
A Federated Learning Framework Based on Incremental Weighting and Diversity Selection for Internet of Vehicles

Abstract
:1. Introduction
Our Contribution
- We first introduced federated learning in the IoV scenario to deal with the isolated data island challenge. Second, we combine incremental learning and federated learning to address the incremental data challenge. More specifically, an algorithm was proposed based on incremental data weights and incremental parameter depth values. In this algorithm, the penalty factor is used to improve the arctangent function, and a weighted aggregation strategy is formed, which optimizes the problems of large steady-state errors and weak anti-interference ability in IoV.
- We then propose a dynamic selection algorithm combining cosine distance and diversity score to deal with the data diversity challenges. The algorithm integrates the local ML model parameters from different vehicles, avoids homogenization computing, maintains independent complementary data diversity, and optimizes the over-fitting problem of the global ML model prediction model in IoV.
- We finally validate the Fed-IW&DS framework on multiple datasets, adopting accuracy, loss value, and Matthews correlation coefficient (MCC) to evaluate the global ML model. The experimental results show that the Fed-IW&DS framework achieves higher accuracy, lower loss, and better MCC metric within the same computational time.
2. Literature Review
2.1. Distributed Machine Learning in IoV
2.2. Federated Learning in IoV
2.3. Incremental Data and Data Diversity in IoV
3. System Model and Problem Description
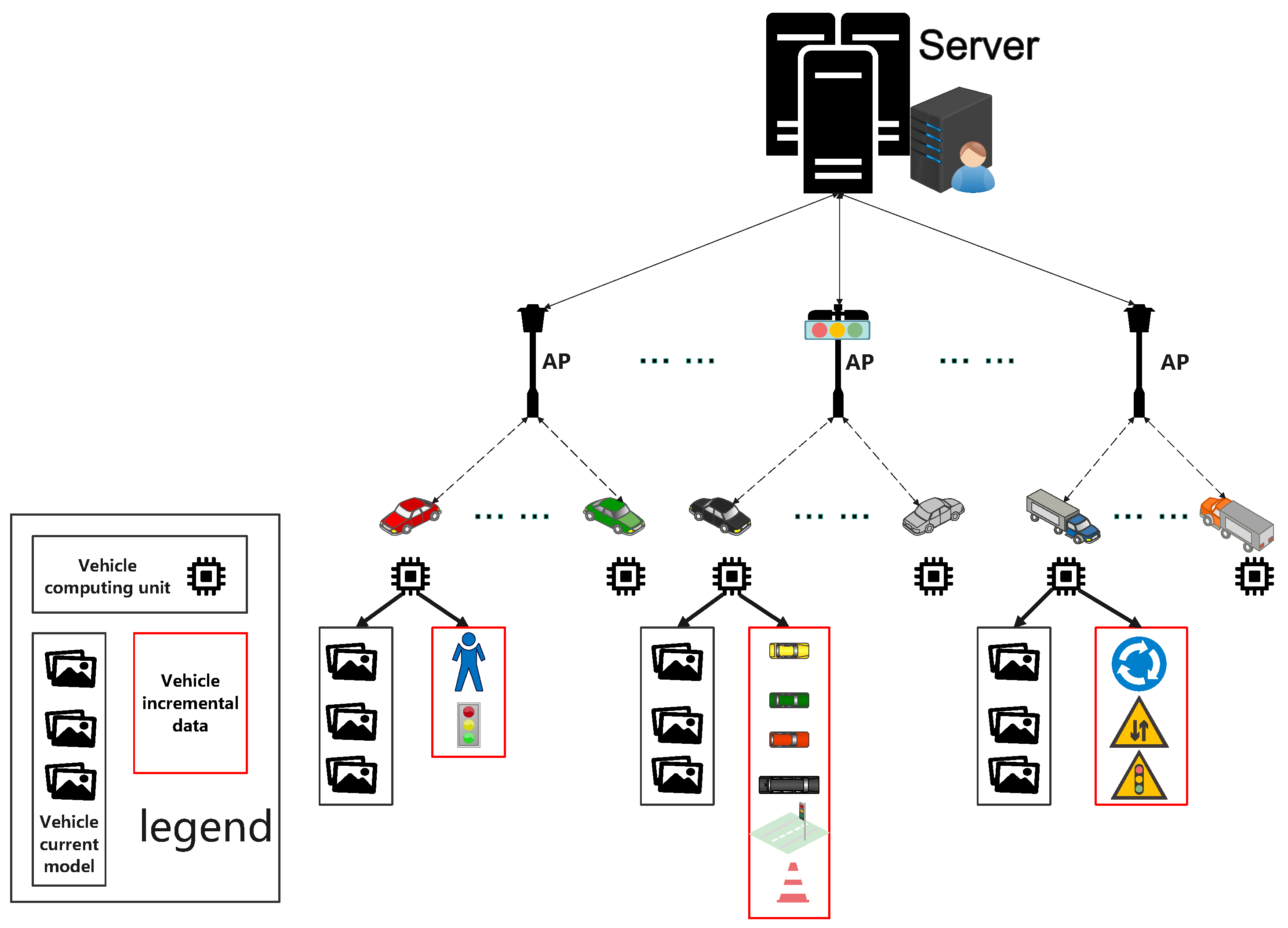
3.1. System Model
- Central server. It is the only core processing node. It does not receive local data collected by the vehicle, only local ML model parameters. In the Fed-IW&DS framework, it is responsible for the highest difficulty calculations, such as Incremental Weighted Calculation and Incremental Parameter Depth-Value Calculation, etc. We assume that the central server has unlimited computing power and storage space, in other words, it is capable of any computation.
- AP (Access Point). There are multiple APs, all connected to the server. They can communicate with each other at any time. Likewise, it does not receive local data collected by the vehicle, only local ML model parameters. In the Fed-IW&DS framework, it is responsible for moderately difficult calculations such as Vehicle Diversity Selection and Diversity Score Calculation. We assume it has enough computing power and storage space to support these moderate calculations.
- Vehicle node. There are many vehicles, and one vehicle will only be connected to one AP at a time. The vehicle node is responsible for collecting a large amount of incremental data (most of which are images from the camera) during the driving process, and only saves them in the local storage to form a local data set . Then is trained to form local ML model parameters . While will be saved locally, the vehicle node will only upload . We define the collection of vehicles as V, and a vehicle as , . The sample data of vehicle is represented as , the label set of these sample data is expressed as . The amount of sample data of the vehicle is S, and the sum of the number of training samples is The sample size of vehicle is S, and the total sample size of all vehicles is .During the first training process, the server will obtain a local ML model parameter in the existing local training set . At this stage, the existing local training sets (assuming they are class a) contain many training samples. When the global model is updated at round , the vehicle nodes will gradually collect a set of incremental data (assuming they are class b). Incremental learning is required to continuously update the global model. Incremental learning keeps learning new classes without forgetting the learned old classes. That is, the global model can correctly identify images of class .
3.2. Problem Description
3.3. Problem Summary
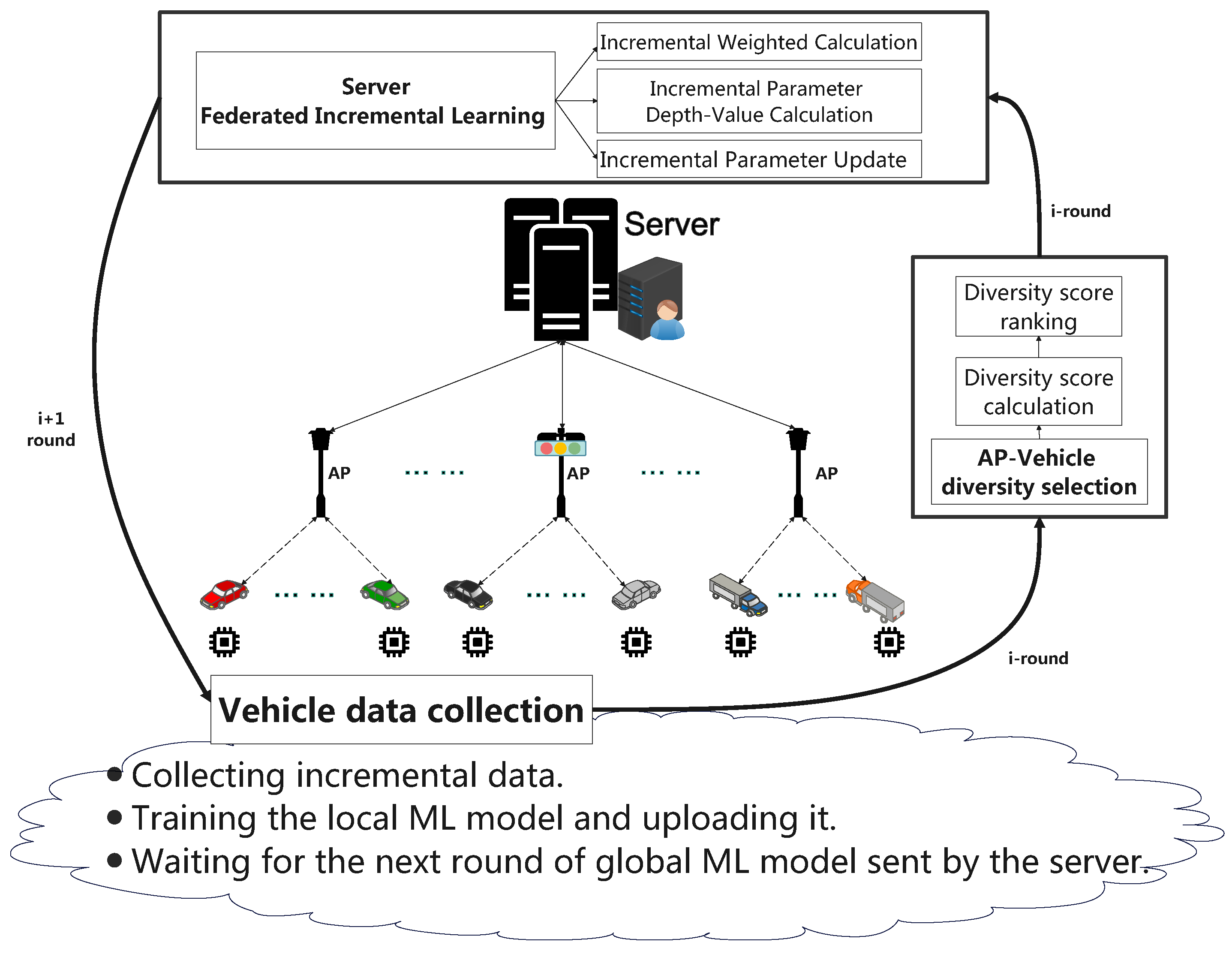
4. The Proposed Fed-IW&DS Framework
4.1. Overall Introduction to the Framework
- Vehicle diversity selection algorithm consists of diversity score calculation and diversity score sorting. Diversity score calculation first uses ACC, Loss, and MCC three vehicle performance indicators, and then calculates the difference of these three indicators through an improved cosine distance. Diversity score sorting is responsible for statistical calculation results and filtering vehicle nodes with high diversity scores.
- The vehicle federated incremental learning algorithm is executed by the central server. It is well known that vehicles in IoV drive freely (as long as they obey the traffic rules). Therefore, the incremental data are different from each other during driving. However, in the traditional federated learning framework, the central server collects the local ML model parameters of all vehicle nodes and then updates the global model with the same weights. This is obviously unreasonable. In response to the above problems, our proposed vehicle federated incremental learning algorithm is divided into three sub-modules: incremental weighted calculation, incremental parameter depth-value calculation, and incremental parameter update.
- We introduce these three sub-modules: incremental weighted calculation, incremental parameter depth-value calculation, and incremental parameter update. (1) Incremental weighted calculation. The server constantly monitors the incremental learning status of vehicle nodes. The server explores the impact of incremental data on the current local ML model according to the ratio of the incremental sample number to the current total number of samples. Its purpose is to make the local ML model decay relatively stable and gentle. (2) Incremental parameter depth-value calculation. It refers to the incremental parameter correction of the global ML model based on the previous incremental weighted calculation results. More specifically, the impact of incremental data on the current local ML model will be reflected by a specific value—the incremental parameter depth value. The incremental parameter depth value enables reasonable, rapid, and stable incremental parameter correction for the global ML model. (3) Finally, only the global ML model updated with incremental parameters could be sent to every vehicle node for the next round of calculation. The above process will continue to repeat until the vehicle node leaves the AP coverage or parks or disconnects.
4.2. AP Node-Vehicle Diversity Selection Algorithm
- The vehicle’s existing data and incremental data are unbalanced, resulting in different requirements for parameter change in the process of ML learning. Simply grading the accuracy of the local ML model from good to bad, or selecting participating vehicles proportionally, it is easy to ignore the useful ML parameters. This will lead to the deviation of the global ML model in the central server’s training process, which cannot cope with the diversity of incremental data, thus affecting the accuracy of the global ML model.
- In traditional federated learning, the selection of nodes is only based on a fixed threshold, which is artificially set and the value of this threshold is too subjective. However, the situation in IoV changes rapidly, and unreasonable fixed thresholds will make the central server to be time-consuming. This will cause the global ML model to fluctuate greatly and not easily converge, and it is also unable to cope with the diversity of incremental data.
4.2.1. Diversity Score Calculation–Initial Process
4.2.2. Diversity Score Calculation–Improvement Based on Penalty Factor
- Motivation of Penalty Factor
- Improved Diversity Score Based on Penalty Factor
4.3. Central Server-Vehicle Federated Incremental Learning Algorithm
4.3.1. Incremental Weighted Calculation
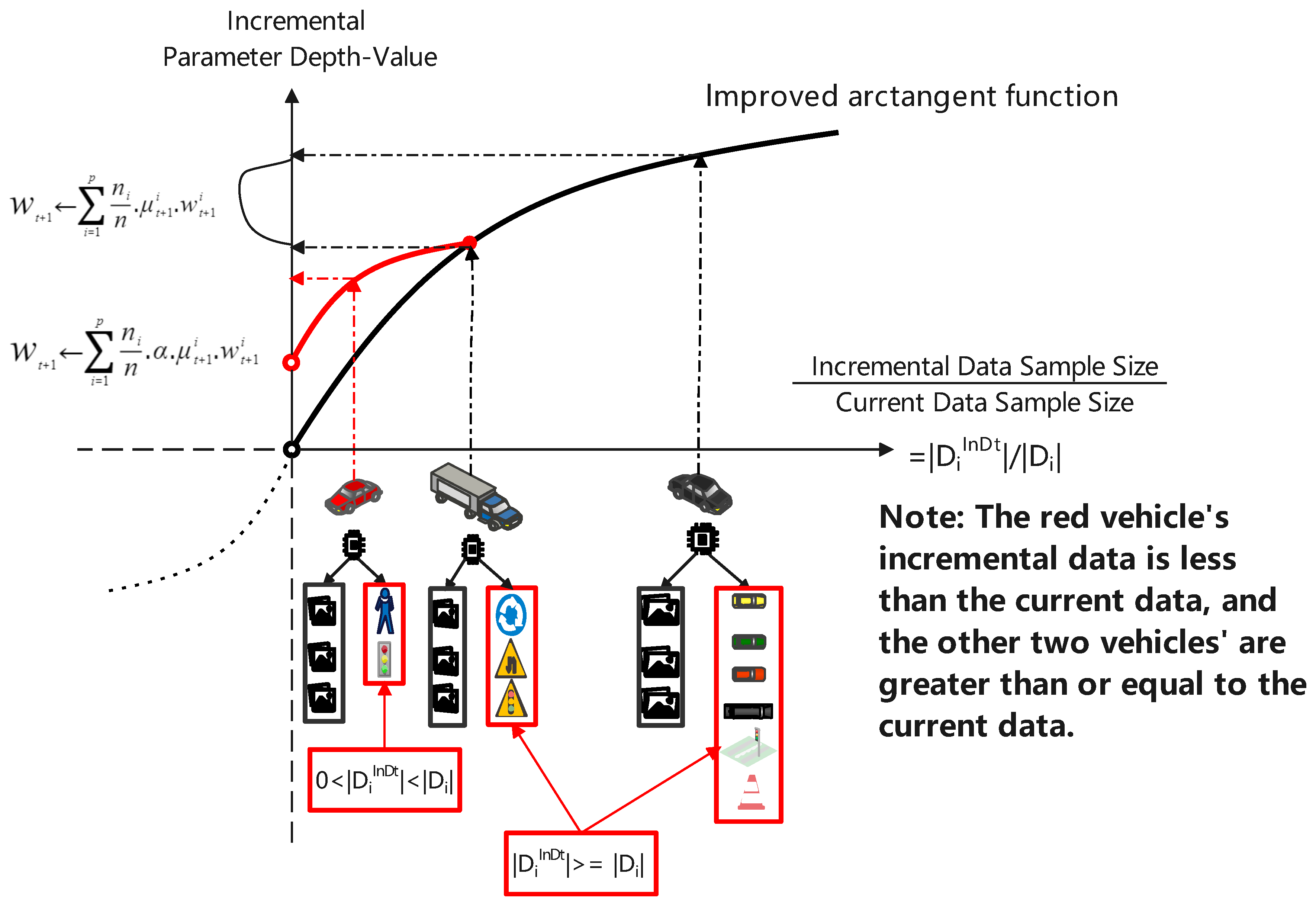
4.3.2. Motivation of Adjustment Variable for Parameter Depth-Value
- Relationship between incremental data & parameter depth-value. Obviously, the amount of incremental data is proportional to the depth value of the incremental parameters. That is to say, the more incremental data of a vehicle, the more we need to consider updating its parameters. Therefore, we first need to consider a “proportional decay function”.
- Massive incremental data. In the early stage of global ML model training, the amount of existing data is small, and the proportion of incremental data is large. If blindly selecting vehicles with massive incremental data will lead to excessive consumption of resources and increase the calculation cost of the global ML model. Therefore, we next need to consider a proportional decay function with “reducing the large signal”.
- Small incremental data. In addition, if we ignore vehicles with small incremental data, it will easily lead to the extreme competition phenomenon of “the strong are stronger, the weak are weaker”. Therefore, we also need to consider a proportional decay function that can “amplifying the small signal + reducing the large signal”.
- Incremental data trends. In the middle and late stages of global ML model training, the amount of existing data will increase, and the proportion of incremental data will decrease. Therefore, the more common situation is a small amount of incremental data. In other words, the key to our incremental parameter depth-value calculation is “amplifying the small signal”.
4.3.3. Incremental Parameter Depth-Value Calculation
4.4. Pseudocode of the Fed-IW&DS Framework
| Algorithm 1: Central Server-Vehicle Federated Incremental Learning Algorithm |
 |
| Algorithm 2: AP Node-Vehicle Diversity Selection Algorithm |
 |
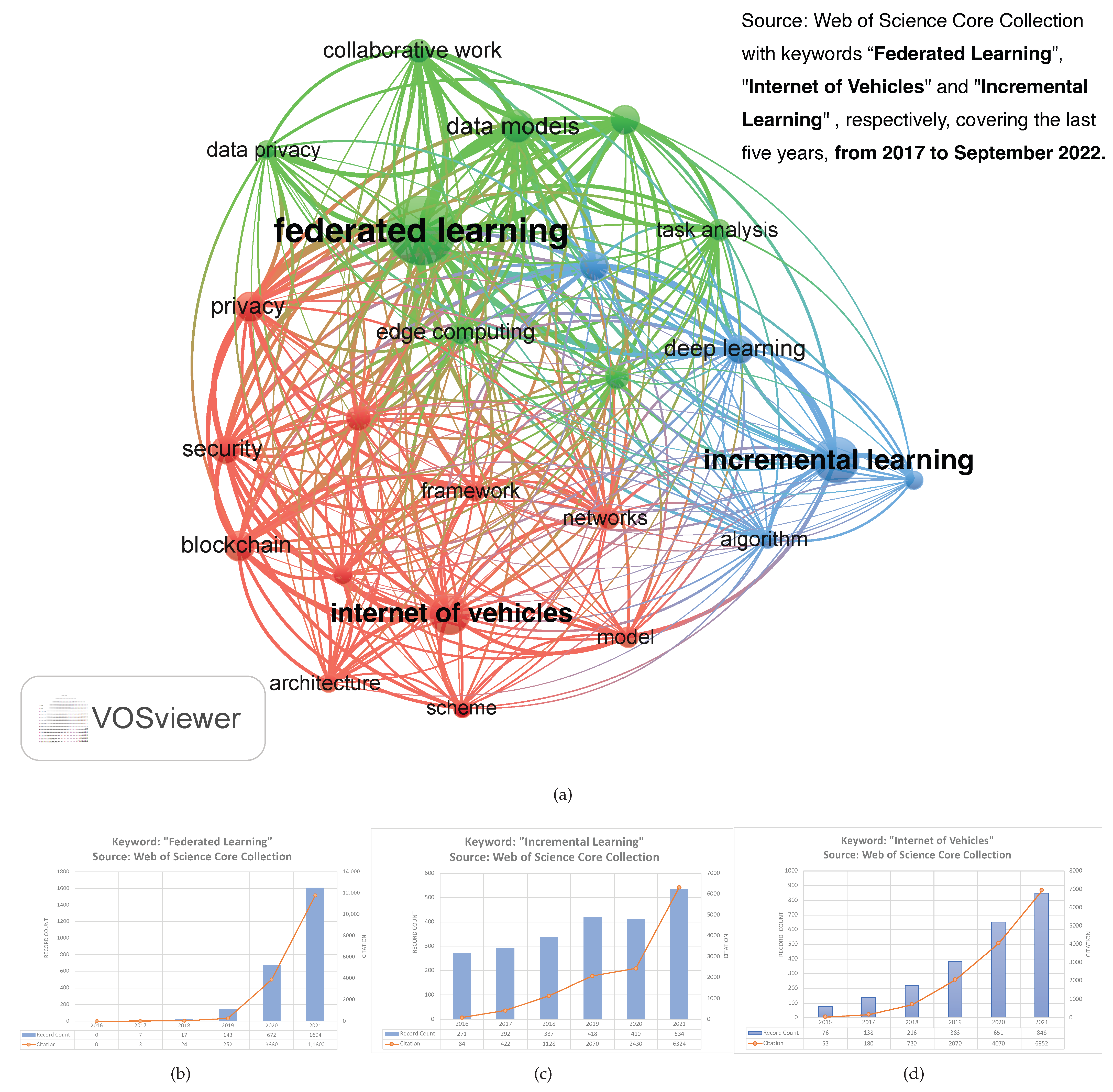
5. Experimental Result
5.1. Dataset Description
5.2. Experimental Parameter Settings and Experimental Platform
5.3. Experimental Results
5.3.1. Diversity-Ratio Values
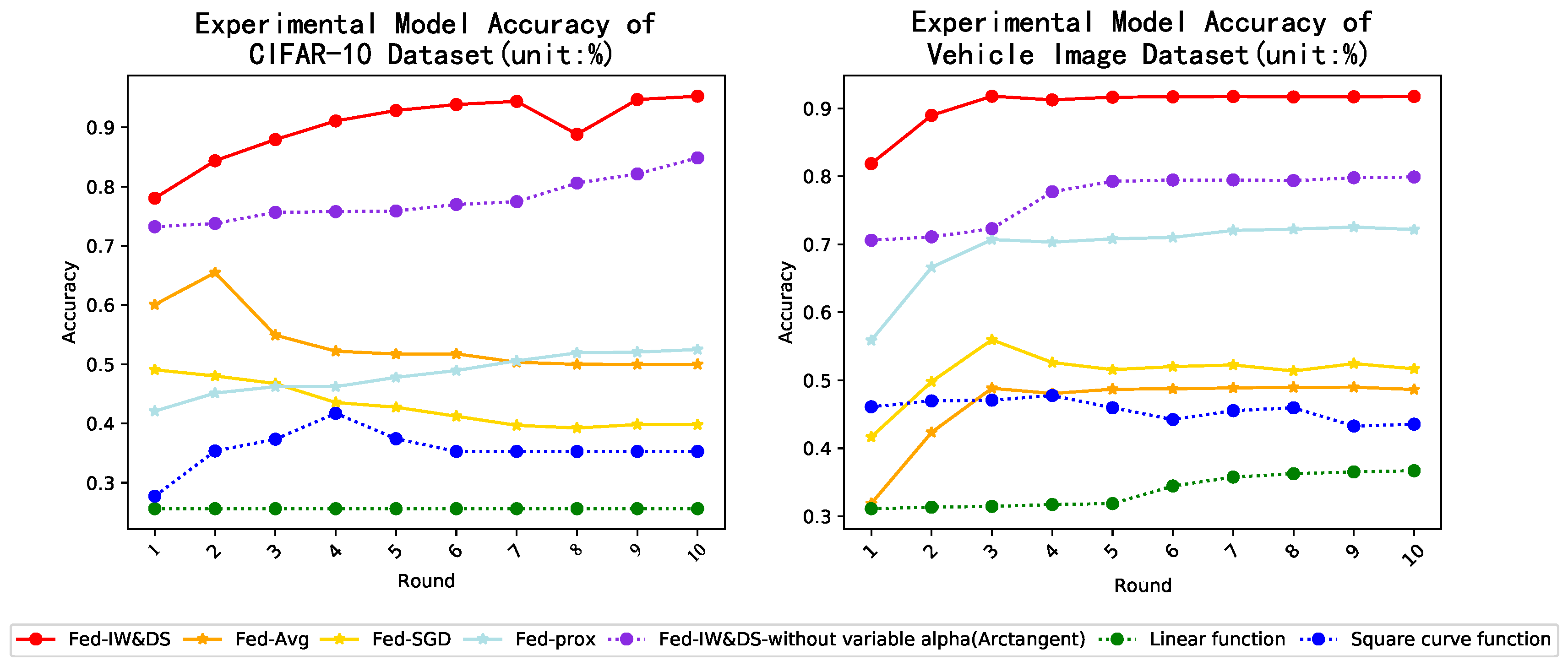
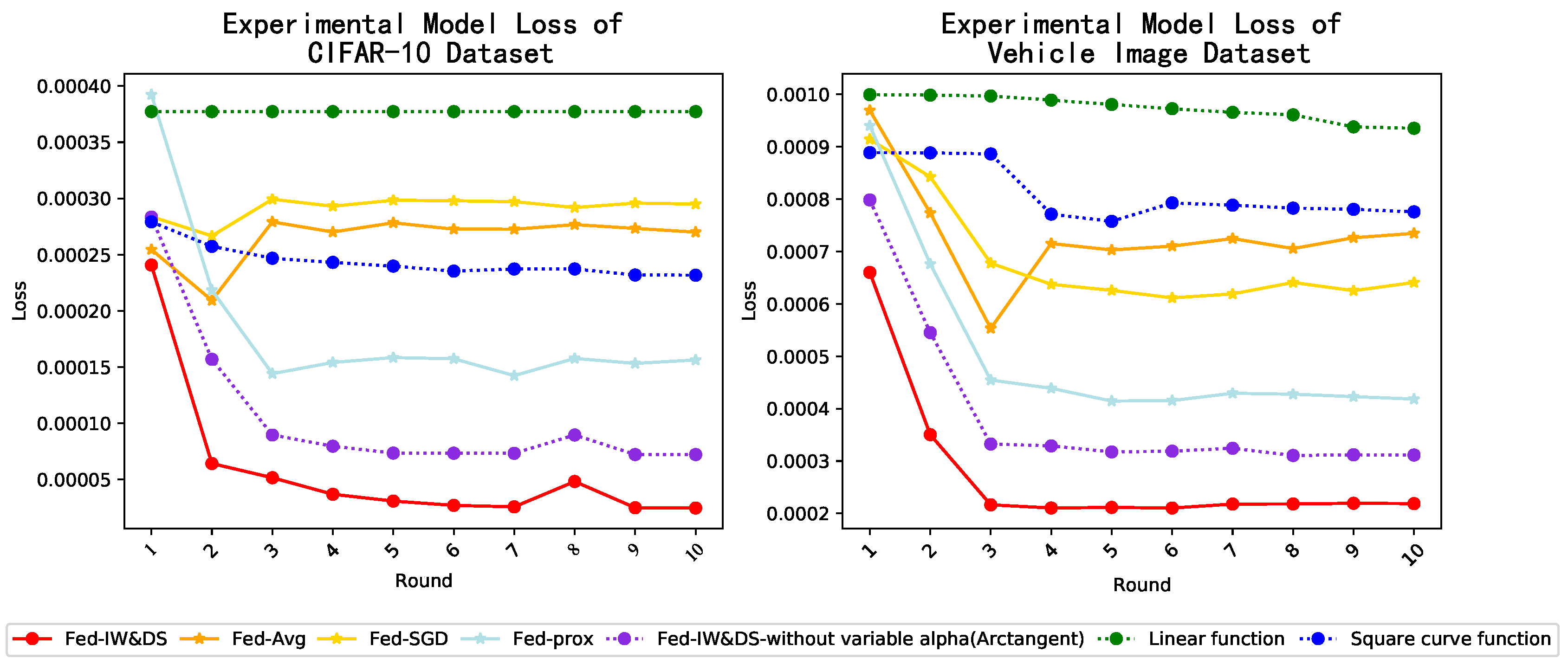
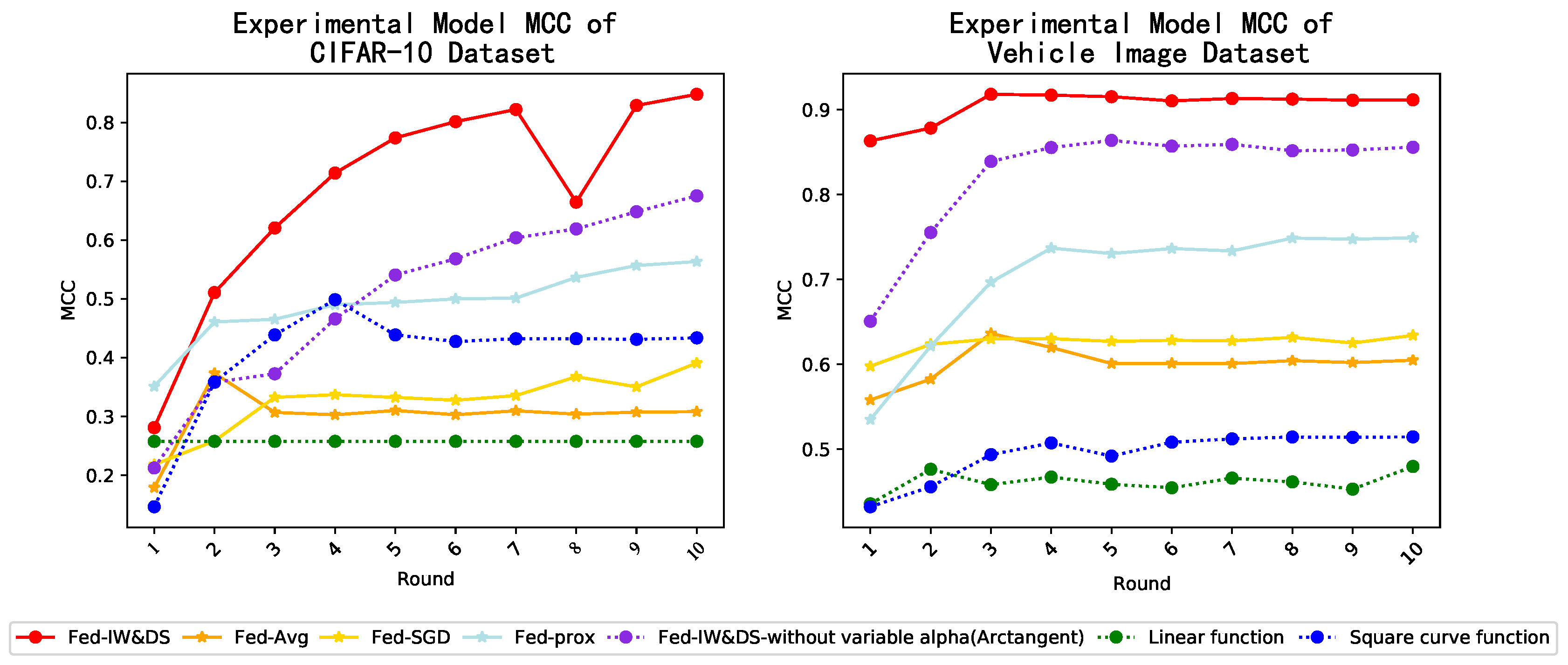
5.3.2. The Acc, Loss, MCC Results and Computational Time Cost
- Accuracy Results
- Loss Results
- MCC Results
- Computational Time Cost
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chaudhry, S.A. Designing an Efficient and Secure Message Exchange Protocol for Internet of Vehicles. Secur. Commun. Netw. 2021, 2021, 5554318. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, J.; Wang, Z. Bearing Faulty Prediction Method Based on Federated Transfer Learning and Knowledge Distillation. Machines 2022, 10, 376. [Google Scholar] [CrossRef]
- Majeed, U.; Hassan, S.S.; Hong, C.S. Cross-Silo Model-Based Secure Federated Transfer Learning for Flow-Based Traffic Classification. In Proceedings of the 35th International Conference on Information Networking (Icoin 2021), Jeju Island, Korea, 13–16 January 2021; IEEE: New York, NY, USA, 2021; pp. 588–593. [Google Scholar] [CrossRef]
- Anowar, F.; Sadaoui, S. Incremental Neural-Network Learning for Big Fraud Data. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (Smc), Toronto, ON, Canada, 11–14 October 2020; IEEE: New York, NY, USA, 2020; pp. 3551–3557. [Google Scholar]
- Ge, S.; Luo, L.; Li, H. Orthogonal Incremental Non-Negative Matrix Factorization Algorithm and Its Application in Image Classification. Comput. Appl. Math. 2020, 39, 54. [Google Scholar] [CrossRef]
- Jiang, Z.; Lin, R.; Yang, F. An Incremental Clustering Algorithm with Pattern Drift Detection for IoT-Enabled Smart Grid System. Sensors 2021, 21, 6466. [Google Scholar] [CrossRef]
- Andrei, M.A.; Boiangiu, C.A.; Tarbă, N.; Voncilă, M.L. Robust Lane Detection and Tracking Algorithm for Steering Assist Systems. Machines 2022, 10, 10. [Google Scholar] [CrossRef]
- Bzai, J.; Alam, F.; Dhafer, A.; Bojović, M.; Altowaijri, S.M.; Niazi, I.K.; Mehmood, R. Machine Learning-Enabled Internet of Things (IoT): Data, Applications, and Industry Perspective. Electronics 2022, 11, 2676. [Google Scholar] [CrossRef]
- Gu, F.; Yang, X.; Li, X.; Deng, H. Computational Resources Allocation and Vehicular Application Offloading in VEC Networks. Electronics 2022, 11, 2130. [Google Scholar] [CrossRef]
- Al-Sharman, M.; Murdoch, D.; Cao, D.; Lv, C.; Zweiri, Y.; Rayside, D.; Melek, W. A Sensorless State Estimation for a Safety-Oriented Cyber-Physical System in Urban Driving: Deep Learning Approach. IEEE-Caa J. Autom. Sin. 2021, 8, 169–178. [Google Scholar] [CrossRef]
- Zhang, D.; Shi, W.; St-Hilaire, M.; Yang, R. Multiaccess Edge Integrated Networking for Internet of Vehicles: A Blockchain-Based Deep Compressed Cooperative Learning Approach. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1–15. [Google Scholar] [CrossRef]
- Zhao, X.P.; Jiang, R. Distributed Machine Learning Oriented Data Integrity Verification Scheme in Cloud Computing Environment. IEEE Access 2020, 8, 26372–26384. [Google Scholar] [CrossRef]
- Magdum, J.; Ghorse, R.; Chaku, C.; Barhate, R.; Deshmukh, S. A Computational Evaluation of Distributed Machine Learning Algorithms. In Proceedings of the 2019 IEEE 5th International Conference for Convergence in Technology (I2ct), 2019, Bombay, India, 29–31 March 2019; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Wasilewska, M.; Bogucka, H.; Kliks, A. Federated Learning for 5G Radio Spectrum Sensing. Sensors 2021, 22, 198. [Google Scholar] [CrossRef]
- Tahir, M.; Ali, M.I. On the Performance of Federated Learning Algorithms for IoT. IoT 2022, 3, 273–284. [Google Scholar] [CrossRef]
- Dahmane, S.; Yagoubi, M.B.; Brik, B.; Kerrache, C.A.; Calafate, C.T.; Lorenz, P. Multi-Constrained and Edge-Enabled Selection of UAV Participants in Federated Learning Process. Electronics 2022, 11, 2119. [Google Scholar] [CrossRef]
- Hammedi, W.; Brik, B.; Senouci, S.M. Federated Deep Learning-Based Framework to Avoid Collisions Between Inland Ships. In Proceedings of the 2022 International Wireless Communications and Mobile Computing (IWCMC), Dubrovnik, Croatia, 30 May–3 June 2022; pp. 967–972. [Google Scholar]
- Gong, H.; Jiang, L.; Liu, X.; Wang, Y.; Wang, L.; Zhang, K. Recover User’s Private Training Image Data by Gradient in Federated Learning. Sensors 2022, 22, 7157. [Google Scholar] [CrossRef]
- Jeong, Y.; Kim, T. A Cluster-Driven Adaptive Training Approach for Federated Learning. Sensors 2022, 22, 7061. [Google Scholar] [CrossRef]
- Sun, R.; Li, Y.; Shah, T.; Sham, R.W.H.; Szydlo, T.; Qian, B.; Thakker, D.; Ranjan, R. FedMSA: A Model Selection and Adaptation System for Federated Learning. Sensors 2022, 22, 7244. [Google Scholar] [CrossRef]
- Wang, S.; Liu, F.; Xia, H. Content-Based Vehicle Selection and Resource Allocation for Federated Learning in IoV. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Nanjing, China, 29 March–1 April 2021; IEEE: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Liang, F.; Yang, Q.; Liu, R.; Wang, J.; Sato, K.; Guo, J. Semi-Synchronous Federated Learning Protocol With Dynamic Aggregation in Internet of Vehicles. IEEE Trans. Veh. Technol. 2022, 71, 4677–4691. [Google Scholar] [CrossRef]
- Yu, H.; Liu, Z.; Liu, Y.; Chen, T.; Cong, M.; Weng, X.; Niyato, D.; Yang, Q. A Fairness-Aware Incentive Scheme for Federated Learning. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–9 February 2020; pp. 393–399. [Google Scholar]
- Lyu, L.; Yu, J.; Nandakumar, K.; Li, Y.; Ma, X.; Jin, J.; Yu, H.; Ng, K.S. Towards Fair and Privacy-Preserving Federated Deep Models. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2524–2541. [Google Scholar] [CrossRef]
- Huang, J.; Xu, C.; Ji, Z.; Xiao, S.; Liu, T.; Ma, N.; Zhou, Q. AFLPC: An Asynchronous Federated Learning Privacy-Preserving Computing Model Applied to 5G-V2X. Secur. Commun. Netw. 2022, 2022, 9334943. [Google Scholar] [CrossRef]
- Ayub, A.; Wagner, A.R. Cognitively-Inspired Model for Incremental Learning Using a Few Examples. In Proceedings of the 2020 IEEE/Cvf Conference on Computer Vision and Pattern Recognition Workshops (Cvprw 2020), Seattle, WA, USA, 14–19 June 2020; IEEE Computer Soc: Los Alamitos, CA, USA, 2020; pp. 897–906. [Google Scholar] [CrossRef]
- Jaiswal, G. Performance Analysis of Incremental Learning Strategy in Image Classification. In Proceedings of the 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence 2021), Noida, India, 28–29 January 2021; IEEE: New York, NY, USA, 2021; pp. 427–432. [Google Scholar] [CrossRef]
- Yang, Q.; Gu, Y.; Wu, D. Survey of Incremental Learning. In Proceedings of the 2019 31st Chinese Control and Decision Conference (CCDC 2019), Nanchang, China, 3–5 June 2019; IEEE: New York, NY, USA, 2019; pp. 399–404. [Google Scholar]
- Cui, W.; Xia, W.; Lan, Z.; Qian, C.; Yan, F.; Shen, L. A Self-adaptive Feedback Handoff Algorithm Based Decision Tree for Internet of Vehicles. In Proceedings of the Ad Hoc Networks, Adhocnets, Cairns, Australia, 20–23 September 2018; Zheng, J., Xiang, W., Lorenz, P., Mao, S., Yan, F., Eds.; Springer International Publishing Ag: Cham, Switzerland, 2019; Volume 258, pp. 177–190. [Google Scholar] [CrossRef]
- Wang, X.; Zhu, Y.; Han, S.; Yang, L.; Gu, H.; Wang, F.Y. Fast and Progressive Misbehavior Detection in Internet of Vehicles Based on Broad Learning and Incremental Learning Systems. IEEE Internet Things J. 2022, 9, 4788–4798. [Google Scholar] [CrossRef]
- Zhu, M.y.; Chen, Z.; Chen, K.f.; Lv, N.; Zhong, Y. Attention-Based Federated Incremental Learning for Traffic Classification in the Internet of Things. Comput. Commun. 2022, 185, 168–175. [Google Scholar] [CrossRef]
- Huang, Q.; Wang, D. Study on the Rumor Propagation Model with Penalty Factor. In Proceedings of the 32nd 2020 Chinese Control and Decision Conference (Ccdc 2020), Hefei, China, 22–24 August 2020; IEEE: New York, NY, USA, 2020; pp. 5176–5181. [Google Scholar]
- Liu, J.; Shi, J.; Hao, F.; Dai, M.; Zhang, Z. Arctangent Entropy: A New Fast Threshold Segmentation Entropy for Light Colored Character Image on Semiconductor Chip Surface. Pattern Anal. Appl. 2022, 25, 1075–1090. [Google Scholar] [CrossRef]
- Lei, Y.; Wang, S.L.; Su, C.; Ng, T.F. OES-Fed: A Federated Learning Framework in Vehicular Network Based on Noise Data Filtering. PeerJ Comput. Sci. 2022, 8, e1101. [Google Scholar] [CrossRef]
- Gharibi, M.; Bhagavan, S.; Rao, P. FederatedTree: A Secure Serverless Algorithm for Federated Learning to Reduce Data Leakage. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; Chen, Y., Ludwig, H., Tu, Y., Fayyad, U., Zhu, X., Hu, X., Byna, S., Liu, X., Zhang, J., Pan, S., et al., Eds.; IEEE: New York, NY, USA, 2021; pp. 4078–4083. [Google Scholar] [CrossRef]
- Ullah, S.; Kim, D.H. Federated Learning Using Sparse-Adaptive Model Selection for Embedded Edge Computing. IEEE Access 2021, 9, 167868–167879. [Google Scholar] [CrossRef]
- Xiao, J.; Du, C.; Duan, Z.; Guo, W. A Novel Server-side Aggregation Strategy for Federated Learning in Non-IID Situations. In Proceedings of the 2021 20th International Symposium on Parallel and Distributed Computing (ISPDC), Cluj-Napoca, Romania, 28–30 July 2021; Potolea, R., Iancu, B., Slavescu, R.R., Eds.; IEEE: New York, NY, USA, 2021; pp. 17–24. [Google Scholar] [CrossRef]
- Sun, Y.; Chong, N.S.T.; Ochiai, H. Information Stealing in Federated Learning Systems Based on Generative Adversarial Networks. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; IEEE: New York, NY, USA, 2021; pp. 2749–2754. [Google Scholar] [CrossRef]
- Zhong, Z.; Zhou, Y.; Wu, D.; Chen, X.; Chen, M.; Li, C.; Sheng, Q.Z. FedAvg: Parallelizing Federated Learning with Theoretical Guarantees. In Proceedings of the IEEE Conference on Computer Communications (IEEE Infocom 2021), Vancouver, BC, Canada, 10–13 May 2021; IEEE: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Rjoub, G.; Wahab, O.A.; Bentahar, J.; Bataineh, A. Trust-Driven Reinforcement Selection Strategy for Federated Learning on IoT Devices. Computing 2022, 1–23. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Q.; Liang, H.; Gauri, J.; Poor, H.V. A Novel Framework for the Analysis and Design of Heterogeneous Federated Learning. IEEE Trans. Signal Process. 2021, 69, 5234–5249. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frameworks | Isolated Data Island Challenge | Incremental Data & Data Diversity Challenges | Computational Time Cost |
|---|---|---|---|
| Al-Sharman et al. [10] | ✕ | ✕ | ✕ |
| Zhang et al. [11] | ✕ | ✕ | ✓ |
| Wang et al. [21] | ✕ | ✕ | ✓ |
| Liang et al. [22] | ✓ | ✕ | ✓ |
| Hang et al. [25] | ✓ | ✕ | ✕ |
| Cui et al. [29] | ✕ | ✓ | ✓ |
| Symbols | Explanation | Symbols | Explanation |
|---|---|---|---|
| vehicle local dataset | local ML model parameters for the p-th vehicle | ||
| local ML model parameters | local model parameters of the i-th vehicle in the (t+1)th round | ||
| p | total number of vehicles | extractor | |
| i-th vehicle node | extractor parameters | ||
| The p-th vehicle participating in the calculation | classifier | ||
| local dataset of the p-th vehicle | classifier parameters | ||
| the i-th data in the p-th vehicle | L | number of neural network layers | |
| local raw label dataset | bias from layer l-1 to layer l | ||
| S | vehicle sample data volume | the input of the first layer neuron | |
| N | number of sample categories | l-1 layer parameter mapping result | |
| sample data | learning bias | ||
| sample label | A | number of convolution kernels | |
| incremental dataset of vehicle nodes at round t + 1 | image predicted category | ||
| W | all vehicle parameters | image real category |
| Parameter Category | Parameter Name | CIFAR-10 | Vehicle Image |
|---|---|---|---|
| CNN parameters | Number of input channels | 3 | 3 |
| Number of output channels | 5 | 1 | |
| Convolution kernel size | 5 * 5 | 2 * 2 | |
| Fully connected layer 1 | 64 * 4 * 4 | 61* 61 * 64 | |
| Fully connected layer 2 | 4 * 4 *16 | 4 * 4 * 16 | |
| Convolutional Layer 1 | 3, 64, 5 | 3, 32, 5, 1 | |
| Convolutional Layer 2 | 64, 64, 5 | 32, 64, 5, 1 | |
| Stride | 2 | 2 | |
| Padding | 0 | 0 | |
| Dilation | 1 | 1 | |
| Federated Learning Parameters | Global training rounds | 10 | |
| Local training rounds | 5 | ||
| Initial vehicles | 10 | ||
| Data Distribution | Non-iid | ||
| Learning rate | 0.01 | ||
| Decay rate | 0.1 | ||
| Processor | Cpu | ||
| Incremental data parameters | The number of images in the training set | 50,000 | 18,305 |
| The number of images in the testing set | 10,000 | 7845 | |
| Initial allocation quantity for each vehicle (round 1) | 2000 | 750 | |
| Allocation quantity for each vehicle (2nd to 10th rounds) | Initial * (1/R) * Rnd_Int Initial is the initial allocation quantity for each vehicle (round 1). R is the global training round (1∼10). Rnd_Int is a random real number between 1∼2. | ||
| Dataset | D-R Value | Local ML Model Training Time Per Round (Unit: Seconds) | Training Set Accuracy | Testing Set Accuracy | Testing Set Loss | Testing Set MCC |
|---|---|---|---|---|---|---|
| CIFAR-10 | 0.2 | 4.1257 | 0.9265 | 0.8623 | 0.0002573 | 0.7738 |
| 0.4 | 4.6481 | 0.9375 | 0.8845 | 0.0002467 | 0.6644 | |
| 0.6 | 4.8962 | 0.9414 | 0.9143 | 0.0002397 | 0.8014 | |
| 0.8 | 7.8413 | 0.9283 | 0.8926 | 0.0002372 | 0.8479 | |
| 1.0 | 10.9625 | 0.9224 | 0.8741 | 0.0002431 | 0.7738 | |
| Vehicle Image | 0.2 | 6.2590 | 0.9073 | 0.8687 | 0.0002545 | 0.8638 |
| 0.4 | 6.7105 | 0.9377 | 0.8520 | 0.0000284 | 0.8592 | |
| 0.6 | 6.2426 | 0.9631 | 0.9528 | 0.0000262 | 0.9172 | |
| 0.8 | 9.6470 | 0.9680 | 0.9461 | 0.0000478 | 0.9117 | |
| 1.0 | 13.0640 | 0.9279 | 0.9113 | 0.0004791 | 0.8633 |
| Training Time for Local ML Models | CIARF-10 (Unit: Second) | Vehicle Image (Unit: Second) |
|---|---|---|
| Fed-AVG | 3.4311 | 4.8437 |
| Fed-SGD | 4.9523 | 6.8524 |
| Fed-prox | 4.9354 | 6.1489 |
| Fed-IW&DS | 4.8962 | 6.2426 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, Y.; Wang, S.L.; Zhong, M.; Wang, M.; Ng, T.F. A Federated Learning Framework Based on Incremental Weighting and Diversity Selection for Internet of Vehicles. Electronics 2022, 11, 3668. https://doi.org/10.3390/electronics11223668
Lei Y, Wang SL, Zhong M, Wang M, Ng TF. A Federated Learning Framework Based on Incremental Weighting and Diversity Selection for Internet of Vehicles. Electronics. 2022; 11(22):3668. https://doi.org/10.3390/electronics11223668
Chicago/Turabian StyleLei, Yuan, Shir Li Wang, Minghui Zhong, Meixia Wang, and Theam Foo Ng. 2022. "A Federated Learning Framework Based on Incremental Weighting and Diversity Selection for Internet of Vehicles" Electronics 11, no. 22: 3668. https://doi.org/10.3390/electronics11223668