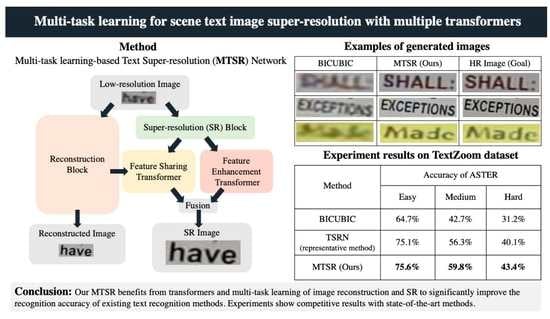
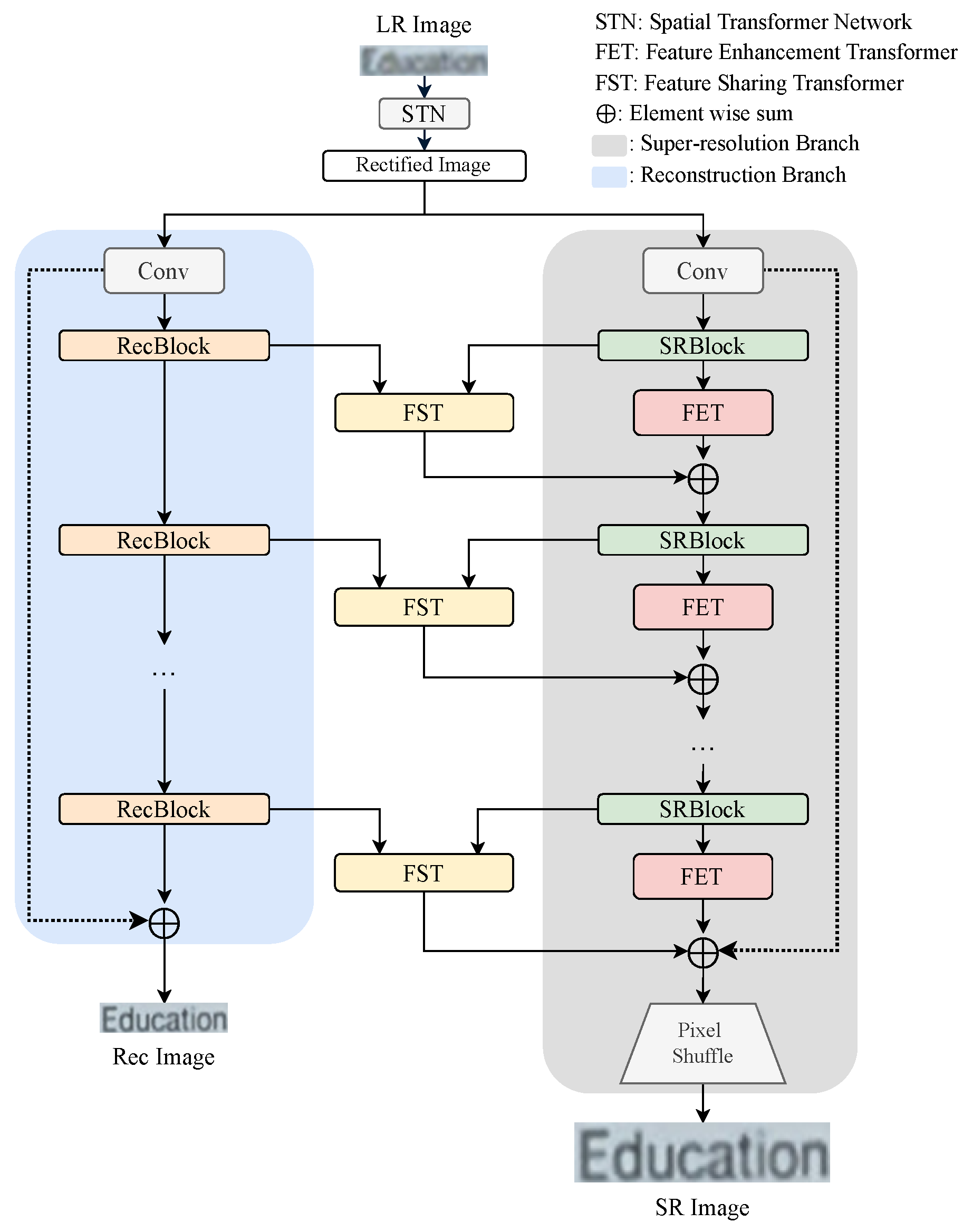
3.1. Overall Architecture
In this paper, we propose the MTSR network for STISR that MTL architecture of SR and reconstruction. The overall architecture of our MTSR is shown in
Figure 2. The input image is
(
h and
w are the height and width) shape concatenated with an RGB image and a binary mask following [
12]. MTSR consists of an image reconstruction branch and an SR branch in parallel, each processing LR text images rectified by the Spatial Transformer Network (STN) [
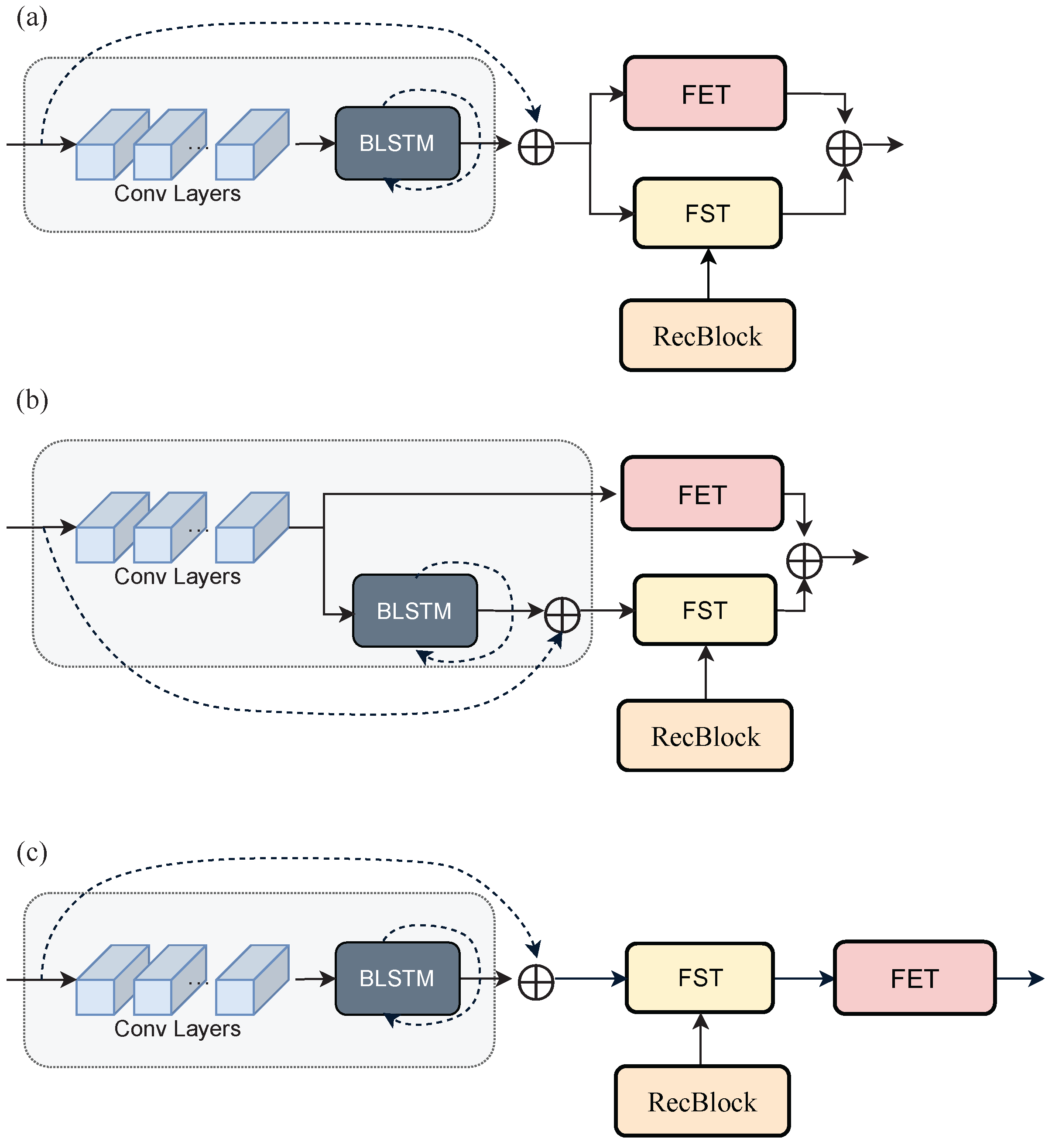
26]. First, a shallow feature map is extracted by
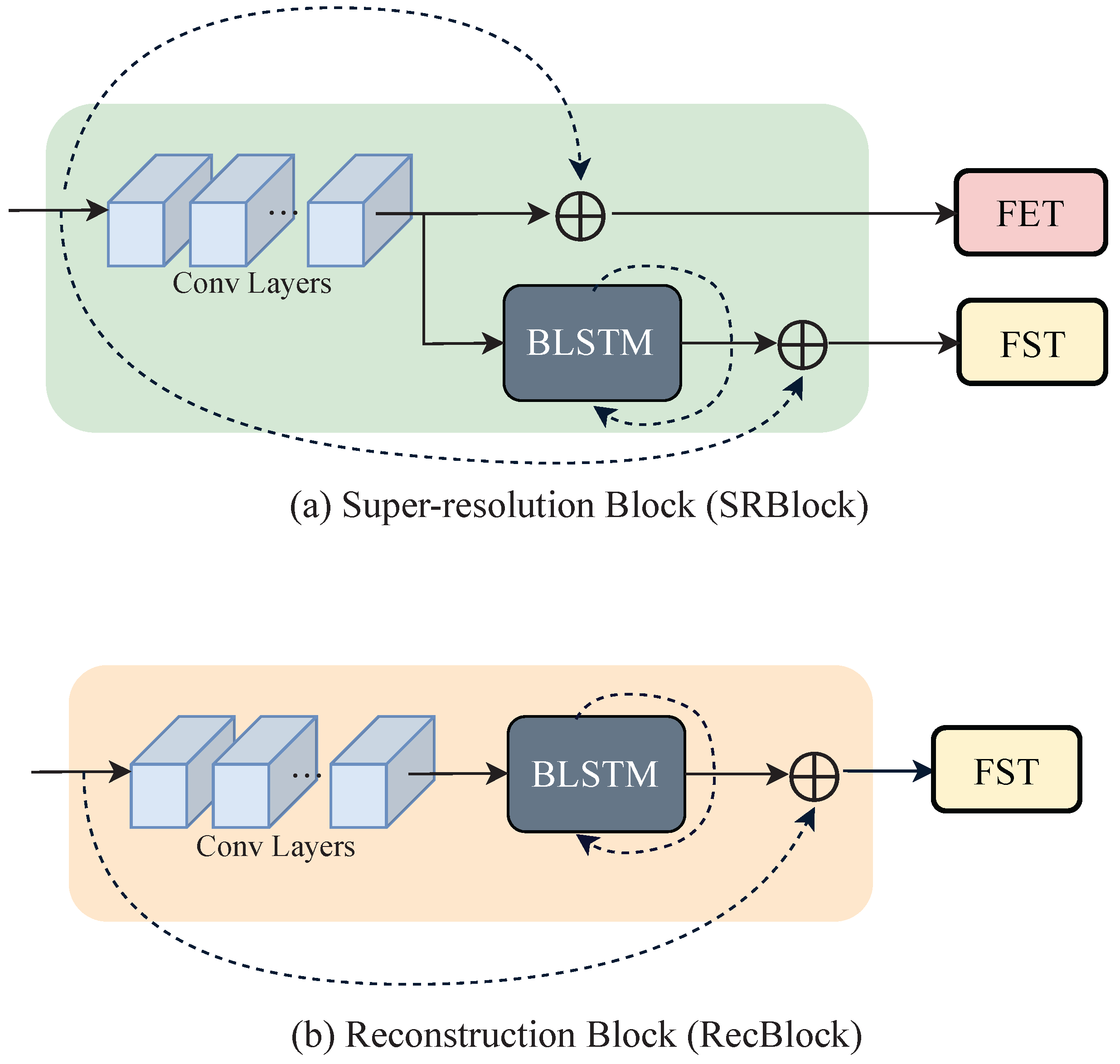
convolution in each branch, and then features are extracted by SRBlock and Reconstruction Block (RecBlock) based on EDSR [
29] consisting of CNNs and BLSTM [
16], shown in
Figure 3. More details of SRBlock are introduced in
Appendix A. The extracted features from the reconstruction branch are sent as a key and value to the FST module for sharing/transferring the complementary characteristics of the reconstruction branch to the SR branch. On the other hand, the features extracted in the SR branch are sent to two modules, the FET, which enhances the feature using MHA and adaptive 2D positional encoding, and FST. The feature maps generated from the two transformer modules are fused and output as the final feature map. The model is trained to minimize the loss function between the images generated from each branch and the target images. Here, the target image for the SR branch is a pre-prepared HR image in TextZoom [
12], and the target image for the reconstruction branch is a high-quality small image downsampled from the HR image.
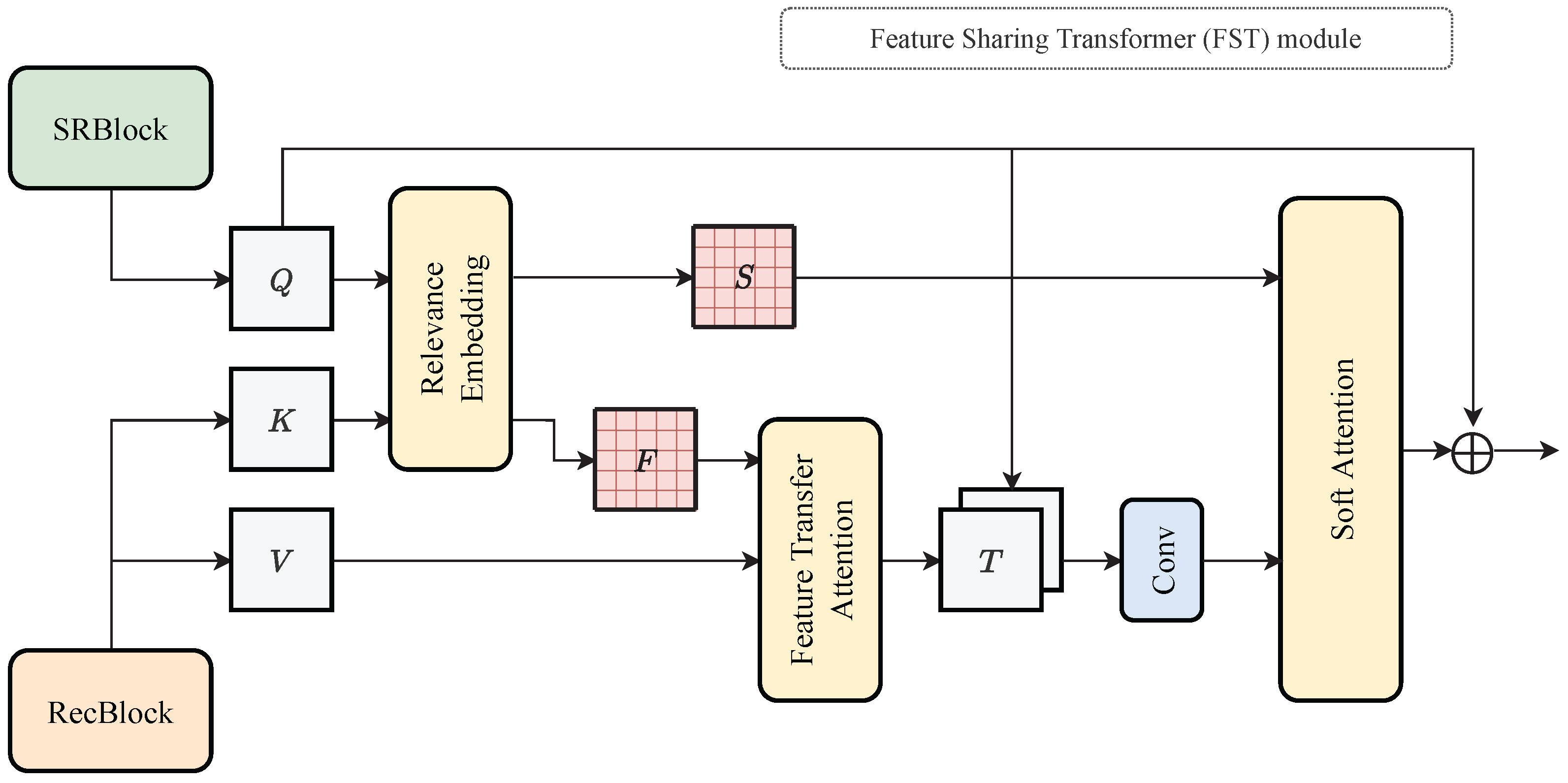
3.2. Feature Sharing Transformer (FST) for MTL
The reconstruction branch aims to remove noise from LR text images and generate visually high-quality images without up-sampling. The image reconstruction task is very close to SR in computer vision. However, it tends to be superior in removing noise and capturing structural features of objects because they clean the image without up-sampling. To exploit these characteristics for text reconstruction, we adopt the MTL architecture of SR and image reconstruction, and the features extracted reconstruction branch are shared/transmitted through the FST module to the SR branch. The architecture of the FST module is inspired by the transformer [
22,
30], which shares/transfers features between different inputs or tasks. The overall diagram of the FST module is shown in
Figure 4. Here, feature maps extracted from RecBlock are treated as key (
K) and value (
V), and from SRBlock as query (
Q).
First, feature maps extracted from RecBlock as key (
K) and value (
V) and from SRBlock as query (
Q) are sent to the FST module, respectively. Then, for each patch
and
of
Q and
K, the relevance
between these two patches is calculated with the normalized inner product as shown in Equation (
1):
Next, Feature Transfer Attention is calculated using this
to transfer the structural features of the text image. In order to transfer the feature with the most relevant position in
V for each query
, we generate an index map
F that represents the most relevant position of
Q and
K. The definition is shown in the following Equation (
2):
where
h and
w are the height and width of the input, and
is the index representing the
i-th element of the feature map from the SRBlock and the most relevant position of the feature map from the RecBlock. Then, the feature
T transferred from the feature map of the RecBlock is obtained using
as the index and applying the index selection operation to
V. Here, the Feature Transfer Attention map
T contains the structural features of the text image and is denoised.
Finally, Soft Attention is calculated to synthesize the features from
Q and Feature Transfer Attention map
T. In order to transfer relevant features, a soft attention map
S is calculated from
to estimate the confidence of the transferred texture features for each position of
T as shown in Equation (
3):
where
is the
i-th position of the Soft Attention map
S. Then, the feature map concatenating
T and
Q and the Soft Attention map
S are multiplied element by element and output as the final feature map
. The definition is shown in the following Equation (
4):
Here, ⊗ is the element-wise multiplication, and ⊕ is the element-wise summation.
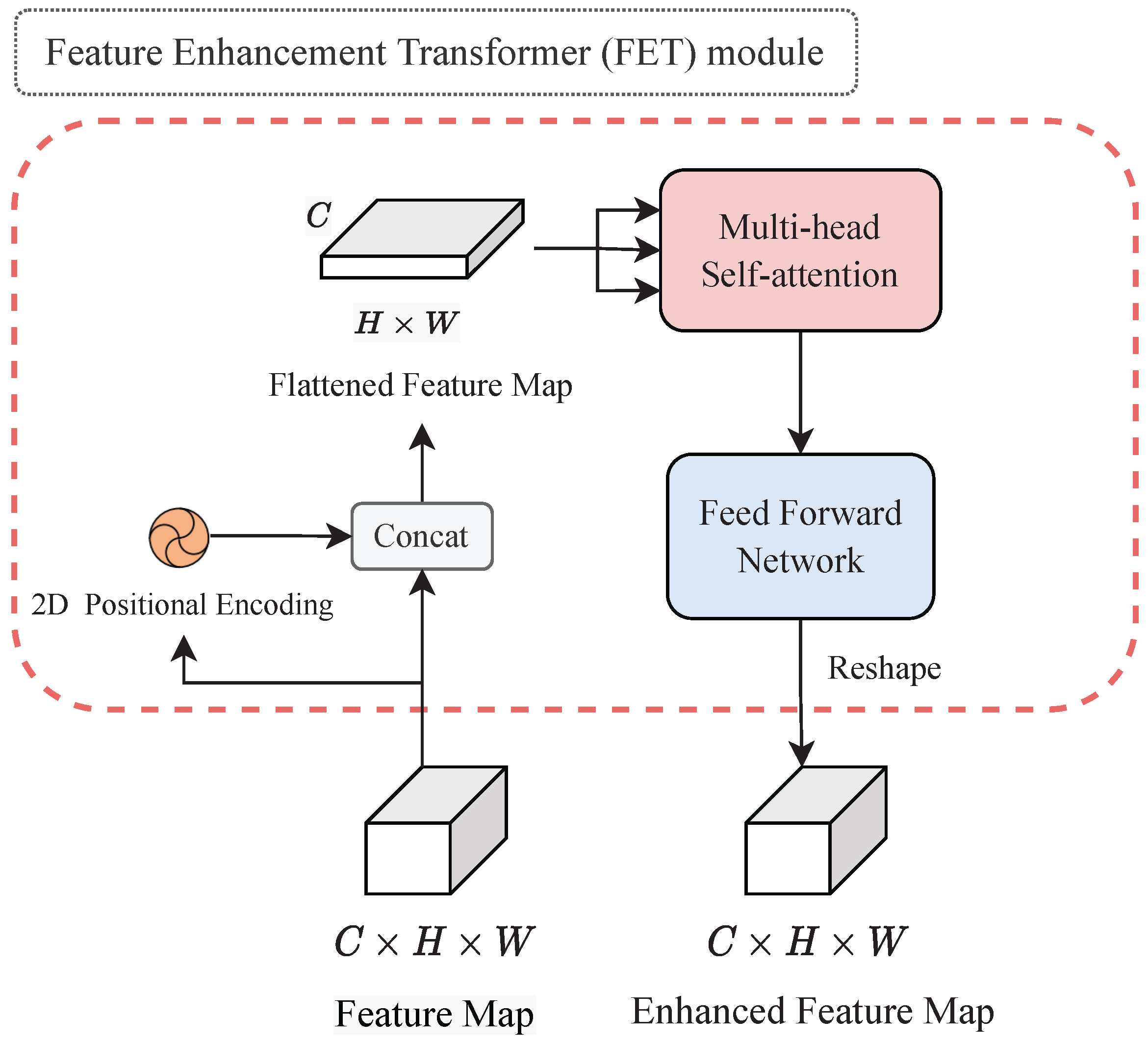
3.3. Feature Enhancement Transformer (FET)
FET is a transformer designed to capture sequential information for arbitrary directions in text images tilted or curved using 2D positional encoding. BLSTM [
16], which has been used to capture sequential information in our previous work [
31] and TSRN [
12], is effective for horizontal and vertical sequential information but is insufficient for text images of real scenes with various shapes and orientations. Therefore, inspired by the results of studies [
15,
27,
28] on the text image using 2D attention and recent achievements of the transformer in computer vision [
32,
33,
34], we attempt to use a transformer for a feature enhancement to capture sequential information in arbitrary orientations.
The attention mechanism in typical transformers used for natural language processing and time series data processing cannot recognize spatial location information or context because the input is processed in parallel in one dimension. Thus, positional encoding for 2D orientation considers spatial positional information to enable the transformer for text images. Furthermore, we propose two transformers, one using 2D APE and the other using 2D RPE, and compare them in an ablation study.
3.3.1. 2D Absolute Positional Encoding (APE)
Unlike sequence data, text in images appears in various orders. In particular, text in real scenes often appears not only horizontally and vertically but also tilted or curved. Therefore, based on the feature maps, positional encoding is adaptively determined for the vertical and horizontal directions. For an index
p to the vertical and horizontal position of the input feature map, its positional encoding is defined as in Equations (5) and (6):
where
is the
-th element in each axis
p of the positional encoding and
D is the number of dimensions in the depth direction. This is calculated for each of the vertical and horizontal directions. These positional encodings and feature maps are concatenated and flattened into a one-dimensional sequence, which is then input to the attention layer. Thus, the input
X in FET using APE is defined as in Equation (
7):
where
is the vertical positional coding and
is the horizontal positional coding. The architecture of the FET with 2D APE is shown in
Figure 5.
In FET with 2D APE, for
n elements of input
, the output
of self-attention is computed as a weighted sum of the input elements, as in the general transformer, as shown in Equation (
8):
where the projection
is a parameter matrix and
is each weight coefficient.
is calculated using softmax and defined by Equation (
9):
where
is the value calculated using scaled dot-product attention. It is defined in Equation (
10):
Here, the projections
and
are parameter matrices and are unique for each layer.
is the number of dimensions of
z. In MHA, self-attention is calculated multiple times in parallel and then concatenated to produce the output. The output attention map is then sent to the Feed-Forward Network and finally reshaped to the same size as the input feature map.
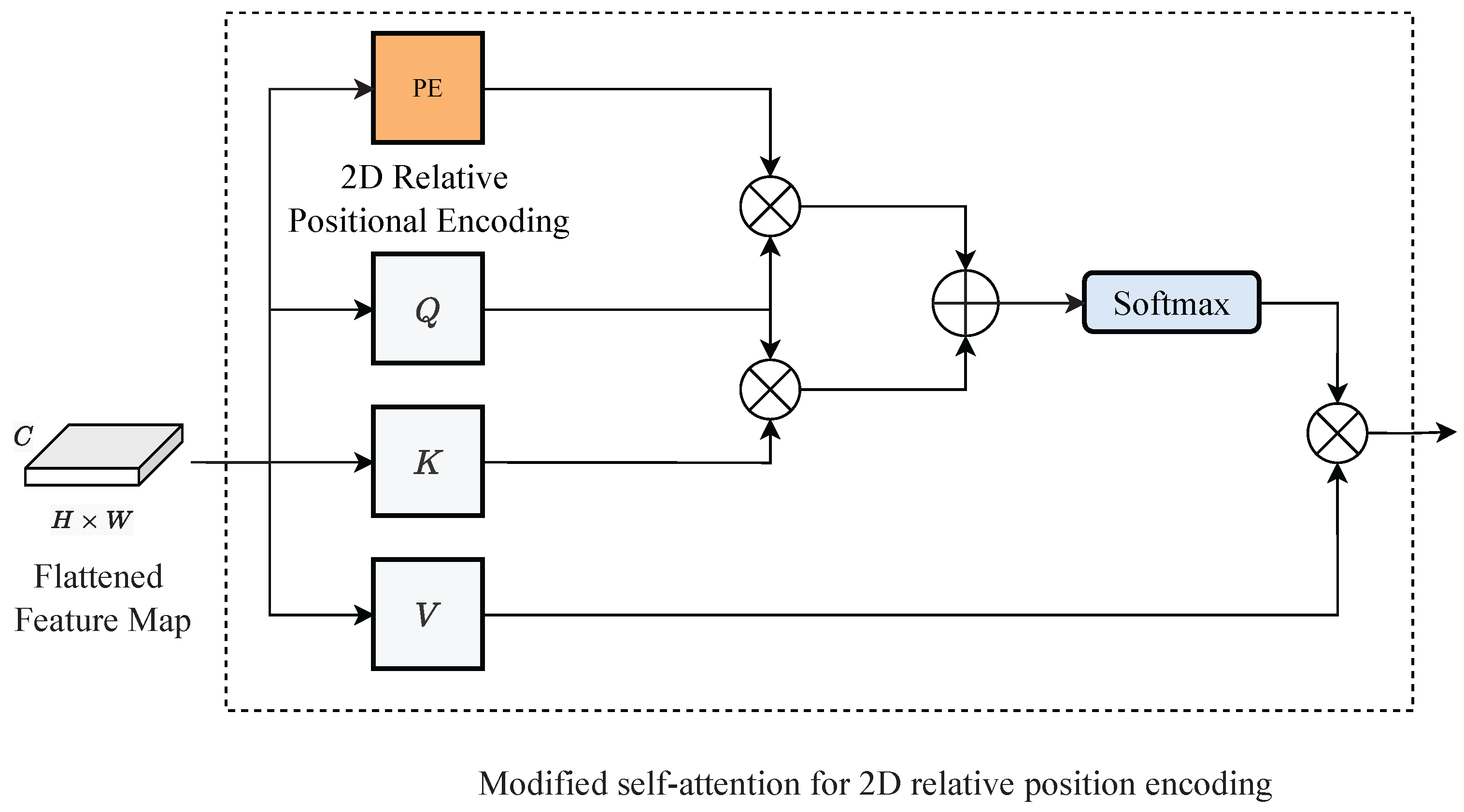
3.3.2. 2D Relative Positional Encoding (RPE)
In recent studies [
33,
34], approaches that consider the relative position between each input element in the transformer have been proposed. Information such as the relative sequence and distance between elements is essential for tasks involving images. Following the RPE designed for images [
33], we use a contextual RPE for text images in our FET to validate the effectiveness of the RPE. In RPE, encoding vectors are embedded in a self-attention module, and the relative positions between elements are trained during training for the transformer. The positional encoding vector
in 2D RPE is defined for Equation (
11):
where
is a trainable vector that denotes the relative positional weights between each position
i and
j of the input and interacts with the query embedding. In order to incorporate the encoding vector into the self-attention module, Equations (8) and (10) are reformulated as in Equations (12) and (13).
Following [
33], the
is weighted by the Euclidean method based on the Euclidean distance between the elements and the Cross method, which considers the pixel position direction. These details are introduced in
Appendix B. A self-attention module based on 2D RPE is shown in
Figure 6. As in the case of using APE, the self-attention module is processed multiple times in parallel as the MHA, and then the output attention map is sent to the Feed-Forward Network.
3.4. Loss Function
In our MTSR, we attempt to optimize the model by minimizing the loss function for each SR and reconstruction branch, respectively. Following TSRN [
12], we employed a combination of Gradient Profile Prior (GPP) [
35] loss and L2 loss as the base loss function for each branch. The GPP loss
is defined as in Equation (
14):
where
is the ground truth image,
I is the generated image, and ∇ is the gradient fields. Then,
and
, which are the loss functions for each branch, are defined as the sum of GPP loss and L2 loss, respectively. The final overall loss function
L is defined as in Equation (
15):
Here,
and
are arbitrary values and hyperparameters. The sum of
and
is set to a maximum value of
.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







