1. Introduction
Due to the demand for diverse realistic video content on online video services, the data traffic for video streaming over wireless or wired networks has been substantially increasing in the field of various video-on-demand (VoD) or live services. Video compression is required to reduce the amount of original data within a specified network bandwidth for transmission while maintaining the visual quality of the original video as much as possible. In 2020, Versatile Video Coding (VVC) [
1] was developed by the Joint Video Experts Team (JVET) of the ISO/IEC Moving Picture Experts Group (MPEG) and the ITU-T Video Coding Experts Group (VCEG) as the latest international standard of video compression. The VVC test model (VTM) [
2] can achieve a coding performance of up to 41% when compared with the high-efficiency video coding (HEVC) [
3] test model (HM) under the random-access (RA) configuration of the JVET common test conditions (CTC) [
4]. To improve the coding performance, VVC adopted new coding tools, such as quaternary tree plus multitype tree (QTMTT), affine inter prediction, bi-prediction with CU-level weight (BCW) [
5], adaptive motion vector resolution (AMVR) [
6], symmetric motion vector difference (SMVD) [
7], geometric partitioning mode (GPM) [
8], merge with motion vector difference (MMVD) [
9], decoder-side motion vector refinement (DMVR) [
10], and various intra-prediction tools. Although it can significantly enhance the coding performance, the complexity of the VVC encoder increases by up to eight times [
11] compared with HEVC. Therefore, it is essential to reduce the encoding complexity of VVC for high-quality video services on hand-held devices with limited hardware capacity.
As one of the essential methods in the conventional inter prediction of video coding, bi-prediction can improve the coding efficiency compared with uni-prediction. In general, it generates a better predicted block from both forward and backward prediction blocks than a uni-prediction block, except for scene change or illumination change. VVC adopted the BCW method to enhance the conventional bi-prediction by assigning different weights between the two uni-prediction blocks to adaptively highlight either the forward or backward predicted block. As shown in
Table 1, it allows BCW to utilize the five different weights according to the BCW index (BCW-Idx). While BCW can provide better coding efficiency than the conventional bi-prediction, it causes the encoding complexity of the bi-prediction to increase by up to five times due to the rate-distortion optimization (RDO) computations for five weights. According to the tool-off test of BCW [
12], the coding loss and time savings were 0.40% and 9%, respectively.
In addition, there are several limitations when applying the BCW mode. Firstly, when combined with AMVR, it is only applied to 1-pel and 4-pel motion vector precision for the current low-delay frame. Secondly, when combined with affine, it is performed only when the affine mode is currently the best mode. Thirdly, in the case of paired prediction using the same reference frame, the BCW mode is conditionally checked. Finally, the BCW mode is not applied if specific conditions are met based on the POC distance, quantization parameter (QP), and temporal level between the current frame and reference frame.
The formula for applying the weight of BCW is as follows:
where
w,
, and
denote the BCW weight and the forward and backward prediction block, respectively.
Table 2 shows that the ratio of the chosen BCW to the average weight (BCW-Idx 2) has a higher proportion of 60.41% than other BCW modes. BCW requires an approximately 60% rate of unnecessary encoding complexity. Based on the biased ratio of the BCW modes, we propose a fast BCW mode decision method using a lightweight multilayer perceptron (MLP) in this paper. To reduce the RDO computation number of the BCW, the proposed method determines whether to perform the BCW mode—except for the average-weight BCW mode.
In order to develop the fast BCW mode decision method, we investigated six input features to use as an input vector in the proposed MLP model, the so-called BCW-MLP. Its design should consider the trade-off between the high accuracy and the low complexity to be implemented on top of the VVC encoder (VTM-11.0). Therefore, the proposed method was evaluated in terms of the complexity reduction as well as the coding loss on the JVET test sequences in the middle of the development of BCW-MLP.
The remainder of this paper is organized as follows: In
Section 2, we review the related fast encoding schemes to reduce the computational complexity of the video encoder. Subsequently, the proposed method is described in
Section 3. Finally, the experimental results and conclusions are presented in
Section 4 and
Section 5, respectively.
2. Related Works
In terms of block structure, the VVC integrated coding unit (CU), prediction unit (PU), and transform unit (TU) are provided by HEVC. In other words, CU is simultaneously defined as PU and TU. In addition, the shape of the coding block is either a square or rectangular shape. Therefore, VVC with a more flexible block structure can deal with numerous complex textures through the adaptive block partitioning scheme. This implies that the flexible block structure of VVC can provide better coding performance than that of HEVC.
While HEVC allows only a quad-tree (QT) structure split with a square shape, VVC can support multi-type tree (MTT) structures to include binary tree (BT) and ternary tree (TT) splits with a rectangular shape. The CU split structure of the VVC can be independently encoded and decoded according to the quad-tree split (SPLIT_QT), binary vertical split (SPLIT_BT_VER), binary horizontal split (SPLIT_BT_HOR), ternary vertical split (SPLIT_TT_VER), and ternary horizontal split (SPLIT_TT_HOR) structures defined in the VVC standard. For example, a QT node with a square shape can be further partitioned into sub-QT or MTT nodes with a rectangular shape, whereas an MTT should be further split into sub-MTT nodes. Here, the QT or MTT leaf nodes are considered as CU and are encoded as PU and TU.
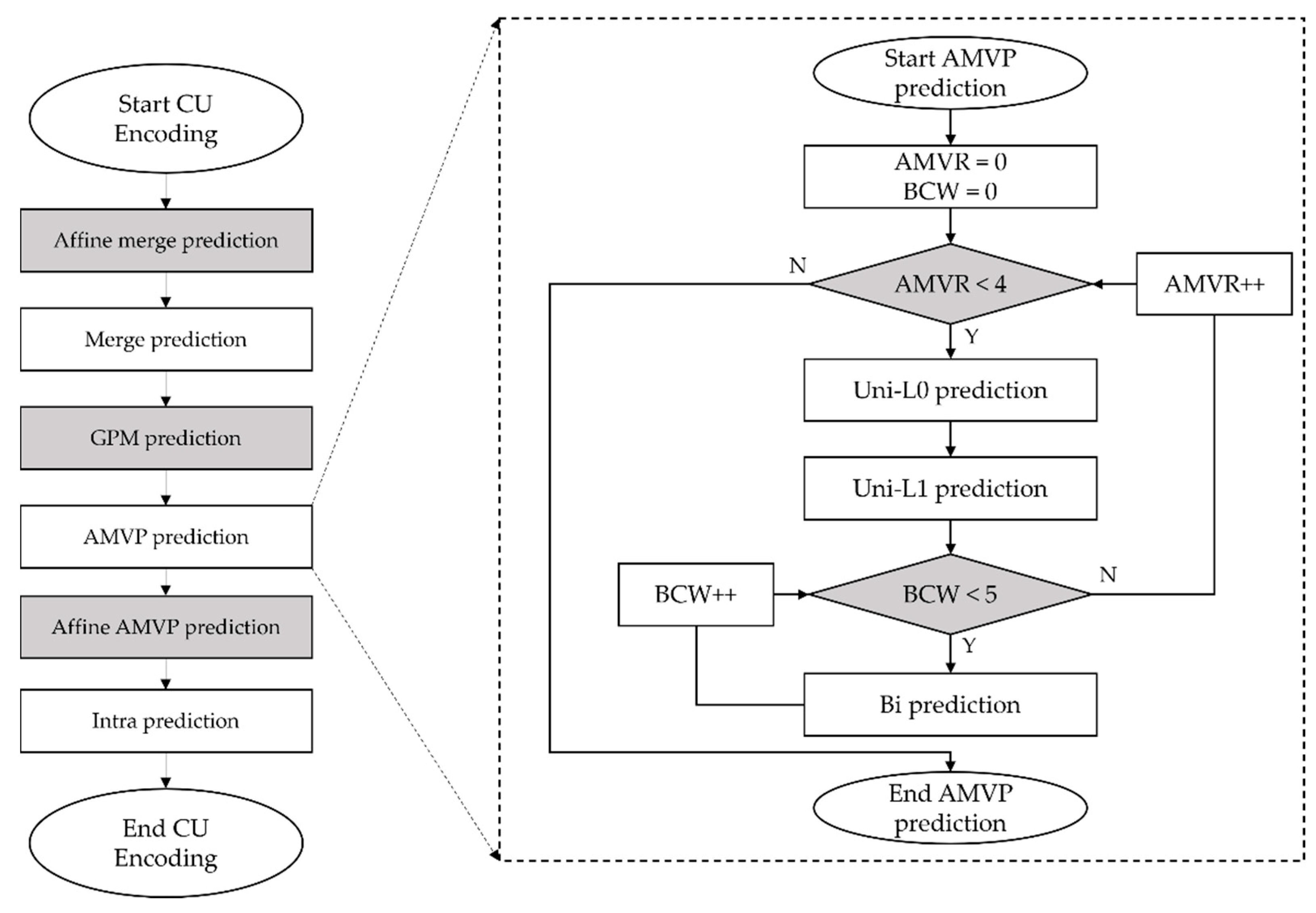
Figure 1 shows the CU encoding procedure in VVC. First, a CU performs the encoding process according to the order of affine merge, regular merge, GPM prediction, and AMVP prediction. In AMVP prediction, the five BCW weights are performed as the bi-prediction within the loop of the four AMVR iterations. Finally, the optimal mode of the current CU is determined after performing intra prediction.
Recently, several studies have aimed to reduce the computational complexity of VVC encoders. These studies mainly focused on reducing the complexity of the new block partitioning tools in VVC. In addition, studies utilizing convolutional neural networks (CNNs) or multilayer perceptrons (MLPs) for complexity reduction have showed convincing results from the development of deep learning technology. Zhao et al. [
13] proposed the complexity reduction algorithm of VVC intra prediction based on statistical analysis and a size-adaptive CNN (SAE-CNN) to determine whether to split CUs of different sizes. Zhang et al. [
14] designed a prediction tool using DenseNet to predict the probability of whether the edges of 4 × 4 CU units are division boundaries and consequently reduce the coding complexity of VVC. Yoon et al. [
15] proposed an activity-based fast block partitioning decision method using the information of the current CU, minimizing the dependence on the QP and utilizing the gradient calculation used in the adaptive loop filter (ALF). Wang et al. [
16] designed a multistage early termination CNN (MET-CNN) model to predict the partition information of 32 × 32-sized CUs. In addition, they proposed the concept of stage grid maps by dividing the entire partition into four stages to represent the structured output and consequently predict all partition information of the 32 × 32-sized CUs and their sub-CUs as the model outputs. Zhao et al. [
17] proposed a support vector machine (SVM)-based fast CU partition decision algorithm by analyzing the ratio of the split modes of CUs of different sizes to effectively reduce the coding complexity of VVC. Jin et al. [
18] proposed a CNN-based fast QTBT partitioning method to predict the depth range of the QTBT partition for 32 × 32 blocks based on the inherent texture richness of the image rather than judging the split at each depth level. Pan et al. [
19] proposed an early termination of the QTMT-based block partition process using a multi-information fusion CNN (MFCNN) model. In addition, a content-complexity-based early merge mode decision method was proposed for the CU prediction residuals and the confidence of MFCNN. Liu et al. [
20] designed a CNN-based model for fast inter partitioning in VVC, limiting the QT split search and avoiding partitions that are unlikely to be selected.
In VVC, complexity reduction studies of prediction tools were mainly conducted on statistical characteristics. Jung et al. [
21] proposed a fast affine prediction method that determines whether to perform a context-based affine prediction mode to reduce inter-prediction complexity. Zhang et al. [
22] proposed a fast GPM decision algorithm by comparing the average values of the gradients in four directions of the CUs to determine whether to perform GPM in VVC. They used the Sobel operator to calculate the gradients and determined six GPM candidate modes based on the gradient directions. Tun et al. [
23] investigated the relationship between the RD cost and the sum of absolute transformed difference (SATD) of rough mode decision (RMD) to decrease the RDO calculations of intra-prediction modes. Park et al. [
24] proposed a method to reduce the encoding complexity of intra prediction, which designed a light gradient boosting machine (LightGBM) model using the average absolute sum of transform coefficients as a key feature to determine whether to perform the ISP mode. Dong et al. [
25] proposed a fast intra mode decision algorithm consisting of two aspects of mode selection and prediction termination. Shang et al. [
26] also designed a fast intra-prediction algorithm based on statistical characteristics using the distribution of neighboring coding regions and prediction modes to skip unnecessary splits and prediction modes in advance. Although studies to reduce the complexity of intra-prediction tools have been conducted in various aspects, more studies are needed to speed up the newly adopted inter-prediction tools in VVC.
3. Proposed Method
To implement a fast encoding algorithm on the limited hardware platform, it is efficient to use an MLP with lower complexity than a CNN. Therefore, the proposed method designed an MLP-based neural network that exhibits significantly lower complexity than the CNN-based model.
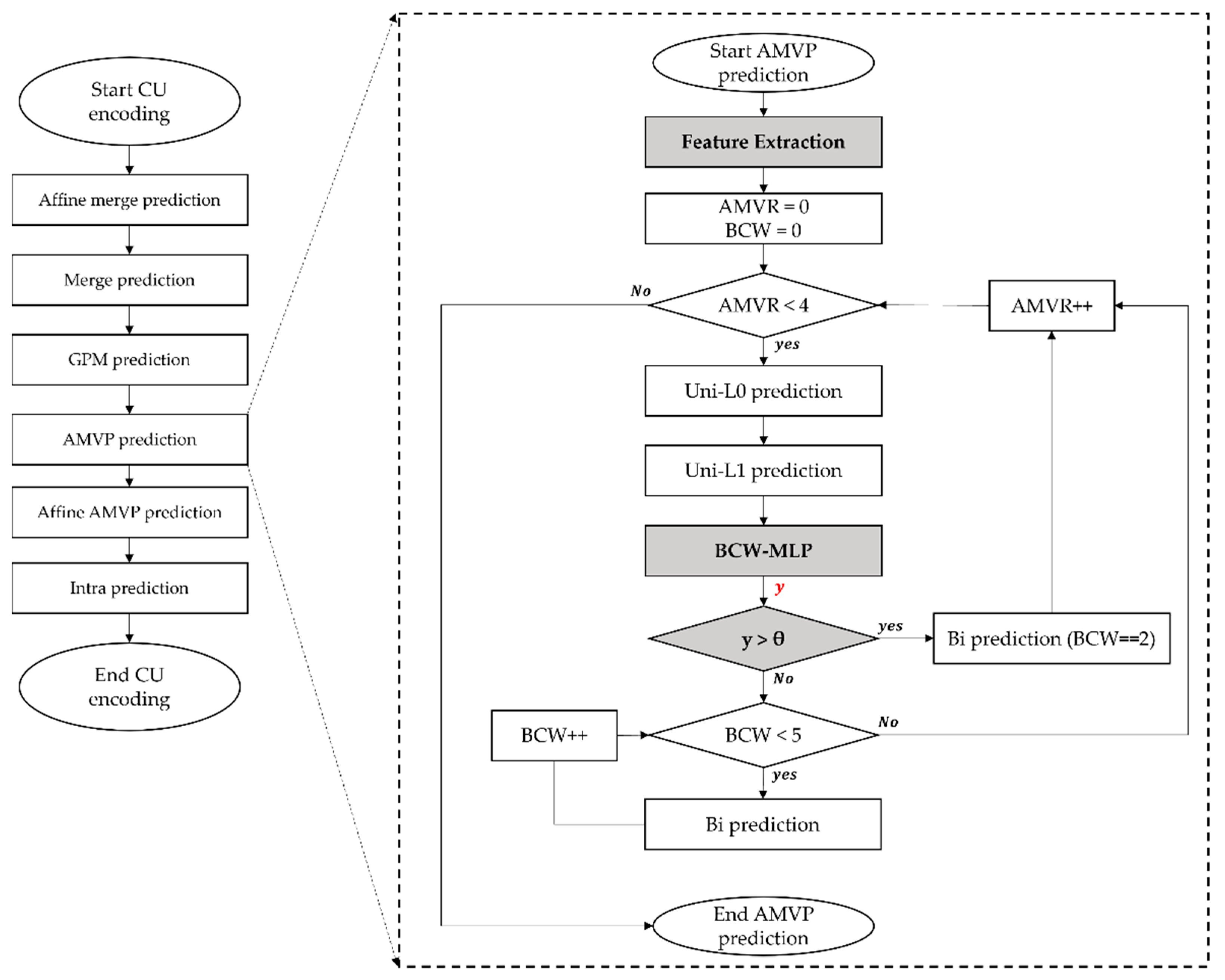
As shown in
Figure 2, the proposed method is divided into two processes: extracting input features and determining whether to perform average weighting based on the output of the BCW-MLP. First, we extracted six input features to be fed into the BCW-MLP model. Subsequently, the BCW-MLP model outputted the y value to determine whether to perform the BCW with average weight. If the output y value is greater than the predefined threshold, the BCW-Idx 2 is performed; otherwise, the encoding process is performed for all BCW modes.
3.1. Feature Extraction for BCW-MLP
In this study, the proposed method defined the relationship between the parent and neighboring CUs of a current CU, where the parent CU can be a square QT node or a rectangular MTT node covering the area of the current CU. On the other hand, the neighboring CUs refer to the left and above CUs, which complete the encoding and decoding process.
The network input features are classified into four categories, all input features are extracted during the encoding process, and each input feature is converted into a value between 0 and 1. The first category shows the correlation of the BCW modes with the parent and neighboring CUs, which can be related to the current BCW mode. The second category includes base QP, slice QP, and temporal layers, which are features associated with QP. The third category represents the current CU size, such as width, height, and pixel ratios. Finally, the fourth category consists of AMVR and coded block flags (CBFs), which are related to the interference of other prediction tools.
Table 3 presents the detailed definitions of the abovementioned input feature candidates.
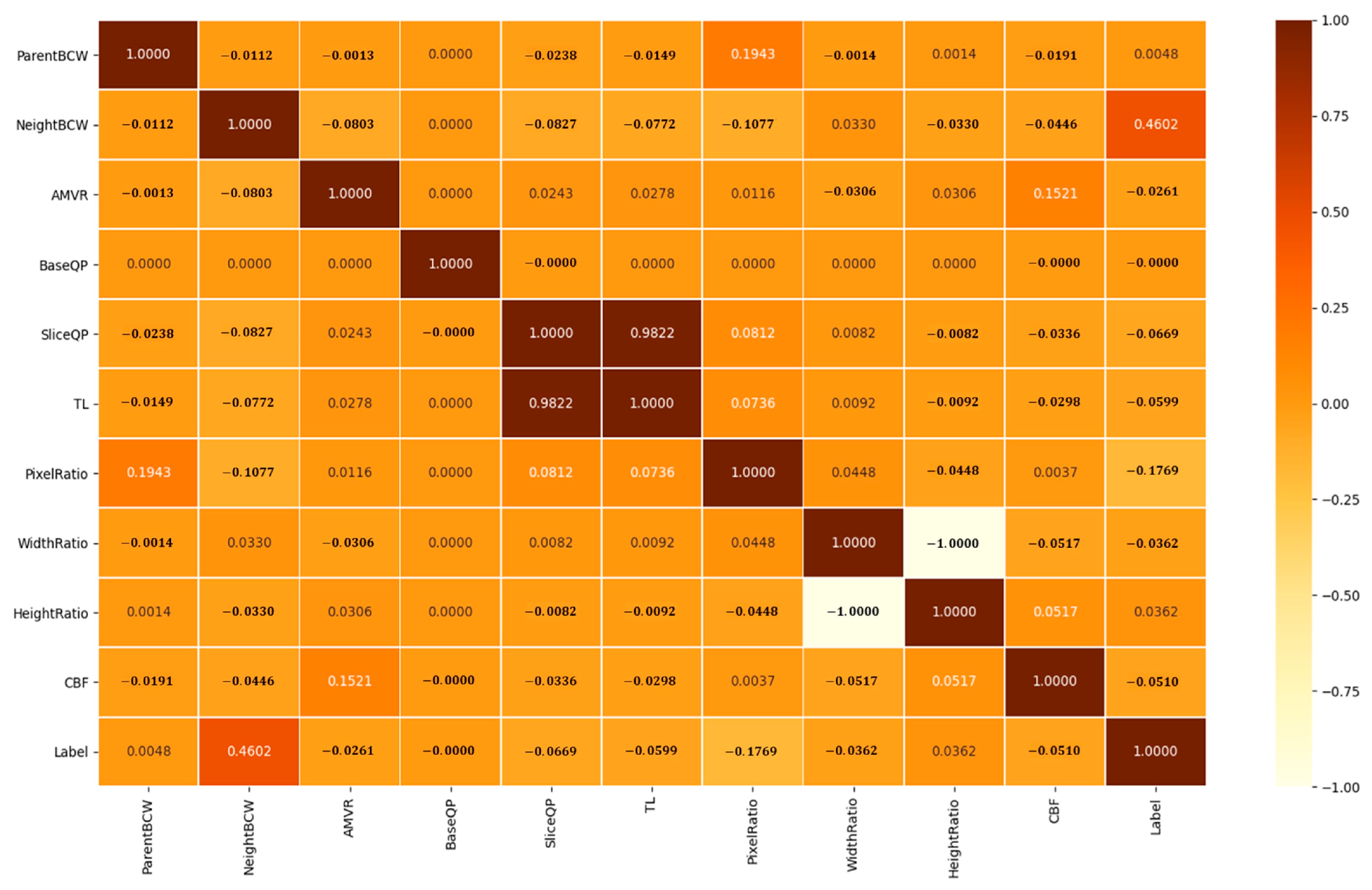
The proposed BCW-MLP model selects fewer input feature candidates to set the input features based on a Pearson correlation coefficient (PCC) heatmap between the input feature candidates and labels as illustrated in
Figure 3. In the first category of
Table 3, two input feature candidates were selected as input features, because they have a strong relationship with the current BCW mode. In the second category of
Table 3, the slice QP has a higher correlation with the label than the base QP and the temporal layer (TL). Additionally, strong intercorrelations exist among features, for example, the PCC between the slice QP and TL was 0.9822. The pixel ratio with the highest correlation in the third category was set as the input feature. Finally, we used two candidates as input features in the fourth category. Therefore, six candidates were used as input features to design the BCW-MLP model, which are parent BCW, neighboring BCW, slice QP, pixel ratio, AMVR, and CBF, respectively.
3.2. Fast Mode Decision Algorithm Using BCW-MLP
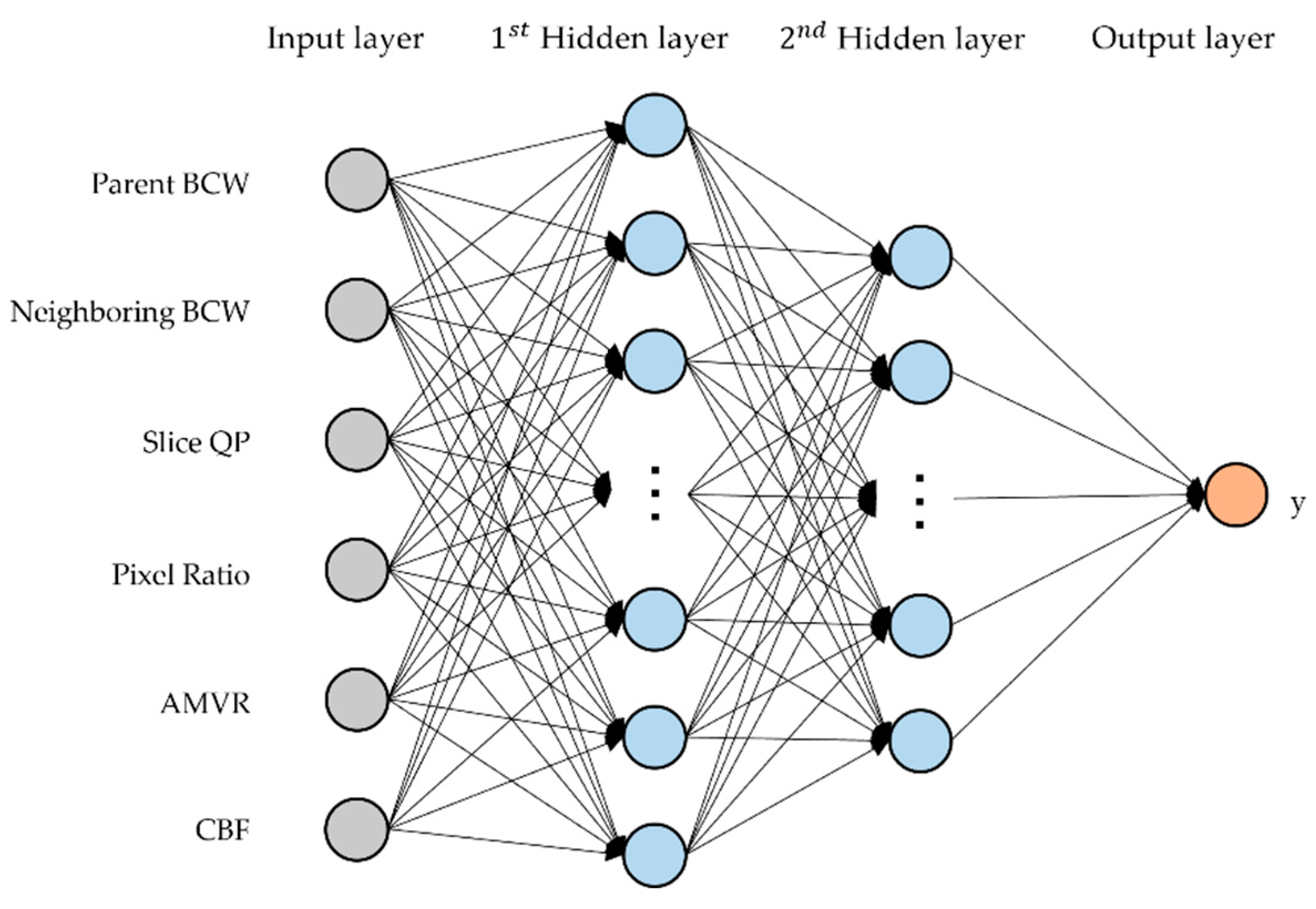
We implemented an MLP architecture before the BCW mode, defined as BCW-MLP, to determine whether to perform the BCW mode—except for the average-weight BCW mode. In the feature extraction stage, a one-dimensional (1D) column vector with six input features was generated as the input vector of BCW-MLP. As shown in
Figure 4, the BCW-MLP consists of six input nodes, two hidden layers with 30 and 15 hidden nodes, and one output node, respectively.
The output of the
th neuron is calculated as in Equation (2):
where
,
,
, and
denote the
th input feature, the filter weight corresponding to the
th input feature, the bias value of the
th node, and the number of nodes within each layer, respectively. In addition,
indicates activation functions of the hidden layer and output layer, which are ReLU and sigmoid function, respectively, and
denotes the output of
the
th neuron. The network output
has a value between 0 and 1. Note that when the output values of the model are close to 1, then only the average-weight BCW mode is performed among the BCW modes.
To establish an appropriate threshold, we investigated the ratio of average weighted BCW modes to the output values of the network.
Table 4 describes the ratio of optimal BCW modes determined by the RDO process during encoding and the distribution by the range of network output values. It can be observed that when the network output value was 0.6 or higher, the distribution of the average weighted BCW mode was over 90%. In this paper, the threshold was set to 0.6. Then, the encoder performs only the average-weight BCW mode when the output value is larger than the threshold.
4. Experimental Results
The proposed method was implemented on top of VTM-11.0 using the Keras2.2.4 library on Python 3.6.8.
Table 5 shows the training environments of the proposed network. The proposed network was trained using the BVI-DVC dataset [
27] with a resolution of 3840 × 2160 pixels and the QPs were set to 22 and 32. The size of the training dataset is 12,511,937 images, which were collected from various CU sizes during the encoding process. In addition, 20% of the data were used as the validation set.
Table 6 lists the hyperparameters used to train the proposed network. While the activation function of all hidden layers, except the final output layer, was set to ReLU, the output layer used the sigmoid function to compute a floating value between 0 and 1. The batch size, learning rate, and optimization method were set to 512, 0.01, and stochastic gradient descent (SGD) [
28], respectively. The weight initialization of the hidden layers was performed according to Xavier’s normalized initialization procedure [
29], whereby the optimized model parameters were updated iteratively within a predefined epoch number and the Mean Squared Error (MSE) was used as a loss function.
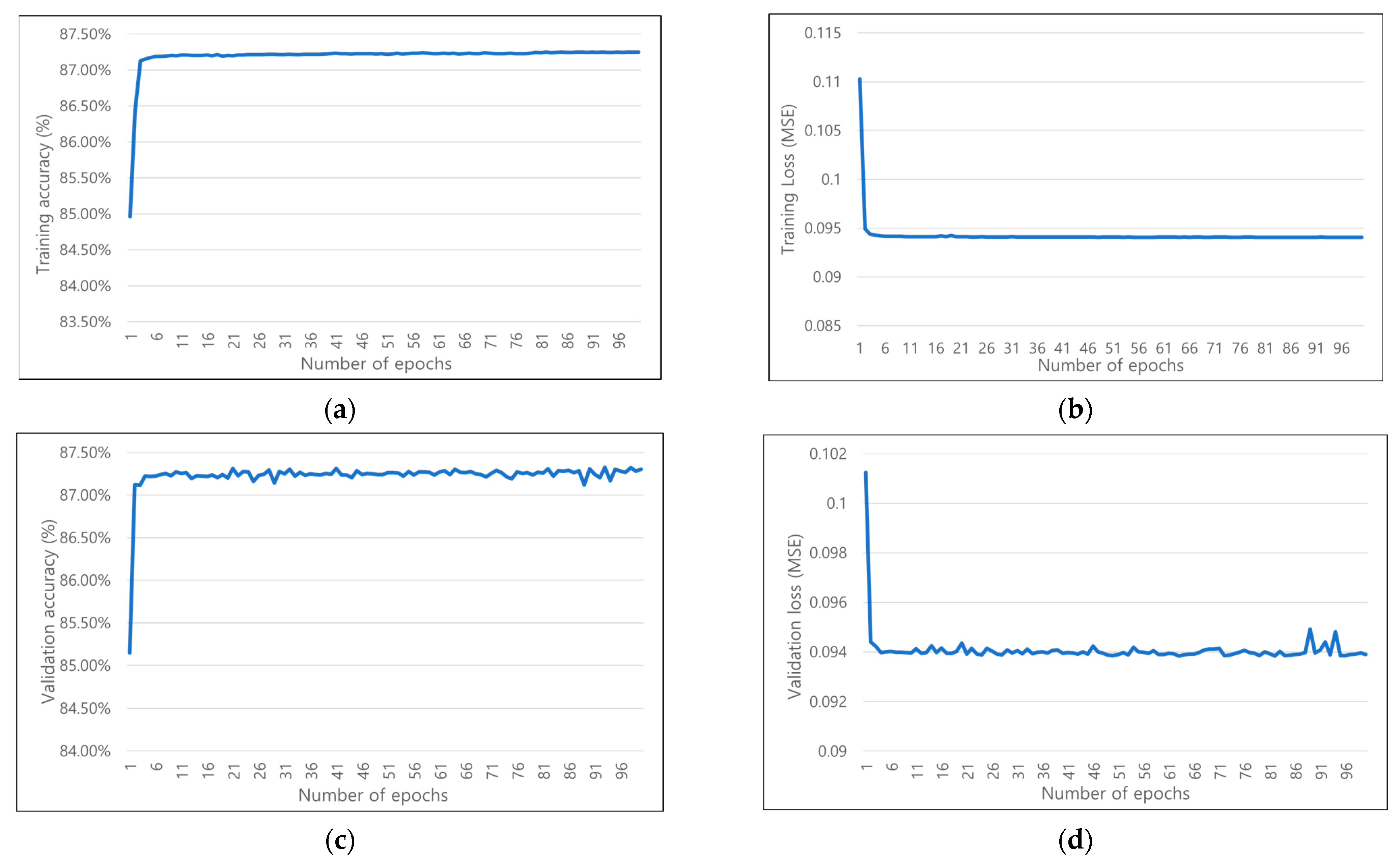
Figure 5 shows the training and validation results of the proposed network, which measure the accuracy of the optimal BCW mode and loss functions according to the number of epochs.
To investigate the optimal architecture of BCW-MLP, various ablation works were conducted in terms of the number of input features, hidden layers, and nodes per hidden layer as shown in
Table 7. After considering both the accuracy and the loss of networks, BCW-MLP has two hidden layers with 30 and 15 nodes in the first and second layer, respectively.
In addition, tool-off tests on the validation and training datasets were performed to measure the effectiveness of the six input features.
Table 8 represents the experimental results obtained by omitting one of the six input features and shows that each input feature has an effect on the performance of our network. In particular, the neighboring BCW is observed as the most effective input feature of BCW-MLP.
All experiments were run on an Intel Xeon Gold 6230R 52-cores 2.10 GHz processor with 256 GB RAM operated by the 64-bit Windows server 2019. In class A (3840 × 2160) and B (1920 × 1080) sequences of JVET CTC, the performance of the proposed method was evaluated under the random-access (RA) and the low-delay-B (LDB) configuration and compared with VTM-11.0. Additionally, the trained model was converted to the C++ standard format and implemented in the VTM-11.0. To measure the coding loss, we used the Bjontegaard Delta Bit Rate (BDBR) [
30]. In general, a BDBR increase of 1% corresponds to a BD-PSNR decrease of 0.05 dB, where the positive increment in BDBR indicates coding loss. The weighted averages of the
BDBR of the
Y,
U, and
V color components were measured as in Equation (3):
where
,
, and
denote the BDBRs of the Y, U, and V color components, respectively. To evaluate the encoding time (
ET) reduction, the
and
are computed as in Equations (4) and (5):
where
,
, and
indicate the total encoding times of the anchor, tool-off test, and proposed methods, respectively. For comparison of the computational complexities, we measured the time savings of total encoding time (
TET) and BCW encoding time (BET) by Equations (6) and (7):
where
,
,
, and
mean the
TET of the
,
TET of the
, BET of the
, and BET of the
, respectively. For reference,
BET measures the time taken only for the portion of the VVC encoder process that performs bi-prediction. In summary, the performance comparisons between the proposed method and the anchor are presented in
Table 9. Compared to the anchor, the proposed method can achieve average time savings of 32% and 33% in terms of
TET and
BET, respectively.
Table 10 shows the performance comparisons between the proposed method and the anchor under the LDB configuration. In addition, the proposed method was tested for class B. Compared to the anchor, the proposed method achieved average time savings of 35% and 49% in terms of TET and BET, respectively. The experimental results show that the proposed method achieves higher coding efficiency in the LDB configuration compared to the RA configuration.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}