
A Transformer-Based Cross-Window Aggregated Attentional Image Inpainting Model
Abstract
:1. Introduction
- We propose a novel Transformer-based cross-window aggregated attentional image restoration network, which improves the information aggregation between windows by embedding WAT modules.
- We effectively obtain the long-range dependence of images without increasing the computational complexity and solve the problem that convolutional operations are limited by local feature extraction.
- Experiments on several datasets demonstrate the effectiveness of the proposed method and outperform the current restoration methods.
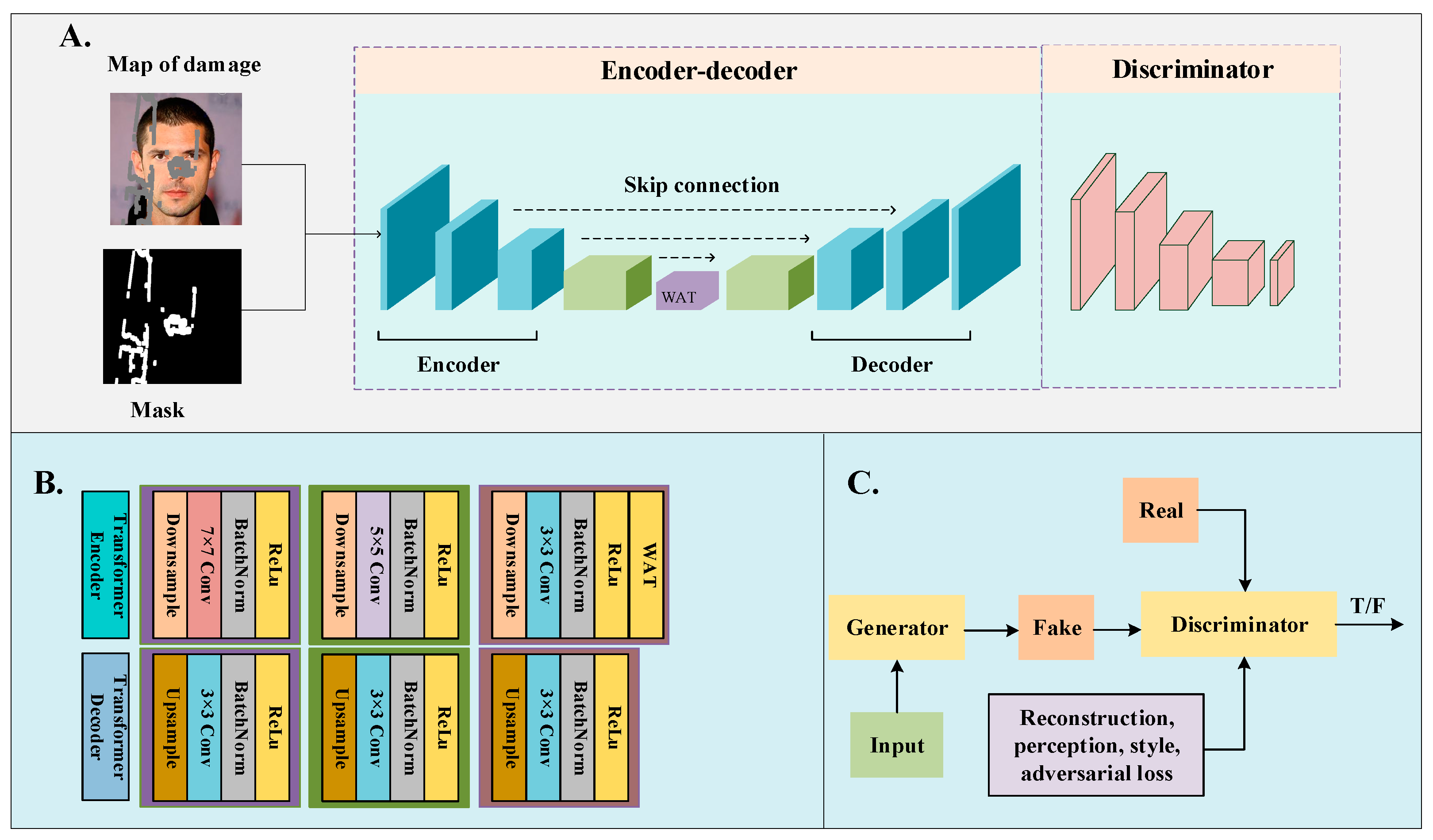
2. Overall Model Design
3. Transformer-Based Window Aggregation Attention Image Inpainting Network
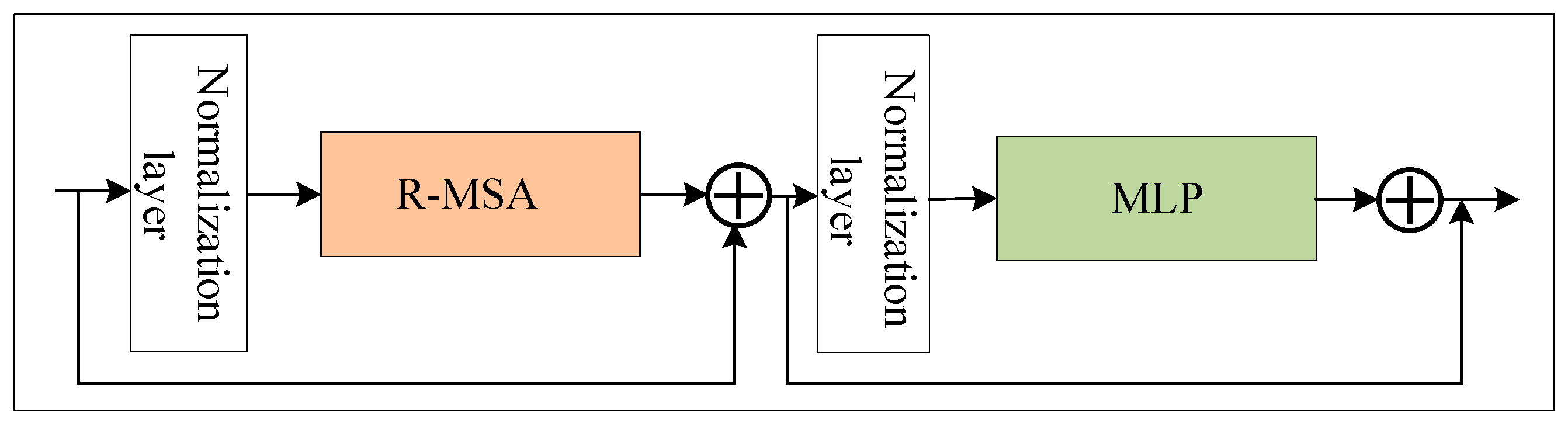
3.1. WAT Module
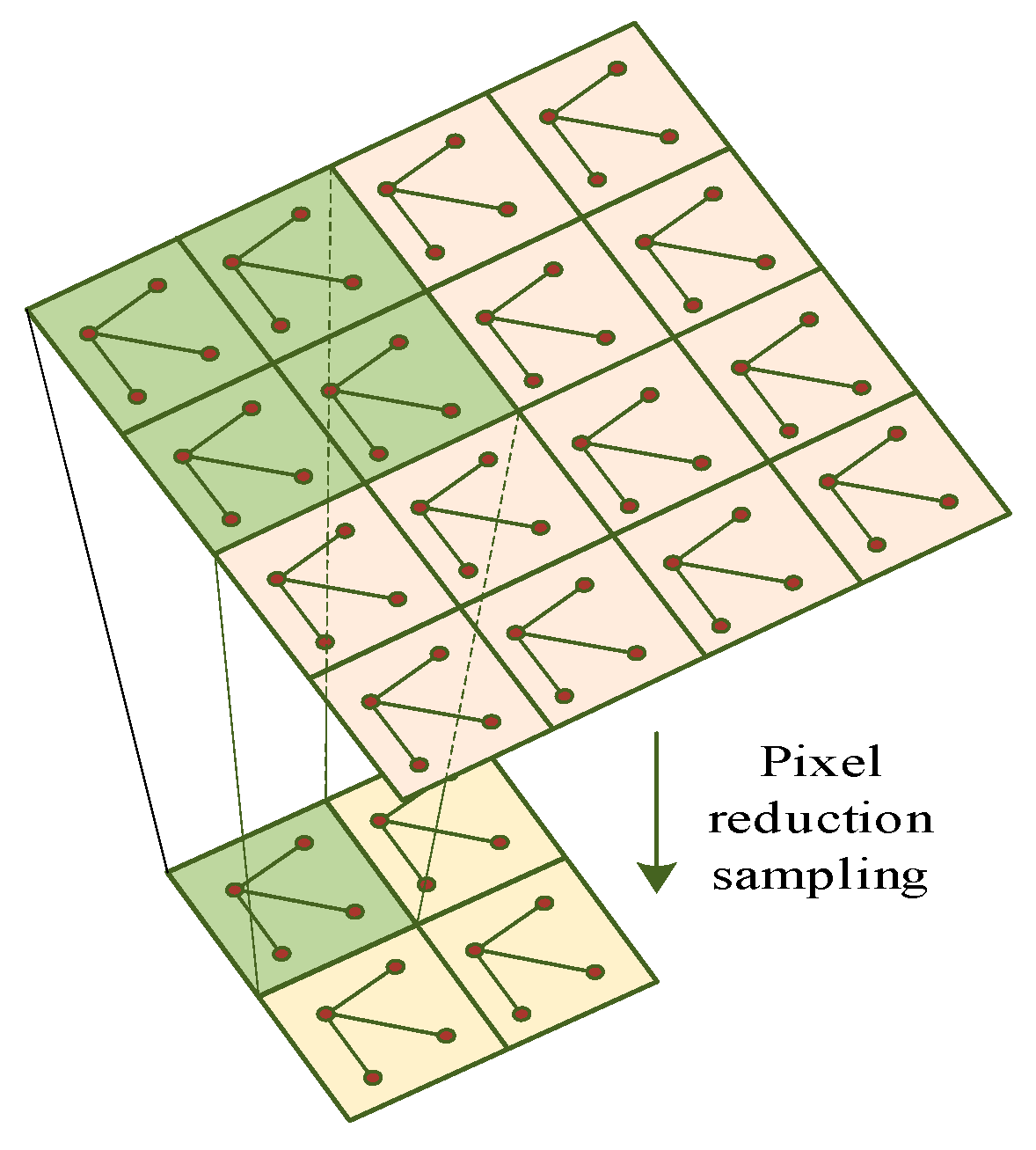
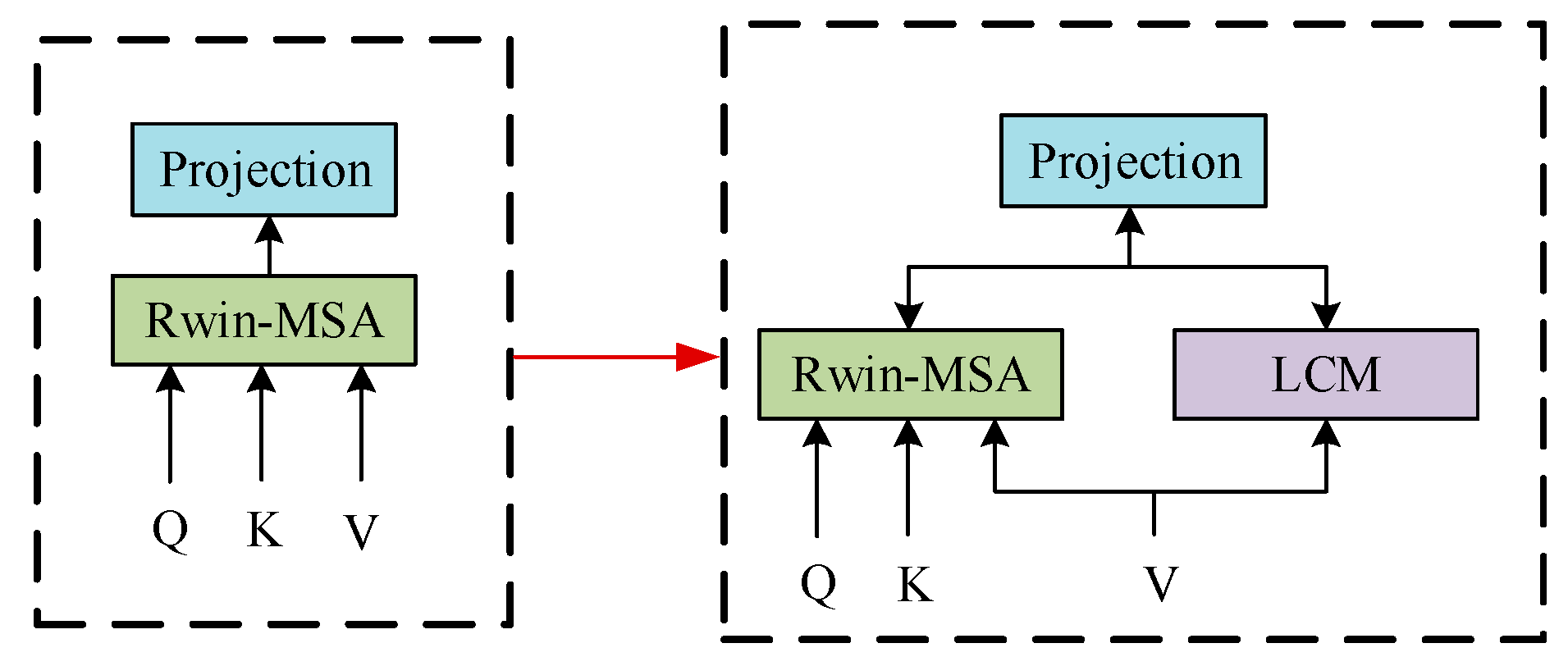
3.1.1. Construction of Rwin-MSA
3.1.2. Construction of LCM
3.2. Discriminator Network
3.3. Loss Function
- (1)
- Reconstruction loss
- (2)
- Perceptual loss [28]
- (3)
- Style loss
- (4)
- Adversarial loss [29]
4. Experimental Environment and Evaluation Index
4.1. Experimental Dataset and Pre-Processing
4.2. Qualitative Analysis
4.3. Quantitative Analysis
4.4. Ablation Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Patwardhan, K.A.; Sapiro, G.; Bertalmio, M. Video inpainting of occluding and occluded objects. In Proceedings of the IEEE International Conference on Image Processing, Genoa, Italy, 11–14 September 2005; Volume 2, pp. 69–72. [Google Scholar]
- Kumar, S.; Biswas, M.; Belongie, S.; Nguyen, T.Q. Spatio-temporal texture synthesis and image inpainting for video applications. In Proceedings of the IEEE International Conference on Image Processing, Genoa, Italy, 11–14 September 2005; Volume 2, pp. 85–88. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoder: Feature Learning by Inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and Locally Consistent Image Completion. ACM Trans. Graph. (TOG) 2017, 36, 107. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Jeon, Y.; Kim, J. Active convolution: Learning the shape of convolution for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1846–1854. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Song, Y.; Yang, C.; Lin, Z.; Liu, X.; Huang, Q.; Li, H.; Jay Kuo, C.-C. Contextual-based image inpainting: Infer, match, and translate. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. Edgeconnect: Structure guided image inpainting using edge prediction. In Proceedings of the IEEE International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Xiong, W.; Yu, J.; Lin, Z.; Yang, J.; Lu, X.; Barnes, C.; Luo, J. Foreground-aware image inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Yurui, R.; Xiaoming, Y.; Ruonan, Z.; Li, T.H.; Liu, S.; Li, G. Structureflow: Image inpainting via structure-aware appearance flow. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Li, J.; He, F.; Zhang, L.; Du, B.; Tao, D. Progressive reconstruction of visual structure for image inpainting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Yang, J.; Qi, Z.Q.; Shi, Y. Learning to incorporate structure knowledge for image inpainting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Liu, H.; Jiang, B.; Song, Y.; Huang, W.; Yang, C. Rethinking image inpainting via a mutual encoder-decoder with feature equalizations. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Guo, X.; Yang, H.; Huang, D. Image Inpainting via Conditional Texture and Structure Dual Generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 14114–14123. [Google Scholar]
- Liu, H.; Wan, Z.; Huang, W.; Song, Y.; Han, X.; Liao, J. PD-GAN: Probabilistic diverse GAN for image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 9367–9376. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.-C.; Tao, A.; Catanzaro, B. Image Inpainting for Irregular Holes using Partial Convolutions; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Zheng, C.; Zhang, Y.; Gu, J.; Zhang, Y.; Kong, L.; Yuan, X. Cross aggregation transformer for image inpainting. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position repre-sentations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.H.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1125–1134. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; Available online: OpenReview.net (accessed on 5 October 2021).
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; p. 80. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 3730–3738. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; Ithaca: New York, NY, USA, 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Convolution Kernels | Step Lengths | Activation Functions |
|---|---|---|---|
| 1 | 4 | 2 | LeakyReLu |
| 2 | 4 | 2 | LeakyReLu |
| 3 | 4 | 2 | LeakyReLu |
| 4 | 4 | 1 | LeakyReLu |
| Full Connection | - | - | Sigmoid |
| Evaluation Metrics | Mask Category | BIFPN | CTSDG | DF-Net | Ours |
|---|---|---|---|---|---|
| PSNR | 10–20% | 32.34 | 38.78 | 38.56 | 38.61 |
| 20–30% | 31.82 | 37.75 | 38.63 | 38.71 | |
| 30–40% | 29.28 | 31.76 | 31.79 | 34.34 | |
| 40–50% | 26.13 | 29.30 | 29.12 | 31.25 | |
| 50–60% | 23.73 | 24.37 | 25.50 | 26.15 | |
| SSIM | 10–20% | 0.968 | 0.967 | 0.969 | 0.973 |
| 20–30% | 0.963 | 0.962 | 0.965 | 0.967 | |
| 30–40% | 0.929 | 0.927 | 0.929 | 0.940 | |
| 40–50% | 0.858 | 0.855 | 0.861 | 0.865 | |
| 50–60% | 0.734 | 0.729 | 0.737 | 0.741 | |
| FID | 10–20% | 6.31 | 5.48 | 4.98 | 4.86 |
| 20–30% | 8.51 | 7.69 | 7.80 | 7.67 | |
| 30–40% | 18.96 | 20.77 | 16.04 | 15.24 | |
| 40–50% | 22.36 | 21.18 | 18.98 | 17.74 | |
| 50–60% | 25.26 | 23.74 | 22.91 | 19.58 |
| Evaluation Metrics | Mask Category | BIFPN | CTSDG | DF-Net | Ours |
|---|---|---|---|---|---|
| PSNR | 20–30% | 31.34 | 30.21 | 32.08 | 33.32 |
| 30–40% | 29.85 | 28.53 | 30.97 | 32.79 | |
| 40–50% | 28.69 | 27.53 | 30.06 | 31.20 | |
| 50–60% | 28.20 | 27.29 | 29.68 | 29.76 | |
| SSIM | 20–30% | 0.954 | 0.958 | 0.957 | 0.961 |
| 30–40% | 0.864 | 0.850 | 0.861 | 0.872 | |
| 40–50% | 0.847 | 0.835 | 0.849 | 0.854 | |
| 50–60% | 0.812 | 0.809 | 0.826 | 0.831 | |
| FID | 20–30% | 11.23 | 10.98 | 10.40 | 10.34 |
| 30–40% | 19.61 | 20.70 | 15.26 | 15.13 | |
| 40–50% | 24.36 | 18.18 | 17.98 | 17.58 | |
| 50–60% | 26.27 | 21.74 | 21.30 | 19.92 |
| Evaluation Metrics | Mask Category | No/WAT | Ours |
|---|---|---|---|
| PSNR | 10–20% | 37.34 | 38.61 |
| 20–30% | 36.82 | 38.21 | |
| 30–40% | 30.28 | 34.34 | |
| 40–50% | 26.13 | 31.25 | |
| 50–60% | 19.73 | 26.15 | |
| SSIM | 10–20% | 0.968 | 0.973 |
| 20–30% | 0.961 | 0.967 | |
| 30–40% | 0.921 | 0.930 | |
| 40–50% | 0.848 | 0.865 | |
| 50–60% | 0.714 | 0.741 | |
| FID | 10–20% | 5.10 | 4.86 |
| 20–30% | 8.72 | 7.67 | |
| 30–40% | 18.56 | 15.24 | |
| 40–50% | 22.10 | 17.74 | |
| 50–60% | 25.12 | 19.58 |
| Evaluation Metrics | Mask Category | No/WAT | Ours |
|---|---|---|---|
| PSNR | 10–20% | 34.15 | 34.21 |
| 20–30% | 32.72 | 33.21 | |
| 30–40% | 30.89 | 32.57 | |
| 40–50% | 28.13 | 30.39 | |
| 50–60% | 24.73 | 28.46 | |
| SSIM | 10–20% | 0.968 | 0.971 |
| 20–30% | 0.956 | 0.963 | |
| 30–40% | 0.856 | 0.867 | |
| 40–50% | 0.839 | 0.850 | |
| 50–60% | 0.794 | 0.834 | |
| FID | 10–20% | 7.53 | 6.78 |
| 20–30% | 11.02 | 10.29 | |
| 30–40% | 16.76 | 15.56 | |
| 40–50% | 20.10 | 17.51 | |
| 50–60% | 24.19 | 19.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Liu, T.; Xiong, X.; Duan, Z.; Cui, A. A Transformer-Based Cross-Window Aggregated Attentional Image Inpainting Model. Electronics 2023, 12, 2726. https://doi.org/10.3390/electronics12122726
Chen M, Liu T, Xiong X, Duan Z, Cui A. A Transformer-Based Cross-Window Aggregated Attentional Image Inpainting Model. Electronics. 2023; 12(12):2726. https://doi.org/10.3390/electronics12122726
Chicago/Turabian StyleChen, Mingju, Tingting Liu, Xingzhong Xiong, Zhengxu Duan, and Anle Cui. 2023. "A Transformer-Based Cross-Window Aggregated Attentional Image Inpainting Model" Electronics 12, no. 12: 2726. https://doi.org/10.3390/electronics12122726