
A Novel Turbo Detector Design for a High-Speed SSVEP-Based Brain Speller

Abstract
:1. Introduction
2. Methods and Materials
2.1. Filter Bank Canonical Correlation Analysis and Extend Canonical Correlation Analysis
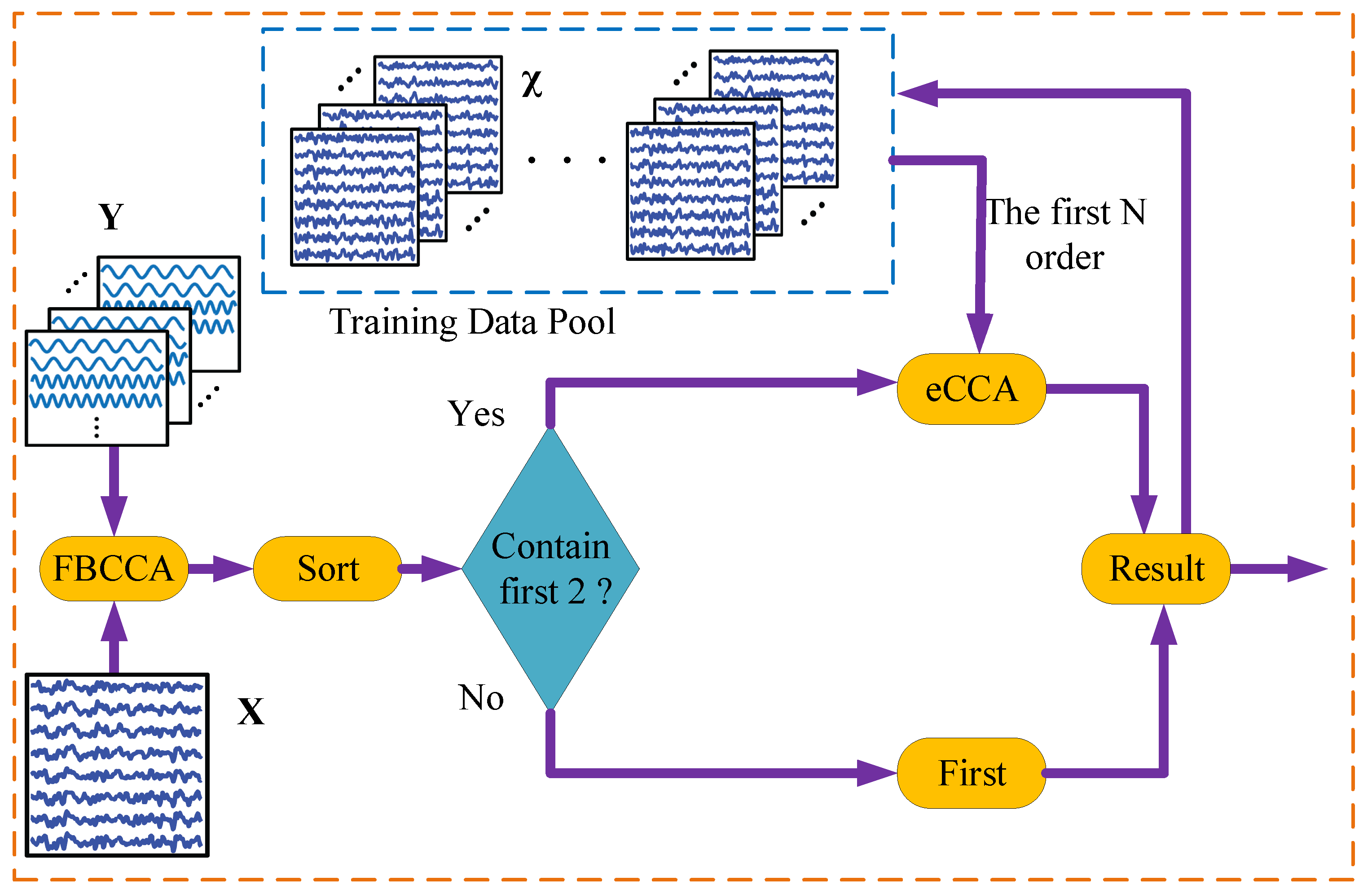
2.2. Turbo Detector
| Algorithm 1 Turbo strategy for SSVEP-based BCIs. |
|
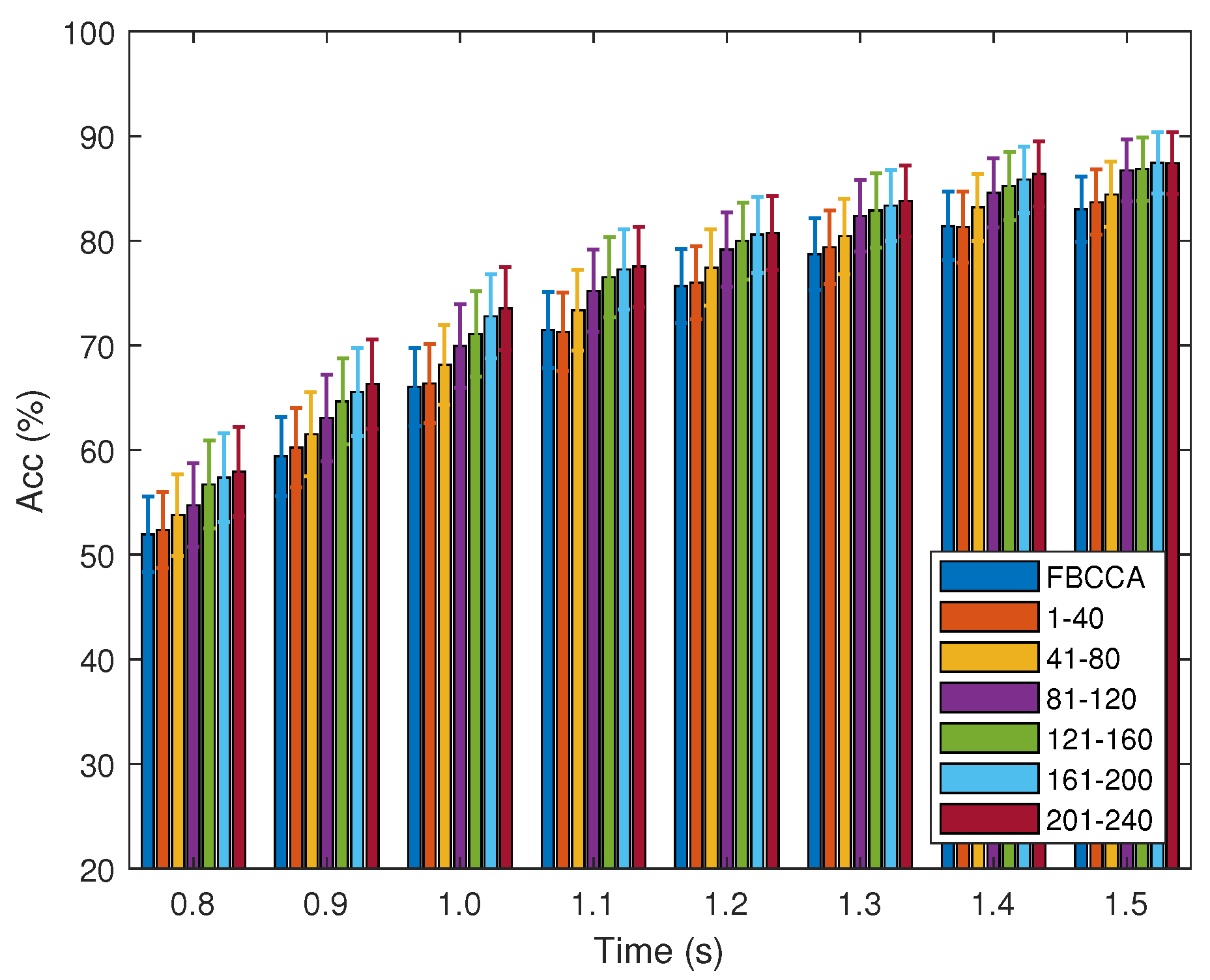
2.3. Training Data Selection
| Algorithm 2 Training data selection method. |
|
3. Performance and Evaluations
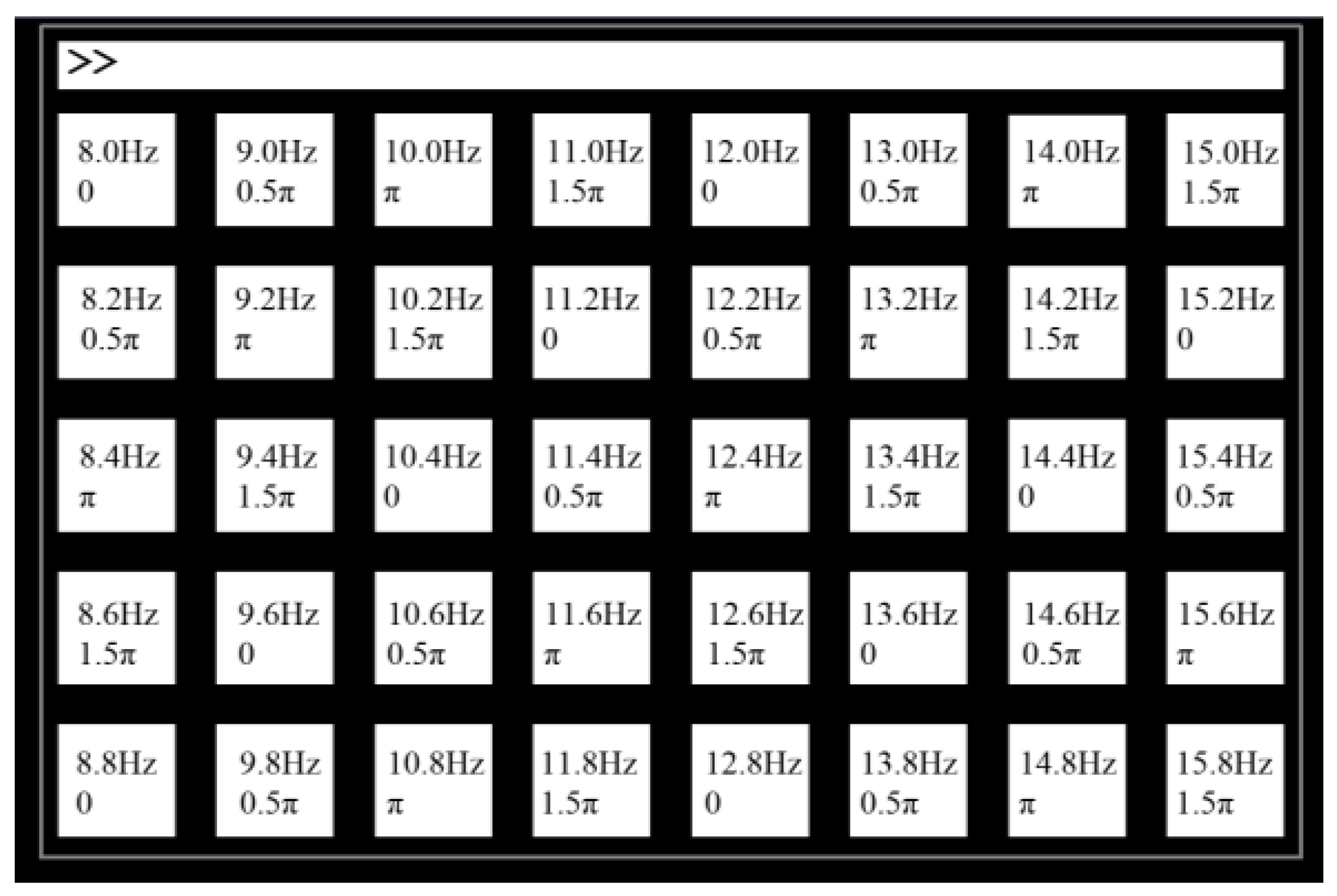
3.1. Test Method and datasets
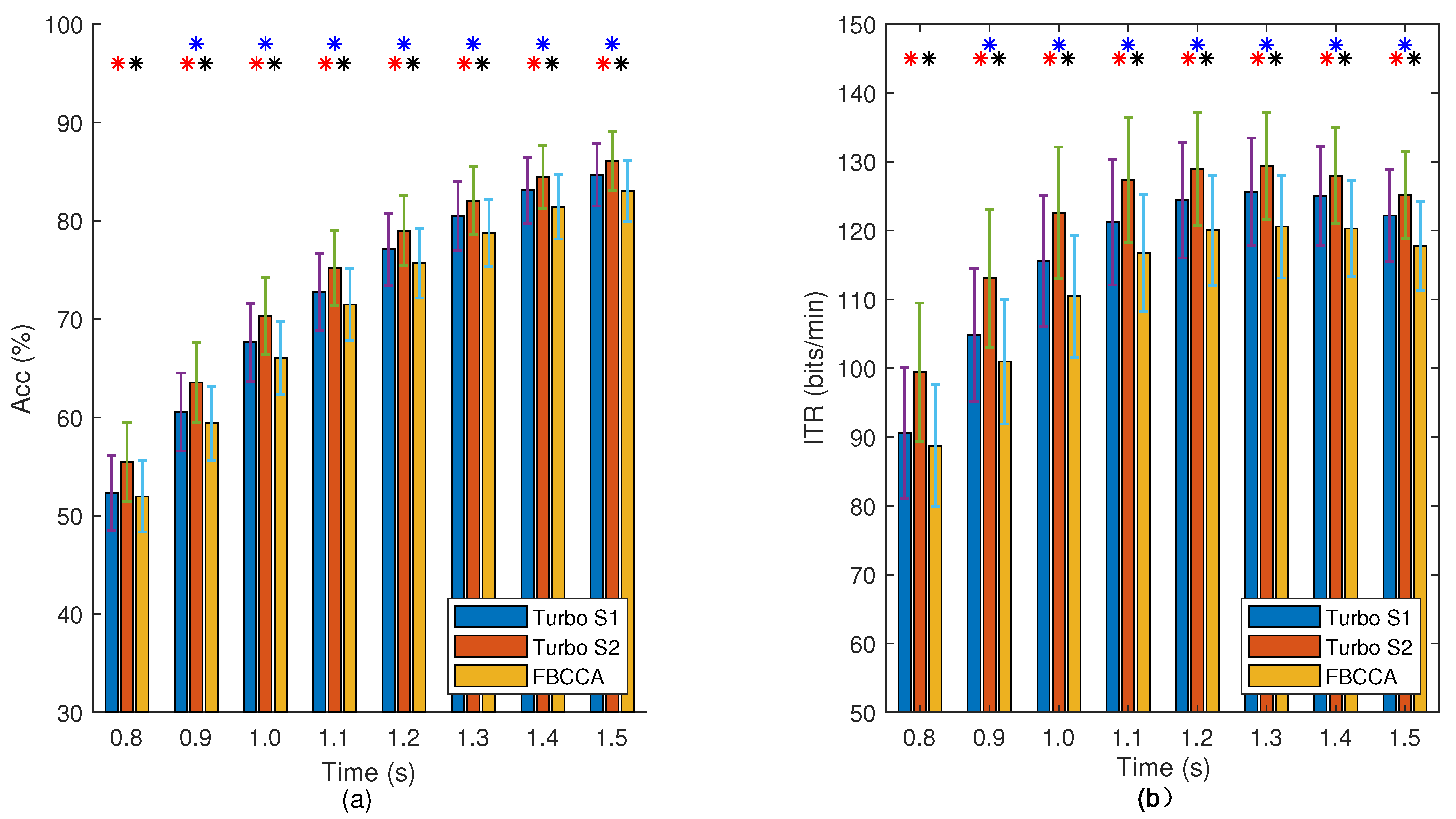
3.2. Performance Evaluation
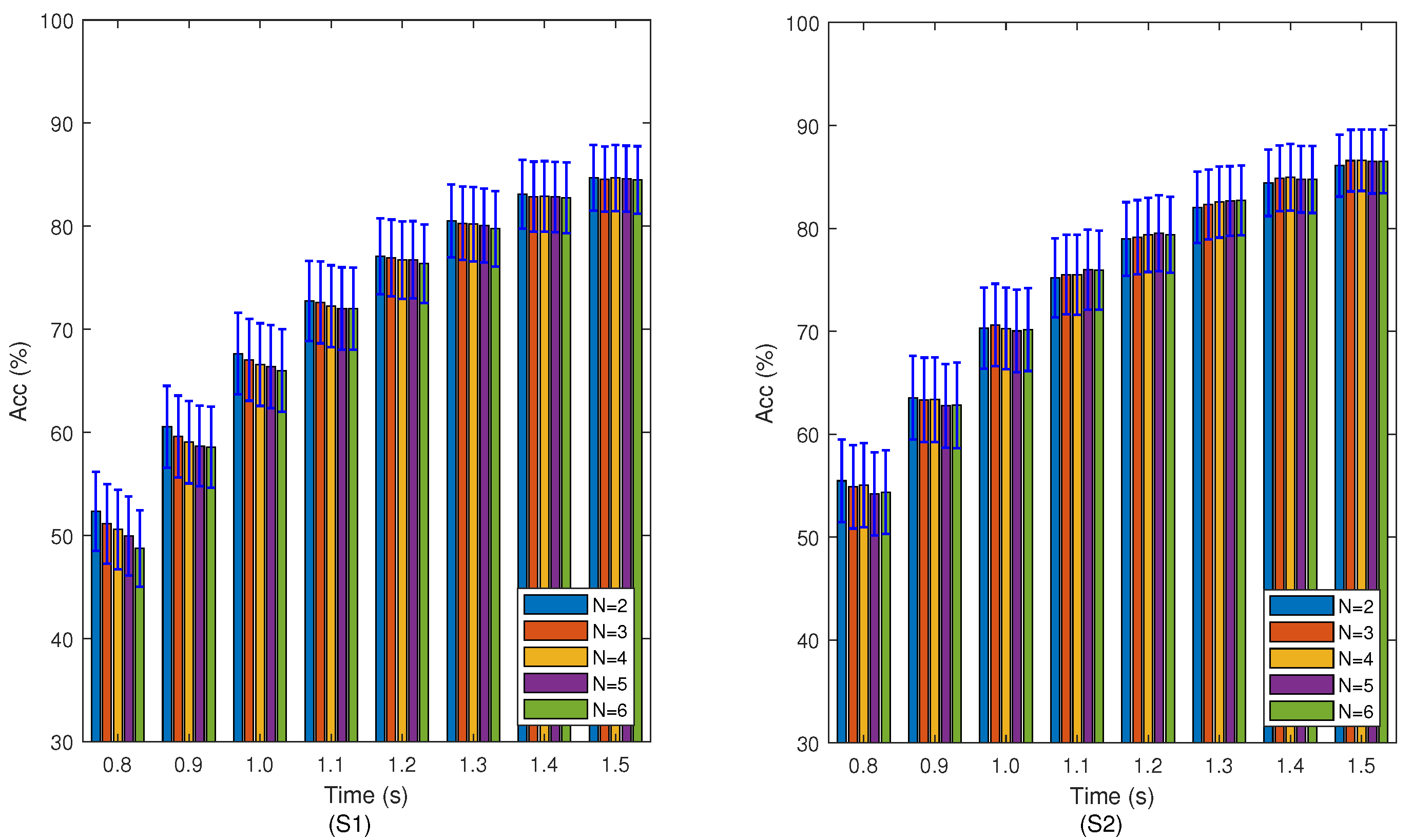
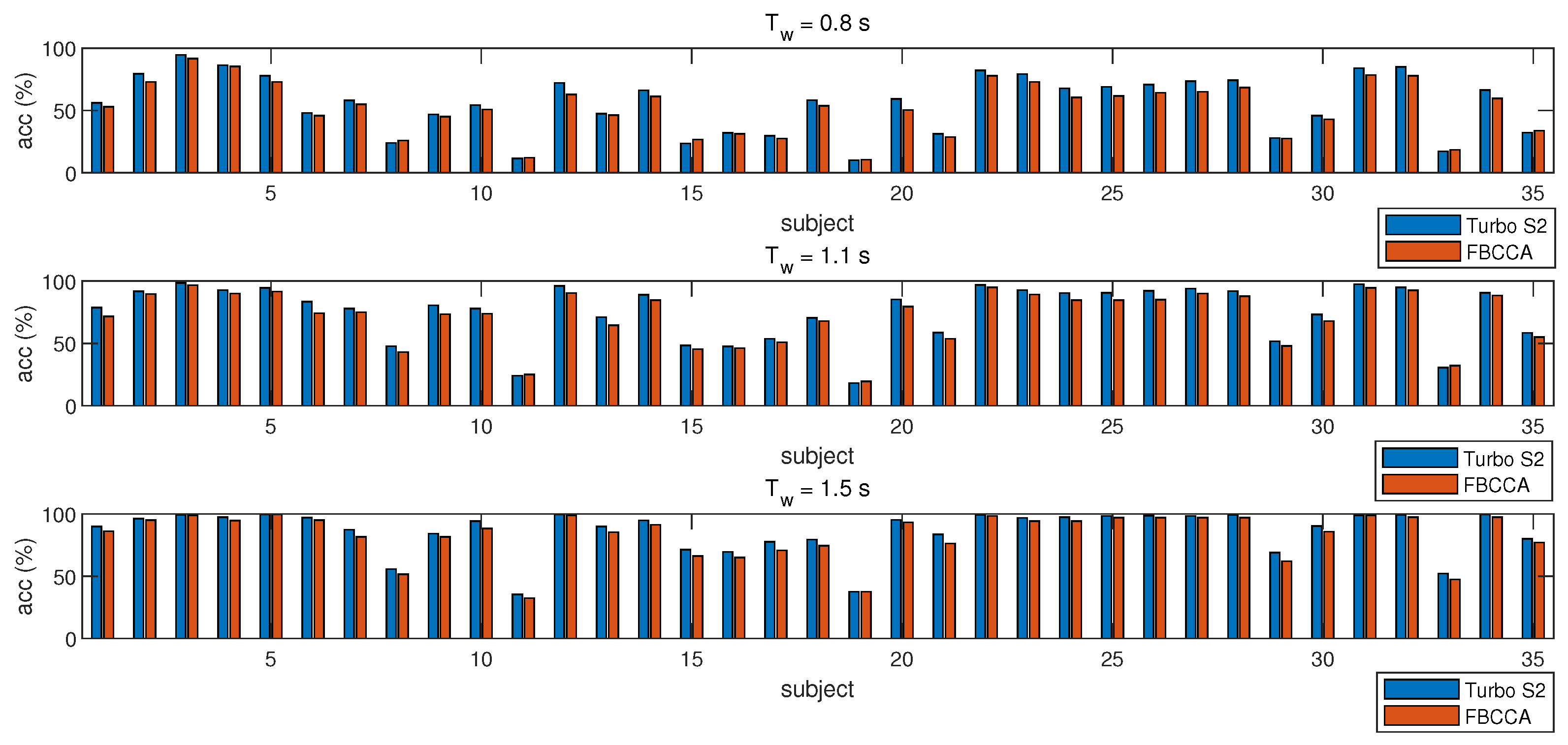
3.3. Results
4. Discussion
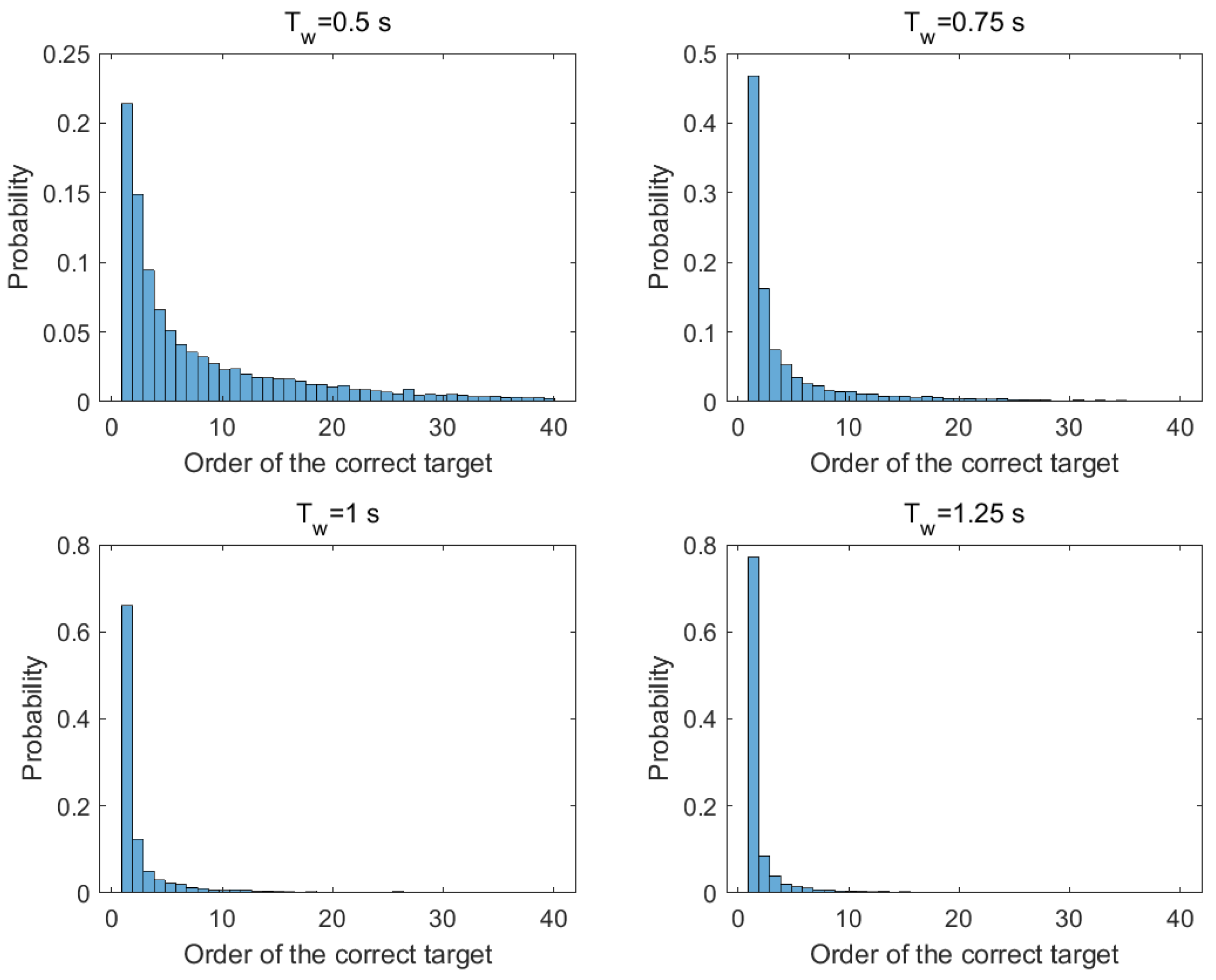
4.1. The Probability of the Second-Stage Detector
4.2. Error Propagation
4.3. Computational Complexity
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Gao, X.; Hong, B.; Jia, C.; Gao, S. Brain-Computer Interfaces Based on Visual Evoked Potentials. IEEE Eng. Med. Biol. Mag. 2008, 27, 64–71. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Chen, X.; Gao, X.; Gao, S. A Benchmark Dataset for SSVEP-Based Brain-Computer Interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 1746–1752. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Huang, X.; Wang, Y.; Chen, X.; Gao, X. BETA: A Large Benchmark Database Toward SSVEP-BCI Application. Front. Neurosci. 2019, 14, 627. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Wang, Y.; Nakanishi, M.; Gao, X.; Jung, T.P.; Gao, S. High-speed spelling with a noninvasive brain-computer interface. Proc. Natl. Acad. Sci. USA 2015, 112, E6058. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, Q.; Liu, Y.; Gao, X.; Wang, Y.; Yang, C.; Lu, Z.; Gong, H. A Novel c-VEP BCI Paradigm for Increasing the Number of Stimulus Targets Based on Grouping Modulation With Different Codes. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 1178–1187. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Wang, Y.; Nakanishi, M.; Jung, T.; Gao, X. Hybrid frequency and phase coding for a high-speed SSVEP-based BCI speller. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 3993–3996. [Google Scholar] [CrossRef]
- Kimura, Y.; Tanaka, T.; Higashi, H.; Morikawa, N. SSVEP-Based Brain–Computer Interfaces Using FSK-Modulated Visual Stimuli. IEEE Trans. Biomed. Eng. 2013, 60, 2831–2838. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Y.; Jung, T. Visual stimulus design for high-rate SSVEP BCI. Electron. Lett. 2010, 46, 1057–1058. [Google Scholar] [CrossRef]
- Hwang, H.; Han, C.; Lim, J.; Kim, Y.; Choi, S.; An, K.; Lee, J.; Cha, H.; Kim, S.H.; Im, C. Clinical feasibility of brain-computer interface based on steady-state visual evoked potential in patients with locked-in syndrome: Case studies: Clinical feasibility of SSVEP-based BCI. Psychophysiology 2016, 54, 444. [Google Scholar] [CrossRef]
- Lim, J.H.; Kim, Y.W.; Lee, J.H.; An, K.O.; Hwang, H.J.; Cha, H.S.; Han, C.H.; Chang-Hwan, I. An emergency call system for patients in locked-in state using an SSVEP-based brain switch. Psychophysiology 2017, 54, 1632. [Google Scholar] [CrossRef]
- Zerafa, R.; Camilleri, T.; Falzon, O.; Camilleri, K.P. To train or not to train? A survey on training of feature extraction methods for SSVEP-based BCIs. J. Neural Eng. 2018, 15, 051001. [Google Scholar] [CrossRef]
- Lin, Z.; Zhang, C.; Wu, W.; Gao, X. Frequency Recognition Based on Canonical Correlation Analysis for SSVEP-Based BCIs. IEEE Trans. Biomed. Eng. 2006, 53, 2610–2614. [Google Scholar] [CrossRef] [PubMed]
- Bin, G.; Gao, X.; Yan, Z.; Hong, B.; Gao, S. An online multi-channel SSVEP-based brain-computer interface using a canonical correlation analysis method. J. Neural Eng. 2009, 6, 046002. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Yang, C.; Chen, X.; Wang, Y.; Gao, X. A novel training-free recognition method for SSVEP-based BCIs using dynamic window strategy. J. Neural Eng. 2021, 18, 036007. [Google Scholar] [CrossRef] [PubMed]
- Friman, O.; Volosyak, I.; Graser, A. Multiple Channel Detection of Steady-State Visual Evoked Potentials for Brain-Computer Interfaces. IEEE Trans. Biomed. Eng. 2007, 54, 742–750. [Google Scholar] [CrossRef]
- Yang, C.; Han, X.; Wang, Y.; Saab, R.; Gao, X. A Dynamic Window Recognition Algorithm for SSVEP-Based Brain-Computer Interfaces Using a Spatio-Temporal Equalizer. Int. J. Neural Syst. 2018, 28, 1850. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Xu, P.; Cheng, K.; Yao, D. Multivariate Synchronization Index for Frequency Recognition of SSVEP-based Brain-computer Interface. J. Neurosci. Methods 2013, 221, 32–40. [Google Scholar] [CrossRef] [PubMed]
- Bin, G.; Gao, X.; Wang, Y.; Li, Y.; Hong, B.; Gao, S. A high-speed BCI based on code modulation VEP. J. Neural Eng. 2011, 8, 025015. [Google Scholar] [CrossRef] [Green Version]
- Nakanishi, M.; Wang, Y.; Wang, Y.T.; Mitsukura, Y.; Jung, T.P. A high-speed brain speller using steady-state visual evoked potentials. Int. J. Neural Syst. 2014, 24, 1450019. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, G.; Zhao, Q.; Onishi, A.; Jin, J.; Wang, X.; Cichocki, A. Multiway Canonical Correlation Analysis for Frequency Components Recognition in SSVEP-Based BCIs. Lect Notes Comput. Sci. 2011, 7062, 287–295. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, G.; Jin, J.; Wang, M.; Wang, X.; Cichocki, A. L1-Regularized Multiway Canonical Correlation Analysis for SSVEP-Based BCI. IEEE Trans. Neural Syst. Rehabil. Eng. 2013, 21, 887–896. [Google Scholar] [CrossRef] [PubMed]
- Nakanishi, M.; Wang, Y.; Nakanishi, M.; Wang, Y.T.; Jung, T.P. Enhancing detection of steady-state visual evoked potentials using individual training data. In Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 3037–3040. [Google Scholar]
- Chi, M.W.; Wan, F.; Wang, B.; Wang, Z.; Nan, W.; Lao, K.F.; Peng, U.M.; Vai, M.I.; Rosa, A. Learning across multi-stimulus enhances target recognition methods in SSVEP-based BCIs. J. Neural Eng. 2020, 17, 016026. [Google Scholar]
- Chen, X.; Wang, Y.; Gao, S.; Jung, T.P.; Gao, X. Filter bank canonical correlation analysis for implementing a high-speed SSVEP-based brain-computer interface. J. Neural Eng. 2015, 12, 046008. [Google Scholar] [CrossRef] [PubMed]
- Proakis, J.G.; Salehi, M. Digital Communications, 5th ed.; McGraw-Hill: New York, NY, USA, 2008. [Google Scholar]
- Li, H. Statistical Learning Method; Tsinghua University Press: Beijing, China, 2012; pp. 137–153. [Google Scholar]
- Kobza, J.E.; Jacobson, S.H.; Vaughan, D.E. A Survey of the Coupon Collector’s Problem with Random Sample Sizes. Methodol. Comput. Appl. Probab. 2007, 9, 573–584. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S1 | S2 | |||||
|---|---|---|---|---|---|---|
| 0.8 | 1.1 | 1.5 | 0.8 | 1.1 | 1.5 | |
| 2–3 | ≫ | ≈ | ≈ | > | ≈ | < |
| 3–4 | ≫ | > | ≈ | ≈ | ≈ | ≈ |
| 4–5 | ≫ | ≈ | ≈ | ≈ | ≈ | ≈ |
| 5–6 | ≫ | ≈ | ≈ | ≈ | ≈ | ≈ |
| 1–40 | 121–160 | 201–240 | ||||
|---|---|---|---|---|---|---|
| Improvement | p-Value | Improvement | p-Value | Improvement | p-Value | |
| 0.8 | 0.4 | ≈ | 4.8 | ≫ | 6.0 | ≫ |
| 1.1 | −0.2 | ≈ | 5.0 | ≫ | 6.1 | ≫ |
| 1.5 | 0.7 | > | 3.8 | ≫ | 4.4 | ≫ |
| Improved (sub) | AVG ACC (%) | Decreased (sub) | AVG ACC | |
|---|---|---|---|---|
| 0.8 | 29 | 62.9 | 6 | 19.8 |
| 1.1 | 32 | 80.0 | 3 | 24.3 |
| 1.5 | 35 | 86.1 | − | − |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, C.; Wang, H.; Cai, J. A Novel Turbo Detector Design for a High-Speed SSVEP-Based Brain Speller. Electronics 2022, 11, 4231. https://doi.org/10.3390/electronics11244231
Tong C, Wang H, Cai J. A Novel Turbo Detector Design for a High-Speed SSVEP-Based Brain Speller. Electronics. 2022; 11(24):4231. https://doi.org/10.3390/electronics11244231
Chicago/Turabian StyleTong, Changkai, Huali Wang, and Jun Cai. 2022. "A Novel Turbo Detector Design for a High-Speed SSVEP-Based Brain Speller" Electronics 11, no. 24: 4231. https://doi.org/10.3390/electronics11244231