


IoT Device Identification Method Based on Causal Inference
Abstract
:1. Introduction
- An IoT device identification method for cross-layer protocol feature fingerprinting is proposed. The key features are automatically extracted using a causal inference method, which better trades off identification accuracy and labor cost.
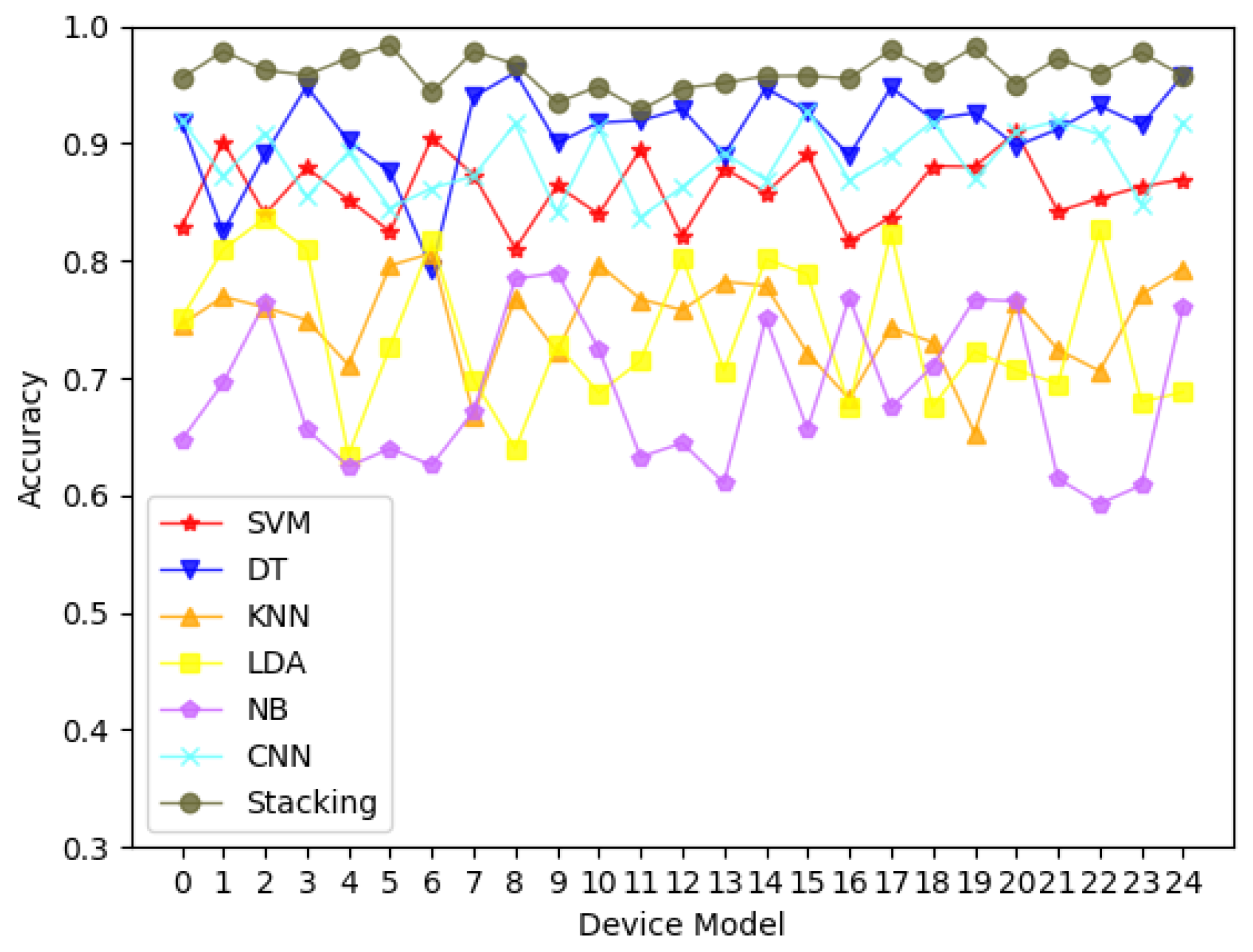
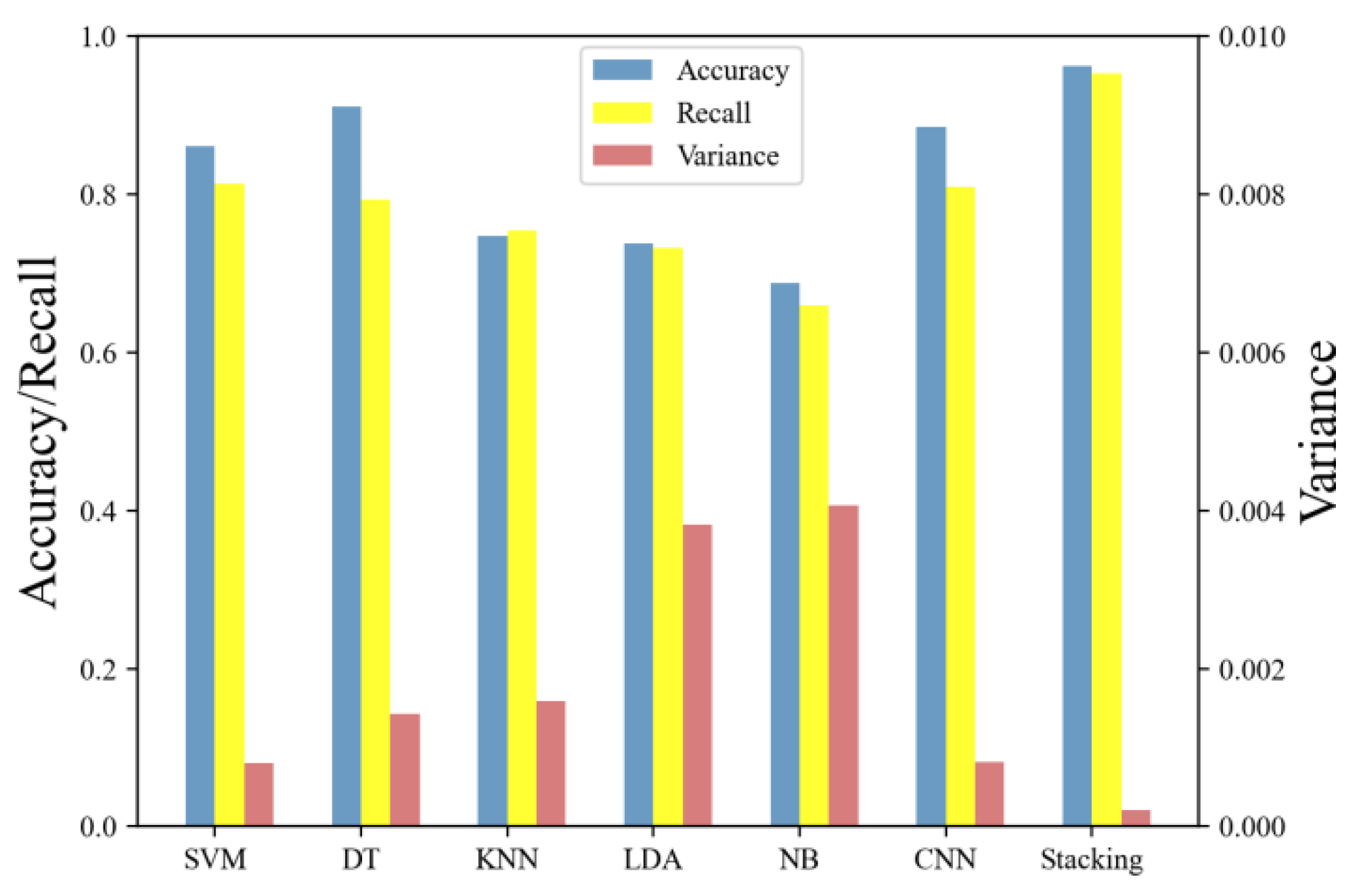
- The Stacking method is used to reduce the model variance and is experimentally demonstrated to achieve 96.3% and 97.7% identification accuracy under HTTP/TCP and SSH/TCP protocol clusters, respectively.
2. Related Work
2.1. Causal Inference
2.2. Device Identification
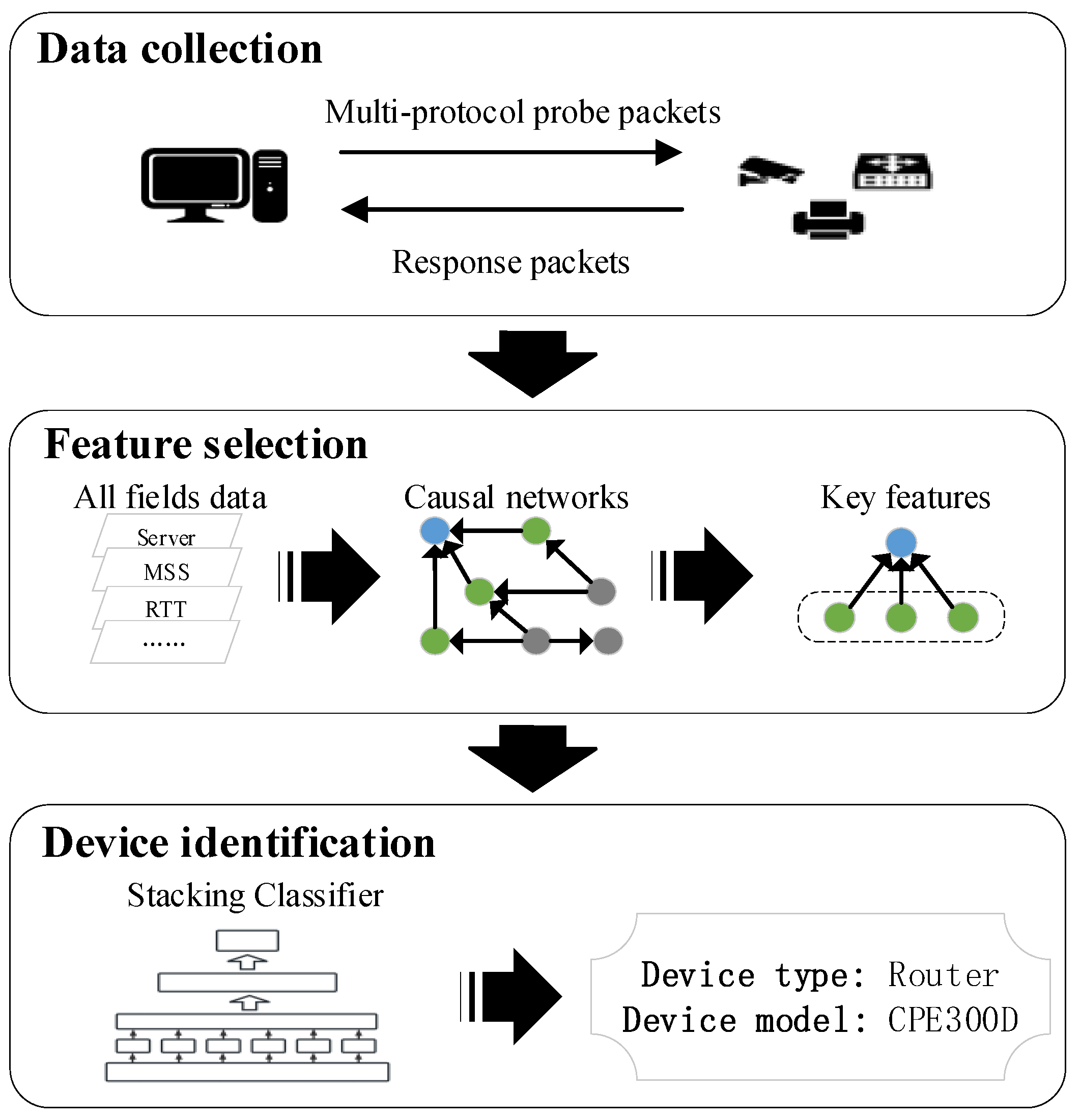
3. Framework for IoT Device Identification
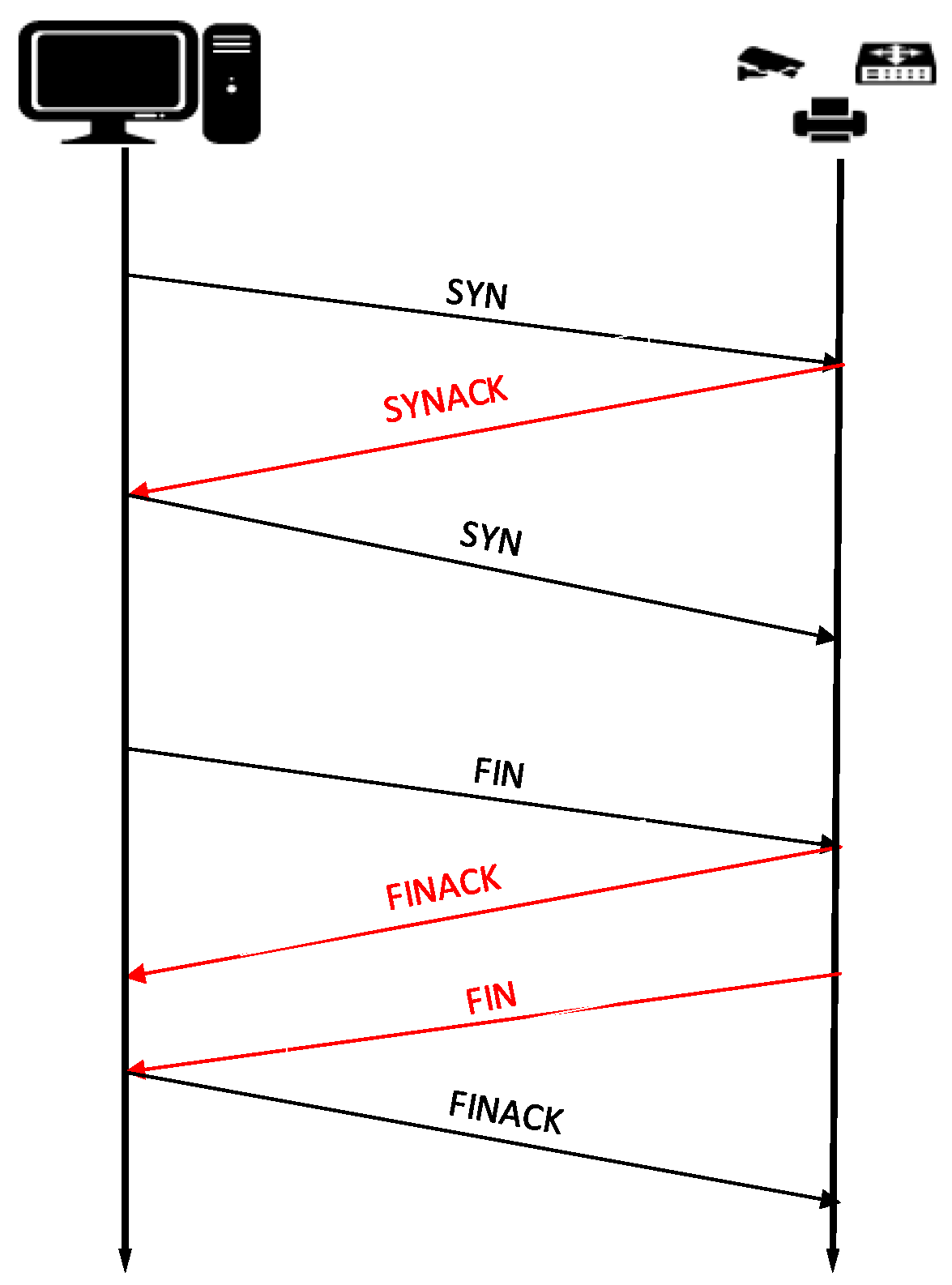
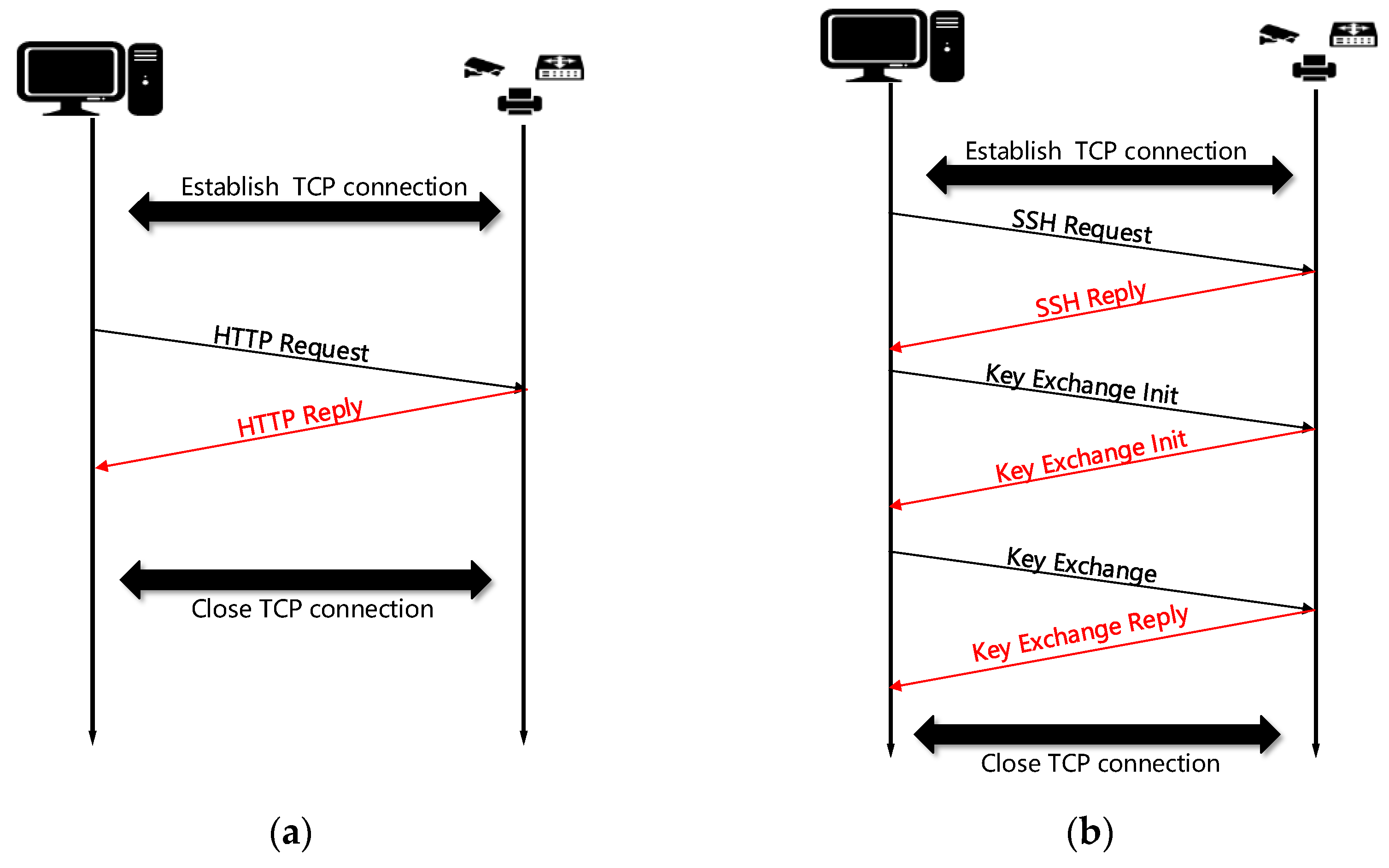
- Data collection. Firstly, based on the normal workflow of IoT devices, the packet sender is used to construct different transport layer and application layer protocol request data messages to send to the target device, and the target device receives the request and returns the transport layer and application layer response messages, and this paper uses the traffic listener to capture these communication messages.
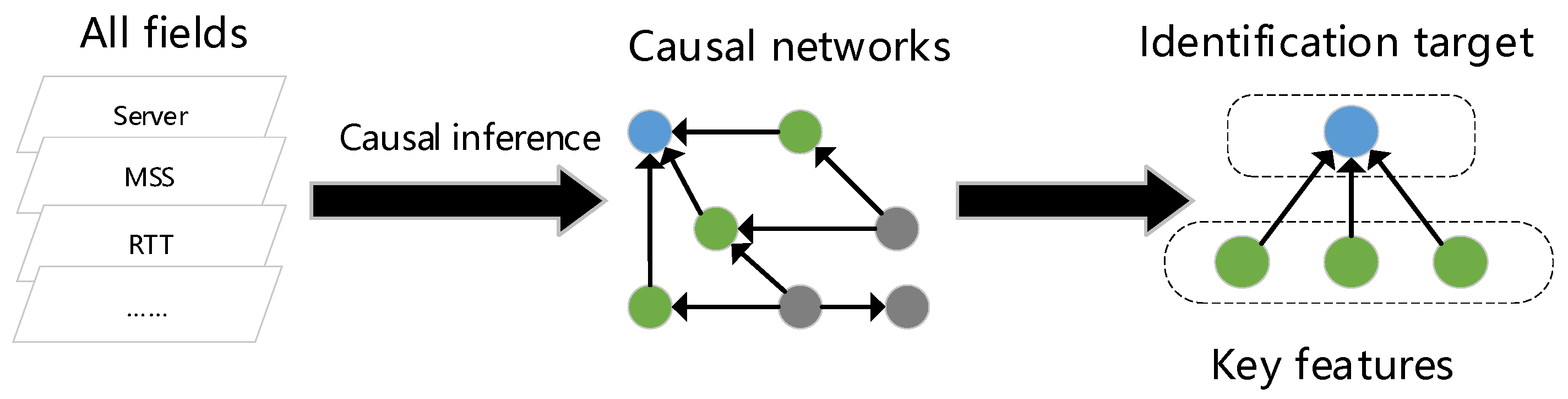
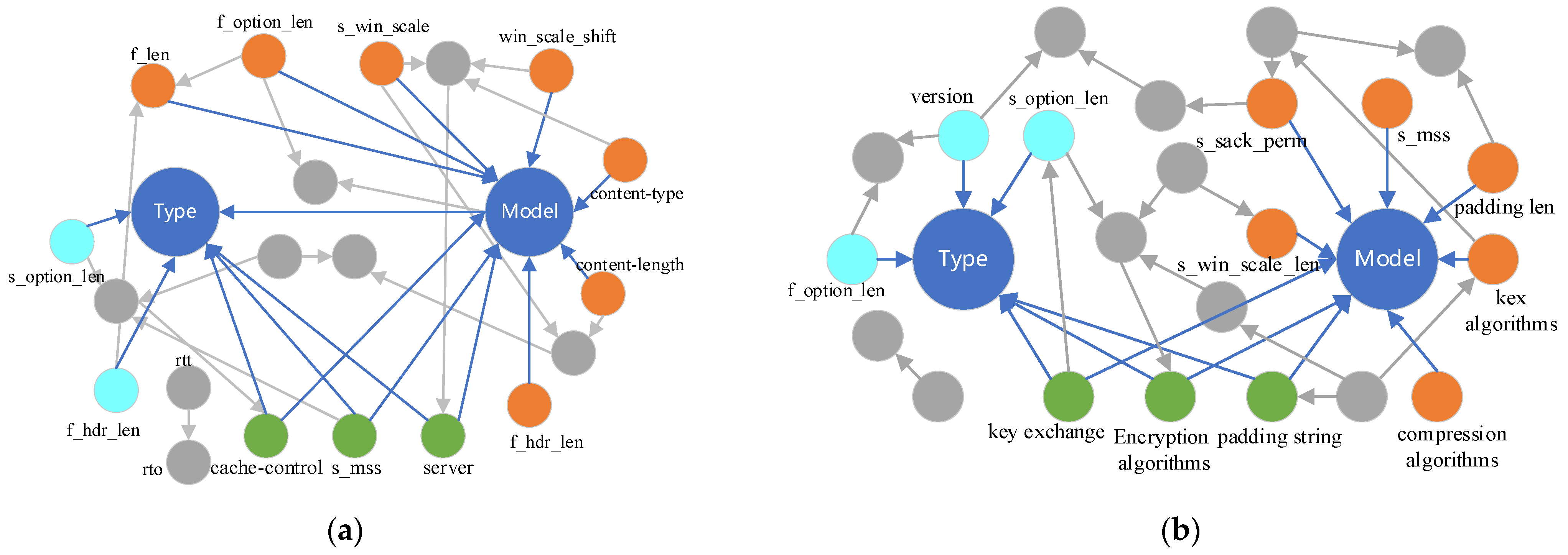
- Data preprocessing and feature selection. Data preprocessing is performed on the collected transport and application layer fields, and the normalization method is used to preprocess for numeric fields, and for text-based fields, the text features are first embedded into n-dimensional vectors using the Doc2Vec [20] method, followed by normalization. After obtaining the normalized data for the causal network between each field, the device identification target is obtained using the PC causal inference algorithm [5], and then, the key features that directly affect the device identification target (device type, device model) are obtained from the causal network.
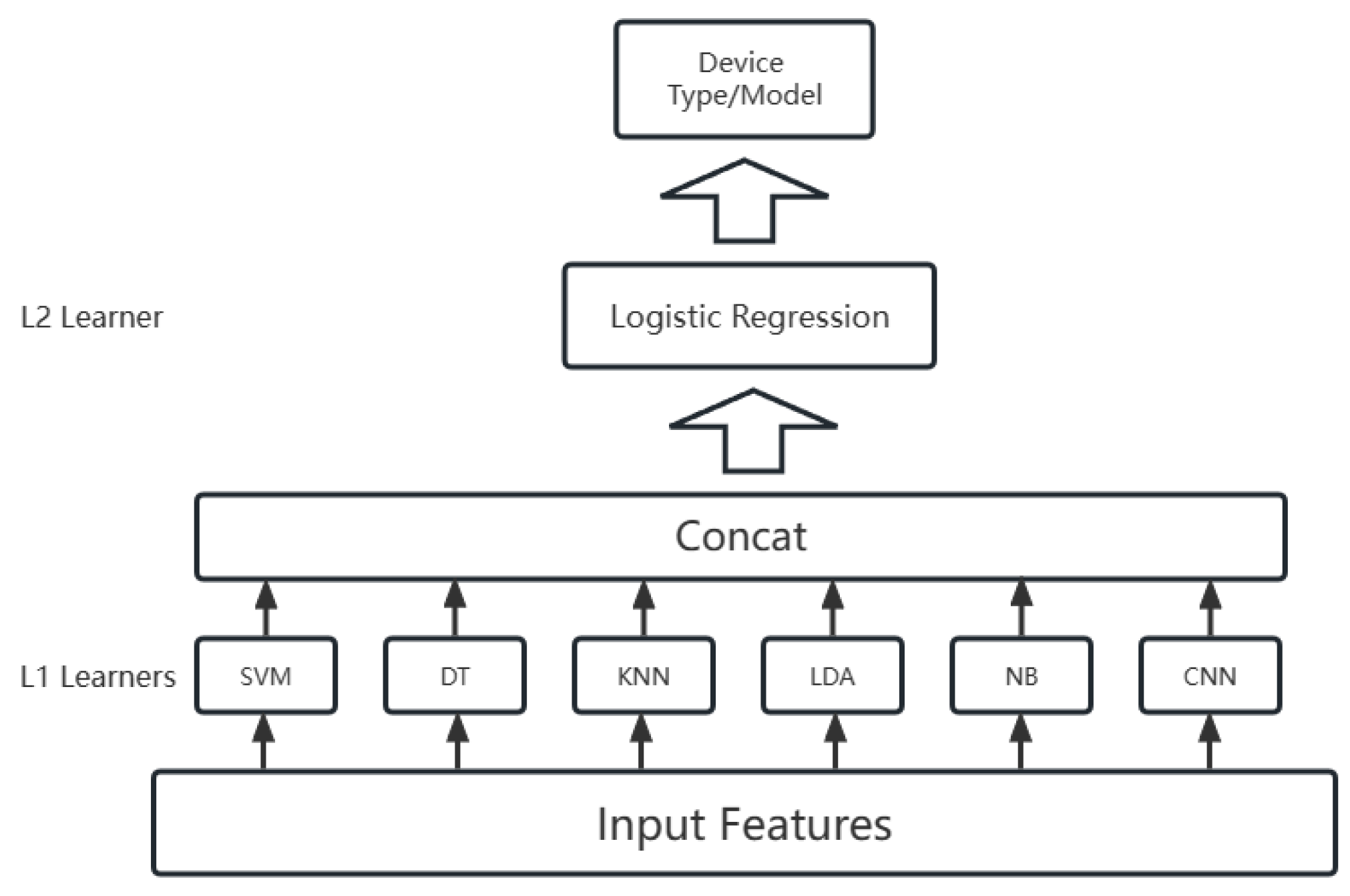
- Device identification. The key features of the devices are classified to achieve device identification. In this paper, a two-layer Stacking [21] approach is used to combine multiple classifiers in order to reduce the variance of the model and improve the overall identification performance.
4. Data Acquisition
4.1. Selection of Protocols
4.2. Rules for Data Acquisition
4.3. Data Preprocessing
5. Feature Extraction and Device Identification
5.1. Method for Feature Selection
5.2. Device Identification
6. Experiments and Evaluation
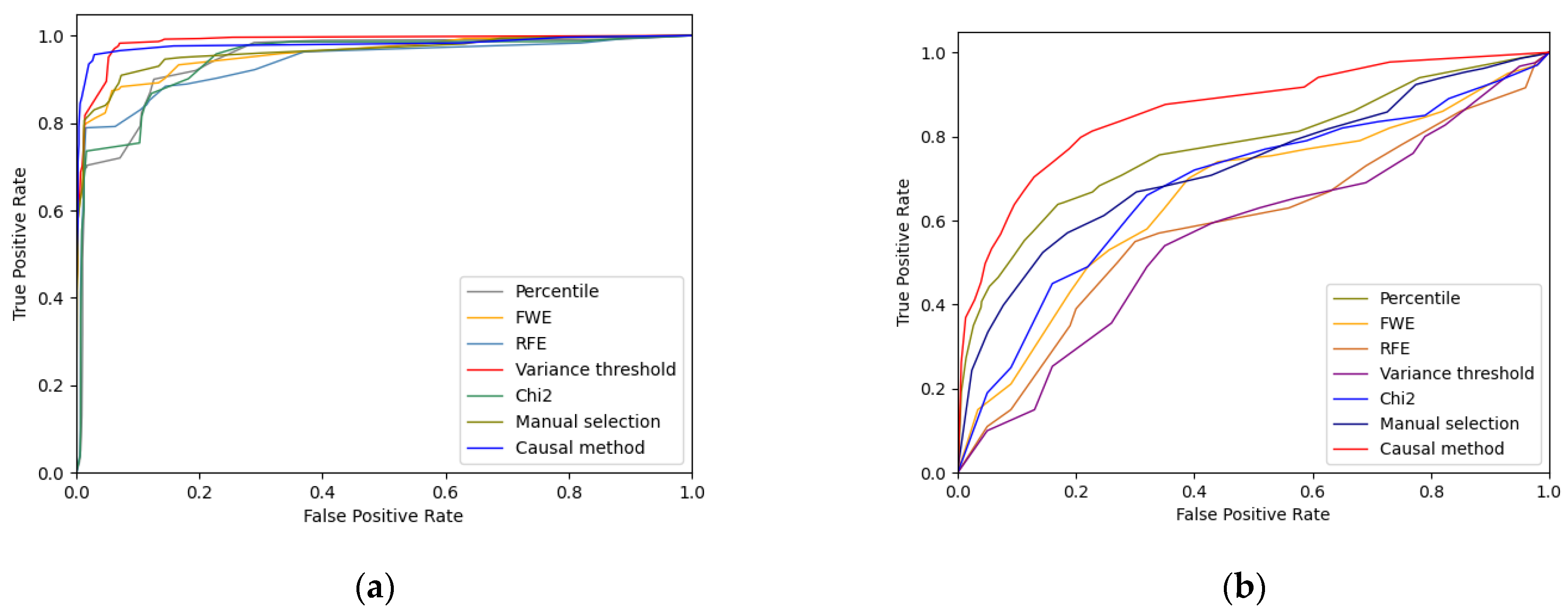
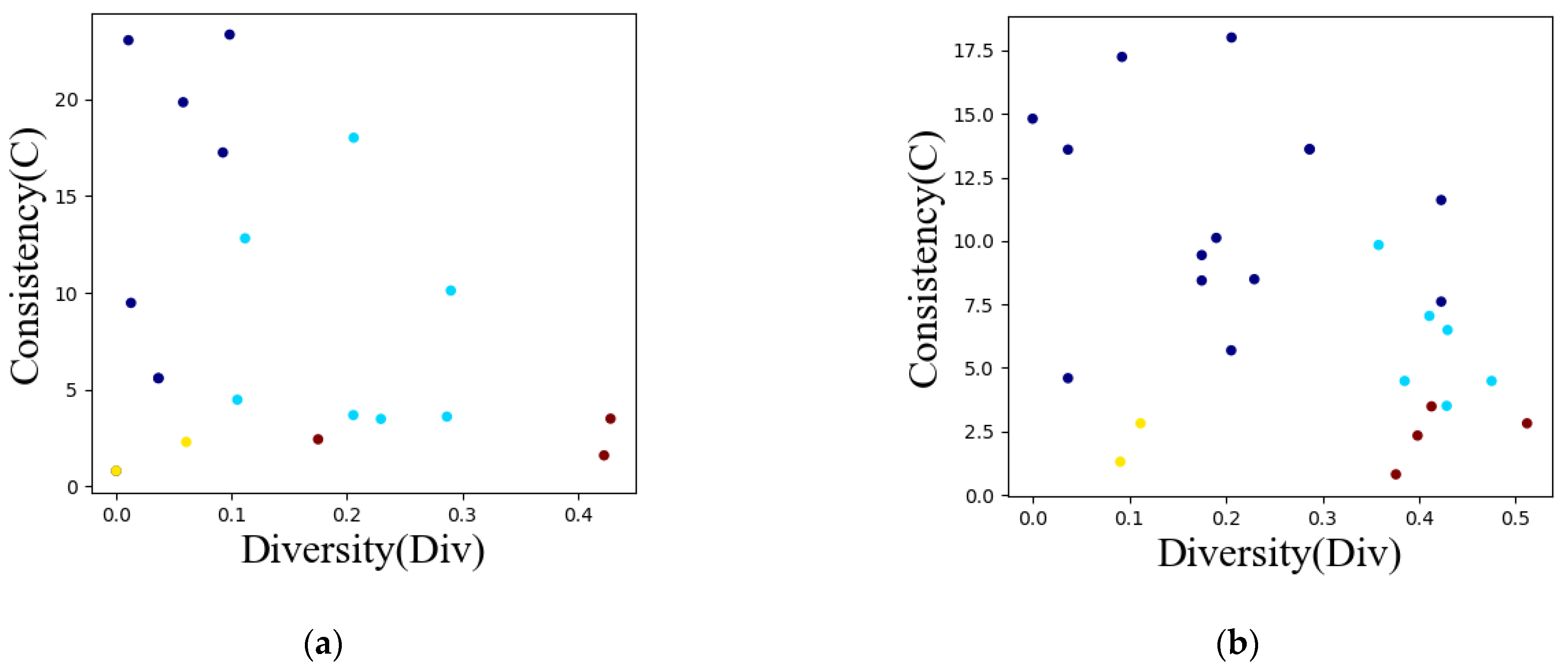
6.1. Evaluation of Feature Selection
6.2. Classification Performance Evaluation
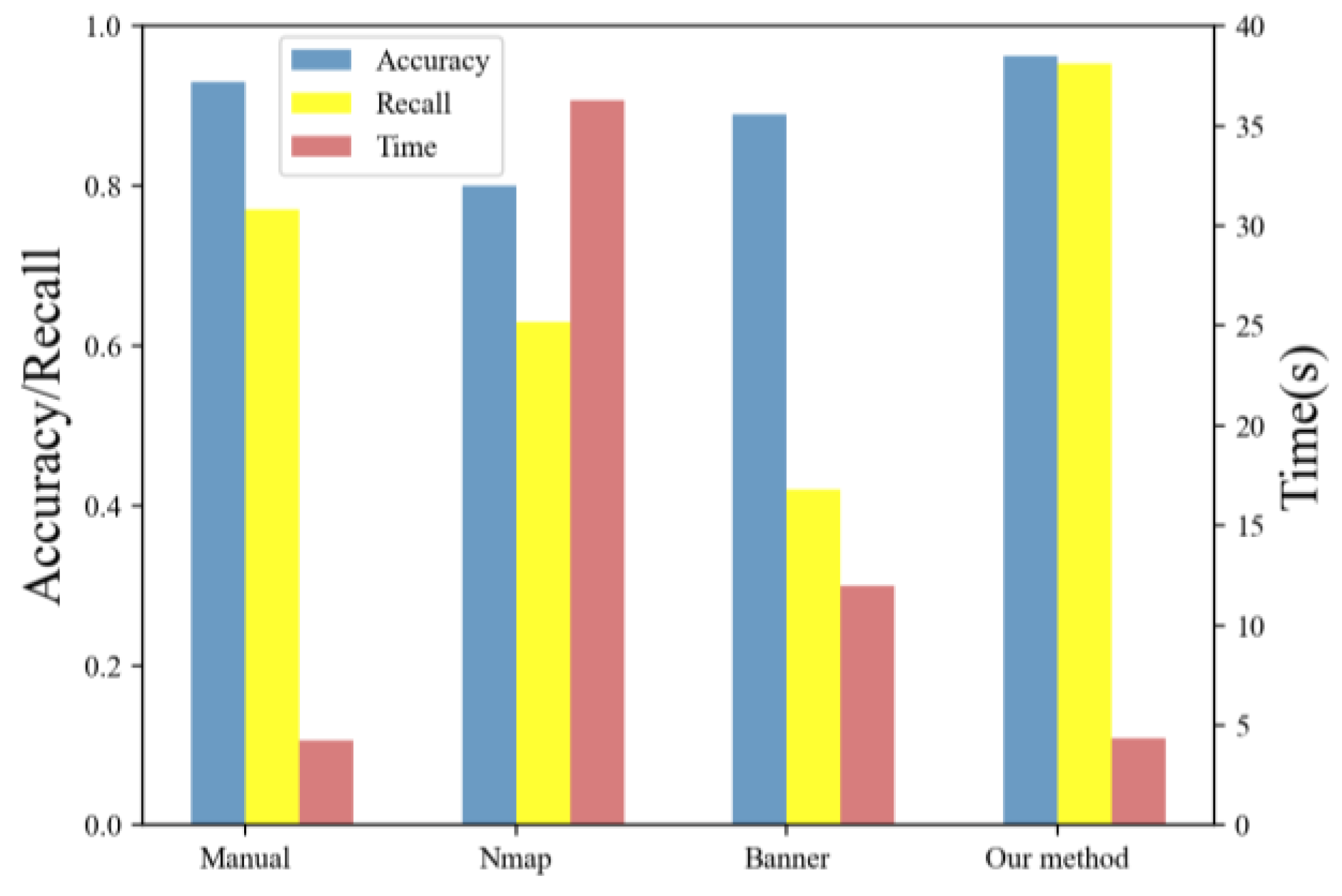
6.3. Comparison with Existing Methods
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pacheco, J.; Hariri, S. IoT security framework for smart cyber infrastructures. In Proceedings of the 2016 IEEE 1st International Workshops on Foundations and Applications of Self* Systems (FAS* W), Augsburg, Germany, 12–16 September 2016; IEEE: New York, NY, USA, 2016. [Google Scholar]
- Li, Q.; Feng, X.; Zhao, L.; Sun, L. A framework for searching Internet-wide devices. IEEE Netw. 2017, 31, 101–107. [Google Scholar] [CrossRef]
- Shodan Search Engine. Available online: https://shodan.io/ (accessed on 25 May 2023).
- Duarte, F.S.L.G.; Sikansi, F.; Fatore, F.M.; Fadel, S.G.; Paulovich, F.V. Nmap: A novel neighborhood preservation space-filling algorithm. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2063–2071. [Google Scholar] [CrossRef] [PubMed]
- Spirtes, P.; Glymour, C.N.; Scheines, R. Causation, Prediction and Search; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Zhang, K.; Peters, J.; Janzing, D.; Schölkopf, B. Kernel-based conditional independence test and application in causal discovery. arXiv 2012, arXiv:1202.3775. [Google Scholar]
- Chickering, D.M. Optimal structure identification with greedy search. J. Mach. Learn. Res. 2002, 3, 507–554. [Google Scholar]
- Tsamardinos, I.; Brown, L.E.; Aliferis, C.F. The max-min hill-climbing Bayesian network structure learning algorithm. Mach. Learn. 2006, 65, 31–78. [Google Scholar] [CrossRef] [Green Version]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Selected Papers of Hirotugu Akaike; Springer: New York, NY, USA, 1998; pp. 199–213. [Google Scholar]
- Lam, W.; Bacchus, F. Learning Bayesian belief networks: An approach based on the MDL principle. Comput. Intell. 1994, 10, 269–293. [Google Scholar] [CrossRef] [Green Version]
- Miettinen, M.; Marchal, S.; Hafeez, I.; Asokan, N.; Sadeghi, A.R.; Tarkoma, S. Iot sentinel: Automated device-type identification for security enforcement in iot. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Thangavelu, V.; Divakaran, D.M.; Sairam, R.; Bhunia, S.S.; Gurusamy, M. DEFT: A distributed IoT fingerprinting technique. IEEE Internet Things J. 2018, 6, 940–952. [Google Scholar] [CrossRef]
- Marchal, S.; Miettinen, M.; Nguyen, T.D.; Sadeghi, A.-R.; Asokan, N. Audi: Toward autonomous iot device-type identification using periodic communication. IEEE J. Sel. Areas Commun. 2019, 37, 1402–1412. [Google Scholar] [CrossRef] [Green Version]
- Aneja, S.; Aneja, N.; Islam, M.S. IoT device fingerprint using deep learning. In Proceedings of the 2018 IEEE International Conference on Internet of Things and Intelligence System (IOTAIS), Bali, Indonesia, 1–3 November 2018; IEEE: New York, NY, USA, 2018. [Google Scholar]
- Feng, X. Acquisitional rule-based engine for discovering internet-of-things devices. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018. [Google Scholar]
- Wang, X.; Wang, Y.; Feng, X.; Zhu, H.; Sun, L.; Zou, Y. Iottracker: An enhanced engine for discovering internet-of-thing devices. In Proceedings of the 2019 IEEE 20th International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM), Washington, DC, USA, 10–12 June 2019; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Censys. Available online: https://censys.io (accessed on 25 May 2023).
- Zoomeye. Available online: https://zoomeye.org (accessed on 25 May 2023).
- Yu, D.; Xin, H.; Chen, Y.; Ma, Y.; Chen, J. Cross-Layer Protocol Fingerprint for Large-Scale Fine-Grain Devices Identification. IEEE 2020, 8, 176294–176303. [Google Scholar] [CrossRef]
- Quoc, L.; Tomas Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; PMLR: Cambridge, MA, USA, 2014. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Barnard, G.A. The foundations of statistics 1964–1974. Bull. IMA 1974, 10, 344–347. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992. [Google Scholar]
- Loh, W.-Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 2007; Volume 1. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part I 13. Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Copas, J.B. Regression, prediction and shrinkage. J. R. Stat. Soc. Ser. B Methodol. 1983, 45, 311–335. [Google Scholar] [CrossRef]
- Percentile. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectPercentile.html (accessed on 25 May 2023).
- FWE. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectFwe.html (accessed on 25 May 2023).
- RFE. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFE.html (accessed on 25 May 2023).
- Variance Threshold. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.VarianceThreshold.html (accessed on 25 May 2023).
- Chi2. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.chi2.html (accessed on 25 May 2023).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Identification Target | HTTP/TCP Features | SSH/TCP Features |
|---|---|---|
| Device Type | server cache-control f_hdr_len s_mss s_option_len | version padding string key exchange code encryption algorithms f_option_len s_option_len |
| Device Model | F_len f_option_len s_mss s_sack_len s_win_scale s_win_scale_shift server cache-control content-type content-length www-authenticate | f_option_len s_mss s_sack_perm s_win_scale_len padding length padding string key exchange code kex algorithms encryption algorithms compression algorithms |
| Methods | Features |
|---|---|
| Percentile | server, www-authenticate, contenttype, s_mss, f_len, s_rtt, s_len, f_nop |
| FWE | server, www-authenticate, contentlength, cache-control, s_len, f_len, f_rtt, s_nop |
| RFE | www-authenticate, content-type, s_win_scale_len, s_rtt, s_len, f_nop, f_len, s_option_len |
| Variance threshold | www-authenticate, content-type, s_win_scale_len, s_rtt, s_len, f_nop, f_len, s_option_len |
| Chi2 | server, content-length, www-authenticate, cache-control, s_mss, s_len, f_hdr_len, f_nop |
| Manual selection | server, contenttype, contentlength, cache-control, ave-segment, ave-win |
| Methods | Accuracy | Recall | Time (s) |
|---|---|---|---|
| Manual | 93.1% | 77.2% | 4.24 |
| Nmap | 80.3% | 62.9% | 36.31 |
| Banner | 88.9% | 42.1% | 11.95 |
| Our method | 96.3% | 95.4% | 4.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wu, Y.; Yu, D.; Yang, Y.; Ma, Y.; Chen, Y. IoT Device Identification Method Based on Causal Inference. Electronics 2023, 12, 2727. https://doi.org/10.3390/electronics12122727
Wang X, Wu Y, Yu D, Yang Y, Ma Y, Chen Y. IoT Device Identification Method Based on Causal Inference. Electronics. 2023; 12(12):2727. https://doi.org/10.3390/electronics12122727
Chicago/Turabian StyleWang, Xingkui, Yunhao Wu, Dan Yu, Yuli Yang, Yao Ma, and Yongle Chen. 2023. "IoT Device Identification Method Based on Causal Inference" Electronics 12, no. 12: 2727. https://doi.org/10.3390/electronics12122727