


BTM: Boundary Trimming Module for Temporal Action Detection
Abstract
:1. Introduction
2. Related Work
3. Approach
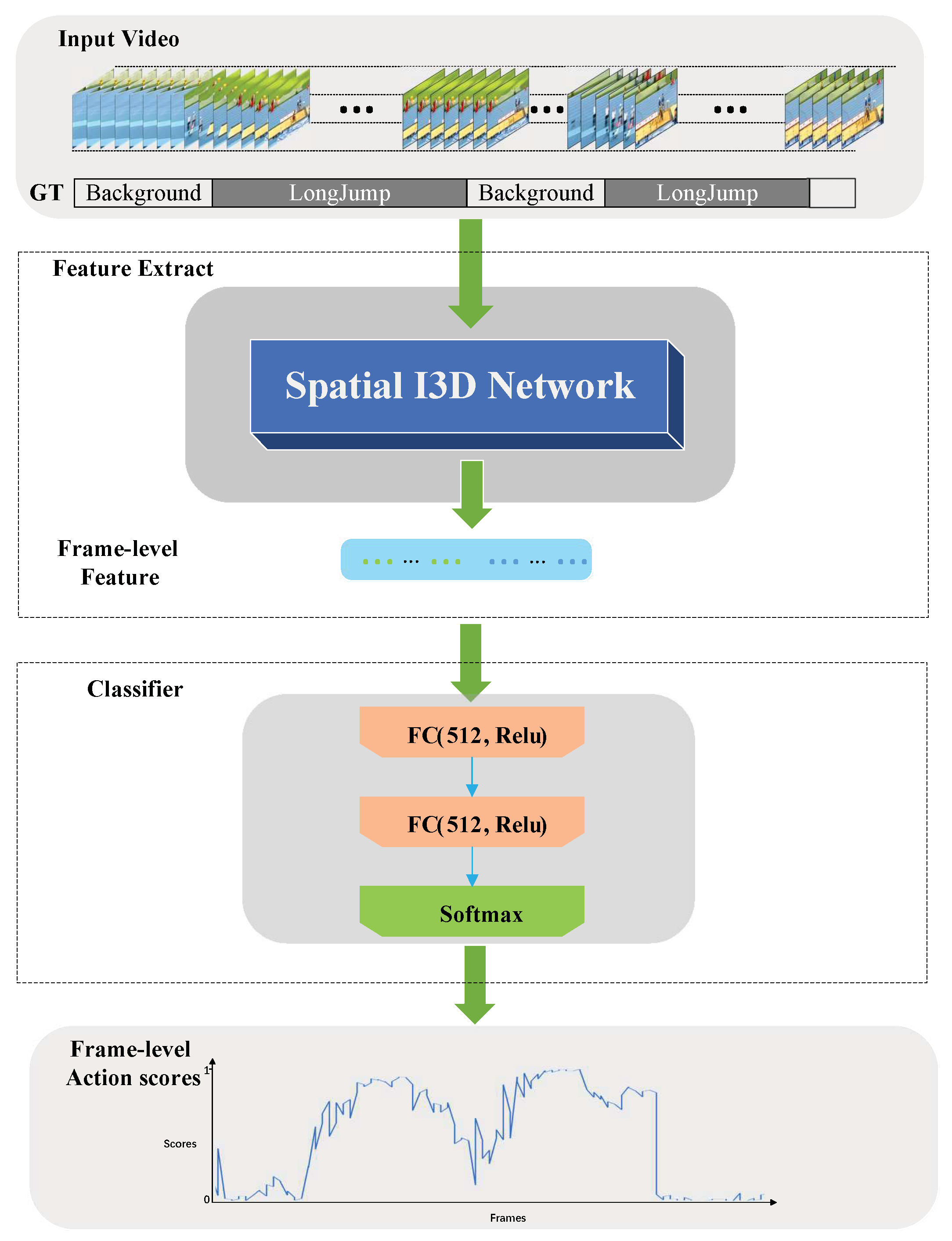
3.1. Action Estimation Network
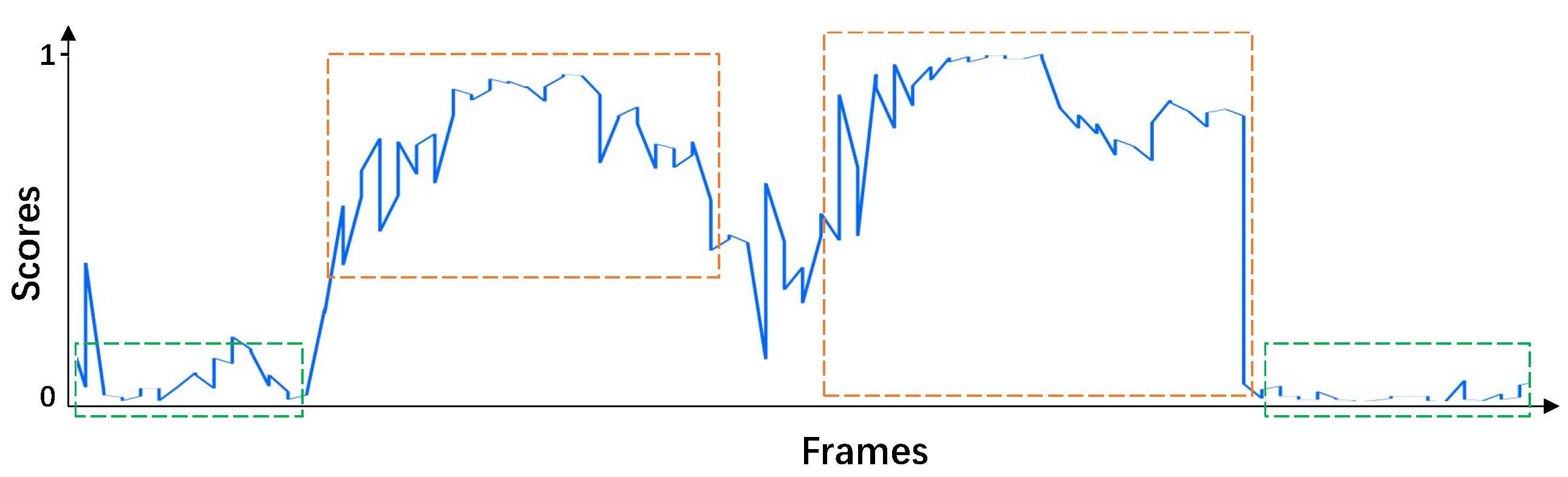
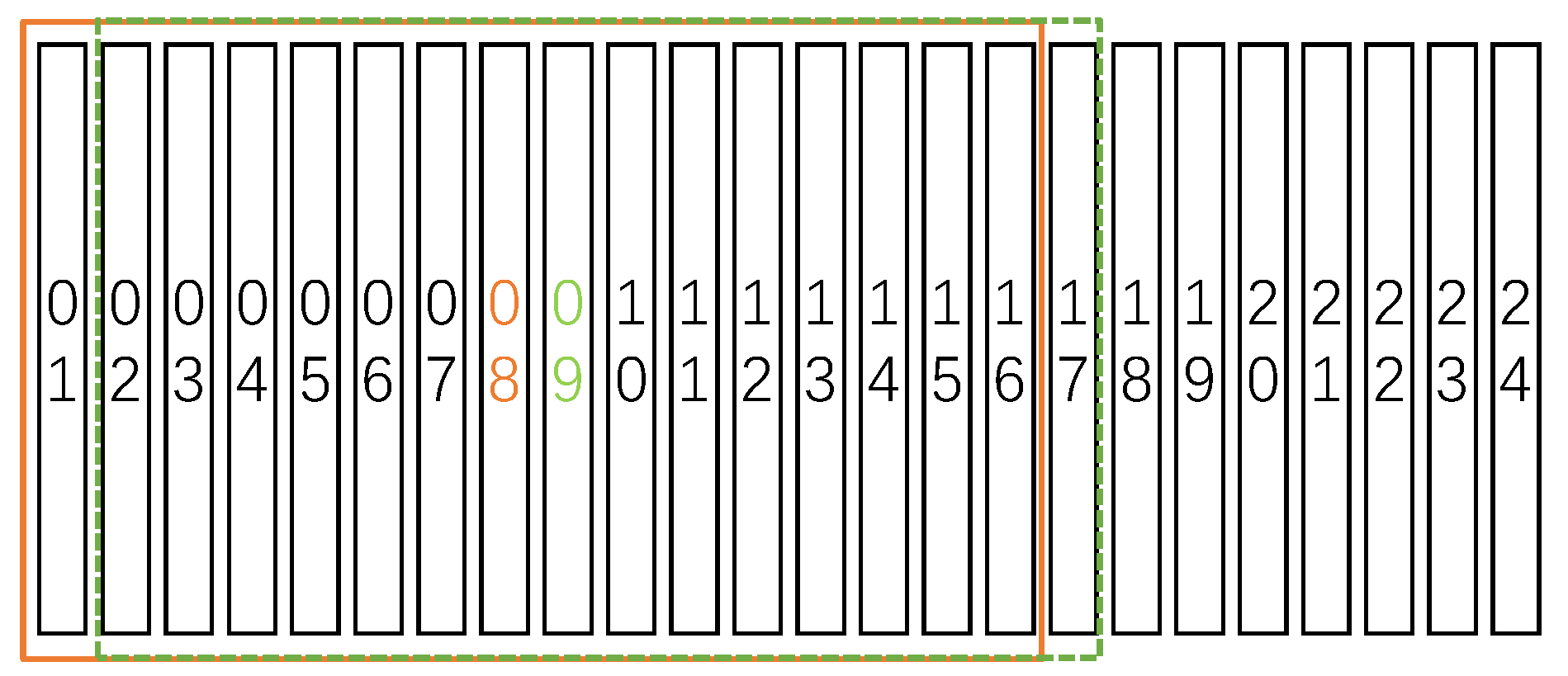
3.2. Timing Boundary Trimming Strategy
| Algorithm 1 Adjust start frame |
Reference range ← m frames before and after the average action score of the frames in the reference range whiledo If then else end if end while |
4. Experiment and Simulation
4.1. Data Sets and Evaluation Indicators
4.2. Implementation Details
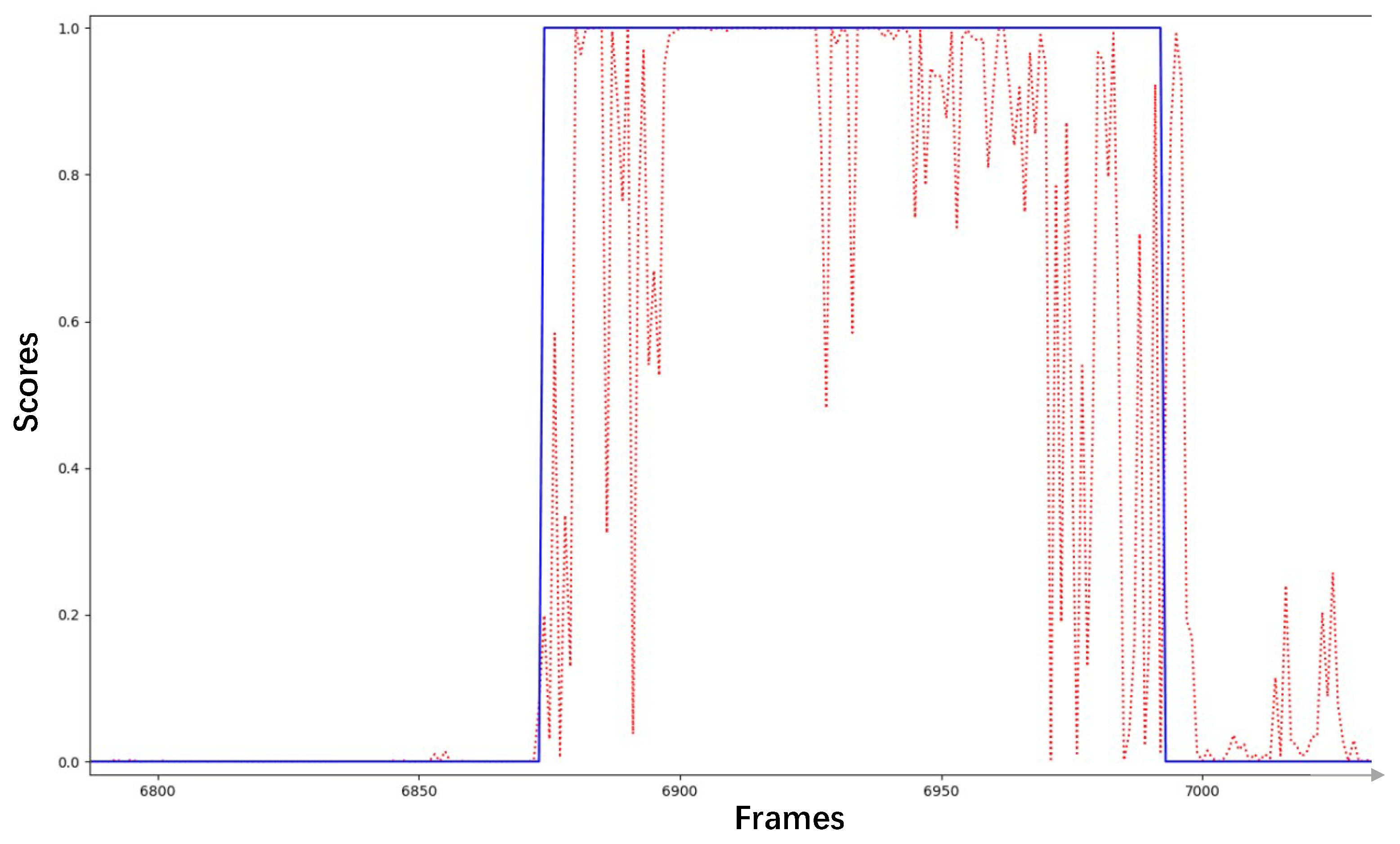
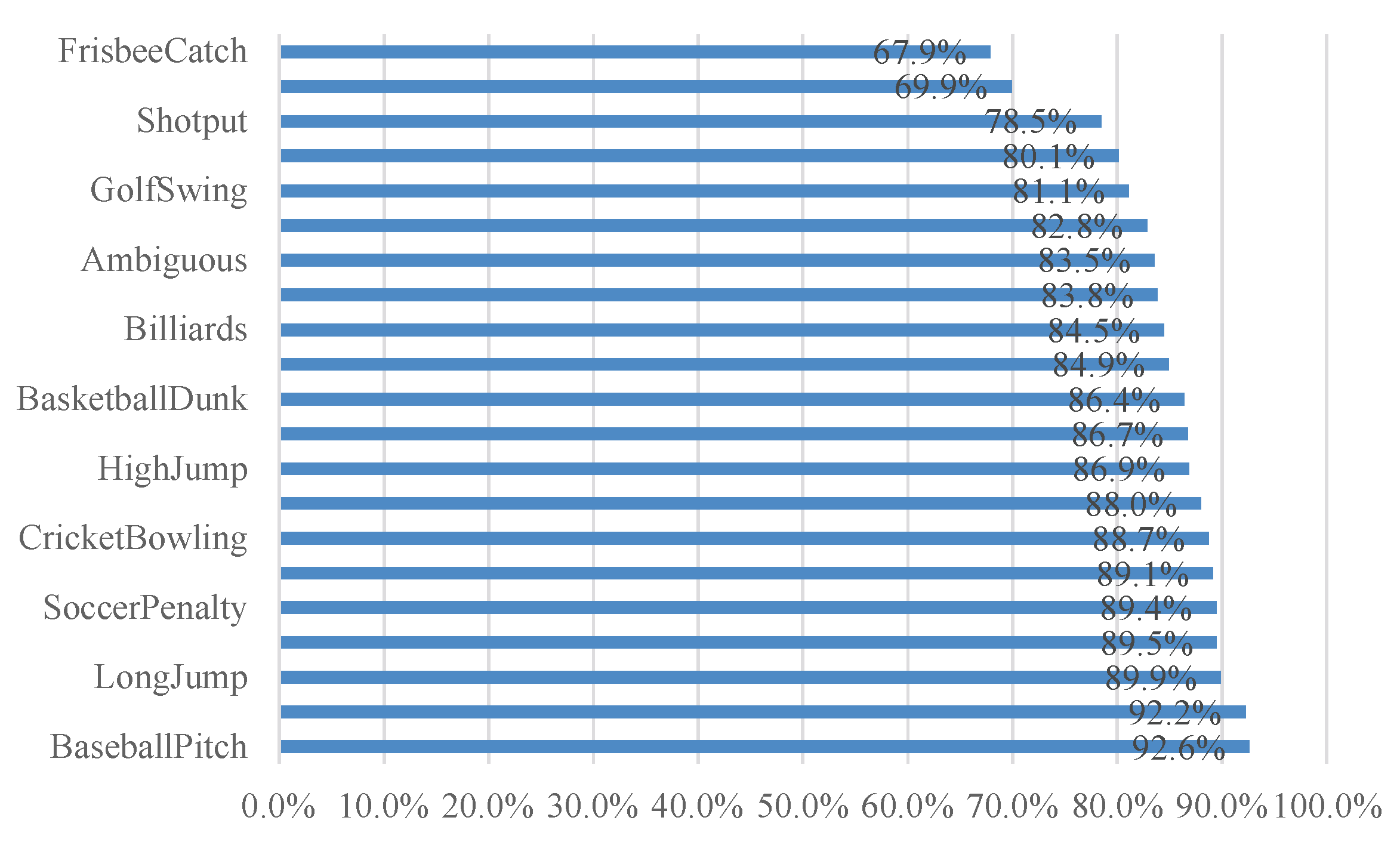
4.3. Simulation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yeung, S.; Russakovsky, O.; Mori, G.; Lei, F.-F. End-to-end learning of action detection from frame glimpses in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2678–2687. [Google Scholar]
- Yuan, J.; Ni, B.; Yang, X.; Kassim, A.A. Temporal action localization with pyramid of score distribution features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3093–3102. [Google Scholar]
- Shou, Z.; Wang, D.; Chang, S.F. Temporal action localization in untrimmed videos via multi-stage cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1049–1058. [Google Scholar]
- Zhu, Y.; Newsam, S. Efficient action detection in untrimmed videos via multi-task learning. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 197–206. [Google Scholar]
- Chao, Y.W.; Vijayanarasimhan, S.; Seybold, B.; Ross, D.A.; Deng, J.; Sukthankar, R. Rethinking the Faster R-CNN Architecture for Temporal Action Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1130–1139. [Google Scholar]
- Zhao, Y.; Xiong, Y.; Wang, L.; Wu, Z.; Tang, X.; Lin, D. Temporal action detection with structured segment networks. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2914–2923. [Google Scholar]
- Xu, H.; Das, A.; Saenko, K. R-C3D: Region convolutional 3d network for temporal activity detection. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 5794–5803. [Google Scholar]
- Peng, Y.; Zhao, Y.; Zhang, J. Two-stream collaborative learning with spatial-temporal attention for video classification. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 773–786. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Zhang, X.; Xiong, H.; Lin, W.; Tian, Q. Weak to Strong Detector Learning for Simultaneous Classification and Localization. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 418–432. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.; Zhao, X.; Shou, Z. Single shot temporal action detection. In Proceedings of the 2017 ACM on Multimedia Conference, Mountain View, CA, USA, 23–27 October 2017; pp. 988–996. [Google Scholar]
- Choi, G.; Heo, P.G.; Park, H.W. Triple-Frame-Based Bi-Directional Motion Estimation for Motion-Compensated Frame Interpolation. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1251–1258. [Google Scholar] [CrossRef]
- Wen, S.; Liu, W.; Yang, Y.; Huang, T.; Zeng, Z. Generating realistic videos from keyframes with concatenated GANs. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2337–2348. [Google Scholar] [CrossRef]
- Shou, Z.; Chan, J.; Zareian, A.; Miyazawa, K.; Chang, S.F. Cdc: Convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos. In Proceedings of the Computer Vision and Pattern Recognition (CVPR) 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1417–1426. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6546–6555. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- Diba, A.; Fayyaz, M.; Sharma, V.; Karami, A.H.; Arzani, M.M.; Yousefzadeh, R.; Van Gool, L. Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv 2017, arXiv:1711.08200. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Andriyanov, N.; Dementiev, V.; Kondratiev, D. Tracking of Objects in Video Sequences. In Proceedings of the Intelligent Decision Technologies; Czarnowski, I., Howlett, R.J., Jain, L.C., Eds.; Springer: Singapore, 2021; pp. 253–262. [Google Scholar]
- Abdu-Aguye, M.; Gomaa, W. Novel Approaches to Activity Recognition Based on Vector Autoregression and Wavelet Transforms. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 951–954. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Evdokimova, V.; Petrov, M.; Klyueva, M.; Zybin, E.; Kosianchuk, V.; Mishchenko, I.; Novikov, V.; Selvesiuk, N.; Ershov, E.; Ivliev, N.; et al. Deep learning-based video stream reconstruction in mass-production diffractive optical systems. Comput. Opt. 2021, 45, 130–141. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Jiang, Y.; Liu, J.; Zamir, A.R.; Toderici, G.; Laptev, I.; Shah, M.; Sukthankar, R. THUMOS Challenge: Action Recognition with a Large Number of Classes. 2014. Available online: https://www.crcv.ucf.edu/THUMOS14/home.html (accessed on 1 October 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Gao, J.; Yang, Z.; Sun, C.; Chen, K.; Nevatia, R. Turn Tap: Temporal Unit Regression Network for Temporal Action Proposals. arXiv 2017, arXiv:1703.06189. [Google Scholar]
- Dai, X.; Singh, B.; Zhang, G.; Davis, L.S.; Chen, Y.Q. Temporal context network for activity localization in videos. In Proceedings of the Computer Vision (ICCV), 2017 IEEE International Conference, Venice, Italy, 22–29 October 2017; pp. 5727–5736. [Google Scholar]
- Hou, R.; Sukthankar, R.; Shah, M. Real-time temporal action localization in untrimmed videos by sub-action discovery. In Proceedings of the BMVC, London, UK, 4–7 September 2017. [Google Scholar]
- Buch, S.; Escorcia, V.; Ghanem, B.; Fei-Fei, L.; Niebles, J. End-to-end, single-stream temporal action detection in untrimmed videos. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017. [Google Scholar]
- Yuan, Z.H.; Stroud, J.C.; Lu, T.; Deng, J. Temporal Action Localization by Structured Maximal Sums. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Buch, S.; Escorcia, V.; Shen, C.; Ghanem, B.; Niebles, J.C. Sst: Single-stream temporal action proposals. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6373–6382. [Google Scholar]
- Escorcia, V.; Heilbron, F.C.; Niebles, J.C.; Ghanem, B. Daps: Deep action proposals for action understanding. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 768–784. [Google Scholar]
- Richard, A.; Gall, J. Temporal action detection using a statistical language model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3131–3140. [Google Scholar]
- Caba Heilbron, F.; Carlos Niebles, J.; Ghanem, B. Fast temporal activity proposals for efficient detection of human actions in untrimmed videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1914–1923. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Lin, T.; Zhao, X.; Su, H.; Wang, C.; Yang, M. BSN: Boundary Sensitive Network for Temporal Action Proposal Generation. arXiv 2018, arXiv:1806.02964. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Chen, Y.; Kalantidis, Y.; Li, J.; Yan, S.; Feng, J. Multi-fiber networks for video recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 352–367. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Zach, C.; Pock, T.; Bischof, H. A duality based approach for realtime TV-L 1 optical flow. In Proceedings of the Joint Pattern Recognition Symposium; Springer: Berlin/Heidelberg, Germany, 2007; pp. 214–223. [Google Scholar]
- Graves, A. Supervised sequence labelling. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Cham, Switzerland, 2012; pp. 5–13. [Google Scholar]
- Gao, J.; Yang, Z.; Nevatia, R. Cascaded boundary regression for temporal action detection. arXiv 2017, arXiv:1705.01180. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IOU | 0.1 | 0.3 | 0.5 | 0.7 |
|---|---|---|---|---|
| Xu et al. [47] | 54.5 | 44.8 | 28.9 | - |
| BTM + Xu et al. | 55.6 | 45.3 | 32.4 | - |
| Gao et al. [48] | 60.1 | 50.1 | 31.0 | 9.9 |
| BTM + Gao et al. | 60.8 | 52.1 | 35.6 | 14.3 |
| Lin et al. [42] | - | 53.5 | 36.9 | 20.0 |
| BTM + Lin et al. | - | 54.3 | 38.3 | 21.1 |
| Chao et al. [5] | 59.8 | 53.2 | 42.8 | 20.8 |
| BTM + Chao et al. | 60.4 | 53.8 | 44.6 | 24.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hamdi, M.; Wen, S.; Yang, Y. BTM: Boundary Trimming Module for Temporal Action Detection. Electronics 2022, 11, 3520. https://doi.org/10.3390/electronics11213520
Hamdi M, Wen S, Yang Y. BTM: Boundary Trimming Module for Temporal Action Detection. Electronics. 2022; 11(21):3520. https://doi.org/10.3390/electronics11213520
Chicago/Turabian StyleHamdi, Maher, Shiping Wen, and Yin Yang. 2022. "BTM: Boundary Trimming Module for Temporal Action Detection" Electronics 11, no. 21: 3520. https://doi.org/10.3390/electronics11213520