
Eye-Blink Event Detection Using a Neural-Network-Trained Frame Segment for Woman Drivers in Saudi Arabia

Abstract
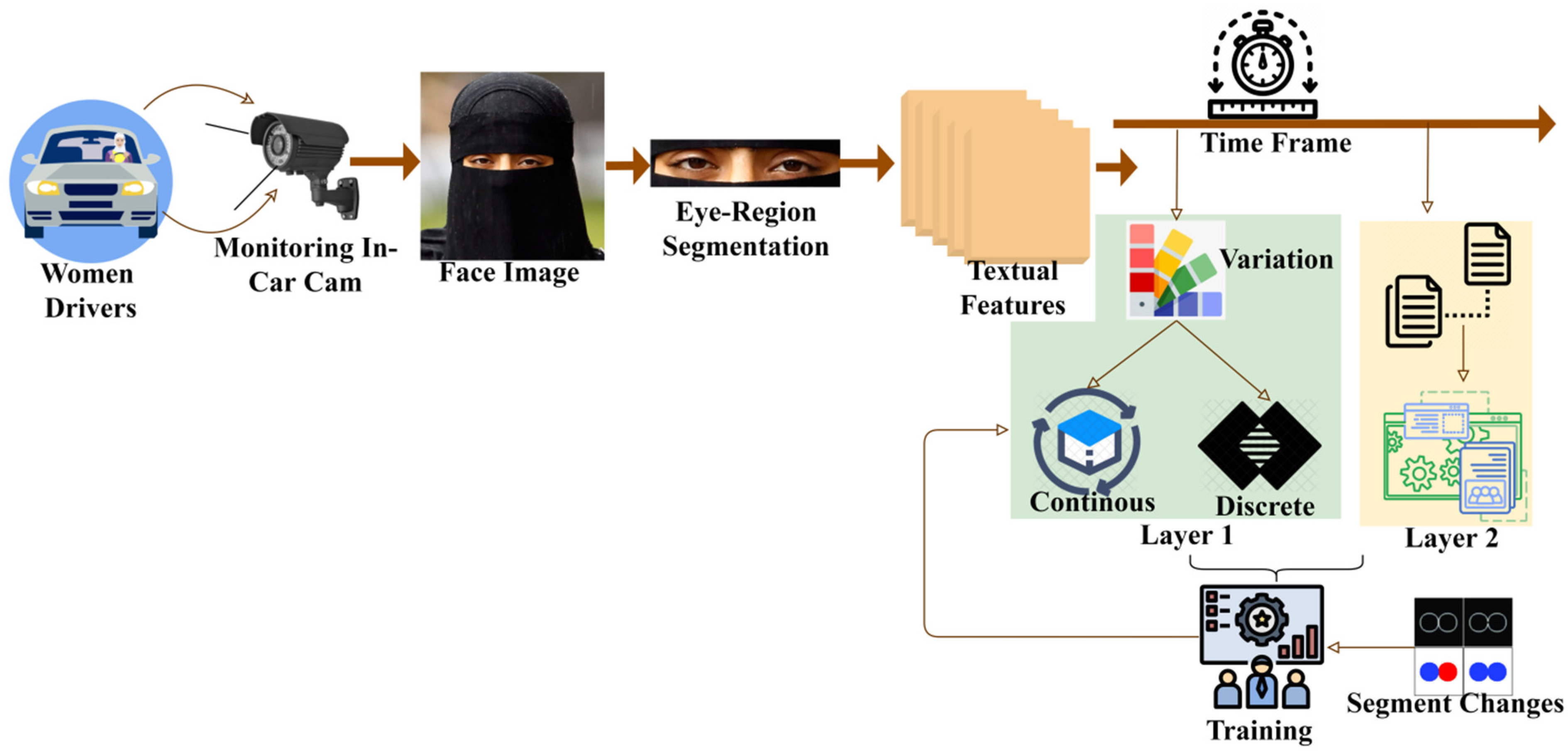
:1. Introduction
- Designing an event detection method for identifying the eye blinks of women drivers in Saudi Arabia to assist in safe driving
- Designing an Event Detection using the Segmented Frame (ED-SF) method, which uses a two-layer convolution neural network for frame differentiation and sequence detection in order to reduce the variation errors in the event detection
- Performing an experimental analysis using the Niqab dataset to prove the consistency of the proposed method
- Performing a comparative analysis using specific metrics and methods for external verification.
2. Related Works
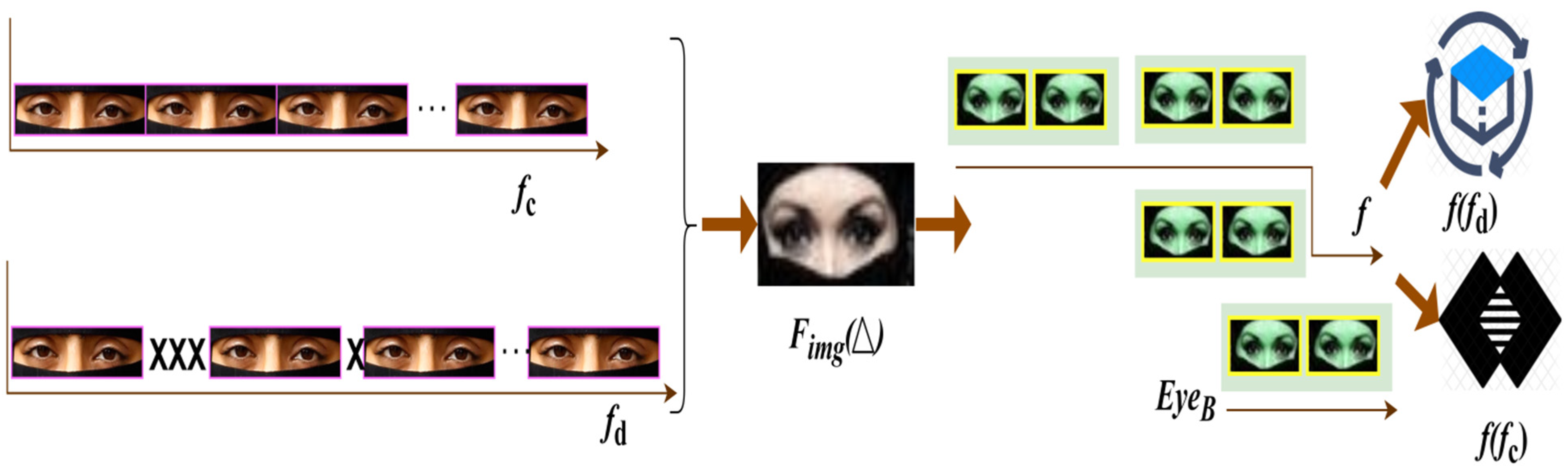
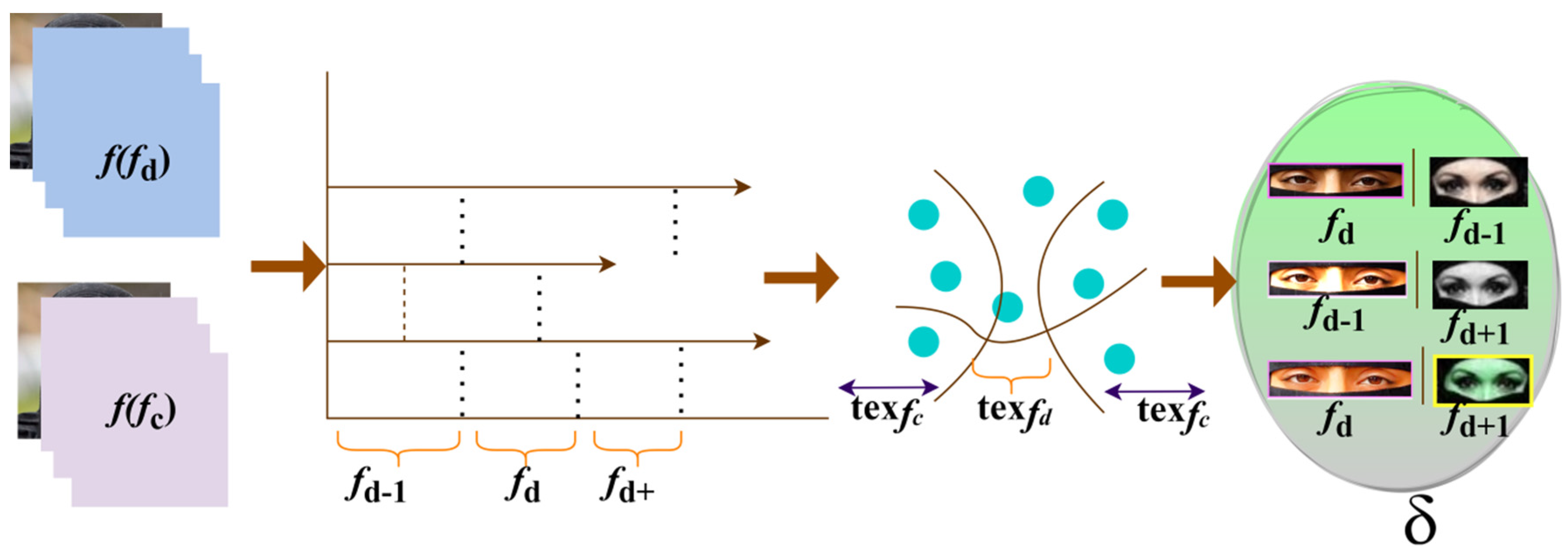
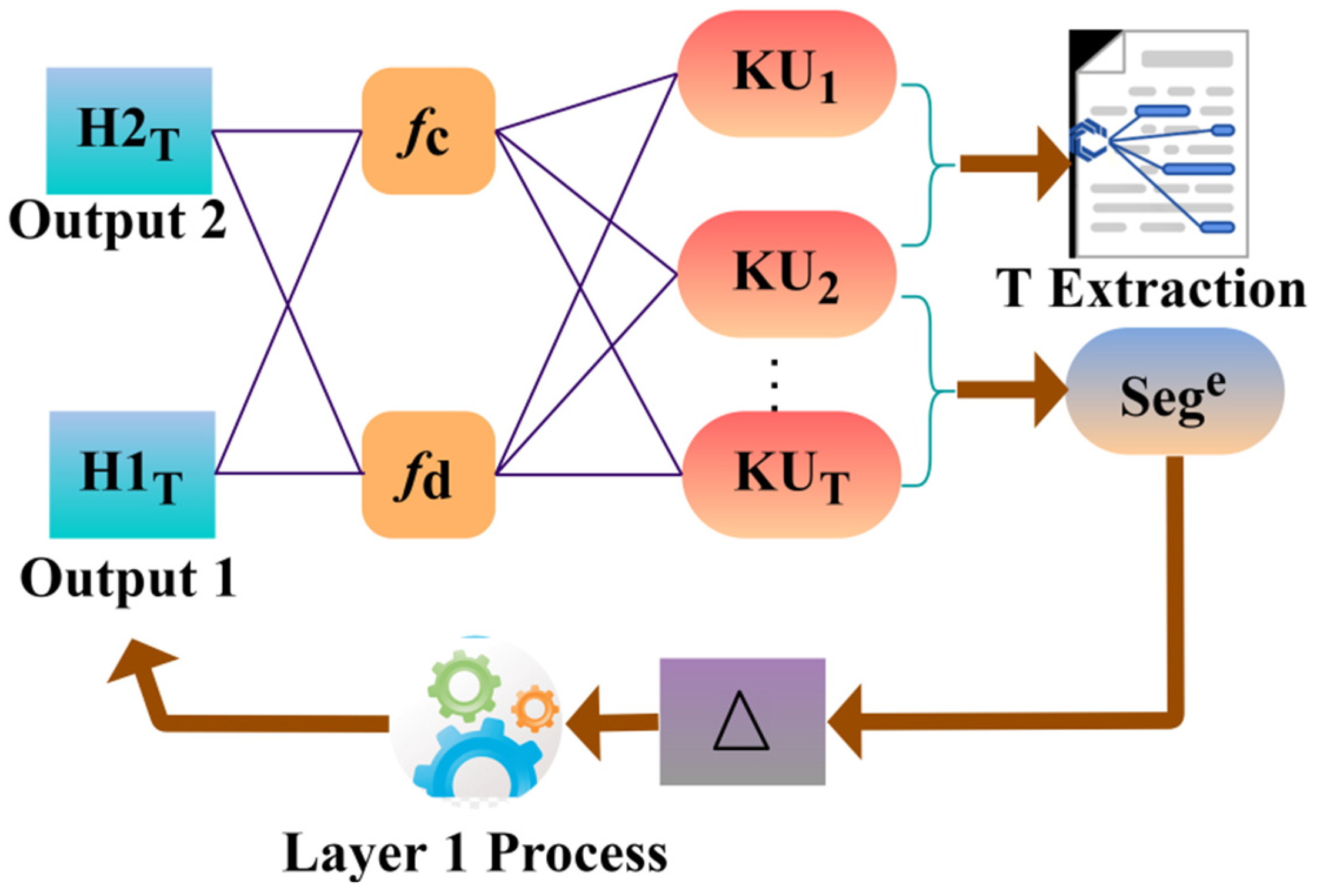
3. Event Detection Using Segmented Frame Method
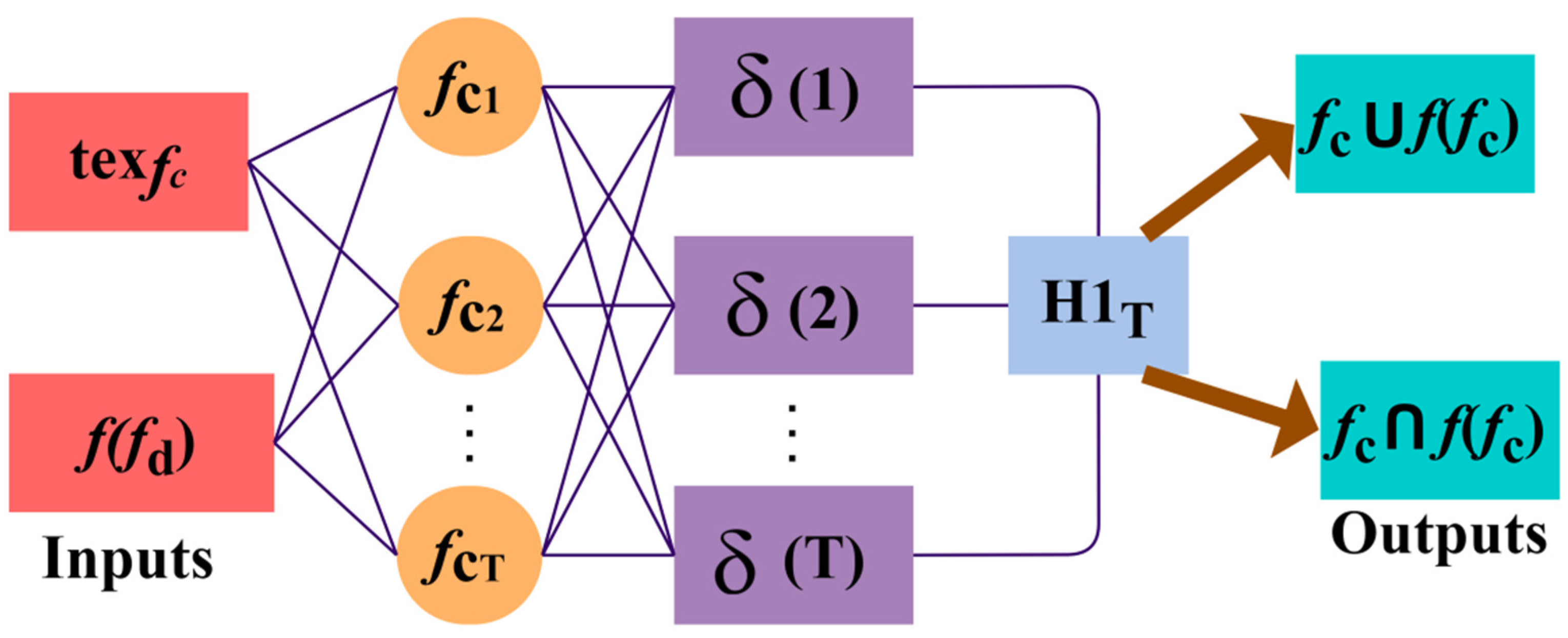
4. Neural Network Process for Event Detection
5. Experimental Analysis
6. Performance Assessment Using Comparative Analysis
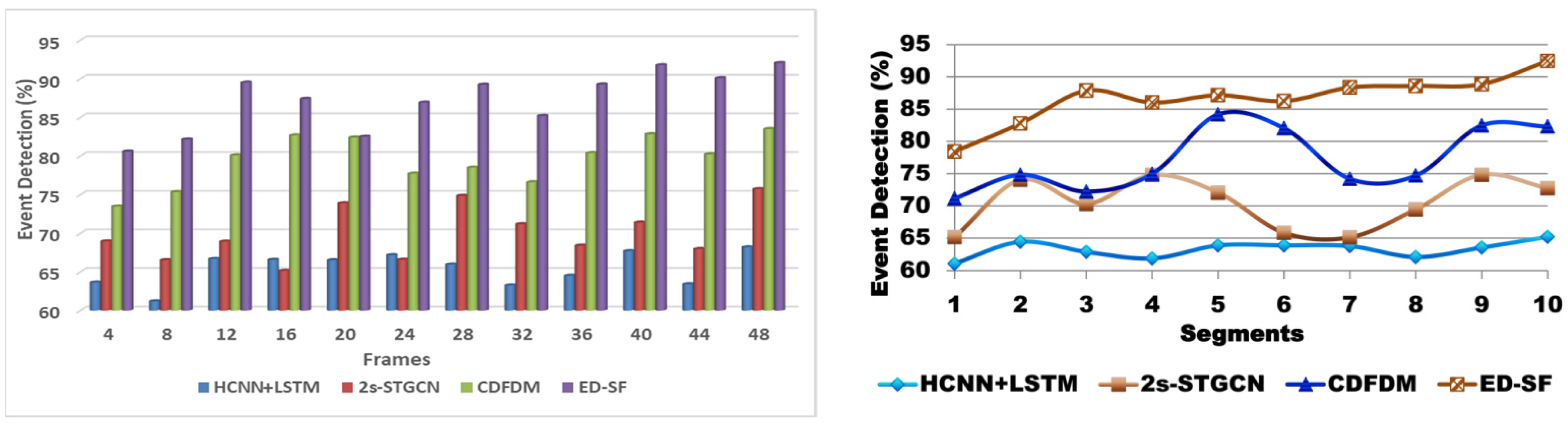
6.1. Event Detection
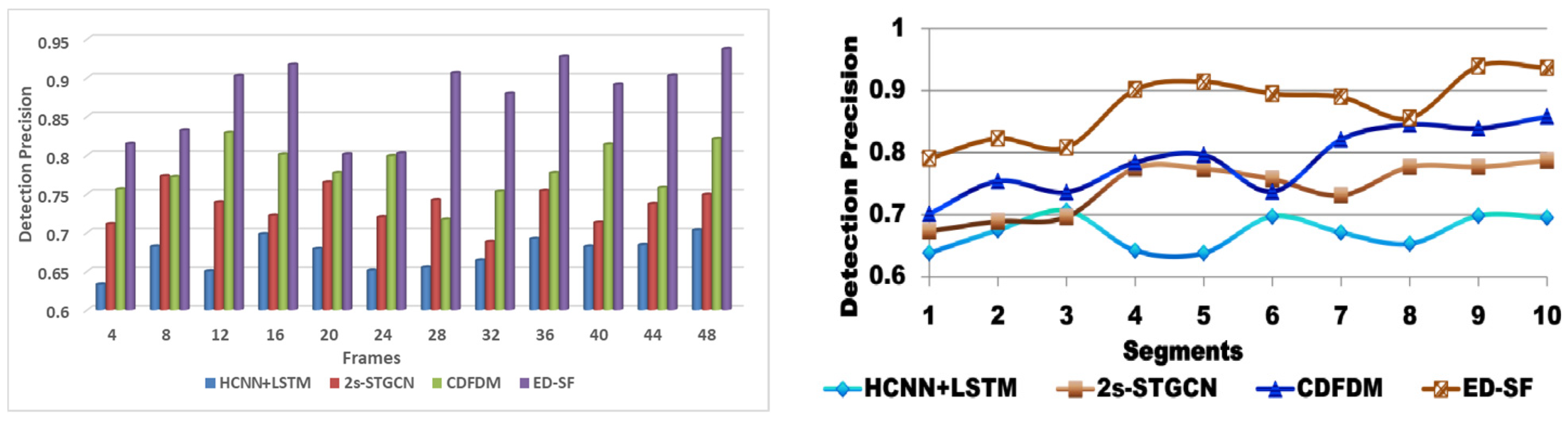
6.2. Detection Precision
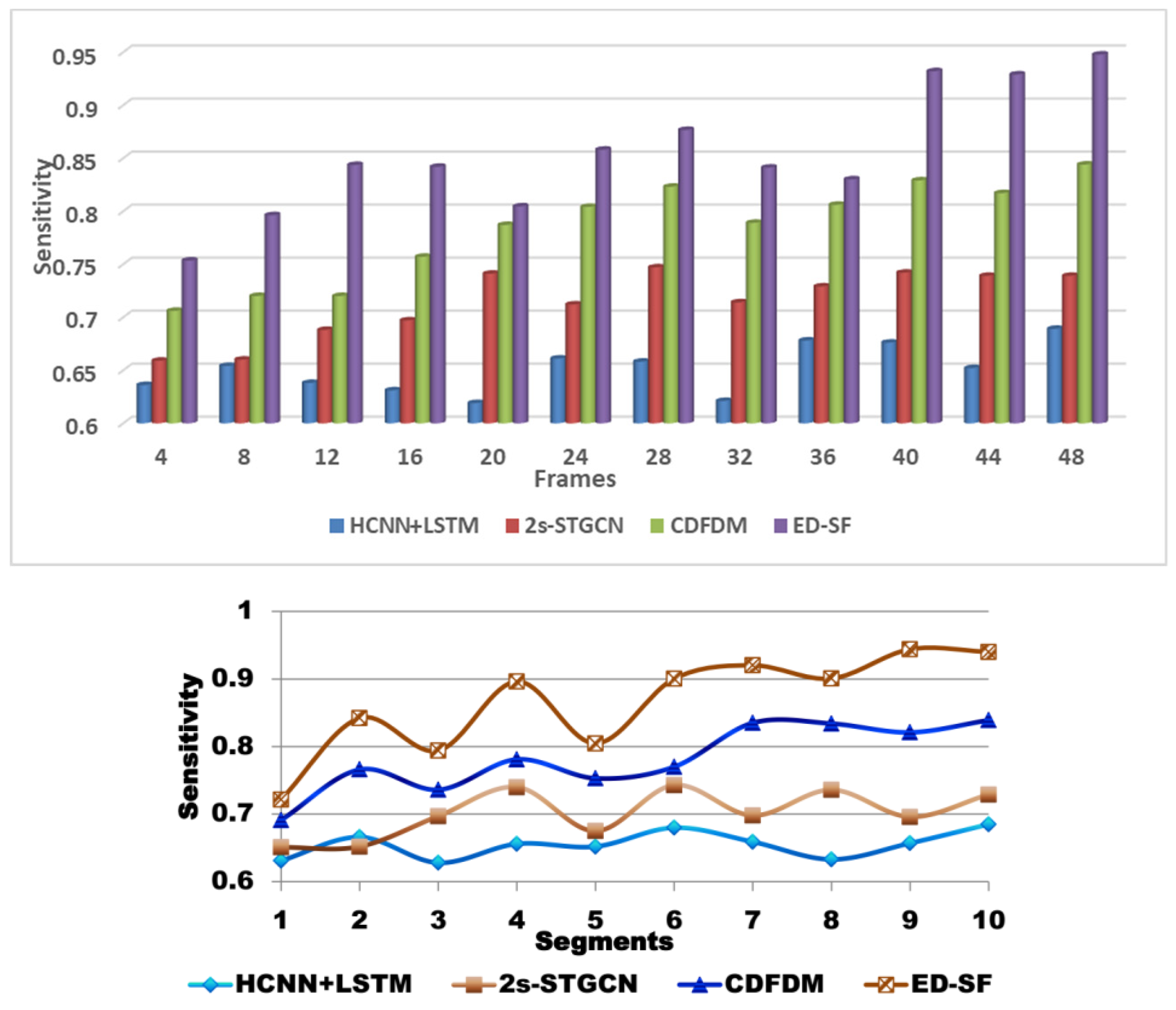
6.3. Sensitivity
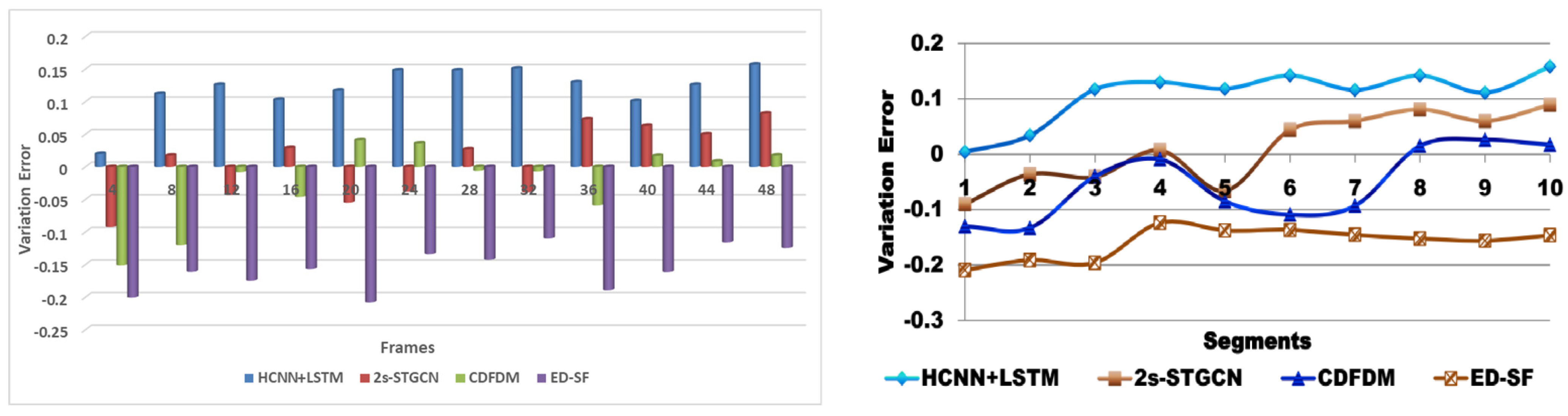
6.4. Variation Error
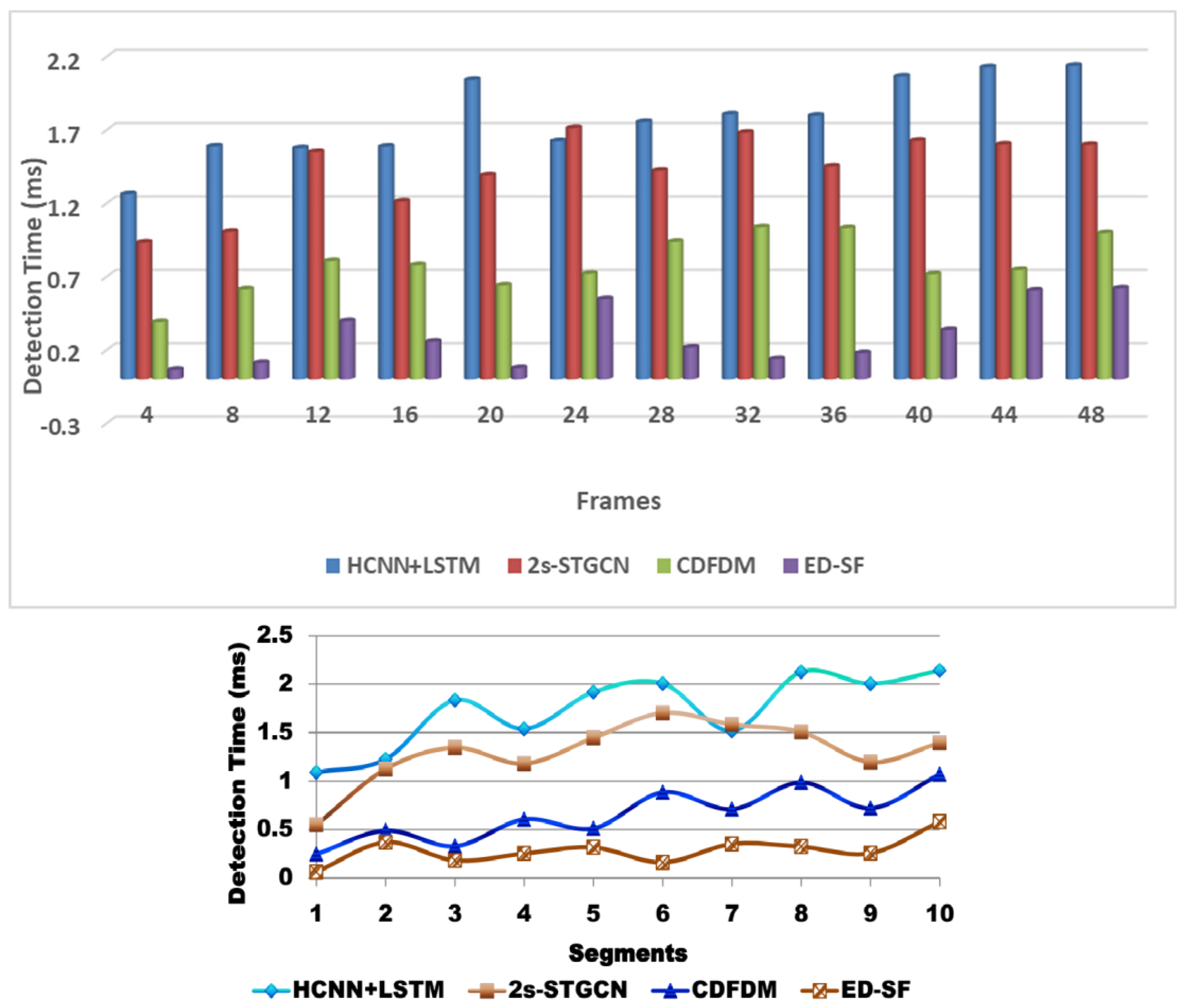
6.5. Detection Time
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jastania, Z.; Abbasi, R.A.; Aslam, M.A.; Khanzada, T.J.S.; Ghori, K.M. Analyzing Public Discussions about# SaudiWomenCanDrive Using Network Science. IEEE Access 2022, 10, 4739–4749. [Google Scholar]
- Al-Garawi, N.; Kamargianni, M. Exploring the factors affecting women’s intention to drive in Saudi Arabia. Travel Behav. Soc. 2022, 26, 121–133. [Google Scholar] [CrossRef]
- Al-Razgan, M.; Alrowily, A.; Al-Matham, R.N.; Alghamdi, K.M.; Shaabi, M.; Alssum, L. Using diffusion of innovation theory and sentiment analysis to analyze attitudes toward driving adoption by Saudi women. Technol. Soc. 2021, 65, 101558. [Google Scholar] [CrossRef]
- Sattari, N. Women driving women: Drivers of women-only taxis in the Islamic Republic of Iran. Women’s Stud. Int. Forum 2020, 78, 102324. [Google Scholar] [CrossRef]
- Al-Garawi, N.; Kamargianni, M. Women’s modal switching behavior since driving is allowed in Saudi Arabia. J. Transp. Geogr. 2021, 96, 103192. [Google Scholar] [CrossRef]
- Jannusch, T.; Shannon, D.; Völler, M.; Murphy, F.; Mullins, M. Cars and distraction: How to address the limits of Driver Monitoring Systems and improve safety benefits using evidence from German young drivers. Technol. Soc. 2021, 66, 101628. [Google Scholar] [CrossRef]
- Corcoba, V.; Paneda, X.G.; Melendi, D.; García, R.; Pozueco, L.; Paiva, S. COVID-19 and its effects on the driving style of spanish drivers. IEEE Access 2021, 9, 146680–146690. [Google Scholar] [CrossRef]
- Vasconez, J.P.; Viscaino, M.; Guevara, L.; Cheein, F.A. A fuzzy-based driver assistance system using human cognitive parameters and driving style information. Cogn. Syst. Res. 2020, 64, 174–190. [Google Scholar] [CrossRef]
- Shi, G.; Gao, C.; Wang, D.; Su, Z. Automatic 3D virtual fitting system based on skeleton driving. Vis. Comput. 2021, 37, 1075–1088. [Google Scholar] [CrossRef]
- Buzon, L.G.; Figueira, A.C.; Larocca, A.P.C.; Oliveira, P.T.M. Effect of speed ondriver’s visual attention: A study using a driving simulator. Transp. Dev. Econ. 2021, 8, 1. [Google Scholar] [CrossRef]
- Sohn, K.; Jang, G. Ground Vehicle Driving by Full Sized Humanoid. J. Intell. Robot. Syst. 2020, 99, 407–425. [Google Scholar] [CrossRef]
- Giot, C.; Hay, M.; Chesneau, C.; Pigeon, E.; Bonargent, T.; Beaufils, M.; Chastan, N.; Perrier, J.; Pasquier, F.; Polvent, S.; et al. Towards a new approach to detect sleepiness: Validation of the objective sleepiness scale under simulated driving conditions. Transp. Res. Part F Traffic Psychol. Behav. 2022, 90, 109–119. [Google Scholar] [CrossRef]
- Bitkina, O.V.; Park, J.; Kim, H.K. The ability of eye-tracking metrics to classify and predict the perceived driving workload. Int. J. Ind. Ergon. 2021, 86, 103193. [Google Scholar] [CrossRef]
- Li, K.; Gong, Y.; Ren, Z. A fatigue driving detection algorithm based on facial multi-feature fusion. IEEE Access 2020, 8, 101244–101259. [Google Scholar] [CrossRef]
- Chen, W.; Sawaragi, T.; Hiraoka, T. Comparing eye-tracking metrics of mental workload caused by NDRTs in semi-autonomous driving. Transp. Res. Part F Traffic Psychol. Behav. 2022, 89, 109–128. [Google Scholar] [CrossRef]
- Xue, Z.; Chen, L.; Liu, Z.; Lin, F.; Mao, W. Rock segmentation visual system for assisting driving in TBM construction. Mach. Vis. Appl. 2021, 32, 77. [Google Scholar] [CrossRef]
- Cori, J.M.; Turner, S.; Westlake, J.; Naqvi, A.; Ftouni, S.; Wilkinson, V.; Vakulin, A.; O’Donoghue, F.J.; Howard, M.E. Eye blink parameters to indicate drowsiness during naturalistic driving in participants with obstructive sleep apnea: A pilot study. Sleep Health 2021, 7, 644–651. [Google Scholar] [CrossRef]
- Kır Savaş, B.; Becerikli, Y. Behavior-based driver fatigue detection system with deep belief network. Neural Comput. Appl. 2022, 34, 14053–14065. [Google Scholar] [CrossRef]
- Jordan, A.A.; Pegatoquet, A.; Castagnetti, A.; Raybaut, J.; Le Coz, P. Deep learning for eye blink detection implemented at the edge. IEEE Embed. Syst. Lett. 2020, 13, 130–133. [Google Scholar] [CrossRef]
- Mou, L.; Zhou, C.; Xie, P.; Zhao, P.; Jain, R.C.; Gao, W.; Yin, B. Isotropic Self-supervised Learning for Driver Drowsiness Detection With Attention-based Multi-modal Fusion. IEEE Trans. Multimed. 2021, 25, 529–542. [Google Scholar] [CrossRef]
- Bai, J.; Yu, W.; Xiao, Z.; Havyarimana, V.; Regan, A.C.; Jiang, H.; Jiao, L. Two-stream spatial–temporal graph convolutional networks for driver drowsiness detection. IEEE Trans. Cybern. 2021, 52, 13821–13833. [Google Scholar] [CrossRef]
- Li, X.; Schroeter, R.; Rakotonirainy, A.; Kuo, J.; Lenné, M.G. Effects of different non-driving-related-task display modes ondrivers’ eye-movement patterns during take-over in an automated vehicle. Transp. Res. Part F Traffic Psychol. Behav. 2020, 70, 135–148. [Google Scholar] [CrossRef]
- Liang, N.; Yang, J.; Yu, D.; Prakah-Asante, K.O.; Curry, R.; Blommer, M.; Swaminathan, R.; Pitts, B.J. Using eye-tracking to investigate the effects of pre-takeover visual engagement on situation awareness during automated driving. Accid. Anal. Prev. 2021, 157, 106143. [Google Scholar] [CrossRef]
- Akrout, B.; Mahdi, W. A novel approach for driver fatigue detection based on visual characteristics analysis. J. Ambient Intell. Humaniz. Comput. 2023, 14, 527–552. [Google Scholar] [CrossRef]
- Zeng, L.; Zhou, K.; Han, Q.; Wang, Y.; Guo, G.; Ye, L. An fNIRS labeling image feature-based customized driving fatigue detection method. J. Ambient. Intell. Humaniz. Comput. 2022, 1–17. [Google Scholar] [CrossRef]
- Yamabe, S.; Kawaguchi, S.; Anakubo, M. Comfortable awakening method for sleeping driver during autonomous driving. Int. J. Intell. Transp. Syst. Res. 2022, 20, 266–278. [Google Scholar] [CrossRef]
- Guo, J.M.; Markoni, H. Driver drowsiness detection using hybrid convolutional neural network and long short-term memory. Multimed. Tools Appl. 2019, 78, 29059–29087. [Google Scholar] [CrossRef]
- Li, D.; Zhang, X.; Liu, X.; Ma, Z.; Zhang, B. Driver fatigue detection based on comprehensive facial features and gated recurrent unit. J. Real-Time Image Process. 2023, 20, 19. [Google Scholar] [CrossRef]
- Wijnands, J.S.; Thompson, J.; Nice, K.A.; Aschwanden, G.D.; Stevenson, M. Real-time monitoring of driver drowsiness on mobile platforms using 3D neural networks. Neural Comput. Appl. 2020, 32, 9731–9743. [Google Scholar] [CrossRef] [Green Version]
- Cui, Z.; Sun, H.M.; Yin, R.N.; Gao, L.; Sun, H.B.; Jia, R.S. Real-time detection method of driver fatigue state based on deep learning of face video. Multimed. Tools Appl. 2021, 80, 25495–25515. [Google Scholar] [CrossRef]
- Ghosh, R.; Phadikar, S.; Deb, N.; Sinha, N.; Das, P.; Ghaderpour, E. Automatic Eye-blink and Muscular Artifact Detection and Removal from EEG Signals Using k-Nearest Neighbor Classifier and Long Short-Term Memory Networks. IEEE Sens. J. 2023, 23, 5422–5436. [Google Scholar] [CrossRef]
- Egambaram, A.; Badruddin, N. An Investigation to Detect Driver Drowsiness from Eye blink Artifacts Using Deep Learning Models. In Proceedings of the 2022 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES), Kuala Lumpur, Malaysia, 7–9 December 2022; pp. 23–29. [Google Scholar] [CrossRef]
- A Alashbi, A.; Sunar, M.S.; Alqahtani, Z. Deep-Learning-CNN for Detecting Covered Faces with Niqab. J. Inf. Technol. Manag. 2022, 14, 114–123. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Title | Key Areas | Methods Used | Findings |
|---|---|---|---|---|
| Jordan et al. [19] | Deep learning (DL)-based EBD method for edge computing systems. | The main aim of the method is to identify the driver’s drowsiness ratio during driving. | The convolutional neural network (CNN) model is used here to detect the eye blinking range of the person. | Increases the accuracy of the EBD process. |
| Mou et al. [20] | An isotropic self-supervised learning (IsoSSL) model for driver drowsiness detection process. | IsoSSL detects the exact drowsiness range of drivers via videos and images. | An attention-based multi-modal fusion method is implemented to identify the facial features of the drivers. | The IsoSSL model reduces the accident range on roadsides. |
| Bai et al. [21] | A Two-Stream Spatial-Temporal Graph Convolutional Network (2S-STGCN) for drowsiness detection. | The STGCN identifies the facial expression ratio of the drivers. | A feature extraction method is used to extract the important data for detection. | Minimizes the error ratio in drowsiness detection. |
| Li et al. [22] | A new EBD method for non-driving-related tasks (NDRT) in automated vehicles. | The goal is to reduce accidents and ensure the users’ safety. | Head-up-display (HUD) technique is used to predict the eye-blinking range of the drivers. | Increases the accuracy of the EBD process. |
| Liang et al. [23] | A new technique for the eye-tracking investigation process. | The proposed technique investigates the effects of pre-takeover request (TOR) for the tracking process. | Situation awareness global assessment technique (SAGAT) is used here to analyze the actual behavioral patterns of the drivers. | Enhances the accuracy and efficiency range of the eye-tracking system. |
| Akrout et al. [24] | A novel approach for driver fatigue detection process. | The proposed approach identifies drivers’ drowsiness, fatigue, and yawning levels during driving. | Visual characteristics analysis is used to produce optimal data for the detection process. | Maximizes the accuracy of fatigue detection. |
| Zeng et al. [25] | A Customized Driving Fatigue Detection Method (CDFDM). | The developed method identifies the fatigue level of drivers from the given images. | A long short-term memory (LSTM) algorithm is used here to detect the important datasets from the database. | Increases the overall accuracy in the fatigue recognition process. |
| Input Image | Segmented Image | Variation Plot |
|---|---|---|
 |  |  |
| Input Image | Segmented Image | Variation Plot |
|---|---|---|
 |  |  |
| Sequence | Segmented Input | ||
|---|---|---|---|
 |  |  | |
 |  |  |
| Sequence | Output | Error |
|---|---|---|
 |  | |
 |  |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Razgan, M.S.; Alruwaly, I.; Ali, Y.A. Eye-Blink Event Detection Using a Neural-Network-Trained Frame Segment for Woman Drivers in Saudi Arabia. Electronics 2023, 12, 2699. https://doi.org/10.3390/electronics12122699
Al-Razgan MS, Alruwaly I, Ali YA. Eye-Blink Event Detection Using a Neural-Network-Trained Frame Segment for Woman Drivers in Saudi Arabia. Electronics. 2023; 12(12):2699. https://doi.org/10.3390/electronics12122699
Chicago/Turabian StyleAl-Razgan, Muna S., Issema Alruwaly, and Yasser A. Ali. 2023. "Eye-Blink Event Detection Using a Neural-Network-Trained Frame Segment for Woman Drivers in Saudi Arabia" Electronics 12, no. 12: 2699. https://doi.org/10.3390/electronics12122699