust does; however, we acknowledge that if FLEST uses a poisoned root dataset, it may not be able to defend against existing attacks. In order to avoid the possibility of root dataset pollution, service providers may opt to have their personnel manually curate the root dataset.
- Targeted poisoning attacks and root dataset with low BP. We acknowledge that the various poisoning attacks used in the experimental evaluation did not specifically target our FLEST approach. We recognize that stronger poisoning attacks may exist against FLEST, which would be an interesting avenue for future exploration. Additionally, considering the collection of root dataset with low BP is a promising direction for future work: for instance, if the dynamic trust ratio of an FL system using FLEST falls below a certain threshold (e.g., ) during an iteration, it indicates a significant distributional bias between the root dataset collected by the server and the overall local training data distribution on the clients; in such cases, the server can re-collect the root dataset before the next iteration, thus avoiding the use of a biased root dataset from the initial iteration onward.
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtarik, P.; Suresh, A.T.; Bacon, D. Federated Learning: Strategies for Improving Communication Efficiency. In Proceedings of the NIPS Workshop on Private Multi-Party Machine Learning, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. Proc. Artif. Intell. Stat. PMLR 2017, 54, 1273–1282. [Google Scholar]
- Zhang, Y.; Bai, G.; Li, X.; Nepal, S.; Grobler, M.; Chen, C.; Ko, R.K. Preserving Privacy for Distributed Genome-Wide Analysis Against Identity Tracing Attacks. IEEE Trans. Dependable Secur. Comput. 2022, 1–17. [Google Scholar] [CrossRef]
- Fang, M.; Liu, J.; Gong, N.Z.; Bentley, E.S. AFLGuard: Byzantine-robust Asynchronous Federated Learning. In Proceedings of the 38th Annual Computer Security Applications Conference, Austin, TX, USA, 5–9 December 2022; pp. 632–646. [Google Scholar]
- Nguyen, J.; Malik, K.; Zhan, H.; Yousefpour, A.; Rabbat, M.; Malek, M.; Huba, D. Federated learning with buffered asynchronous aggregation. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Valencia, Spain, 28–30 March 2016; pp. 3581–3607. [Google Scholar]
- Huba, D.; Nguyen, J.; Malik, K.; Zhu, R.; Rabbat, M.; Yousefpour, A.; Wu, C.J.; Zhan, H.; Ustinov, P.; Srinivas, H.; et al. Papaya: Practical, private, and scalable federated learning. Proc. Mach. Learn. Syst. 2022, 4, 814–832. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning Attacks against Support Vector Machines. In Proceedings of the 29th International Coference on International Conference on Machine Learning, Edinburgh, Scotland, 26 June–1 July 2012. [Google Scholar]
- Jagielski, M.; Oprea, A.; Biggio, B.; Liu, C.; Nita-Rotaru, C.; Li, B. Manipulating machine learning: Poisoning attacks and countermeasures for regression learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 19–35. [Google Scholar]
- Li, B.; Wang, Y.; Singh, A.; Vorobeychik, Y. Data poisoning attacks on factorization-based collaborative filtering. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Xiao, H.; Biggio, B.; Brown, G.; Fumera, G.; Eckert, C.; Roli, F. Is feature selection secure against training data poisoning? In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1689–1698. [Google Scholar]
- Mei, S.; Zhu, X. Using machine teaching to identify optimal training-set attacks on machine learners. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local Model Poisoning Attacks to Byzantine-Robust Federated Learning. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1605–1622. [Google Scholar]
- Xie, C.; Huang, K.; Chen, P.Y.; Li, B. Dba: Distributed backdoor attacks against federated learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Analyzing federated learning through an adversarial lens. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 634–643. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics. PMLR, Online, 26–28 August 2020; pp. 2938–2948. [Google Scholar]
- Lyu, L.; Yu, H.; Ma, X.; Sun, L.; Zhao, J.; Yang, Q.; Yu, P.S. Privacy and robustness in federated learning: Attacks and defenses. arXiv 2020, arXiv:2012.06337. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Su, L.; Xu, J. Distributed statistical machine learning in adversarial settings: Byzantine gradient descent. Proc. ACM Meas. Anal. Comput. Syst. 2017, 1, 1–25. [Google Scholar] [CrossRef]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning. PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Sohn, J.y.; Han, D.J.; Choi, B.; Moon, J. Election coding for distributed learning: Protecting signsgd against byzantine attacks. Adv. Neural Inf. Process. Syst. 2020, 33, 14615–14625. [Google Scholar]
- Yu, L.; Wu, L. Towards byzantine-resilient federated learning via group-wise robust aggregation. In Federated Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 81–92. [Google Scholar]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Cao, X.; Fang, M.; Liu, J.; Gong, N.Z. FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping. In Proceedings of the ISOC Network and Distributed System Security Symposium (NDSS), Virtually, 21–25 February 2021. [Google Scholar]
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data poisoning attacks against federated learning systems. In European Symposium on Research in Computer Security; Springer: Berlin/Heidelberg, Germany, 2020; pp. 480–501. [Google Scholar]
- Li, L.; Xu, W.; Chen, T.; Giannakis, G.B.; Ling, Q. RSA: Byzantine-robust stochastic aggregation methods for distributed learning from heterogeneous datasets. Proc. AAAI Conf. Artif. Intell. 2019, 33, 1544–1551. [Google Scholar] [CrossRef] [Green Version]
- Zhao, B.; Sun, P.; Wang, T.; Jiang, K. FedInv: Byzantine-robust Federated Learning by Inversing Local Model Updates. Proc. Aaai Conf. Artif. Intell. 2022, 36, 9171–9179. [Google Scholar] [CrossRef]
- Xie, C.; Koyejo, S.; Gupta, I. Zeno: Distributed stochastic gradient descent with suspicion-based fault-tolerance. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6893–6901. [Google Scholar]
- Xie, C.; Koyejo, S.; Gupta, I. Zeno++: Robust fully asynchronous sgd. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 10495–10503. [Google Scholar]
- Mhamdi, E.M.E.; Guerraoui, R.; Rouault, S. The hidden vulnerability of distributed learning in byzantium. In Proceedings of the International Conference on Machine Learning. PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3521–3530. [Google Scholar]
- Chen, X.; Liu, C.; Li, B.; Lu, K.; Song, D. Targeted backdoor attacks on deep learning systems using data poisoning. arXiv 2017, arXiv:1712.05526. [Google Scholar]
- Wang, N.; Xiao, Y.; Chen, Y.; Hu, Y.; Lou, W.; Hou, Y.T. FLARE: Defending Federated Learning against Model Poisoning Attacks via Latent Space Representations. In Proceedings of the 2022 ACM on Asia Conference on Computer and Communications Security, Nagasaki, Japan, 30 May–3 June 2022; pp. 946–958. [Google Scholar]
- Shen, L.; Zhang, Y.; Wang, J.; Bai, G. Better Together: Attaining the Triad of Byzantine-robust Federated Learning via Local Update Amplification. In Proceedings of the 38th Annual Computer Security Applications Conference, Austin, TX, USA, 5–9 December 2022; pp. 201–213. [Google Scholar]
- Fang, M.; Yang, G.; Gong, N.Z.; Liu, J. Poisoning attacks to graph-based recommender systems. In Proceedings of the 34th Annual Computer Security Applications Conference, San Juan, PR, USA, 3–7 December 2018; pp. 381–392. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv 2017, arXiv:1708.06733. [Google Scholar]
- Muñoz-González, L.; Biggio, B.; Demontis, A.; Paudice, A.; Wongrassamee, V.; Lupu, E.C.; Roli, F. Towards poisoning of deep learning algorithms with back-gradient optimization. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 27–38. [Google Scholar]
- Nelson, B.; Barreno, M.; Chi, F.J.; Joseph, A.D.; Rubinstein, B.I.; Saini, U.; Sutton, C.; Tygar, J.D.; Xia, K. Exploiting machine learning to subvert your spam filter. LEET 2008, 8, 16–17. [Google Scholar]
- Rubinstein, B.I.; Nelson, B.; Huang, L.; Joseph, A.D.; Lau, S.H.; Rao, S.; Taft, N.; Tygar, J.D. Antidote: Understanding and defending against poisoning of anomaly detectors. In Proceedings of the 9th ACM SIGCOMM Conference on Internet Measurement, Chicago, IL, USA, 4–6 November 2009; pp. 1–14. [Google Scholar]
- Shafahi, A.; Huang, W.R.; Najibi, M.; Suciu, O.; Studer, C.; Dumitras, T.; Goldstein, T. Poison frogs! targeted clean-label poisoning attacks on neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Suciu, O.; Marginean, R.; Kaya, Y.; Daume III, H.; Dumitras, T. When does machine learning fail? generalized transferability for evasion and poisoning attacks. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18). Baltimore, MD, USA, 15–17 August 2018; pp. 1299–1316. [Google Scholar]
- Wang, B.; Gong, N.Z. Attacking graph-based classification via manipulating the graph structure. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, Baltimore, MD, USA, 15–17 August 2018; pp. 2023–2040. [Google Scholar]
- Yang, G.; Gong, N.Z.; Cai, Y. Fake Co-visitation Injection Attacks to Recommender Systems. In Proceedings of the NDSS, San Diego, CA, USA, 26 February–1 March 2017. [Google Scholar]
- Box Plot—Wikipedia. Available online: https://en.wikipedia.org/wiki/Box_plot (accessed on 4 October 2022).
- Deng, L. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.semanticscholar.org/paper/Learning-Multiple-Layers-of-Features-from-Tiny-Krizhevsky/5d90f06bb70a0a3dced62413346235c02b1aa086 (accessed on 2 July 2023).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Robustness | Root of Trust |
|---|---|---|
| FedAvg | no | no |
| Krum | yes | no |
| Trim-Mean | yes | no |
| Median | yes | no |
| FLTrust | yes | yes |
| Mnist-0.1 | Mnist-0.5 | Fashion-Mnist | Cifar-10 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attack | FedAvg | Trim-Mean | FLTrust | FLEST | FedAvg | Trim-Mean | FLTrust | FLEST | FedAvg | Trim-Mean | FLTrust | FLEST | FedAvg | Trim-Mean | FLTrust | FLEST |
| No | 0.97 | 0.98 | 0.97 | 0.98 | 0.98 | 0.98 | 0.96 | 0.97 | 0.89 | 0.86 | 0.89 | 0.90 | 0.64 | 0.54 | 0.62 | 0.63 |
| LF | 0.96 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.95 | 0.96 | 0.84 | 0.80 | 0.89 | 0.90 | 0.54 | 0.46 | 0.57 | 0.57 |
| Trim | 0.91 | 0.93 | 0.95 | 0.95 | 0.91 | 0.89 | 0.95 | 0.94 | 0.66 | 0.44 | 0.88 | 0.88 | 0.19 | 0.28 | 0.48 | 0.48 |
| Adaptive | 0.94 | 0.95 | 0.95 | 0.95 | 0.94 | 0.92 | 0.93 | 0.94 | 0.78 | 0.65 | 0.88 | 0.88 | 0.10 | 0.31 | 0.49 | 0.49 |
| (a) Mnist-0.1 and Mnist-0.5 | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Mnist-0.1 | Mnist-0.5 | ||||||||||||||||||||||
| BP | 0.1 | 0.2 | 0.4 | 0.6 | 0.8 | 1 | 0.1 | 0.2 | 0.4 | 0.6 | 0.8 | 1 | ||||||||||||
| Method | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours |
| No | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | 0.97 | 0.96 | 0.97 | 0.66 | 0.98 | 0.96 | 0.97 | 0.96 | 0.97 | 0.95 | 0.96 | 0.93 | 0.97 | 0.93 | 0.97 | 0.20 | 0.97 |
| LF | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | 0.96 | 0.95 | 0.96 | 0.22 | 0.71 | 0.16 | 0.64 | 0.95 | 0.96 | 0.95 | 0.95 | 0.92 | 0.93 | 0.90 | 0.92 | 0.78 | 0.72 | 0.11 | 0.56 |
| Trim | 0.95 | 0.95 | 0.95 | 0.95 | 0.92 | 0.94 | 0.90 | 0.93 | 0.54 | 0.93 | 0.11 | 0.93 | 0.95 | 0.94 | 0.94 | 0.94 | 0.92 | 0.93 | 0.91 | 0.93 | 0.86 | 0.94 | 0.11 | 0.94 |
| Adaptive | 0.95 | 0.95 | 0.94 | 0.95 | 0.93 | 0.93 | 0.87 | 0.93 | 0.10 | 0.93 | 0.10 | 0.92 | 0.93 | 0.94 | 0.93 | 0.94 | 0.92 | 0.92 | 0.87 | 0.92 | 0.50 | 0.91 | 0.10 | 0.86 |
| (b) Fashion-Mnist and Cifar-10 | ||||||||||||||||||||||||
| Dataset | Fashion-Mnist | Cifar-10 | ||||||||||||||||||||||
| BP | 0.1 | 0.2 | 0.4 | 0.6 | 0.8 | 1 | 0.1 | 0.2 | 0.4 | 0.6 | 0.8 | 1 | ||||||||||||
| Method | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours | FLTrust | Ours |
| No | 0.89 | 0.90 | 0.89 | 0.89 | 0.88 | 0.89 | 0.86 | 0.88 | 0.85 | 0.89 | 0.10 | 0.89 | 0.62 | 0.62 | 0.62 | 0.63 | 0.61 | 0.61 | 0.59 | 0.62 | 0.10 | 0.62 | 0.10 | 0.62 |
| LF | 0.89 | 0.90 | 0.89 | 0.89 | 0.88 | 0.89 | 0.85 | 0.88 | 0.86 | 0.87 | 0.10 | 0.69 | 0.57 | 0.57 | 0.56 | 0.56 | 0.45 | 0.47 | 0.41 | 0.47 | 0.10 | 0.44 | 0.10 | 0.40 |
| Trim | 0.88 | 0.88 | 0.87 | 0.87 | 0.87 | 0.87 | 0.84 | 0.84 | 0.10 | 0.79 | 0.10 | 0.78 | 0.48 | 0.48 | 0.47 | 0.48 | 0.40 | 0.43 | 0.33 | 0.35 | 0.10 | 0.32 | 0.10 | 0.30 |
| Adaptive | 0.88 | 0.88 | 0.86 | 0.86 | 0.84 | 0.86 | 0.82 | 0.81 | 0.10 | 0.79 | 0.10 | 0.69 | 0.49 | 0.49 | 0.45 | 0.46 | 0.42 | 0.44 | 0.32 | 0.34 | 0.10 | 0.33 | 0.10 | 0.29 |
| (a) BP = 0.1 and 0.2 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BP = 0.1 | BP = 0.2 | |||||||||||||||
| Fixed | 0 | 10% | 20% | 40% | 60% | 80% | 100% | 0 | 10% | 20% | 40% | 60% | 80% | 100% | ||
| No | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | 85.4% | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | 83.7% |
| LF | 0.30 | 0.70 | 0.94 | 0.95 | 0.95 | 0.95 | 0.95 | 78.6% | 0.30 | 0.70 | 0.94 | 0.95 | 0.95 | 0.95 | 0.95 | 73.2% |
| Trim | 0.94 | 0.94 | 0.95 | 0.94 | 0.94 | 0.95 | 0.95 | 76.3% | 0.95 | 0.94 | 0.95 | 0.94 | 0.94 | 0.94 | 0.94 | 64.9% |
| Adaptive | 0.93 | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 | 0.93 | 66.8% | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 | 0.93 | 0.93 | 63.4% |
| BP = 0.4 | BP = 0.6 | |||||||||||||||
| Fixed | 0 | 10% | 20% | 40% | 60% | 80% | 100% | 0 | 10% | 20% | 40% | 60% | 80% | 100% | ||
| No | 0.97 | 0.97 | 0.97 | 0.96 | 0.96 | 0.97 | 0.95 | 71.6% | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | 0.96 | 0.93 | 43.3% |
| LF | 0.30 | 0.58 | 0.84 | 0.92 | 0.92 | 0.92 | 0.92 | 65.6% | 0.20 | 0.36 | 0.75 | 0.85 | 0.91 | 0.91 | 0.90 | 74.7% |
| Trim | 0.94 | 0.95 | 0.94 | 0.94 | 0.93 | 0.92 | 0.92 | 66.2% | 0.94 | 0.94 | 0.94 | 0.94 | 0.93 | 0.91 | 0.91 | 61.8% |
| Adaptive | 0.93 | 0.94 | 0.94 | 0.93 | 0.93 | 0.92 | 0.92 | 72.5% | 0.94 | 0.94 | 0.93 | 0.93 | 0.92 | 0.89 | 0.87 | 65.4% |
| (c) = 0.8 and 1 | ||||||||||||||||
| BP = 0.8 | BP = 1 | |||||||||||||||
| Fixed | 0 | 10% | 20% | 40% | 60% | 80% | 100% | 0 | 10% | 20% | 40% | 60% | 80% | 100% | ||
| No | 0.98 | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | 0.93 | 34.9% | 0.98 | 0.98 | 0.97 | 0.97 | 0.97 | 0.97 | 0.20 | 26.3% |
| LF | 0.16 | 0.37 | 0.48 | 0.53 | 0.68 | 0.80 | 0.78 | 74.6% | 0.26 | 0.31 | 0.38 | 0.39 | 0.39 | 0.40 | 0.11 | 53.8% |
| Trim | 0.95 | 0.95 | 0.94 | 0.94 | 0.93 | 0.92 | 0.86 | 42.8% | 0.94 | 0.94 | 0.94 | 0.94 | 0.91 | 0.40 | 0.11 | 47.1% |
| Adaptive | 0.94 | 0.94 | 0.93 | 0.90 | 0.83 | 0.87 | 0.50 | 31.3% | 0.95 | 0.92 | 0.89 | 0.56 | 0.23 | 0.11 | 0.10 | 32.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geng, G.; Cai, T.; Yang, Z. Better Safe Than Sorry: Constructing Byzantine-Robust Federated Learning with Synthesized Trust. Electronics 2023, 12, 2926. https://doi.org/10.3390/electronics12132926
Geng G, Cai T, Yang Z. Better Safe Than Sorry: Constructing Byzantine-Robust Federated Learning with Synthesized Trust. Electronics. 2023; 12(13):2926. https://doi.org/10.3390/electronics12132926
Chicago/Turabian StyleGeng, Gangchao, Tianyang Cai, and Zheng Yang. 2023. "Better Safe Than Sorry: Constructing Byzantine-Robust Federated Learning with Synthesized Trust" Electronics 12, no. 13: 2926. https://doi.org/10.3390/electronics12132926