1. Introduction
In recent years, deep learning has made significant progress in image processing [
1,
2,
3]. Particularly, generative models [
4,
5,
6,
7] have achieved remarkable success in image generation and manipulation. A more recent trend in image generation is compositional image synthesis. Compositional image synthesis aims to capture the inherent compositional nature of our world, where complex objects are formed by combining simpler components [
8]. By incorporating this prior into the generation process, compositional image synthesis allows for the semantic control of its components, enabling the localized manipulation of the image, increasing the interpretability of the generation process, and improving the reusability and efficiency of the model. It has numerous applications, including content creation and design, image editing, virtual reality, and gaming. Despite these important characteristics and potential applications, compositional image synthesis has received relatively little attention from the research community until recently.
Most previous works have primarily focused on generating visually appealing images. One notable approach in this context is the style-based GAN known as StyleGAN [
9]. While it is capable of producing high-fidelity images and achieving some extent of disentanglement between coarse and fine features, it lacks the ability to represent the semantic parts of the object and cannot effectively control the attributes of these parts accordingly. Additionally, the achieved disentanglement is limited, since editing one attribute often affects other attributes. These limitations arise from the usage of a single latent vector to govern the generation of the entire image. In this study, we propose the utilization of a set of latent codes to control the generation process, where each latent code corresponds to a specific semantic part of the object.
Other researchers focus on mapping segmentation masks to realistic images. A notable work in this field is SEAN [
10], which encodes the mask as a modulation vector to control the semantic meaning of each region and employs a per-region style to control the appearance of each semantic region. While this approach achieves semantic generation and control, it requires the segmentation mask as input, thus limiting its ability to generate images from scratch. Additionally, since the generation is conditioned on the segmentation mask, it can only manipulate the appearance of the region and necessitates manual effort to change the shape of the region. In contrast, our method can generate images from scratch and automatically control both the shape and appearance of each semantic part.
A recently proposed work called SemanticStyleGAN [
11] achieves compositional synthesis. While it demonstrates high-quality image generation and composition, it requires a set of pre-defined generators and uses a separate generator for each component. This structure has several disadvantages. First, the parameter count increases linearly with the semantic part count, rendering it non-scalable. Second, the representation is inefficient because each part is individually modeled without parameter sharing. Third, it lacks flexibility as the generators are designed for specific tasks, making it challenging to transfer the learned representations to new tasks. Manual decisions regarding the choice of generator are necessary for new tasks, introducing subjective bias and potentially leading to suboptimal training. Thus, the question arises: How can we achieve compositional image synthesis without encountering these limitations?
We draw inspiration from the human memory system, which exhibits compositionality as a key feature of human intelligence. Evidence suggests that humans store, retrieve, and manipulate information through a structured memory system. Knowledge is accumulated in long-term memory, which is then retrieved and manipulated in working memory, which is also known as short-term memory [
12]. This memory system enables human beings to demonstrate flexible out-of-distribution and systematic generalization abilities, highlighting a significant gap between state-of-the-art machine learning models and human intelligence [
8,
13]. In terms of compositional learning, this memory system offers efficiency and flexibility. This raises the question: Can we enhance compositional learning in machine learning by introducing a similar memory system? Our work demonstrates that this possibility is indeed achievable.
Interestingly, recent work has shown that the hidden features generated by the generators of GANs posses several important properties, such as disentanglement [
14,
15] and out-of-domain generalization [
16,
17]. These results indicate that the generator of GANs could potentially be a suitable memory model. It turns out GANs, especially StyleGANs [
9,
14,
18] can be naturally viewed as a memory system. A random vector
z is sampled from a Gaussian distribution, which is mapped to a latent code
w by Multi-Layer Perceptrons (MLPs). The latent code is used to modulate the generator and produce the final image. We may simply treat
z or
w as the query code and the output of the generator as the corresponding retrieved result. Unfortunately, as a memory model, a basic function is to store heterogeneous information. It is well known that it is hard for GANs to generate heterogeneous objects, and it tends to suffer mode collapse. Most GAN models in the literature are designed to model homogeneous objects sampled from a single distribution, which makes them less useful as a memory model.
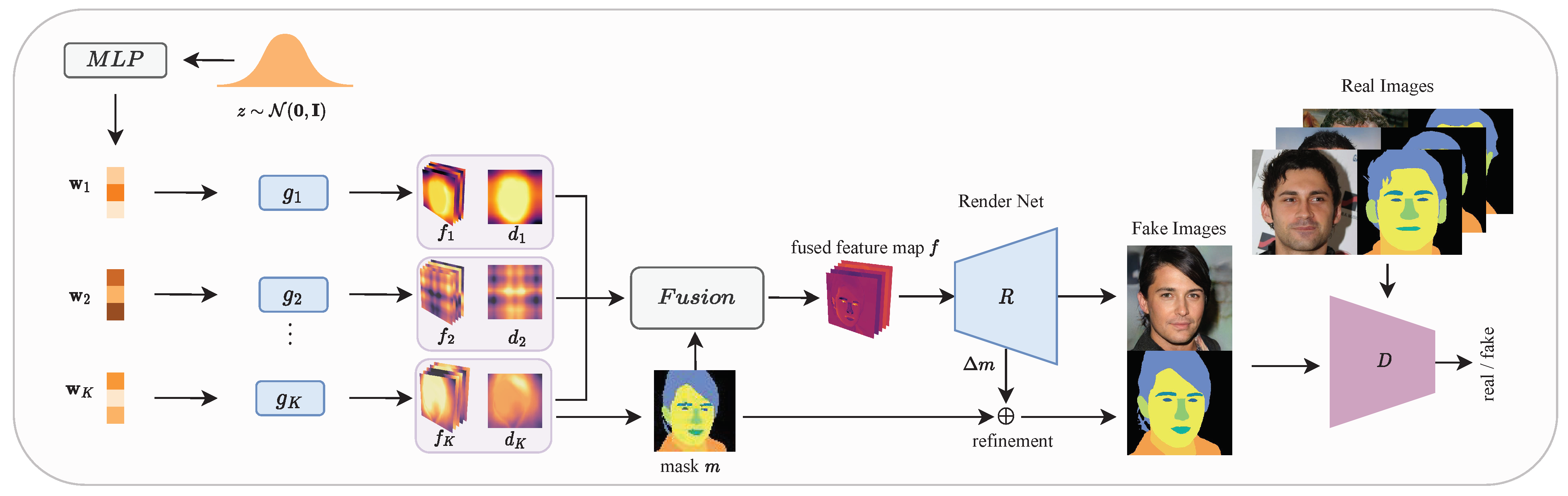
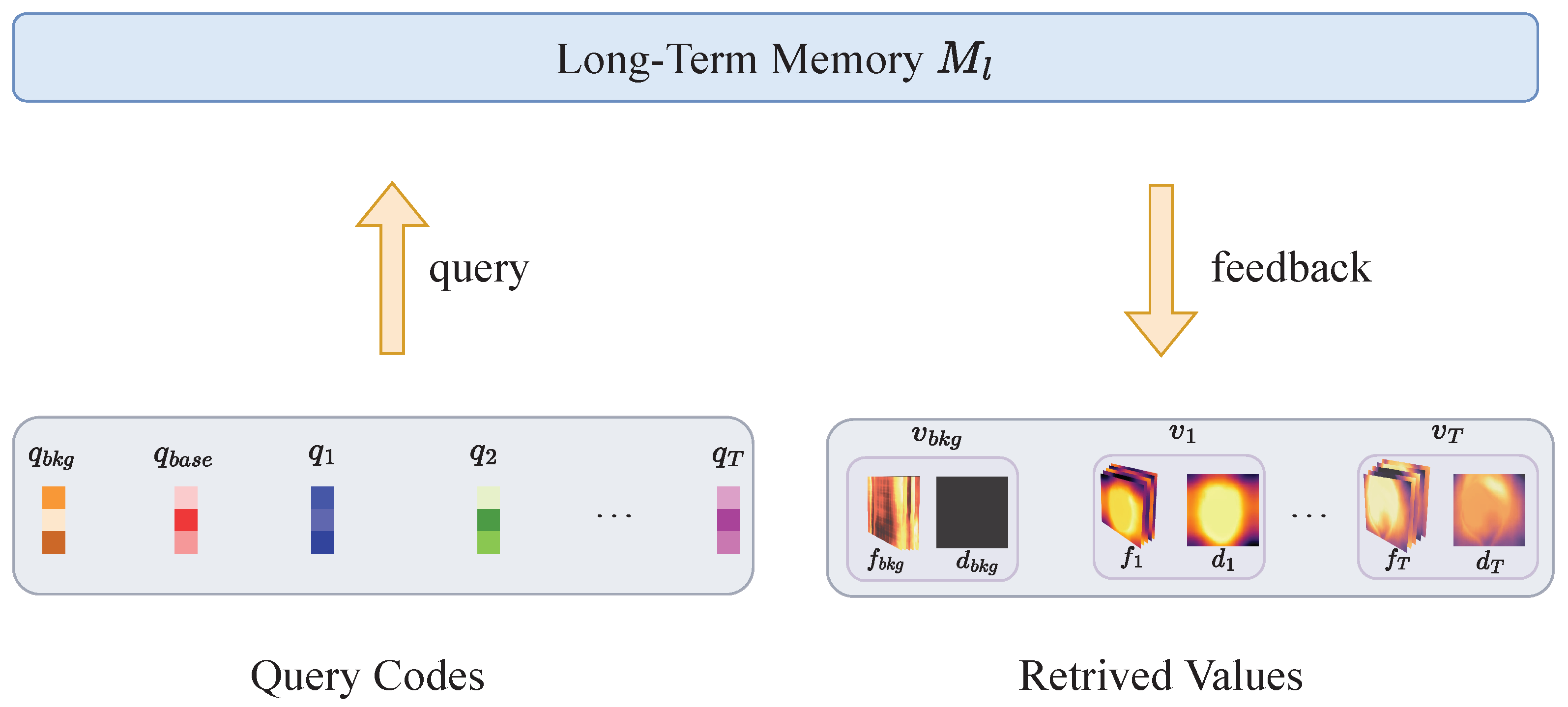
In this work, we propose MemoryGAN as a solution to overcome these limitations. MemoryGAN employs a memory system consisting of a long-term memory and a working memory. The long-term memory is a GAN generator, serving as a centralized memory to store information about all the parts. To address the mode collapse issue mentioned earlier, we introduce the working memory, which comprises an auto-regressive model that captures the dependencies between parts and generates the query code for the long-term memory. Consequently, the query vector fed into the long-term memory is conditionally sampled based on previous samples. This enables our model to avoid sampling at non-smooth boundaries between parts, effectively mitigating mode collapse issue. Despite using a single generator for all parts, our experiments demonstrate that MemoryGAN achieves comparable performance to state-of-the-art models that employ multiple generators, both in terms of image quality and compositional ability.
MemoryGAN offers three key advantages. First, the parameter count required for parts remains constant, ensuring scalability. Second, all parts are modeled within a single generator, facilitating the interaction between parts and enabling parameter sharing. This aspect is crucial for out-of-distribution generalization. Third, as a memory system, MemoryGAN features a flexible query and feedback mechanism, making it convenient to transfer learned representations to new tasks. We believe that our approach of utilizing the GAN generator as a memory model will pave the way for future research on both biologically inspired models and memory-augmented models. Our contributions in this work are summarized as follows:
We propose a compositional image synthesis model that explicitly models each component of the object. Our model is more interpretable and enables individual control over the attributes of each semantic part with minimal impact on other components.
We propose a method that utilizes a single generator for all semantic parts, making our model scalable. We extensively conduct experiments to evaluate the performance of our model and demonstrate that it achieves comparable results in terms of image quality and compositional ability to state-of-the-art approaches that employ multiple generators.
We demonstrate that the generator of a GAN can serve as a heterogeneous memory model and present MemoryGAN that mimics humans’ long-term memory and working memory system. Our work has the potential to inspire future research in the development of bio-friendly models and memory-augmented models.
2. Related Work
There are three features of our model: compositional image synthesis; iteratively generating images; and using a memory model to store and retrieve information. In this section, we will review related works from these three aspects.
Compositional Image Synthesis Composition can occur at different levels depending on how the underlying generative factors are disentangled. One approach is to disentangle the generation factors into a background, a foreground shape and a foreground appearance [
19,
20]. This line of work is usually performed under an unsupervised manner or with the bounding box information to disentangle the foreground object with the background. Different from these models, we are interested in fine-grained disentanglement and composition under supervision. Another line of work tries to decompose scenes or objects into meaningful parts [
11,
21], with [
11] or without [
21] supervision. Unfortunately, the work in [
21] can only disentangle large parts on the face dataset, such as background, skin and hair. Their disentanglement quality is low and needs to carefully chose the total part count to match the ground truth. Although SemanticStyleGAN [
11] achieves high quality part level disentanglement and composition, they use a separate local generator for the generation of each part, while our MemoryGAN uses a single generator for the generation of all the parts, which makes the generator flexible and suitable as a memory model.
The world is intrinsically three-dimensional. Many researchers have recently taken this fact into account for image generation [
22,
23,
24]. The work in [
22], known as NeRF, achieves impressive 3D scene rendering. There, given enough 2D images of one scene taken from various viewpoints, the 3D scene is molded as a neural radiance field, which maps the point location and the camera view direction into a volume density and a color value. Images with novel viewpoints can be generated by volume rendering along a novel camera view direction. GRAF [
23] extends NeRF to generate novel objects by conditioning the generator with a set of random codes for the camera view direction and the object shape and appearance. GIRAFFE [
24] further extends the model to handle multiple objects and achieves better control of rotation and translation. The work in these papers is promising, but their disentanglement is at the object level, while we are interested in disentanglement at the semantic part level and emphasize the usefulness of the GAN generator as a memory model.
Iteratively Generate Images Iteratively generating images has a long history in the literature [
25,
26,
27,
28,
29,
30,
31]. Auto-regressive models [
6,
32] generate images pixel by pixel, where the sampling for current step is conditioned on the previous sampling. The work of [
25] provides a recurrent attention model (RAM) to mimic a human’s glimpse process, in which information is accumulated piece by piece through a sequence of attention steps. DRAW [
26] and its follow-up convolutional version [
27] extend this idea to a generative model. Their work can be viewed as an extension of a variational auto-encoder [
5], where the encoder and the decoder are recurrent neural networks. They use a differentiable read and write head to determine where to read, where to write and what to write; as a result, images are drawn on a canvas matrix step by step. Instead of iteratively generating the images, a recently proposed work, PEGANs [
33], adopts evolutionary computing techniques to iteratively refine a set of generators. The main difference between these works and ours is that there is no disentanglement in the generation process of these works.
Another line of work considers the fact that a scene usually composes multiple objects. AIR [
28] and its follow-up work [
29] represent the object with a what code, a where code and a scalar value that represents the presence probability. One object is generated at each step until all the objects are generated. MONet [
31] uses an attention network to generate a mask for each object. They use this mask to control what object to generate and where the object is located. IODINE [
30] uses a spatial Gaussian mixing model to encode the “where” and “what” information of the object. The parameters of the spatial Gaussian mixing model are updated using iterative amortization [
34], which is helpful to disentangle ambiguous objects by leveraging both bottom–up and top–down signals.
These models differ from ours presented in this paper in the following three aspects. First, they are all built upon VAE models, which needs an encoder network to encode the distribution of the statistic layer. Our model is mainly built upon a GAN; thus, there is no encoder network in our model. Second, although these models achieve disentanglement during image generation, their disentanglement is at the object level, while our model is concerned with disentanglement at the semantic part level. Third, these models consider the “where” information of objects: although an important factor to consider and definitely worth exploring, it inevitably complicates the model. Thus, they are only feasible on simple datasets, and there is no evidence that their model can scale to real-world and high-resolution image generation.
Memory Models There are a large number of memory models published in the literature. Early work dates back to the associative memory models, such as the hopfield neural network [
35] and sparse distributed memory model [
36]. The notion of association there means that given a part of the query information, the whole information can be retrieved from the memory. Those works only focus on memory itself and do not consider how to use the memory to perform compositional learning. With the rise of deep learning, several memory-augmented neural network models are developed [
37,
38,
39,
40]. NTM [
39], and the follow-up work DNC [
40] maintains an external memory with differentiable read and write heads. These read and write heads are controlled by a recurrent neural network (RNN) [
41,
42]. Their work shows that the model can learn to use the memory to solve tasks that need reasoning, such as copy, sorting and shortest path search. Different from these models, our memory model is actually a GAN generator. Compared with these deterministic memory models, the generative memory model has several advantages. First, it does not passively store information but is able to generate novel information that have never been seen. Second, it embeds the entities in a smooth manifold. This property is evidenced by style-based GAN models [
9]. Given two images, we can generate smoothly changing images by linearly interpolating the latent codes, which means the latent space representing the images is smooth. This property is beneficial for out-of-distribution generalization and association since, given a latent representation, it is possible to find a similar but different latent representation near it. Recent work also treats the generator of GAN as a memory model [
43,
44], but these models focus on lifelong learning [
45]. They leverage the generative nature of GAN to perform pseudo-rehearsal to solve a catastrophic forgetting problem [
46], which is not our focus in this paper.
4. Experiments and Results
4.1. Dataset and Training Method
Our experiments are performed on the CelebAMask-HQ dataset [
49], which consists of 30,000 facial images with size 512 × 512; all images are annotated with 19 classes of segmentation masks. Following SemanticStyleGAN [
11], the first 28,000 images resized to 256 × 256 are used for training. Thirteen segmentation masks are selected for semantic supervision, which are background, skin, eyes, eyebrows, nose, mouth, ears, hair, neck, cloth, eye glass, hat and ear ring. The values of the images and the segmentation masks are normalized to range [−1, 1] before being fed into the network.
As for training, we use the identity setting with SemanticStyleGAN. Specifically, we use an Adam optimizer [
50], with
. The learning rate is 0.002 for all the modules except for the LSTM sub-module, as we found that the learning rate of 0.002 is too large for LSTM and it tends to cause a gradient spike. So, we reduce it to 1
. The path length regularization and
regularization are performed every 4 and 16 iterations, respectively. The weight factors for
and
are set to 100 and 1
, respectively. The style mixing is performed during training with a probability of 0.3. Our experiments are executed on a single RTX3090 GPU, and we use the largest batch size that can fit our VRAM. We use a batch size of 16 with a gradient accumulation every two steps. We train our model for 150,000 steps, and it took about 7 days.
4.2. Model Complex Comparison
As we use the same discriminator as SemanticStyleGAN, for clarity, we compare the model complexity based on the generator for both models. Algorithm 1 and Algorithm 2 show the inference algorithm for SemanticStyleGAN and MemoryGAN, respectively. In both algorithms, we use the same symbols as in
Section 3.2 and
Section 3.3, with the exception that we omit the spatial dimension in the calculation of the coarse mask for clarity (line 6 in Algorithm 1 and line 20 in Algorithm 2).
| Algorithm 1: Inference algorithm of SemanticStyleGAN |
![Electronics 12 02927 i001]() |
The main difference between our model and SemanticStyleGAN is in line 12 and 18 of Algorithm 2. In line 12, we utilize an LSTM module to model the dependency between the part query codes, which enables us to use a single local generator for generating all the semantic parts, as shown in line 18. As both the LSTM module and the local generator are shared, the complexity with respect to model size is , which makes our model efficient and scalable. In contrast, SemanticStyleGAN employs a single latent code to modulate a set of local generators, as shown in line 4 of Algorithm 1. It is easy to see that the complexity with respect to model parameters is for SemanticStyleGAN. This makes the model impractical when the semantic parts count is large. Another advantage of our algorithm is that we associate each semantic part with a query code (line 4 and line 15), and all part information is stored in a shared memory—the local generator—which can be retrieved by providing the query code, eliminating the need to determine which local generator should be used for storage or retrieval of the part information (line 18). In contrast, as depicted in Algorithm 1, SemanticStyleGAN uses a separate local generator to model each semantic part (line 4), requiring additional effort to determine the appropriate generator for retrieval or storage of the semantic part information, which is inflexible.
It should be noted that the computational complexity of both models is . More effort is needed to further reduce the compositional complexity. One promising direction is to consider taxonomy and use a hierarchy of latent codes to modulate the shared generator. We leave this topic to our future research.
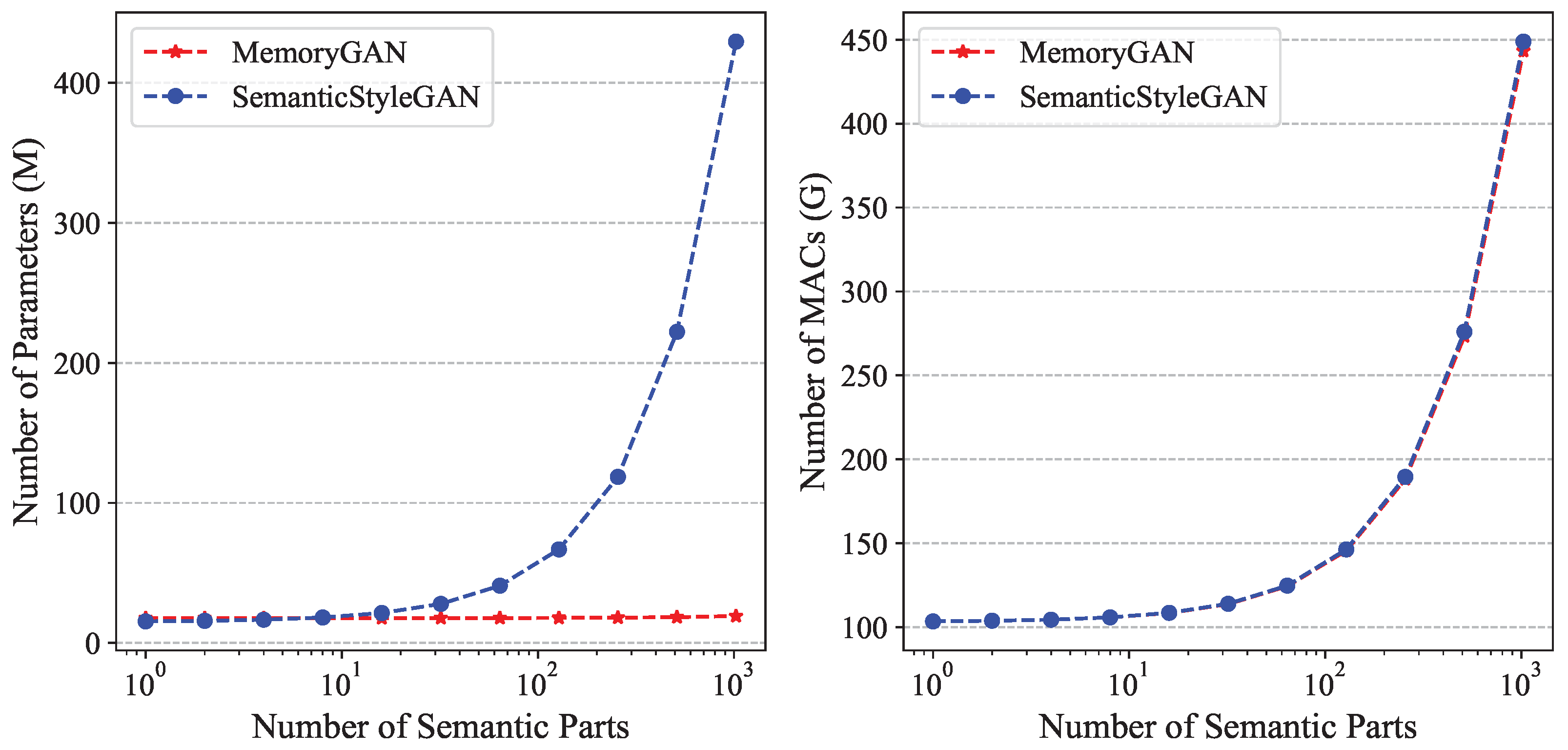
Table 1 and
Figure 7 show the real parameter count and Multiply–Accumulate operations (MACs) count with respect to semantic part count. It can be seen in
Table 1 that for the parameter count, MemoryGAN has a small overhead for one semantic part (2.3 M) compared to SemanticStyleGAN. However, as the semantic parts count grows, the parameter count for MemoryGAN only increases slightly, whereas for SemanticStyleGAN, it grows dramatically. With 1000 semantic parts, the parameter count for SemanticStyleGAN is over 20 times larger than that for MemoryGAN. This trend is more clearly depicted in
Figure 7. The difference in parameter count between SemanticStyleGAN and MemoryGAN becomes obvious when the semantic part count exceeds 10. In accordance with previous analysis, the MACs count reveals that both models exhibit similar trends. The MACs count increases significantly when the semantic part count exceeds 10, indicating that it remains an open problem that requires further exploration in future work.
| Algorithm 2: Inference algorithm of MemoryGAN |
![Electronics 12 02927 i002]() |
4.3. Image Quality Evaluation
We first evaluate the image quality generated by MemoryGAN.
Figure 8 shows the generated images and semantic masks by our model. We can see that MemoryGAN is able to generate perceptually high-quality images and correct segmentation masks. To quantitatively measure the quality of the generated images, we calculate the Fréchet Inception Distance [
51] and Inception Score [
52]. We compare our results with that reported in SemanticStyleGAN [
11].
Table 2 shows that compared with SemanticStyleGAN and SemanticGAN [
17], our model achieves comparable FID (the lower the better) and slightly lower IS (the higher the better) values, indicating that our model is able to generate comparable fidelity images.
For the CelebAMask-HQ task, SemanticStyleGAN uses 13 local generators, and each controls one semantic part generation. On the contrary, our model only uses a single local generator (the long-term memory in our architecture). One insight of our result is that it is possible to hold all the heterogeneous parts information in a single generator and then recall and composite them together to form high-fidelity images. So, it is unnecessary to use a separate generator for each part object. An interesting consequence of this result is that the single generator can be reasonably treated as a shared memory. Heterogeneous information can be stored in and retrieved from it. We believe this will lead to future work on both bio-friendly models and memory augmented models.
4.4. Sequential Composition
SemanticStyleGAN [
11] exhibits an impressive sequential composition property. Starting from the background, each part is sequentially added for composition. This method intuitively demonstrates both the compositional property and the disentanglement property of the model. It is interesting to see to what extent MemoryGAN preserves this desirable property using only a single generator. Our evaluation results are shown in
Figure 9.
Figure 9a displays the results of SemanticStyleGAN, while
Figure 9b shows the results of MemoryGAN. In each sample of the figure, the composed images are shown in the top row, which is followed by the depth maps in the middle row and the segmentation masks in the bottom row. It can be observed that for both models, new parts are sequentially added with minimal disturbance to the previously added parts. The depth maps largely correspond to their respective semantic parts, and the segmentation masks align well with the added semantic parts. These results indicate that MemoryGAN achieves comparable performance to SemanticStyleGAN. It is worth noting that there is no depth map supervision in the training data, yet both models are able to learn the depth maps automatically. We believe this phenomenon provides evidence of the advantages of compositional-aware models. The key to a compositional model is to express the whole object as a composition of its parts. This prior encourages the reuse of learned features by recombining them with different configurations to form new objects. Driven by this reusability prior, the models tend to learn the complete part from occluded parts images, as the complete part is more general and reusable compared to the occluded part. Additionally, guided by the recombination prior, the models tend to learn a configuration strategy to express the occlusions of the parts. The depth maps simply represent the learned configuration strategy.
Although it is difficult to see the change of the previous part when a new part is added with the human eyes, a closer inspection reveals that there is still interference between them. For example, the jaw is slightly changed when a neck is added in both, as shown in
Figure 9a,b. This indicates that there is still an entanglement between parts. To quantify the entanglement strength, we provide a metric called Sequential Mean Square Error (SMSE), which is defined in Equation (
15).
where
i is the sequence index,
are the spatial height and width index, respectively,
is the image pixel value at location
at step
i, and
is the mask value at location
of the
j-th part at step
i. Intuitively, it describes the varying intensity of the original image when the
i-th part is added. A lower value of SMSE indicates a smaller entanglement between current part with the parts previously added.
The SMSE results are shown in
Figure 10 and
Table 3. It can be seen that both SemanticStyleGAN and MemoryGAN have a relatively larger SMSE value when the skin and hair are added, indicating that there is entanglement in both models, especially for the larger parts. The SMSE value of MemoryGAN is slightly higher than that of SemanticStyleGAN, which is expected. As MemoryGAN uses a single generator for all the parts, there should be stronger interaction between the parts than its multi-generator counterpart.
4.5. Latent Space Property
In this section, we study the latent space property of MemoryGAN through style mixing, interpolation, low-dimensional embedding and correlation.
Style Mixing Style mixing means the information encoded in the latent code of one sample can be transferred to another sample by swapping the latent code on certain layers of the generator. Meaningful style mixing requires the latent codes to be disentangled, so that when swapping the latent code, only certain property is changed. As MemoryGAN is able to control the composition at a semantic part level, we also evaluate its style-mixing property at this level. The results are shown in
Figure 11. It can be seen that MemoryGAN is able to mix the styles for most of the parts. However, there are some disadvantages of using MemoryGAN on this task. One disadvantage is that we found it is not enough to swap the latent code for the layers of shape and texture in
to transfer the style information for smaller parts, such as the eyebrows, the mouth and the nose. We have empirically found that we have to swap the latent code for the base layer in
, too. Here, we additionally swap the latent code for the last base layer for the small parts. This is probably due to the fact that the smaller part occupies fewer spatial regions. Hence, fewer neurons are involved to encode their information. MemoryGAN learns to compensate for this disadvantage by encoding the information of the smaller part in more layers in
. Another disadvantage is that there is entanglement for the face parts, especially for the eyes. It can be seen from
Figure 11 that the eye color is not affected if we only swap the eye latent code. On the other hand, the eye color is affected by the skin or the hair. This indicates that the eye color is entangled with the colors of the skin and hair. It is actually well known that the colors of the eyes, skin and hair of the human are strongly correlated [
53]. Their colors are determined by the same thing: that is, the amount of pigment in the body. We conjecture that both the design of using a single generator and the explicit dependency modeling in the
module make MemoryGAN sensitive to these dependence and bias in the dataset. MemoryGAN captures this dependency and uses the hair and skin latent code to model the color of the eyes to save memory resources. This conjecture is supported by the results in
Section 4.6.1. Considering the result that MemoryGAN is able to disentangle and mix styles for most smaller parts, we believe it is possible to achieve full disentanglement and style mixing with further development. We leave this problem for our further research.
Interpolation Latent code interpolation reflects both the smoothness and disentanglement property of the latent space. We interpolated the main parts of the face image, and the results are shown in
Figure 12. Similar to the results of style mixing, we have empirically found that only interpolating the shape and the texture latent code for the small parts usually results in tiny changes to the image. To enhance the impact of the small part’s latent code, we additionally interpolate the latent code on the last base layer. It can be seen from the result that for both the whole image and the semantic part, the interpolated image changes smoothly. This indicates that both the whole latent space and the sub-space for each part are smooth in MemoryGAN. Similar to the style-mixing result, we also found that (a) there is an entanglement between parts, such as hair, eyebrows and eyes and (b) the latent code for the eyes seems to mainly control the shape and is unable to control the color. The color is mainly controlled by larger parts such as the skin and the hair.
Low-Dimensional Embedding As MemoryGAN uses a single generator for all the parts, the latent codes lie in the same semantic space. This allows us to analyze the relationship between the parts directly through the latent codes themselves. On the contrary, we cannot directly analyze the latent codes for SemanticStyleGAN, because each latent code is designed for a specific local generator. Therefore, the latent codes have to be analyzed with the generators together. For example, the same latent code can be applied to different local generators in SemanticStyleGAN, and this produces different semantic parts.
A straightforward analysis is to visualize the latent codes in a two-dimensional space. We use the t-SNE [
54] algorithm for dimension reduction. The results are shown in
Figure 13. It can be seen that in the query space, parts are already pretty well grouped. We can also observe that the parts generated in succession are more closely grouped, such as the skin and the eyes, the eyebrows, and the mouth. This reflects the fact that the LSTM module in
captures the dependence between successive parts. On the contrary, all the parts are well separately grouped in the latent space. This indicates that the latent space is flatter than the query space, and it is also more disentangled than the query space.
Correlation between Parts t-SNE is particularly suitable for encoding the local structure of data points. In other words, if two codes are similar enough, they should be grouped together. It tells less about two codes, which are not similar but may be correlated. So, we also calculate the correlation between parts by pairwise cosine similarity. The results are shown in
Figure 14. We can see that the correlation between parts is much weaker in the query space than in the latent space. We hypnosize that this is because the roles of the query code and the latent code are different in MemoryGAN. The role of the query code is to tell the long-term memory what information is needed. So, the codes should be distinguishable, and thus, weaker correlation is helpful. On the other hand, the latent code is used to modulate the generator to produce the features. It is critical for the latent code to be informative. As correlation reflects the structure of the data, it is beneficial for the latent codes to be more strongly correlated. Now, we focus on the details of the correlation matrix. We can see from
Figure 14 that in the query space, there is a relatively stronger correlation in the nearby parts. The order of the parts in the correlation matrix matches the order in which they are generated in the working memory. The result shows that our working memory captures the dependency of the consecutive parts successfully. Compared with the query space, there is a much stronger correlation in the latent space between facial parts, such as the correlation between the eyes, eyebrows, mouth and ears. As mentioned above, we believe this result indicates that the latent code encodes the structure of the face much better than the query codes.
4.6. Controlled Image Editing
4.6.1. Text Driving Image Editing
One advantage of the semantic part compositional model is that we can edit the attribute of one part individually with no or little affect on the attribute of other parts.
Figure 15 shows the results of part attribute editing using the StyleCLIP [
55] optimization method. Given a description of the image using natural language, StyleCLIP is able to modify the image to match the description. StyleCLIP uses three losses defined below for optimization:
where
w is the latent code for optimization,
t is the text prompt,
is the source latent code, and
G is the generator. As MemoryGAN generates both the image and segmentation mask, we use subscript
and
to distinguish them.
is the CLIP loss [
56]. It measures the cosine distance between the CLIP embedding of the image and the text prompt.
represents identity loss [
57] and is defined below:
where
F is a pre-trained ArcFace [
58] network and
represents the cosine similarity between its arguments. In MemoryGAN, the parts are usually spatially separated. It is, therefore, possible that the optimized latent code for a part may change too much and thus affect nearby parts. To control this interference, we add a segmentation loss term, so that the final loss is:
The result of attribute editing using StyleCLIP is shown in
Figure 15. For skin, eyebrows, mouth, nose and hair, we only allow optimizing the corresponding part latent code, while the latent codes of other parts are fixed. The results show that StyleCLIP is able to edit the attribute of these parts individually with little effect on other parts. Similar to the results in
Section 4.5, we find that we are unable to control the color of the eyes through the latent code of the eyes. To verify the previous conjecture that the color of the eyes may be strongly entangled with the colors of the skin and the hair, we only allow optimizing the latent code of the skin and hair for a text prompt that aims to change the color of eyes, such as “a person with blue eyes”. The results show that we can achieve the desired eye color editing, and the colors of the skin and the hair change correspondingly. For “blue eyes”, the skin tends to be “white” and the hair color tends to be “red” or “blonde”. This results is consistent with our conjecture.
4.6.2. Localized Attribute Editing
One advantage of compositional image synthesis models is their ability to offer a higher level of control and editing over images. In this section, we compare our model with the seminal work of StyleGAN2 [
9] in the context of localized attribute editing. We first invert the original image into the latent space of StyleGAN2 and MemoryGAN using e4e [
59], and then, we utilize the optimization method of StyleCLIP [
55] to edit the attributes. Each attribute uses the same text for editing, and we showcase the results after 300 optimization steps. Specifically, we use “a man with a beard” for beard attribute editing, “a man with gray hair” for hair attribute editing, “a smiling woman” for mouth attribute editing, and “a woman with a big nose” for nose attribute editing. The results are displayed in
Figure 16. It is evident that our model achieves significantly better localization for all attributes, particularly for small parts such as the nose and mouth, in comparison to StyleGAN2. Our model demonstrates precise control over attribute editing, wherein modifying one attribute of a semantic part has a small impact on other parts. These results highlight the fine-grained control that our model provides.
We have observed that StyleGAN2 tends to generate darker images when used in conjunction with StyleCLIP. We conjecture that this behavior can be attributed to the fact that StyleGAN2 employs a single latent code to generate the entire image, which makes it challenging for StyleCLIP to accurately identify the corresponding semantic meaning of a word (e.g., hair) in the latent space. The blind search in the latent space may lead to an erroneous penalization of image appearance, resulting in darker outputs. In contrast, our model utilizes a set of latent codes to modulate the generator, with each latent code corresponding to a specific semantic meaning. Consequently, it becomes much easier for StyleCLIP to identify the corresponding latent code for a given word, leading to improved results.
One way to quantitatively assess the localization property is by calculating the percentage of preserved pixels required to achieve a certain amount of reduction in CLIP loss [
56]. In this evaluation, we utilize
loss between the inverted image and the edited image to measure the difference between the images. Additionally, we use the complement of the
loss to determine the percentage of preserved pixels after editing. The results are displayed in
Figure 17, where the term “score gain” refers to the reduction in CLIP loss. Notably, our model consistently achieves a significantly higher percentage of preserved pixels, particularly for editing small semantic parts, which aligns with previous findings. Although StyleGAN2 tends to yield lower CLIP loss, it does so at the expense of affecting unrelated areas in the images, as demonstrated in
Figure 16.
4.6.3. Comparison with Layout-to-Image Model
Another research direction that explores semantic control is layout-to-image generative models, which map layouts to corresponding images. In this section, we have chosen the representative model SEAN [
10] for comparison. As discussed in
Section 1, the primary limitation of these models is their reliance on input layouts and inability to generate images from scratch. Another consequence of this limitation is that these models can only automatically transfer the texture of the image and require manual intervention to modify the shape. To validate this observation, we conducted style-mixing experiments for both SEAN and our model, and the results are presented in
Figure 18. We selected six images with diverse hair styles as source images and aimed to transfer these styles to a target image. With SEAN, style mixing can be constrained to a specific region (such as the hair region), allowing the transfer of hair texture to the target image. However, due to the shape being controlled by the input layout, SEAN cannot transfer the hair shape of the source image to the target image. In contrast, our model offers the flexibility to transfer hair styles either for the texture only or incorporate both shape and texture. By enabling the swapping of either just the texture code or both the shape and texture codes, we can achieve texture-level or shape-and-texture-level hair style transfers. These results clearly highlight the advantages of compositional-aware models.
5. Conclusions
Inspired by humans’ structured memory system, we present MemoryGAN, which is a compositional generative model for image synthesis. MemoryGAN consists of a long-term memory and a working memory. The long-term memory is a shared generator responsible for storing heterogeneous information about the parts. The working memory utilizes LSTM to model the dependency between the parts and generate query codes for the long-term memory. The retrieved part features are then combined in the working memory to produce the complete image. Despite employing a single generator for all parts, MemoryGAN achieves comparable image synthesis performance and compositional ability to state-of-the-art models that utilize multiple generators. The advantages of MemoryGAN are as follows: First, as a compositional model, it provides a higher level of control over the generation and image editing processes. Second, MemoryGAN utilizes a shared generator for all semantic parts, making the representation efficient and the model scalable. Third, as a memory system, its information retrieval mechanism is general, making it a suitable base framework for knowledge transformation. We believe that our approach, utilizing the generator of GAN as a memory model, will lead to future advancements in bio-friendly models and memory-augmented models. Furthermore, we anticipate that this memory framework will pave the way for addressing challenges in large-scale compositional image generation.
While our model achieves promising results in compositional image synthesis, there are still several challenges that need to be addressed in future work. First, MemoryGAN only reduces the parameter requirements for the semantic parts, while the computational complexity remains the same as SemanticStyleGAN. A promising solution to this issue is to consider taxonomy and use a hierarchy of latent codes to modulate the shared generator, thereby significantly reducing both the parameters and computational complexity. Second, MemoryGAN does not take into account the scale of the semantic parts, resulting in the need to process with the entire image resolution to generate a small part feature, which leads to unnecessary computation. This issue could potentially be resolved by introducing a hard attention mechanism. Last, MemoryGAN requires full supervision for the semantic parts. A valuable direction for future research would be to explore semi-supervised approaches.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}