
Seismic Data Query Algorithm Based on Edge Computing
Abstract
:1. Introduction
- Construct the System Model. We propose a lookup mechanism by bloom filter, which can quickly determine if there is the information that we need on a particular edge server. In addition, we formulate the MEC-based data query as a long-term average optimization problem, whose goal is to optimize the service delay with the constraints of computing capacity.
- DRL-based Algorithm. Considering the complexity of problem, we further transform the problem into an MDP by defining the state space, action space and reward function. A model-free deep reinforcement learning algorithm is proposed to solve the problem. Instead of using a traditional -greedy strategy, we introduce the confidence interval to explore action, which can improve the training efficiency of the model.
- Comparison-based Evaluation. We perform extensive simulations to evaluate the performance of our proposed algorithm. The simulation results show that our algorithm achieves better performance in comparison with two baselines.
2. Related Works
2.1. Edge Computing
2.2. Wireless Network in Earthquakes
2.3. Quick Lookup Mechanism
3. System Modeling
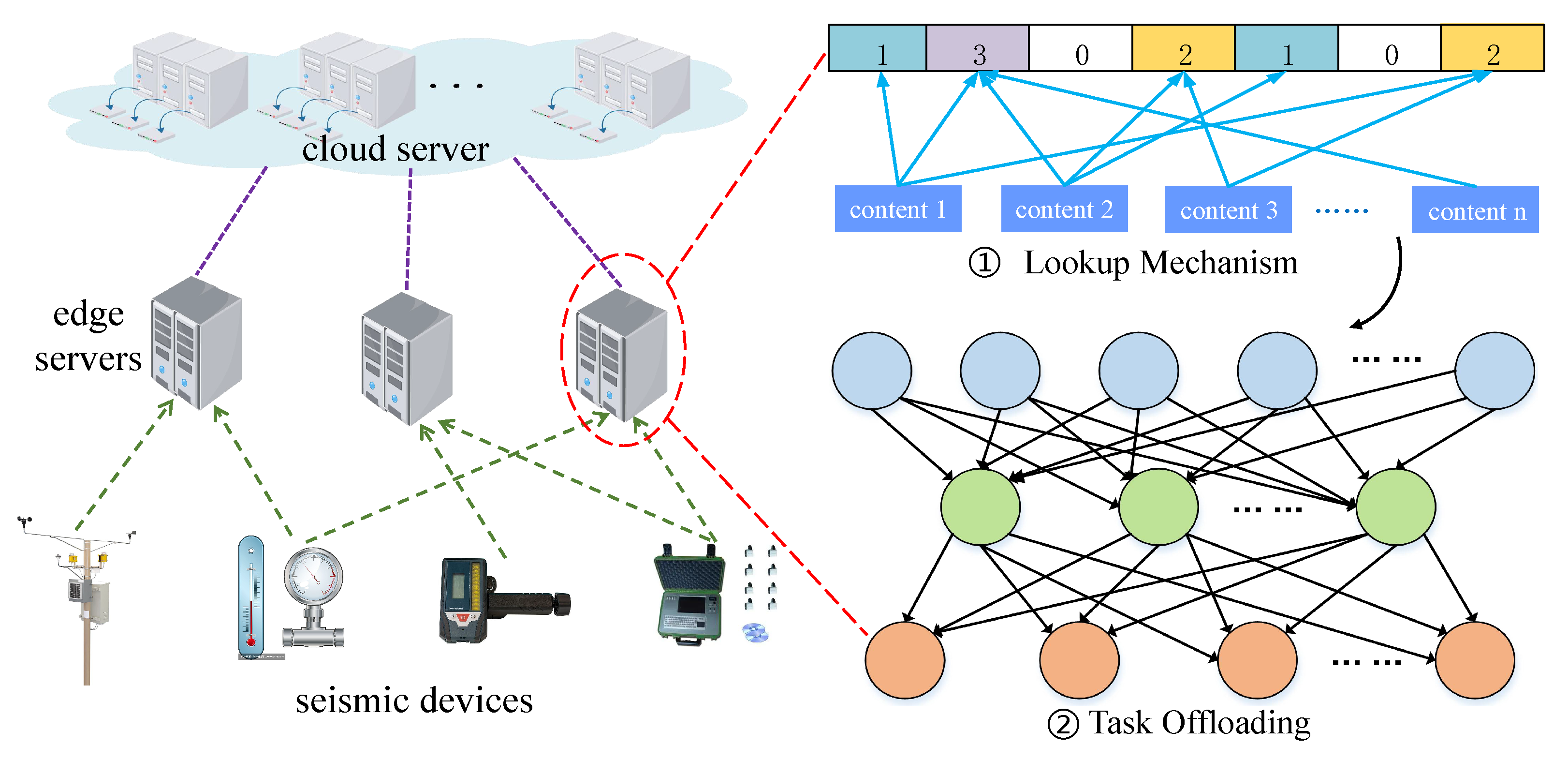
3.1. Scenario Description
3.2. Lookup Mechanism
3.3. Service Delay
3.4. Problem Formulation
4. Algorithm Design
4.1. Markov Decision Process
4.2. DRL-Based Algorithm
| Algorithm 1 DQN-based seismic data query algorithm. |
|
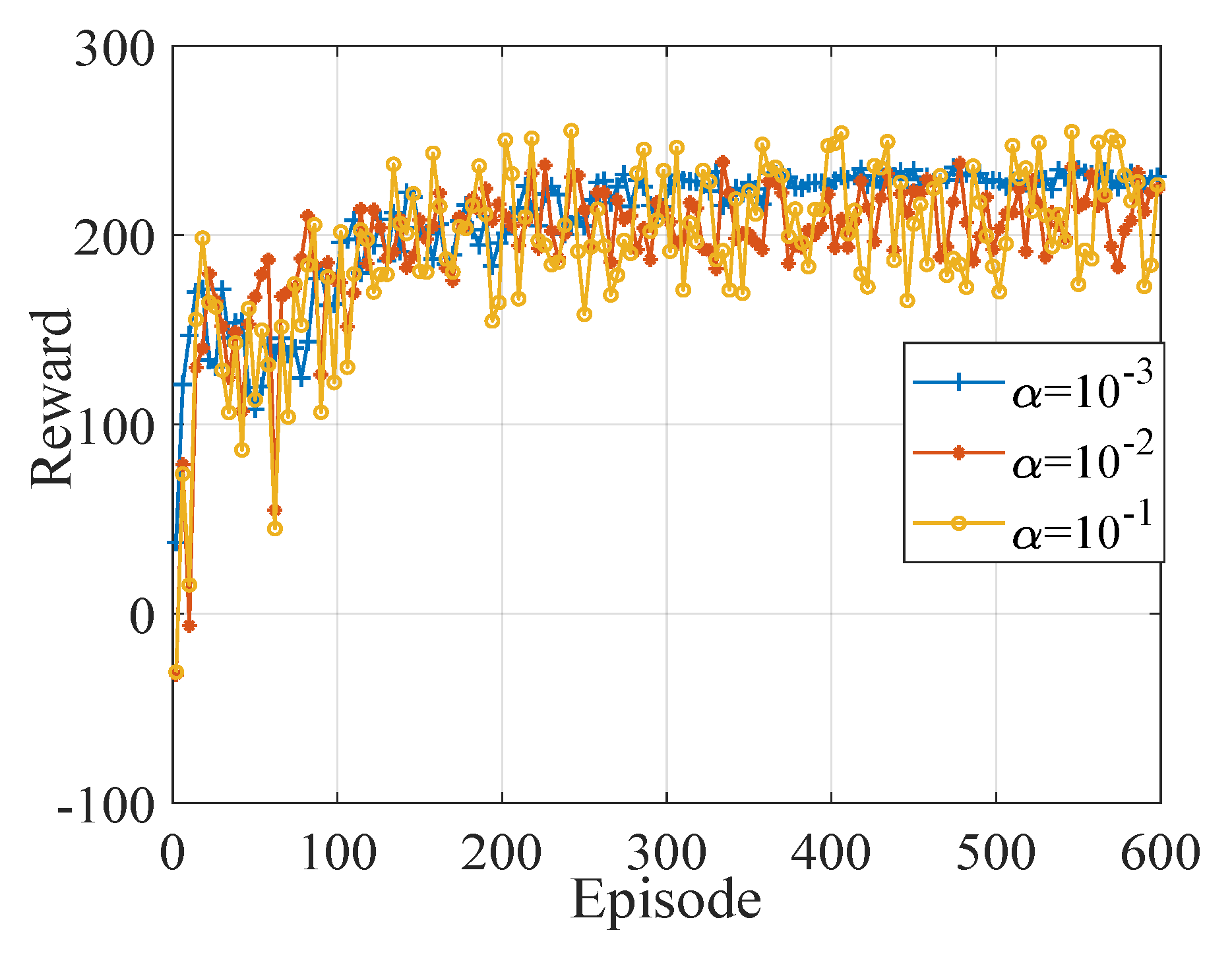
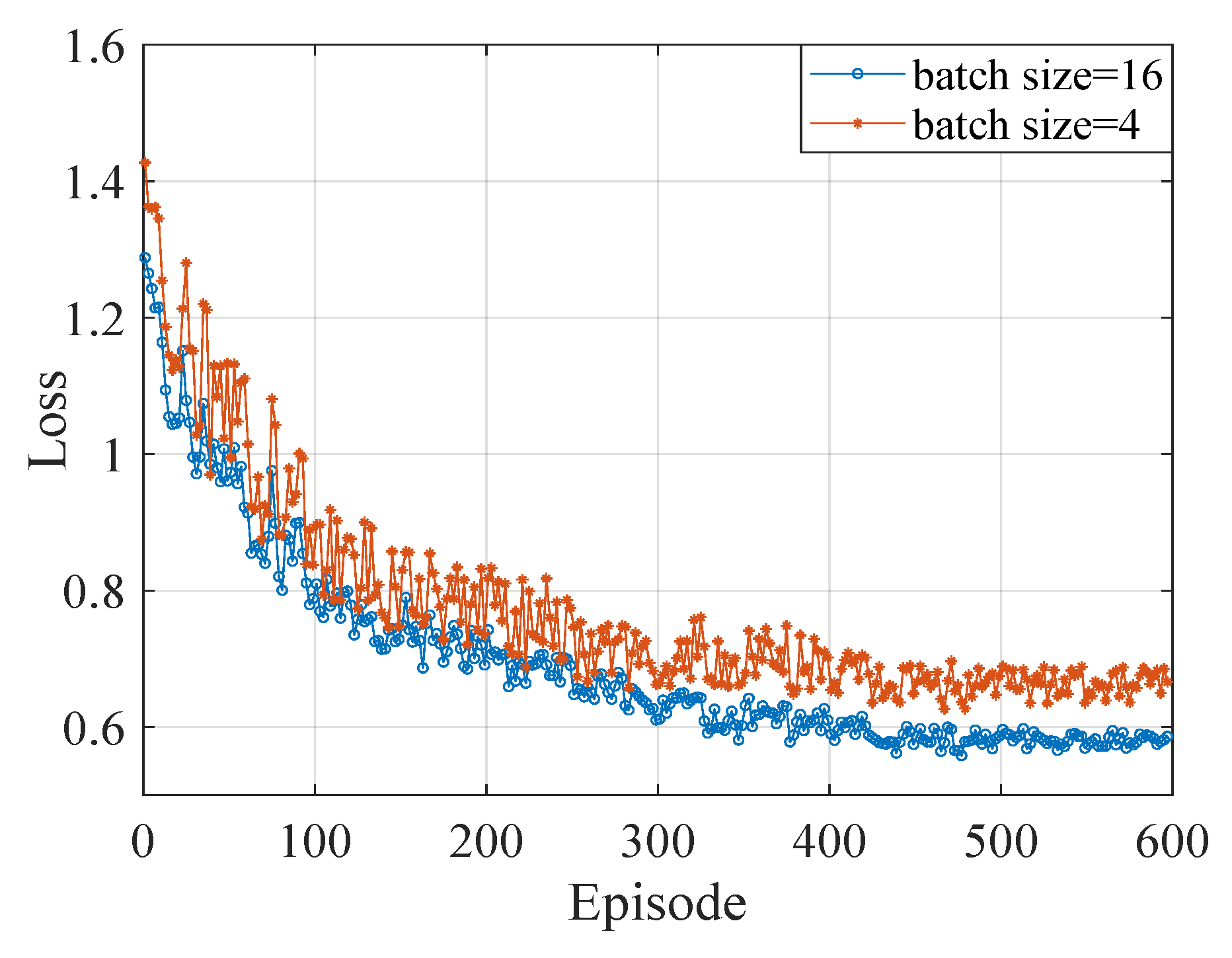
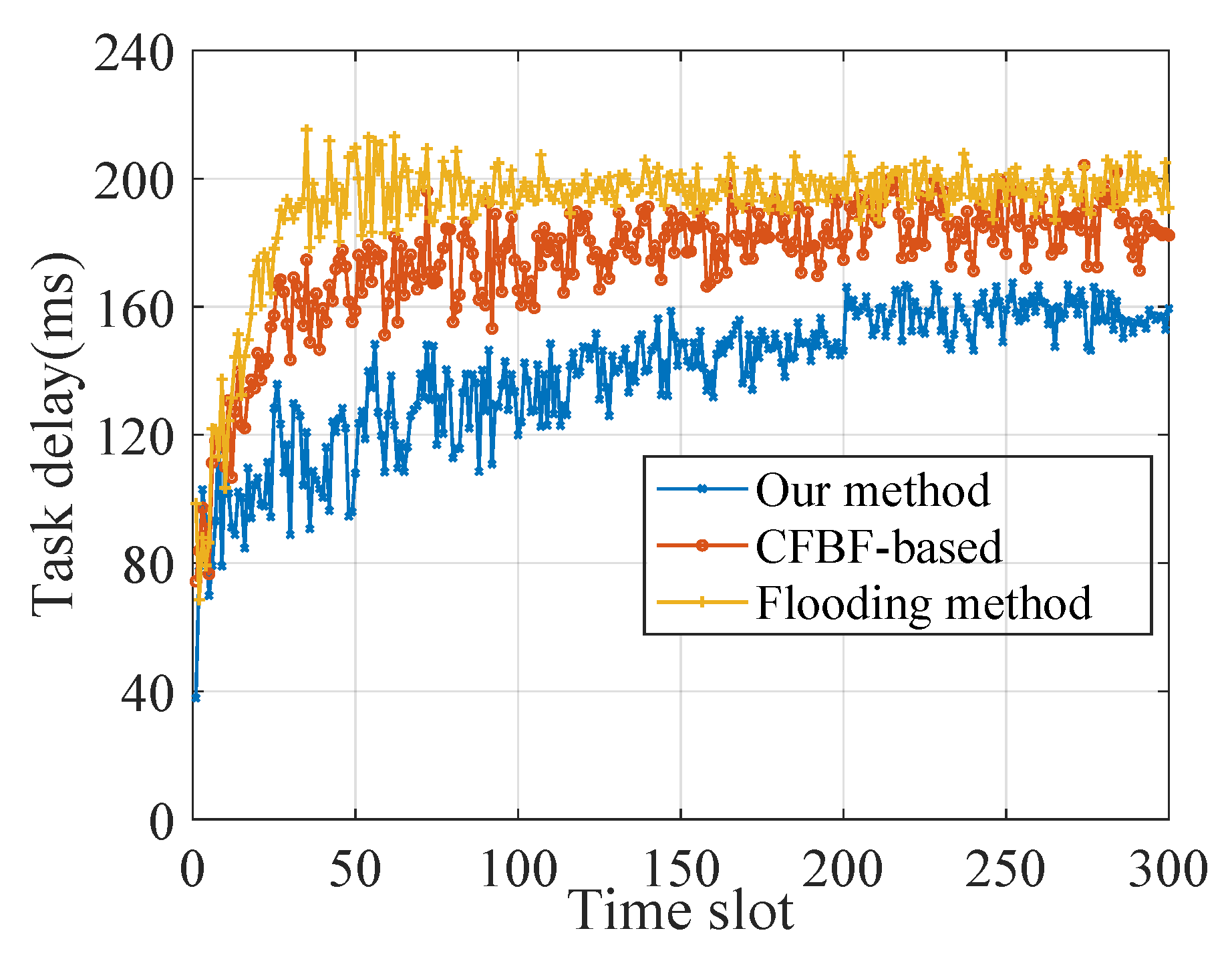
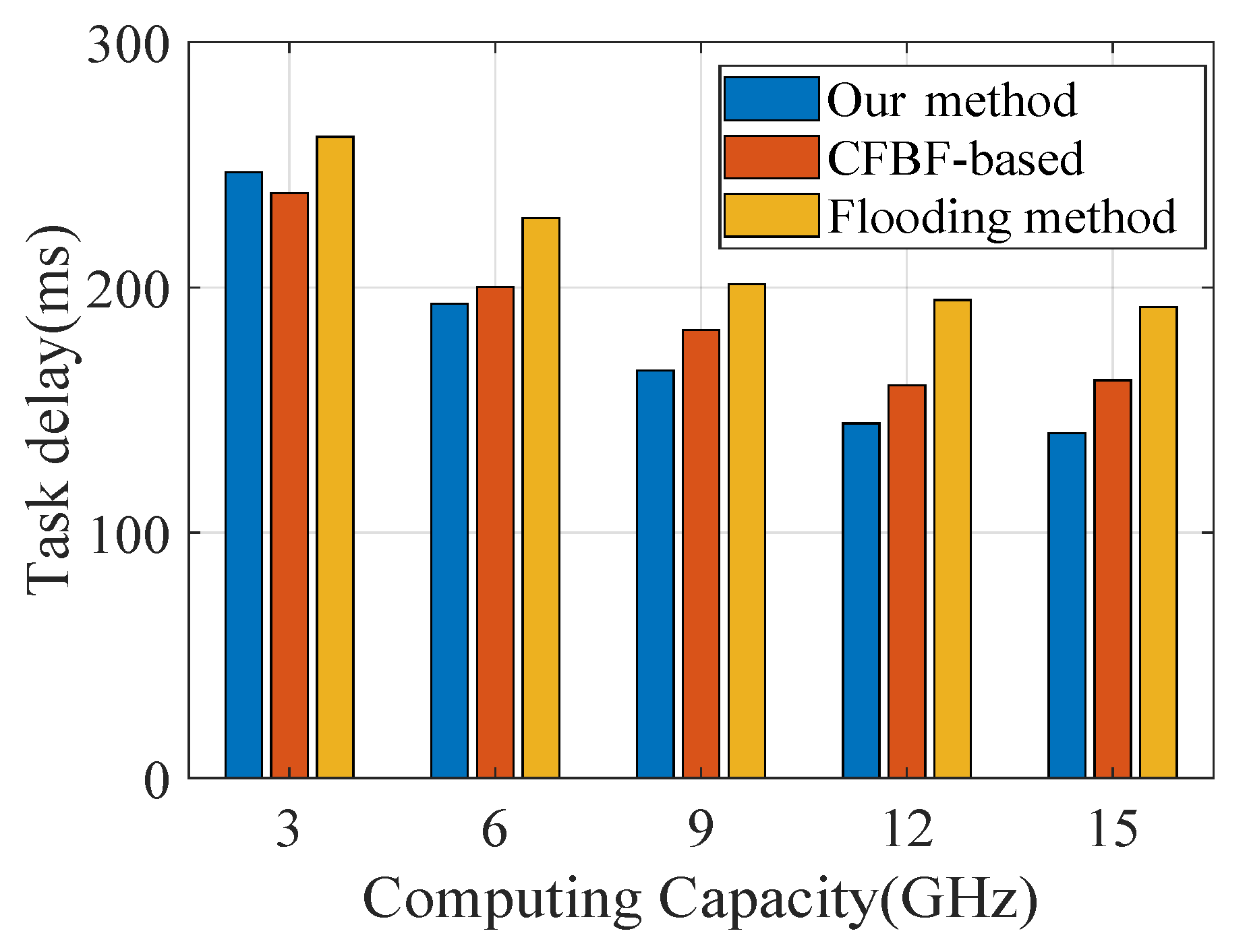
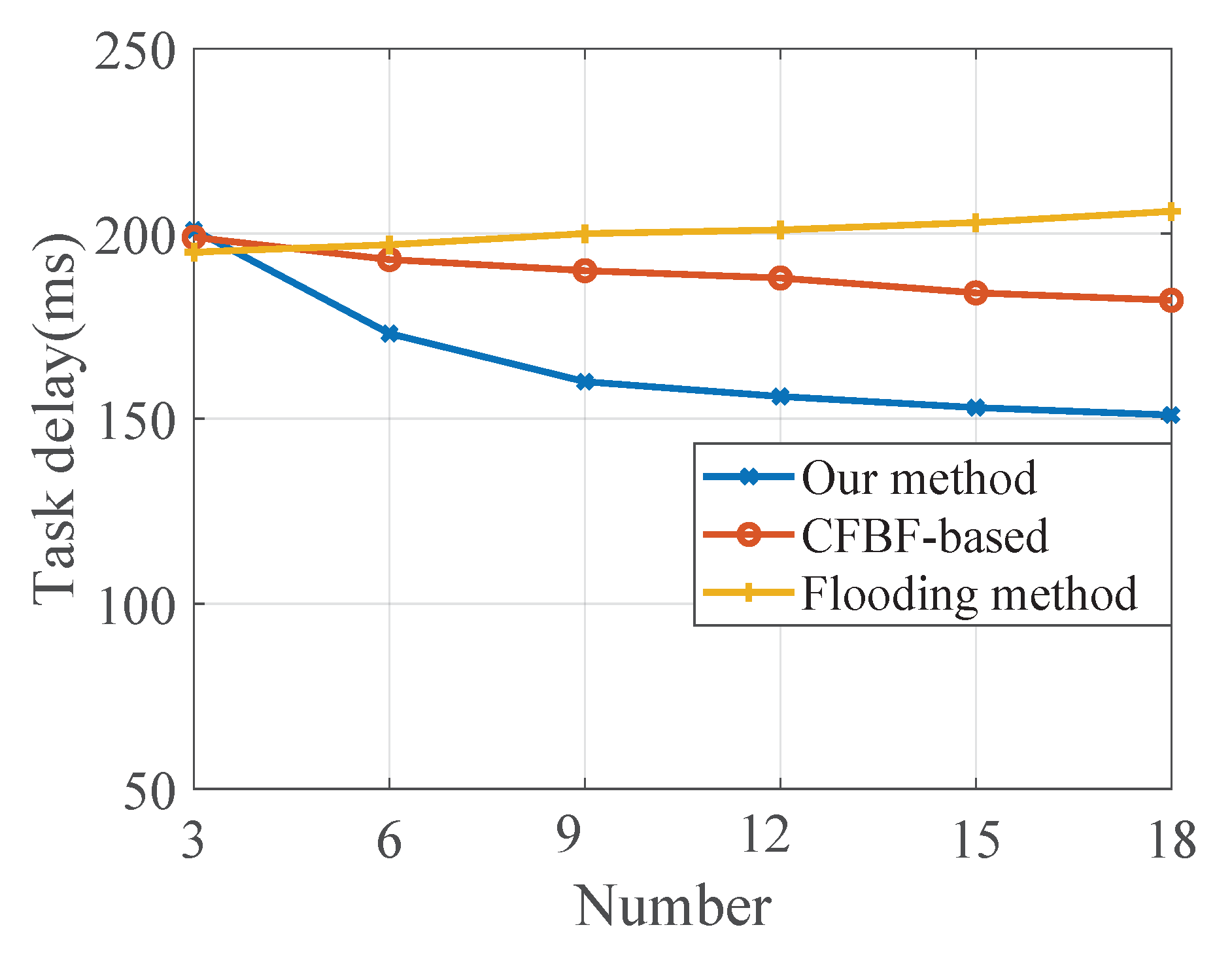
5. Simulation Results
5.1. Simulation Scenario and Setup
- Flooding method: When the edge server receives the lookup request, if there is no relevant content after the local lookup, it will forward the request to all other edge server nodes. When the other edge server receives the request, it will perform the lookup of the task.
- CFBF-based method: We apply Cuckoo Filters With an Integrated Bloom Filter (CFBF) [23] to the content lookup of edge servers. When the edge server receives the lookup request, it will quickly determine which edge servers store the content by cuckoo filters and randomly select a edge server to forward the request.
5.2. Performance Evaluation
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abdalzaher, M.S.; Soliman, M.S.; El-Hady, S.M.; Benslimane, A.; Elwekeil, M. A Deep Learning Model for Earthquake Parameters Observation in IoT System-Based Earthquake Early Warning. IEEE Internet Things J. 2022, 9, 8412–8424. [Google Scholar] [CrossRef]
- Khan, I.; Pandey, M.; Kwon, Y.-W. An earthquake alert system based on a collaborative approach using smart devices. In Proceedings of the IEEE/ACM International Conference on Mobile Software Engineering and Systems (MobileSoft), Madrid, Spain, 17–19 May 2021. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Luo, R.; Jin, H.; He, Q.; Wu, S.; Xia, X. Cost-Effective Edge Server Network Design in Mobile Edge Computing Environment. IEEE Trans. Sustain. Comput. 2022, 7, 839–850. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Chen, Y.; Zhang, N.; Zhang, Y.; Chen, X.; Wu, W.; Shen, X. Energy Efficient Dynamic Offloading in Mobile Edge Computing for Internet of Things. IEEE Trans. Cloud Comput. 2021, 9, 1050–1060. [Google Scholar] [CrossRef] [Green Version]
- Zaw, C.W.; Tran, N.H.; Han, Z.; Hong, C.S. Radio and Computing Resource Allocation in Co-Located Edge Computing: A Generalized Nash Equilibrium Model. IEEE Trans. Mob. Comput. 2023, 22, 2340–2352. [Google Scholar] [CrossRef]
- Sun, W.-B.; Xie, J.; Yang, X.; Wang, L.; Meng, W.-X. Efficient Computation Offloading and Resource Allocation Scheme for Opportunistic Access Fog-Cloud Computing Networks. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 521–533. [Google Scholar] [CrossRef]
- Yuan, L.; He, Q.; Tan, S.; Li, B.; Yu, J.; Chen, F.; Yang, Y. CoopEdge+: Enabling Decentralized, Secure and Cooperative Multi-Access Edge Computing Based on Blockchain. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 894–908. [Google Scholar] [CrossRef]
- Zhang, Q.; Sun, S.; Liu, M.; Li, Z.; Zhang, Z. Online Joint Optimization Mechanism of Task Offloading and Service Caching for Multi-Edge Device Collaboration. J. Comput. Res. Dev. 2021, 58, 1318–1339. [Google Scholar]
- Naouri, A.; Wu, H.; Nouri, N.A.; Dhelim, S.; Ning, H. A Novel Framework for Mobile-Edge Computing by Optimizing Task Offloading. IEEE Internet Things J. 2021, 8, 13065–13076. [Google Scholar] [CrossRef]
- Gao, X.; Huang, X.; Bian, S.; Shao, Z.; Yang, Y. PORA: Predictive Offloading and Resource Allocation in Dynamic Fog Computing Systems. IEEE Internet Things J. 2020, 7, 72–87. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, J.; Wang, T.; Wu, K. A Fine-Grained Multi-Access Edge Computing Architecture for Cloud-Network Integration. J. Comput. Res. Dev. 2021, 58, 1275–1290. [Google Scholar]
- Shinde, S.S.; Bozorgchenani, A.; Tarchi, D.; Ni, Q. On the Design of Federated Learning in Latency and Energy Constrained Computation Offloading Operations in Vehicular Edge Computing Systems. IEEE Trans. Veh. Technol. 2022, 71, 2041–2057. [Google Scholar] [CrossRef]
- Pal, Y.; Nagendram, S.; Al Ansari, M.S.; Singh, K.; Gracious, L.A.A.; Patil, P. IoT based Weather, Soil, Earthquake, and Air Pollution Monitoring System. In Proceedings of the International Conference on Computing Methodologies and Communication (ICCMC), Dubai, United Arab Emirates, 28–29 January 2023. [Google Scholar]
- Aoi, S.; Takeda, T.; Kunugi, T.; Shinohara, M.; Miyoshi, T.; Uehira, K.; Takahashi, N. Development and Construction of Nankai Trough Seafloor Observation Network for Earthquakes and Tsunamis: N-net. In Proceedings of the IEEE Underwater Technology (UT), Tokyo, Japan, 6–9 March 2023; pp. 1–5. [Google Scholar]
- Khalifeh, A.; Darabkh, K.A.; Khasawneh, A.; Alqaisieh, I.; Salameh, M.; AlAbdala, A.; Alrubaye, S.; Alassa, A.; Al-HajAli, S.; Al-Wardat, R.; et al. Wireless Sensor Networks for Smart Cities: Network Design, Implementation and Performance Evaluation. Electronics 2021, 10, 218. [Google Scholar] [CrossRef]
- Boccadoro, P.; Montaruli, B.; Grieco, L.A. QuakeSense, a LoRa-compliant Earthquake Monitoring Open System. In Proceedings of the IEEE/ACM International Symposium on Distributed Simulation and Real Time Applications (DS-RT), Cosenza, Italy, 7–9 October 2019. [Google Scholar]
- Liu, J.; Ge, X.; Wen, L.; Zhao, H.; Zhuo, J.; Dong, X. Energy Allocation Strategy of Earthquake Monitoring Wireless Sensor Network Based on Longitude and Latitude Coding and Differential Evolution Algorithm. In Proceedings of the International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; pp. 1136–1141. [Google Scholar]
- Klapez, M.; Grazia, C.A.; Zennaro, S.; Cozzani, M.; Casoni, M. First Experiences with Earthcloud, a Low-Cost, Cloud-Based IoT Seismic Alert System. In Proceedings of the International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Limassol, Cyprus, 15–17 October 2018; pp. 262–269. [Google Scholar]
- Li, Z.; Liu, J.; Yan, L.; Zhang, B.; Luo, P.; Liu, K. Smart Name Lookup for NDN Forwarding Plane via Neural Networks. IEEE/ACM Trans. Netw. 2022, 30, 529–541. [Google Scholar] [CrossRef]
- Reviriego, P.; Martínez, J.; Pontarelli, S. CFBF: Reducing the Insertion Time of Cuckoo Filters With an Integrated Bloom Filter. IEEE Commun. Lett. 2019, 23, 1857–1861. [Google Scholar] [CrossRef]
- Reviriego, P.; Sánchez-Macián, A.; Rottenstreich, O.; Larrabeiti, D. Adaptive One Memory Access Bloom Filters. IEEE Trans. Netw. Serv. Manag. 2022, 19, 848–859. [Google Scholar] [CrossRef]
- Wu, L.; Sharifi, R.; Venkat, A.; Skadron, K. DRAM-CAM: General-Purpose Bit-Serial Exact Pattern Matching. IEEE Comput. Archit. Lett. 2022, 21, 89–92. [Google Scholar] [CrossRef]
- Kaljic, E.; Maric, A.; Njemcevic, P. Bloom filter based acceleration scheme for flow table lookup in SDN switches. In Proceedings of the International Conference on Information, Communication and Automation Technologies (ICAT), Sarajevo, Bosnia and Herzegovina, 16–18 June 2022; pp. 1–6. [Google Scholar]
- Hao, H.; Xu, C.; Zhang, W.; Yang, S.; Muntean, G.-M. Computing Offloading with Fairness Guarantee: A Deep Reinforcement Learning Method. IEEE Trans. Circuits Syst. Video Technol. 2023. early access. [Google Scholar] [CrossRef]
- Fan, Z.; Wen, G.; Huang, Z.; Zhou, Y.; Fu, Q.; Yang, T.; Liu, A.X.; Cui, B. On the Evolutionary of Bloom Filter False Positives—An Information Theoretical Approach to Optimizing Bloom Filter Parameters. IEEE Trans. Knowl. Data Eng. 2022, 35, 7316–7327. [Google Scholar] [CrossRef]
- Xiao, H.; Xu, C.; Ma, Y.; Yang, S.; Zhong, L.; Muntean, G.-M. Edge Intelligence: A Computational Task Offloading Scheme for Dependent IoT Application. IEEE Trans. Wirel. Commun. 2022, 21, 7222–7237. [Google Scholar] [CrossRef]
- Hao, H.; Xu, C.; Yang, S.; Zhong, L.; Muntean, G.-M. Multicast-aware Optimization for Resource Allocation with Edge Computing and Caching. J. Netw. Comput. Appl. 2021, 193, 103195. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Cooperation of Nodes | Long-Term Average | Content Lookup |
|---|---|---|---|
| [7] | × | × | × |
| [8,9] | × | ✓ | × |
| [11,12] | ✓ | × | ✓ |
| [13,14,15] | ✓ | ✓ | × |
| our solution | ✓ | ✓ | ✓ |
| Notation | Explanation |
|---|---|
| Set of edge servers | |
| Computing capacity of edge server n | |
| Set of tasks | |
| Set of time slots | |
| Computing resource requirement of task k | |
| Data size of task k | |
| Fixed transmission power of n | |
| The channel bandwidth between n and m | |
| Channel gain between n and m | |
| Noise power | |
| Service delay status of edge server n for task k | |
| Edge server status for task k | |
| l | Size of the bit array |
| j | The number of element |
| p | The acceptable misjudgment rate |
| i | The number of hash functions |
| Computation delay of task k | |
| Transmission rate between edge server m and n | |
| Transmission delay of service k | |
| Computation resources that m assigns to k |
| Parameters | Value |
|---|---|
| The number of seismic devices | 30 |
| The number of edge servers | 6 |
| Computing capacity of edge server | [30, 40] GHz |
| Transmission rate of the seismic device to the edge server | [10 Mbps, 15 Mbps] |
| Computing workload of a task | [0.5, 1.5] Gigacycles |
| The amount of data transmitted of a computing task | [1 Mbits, 2 Mbits] |
| Batch size of neural network | 16 |
| Learning rate of neural network | |
| optimizer | SGD |
| Algorithm | Lookup Mechanism | Task Offloading Method |
|---|---|---|
| Flooding method | None | None |
| CFBF-based method | CFBF | None |
| Our method | BF | DQN-based |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quan, T.; Zhang, H.; Yu, Y.; Tang, Y.; Liu, F.; Hao, H. Seismic Data Query Algorithm Based on Edge Computing. Electronics 2023, 12, 2728. https://doi.org/10.3390/electronics12122728
Quan T, Zhang H, Yu Y, Tang Y, Liu F, Hao H. Seismic Data Query Algorithm Based on Edge Computing. Electronics. 2023; 12(12):2728. https://doi.org/10.3390/electronics12122728
Chicago/Turabian StyleQuan, Tenglong, Huifeng Zhang, Yonghao Yu, Yongwei Tang, Fushun Liu, and Hao Hao. 2023. "Seismic Data Query Algorithm Based on Edge Computing" Electronics 12, no. 12: 2728. https://doi.org/10.3390/electronics12122728