

Gated Multi-Attention Feedback Network for Medical Image Super-Resolution
 and
and
Abstract
:1. Introduction
- An LAFE module is designed to highlight the vital feature information while removing redundancy to refine the feature map.
- A CSAR module that can facilitate an information exchange between different channel dimensions is built to enhance the representation of semantic feature maps.
- A gradient variance loss is tailored to guide the model learning for the generation of images with rich texture details and sharp edges.
2. Related Work
2.1. Feedback Mechanism
2.2. Attention Mechanism
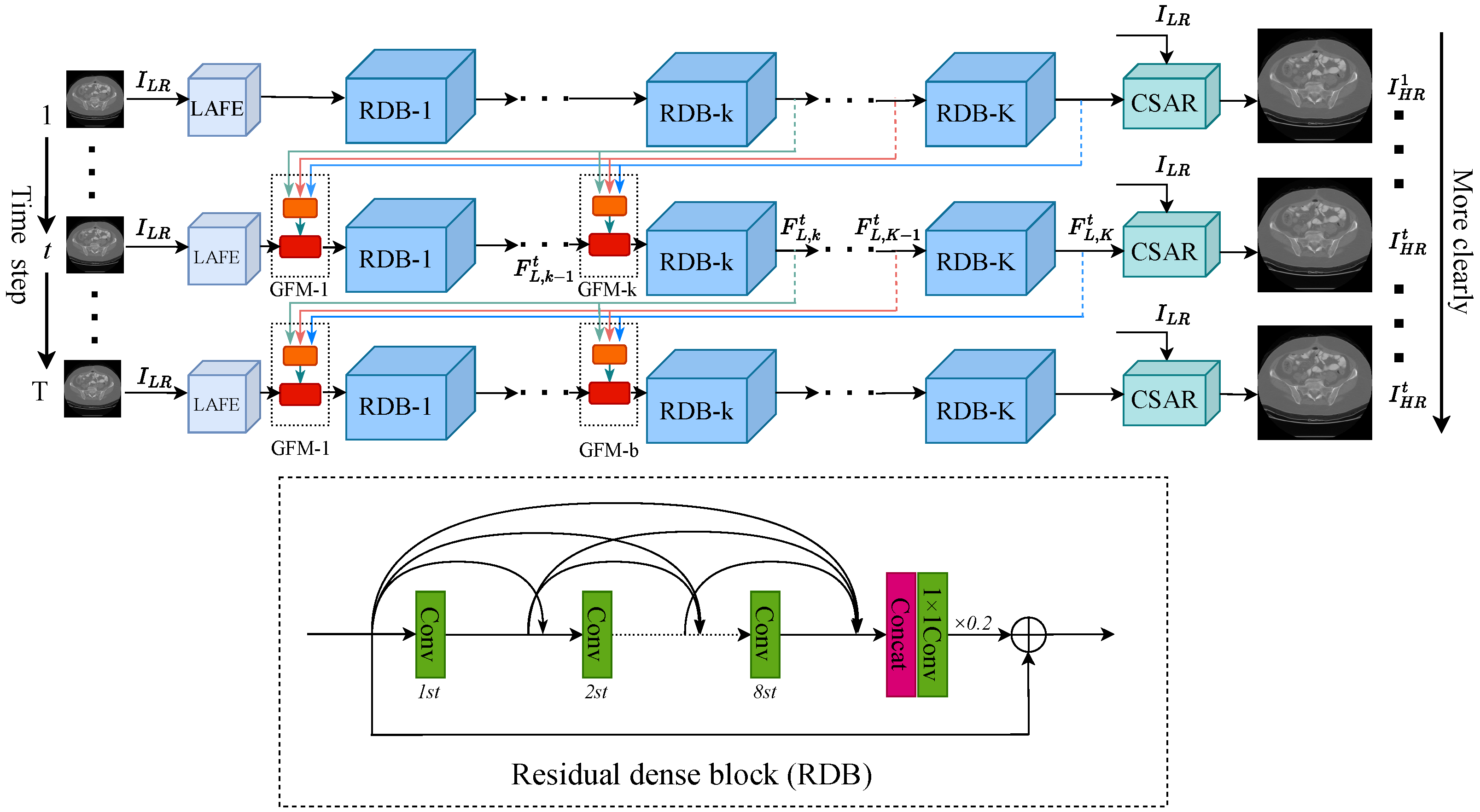
3. The Proposed Approach
3.1. Network Design
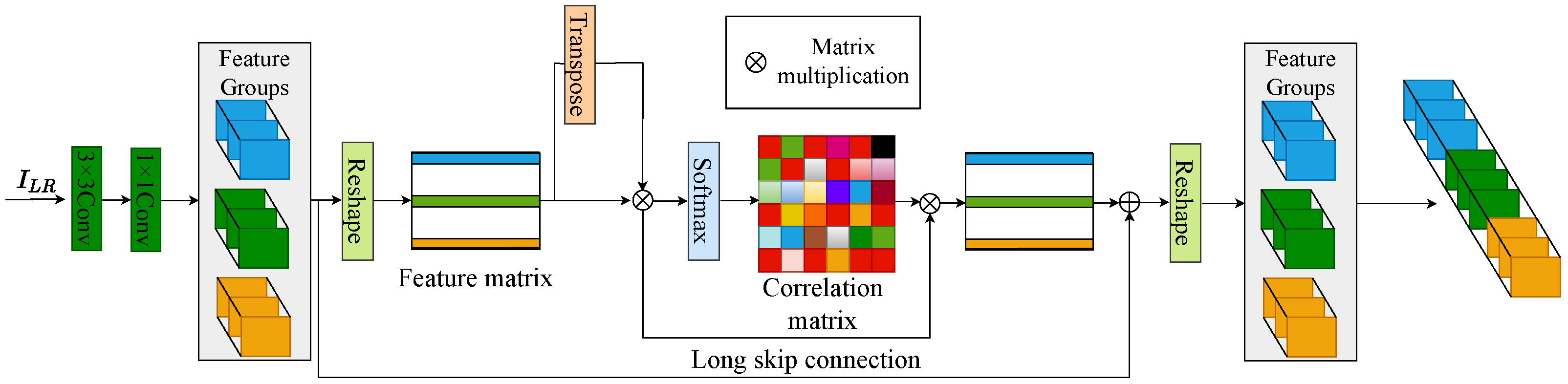
3.2. Layer Attention Feature Extraction Module
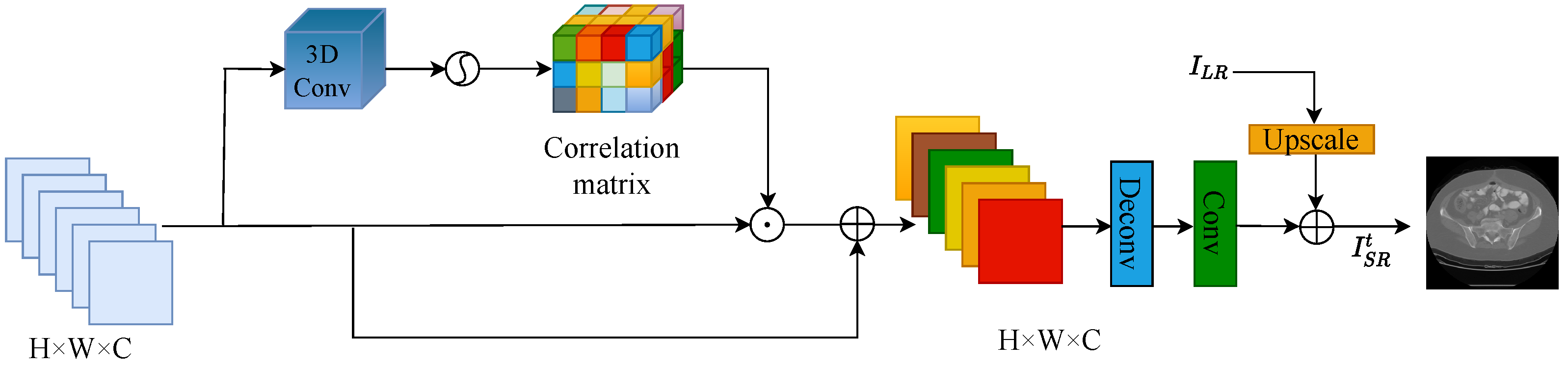
3.3. Channel-Spatial Attention Reconstruction Module
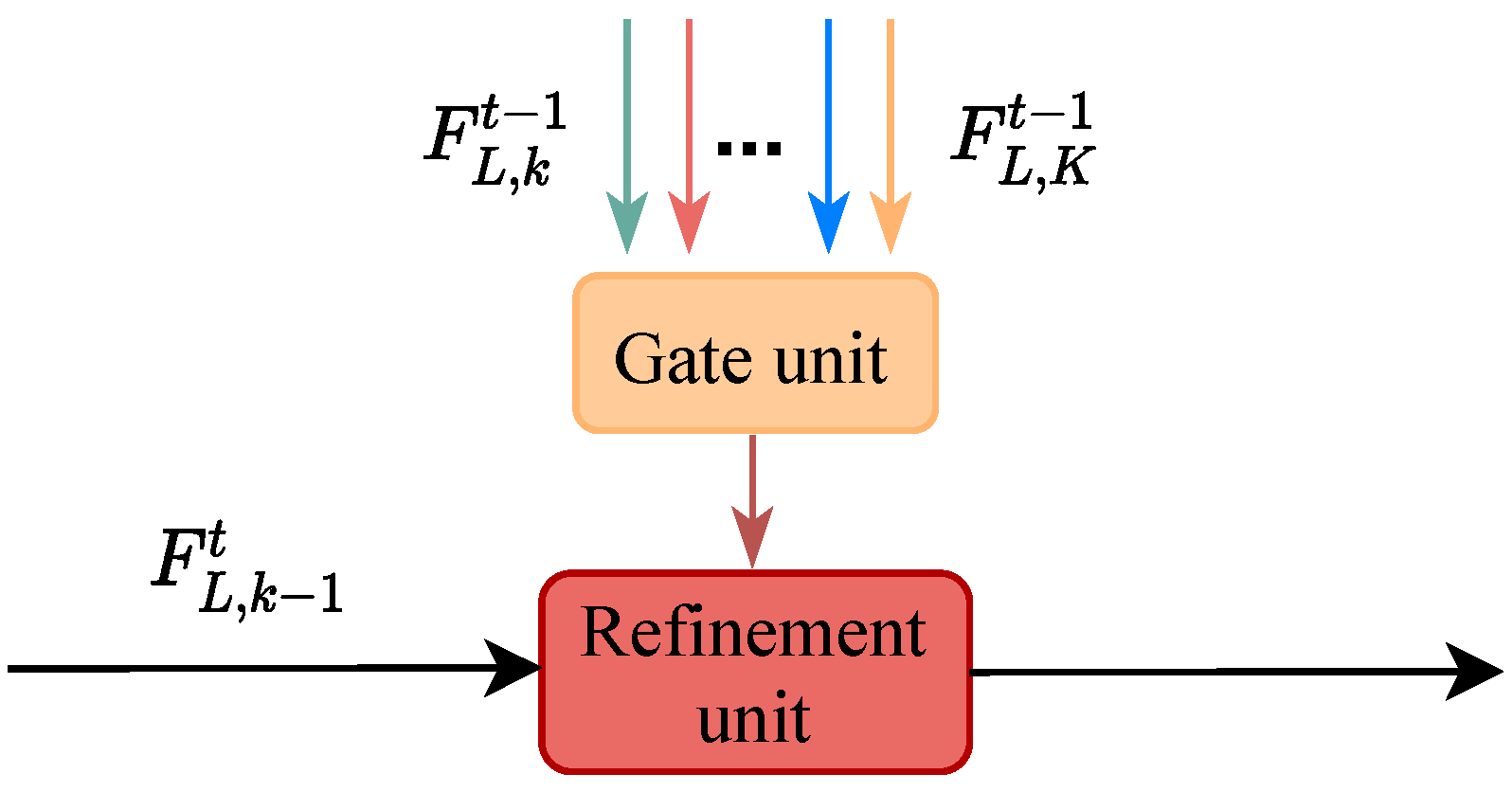
3.4. Gated Feedback Module
3.5. Gradient Variance Loss
4. Experiments and Discussion
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
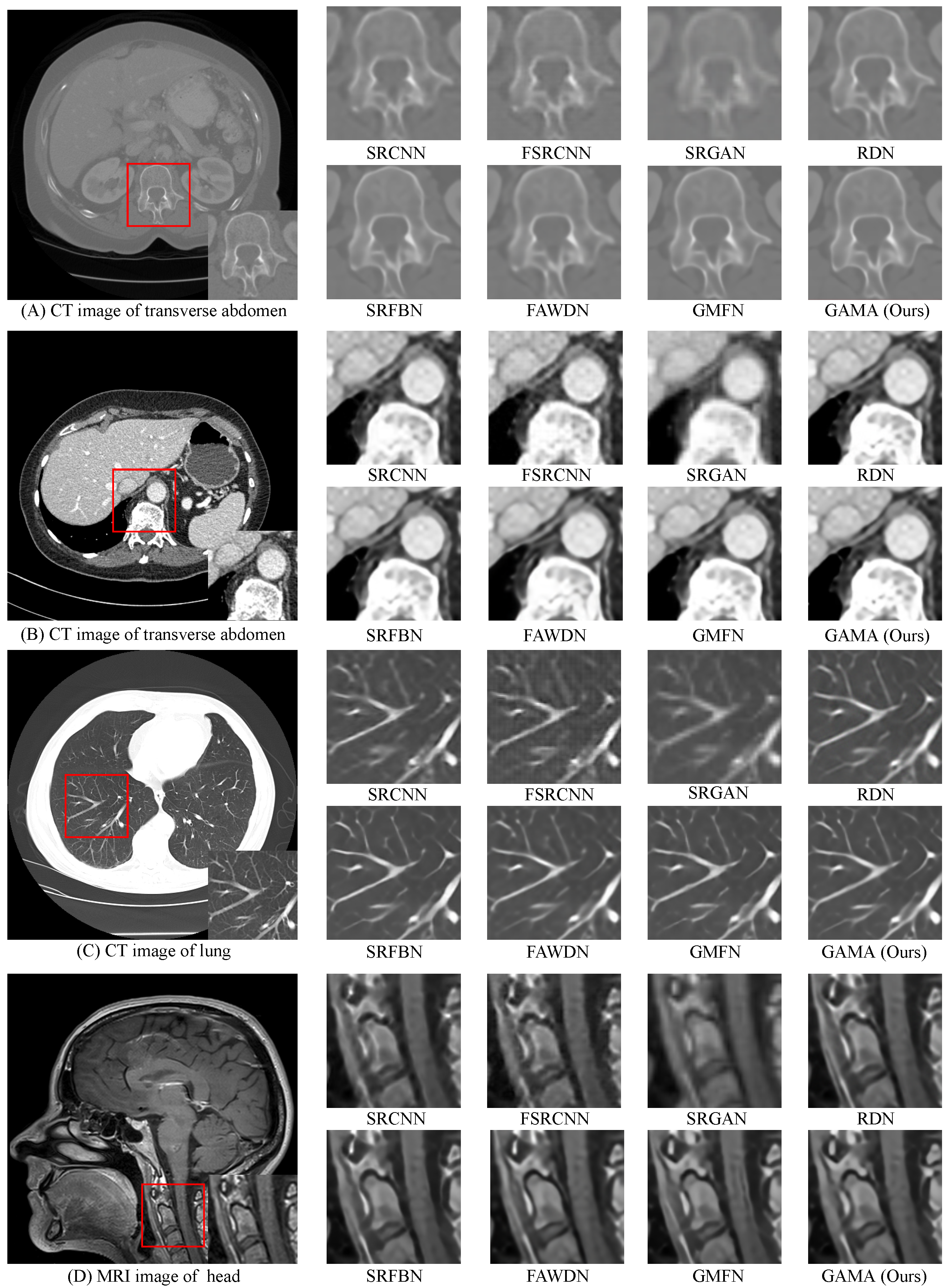
4.4. Comparative Analysis
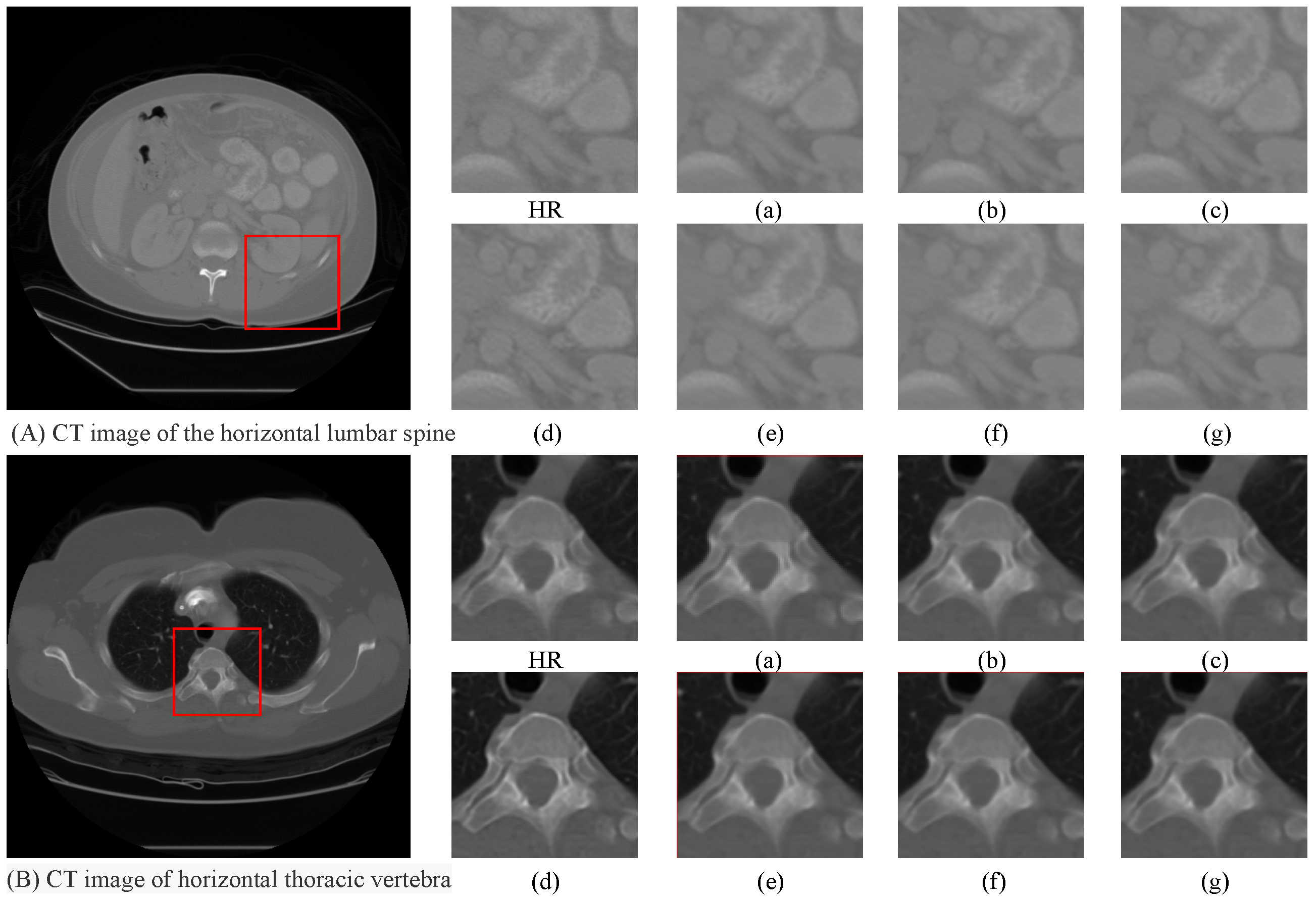
4.5. Ablation Study
- (a)
- “baseline” represents the basic model without the LAFE, CSAR, and .
- (b)
- “baseline + LAFE” refers to the “baseline” with the LAFE module.
- (c)
- “baseline + CSAR” denotes the “baseline” with the CSAR module.
- (d)
- “baseline + LAFE + CSAR” represents the “baseline” with the LAFE module and CSAR module.
- (e)
- “baseline + LAFE + ” refers to the “baseline” with the LAFE module and .
- (f)
- “baseline + CSAR + ” denotes the “baseline” with the CSAR module and .
- (g)
- “baseline + LAFE + CSAR + ” represents the final GAMA.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Su, H.; Zhou, J.; Zhang, Z.H. Survey of super-resolution image reconstruction methods. Acta Autom. Sin. 2013, 39, 1202–1213. [Google Scholar] [CrossRef]
- Chavez, H.; Gonzalez, V.; Hernandez, A.; Ponomaryov, V. Super resolution imaging via sparse interpolation in wavelet domain with implementation in DSP and GPU. In Proceedings of the Iberoamerican Congress on Pattern Recognition, Puerto Vallarta, Mexico, 2–5 November 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 973–981. [Google Scholar]
- Li, Y.; Sixou, B.; Peyrin, F. A review of the deep learning methods for medical images super resolution problems. IRBM 2021, 42, 120–133. [Google Scholar] [CrossRef]
- Lehmann, T.M.; Gonner, C.; Spitzer, K. Survey: Interpolation methods in medical image processing. IEEE Trans. Med. Imaging 1999, 18, 1049–1075. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mu, S.; Zhang, Y.; Qian, X.; Jiang, Y. Research on Super-Resolution Enhancement Algorithm Based on Skip Residual Dense Network. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Gerchberg, R. Super-resolution through error energy reduction. Opt. Acta Int. J. Opt. 1974, 21, 709–720. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3867–3876. [Google Scholar]
- Li, Q.; Li, Z.; Lu, L.; Jeon, G.; Liu, K.; Yang, X. Gated multiple feedback network for image super-resolution. arXiv 2019, arXiv:1907.04253. [Google Scholar]
- Pradhan, A.K.; Mishra, D.; Das, K.; Obaidat, M.S.; Kumar, M. A COVID-19 X-ray image classification model based on an enhanced convolutional neural network and hill climbing algorithms. Multimed. Tools Appl. 2022, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Raheja, S.; Kasturia, S.; Cheng, X.; Kumar, M. Machine learning-based diffusion model for prediction of coronavirus-19 outbreak. Neural Comput. Appl. 2021, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Blau, Y.; Mechrez, R.; Timofte, R.; Michaeli, T.; Zelnik-Manor, L. The 2018 pirm challenge on perceptual image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Jin, X.; Chen, Y.; Jie, Z.; Feng, J.; Yan, S. Multi-path feedback recurrent neural networks for scene parsing. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, G. Progressive attention guided recurrent network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 714–722. [Google Scholar]
- Chen, L.; Yang, X.; Jeon, G.; Anisetti, M.; Liu, K. A trusted medical image super-resolution method based on feedback adaptive weighted dense network. Artif. Intell. Med. 2020, 106, 101857. [Google Scholar] [CrossRef] [PubMed]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4733–4742. [Google Scholar]
- Cao, C.; Liu, X.; Yang, Y.; Yu, Y.; Wang, J.; Wang, Z.; Huang, Y.; Wang, L.; Huang, C.; Xu, W.; et al. Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2956–2964. [Google Scholar]
- Zamir, A.R.; Wu, T.L.; Sun, L.; Shen, W.B.; Shi, B.E.; Malik, J.; Savarese, S. Feedback networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1308–1317. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Han, W.; Chang, S.; Liu, D.; Yu, M.; Witbrock, M.; Huang, T.S. Image super-resolution via dual-state recurrent networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1654–1663. [Google Scholar]
- Sam, D.B.; Babu, R.V. Top-down feedback for crowd counting convolutional neural network. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, J.; Wu, J.; Wu, Z.; Anisetti, M.; Jeon, G. Bayesian method application for color demosaicking. Opt. Eng. 2018, 57, 053102. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Kim, J.H.; Choi, J.H.; Cheon, M.; Lee, J.S. Ram: Residual attention module for single image super-resolution. arXiv 2018, arXiv:1811.12043. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Abrahamyan, L.; Truong, A.M.; Philips, W.; Deligiannis, N. Gradient variance loss for structure-enhanced image super-resolution. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3219–3223. [Google Scholar]
- McCollough, C.; Chen, B.; Holmes, D.; Duan, X.; Yu, Z.; Xu, L.; Leng, S.; Fletcher, J. Low Dose CT Image and Projection Data [Data Set]. The Cancer Imaging Archive. 2020. Available online: https://wiki.cancerimagingarchive.net/pages/viewpage.action?pageId=52758026 (accessed on 21 October 2022).
- Kalpathy-Cramer, J.; Napel, S.; Goldgof, D.; Zhao, B. QIN multi-site collection of Lung CT data with nodule segmentations. Cancer Imaging Arch. 2015, 10, K9. [Google Scholar]
- Wei, S.; Wu, W.; Jeon, G.; Ahmad, A.; Yang, X. Improving resolution of medical images with deep dense convolutional neural network. Concurr. Comput. Pract. Exp. 2020, 32, e5084. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Georgescu, M.I.; Ionescu, R.T.; Miron, A.I.; Savencu, O.; Ristea, N.C.; Verga, N.; Khan, F.S. Multimodal Multi-Head Convolutional Attention with Various Kernel Sizes for Medical Image Super-Resolution. arXiv 2022, arXiv:2204.04218. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- Kumar, S.; Gupta, S.K.; Kumar, V.; Kumar, M.; Chaube, M.K.; Naik, N.S. Ensemble multimodal deep learning for early diagnosis and accurate classification of COVID-19. Comput. Electr. Eng. 2022, 103, 108396. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Scale | LDCT Part_A | LDCT Part_B | QIN LUNG CT | MRI13 | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| SRCNN [7] | 43.79 | 0.9822 | 33.82 | 0.9488 | 34.20 | 0.9352 | 39.32 | 0.9716 | |
| FSRCNN [36] | 44.14 | 0.9837 | 34.39 | 0.9502 | 35.65 | 0.9362 | 41.32 | 0.9769 | |
| SRGAN [12] | 39.80 | 0.9652 | 32.92 | 0.9463 | 27.55 | 0.8426 | 33.43 | 0.9671 | |
| RDN [37] | 44.53 | 0.9841 | 35.05 | 0.9508 | 37.15 | 0.9401 | 41.72 | 0.9785 | |
| SRFBN [8] | 47.32 | 0.9878 | 35.41 | 0.9523 | 38.49 | 0.9800 | 42.01 | 0.9828 | |
| FAWDN [16] | 47.11 | 0.9877 | 34.78 | 0.9518 | 39.07 | 0.9817 | 43.59 | 0.9851 | |
| GMFN [9] | 48.66 | 0.9886 | 35.42 | 0.9529 | 38.58 | 0.9802 | 42.49 | 0.9836 | |
| GAMA (Ours) | 48.73 | 0.9887 | 35.90 | 0.9550 | 42.35 | 0.9835 | 43.08 | 0.9844 | |
| SRCNN [7] | 39.12 | 0.9633 | 29.86 | 0.8072 | 31.85 | 0.8578 | 33.57 | 0.9255 | |
| FSRCNN [36] | 38.87 | 0.9623 | 30.19 | 0.8116 | 32.28 | 0.8612 | 34.85 | 0.9357 | |
| SRGAN [12] | - | - | - | - | - | - | - | - | |
| RDN [37] | 44.70 | 0.9668 | 31.79 | 0.8853 | 33.24 | 0.8911 | 34.98 | 0.9381 | |
| SRFBN [8] | 44.16 | 0.9804 | 31.75 | 0.8843 | 34.55 | 0.9512 | 35.46 | 0.9420 | |
| FAWDN [16] | 43.30 | 0.9792 | 30.97 | 0.8797 | 33.73 | 0.9498 | 36.73 | 0.9479 | |
| GMFN [9] | 44.80 | 0.9630 | 31.84 | 0.8856 | 34.55 | 0.9516 | 35.98 | 0.9443 | |
| GAMA (Ours) | 45.25 | 0.9814 | 32.08 | 0.8886 | 36.69 | 0.9581 | 36.24 | 0.9454 | |
| SRCNN [7] | 36.63 | 0.9465 | 28.46 | 0.8337 | 27.48 | 0.8381 | 30.44 | 0.8774 | |
| FSRCNN [36] | 37.06 | 0.9363 | 28.49 | 0.8215 | 27.55 | 0.8668 | 31.43 | 0.8924 | |
| SRGAN [12] | 35.99 | 0.9308 | 27.92 | 0.8306 | 24.44 | 0.8097 | 28.15 | 0.8488 | |
| RDN [37] | 40.78 | 0.9546 | 29.83 | 0.8346 | 30.43 | 0.8462 | 31.91 | 0.8974 | |
| SRFBN [8] | 41.05 | 0.9714 | 30.06 | 0.8398 | 31.78 | 0.9226 | 32.20 | 0.8981 | |
| FAWDN [16] | 40.59 | 0.9703 | 28.90 | 0.8295 | 30.60 | 0.9180 | 33.21 | 0.9086 | |
| GMFN [9] | 42.55 | 0.9748 | 30.02 | 0.8386 | 31.70 | 0.9237 | 32.58 | 0.9022 | |
| GAMA (Ours) | 43.16 | 0.9758 | 30.34 | 0.8436 | 33.95 | 0.9363 | 32.84 | 0.9043 | |
| Components | PSNR | SSIM |
|---|---|---|
| (a) baseline | 48.66 | 0.9886 |
| (b) baseline + LAFE | 48.67 | 0.9887 |
| (c) baseline + CSAR | 48.68 | 0.9887 |
| (d) baseline + LAEF + CSAR | 48.71 | 0.9887 |
| (e) baseline + LAFE + | 48.73 | 0.9887 |
| (f) baseline + CSAR + | 48.70 | 0.9987 |
| (g) baseline + LAFE + CSAR + (Ours) | 48.75 | 0.9887 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shang, J.; Zhang, X.; Zhang, G.; Song, W.; Chen, J.; Li, Q.; Gao, M. Gated Multi-Attention Feedback Network for Medical Image Super-Resolution. Electronics 2022, 11, 3554. https://doi.org/10.3390/electronics11213554
Shang J, Zhang X, Zhang G, Song W, Chen J, Li Q, Gao M. Gated Multi-Attention Feedback Network for Medical Image Super-Resolution. Electronics. 2022; 11(21):3554. https://doi.org/10.3390/electronics11213554
Chicago/Turabian StyleShang, Jianrun, Xue Zhang, Guisheng Zhang, Wenhao Song, Jinyong Chen, Qilei Li, and Mingliang Gao. 2022. "Gated Multi-Attention Feedback Network for Medical Image Super-Resolution" Electronics 11, no. 21: 3554. https://doi.org/10.3390/electronics11213554