
A Location and Velocity Prediction-Assisted FANET Networking Scheme for Highly Mobile Scenarios



Abstract
:1. Introduction
Contributions
- A FANET clustering algorithm is proposed in this paper. First, the Silhouette coefficient is used to determine the number of clusters for given nodes’ positions and velocities. It aims to find an optimal number of clusters with the highest average coefficient value. Then, the k-means++ algorithm is used to group all nodes into clusters periodically. When calculating nodes’ distance, both position and velocity differences are considered. Moreover, the CHs of the previous iteration are used to initialize the centroids of the current iteration.
- A high-mobility FANET networking scheme is proposed based on the linear Kalman filter. To model nodes’ mobility influenced by external interferences, we use the Gaussian–Markov process to characterize nodes’ mobility influenced by external interferences. Specifically, we establish the state transfer relationship of position and velocity between two adjacent times and the Kalman. On this basis, the Kalman filter is utilized to predict the positions and velocities of all nodes.
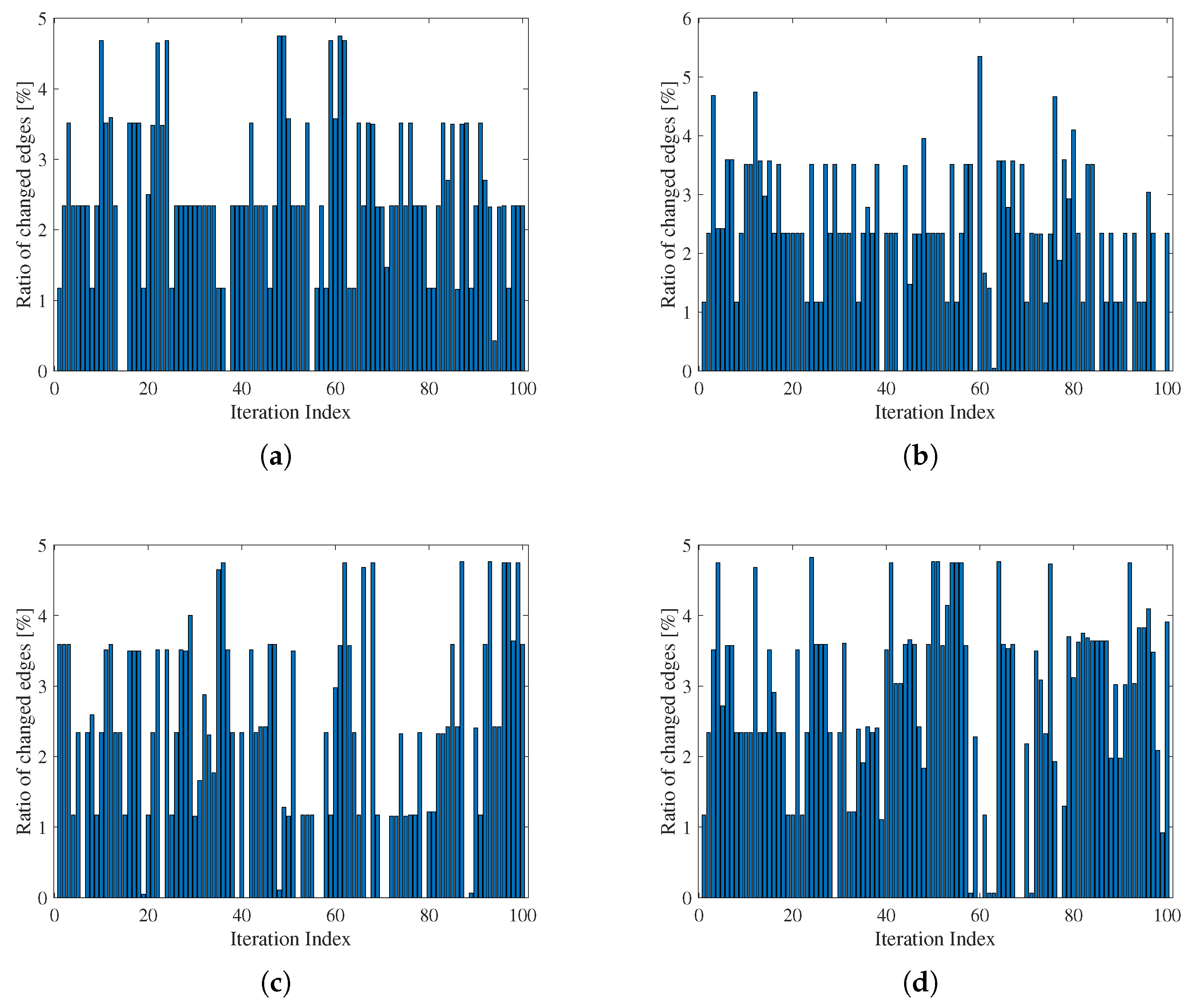
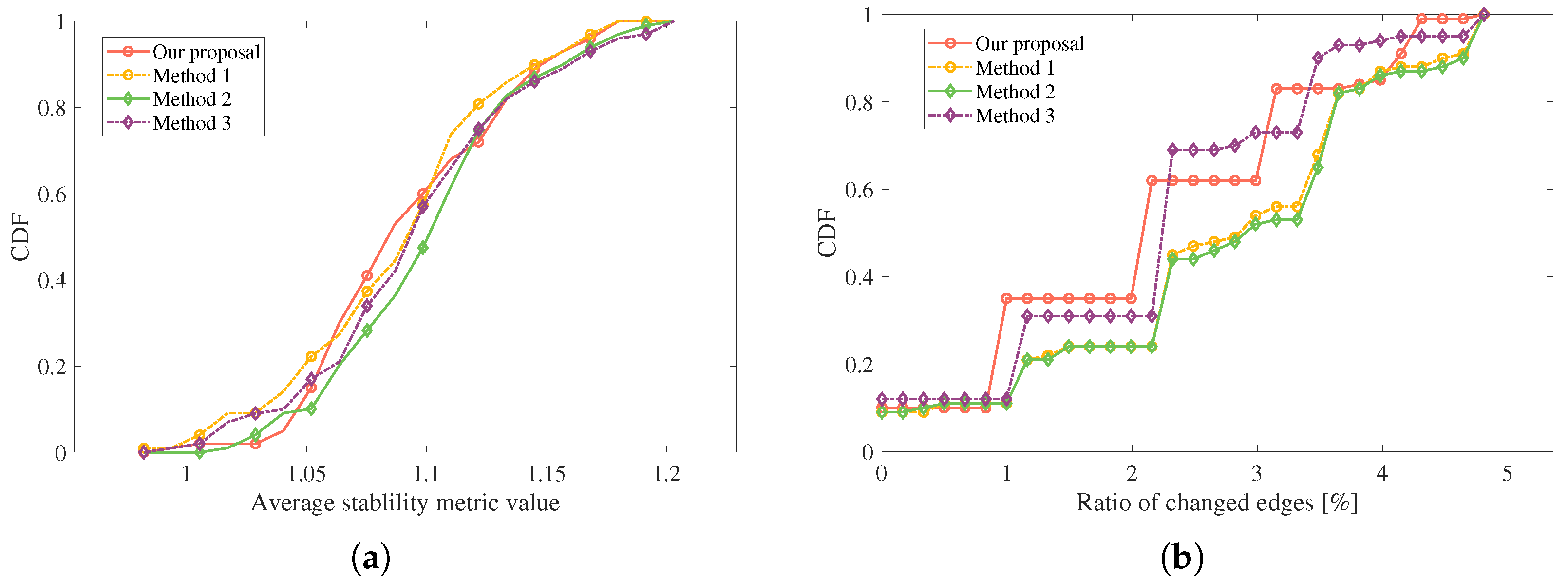
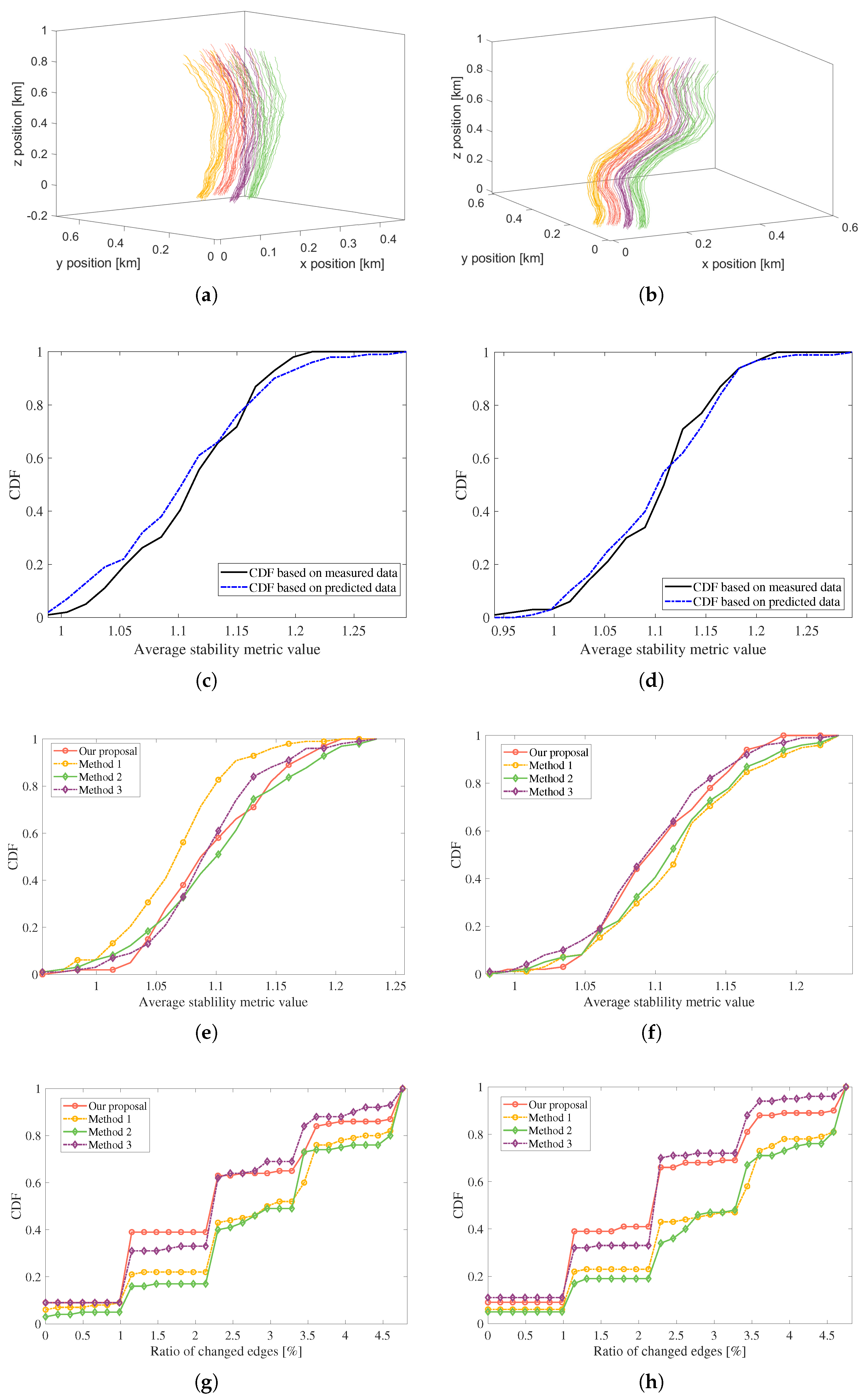
- This paper further evaluates the networking performance from three aspects, i.e., the cluster stability, ratio of changed edges based on the abstracted graph and computational complexity. The first metric measures the relative position and velocity difference within a cluster, whereas the second metric reflects the required communication overhead costs during the network evolution.
- Extensive simulations are conducted to evaluate the performance of our proposal under different node trajectories and velocities. Thereafter, we compare it with the existing FANET networking algorithms. The simulation results show that the proposed scheme outperforms the conventional schemes marginally from the aspects of cluster stability coefficient and ratio of changed edge numbers. Nonetheless, it presents a relatively low computational complexity in contrast to other algorithms; this implies that the proposed scheme is applicable in high-mobile scenarios, which require fast and reliable networking.
2. Review of Related Works
3. Location and Velocity Prediction
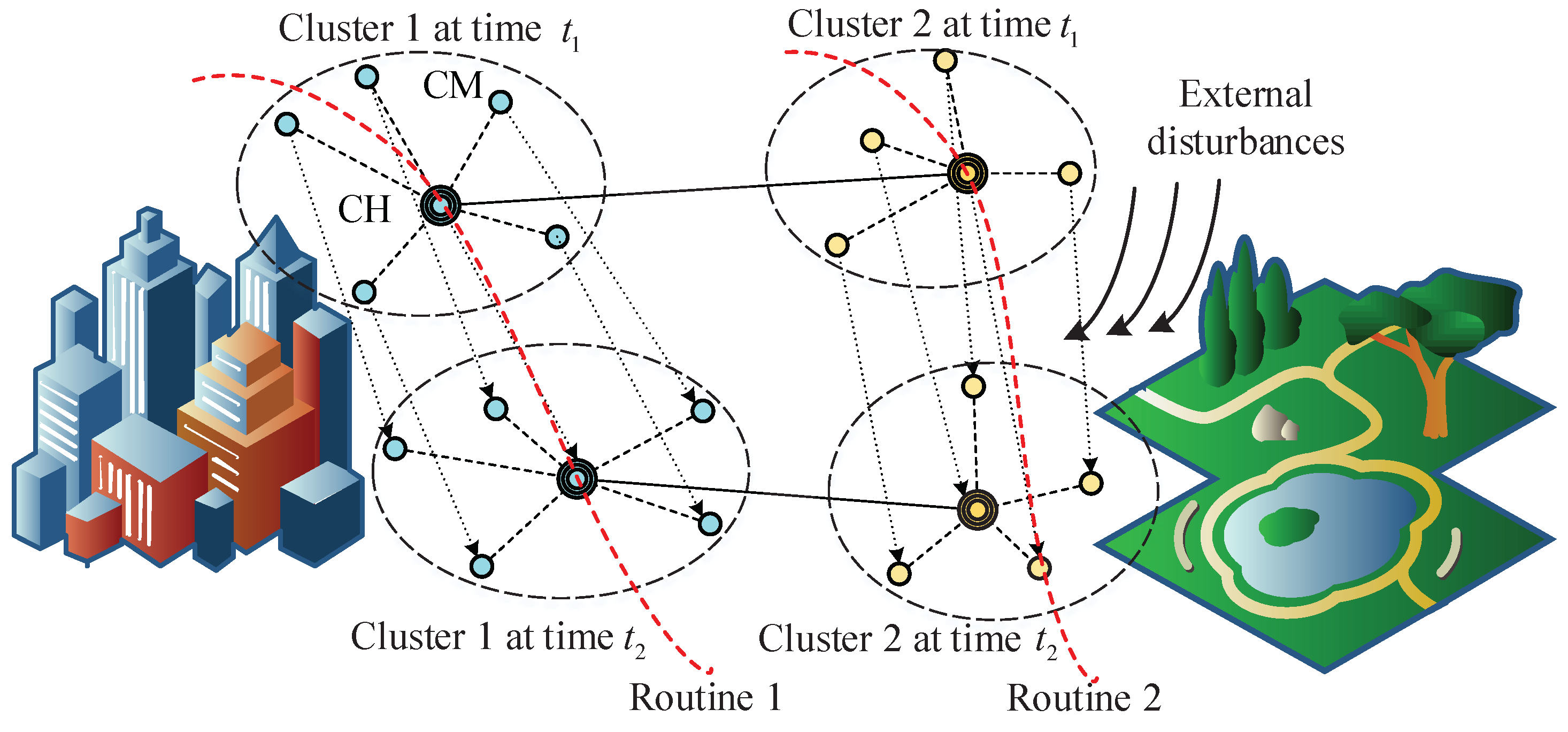
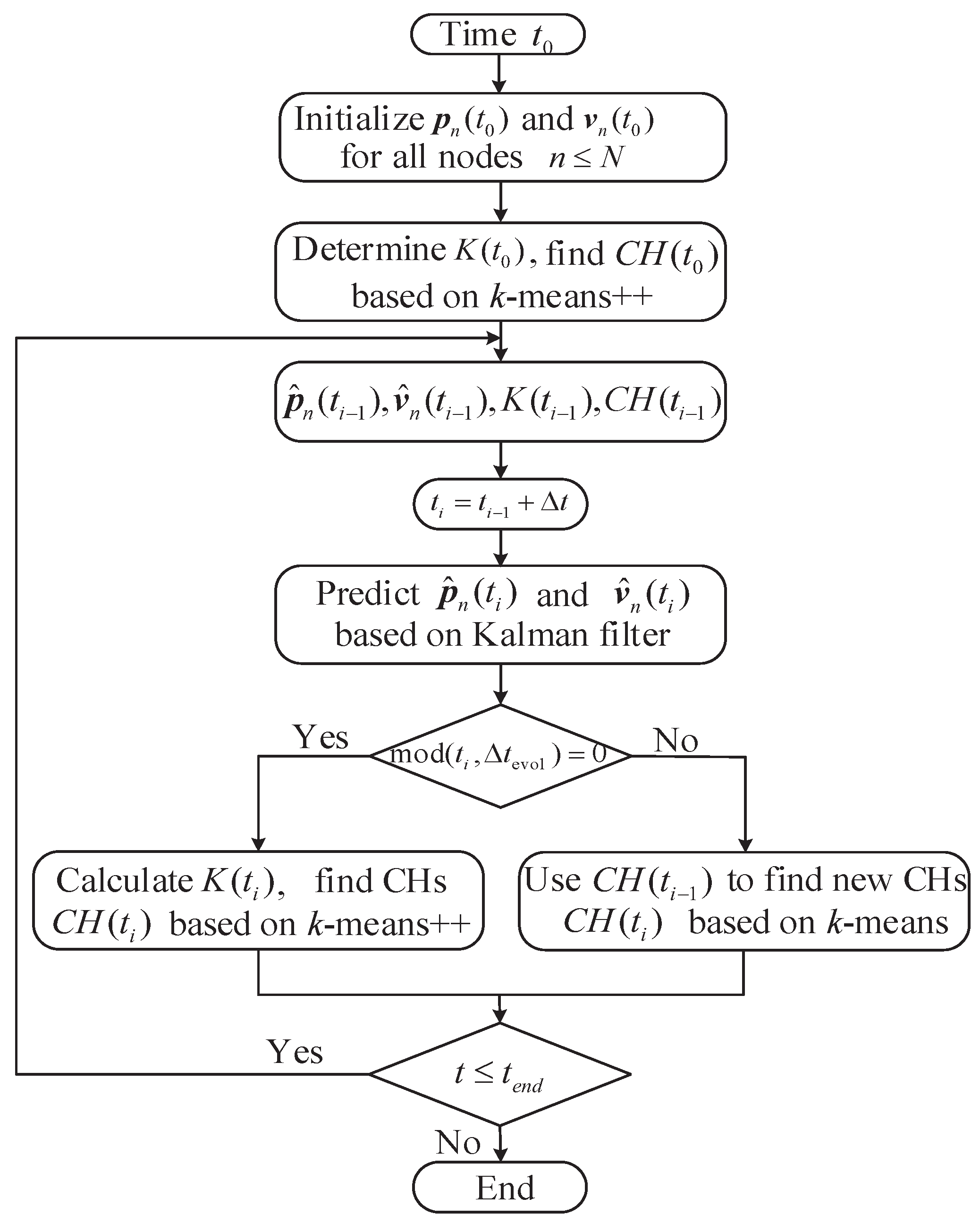
3.1. Framework of the Proposed Algorithm
- Initialize the simulation parameter settings at time , including the total node number, nodes’ locations and velocities. Determine the number of cluster by using the Silhouette coefficient and group all nodes into clusters. Find the CH for each cluster based on the k-means++ algorithm.
- Predict the node location and velocity based on the Kalman filter. Cluster all nodes based on the predicted information via k-means or k-means++ algorithm. Update simulation time .
- Repeat step 2 until the preset simulation time is reached or other convergence conditions are satisfied.
3.2. Initialization and Modeling of Node Movement
- Generate group center nodes and model their movements based on GMMM. First, initialize the center nodes with given positions, velocities, and moving directions at the initialization time . Then, update these three parameters based on the following three equations, which arewhere means the moving speed at time , is a constant, which denotes the average speed and is a random variable following the Gaussian distribution. is a parameter that controls the movement randomness. Specifically, the case of represents a totally random process, i.e., the Brownian motion, whereas the case of means a completely deterministic process.Since flying nodes are moving in 3-D Euclidean space, we use two angular variables to depict the movement direction. Variables and denote the elevation and azimuth angles of the speed vector, respectively. The meanings of variables , , , and are similar to those of Equation (1). Finally, the location at time can be obtained based on the previous location, speed and moving direction at time , which arewhere is the updation time interval. Note that , , and are the corresponding x, y and z coordinates of the node’s position, respectively.
- As for each group center, generate some nodes around the center randomly, of which locations are assumed to obey the Gaussian distribution, and their centers are set as the mean values. Their locations and velocities are derived based on the corresponding centers. According to [8], the velocity of node belonging to the k-th group can be obtained by adding a random motion vector to the center speed vector as shown in Figure 3.This relationship between group center and member velocities can be expressed aswhere is distributed uniformly within a specified maximal speed , i.e., . The random elevation angle is uniformly distributed within and the azimuth angle varies evenly within a range of .
3.3. Kalman-Filter-Based Trajectory Prediction
4. Network Clustering
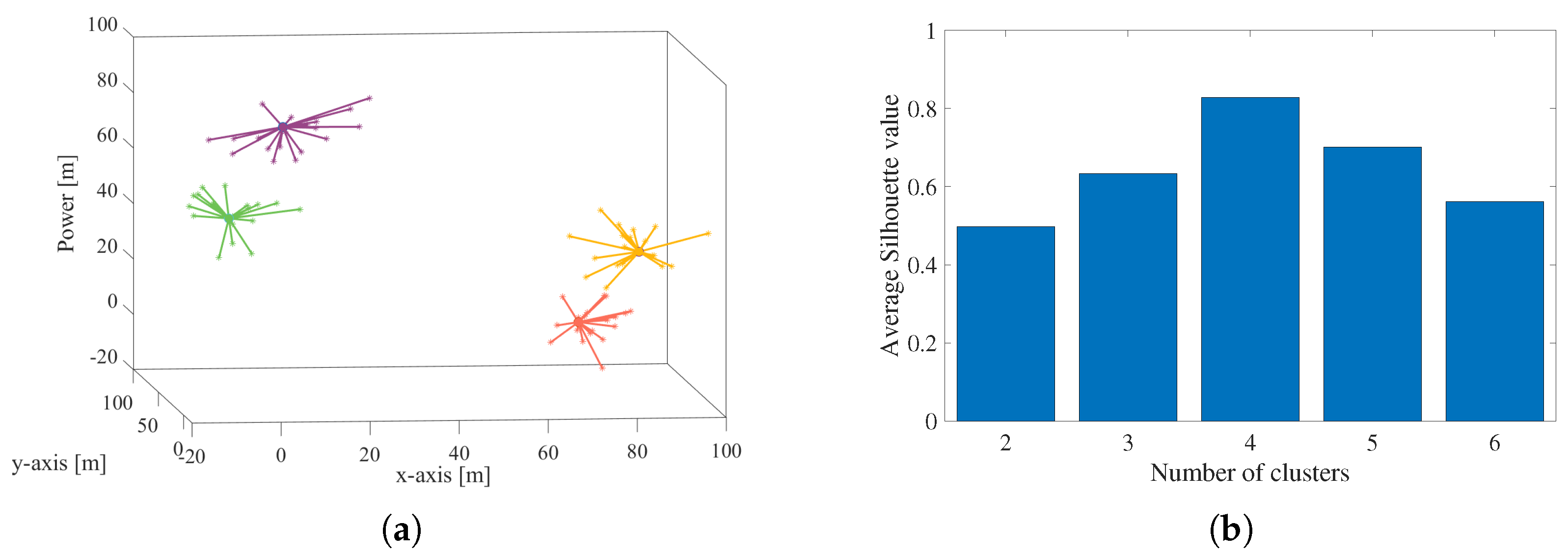
4.1. Number Determination of Clusters
4.2. k-means+ Clustering Algorithm
- Choose a node from the set randomly as the centroid of the 1st cluster, marked as .
- For a node marked as , calculate its distance from the nearest previously chosen centroids and obtain the distance vector. It can be expressed aswhere is a set containing all previously chosen centroids.
- Choose a node as the centroid of next cluster with a probability ofThis formula implies that the probability of a node being selected as the next centroid is highly related to its separation from the nearest, previously chosen centroid.
- Repeat Step 2 and Step 3 until K centroids have been determined.
- Use the k-means algorithm to cluster all nodes and obtain the centroids.
- For the k-th cluster, search a CM from the assigned CMs with the nearest distance to the centroid and take it as the CH, i.e.,
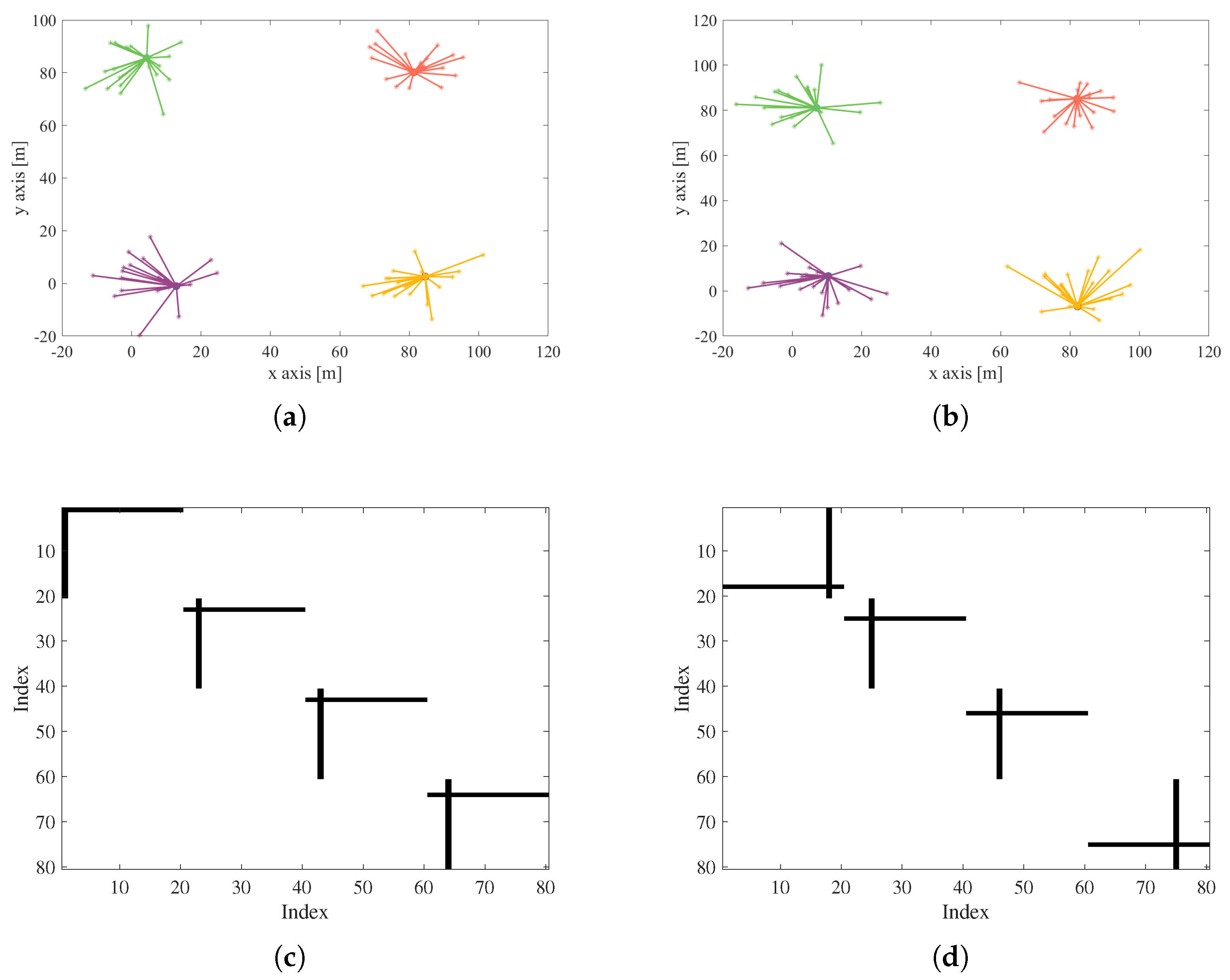
4.3. Dynamic Clustering Evaluation
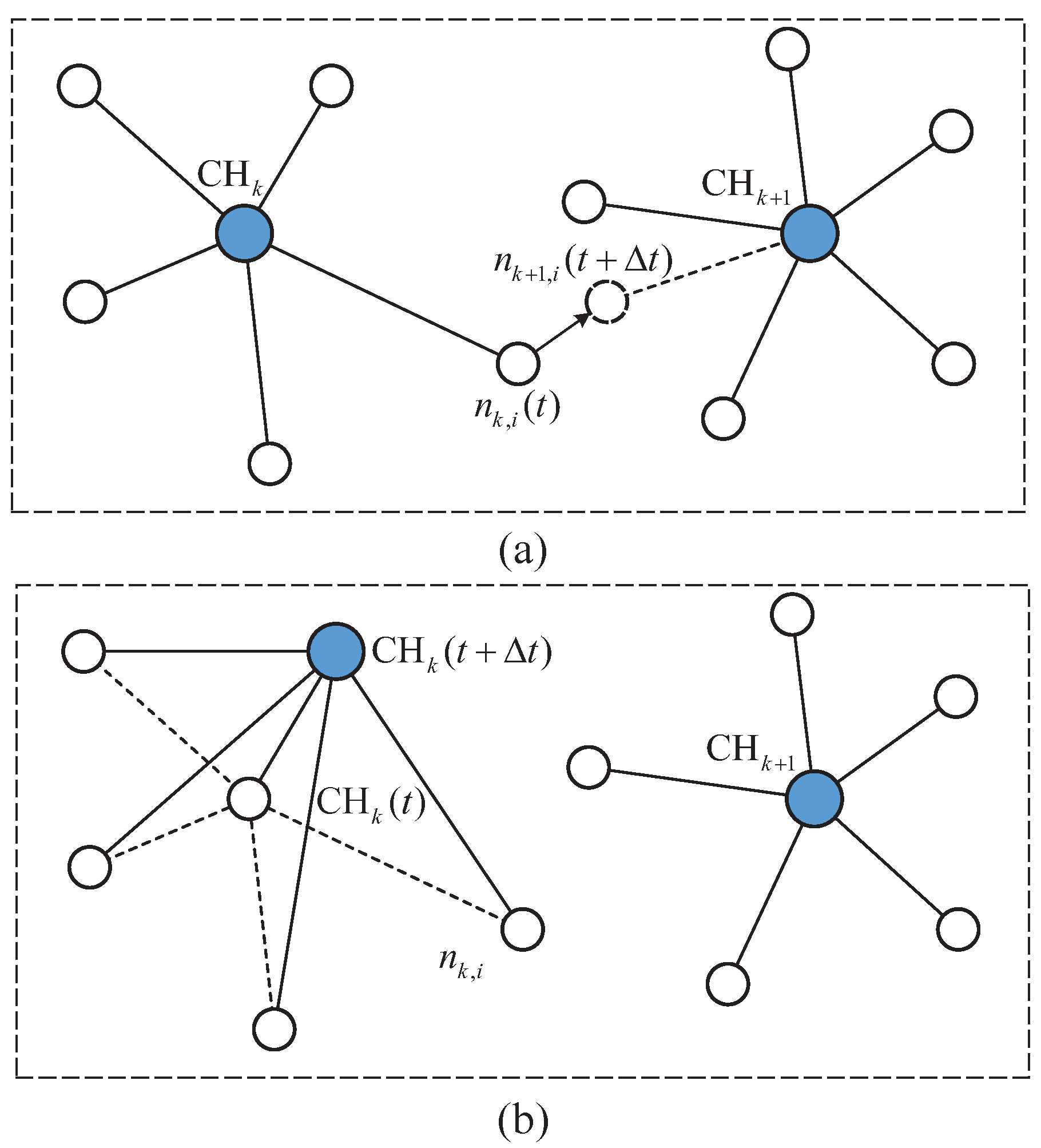
4.3.1. Communication Overhead Metric
4.3.2. Cluster Maintenance Metric
5. Simulation and Analysis
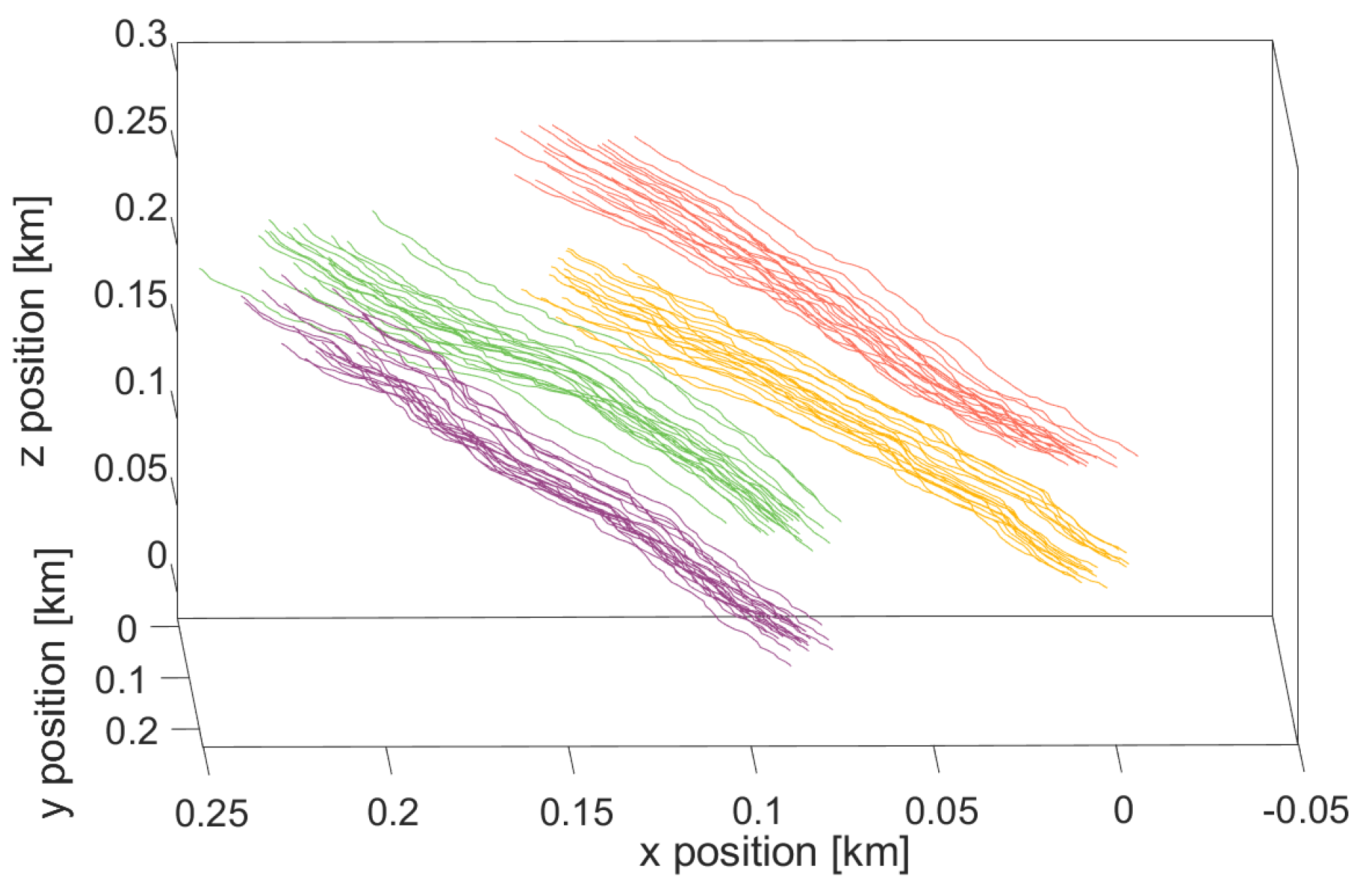
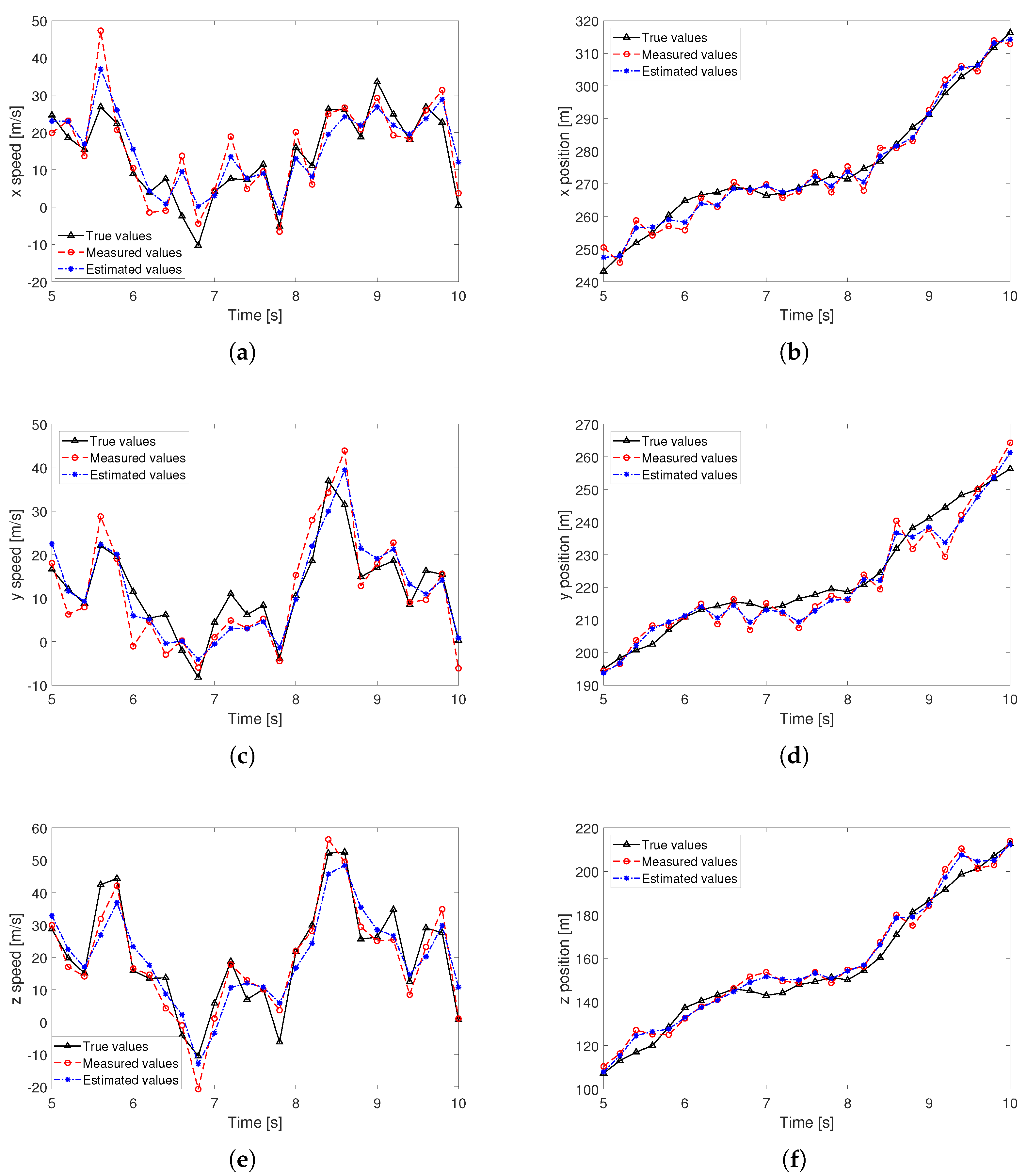
5.1. Node Initialization and Prediction
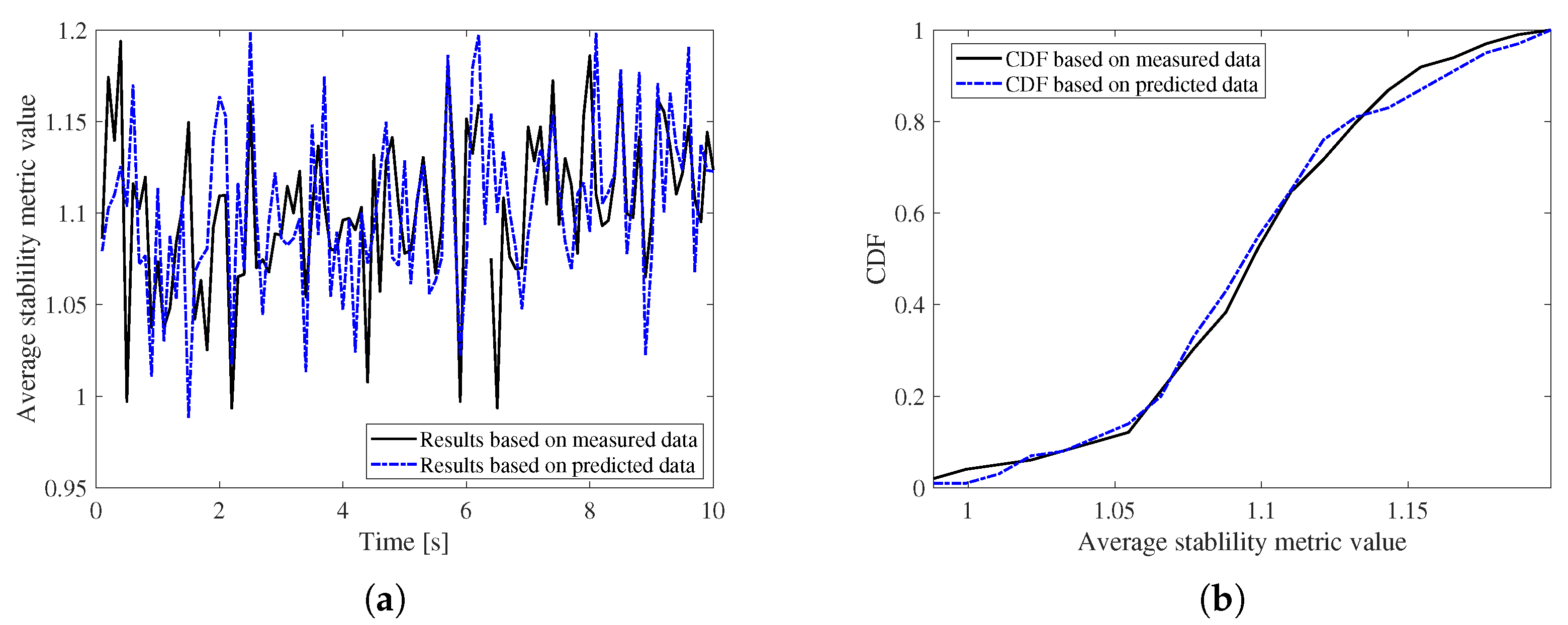
5.2. Performance Evaluation
5.3. Comparisons with Existing Methods
5.4. Simulations over Different Trajectories
5.5. Limitation and Applicability of the Proposal
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xiao, Z.; Zhu, L.; Liu, Y.; Yi, P.; Zhang, R.; Xia, X.G.; Schober, R. A Survey on Millimeter-Wave Beamforming Enabled UAV Communications and Networking. IEEE Commun. Surv. Tutor. 2022, 24, 557–610. [Google Scholar] [CrossRef]
- Lakew, D.S.; Sa’ad, U.; Dao, N.-N.; Na, W.; Cho, S. Routing in Flying Ad Hoc Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 1071–1120. [Google Scholar] [CrossRef]
- Shahraki, A.; Taherkordi, A.; Haugen, Ø.; Eliassen, F. A Survey and Future Directions on Clustering: From WSNs to IoT and Modern Networking Paradigms. IEEE Trans. Netw. Serv. Manag. 2021, 18, 2242–2274. [Google Scholar] [CrossRef]
- Abdulhae, O.-T.; Mandeep, J.-S.; Islam, M. Cluster-Based Routing Protocols for Flying Ad Hoc Networks (FANETs). IEEE Access 2022, 10, 32981–33004. [Google Scholar] [CrossRef]
- Wan, Y.; Namuduri, K.; Zhou, Y.; Fu, S. A Smooth-Turn Mobility Model for Airborne Networks. IEEE Trans. Veh. Technol. 2013, 62, 3359–3370. [Google Scholar] [CrossRef]
- Liu, M.; Wan, Y.; Lewis, F.L. Analysis of the Random Direction Mobility Model with a Sense-and-Avoid Protocol. In Proceedings of the 2017 IEEE Globecom Workshops (GC Wkshps), Singapore, 4–8 December 2017. [Google Scholar]
- Moussaoui, A.; Boukeream, A. A survey of routing protocols based on link-stability in mobile ad hoc networks. J. Netw. Comput. Appl. 2015, 47, 1–10. [Google Scholar] [CrossRef]
- Camp, T.; Boleng, J.; Davies, V. A survey of mobility models for ad hoc network research. Wirel. Commun. Mob. Comput. 2002, 2, 483–502. [Google Scholar] [CrossRef]
- Shao, Y.; Liu, L.; Gao, H.; Xu, H.; Wang, Y.; Gong, S.; Huang, H. Clustering Algorithm Based on the Ground-Air Cooperative Architecture in Border Patrol Scenarios. Electronics 2022, 11, 2876. [Google Scholar] [CrossRef]
- Tropea, M.; Fazio, P.; Rango, F.-D.; Cordeschi, N. A New FANET Simulator for Managing Drone Networks and Providing Dynamic Connectivity. Electronics 2020, 9, 543. [Google Scholar] [CrossRef] [Green Version]
- Bhandari, S.; Wang, X.; Lee, R. Mobility and Location-Aware Stable Clustering Scheme for UAV Networks. IEEE Access 2020, 8, 106364–106372. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Q.; Feng, G.; Qin, S.; Zhou, J.; Cheng, L. Clustering Strategy of UAV Network Based on Deep Q-learning. In Proceedings of the 2020 IEEE 20th International Conference on Communication Technology (ICCT), Nanning, China, 28–31 October 2020. [Google Scholar]
- Zang, C.; Zang, S. Mobility prediction clustering algorithm for UAV networking. In Proceedings of the 2011 IEEE GLOBECOM Workshops (GC Wkshps), Houston, TX, USA, 5–9 December 2011. [Google Scholar]
- Cai, M.; Rui, L.; Liu, D.; Huang, H.; Qiu, X. Group mobility based clustering algorithm for mobile ad hoc networks. In Proceedings of the 2015 17th Asia-Pacific Network Operations and Management Symposium (APNOMS), Busan, Republic of Korea, 19–21 August 2015. [Google Scholar]
- Arafat, M.Y.; Moh, S. Localization and Clustering Based on Swarm Intelligence in UAV Networks for Emergency Communications. IEEE Internet Things J. 2019, 6, 8958–8976. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. Bio-Inspired Approaches for Energy-Efficient Localization and Clustering in UAV Networks for Monitoring Wildfires in Remote Areas. IEEE Access 2021, 9, 18649–18669. [Google Scholar] [CrossRef]
- Dorge, P.-D.; Meshram, S.-L. Design and Performance Analysis of Reference Point Group Mobility Model for Mobile Ad hoc Network. In Proceedings of the 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 15–17 December 2018. [Google Scholar]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; University of North Carolina at Chapel Hill: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Ghaleb, F.-A.; Al-Rimy, B.; Almalawi, A.; Ali, A.M.; Zainal, A.; Rassam, M.A.; Shaid, S.Z.M.; Maarof, M.A. Deep Kalman Neuro Fuzzy-Based Adaptive Broadcasting Scheme for Vehicular Ad Hoc Network: A Context-Aware Approach. IEEE Access 2020, 8, 217744–217761. [Google Scholar] [CrossRef]
- Gholizadeh, N.; Saadatfar, H.; Hanafi, N. K-DBSCAN: An improved DBSCAN algorithm for big data. J. Supercomput. 2021, 77, 6214–6235. [Google Scholar] [CrossRef]
- Bagirov, A.M.; Aliguliyev, R.M.; Sultanova, N. Finding compact and well-separated clusters: Clustering using silhouette coefficients. Pattern Recognit. 2023, 135, 109144. [Google Scholar] [CrossRef]
- Shahapure, K.R.; Nicholas, C. Cluster Quality Analysis Using Silhouette Score. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, NSW, Australia, 6–9 October 2020. [Google Scholar]
- Kubo, Y.; Nii, M.; Muto, T.; Tanaka, H.; Inui, H.; Yagi, N.; Nobuhara, K.; Kobashi, S. Artificial humeral head modeling using Kmeans++ clustering and PCA. In Proceedings of the 2020 IEEE 2nd Global Conference on Life Sciences and Technologies (LifeTech), Kyoto, Japan, 10–12 March 2020. [Google Scholar]
- Ohta, T.; Inoue, S.; Kakuda, Y. An adaptive multihop clustering scheme for highly mobile ad hoc networks. In Proceedings of the Sixth International Symposium on Autonomous Decentralized Systems, Pisa, Italy, 9–11 April 2003. [Google Scholar]
- Rossi, G.V.; Fan, Z.; Chin, W.H.; Leung, K.K. Stable Clustering for Ad-Hoc Vehicle Networking. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017. [Google Scholar]
- Mezouary, R.; Choukri, A.; Kobbane, A.; Koutbi, M. An Energy-Aware Clustering Approach Based on the K-Means Method for Wireless Sensor Networks; Springer: Singapore, 2016; pp. 325–337. [Google Scholar]
- Qin, J.; Fu, W.; Gao, H.; Zheng, W. Distributed k-Means Algorithm and Fuzzy c-Means Algorithm for Sensor Networks Based on Multiagent Consensus Theory. IEEE Trans. Cybern. 2017, 47, 772–783. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Citation | Networking Method | Clustering Metric |
|---|---|---|
| [9] | border patrol clustering algorithm | relative speed and separation distance |
| [11] | k-means | mobility and relative positions |
| [12] | k-means | bandwidth balance |
| [13] | weighted clustering algorithm | node mobility, connectivity degree, total distance to neighbors, and consumed battery power |
| [14] | group mobility based clustering algorithm | residual energy, relative velocities difference, and connections with neighbor nodes |
| [15] | hybrid gray wolf optimization method | inter-cluster distance, intra-cluster distance, residual energy, and geographic location |
| [16] | bio-inspired localization and clustering schemes | cluster building time, number of clusters, cluster lifetime, and energy consumption |
| Parameters | Values | Parameters | Values |
|---|---|---|---|
| 0.5 | |||
| 5 m/s | |||
| Initial direction | Updation interval | 0.1 s | |
| Evolution interval | 0.4 s | Total simulation time | 10 s |
| Initial number of clusters | 4 | Maximal random speed | 3 m/s |
| Cluster center speed | 30 m/s | Number of node N | 80 |
| Initial | [0, 0, 80] m | Initial | [0, 80, 40] m |
| Initial | [80, 0, 40] m | Initial | [80, 80, 0] m |
| Algorithm | Computational Complexity | Time Consumption |
|---|---|---|
| Our proposal | 0.93 s | |
| Method 1 | 1.04 s | |
| Method 2 | 0.51 s | |
| Method 3 | 2.62 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wang, X.; Liu, L. A Location and Velocity Prediction-Assisted FANET Networking Scheme for Highly Mobile Scenarios. Electronics 2023, 12, 2731. https://doi.org/10.3390/electronics12122731
Zhang J, Wang X, Liu L. A Location and Velocity Prediction-Assisted FANET Networking Scheme for Highly Mobile Scenarios. Electronics. 2023; 12(12):2731. https://doi.org/10.3390/electronics12122731
Chicago/Turabian StyleZhang, Jiachi, Xueyun Wang, and Liu Liu. 2023. "A Location and Velocity Prediction-Assisted FANET Networking Scheme for Highly Mobile Scenarios" Electronics 12, no. 12: 2731. https://doi.org/10.3390/electronics12122731