


Artificial Intelligence Model for the Identification of the Personality of Twitter Users through the Analysis of Their Behavior in the Social Network
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Development Tools
2.2. Machine Learning
- Supervised learning;
- Unsupervised learning;
- Reinforced learning;
- Semi-supervised learning;
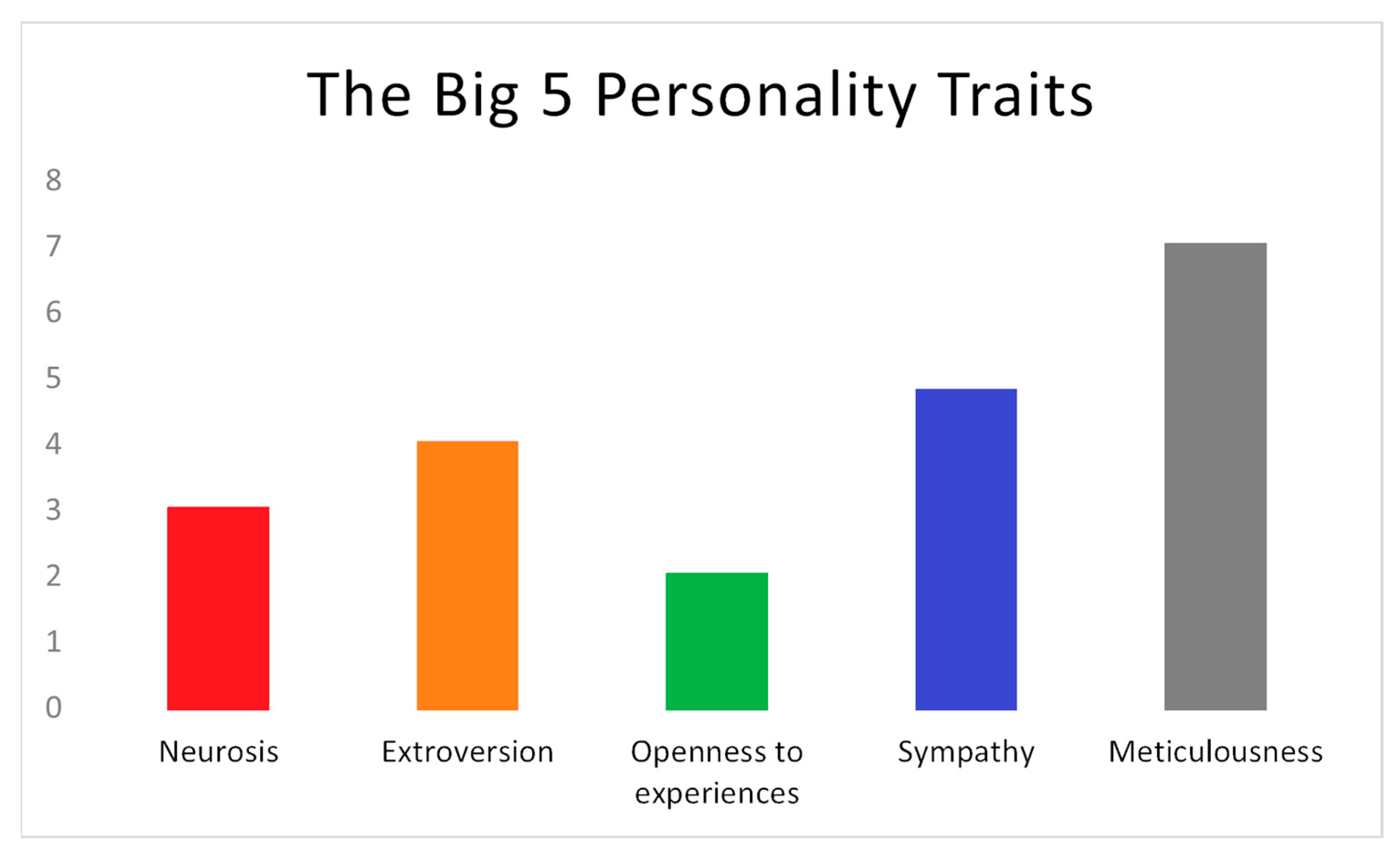
2.3. The Big Five Personality Traits
- Openness to experiences: people with this personality tend to seek new personal experiences and prefer to break the routine. These types of people are more creative and know different topics thanks to their intellectual curiosity.
- Meticulousness: in this case, this type of person usually has self-control, they have a great ability to plan and organize. In addition, they tend to be introverted and develop a behavior of perfectionism or obsession, usually requiring a balance to avoid reaching these extremes.
- Extraversion: the subject with this personality is open with others and is focused on social environments. These people have a better type of communication with large groups of people and tend to relate more personally than on social networks.
- Kindness: people in this category rely on honesty and are willing to lend help to people in need, and tend to be respectful, tolerant, and calm people.
- Neurosis or emotional instability: those who have this personality have unpredictable behavior, are reactive people in intense situations, and tend to have negative thoughts.
2.4. Method Design
- Population identification and data collection;
- Data preprocessing;
- Sentiment analysis;
- Training and evaluation of the AI model;
- Implementation of the model in a real environment.
2.4.1. Population Identification and Data Collection
- The number of followers;
- The number of people you follow;
- The total number of tweets;
- Twitter ID of the user;
- Retweets;
- Total retweets;
- The number of user mentions;
- Tweets where the user is mentioned;
- A total number of tweets the user has liked;
- Tweets that the user has liked;
- Tweets are written by the user.
2.4.2. Data Preprocessing
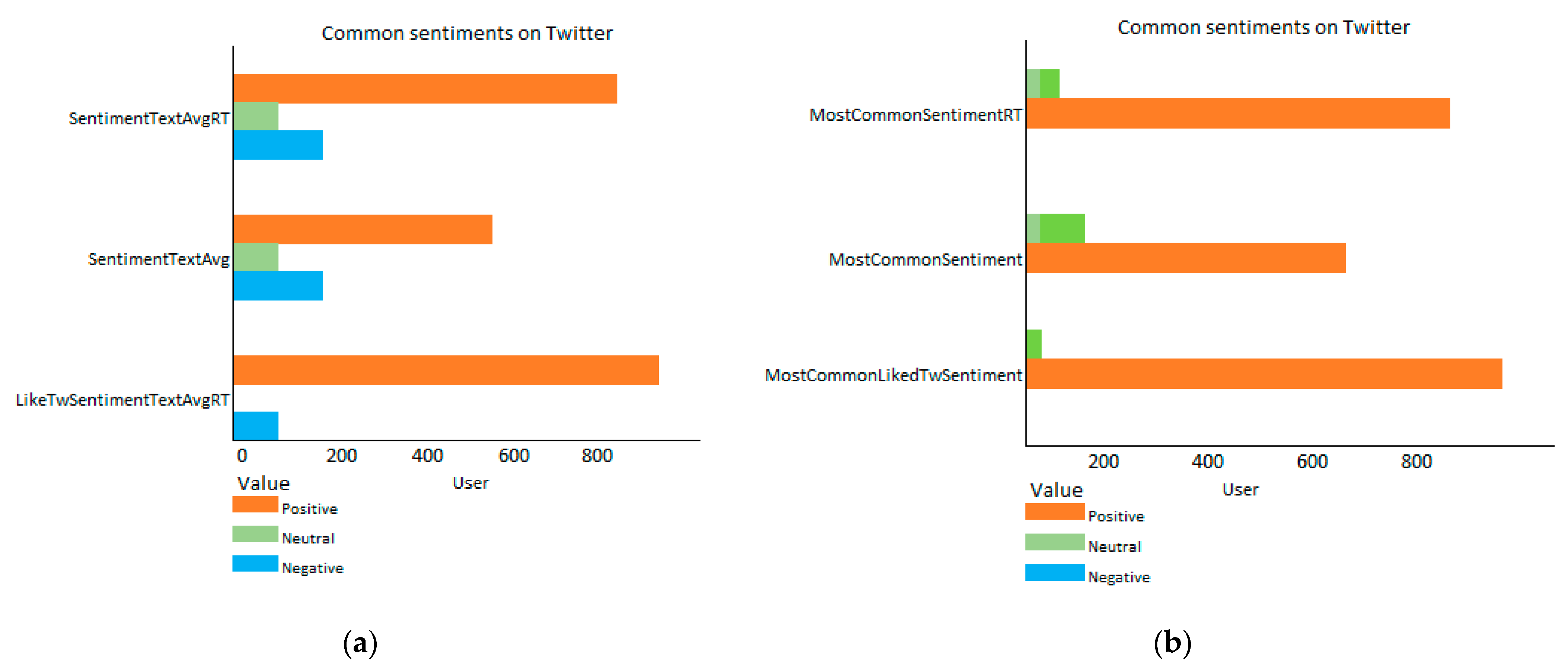
2.4.3. Sentiment Analysis
- result = analyze_lexicon (“I hate the life I hate my family”)
- for k,v in result.items ( ):
- if v >= 0.25:
- print (f”{k}:{v}”)
- Resulted:
- hate = 0.25;
- envy = 0.25;
- nagtive_emotion = 0.25;
- result = analyze_lexicon (“I hate the life I hate my family”)
- for k,v in result.items( ):
- if v >= 0.25:
- print (f”{k}:{round (v,3)}”)
- Resulted:
- school = 0.333;
- love = 0.333;
- science= 0.333;
- reading = 0.333;
- positive_emotion = 0.333;
2.4.4. Training and Evaluation of the AI Model
- It is an algorithm of easy use and understanding of results;
- It adjusts to large data sets since it can generate as many decision trees as necessary;
- It tends to handle data overfitting through the random generation of trees based on the training set;
- This algorithm tends to generate better accuracy in its predictions compared to decision trees or other similar algorithms.
- Class_weight;
- Criterion;
- Max-depth;
- Max_features;
- Max_leaf_node;
- N_estimators;
- Max-samples, etc.
- Parameters = {“criterion”: (“gini”, “entropy”);
- “n_estimators”: (10, 20, 30);
- “max_samples”: (1/3, 2/3)}.
- Estimators or decision trees = 100;
- Maximum number of nodes = 100.
- Number of followers;
- Number of followed;
- Total, user tweets;
- Total number of tweets that the user has liked;
- Average sentiment polarity of the user’s original tweets;
- Average sentiment polarity of user retweets;
- The average polarity of the sentiment of the tweets that the user has liked.
- P(X|c) =probability document X in class c;
- Nc = total documents in class c;
- N = total documents;
- t1 = weight term t;
- ∝ = smoothing parameter.
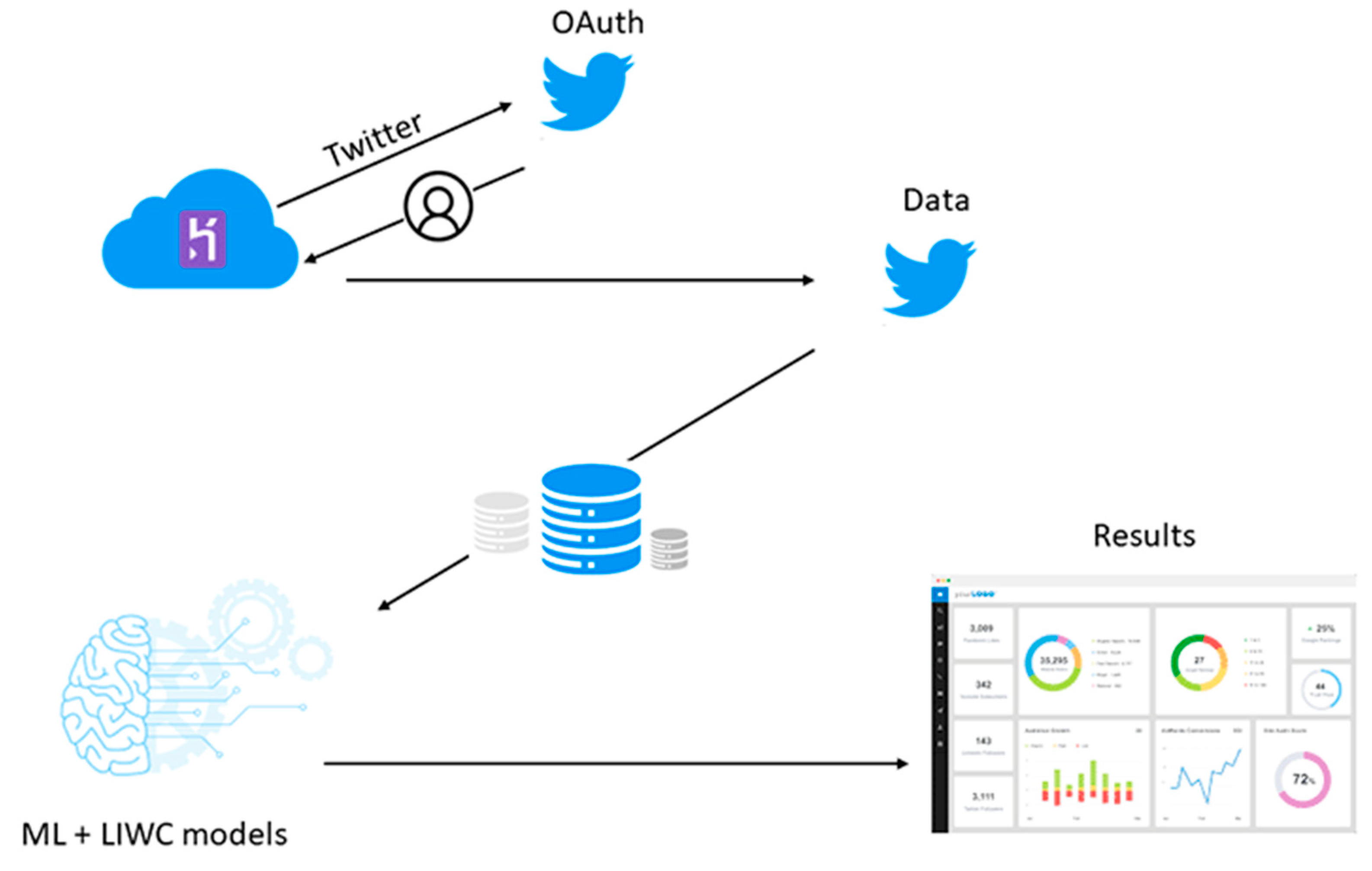
2.4.5. Implementation of the Model in a Real Environment
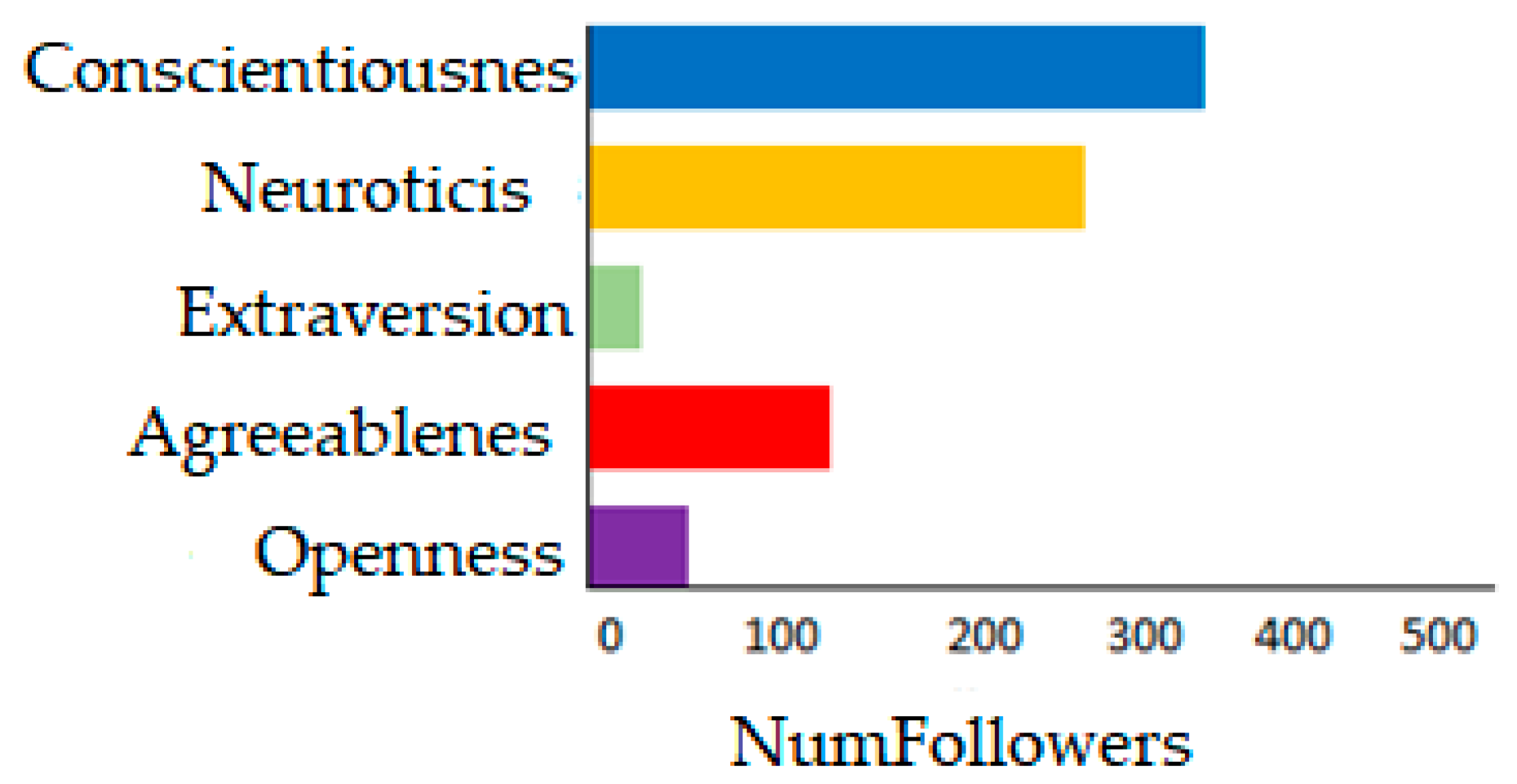
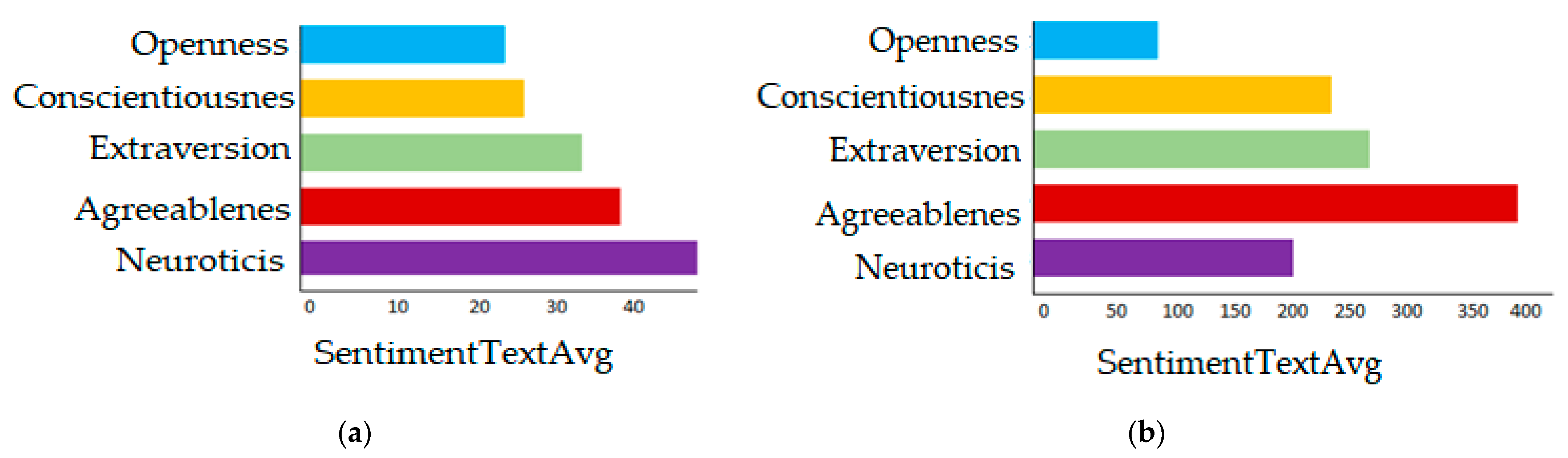
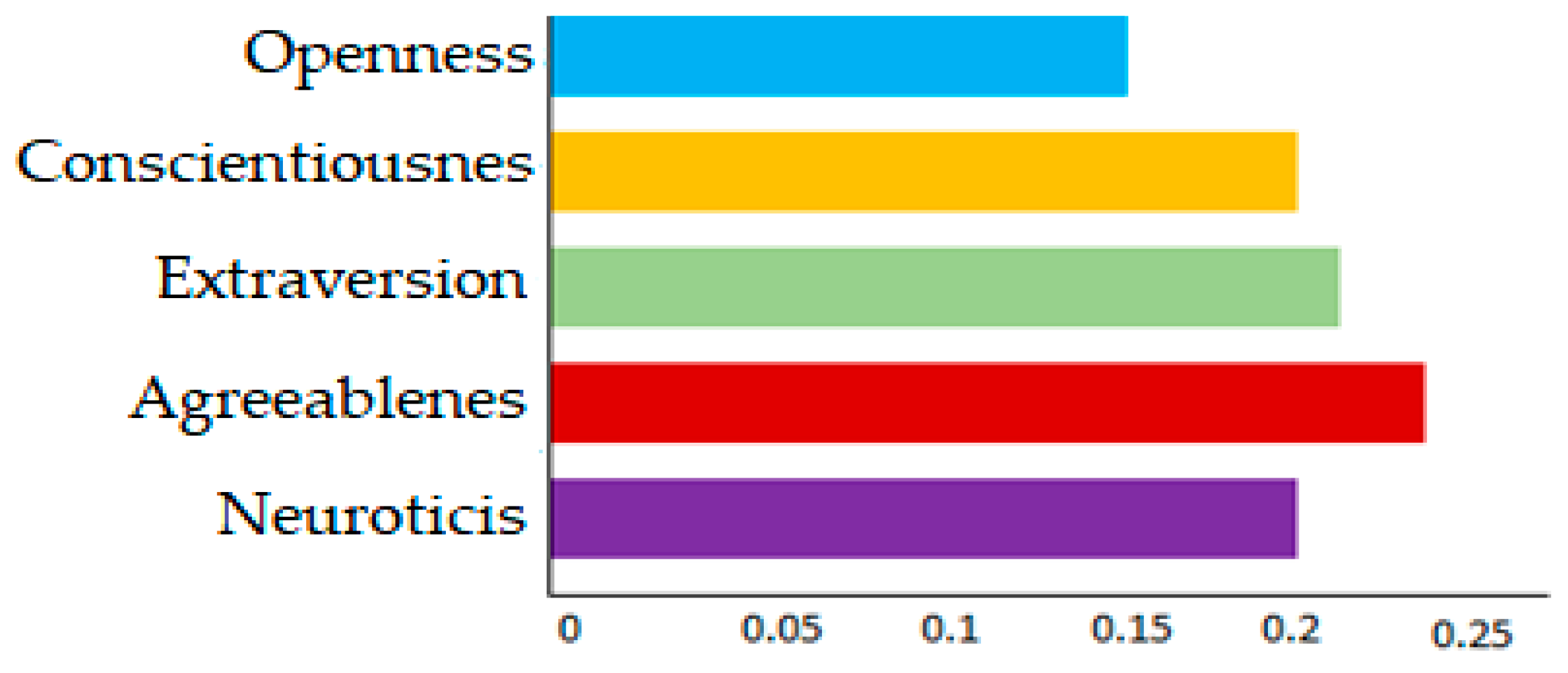
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bullini Orlandi, L.; Zardini, A.; Rossignoli, C.; Ricciardi, F. To Do or Not to Do? Technological and Social Factors Affecting Vaccine Coverage. Technol. Forecast. Soc. Chang. 2022, 174, 121283. [Google Scholar] [CrossRef]
- Tankovska, H. Global social network penetration rate as of January 2022, by region. In Social Media—Statistics & Facts; EEUU: New York, NY, USA, 2019. [Google Scholar]
- Social Media Statistics. 2018. Available online: Statista.com (accessed on 23 June 2022).
- Zhu, Q. Citizen-Driven International Networks and Globalization of Social Movements on Twitter. Soc. Sci. Comput. Rev. 2017, 35, 68–83. [Google Scholar] [CrossRef]
- Li, Z.; Huang, X.; Ye, X.; Jiang, Y.; Martin, Y.; Ning, H.; Hodgson, M.E.; Li, X. Measuring Global Multi-Scale Place Connectivity Using Geotagged Social Media Data. Sci. Rep. 2021, 11, 14694. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Huang, X.; Ye, X.; Jiang, Y.; Yago, M.; Ning, H.; Hodgson, M.E.; Li, X. Measuring Place Connectivity Using Big Social Media Data. arXiv 2021, arXiv:2102.03991v1. [Google Scholar]
- Choi, H.; Kim, S.H.; Lee, J. Role of Network Structure and Network Effects in Diffusion of Innovations. Ind. Mark. Manag. 2010, 39, 170–177. [Google Scholar] [CrossRef]
- Zaidi, F.; Sallaberry, A.; Melançon, G. Generating Artificial Social Networks with Small World and Scale Free Properties. Hal-00659971 2012, 7861, 34. [Google Scholar]
- Zerubavel, N.; Bearman, P.S.; Weber, J.; Ochsner, K.N. Neural Mechanisms Tracking Popularity in Real-World Social Networks. Proc. Natl. Acad. Sci. USA 2015, 112, 15072–15077. [Google Scholar] [CrossRef] [Green Version]
- Lloyd, P.; Mahutga, M.C.; de Leeuw, J. Looking Back and Forging Ahead: Thirty Years of Social Network Research on the World-System. J. World Syst. Res. 2009, 15, 48–85. [Google Scholar] [CrossRef] [Green Version]
- Indu, V.; Thampi, S.M. A Systematic Review on the Influence of User Personality in Rumor and Misinformation Propagation Through Social Networks. In Communications in Computer and Information Science; Springer: Singapore, 2021. [Google Scholar] [CrossRef]
- Golbeck, J.; Robles, C.; Turner, K. Predicting Personality with Social Media. In Proceedings of the Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 253–262. [Google Scholar]
- González-Varona, J.M.; López-Paredes, A.; Poza, D.; Acebes, F. Building and Development of an Organizational Competence for Digital Transformation in SMEs. J. Ind. Eng. Manag. 2021, 14, 15–24. [Google Scholar] [CrossRef]
- Shahi, C.; Sinha, M. Digital Transformation: Challenges Faced by Organizations and Their Potential Solutions. Int. J. Innov. Sci. 2021, 13. [Google Scholar] [CrossRef]
- Bazkiaei, H.A.; Heng, L.H.; Khan, N.U.; Saufi, R.B.A.; Kasim, R.S.R. Do Entrepreneurial Education and Big-Five Personality Traits Predict Entrepreneurial Intention among Universities Students? Cogent Bus. Manag. 2020, 7, 1801217. [Google Scholar] [CrossRef]
- Kouadri, W.M.; Ouziri, M.; Benbernou, S.; Echihabi, K.; Palpanas, T.; Amor, I. ben Quality of Sentiment Analysis Tools: The Reasons of Inconsistency. Proc. VLDB Endow. 2020, 14, 668–681. [Google Scholar] [CrossRef]
- Hirschberg, J.; Manning, C.D. Advances in Natural Language Processing. Science 2015, 349, 221–266. [Google Scholar] [CrossRef]
- Patel, R.; Patel, S. Deep Learning for Natural Language Processing. In Proceedings of the Lecture Notes in Networks and Systems, Rabat, Morocco, 17–18 March 2021; Volume 190. [Google Scholar]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Trans Neural Netw. Learn. Syst. 2021, 32, 604–624. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baloglu, O.; Latifi, S.Q.; Nazha, A. What Is Machine Learning? Arch. Dis. Child Educ. Pr. Ed. 2021, 107, 386–388. [Google Scholar] [CrossRef] [PubMed]
- Tiezzi, J.; Tyler, R.; Sharma, S. Lessons Learned: A Case Study in Creating a Data Pipeline Using Twitter’s API. In Proceedings of the 2020 Systems and Information Engineering Design Symposium, SIEDS, Charlottesville, VA, USA, 24 April 2020; pp. 1–6. [Google Scholar]
- Golbeck, J.; Robles, C.; Edmondson, M.; Turner, K. Predicting Personality from Twitter. In Proceedings of the 2011 IEEE International Conference on Privacy, Security, Risk and Trust and IEEE International Conference on Social Computing, PASSAT/SocialCom, Boston, MA, USA, 9–11 October 2011. [Google Scholar]
- Şahin, F.; Karadağ, H.; Tuncer, B. Big Five Personality Traits, Entrepreneurial Self-Efficacy and Entrepreneurial Intention: A Configurational Approach. Int. J. Entrep. Behav. Res. 2019, 25, 1188–1211. [Google Scholar] [CrossRef]
- Zimbra, D.; Abbasi, A.; Zeng, D.; Chen, H. The State-of-the-Art in Twitter Sentiment Analysis: A Review and Benchmark Evaluation. ACM Trans. Manag. Inf. Syst. 2018, 9, 5. [Google Scholar] [CrossRef]
- Carvalho, J.; Plastino, A. On the Evaluation and Combination of State-of-the-Art Features in Twitter Sentiment Analysis. Artif. Intell. Rev. 2021, 54, 1887–1936. [Google Scholar] [CrossRef]
- Sánchez-Holgado, P.; Martín-Merino Acera, M.; Blanco Herrero, D. Del Data-Driven al Data-Feeling: Análisis de Sentimiento En Tiempo Real de Mensajes En Español Sobre Divulgación Científica Usando Técnicas de Aprendizaje Automático. Anu. Electrónico De Estud. En Comun. Soc. “Disert.” 2020, 13, 35–58. [Google Scholar] [CrossRef]
- Sharma, S.; Jain, A. Hybrid Ensemble Learning with Feature Selection for Sentiment Classification in Social Media. Int. J. Inf. Retr. Res. 2020, 10, 1183–1203. [Google Scholar] [CrossRef]
- Hourrane, O.; Idrissi, N.; Benlahmar, E.H. Sentiment Classification on Movie Reviews and Twitter: An Experimental Study of Supervised Learning Models. In Proceedings of the ICSSD 2019—International Conference on Smart Systems and Data Science, Rabat, Morocco, 3–4 October 2019. [Google Scholar]
- Salsabila, G.D.; Setiawan, E.B. Semantic Approach for Big Five Personality Prediction on Twitter. J. RESTI (Rekayasa Sist. Dan Teknol. Inf.) 2021, 5, 680–687. [Google Scholar] [CrossRef]
- Zheng, X.; Schweickert, R. Comparing Hall Van de Castle Coding and Linguistic Inquiry and Word Count Using Canonical Correlation Analysis. Dreaming 2021, 31, 207–224. [Google Scholar] [CrossRef]
- McDonnell, M.; Owen, J.E.; Bantum, E.O.C. Identification of Emotional Expression with Cancer Survivors: Validation of Linguistic Inquiry and Word Count. JMIR Res. 2020, 4, e18246. [Google Scholar] [CrossRef] [PubMed]
- Long, Y.; Xiang, R.; Lu, Q.; Huang, C.R.; Li, M. Improving Attention Model Based on Cognition Grounded Data for Sentiment Analysis. IEEE Trans. Affect. Comput. 2021, 12, 900–912. [Google Scholar] [CrossRef]
- Sravya, K.; Sowmya, G.; Yamini, P.; Anusha, P.; Sandhya Krishna, P. Sentiment Analysis on Twitter K. SSRN Electron. J. 2021, XIII, 925–930. [Google Scholar] [CrossRef]
- Adwan, O.Y.; Al-Tawil, M.; Huneiti, A.M.; Shahin, R.A.; Abu Zayed, A.A.; Al-Dibsi, R.H. Twitter Sentiment Analysis Approaches: A Survey. Int. J. Emerg. Technol. Learn. 2020, 15, 79–93. [Google Scholar] [CrossRef]
- Xue, Y.; Wang, Y. Artificial Intelligence for Education and Teaching. Wirel. Commun. Mob. Comput. 2022, 2022, 4750018. [Google Scholar] [CrossRef]
- Cumming, G. Artificial Intelligence in Education: An Exploration. J. Comput. Assist. Learn. 1998, 14, 251–259. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Buenaño-Fernández, D.; Luján-Mora, S. Educational Data Analysis Applying a Kdd Methodology. In Proceedings of the 16th International Conference e-Society, Lisbon, Portugal, 14–16 April 2018; pp. 301–305. [Google Scholar]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. The KDD Process for Extracting Useful Knowledge from Volumes of Data. Commun. ACM 1996, 39, 27–34. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, Z.X.; Yang, B. Personality Analysis and Prediction of Social Network Users. Jisuanji Xuebao/Chin. J. Comput. 2014, 37. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Palacios-Pacheco, X. Proposal for a Secure Architecture for the Internet of Things on a Smart Campus. In Advances in Intelligent Systems and Computing; Springer: Quito, Ecuador, 2021; Volume 1277, pp. 269–280. [Google Scholar]
- Villegas-Ch., W.; Palacios-Pacheco, X.; Ortiz-Garcés, I.; Luján-Mora, S. Management of Educative Data in University Students with the Use of Big Data Techniques. RISTI Rev. Iber. Sist. E Tecnol. Inf. 2019, 2019, 227–238. [Google Scholar]
- Villegas-Ch, W.; Palacios-Pacheco, X.; Roman-Cañizares, M.; Luján-Mora, S. Analysis of Educational Data in the Current State of University Learning for the Transition to a Hybrid Education Model. Appl. Sci. 2021, 11, 2068. [Google Scholar] [CrossRef]
- Goeuriot, L.; Pasi, G.; Viviani, M.; Villegas-Ch, W.; Molina, S.; de Janón, V.; Montalvo, E.; Mera-Navarrete, A. Proposal of a Method for the Analysis of Sentiments in Social Networks with the Use of R. Informatics 2022, 9, 63. [Google Scholar] [CrossRef]
- Anand, N.; Kumar, M. Modeling and Optimization of Extraction- Transformation-Loading (ETL) Processes in Data Warehouse: An Overview. In Proceedings of the 2013 Fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013; pp. 1–5. [Google Scholar]
- Shetty, S.D. Sentiment Analysis, Tweet Analysis and Visualization on Big Data Using Apache Spark and Hadoop. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1099, 012002. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep Learning for Sentiment Analysis: A Survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef] [Green Version]
- Ligthart, A.; Catal, C.; Tekinerdogan, B. Systematic Reviews in Sentiment Analysis: A Tertiary Study. Artif. Intell. Rev. 2021, 54, 4997–5053. [Google Scholar] [CrossRef]
- Gandía, J.L.; Huguet, D. Textual Analysis and Sentiment Analysis in Accounting. Rev. Contab. Span. Account. Rev. 2021, 24, 168–183. [Google Scholar] [CrossRef]
- Kian, T.P.; Boon, G.H.; Fong, S.W.L.; Ai, Y.J. Factors That Influence the Consumer Purchase Intention in Social Media Websites. Int. J. Supply Chain Manag. 2017, 6, 214. [Google Scholar]
- Mlačić, B.; Goldberg, L.R. An Analysis of a Cross-Cultural Personality Inventory: The IPIP Big-Five Factor Markers in Croatia. J. Pers. Assess. 2007, 88, 168–177. [Google Scholar] [CrossRef]
- Wang, S.S. To Tweet or Not to Tweet: Factors Affecting the Intensity of Twitter Usage in Japan and the Online and Offline Sociocultural Norms. Int. J. Commun. 2016, 10, 24. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LIWC | NEU | EXT | OPN | AGR | CON |
|---|---|---|---|---|---|
| Total pronouns | 0.06 | 0.06 | −0.21 | 0.11 | −0.02 |
| First person sings | 0.12 | 0.01 | −0.16 | 0.05 | 0 |
| First person plural | −0.07 | 0.11 | −0.1 | 0.18 | 0.03 |
| First person | 0.1 | 0.03 | −0.19 | 0.08 | 0.02 |
| Second person | −0.15 | 0.16 | −0.12 | 0.08 | 0 |
| Third person | 0.02 | 0.04 | −0.06 | 0.08 | −0.08 |
| ACC | MNB | KNN | SVM |
|---|---|---|---|
| AGR | 60.45 ± 1.98 | 59.38 ± 1.54 | 62.75 ± 1.36 |
| CON | 59.86 ± 1.65 | 61.95 ± 1.75 | 61.74 ± 1.23 |
| EXT | 61.02 ± 1.21 | 63.51 ± 2.06 | 58.92 ± 1.81 |
| NEU | 58.48 ± 1.75 | 55.3 ± 1.42 | 60.12 ± 1.15 |
| OPN | 63.98 ± 1.94 | 65.71 ± 2.51 | 59.66 ± 1.61 |
| Third person | 60.75 ± 1.71 | 61.17 ± 1.85 | 60.63 ± 1.43 |
| Method | ACC |
|---|---|
| MNB | 61% |
| KNN | 59% |
| SVM | 60% |
| Combined | 63% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villegas-Ch., W.; Erazo, D.M.; Ortiz-Garces, I.; Gaibor-Naranjo, W.; Palacios-Pacheco, X. Artificial Intelligence Model for the Identification of the Personality of Twitter Users through the Analysis of Their Behavior in the Social Network. Electronics 2022, 11, 3811. https://doi.org/10.3390/electronics11223811
Villegas-Ch. W, Erazo DM, Ortiz-Garces I, Gaibor-Naranjo W, Palacios-Pacheco X. Artificial Intelligence Model for the Identification of the Personality of Twitter Users through the Analysis of Their Behavior in the Social Network. Electronics. 2022; 11(22):3811. https://doi.org/10.3390/electronics11223811
Chicago/Turabian StyleVillegas-Ch., William, Daniel Mauricio Erazo, Iván Ortiz-Garces, Walter Gaibor-Naranjo, and Xavier Palacios-Pacheco. 2022. "Artificial Intelligence Model for the Identification of the Personality of Twitter Users through the Analysis of Their Behavior in the Social Network" Electronics 11, no. 22: 3811. https://doi.org/10.3390/electronics11223811