
Robust Adaptive Beamforming Based on a Convolutional Neural Network

Abstract
:1. Introduction
- Diagonal loading methods [8] augment the sample covariance matrix (SCM) with a coefficient-scaled identity matrix to enhance the system’s robustness to SoI mismatches and the finite snapshot effect. However, these methods require determining the optimal diagonal loading factor in various scenarios, which remains challenging.
- Feature subspace projection-based RBF [9,10], which projects the SoI steering vector onto both the noise and signal plus interference subspaces to mitigate interference. However, this method may struggle at differentiating between subspaces when the signal to interference plus noise ratio (SINR) is low.
- Convex optimization-based RBF extends the diagonal loading technique by obtaining the diagonal loading factor through an optimization problem. Different approaches have been proposed, including minimizing a quadratic function with non-convex quadratic constraints [11], shrinking the unbiased SCM [12], employing an iterative method to reduce the estimation error of the SCM [13], and obtaining the diagonal loading factor adaptively via a shrinkage method [14]. However, these methods often have a gap in output SINR compared to the optimal SINR and do not directly relate the adaptive weight vector to the scene’s error [15].
- Most DL-based ADBF methods utilize radiation patterns or direction of arrival (DoA) as the network input, resulting in undesired computational load and information loss. To solve this issue, we propose an end-to-end RBF network with a factored architecture.
- To account for real-world effects, such as the G/P errors of array channels and the shortage of available snapshots, our dataset incorporates various G/P errors and involves the calculation of input data using just a few snapshots.
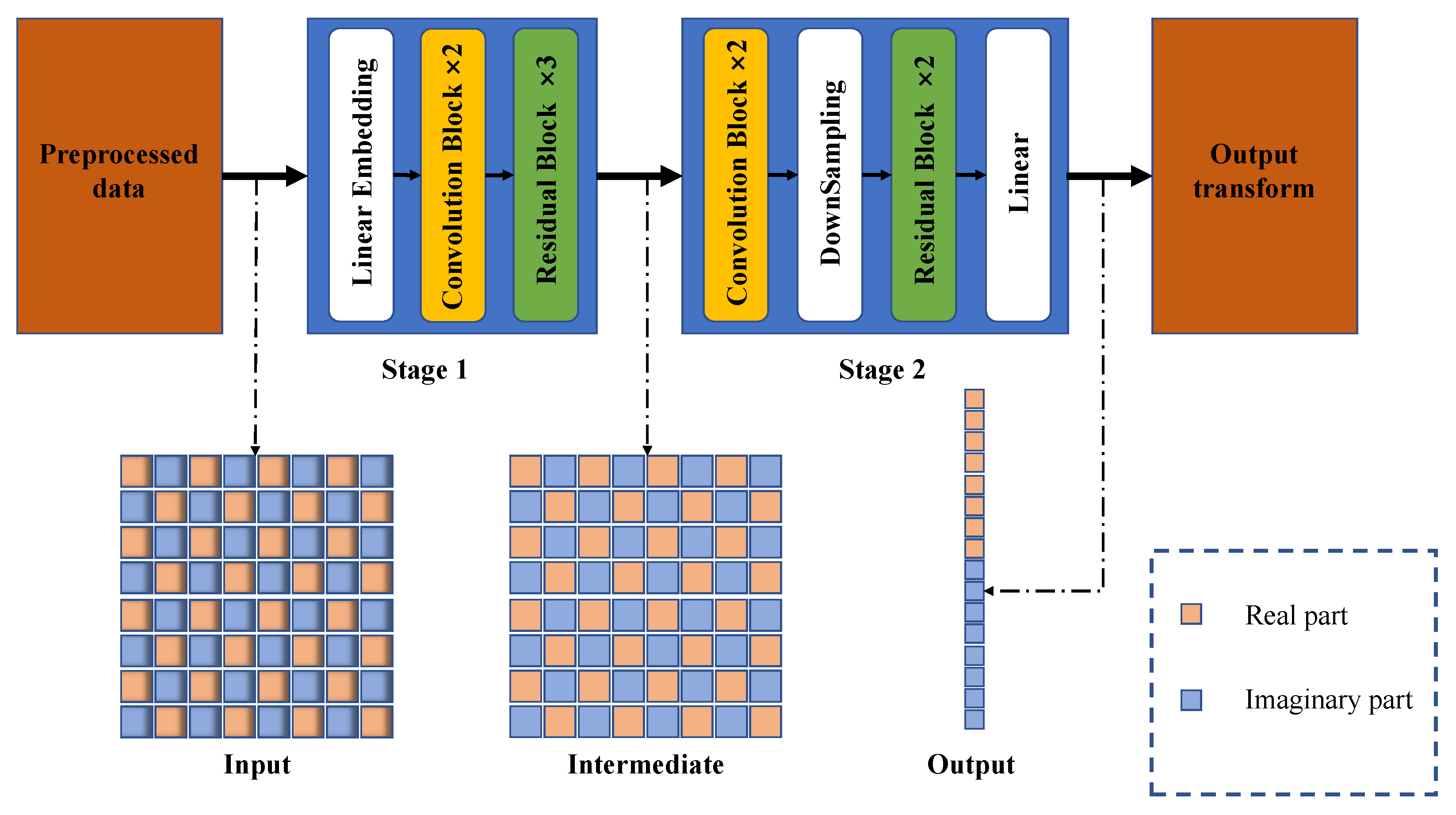
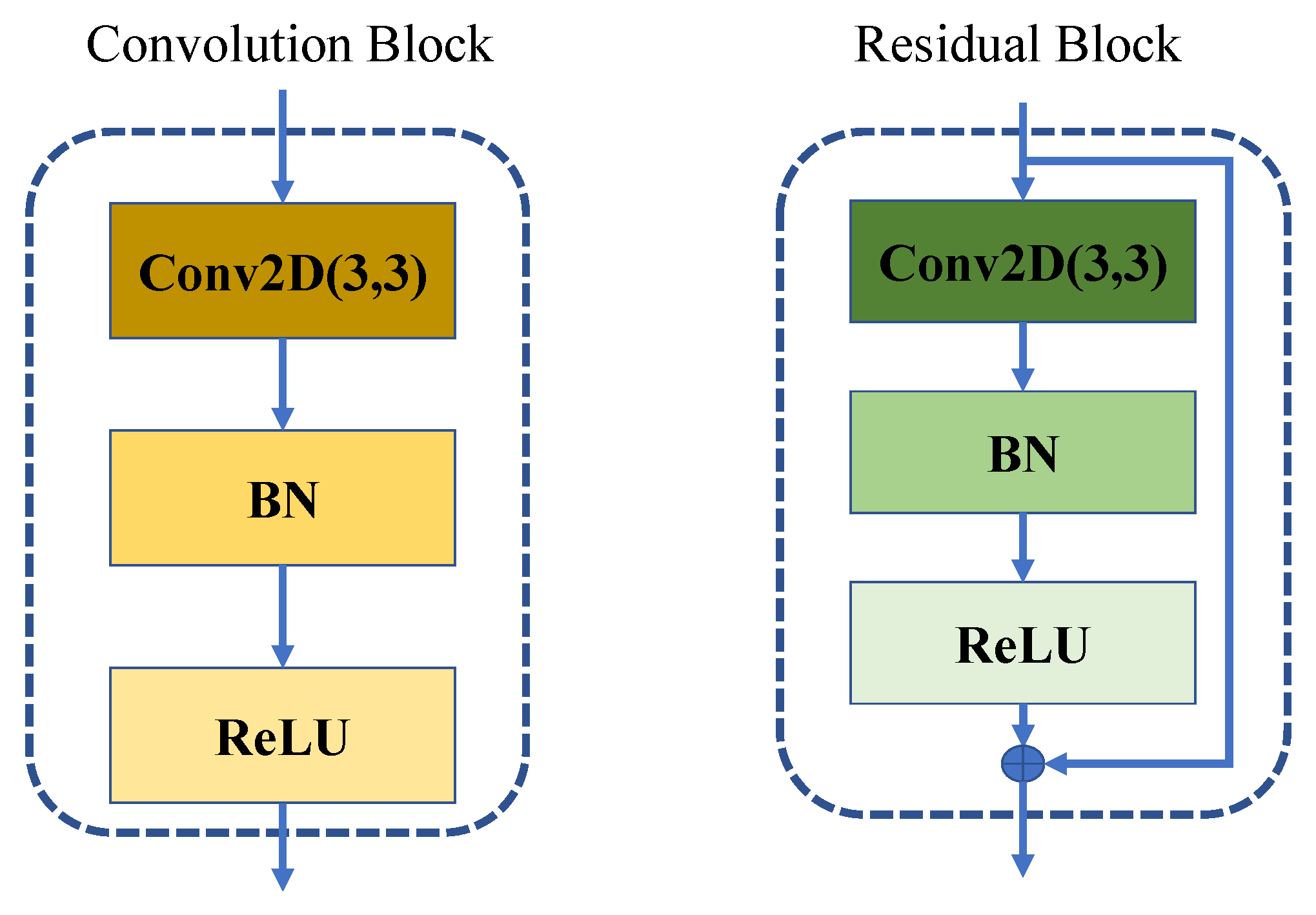
- Our proposed two-stage network has a clear physical meaning. Specifically, stage 1 utilizes several conventional blocks and residual blocks to estimate the SCM accurately, while in stage 2, a similar structure with an additional downsampling layer and linear layer is employed to compute the MVDR weights.
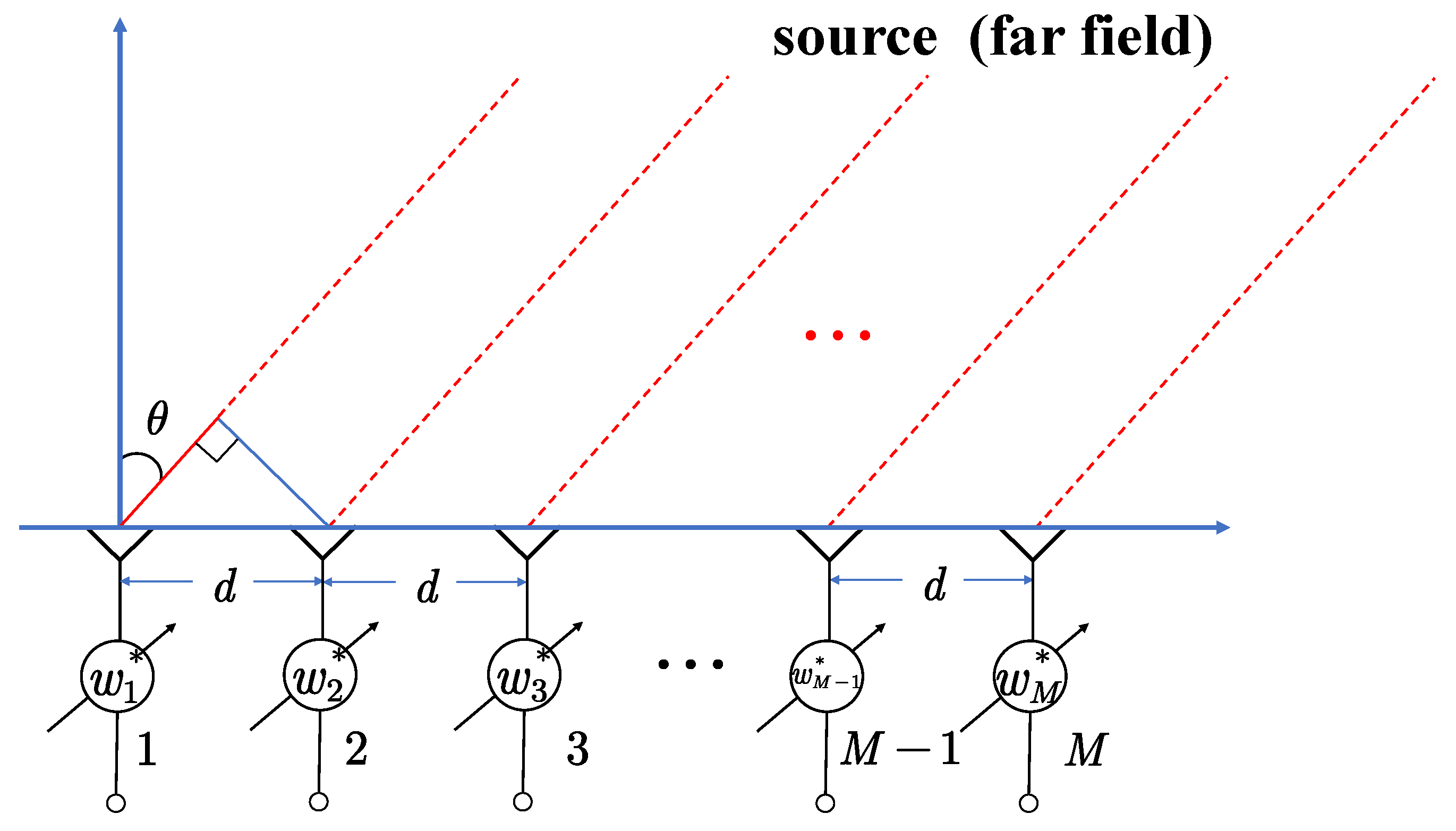
2. MVDR Estimator
3. A Deep Neural Network for Robust Adaptive Beamforming
3.1. Architecture
- Input layer and Output layer: The data size of the input and output layers.
- Convolution block: The number of channels used in the convolution block.
- Residual block: The number of channels used in the residual block.
- Linear layer: The number of channels used in the linear layer.
- Downsampling layer: The downsampling size used in the Downsampling layer.
3.2. Dataset and Training
4. Experiments
- In [27], the output of the network is an ultrasound image obtained after adaptive processing, which can be essentially regarded as a spectral estimator. This differs from our CNN beamformer’s output, which is a set of adaptive weights.
- In [29], the DoA of the signal must be known a priori, which is not required in our CNN beamformer.
- In [30], the 1D CVCNN RBF method uses much larger training samples (100 to 400 snapshots) compared to our proposed method, which only requires four snapshots or fewer.
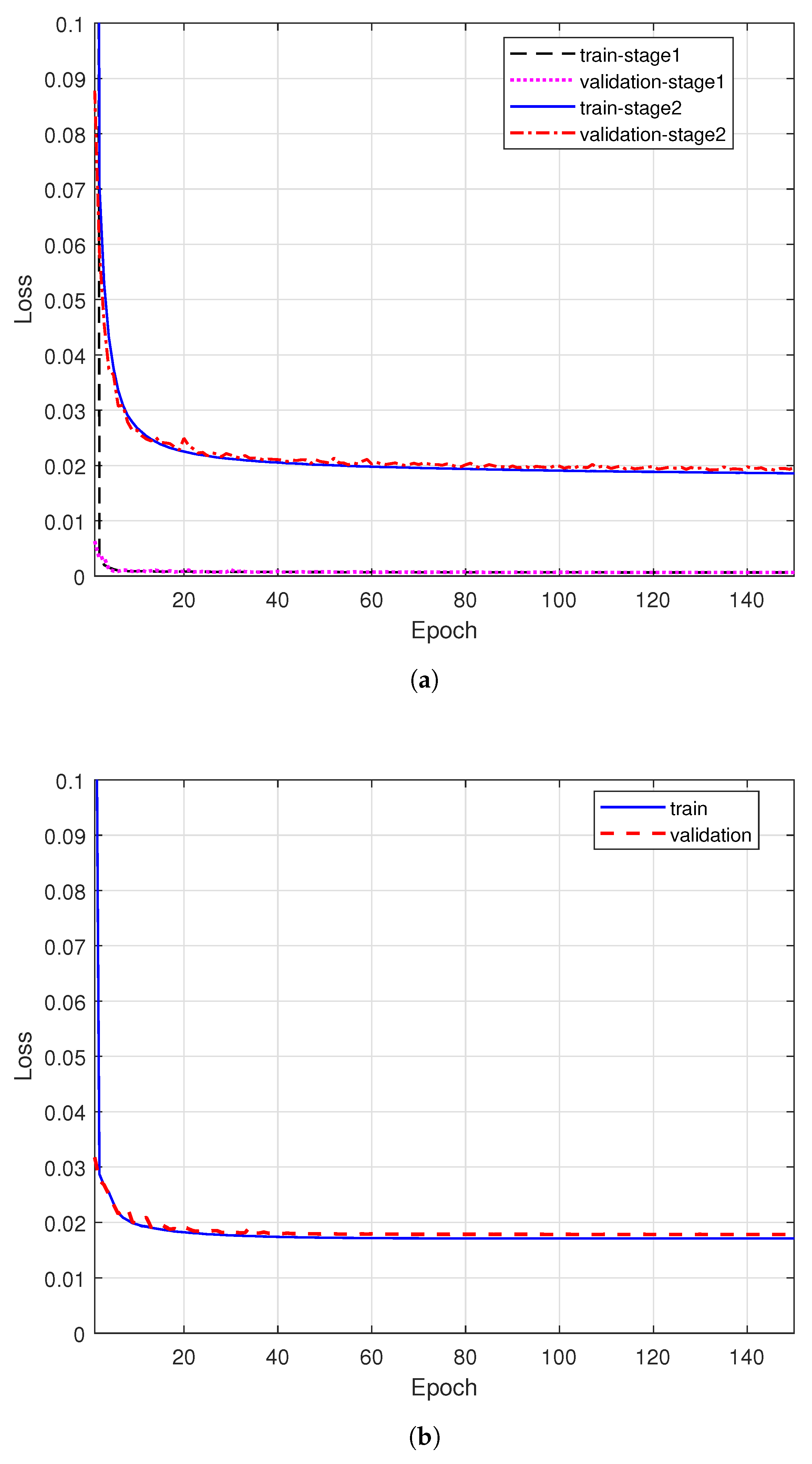
4.1. Network Convergence Performance
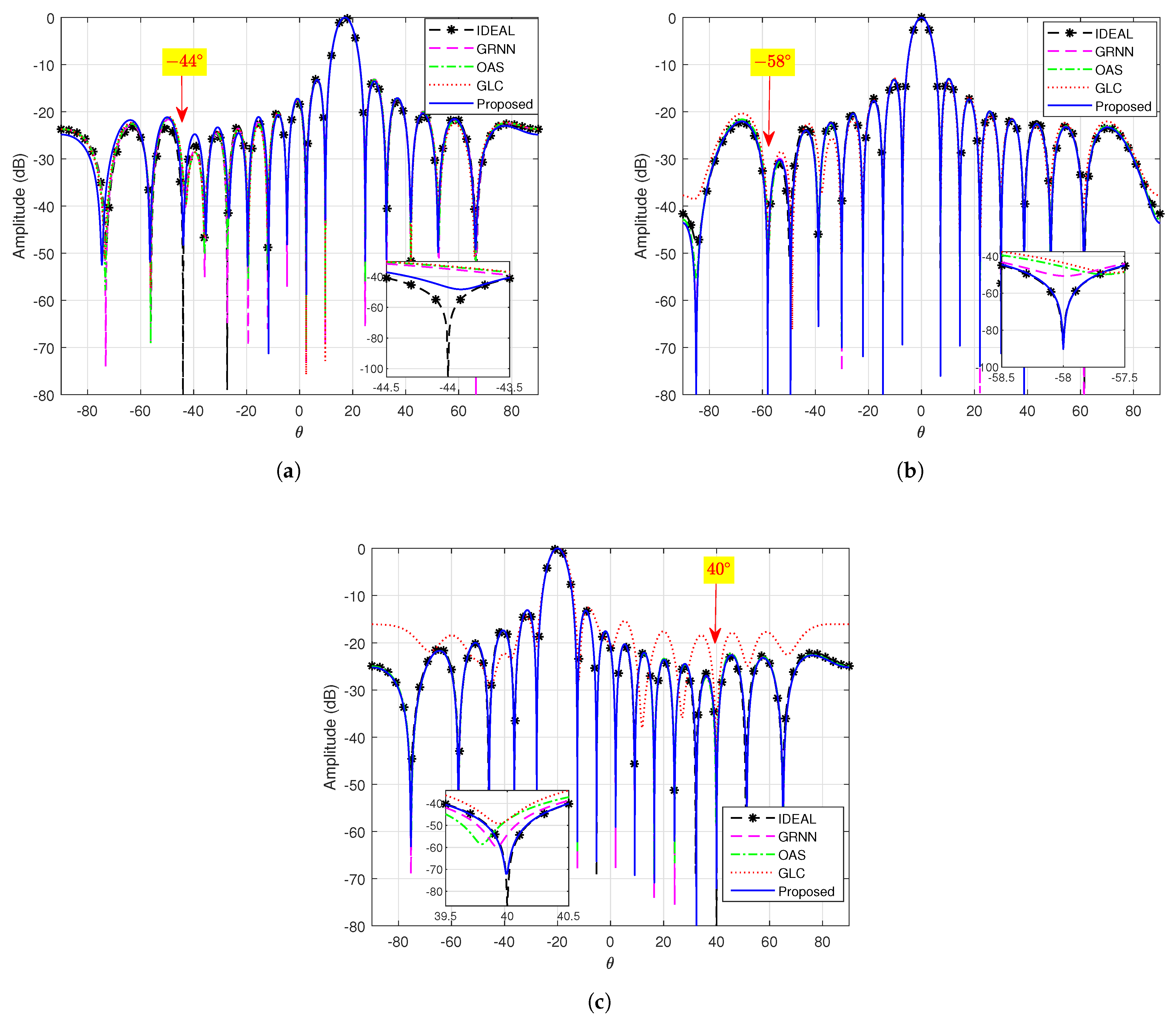
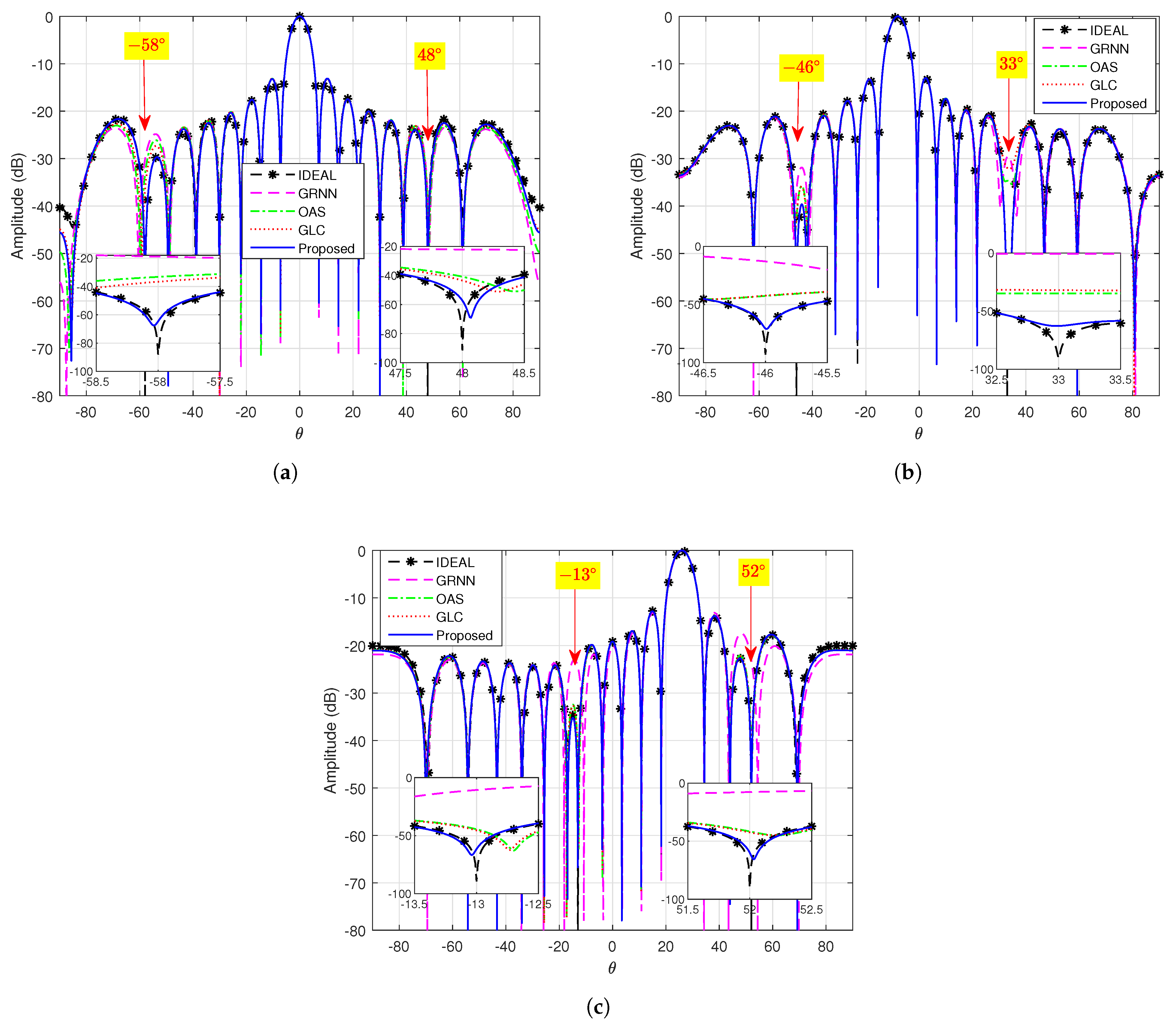
4.2. Adaptive Pattern Comparison in the Case of Finite Snapshots
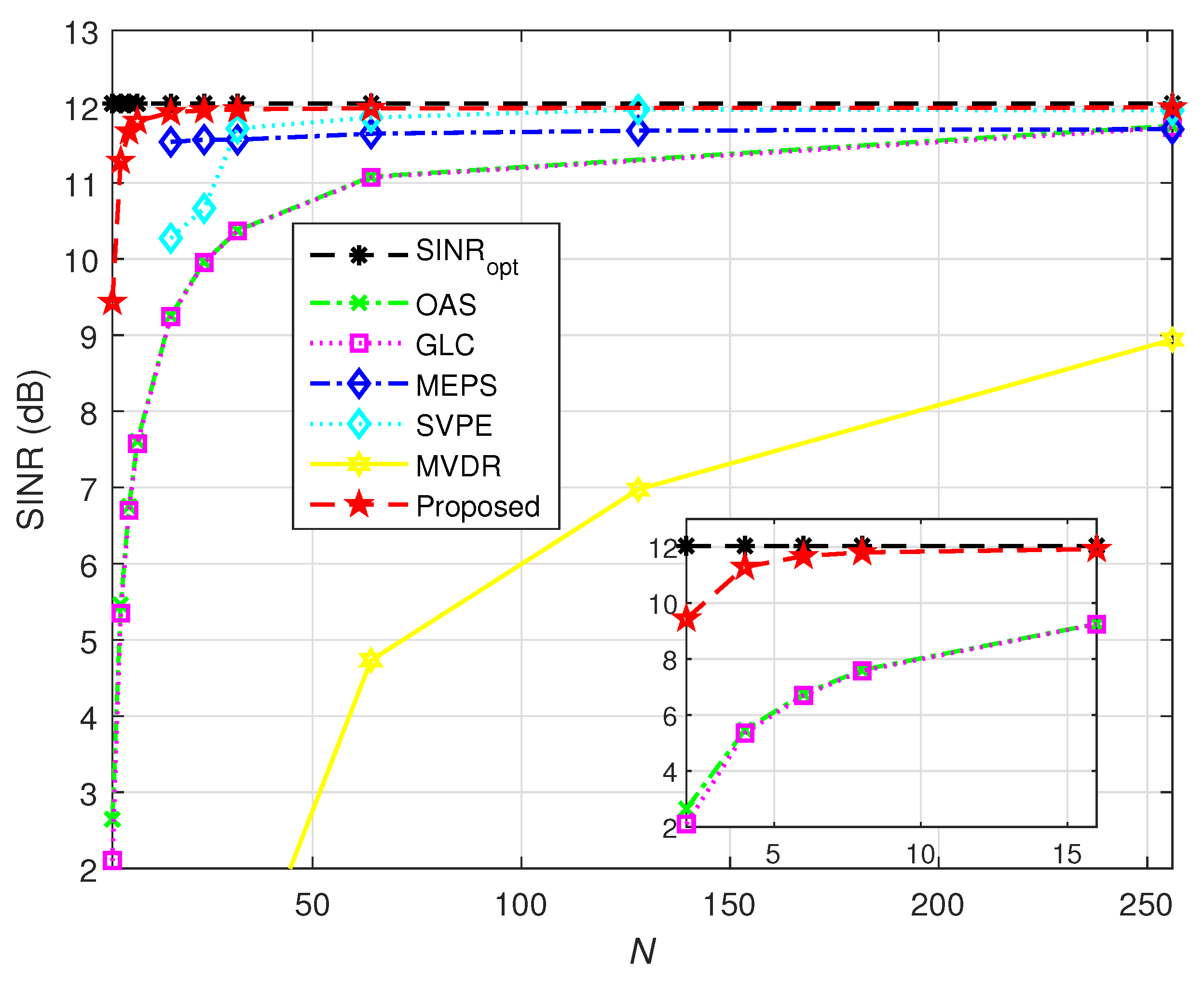
4.3. Performance Comparison of Convergence
4.4. Performance Comparison in the Presence of G/P Errors
4.5. Computational Complexity Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bryn, F. Optimum signal processing of three-dimensional arrays operating on Gaussian signals and noise. Acoust. Soc. Am. 1962, 34, 289–297. [Google Scholar] [CrossRef]
- Applebaum, S. Adaptive arrays. IEEE Trans. Antennas Propag. 1976, 24, 585–598. [Google Scholar] [CrossRef]
- Green, P.E., Jr.; Kelly, E.J., Jr.; Levin, M.J. A comparison of seismic array processing methods. Geophys. J. Int. 1966, 11, 67–84. [Google Scholar] [CrossRef] [Green Version]
- Choi, S.; Shim, D. A novel adaptive beamforming algorithm for a smart antenna system in a CDMA mobile communication environment. IEEE Trans. Veh. Technol. 2000, 49, 1793–1806. [Google Scholar] [CrossRef] [Green Version]
- Navarro-Camba, E.A.; Felici-Castell, S.; Segura-García, J.; García-Pineda, M.; Pérez-Solano, J.J. Feasibility of a Stochastic Collaborative Beamforming for Long Range Communications in Wireless Sensor Networks. Electronics 2018, 7, 417. [Google Scholar] [CrossRef] [Green Version]
- Capon, J. High-resolution frequency-wave number spectrum analysis. Proc. IEEE 1969, 57, 1408–1418. [Google Scholar] [CrossRef] [Green Version]
- Shahbazpanahi, S.; Gershman, A.B.; Luo, Z.Q.; Wong, K.M. Robust adaptive beamforming for general-rank signal models. IEEE Trans. Signal Process. 2003, 51, 2257–2269. [Google Scholar] [CrossRef]
- Cox, H.; Zeskind, R.; Owen, M. Robust adaptive beamforming. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 1365–1376. [Google Scholar] [CrossRef] [Green Version]
- Feldman, D.D.; Griffiths, L.J. A projection approach for robust adaptive beamforming. IEEE Trans. Signal Process. 1994, 42, 867–876. [Google Scholar] [CrossRef]
- Lee, C.C.; Lee, J.H. Eigenspace-based adaptive array beamforming with robust capabilities. IEEE Trans. Antennas Propag. 1997, 45, 1711–1716. [Google Scholar]
- Vorobyov, S.A.; Gershman, A.B.; Luo, Z.Q. Robust adaptive beamforming using worst-case performance optimization: A solution to the signal mismatch problem. IEEE Trans. Signal Process. 2003, 51, 313–324. [Google Scholar] [CrossRef] [Green Version]
- Ledoit, O.; Wolf, M. Improved estimation of the covariance matrix of stock returns with an application to portfolio selection. J. Empir Finance 2003, 10, 603–621. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wiesel, A.; Eldar, Y.C. Shrinkage algorithms for MMSE covariance estimation. IEEE Trans. Signal Process. 2010, 58, 5016–5029. [Google Scholar] [CrossRef] [Green Version]
- Du, L.; Li, J.; Stoica, P. Fully automatic computation of diagonal loading levels for robust adaptive beamforming. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 449–458. [Google Scholar] [CrossRef]
- Wu, R.; Bao, Z.; Ma, Y. Control of peak sidelobe level in adaptive arrays. IEEE Trans. Antennas Propag. 1996, 44, 1341–1347. [Google Scholar]
- Gu, Y.; Leshem, A. Robust Adaptive Beamforming Based on Interference Covariance Matrix Reconstruction and Steering Vector Estimation. IEEE Trans. Signal Process. 2012, 60, 3881–3885. [Google Scholar]
- Mohammadzadeh, S.; Kukrer, O. Adaptive beamforming based on theoretical interference-plus-noise covariance and direction-of-arrival estimation. IET Signal Process. 2018, 12, 819–825. [Google Scholar] [CrossRef]
- Mohammadzadeh, S.; Nascimento, V.H.; De Lamare, R.C.; Kukrer, O. Maximum Entropy-Based Interference-Plus-Noise Covariance Matrix Reconstruction for Robust Adaptive Beamforming. IEEE Signal Process. Lett. 2020, 27, 845–849. [Google Scholar] [CrossRef]
- Zheng, Z.; Zheng, Y.; Wang, W.Q.; Zhang, H. Covariance Matrix Reconstruction With Interference Steering Vector and Power Estimation for Robust Adaptive Beamforming. IEEE Trans. Veh. Technol. 2018, 67, 8495–8503. [Google Scholar] [CrossRef]
- Zhu, X.; Xu, X.; Ye, Z. Robust adaptive beamforming via subspace for interference covariance matrix reconstruction. Signal Process. 2020, 167, 107289. [Google Scholar] [CrossRef]
- Mohammadzadeh, S.; Nascimento, V.H.; De Lamare, R.C.; Kukrer, O. Robust adaptive beamforming based on virtual sensors using low-complexity spatial sampling. Signal Process. 2021, 188, 108172. [Google Scholar] [CrossRef]
- Davoli, A.; Guerzoni, G.; Vitetta, G.M. Machine learning and deep learning techniques for colocated MIMO radars: A tutorial overview. IEEE Access 2021, 9, 33704–33755. [Google Scholar] [CrossRef]
- Pan, P.; Zhang, Y.; Deng, Z.; Qi, W. Deep learning-based 2-D frequency estimation of multiple sinusoidals. IEEE Trans. Neural Networks Learn. Syst. 2022, 33, 5429–5440. [Google Scholar] [CrossRef]
- Duan, K.; Chen, H.; Xie, W.; Wang, Y. Deep learning for high-resolution estimation of clutter angle-Doppler spectrum in STAP. IET Radar Sonar Navig. 2022, 16, 193–207. [Google Scholar] [CrossRef]
- Rogers, J.; Ball, J.E.; Gurbuz, A.C. Estimating the Number of Sources via Deep Learning. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; pp. 1–5. [Google Scholar]
- Bianco, S.; Napoletano, P.; Raimondi, A.; Feo, M.; Petraglia, G.; Vinetti, P. AESA Adaptive Beamforming Using Deep Learning. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020; pp. 1–6. [Google Scholar]
- Luijten, B.; Cohen, R.; de Bruijn, F.J.; Schmeitz, H.A.; Mischi, M.; Eldar, Y.C.; van Sloun, R.J. Adaptive ultrasound beamforming using deep learning. IEEE Trans. Med. Imaging 2020, 39, 3967–3978. [Google Scholar] [CrossRef] [PubMed]
- Hamza, S.A.; Amin, M.G. Learning Sparse Array Capon Beamformer Design Using Deep Learning Approach. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020. [Google Scholar]
- Mallioras, I.; Zaharis, Z.D.; Lazaridis, P.I.; Pantelopoulos, S. A novel realistic approach of adaptive beamforming based on deep neural networks. IEEE Trans. Antennas Propag. 2022, 70, 8833–8848. [Google Scholar] [CrossRef]
- Mohammadzadeh, S.; Nascimento, V.H.; De Lamare, R.C.; Hajarolasvadi, N. Robust Beamforming Based on Complex-Valued Convolutional Neural Networks for Sensor Arrays. IEEE Signal Process. Lett. 2022, 29, 2108–2112. [Google Scholar] [CrossRef]
- Xiao, X.; Lu, Y. Data-Based Model for Wide Nulling Problem in Adaptive Digital Beamforming Antenna Array. IEEE Antennas Wirel. Propag. Lett. 2019, 18, 2249–2253. [Google Scholar] [CrossRef]
- Carlson, B.D. Covariance matrix estimation errors and diagonal loading in adaptive arrays. IEEE Trans. Aerosp. Electron. Syst. 1988, 24, 397–401. [Google Scholar] [CrossRef]
- Liu, Z.M.; Zhang, C.; Philip, S.Y. Direction-of-arrival estimation based on deep neural networks with robustness to array imperfections. IEEE Trans. Antennas Propag. 2018, 66, 7315–7327. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Amari, S.I. Backpropagation and stochastic gradient descent method. IEEE Trans. Antennas Propag. 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Parameter |
|---|---|
| Input | (16,16) |
| Convolution block | 4 |
| Convolution block | 16 |
| Residual block | 16 |
| Residual block | 16 |
| Residual block | 16 |
| Output | (16,16) |
| Type | Parameter |
|---|---|
| Input | (16,16) |
| Convolution block | 4 |
| Convolution block | 16 |
| DownSampling | (2,2) |
| Residual block | 16 |
| Residual block | 16 |
| Linear | 1024 |
| Output | (32,1) |
| Parameter | Value |
|---|---|
| Num_array | |
| snapshots | |
| SOI | |
| SNR | 0 dB |
| SOAs | |
| INR | dB |
| G/P error maximum variance | = |
| G/P Errors | SINR (dB) | |||
|---|---|---|---|---|
| OPT | GLC | OAS | Proposed | |
| 0.000 | 12.0327 | 5.4625 | 5.5570 | 11.3433 |
| 0.005 | 12.0325 | 5.3563 | 5.4843 | 10.8617 |
| 0.010 | 12.0321 | 5.2422 | 5.3666 | 9.8965 |
| 0.015 | 12.0321 | 5.3172 | 5.4270 | 8.8833 |
| 0.020 | 12.0324 | 5.3730 | 5.4808 | 8.0496 |
| 0.025 | 12.0322 | 5.3916 | 5.4918 | 7.3809 |
| 0.030 | 12.0320 | 5.3638 | 5.4664 | 6.9473 |
| 0.035 | 12.0316 | 5.3609 | 5.4643 | 6.5472 |
| 0.040 | 12.0315 | 5.3320 | 5.4362 | 6.2157 |
| 0.045 | 12.0303 | 5.3125 | 5.4056 | 5.8945 |
| 0.050 | 12.0299 | 5.3886 | 5.4646 | 5.5795 |
| Method | Computational Complexity | Running Time (s) |
|---|---|---|
| Proposed | 0.0118 | |
| OAS | 0.0025 | |
| GLC | 0.0017 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, Z.; Duan, K.; He, J.; Qiu, Z.; Li, B. Robust Adaptive Beamforming Based on a Convolutional Neural Network. Electronics 2023, 12, 2751. https://doi.org/10.3390/electronics12122751
Liao Z, Duan K, He J, Qiu Z, Li B. Robust Adaptive Beamforming Based on a Convolutional Neural Network. Electronics. 2023; 12(12):2751. https://doi.org/10.3390/electronics12122751
Chicago/Turabian StyleLiao, Zhipeng, Keqing Duan, Jinjun He, Zizhou Qiu, and Binbin Li. 2023. "Robust Adaptive Beamforming Based on a Convolutional Neural Network" Electronics 12, no. 12: 2751. https://doi.org/10.3390/electronics12122751