1. Introduction
In recent years, the performance of image classification based on image signal processing which extracts image feature with neural networks have been significantly improved with the aid of highly complex
deep neural network models. At the same time, significant advances have been made in network compression [
1], in which the complexity of the neural network models are reduced while attempting to minimize the accompanying loss in accuracy of the models used.
Knowledge distillation [
2,
3] has recently attracted attention as an effective model compression method. Knowledge distillation is a method that transfers knowledge from a pre-trained large neural network model (teacher network model) to a relatively small and low-performance neural network model (student network model). By doing so, the student network model can achieve higher performance than when it is trained from scratch using a given training dataset. There are also other model compression methods such as neural network quantization [
4,
5], pruning [
6,
7] and binarization [
8,
9,
10,
11,
12,
13]. These latter methods sometimes used in conjunction with knowledge distillation.
The training method used in knowledge distillation varies according to the knowledge types and knowledge distillation algorithms used. According to the survey paper written by Gou et al. [
14], knowledge types can be divided into response-based, feature-based, and relation-based knowledge. Also, depending on the primary techniques used, distillation algorithms are classified into adversarial knowledge distillation, data-free knowledge distillation and other types of knowledge distillation [
15,
16,
17,
18,
19].
Adversarial knowledge distillation is a method that uses a Generative Adversarial Network (GAN) [
20] for neural network compression using knowledge distillation. GANs can be used in conjunction with knowledge distillation to improve the performance of knowledge distillation by allowing the student network to better mimic the teacher network. Since the student network has a relatively smaller capability to learn from a given dataset, adversarial knowledge distillation has been used to provide better knowledge about the distribution of the dataset to the student network.
In [
15], images are augmented to the existing training dataset, and this improved the performance of knowledge distillation due to the augmented dataset. However, to train the student network, this training method requires three additional neural networks—i.e., the teacher network, generator network and discriminator network. Furthermore, before training the targeted student network, additional training is required for the GAN architecture.
In this paper, we propose a novel knowledge distillation training strategy based on generative image processing method, which leverages the inherent knowledge of the teacher network captured by the generator network. Unlike previous adversarial knowledge distillation using both the generator and discriminator parts of GANs to create synthesized training images, the proposed method uses only a generator network to create the synthesized images. Furthermore, since a generator network is trained simultaneously with the student network, no additional training processes are required for the generator network. The intrinsic knowledge of the teacher network is used not only for knowledge distillation itself but also for training the generator to synthesize the images.
Several techniques are utilized to improve the effectiveness of the generator network used. Unlike in typical GANs architecture, the generator is not trained separately, but together with the student network. A loss function is used that is based on the information inherent in the intermediate features of the teacher network and the predictions of the teacher network on a given dataset. Using this loss function, the synthetic images generated are not necessarily realistic looking images—the generator is specifically
designed to improve student network training rather than to produce realistic images. However, the loss function is also designed, using the pre-trained batch normalization statistics [
21,
22] of the teacher network, so that the synthetic images produced have an image data distribution that is
close to a real dataset image distribution.
We conducted experiments to verify the effectiveness of the proposed method not only on the full-precision neural network model but also on an extremely quantized neural network model, which only uses 1-bit values for weight and activation parameters. For further verification, we compared the performance with other GAN-based knowledge distillation methods [
15]. CIFAR-10 and CIFAR-100 datasets [
23] were used for the experiments.
3. Proposed Method: Generative Image Processing
In the proposed
Generative Image Processing(
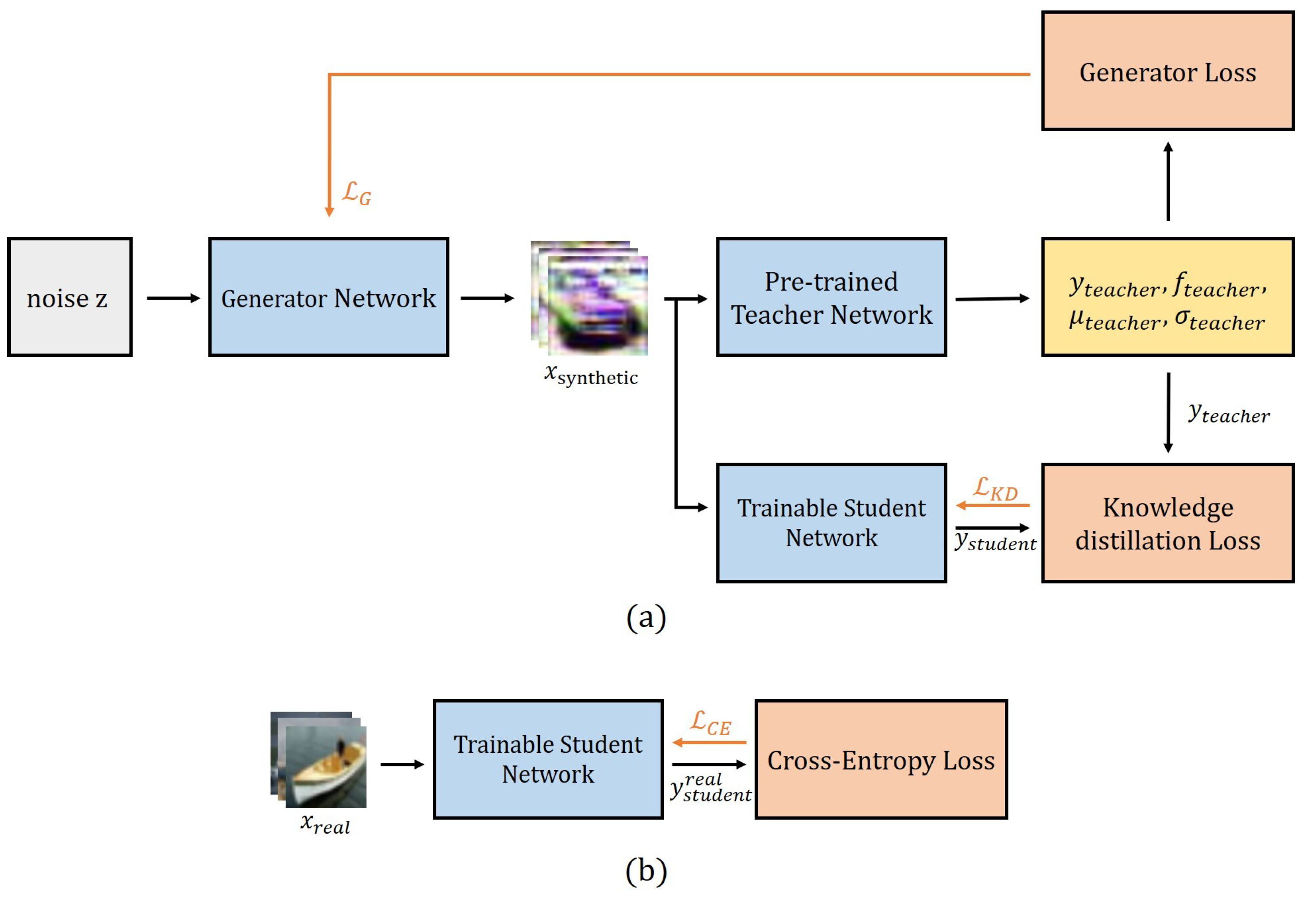
GIP) based knowledge distillation training strategy, synthetic images based on a pre-trained teacher network model’s intrinsic knowledge are augmented to a training dataset in order to improve the performance of the student network. The structure of the proposed GIP method strategy is illustrated in
Figure 2.
Synthetic images are processed and generated from a generator trained with loss functions based on the intermediate layers, output layer, and batch normalization statistics of the teacher network model. In other words, since the generator generates images from the teacher network model rather than from the image dataset, there is no need for a separate training process, and it is trained simultaneously with the student network model. Furthermore, the generated synthetic images are generated anew during each epoch and used together with the previous real image training dataset.
3.1. Definitions and Equations
In this section, definitions and equations related to knowledge distillation, including Kullback-Liebler diversity loss and knowledge distillation loss, will be explained.
3.1.1. Logit Vector
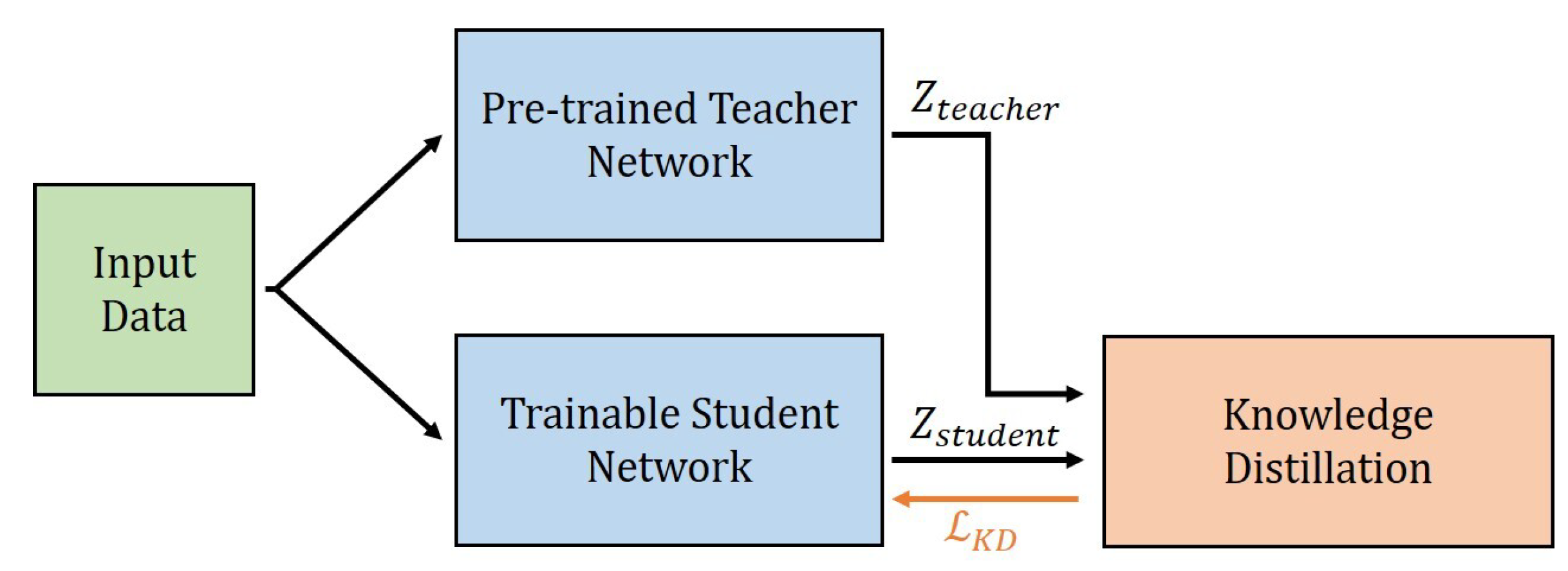
The output of the teacher network model can be expressed as a
logit vector y. Logit is a function described using Equation (
1), which uses the natural logarithm value of the ratio between the probabilities
p and
. Therefore, knowledge distillation loss can be represented by a logit vector
of the student network model and a logit vector
of the teacher network model as shown in
Figure 1.
3.1.2. Softmax Function with Temperature
Hinton et al. [
2] introduced a softmax temperature
T to “soften” the logit vector of the teacher network model. By doing this, the student network model can be trained with information that indicates the relationship among the entire set of classes, and not just a specific class. This concept can be encapsulatd in a
softmax function, which can be expressed as follows.
3.1.3. KD Loss
In Equation (
2),
j represents the
j-th class of the dataset and
T is the softmax temperature factor. As Factor
T increases, the distribution of probabilities becomes smoother. Based on the above softmax function, the loss between the student network model and the teacher network model can be expressed as follows.
In the knowledge distillation training process, Kuleback-Leibler divergence loss is used as the loss function.
Kullback-Leibler diversity loss (
KL loss) is the difference between cross-entropy function and entropy function. The softmax value of the teacher network model and the softmax value of the student network model are used as inputs to KL loss. The cross-entropy loss function and KL loss function used for the experiments can be expressed as follows.
By using the above formula as a loss function for knowledge distillation training, the loss function for knowledge distillation with the softmax function can be expressed as follows.
Allowing the student network model to imitate the logits of the teacher network model can achieve higher performance compared to training without knowledge distillation.
3.2. Generative Adversarial Networks
In the proposed method, GANs architecture is used to generate synthetic images. GANs architecture consists of generator (
G) and discriminator (
D).
G generates synthetic images from real image dataset and
D discriminates synthetic images from real image dataset. Therefore,
G learns to generate synthetic images that is difficult to distinguish, and
D is trained to well distinguish between two image groups. Through this process,
G creates synthetic images close to real image dataset. Formula of objective function, which indicates GANs structure, can be expressed as follows.
where noise vector
z indicates input of
G, and
r means real dataset. Optimized
G after training process can be expressed with optimized
D as follows.
As such, a general GANs structure requires a real image dataset, but [
17] method suggests a way to utilize the GANs architecture in case where the real image dataset is not available. More specifically, the optimized
D was fixed with a pre-trained teacher network model so that it is not necessary to train
D separately.
In our proposed method, we maximized the utilization of the teacher network model by applying the generator structure of the corresponding GANs architecture to a general knowledge distillation training process rather than a restricted scenario where the real image dataset is not available. Since the generator object function of a typical GANs architecture is not suitable for utilizing the knowledge of a teacher network model, new loss functions should be introduced, and the corresponding loss functions will be described in more detail in the later part of this section.
3.3. Batch Normalization Statistics
According to [
21], the distribution information for the training dataset can be preserved in the batch normalization layer of the neural network model trained with the corresponding dataset. Therefore, batch normalization statistics (BNS), which means the values of mean and variance of the batch normalization layers, can be used to manage the distribution of the generated images. Accordingly, it is possible to synthesize images that improve the performance of knowledge distillation by utilizing the knowledge inherent in the BNS of the teacher network model. Detailed loss functions to leverage corresponding BNS of the teacher network model will be described in the next part of this section.
3.4. Proposed Generative Image Processing (GIP) Algorithm
In the GIP Algorithm, shown in Algorithm 1, the method we proposed consists of two parts. The first part shown in
Figure 2a is a training process using synthesized images created from the generator.
refers to the number of iterations for training with synthetic images. Noise vectors of a pre-determined batch size are randomly generated from a normal distribution and used as an input of a generator. After that,
, which is the synthetic images of batch size same as input noise vectors, are generated from the generator. Input the generated
into the teacher network
and extract
,
,
,
. The output
is the prediction of the last layer of the teacher model,
is the output just before the final fully-connected layer, and
and
are BNS of the teacher network. Calculate the loss function of the generator composed of the corresponding values and update the generator. After that, also input the same
into the student network, and calculate the knowledge distillation loss value to update the student network.
The second part shown in
Figure 2b is a training process using real dataset images.
refers to the number of iterations for training with real dataset images. In this part, input the real image dataset into the student network and update the student network by calculating the cross entropy loss between the output prediction of the student network and the ground truth label of real image dataset.
| Algorithm 1 Knowledge distillation training improvement using generative image processing |
Input: Teacher network , Student network , Hyper-parameters, Real dataset images Output: Optimized student network Initialize: Initialization of generator network G and student network - 1:
for
do - 2:
for do ▹Part1: Training with synthetic images - 3:
Generate random noise vector size of a batch: ; - 4:
Generate the synthetic images from generator: ; - 5:
Input the generated synthetic images to teacher network: - 6:
; - 7:
Calculate the generator loss and update G; - 8:
Input the synthetic images to student network: ; - 9:
Calculate student loss with Equation ( 7) and update ; - 10:
end for - 11:
for do ▹Part2: Training with real dataset images - 12:
Input the real dataset images to student network: - 13:
; - 14:
Calculate cross-entropy loss as student loss with Equation ( 4): ; - 15:
Update student network ; - 16:
end for - 17:
end for
|
3.5. Loss Functions
In the proposed algorithm, loss functions of the generator consist of a total of four terms. The first loss function is one-hot loss
[
17]. If the synthesized images are similar to the real dataset images which was used to train teacher network, the output of the teacher network that receives the synthesized image as input will be closer to the one-hot vector. Since the total number of the classes for the image dataset is
k and index of the classes is
j,
of Equation (
11) is a one-hot vector in which only the element with the largest value among
that passes through the softmax function is 1, and the others are 0. Therefore, by training the generator with one-hot loss function, the output of the teacher network will be close to the one-hot vector when using synthesized images from generator as input.
Next, an information entropy loss
is introduced to maintain the class balance of generated synthetic images [
17]. In Equation (
12),
is the average logit in a class
j. And
is the information entropy, which represents the amount of information
p has. As the number of the class is
k,
has a minimum value when all
s are equal to
. Therefore, the frequency of each class of output prediction can be made uniform by optimizing information entropy loss function.
The intermediate feature extracted by the convolution layer of the neural network also has information about the input image. When the input image
is used,
is the feature of the output right before the final fully-connected layer of the teacher network. The closer the input image is to the real dataset image, the higher the activation value of the feature map. Therefore, by using activation loss
, the generator can synthesize images with a high activation value and make the synthesized image close to the real image dataset [
17].
The last loss function is batch normalization statistics loss
[
22]. The distribution information for the training dataset can be extracted from the batch normalization layer of the neural network model trained with the corresponding dataset. When training a teacher network, i.e., a pre-trained model, means and variances of batch normalization layers are learned. When the synthesized images are used as input to the teacher network, the more the newly calculated means and variances based on synthetic images are similar to the pre-trained BNS, the distribution in which the synthesized images are generated becomes similar to the distribution of the real image dataset. Therefore, by using the BNS loss function to train the generator to reduce the difference between the fixed pre-trained BNS and the mean and variance calculated from the synthesized image, images generated from the generator become more similar to the distribution of training data.
Therefore, the final loss function for training the generator network composed of the aforementioned loss functions is written as follows.
Here,
are the coefficient for each loss function. Each coefficient is used as a hyperparameter to adjust the weight of each loss function. The values for
are selected as 1, 5, and 0.1, respectively, which are the same values used in [
17]. The performance is compared by increasing
, which is the weight of
, at intervals of 0.2 from 1 to 10. After that, the final weight values are selected as
,
,
, and
in Equation (
16).
4. Experiments
In this section, implementation details and results of the experiments conducted are explained. Also, an ablation study related to various loss functions of the proposed method will be reported.
4.1. Implementation Details
All of the experiments are conducted with the PyTorch [
29] machine learning framework on two NVIDIA GeForce RTX 3090 GPUs. Details about the datasets and neural network models used are described below.
4.1.1. Datasets
There are two datasets used in the experiment of the proposed method, CIFAR-10 and CIFAR-100 dataset [
23]. Both datasets consist of a total of 60,000 32 × 32 size, 3 channel color images, of which 50,000 images are for training and 10,000 images are for testing. CIFAR-10 is a dataset consisting of 10 classes, and CIFAR-100 is a dataset consisting of 100 classes. Accordingly, CIFAR-10 consists of 6000 images per class and CIFAR-100 consists of 600 images per class. Data augmentation methods such as random cropping, lighting, and random horizontal flipping were applied to the corresponding datasets, and were commonly applied to the teacher network model training, baseline training, general knowledge distillation training and proposed method.
4.1.2. Neural Network Model Settings
We used ResNet-34 [
30] as a teacher network model and ResNet-18 [
30] and ReActNet-18 [
13] as a student network model. ReActNet-18 is a binarized neural network model based on ResNet-18, and knowledge distillation is used during training. Therefore, other model compression methods such as binarization were included in the experiment to show the effectiveness with our proposed method.
In all experiments, the dimension of noise input to generator was 1000, the batch size of syntheic images made from generator was 1024, and the number of training iterations through syntheic image was 120. The generator neural network model was the same as the model used in [
17,
31]. Adam optimizer [
32] was used for generator network model training, and the initial learning rate was 1e-2, without additional learning rate scheduler. The same pre-trained ResNet-34 model was used for two different student network models.
For ResNet-18 student network model training, 200 epoch training was performed, and the mini batch size for the real image dataset was 128. Stochastic Gradient Descent (SGD) optimizer [
33] was used, with Nesterov momentum of 0.9 and weight decay of
. The initial learning rate was
, and the learning rate was reduced by 10 times at 80 epochs and 120 epochs, respectively.
For ReActNet-18 training, we referred to the training settings of [
13] and trained with two-step training strategy. In the first step, only activations of the neural network model are binarized, and in the second step, fine-tuning is performed based on the model parameter learned in the first step, and not only activations but also weights are binarized. In each step, the student network model was trained 256 epochs, and the mini-batch size for the real image dataset was 128. Adam optimizer was used and weight decay was
at first stage and 0 at second stage. The initial learning rate was
, and the learning rate was linearly reduced from the initial value to 0.
4.2. Experiment Results
In
Table 1 and
Table 2, dataset indicates the dataset used for the experiments, baseline means the training of the student network model without using knowledge distillation method. And KD refers to the method of training only by knowledge distillation method without using the proposed method. The hyperparameter settings of baseline and KD for ResNet-18 model and ReActNet-18 are the same as that used in the proposed method. All the values in the table are mean and standard deviation values of three repeated experiments of each case. More specifically, each values in the table are indicating
. In all cases, ResNet-34 was used as the teacher network model. ResNet-34 model was pretrained on each dataset and the accuracy was 95.54% on CIFAR-10 dataset and 77.62% on CIFAR-100 dataset. The time required for training with the proposed method in our experimental settings was about 108 s per epoch for the ResNet-18 model and about 129 s per epoch for the ReActNet-18 model.
As shown in
Table 1, with the CIFAR-10 dataset, the ResNet-18 model was improved by 0.17% compared to general response-based knowledge distillation training. Also, it was improved by 0.32% compared to the baseline. With the CIFAR-100 dataset, the ResNet-18 model was improved by 0.57% compared to the general KD method, and was improved by 1.08% compared to the baseline method.
In the case of ReActNet-18 model, as shown in
Table 2, with the CIFAR-10 dataset, the ReActNet-18 model was improved by 0.91% compared to the KD method, and was improved by 1.20% compared to the baseline method. With the CIFAR-100 dataset, the ReActNet-18 model was improved 3.06% compared to the general KD method, and was improved by 3.40% compared to the baseline method.
The results show that the performance in all cases improved when using our proposed method compared to baseline and general knowledge distillation method. And the proposed method was more effectively improved the performance of the student network model when the number of images per class is small, such as CIFAR-100. ResNet-18 model even outperformed the teacher network with the proposed method and exceeded 0.68% on the CIFAR-100 dataset. This means that the performance degradation of knowledge distillation training caused by the lack of dataset can be recovered through our proposed method.
More interestingly, the performance improvement of our proposed method was significant even when used with other model compression method. While neural network binarization has a high compression effect, it suffers from serious performance degradation. By leveraging our proposed knowledge distillation training strategy, performance degradation caused by parameter binarization can be recovered significantly.
We also conducted experiment to compare our proposed method with other related method. In [
15], fake images synthesized from generator was augmented to the training dataset. It suggested to mix the real image dataset and fake images with certain ratio
. Generator network and discriminator network was optimized with additional training process by using real image dataset. In the
Table 3,
Teacher refers to the performance of WideResNet-28-10 which is used for teacher network on each method. And
Student refers to the performance of student network trained by each method. Since the performance values of teacher network in the two methods are different, new metric called
Restored ratio is introduced.
Restored ratio indicates the percentage of student network accuracy to teacher network accuracy. It is calculated by dividing the student accuracy with teacher accuracy of each method.
As shown in
Table 3,
Restored ratio of our proposed method was better than that of GAN-TSC in [
15]. Our proposed method leverages knowledge of teacher network model which contains information related to the images that teacher network was trained and teacher network itself. Therefore, student network model trained with our method was better mimic the teacher network. Furthermore, our method does not require additional process of training discriminator network. Therefore, our proposed method successfully improved the performance of the related knowledge distillation method using GANs architecture.
Since the proposed method is closely related to Data-Free Learning (DAFL) [
17], we compare the performance between the proposed method and the DAFL method using the Restored ratio metric. As shown in
Table 4, the
Restored ratio of our method was better than the DAFL method because the proposed method is using not only the synthesized images from the generator but also the real training dataset. This implies that synthesized images generated by the proposed method are compatible with the real training dataset for knowledge distillation training.
4.3. Ablation Study
In this section, we conduct massive ablation study related to various loss functions that we used for training the generator network. The ablation study is conducted on our proposed knowledge distillation training strategy with CIFAR-100 dataset and ResNet-18 model. 200 epochs training was performed with the mini batch size of 256 for the real image dataset. The initial learning rate was , and the learning rate was decreased by 10 times at 80 epochs and 120 epochs. Stochastic Gradient Descent optimizer was used, with Nesterov momentum of 0.9 and weight decay of . Other experimental settings are equivalent to preceding experiment of our proposed method except generator loss functions. Every possible combinations of the generator loss functions are tested. The ablation study was repeated three times for each combinations and test accuracy of each combinations are reported with its mean value.
As shown in
Table 5, some combinations of the generator loss functions are not suitable for our proposed knowledge distillation training strategy. When the information entropy loss functions are not included, the student network model was not trained except for the case which only the BNS loss function was included. It shows that maintaining the class balance of the synthetic images plays an important role for training the student network with the proposed method. Interestingly, when the BNS loss function is used only, it was possible to train the student network, even though the information entropy loss function was not included. It implies that BNS also inhere the knowledge related to the class balance of the dataset which was used for training of corresponding batch normalization layers. Accordingly, the combination of the information entropy loss function and the BNS loss function showed the third good performance which achieves 77.41%. When the one-hot loss function is included to this combination, it becomes the second good performance case which achieves 77.45%. Finally, when all of the loss functions that we suggested are used, the performance of the student model achieves 77.68% which is the best among the combinations.
Ablation study experiments we conducted suggest that each of the generator loss functions are important for our proposed method. And the experiments also showed that the absence of a specific loss function made the student network completely untrained.
Also, further experiments were conducted to evaluate the effectiveness of the training epoch on the performance of the proposed method. The evaluation was conducted on both ResNet-18 model and ReActNet-18 model with CIFAR-100 dataset. The ResNet-18 model was trained for 100 epochs for the case of fewer epochs and 300 epochs for the case of more epochs. The ReActNet-18 model was trained for 128 epochs for the case of fewer epochs and 384 epochs for the case of more epochs.
As shown in
Table 6, for ResNet-18, increasing training epochs does not always improve accuracy level. The result after 200 epochs, which is the result of the proposed method, provides better results than after 300 epochs. However, for ReActNet-18 shown in
Table 7, the accuracy gain and number of training epochs show a positive correlation. This is an interesting result and worth further exploration.
5. Conclusions
To further improve the performance of knowledge distillation training, we proposed a generative image processing based knowledge distillation training strategy that leverages the inherent knowledge of the pre-trained teacher network model. The generator network does not need to be pre-trained to synthesize the images by processing the random noise. It is simply trained while undergoing knowledge distillation training.
Experiments were conducted on widely used ResNet-18 models. In addition, experiments with ReActNet-18, an extremely quantized network that uses only 1-bit values for weight and activation parameters, were also performed to show the effectiveness of this method in conjunction with other model compression methods such as neural network binarization. The experiments showed that our proposed method significantly improved the performance of the knowledge distillation training.









{kind=link}
{kind=link}