
LPE-Unet: An Improved UNet Network Based on Perceptual Enhancement

Abstract
:1. Introduction
- We propose a new end-to-end segmentation network, LPE-UNet, which accurately segments calcium plaques in the coronary artery.
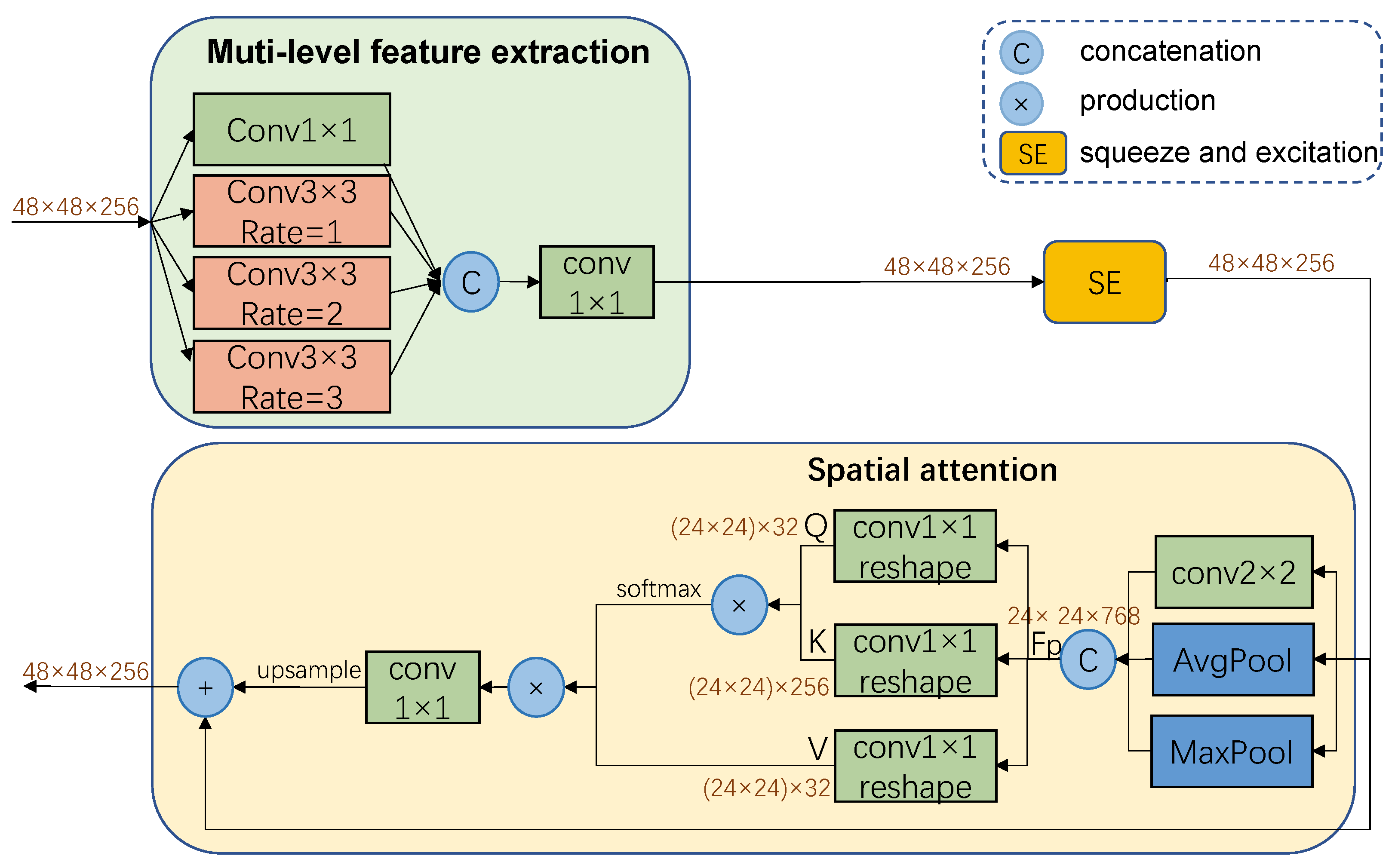
- We design a low-rank perceptual enhancement module (LPE), which adds the ability to capture and process multi-scale information to the model and establish global dependencies between local features. It can improve the segmentation accuracy.
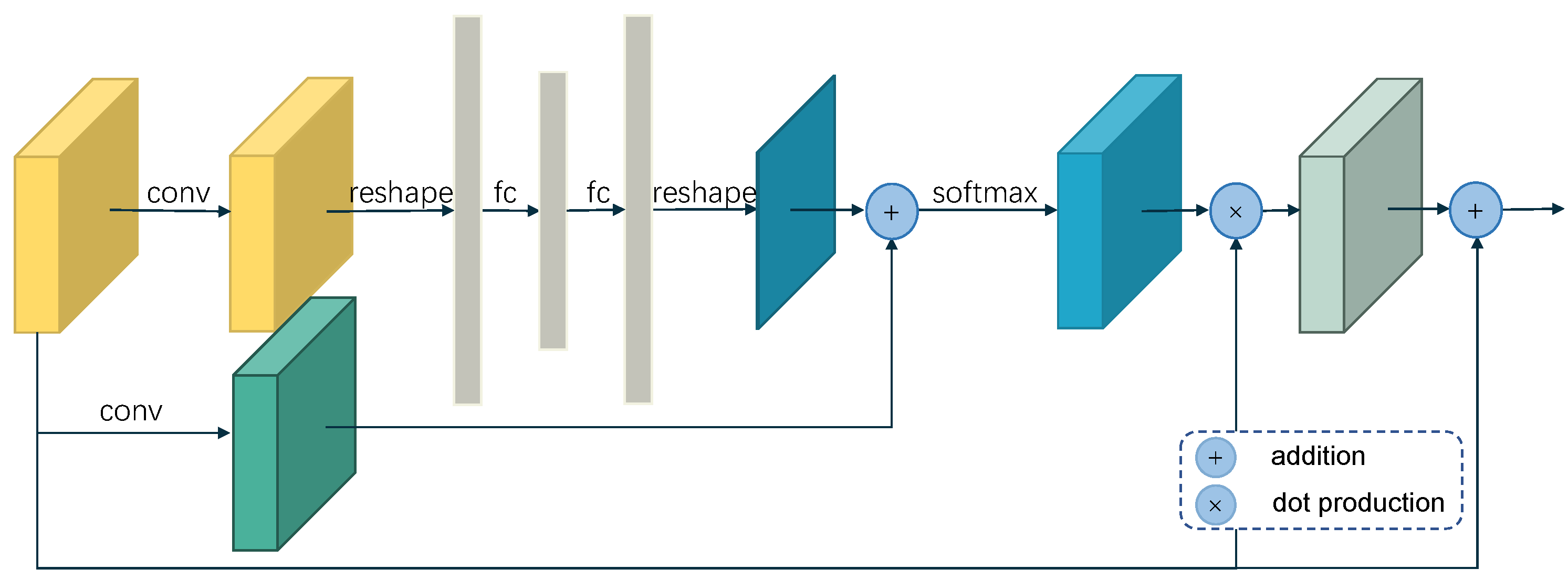
- By adding noise optimization modules to suppress noise information in skip connections, which use attention based gates to filter low-level features, We further improved the accuracy of network inference.
- Due to the small-scale characteristics of calcium plaques, class imbalance can easily occur during network training. We proposed a new weighting method that uses a combination of weighted cross-entropy and DiceLoss for mixed supervision training of the network, which effectively improves the stability of model training and prediction accuracy.
2. Related Work
2.1. Calcified Plaque Segmentation Algorithm
2.2. Medical Image Segmentation
3. Method
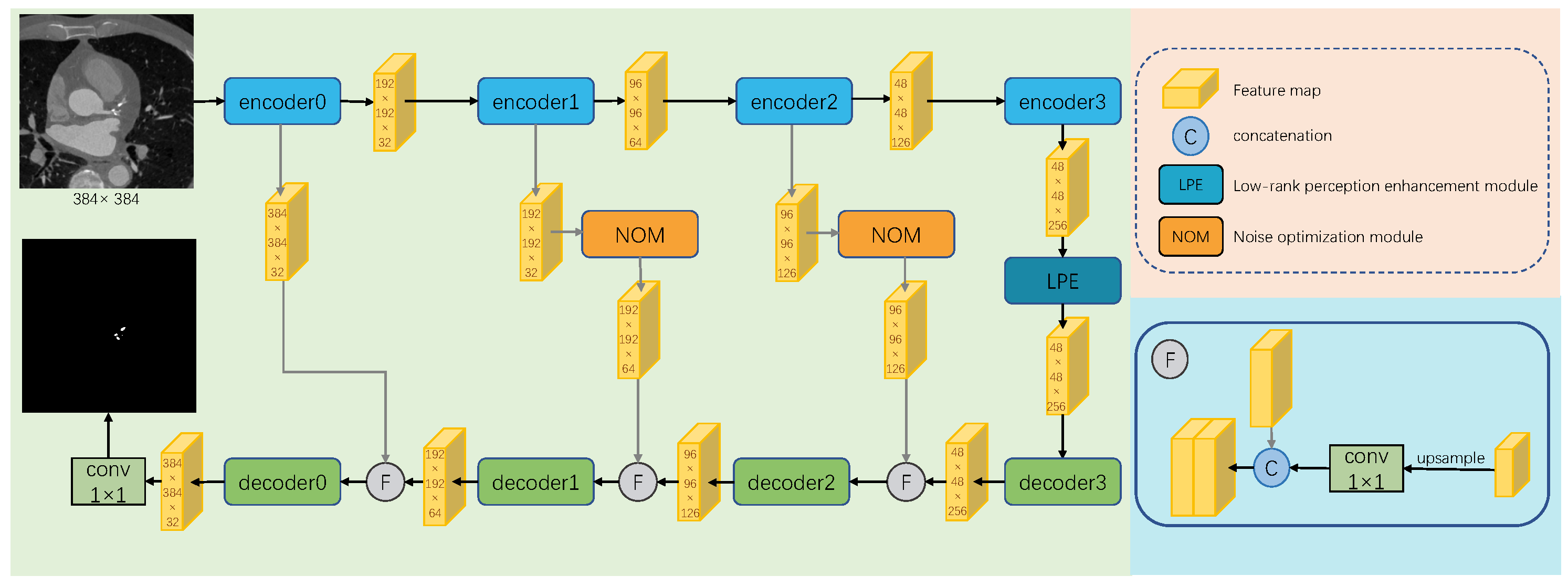
3.1. Overview of LPE-Unet
3.1.1. Low-Rank Perception Enhancement Module
3.1.2. Noise Optimization Module
3.2. Mixed Training
4. Experiments
4.1. Experiment Setting
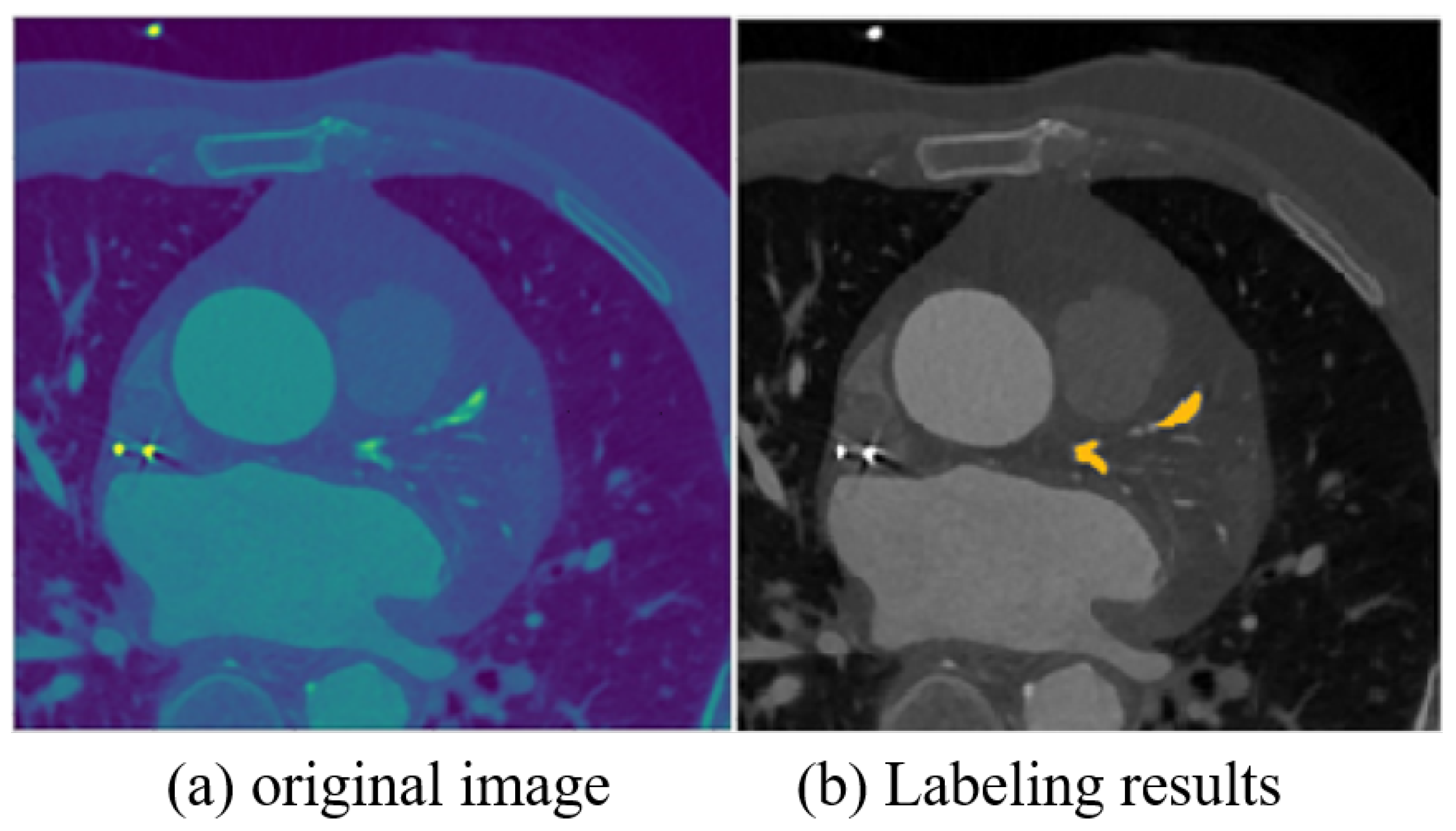
4.2. Dataset
4.3. Evaluation Index
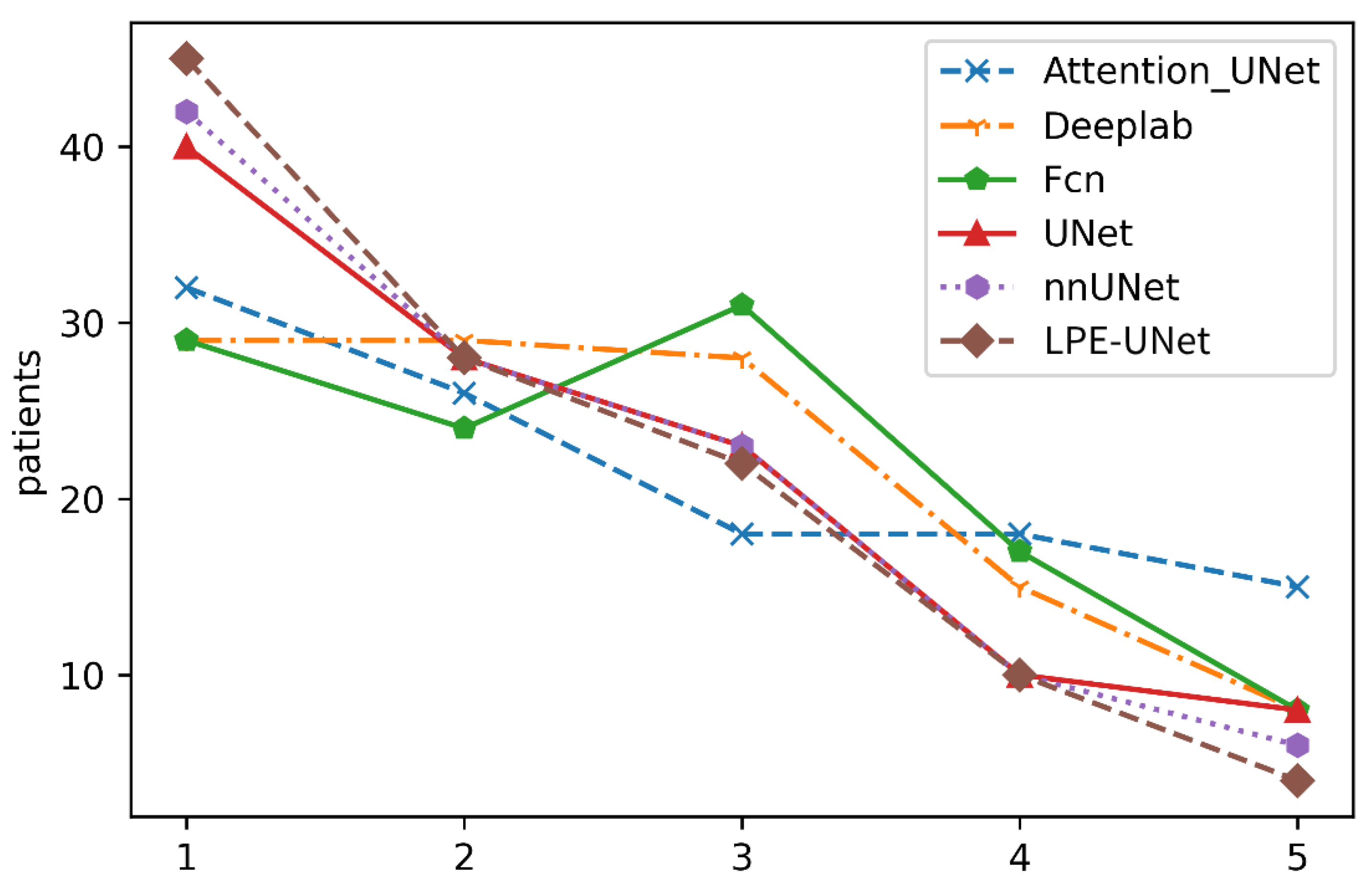
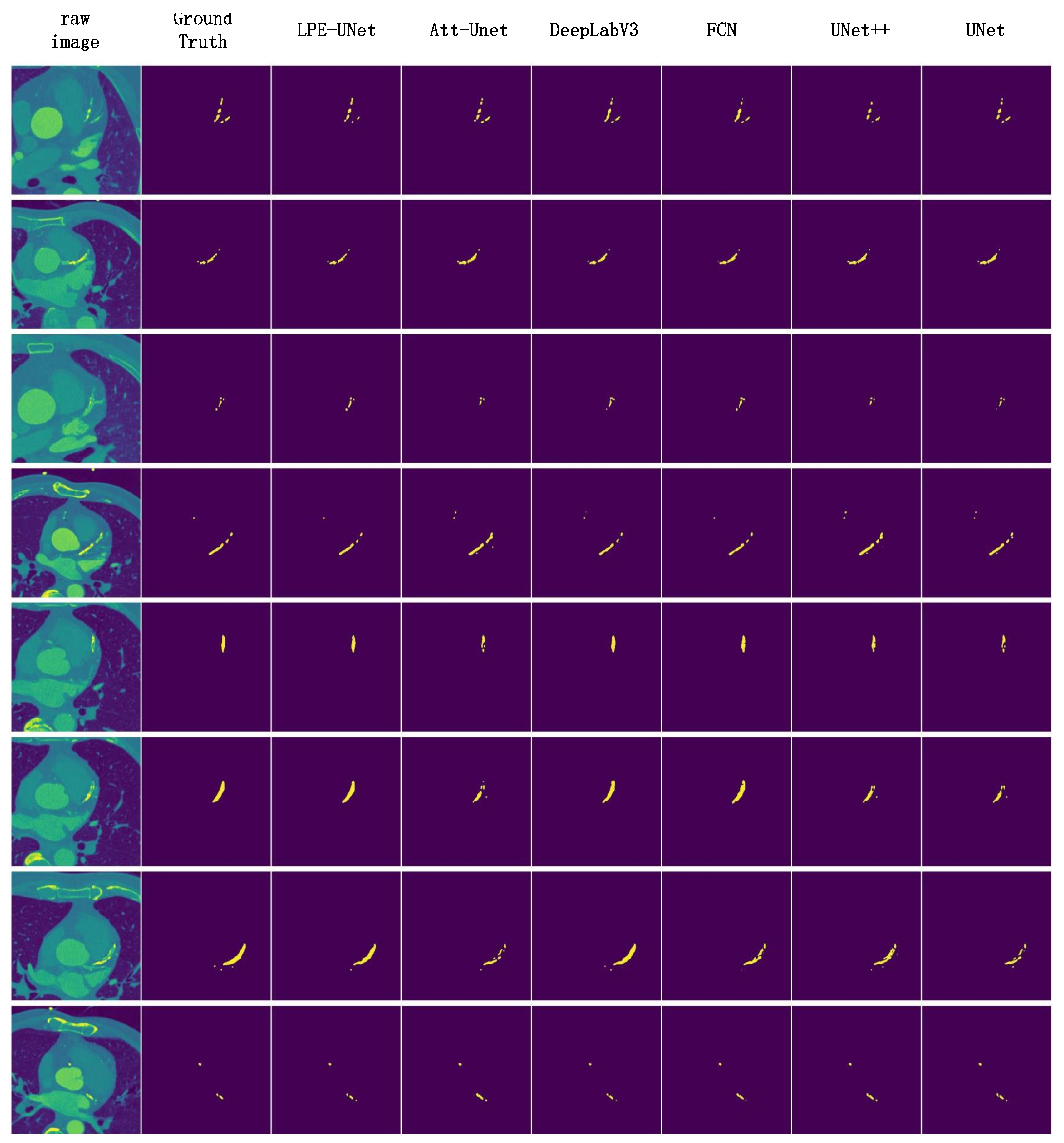
4.4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Virani, S.S.; Alonso, A.; Benjamin, E.J.; Bittencourt, M.S.; Callaway, C.W.; Carson, A.P.; Chamberlain, A.M.; Chang, A.R.; Cheng, S.; Delling, F.N.; et al. Heart disease and stroke statistics—2020 update: A report from the American Heart Association. Circulation 2020, 141, e139–e596. [Google Scholar] [CrossRef] [PubMed]
- Lessmann, N.; van Ginneken, B.; Zreik, M.; de Jong, P.A.; de Vos, B.D.; Viergever, M.A.; Išgum, I. Automatic calcium scoring in low-dose chest CT using deep neural networks with dilated convolutions. IEEE Trans. Med. Imaging 2017, 37, 615–625. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahim, T.; Usman, M.A.; Shin, S.Y. A survey on contemporary computer-aided tumor, polyp, and ulcer detection methods in wireless capsule endoscopy imaging. Comput. Med. Imaging Graph. 2020, 85, 101767. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- He, J.; Zhu, Q.; Zhang, K.; Yu, P.; Tang, J. An evolvable adversarial network with gradient penalty for COVID-19 infection segmentation. Appl. Soft Comput. 2021, 113, 107947. [Google Scholar] [CrossRef] [PubMed]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; p. 29. [Google Scholar]
- Gao, Z.; Hau, W.K.; Zhang, H.; Zhang, Y.T. Automatic Detection of Calcified Plaque with Acoustic Shadowing. In Proceedings of the International Conference on Health Informatics, Verona, Italy, 15–17 September 2014; Zhang, Y.T., Ed.; pp. 197–199. [Google Scholar]
- Yoshida, Y.; Fujisaku, K.; Sasaki, K.; Yuasa, T.; Shibuya, K. Semi-automatic detection of calcified plaque in coronary CT angiograms with 320-MSCT. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; pp. 1703–1707. [Google Scholar]
- Sun, Q.; Yang, G.; Shu, H. Calcified coronary plaques detection in CTA based-on automatic scale selection and fuzzy C means. In Proceedings of the 2016 International Conference on Machine Learning and Cybernetics (ICMLC), Jeju Island, Republic of Korea, 10–13 July 2016; Volume 2, pp. 807–813. [Google Scholar]
- Wolterink, J.M.; Leiner, T.; Viergever, M.A.; Išgum, I. An automatic deep learning approach for coronary artery calcium segmentation. In Proceedings of the MICCAI, Munich, Germany, 5–9 October 2015; Volume 9349. [Google Scholar]
- Lessmann, N.; Išgum, I.; Setio, A.A.; de Vos, B.D.; Ciompi, F.; de Jong, P.A.; Oudkerk, M.; Willem, P.T.M.; Viergever, M.A.; van Ginneken, B. Deep convolutional neural networks for automatic coronary calcium scoring in a screening study with low-dose chest CT. In Proceedings of the Medical Imaging 2016: Computer-Aided Diagnosis, San Diego, CA, USA, 27 February–3 March 2016; Volume 9785, pp. 255–260. [Google Scholar]
- Lekadir, K.; Galimzianova, A.; Betriu, A.; del Mar Vila, M.; Igual, L.; Rubin, D.L.; Fernández, E.; Radeva, P.; Napel, S. A Convolutional Neural Network for Automatic Characterization of Plaque Composition in Carotid Ultrasound. IEEE J. Biomed. Health Inform. 2017, 21, 48–55. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Santini, G.; Latta, D.D.; Martini, N.; Valvano, G.; Gori, A.; Ripoli, A.; Susini, C.L.; Landini, L.; Chiappino, D. An automatic deep learning approach for coronary artery calcium segmentation. In EMBEC & NBC 2017; Springer: Singapore, 2018; pp. 374–377. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. pp. 234–241. [Google Scholar]
- Shadmi, R.; Mazo, V.; Bregman-Amitai, O.; Elnekave, E. Fully-convolutional deep-learning based system for coronary calcium score prediction from non-contrast chest CT. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 24–28. [Google Scholar]
- Ma, J.; Zhang, R. Automatic calcium scoring in cardiac and chest CT using DenseRAUnet. arXiv 2019, arXiv:1907.11392. [Google Scholar]
- Zhang, W.; Zhang, J.; Du, X.; Zhang, Y.; Li, S. An end-to-end joint learning framework of artery-specific coronary calcium scoring in non-contrast cardiac CT. Computing 2019, 101, 225581–225593. [Google Scholar] [CrossRef]
- Lee, J.; Gharaibeh, Y.; Kolluru, C.; Zimin, V.N.; Dallan, L.A.P.; Kim, J.N.; Bezerra, H.G.; Wilson, D.L. Segmentation of Coronary Calcified Plaque in Intravascular OCT Images Using a Two-Step Deep Learning Approach. IEEE Access 2020, 8, 225581–225593. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.C.; Shen, T.Y.; Chen, C.C.; Chang, W.T.; Lee, P.Y.; Huang, C.C.J. Automatic Detection of Atherosclerotic Plaque and Calcification From Intravascular Ultrasound Images by Using Deep Convolutional Neural Networks. IEEE Trans. Ultrason. Ferroelectr. Freq. Control. 2021, 68, 1762–1772. [Google Scholar] [CrossRef] [PubMed]
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Weighted Res-UNet for High-Quality Retina Vessel Segmentation. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 327–331. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Dilated convolutions for brain tumor segmentation in mri scans. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Interventions (MICCAI), Quebec City, QC, Canada, 10–14 September 2017; pp. 253–262. [Google Scholar]
- Zhao, C.; Vij, A.; Malhotra, S.; Tang, J.; Tang, H.; Pienta, D.; Xu, Z.; Zhou, W. Automatic extraction and stenosis evaluation of coronary arteries in invasive coronary angiograms. Comput. Biol. Med. 2021, 1323, 104667. [Google Scholar] [CrossRef] [PubMed]
- Mu, N.; Lyu, Z.; Rezaeitaleshmahalleh, M.; Tang, J.; Jiang, J. An attention residual u-net with differential preprocessing and geometric postprocessing: Learning how to segment vasculature including intracranial aneurysms. Med. Image Anal. 2023, 84, 102697. [Google Scholar] [CrossRef] [PubMed]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Kaul, C.; Manandhar, S.; Pears, N. Focusnet: An Attention-Based Fully Convolutional Network for Medical Image Segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 455–458. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef] [PubMed]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Islam, M.T.; Khan, H.A.; Naveed, K.; Nauman, A.; Gulfam, S.M.; Kim, S.W. LUVS-Net: A Lightweight U-Net Vessel Segmentor for Retinal Vasculature Detection in Fundus Images. Electronics 2023, 12, 1786. [Google Scholar] [CrossRef]
- Peng, J.; Li, Y.; Liu, C.; Gao, X. The Circular U-Net with Attention Gate for Image Splicing Forgery Detection. Electronics 2023, 12, 1451. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non DL-Based Algorithms | DL-Based Algorithms | |
|---|---|---|
| Patch-Based Scoring | Pixel-Wise Segmentation | |
| Gao et al. [7] | Jelmer et al. [10] | Lekadir et al. [12] |
| Yoshida et al. [8] | Lessmann et al. [11] | Santini et al. [13] |
| Sun et al. [9] | Lessmann et al. [2] | Shadmi et al. [15] |
| Ma et al. [16] | ||
| Zhang et al. [17] | ||
| Lee et al. [18] | ||
| Li et al. [19] | ||
| Layer Name | Parameters | Output Size |
|---|---|---|
| encoder0 | conv3 × 3, 16 | 32, 192, 192 |
| conv3 × 3, 32 | ||
| maxpool2 × 2, stride2 | ||
| encoder1 | conv3 × 3, 32 | 64, 96, 96 |
| conv3 × 3, 64 | ||
| MaxPooll2 × 2, stride2 | ||
| encoder2 | conv3 × 3, 64 | 128, 48, 48 |
| conv3 × 3, 128 | ||
| MaxPooll2 × 2, stride2 | ||
| encoder3 | conv3 × 3, 128 | 256, 48, 48 |
| conv3 × 3, 256 | ||
| decoder3 | conv3 × 3, 256 | 256, 48, 48 |
| conv3 × 3, 256 | ||
| decoder2 | conv3 × 3, 128 | 128, 96, 96 |
| conv3 × 3, 128 | ||
| decoder1 | conv3 × 3, 64 | 64, 192, 192 |
| conv3 × 3, 64 | ||
| decoder0 | conv3 × 3, 32 | 32, 384, 384 |
| conv3 × 3, 32 |
| Model | F1 | Iou | Dice |
|---|---|---|---|
| UNet | 0.9272 | 0.8740 | 0.9328 |
| FCN | 0.9200 | 0.8673 | 0.9289 |
| DeepLabV3+ | 0.9278 | 0.8744 | 0.9330 |
| Attention-Unet | 0.9277 | 0.8747 | 0.9332 |
| Unet++ | 0.9207 | 0.8657 | 0.9280 |
| R2U_UNet | 0.8034 | 0.7400 | 0.8506 |
| nnUNet | 0.9310 | 0.8790 | 0.9356 |
| LPE-UNet | 0.9410 | 0.8950 | 0.9446 |
| Model | F1 | Iou | Dice |
|---|---|---|---|
| Baseline | 0.9319 | 0.8808 | 0.9366 |
| Baseline + MSF | 0.9365 | 0.8878 | 0.9406 |
| Baseline + MSF + AGate | 0.9386 | 0.8913 | 0.9425 |
| Baseline + LPE + AGate + Dice | 0.9401 | 0.8938 | 0.9439 |
| LPE-UNet | 0.9410 | 0.8950 | 0.9446 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Yuan, C.; Zhang, C. LPE-Unet: An Improved UNet Network Based on Perceptual Enhancement. Electronics 2023, 12, 2750. https://doi.org/10.3390/electronics12122750
Wang S, Yuan C, Zhang C. LPE-Unet: An Improved UNet Network Based on Perceptual Enhancement. Electronics. 2023; 12(12):2750. https://doi.org/10.3390/electronics12122750
Chicago/Turabian StyleWang, Suwei, Chenxun Yuan, and Caiming Zhang. 2023. "LPE-Unet: An Improved UNet Network Based on Perceptual Enhancement" Electronics 12, no. 12: 2750. https://doi.org/10.3390/electronics12122750