1. Introduction
Eyes are the main organ for human to receive information from the outside world, according to the findings in [
1], millions of people lose their eyesight every year due to eye diseases [
2], which undoubtedly hit the lives of patients hard. Fundus images contain an abundance of retinal structures [
3], and abnormal lesions can be found by detecting retinal vessels in the fundus images. Early screening for eye disease has been completed by experienced specialist through manual annotation, but it is an expensive and inefficient task in clinical practice [
4,
5]. In addition, there are subjective differences in annotation between experts, which aggravates the difficulty of segmentation. Therefore, methods for automatic segmentation of retinal vessels have been explored.
In recent years, deep learning (DL) has been rapidly developed in the fields of image processing, like object detection [
6,
7,
8], image segmentation [
9]. Due to its powerful feature extraction capability, which further makes automatic image segmentation possible. The emergence of fully convolutional networks(FCN) [
10] introduces the concept to semantic segmentation, and it can obtain a segmentation results of the identical scale as input images. U-shaped network (U-Net) [
11] improves the FCN and designs an encoder-decoder structure, which has achieved great success in the field of medical image segmentation, where the encoder is used for feature extraction and the decoder is used for feature reconstruction, and the skip connection preserves both semantic features and detail information.
Encouraged by U-Net, a number of models based on encoder-decoder structure have emerged [
12,
13]. Inspired by residual connection [
14], Ref. [
15] was proposed for the segmentation of fundus vessels, where residual connection not only avoided the gradient problem but also preserved additional features. Motivated by densely connected convolutional network (DenseNet) [
16], Ref. [
17] was designed to remove artifacts from images. Schlemper et al. [
18] proposed a gated attention mechanism and embedded it in U-Net, which could adaptively correct the features in the encoder and enhance the propagation of relevant information. Alom et al. [
19] designed a recurrent structure for feature extraction, which was able to obtain more contextual information. Mou [
20] embedded an integrated attention block in the bottleneck layer, which could handle both spatial and channel information. In [
21], Keetha et al. embedded a bi-directional feature network(Bi-FPN) between the encoder and decoder, which was a resource efficient method for lung cancer diagnosis. All these methods have improved on the basis of U-Net, but still have problems as follows: (1) These methods use a single path with convolution structure and capture only limited information during feature extraction. (2) The features from the encoder are not fully exploited at all scales during fusion, and the feature fusion approach is rather simple and fails to fully integrate the features extracted.
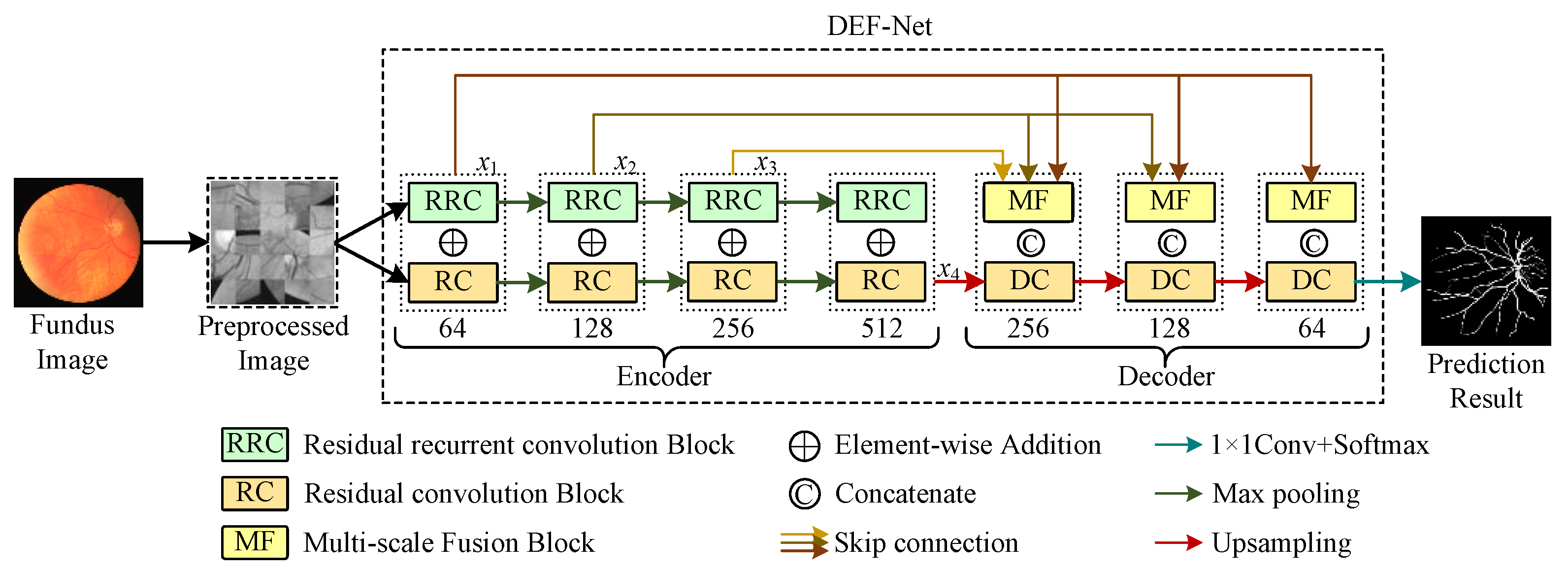
Therefore, a dual-encoder fusion network for fundus vascular segmentation, called DEF-Net, is proposed. Here, we build a dual-encoder structure to obtain richer features than a single path with convolution structure. For this purpose, we design an encoder branch for extracting detail information and an encoder branch for capturing contextual information, respectively. To facilitate the fusion efficiency of features, we present a multi-scale fusion block to fuse features from multiple scales. Extensive experiments are conducted and prove the proposed approach with enhanced performance. Core contributions of our work could be summed up as:
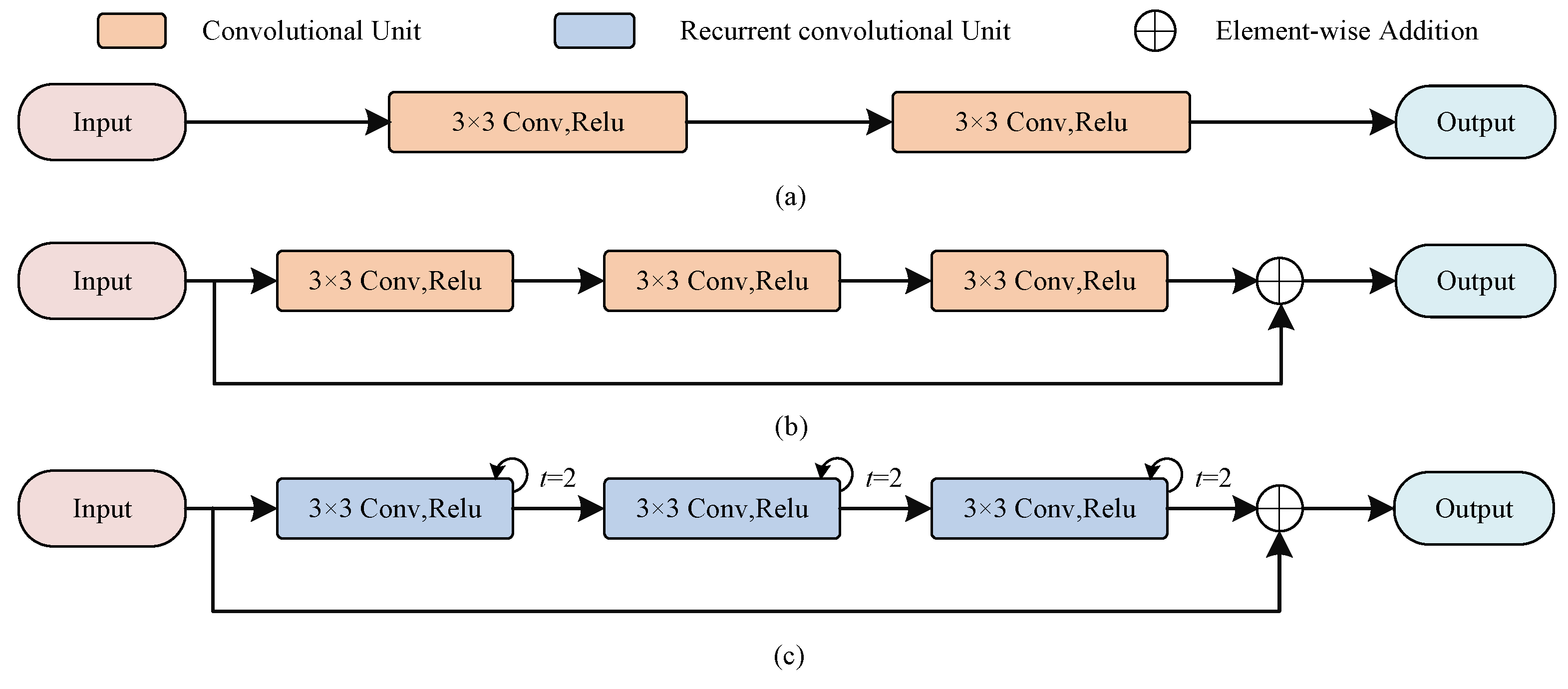
A residual convolution (RC) block based on convolutional structure is designed to capture detail information and a recurrent residual convolution (RRC) block based on recurrent structure is built to obtain rich contextual features. On the basis, a novel dual-encoder structure by RC blocks and RRC blocks is proposed for stronger feature extraction ability.
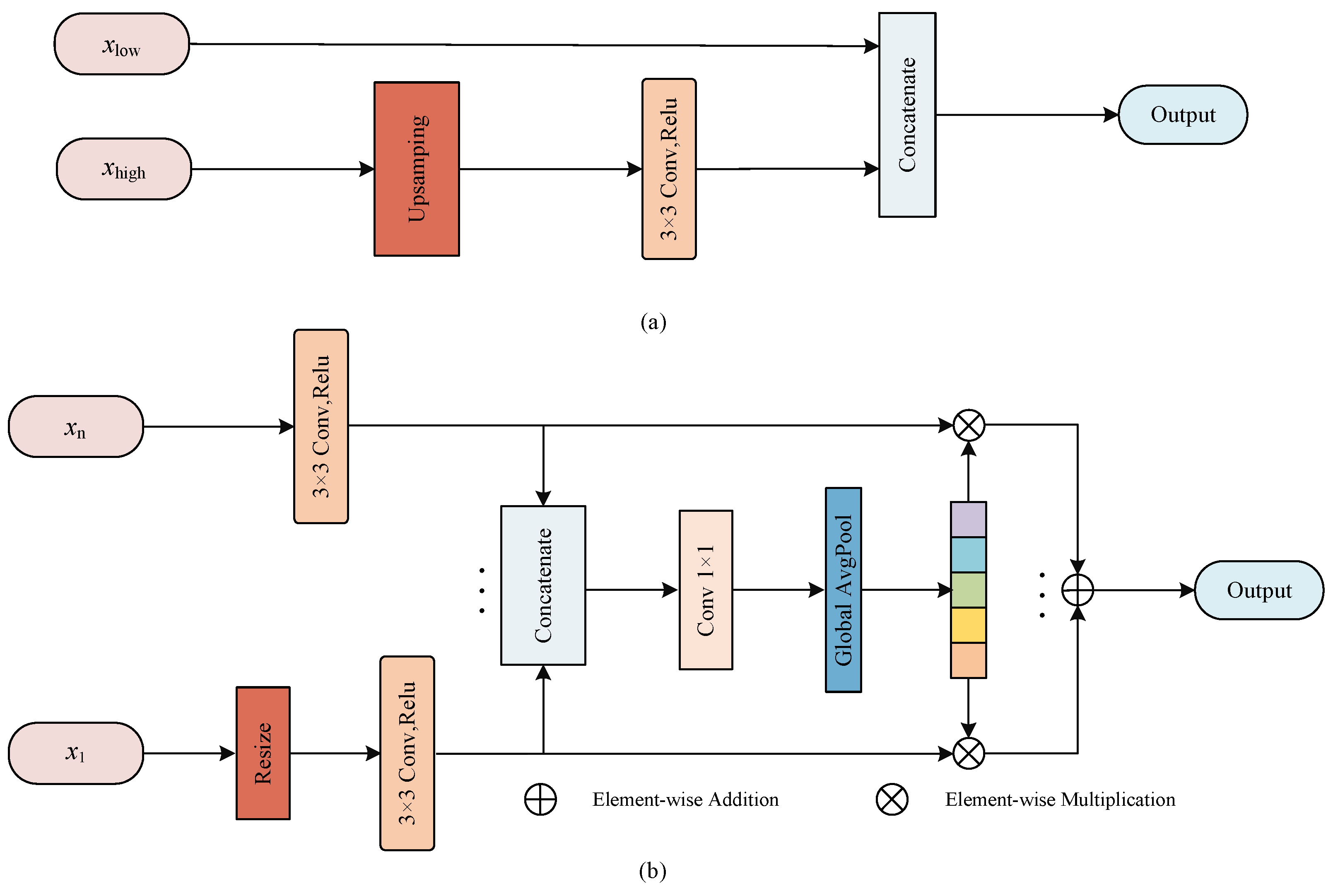
A multiscale fusion (MF) block is adopted to integrate features from different scales into a global vector by taking information from multiple scales into account and guide the original scales to facilitate the flow of features at different scales and enhance the fusion efficiency.
Experiments conducted on fundus image datasets have displayed the overall performance of our method and the results obtain a superior performance compared to other advanced methods.
3. Experimental Preparation
To ensure the reliability of the experiments, in this section the relevant preparation of the experiments will be introduced. The data sets and evaluation metrics used, the necessary preprocessing procedures, and the experimental details will be covered in the subsections.
3.1. Experimental Materials and Evaluation Metrics
Experiments for testing DEF-Net performance have been conducted on retinal image datasets, including DRIVE [
23], CHASE_DB1 [
24], and STARE [
25].
The DRIVE dataset contains 40 fundus retinal images, of which 7 are pathological images and the others are clean images. The resolution of each image is , of which the first 20 images are trained with the first annotation as the ground truth.
The CHASE_DB1 dataset contains 14 pairs of fundus images collected from 14 school children, with a resolution of , of which 20 were used for training while rest were used for testing. We use the annotation result of the first expert as the ground truth.
The STARE dataset contains 20 fundus images, and each of them has a resolution of and half of them is used for training. There are 10 pathological images in this dataset. We also use the first expert’s annotation as the label to train the network.
To assess model performance, the following evaluation metrics are used:
where
represents the correctly classified vessel pixels,
stands for correctly classified background pixels,
represents the incorrectly classified vessel pixels, and
represents the incorrectly classified background pixels. In addition, area under Receiver Operating Characteristic curves (AUC) is also used to evaluate the overall performance of segmentation.
3.2. Experimental Preprocessing
Appropriate preprocessing operations can effectively enhance model performance. To improve the issue of low contrast caused by light in fundus images, we use the approach based on traditional image processing to enhance the contrast of fundus images.
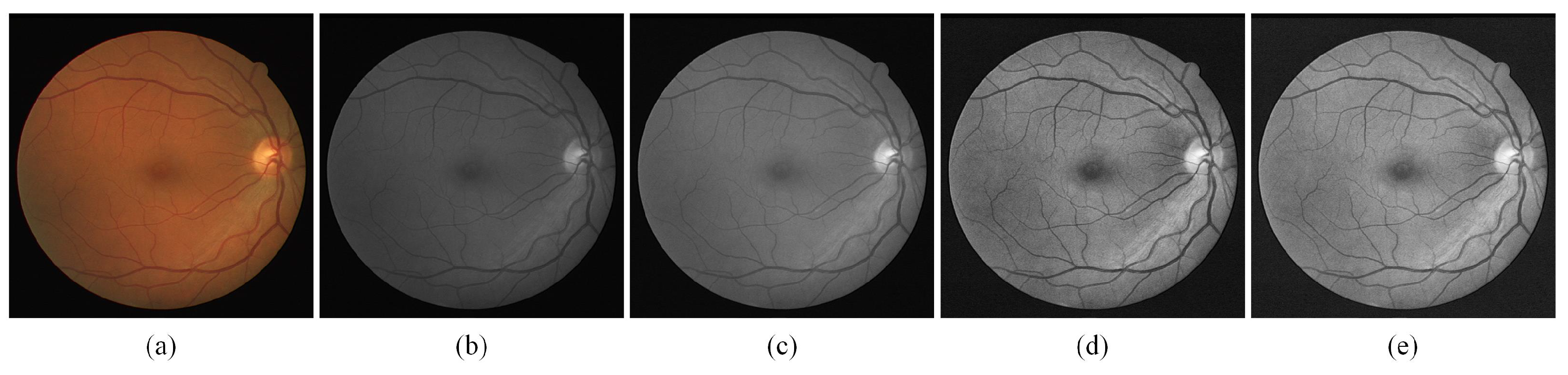
As shown in
Figure 4, an original fundus image is shown in (a), and the fundus image is first grayed by converting colorful images to grayscale images as (b). To variation the intensity range of the pixels, normalization is applied as in (c). (d) is the image after the finite adaptive histogram equalization (CLAHE) process, which shows a significant improvement in the contrast of the image, and (e) is the result obtained after gamma adjustment which compensates the imbalance caused by the fundus light. After the image enhancement referred to above, the contrast of fundus images has dramatically improved, and the enhancement of thin blood vessels in particular will bring notable benefit to experimental accuracy.
3.3. Experimental Details
The retinal vessel segmentation task is a binary classification task, and to better distinguish vascular pixels from non-vascular pixels, the binary cross-entropy is employed. Supposing there are
N pixels in total, the distance of the predicted result
P from the ground truth
G is assessed as
The network is built with PyTorch and trained on an NVIDIA GeForce RTX 3080 Ti GPU. The models are trained with 50 epochs and 0.001 initial learning rate, the batch size is set to 64.
The dataset used in this paper has a rather small scale. To better train the model and avoid overfitting at the same time, we uses the operation of cropping patches, in which the images are randomly cropped into
blocks with a stride of 16 during the training phase. In the test phase, the corresponding segmentation patches are generated by sequentially cropping patches, and we combine these segmentation patches into a complete segmentation result in order, as shown in
Figure 1.
5. Conclusions
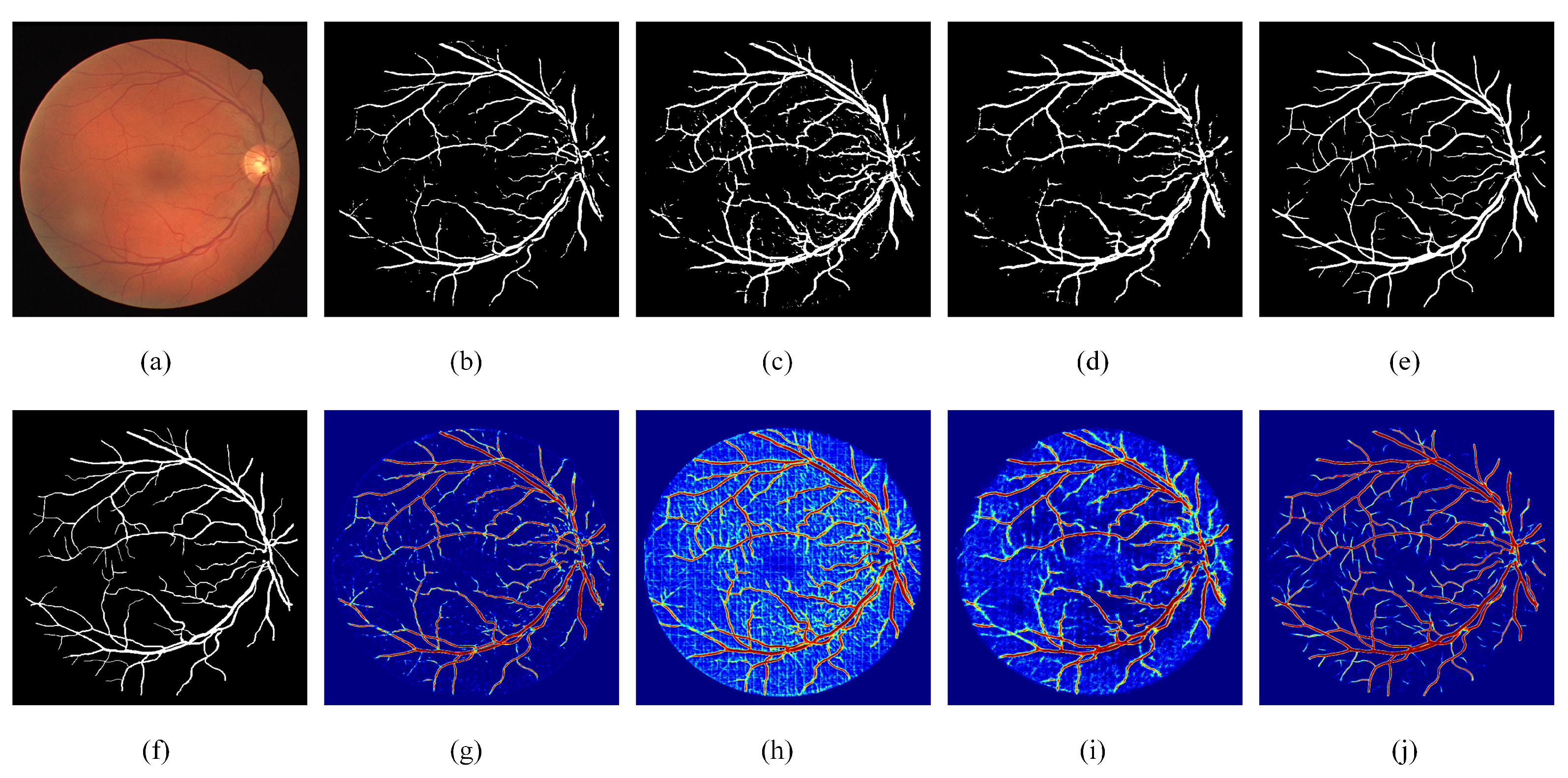
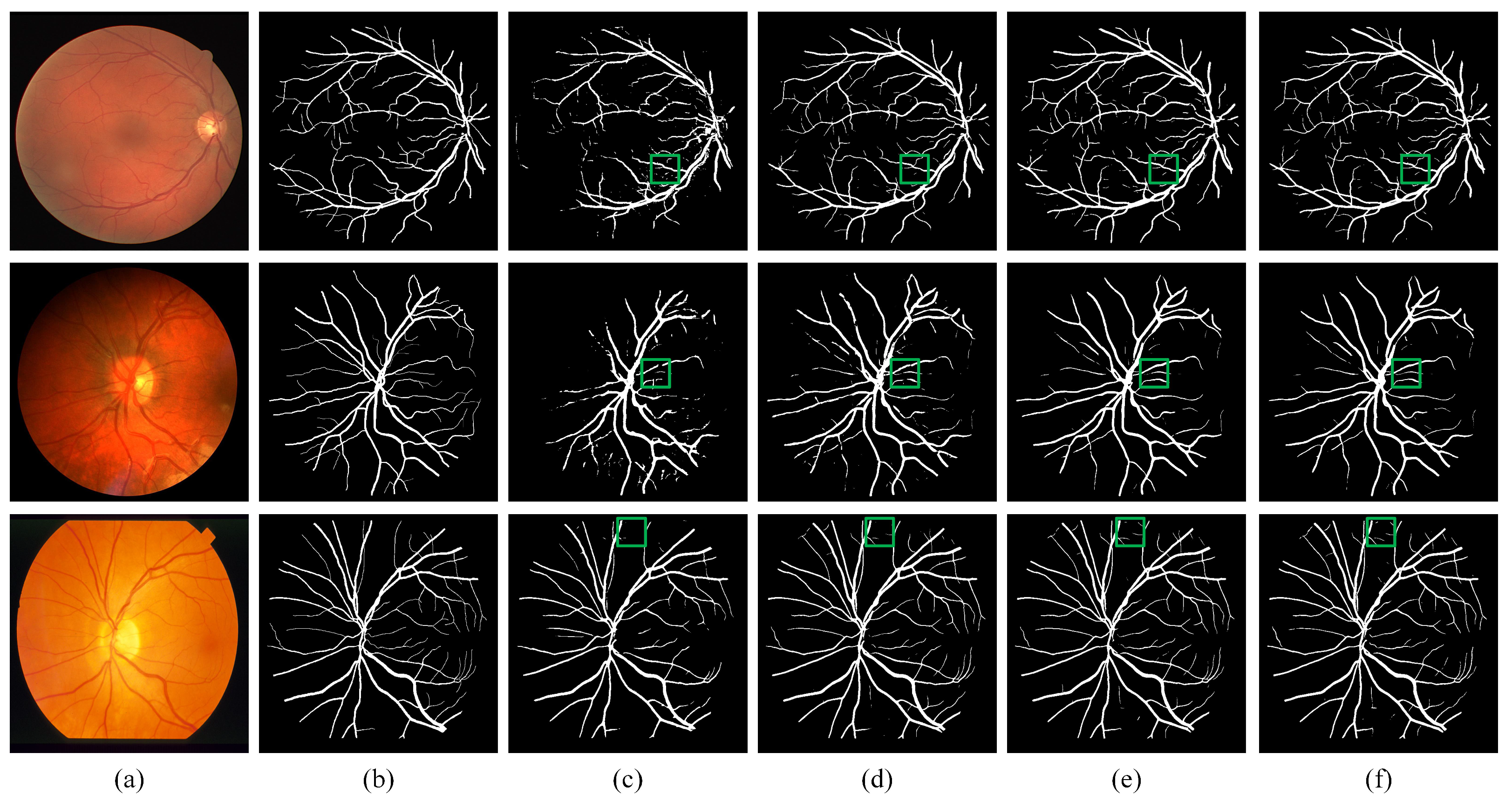
In this paper, we propose a novel retinal vessel segmentation method, called DEF-Net, which can segment the fundus vessels efficiently. First, this paper proposes a dual-encoder structure, which can simultaneously utilize convolution and recurrent convolution to extract detail features and contextual features. Second, the features at different encoder stage are fused by a multi-scale fusion block, which enhance the propagation of effective information from encoder, and promote the fusion efficiency with the decoder features, which improve the overall segmentation performance. We conduct relevant experiments on DRIVE, CHASE_DB1, and STARE, analyze the effectiveness of each component of the model by combining visualization results and evaluation metrics. The superiority of the proposed method is also demonstrated by comparison with other advanced models.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





