


Augmented Lagrangian-Based Reinforcement Learning for Network Slicing in IIoT
 ,
,
Abstract
:1. Introduction
- A two-stage action selection is designed by considering a hierarchical policy network to solve the hybrid action space problem in RL, which can significantly reduce the action space;
- A penalty-based piece-wise reward function and a constraint-handling part involving neural networks for Lagrangian multipliers and cost functions are introduced to solve the constraint problem;
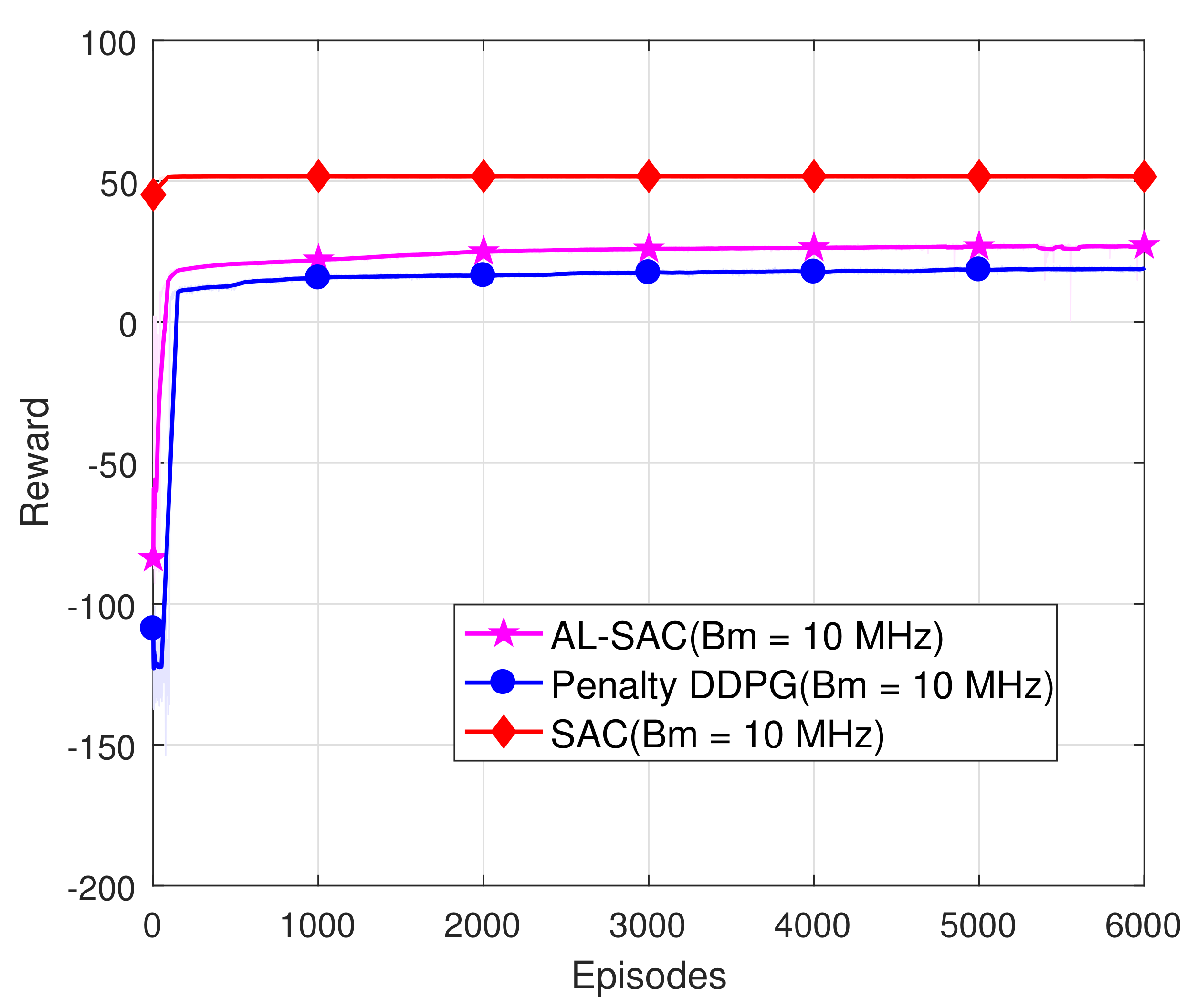
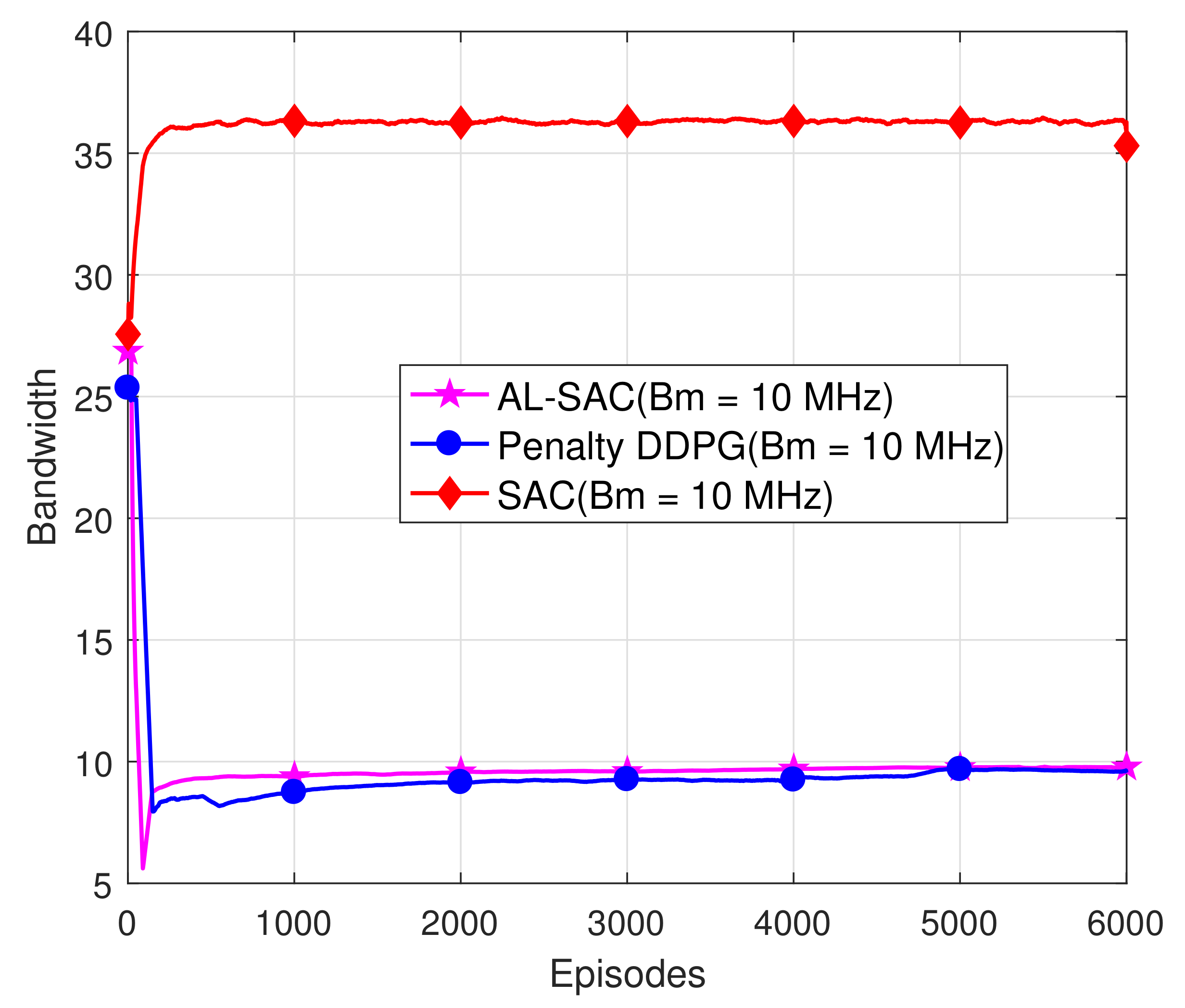
- Simulation results show that our proposed algorithm satisfies the constraints, and AL-SAC has a higher reward value than the DDPG algorithm with a penalty item.
2. System Model and Problem Formulation
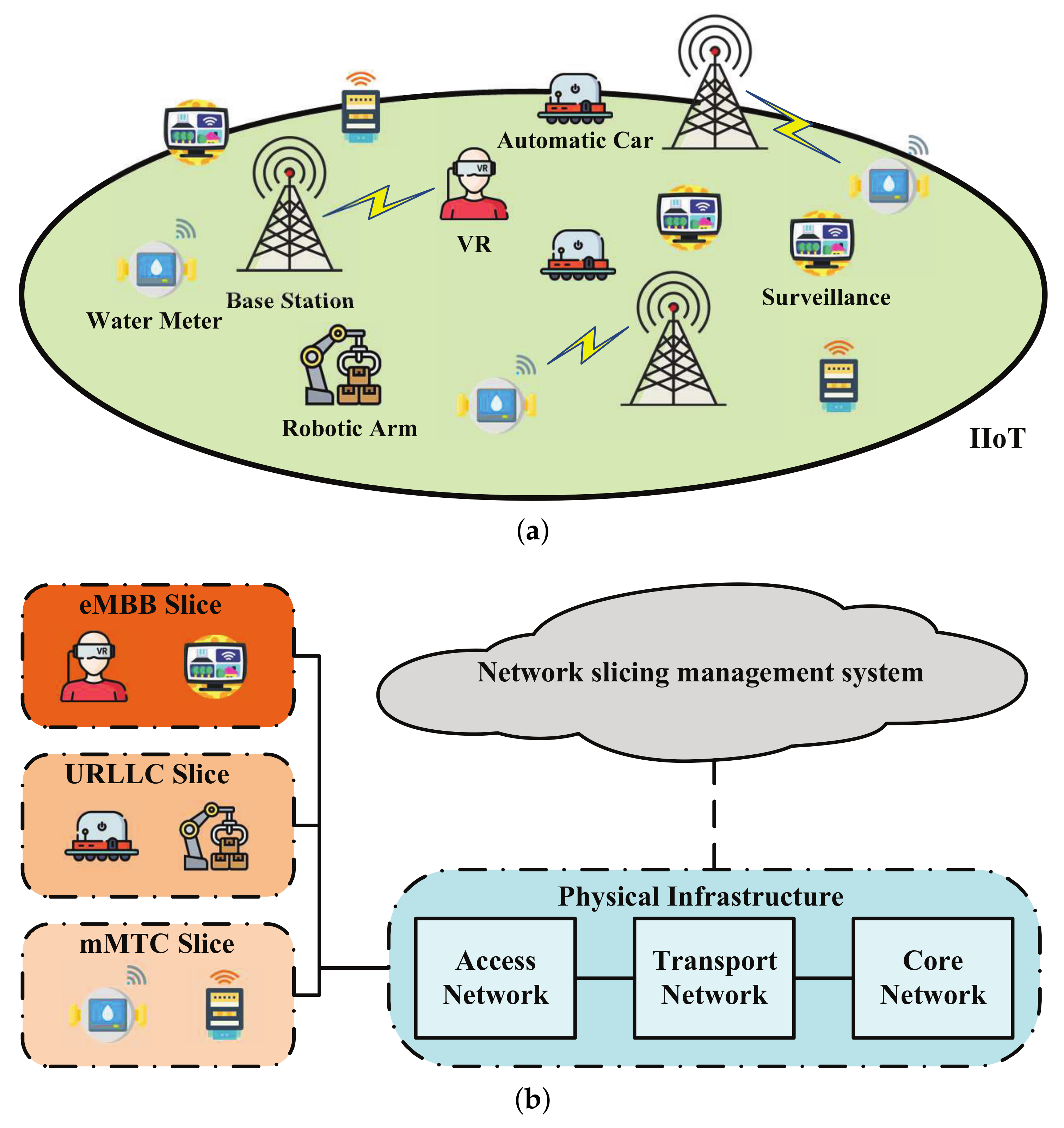
2.1. Network Model
2.2. SINR and Transmission Rate
2.3. Requirements of Different Network Slices
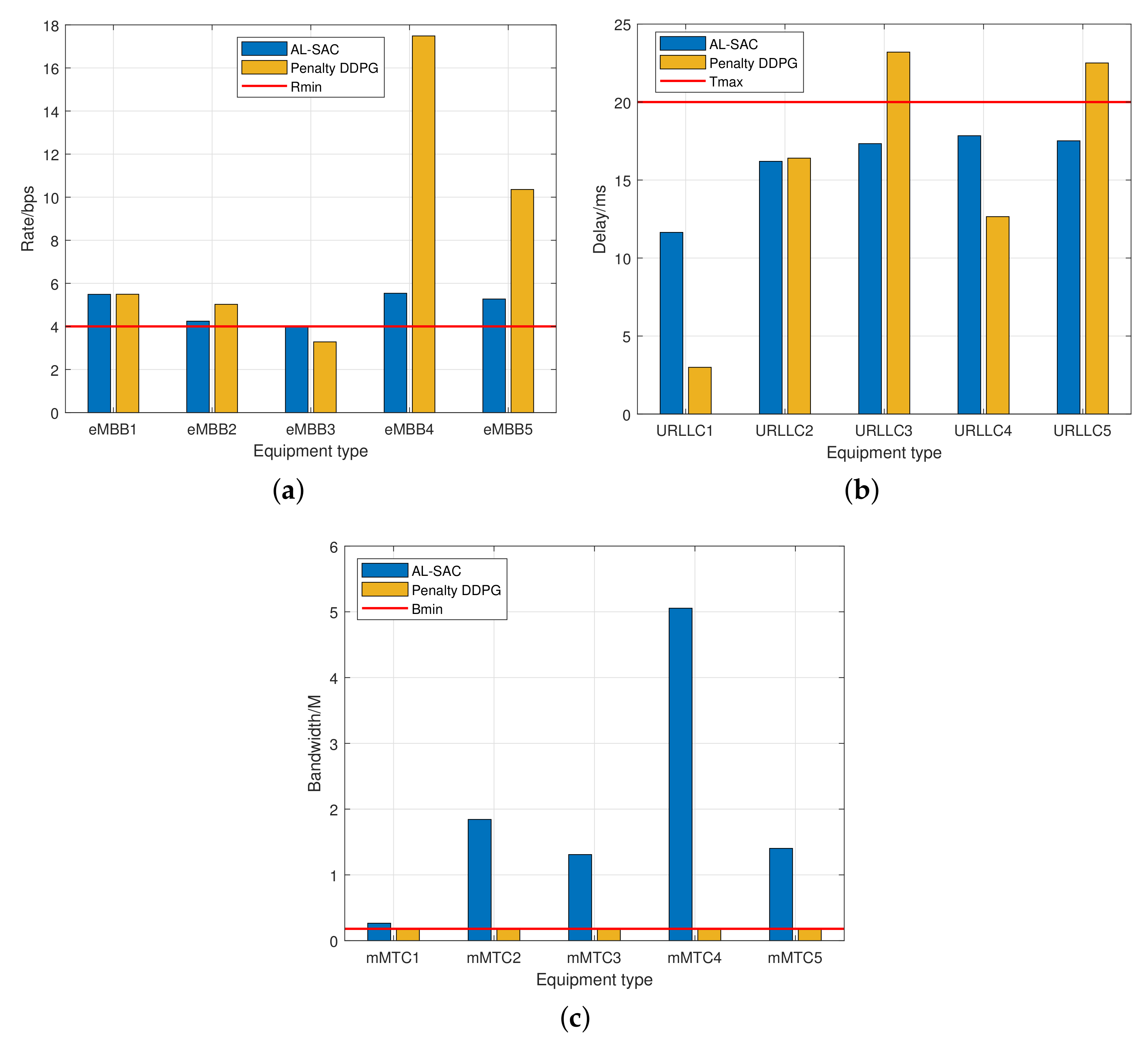
- eMBB slice: The devices served by this network slice require a high transmission rate, such as the device with real-time streaming of high-resolution 4K or 3D video [24]. That is, the transmission rate achieved by these devices has a minimum requirement:where denotes the rate threshold.
- URLLC slice: The devices served by this network slice have a strict requirement on delay, which include the transmission delay, queuing delay, propagation delay, and routing delay [25]. Denoted them by , respectively, the end-to-end delay can be calculated as . The minimum requirement for wireless transmission delay is as follows:where L denotes the packet length, and denotes the delay threshold. As mentioned in [26], the achievable rate of a URLLC wireless link, i.e., Equation (4) in [26], can be approximated by the Shannon capacity when the block length is large. For this reason, in this work, we use the Shannon capacity to calculate the link rate and focus on the transmission time independent of the other delay components [27].
- mMTC slice: The devices served by this network slice have no strict rate or latency requirements [27]. Hence, to ensure the basic wireless connection, a minimum bandwidth should be allocated to support the connection. That is,
2.4. Problem Formulation
3. Proposed Augmented Lagrangian-Based Reinforcement Learning
3.1. Preliminary of Augmented Lagrangian Method
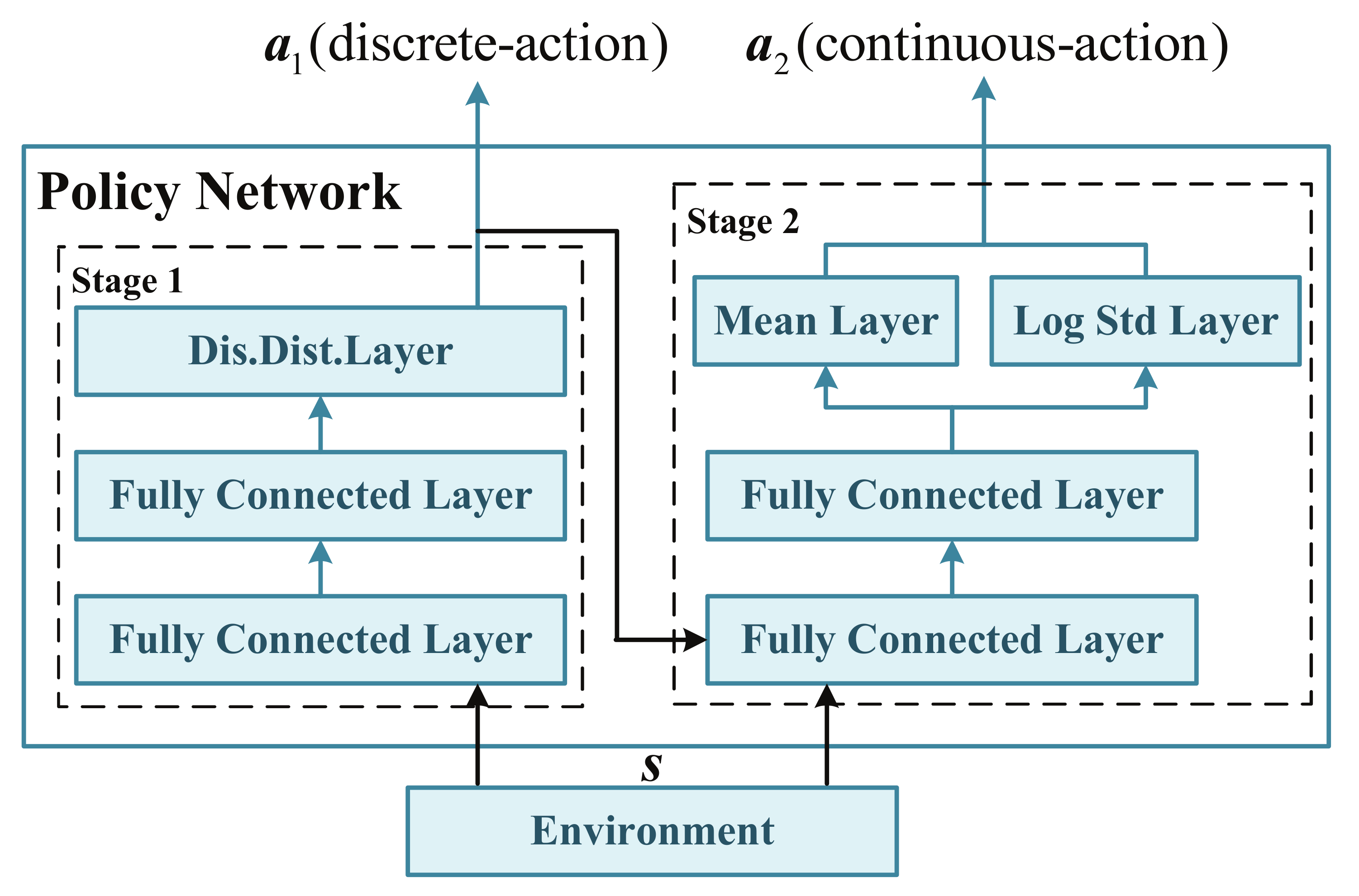
3.2. Definition of State, Action and Reward in RL
3.2.1. State Space
3.2.2. Hybrid Action Space
3.2.3. Reward Function
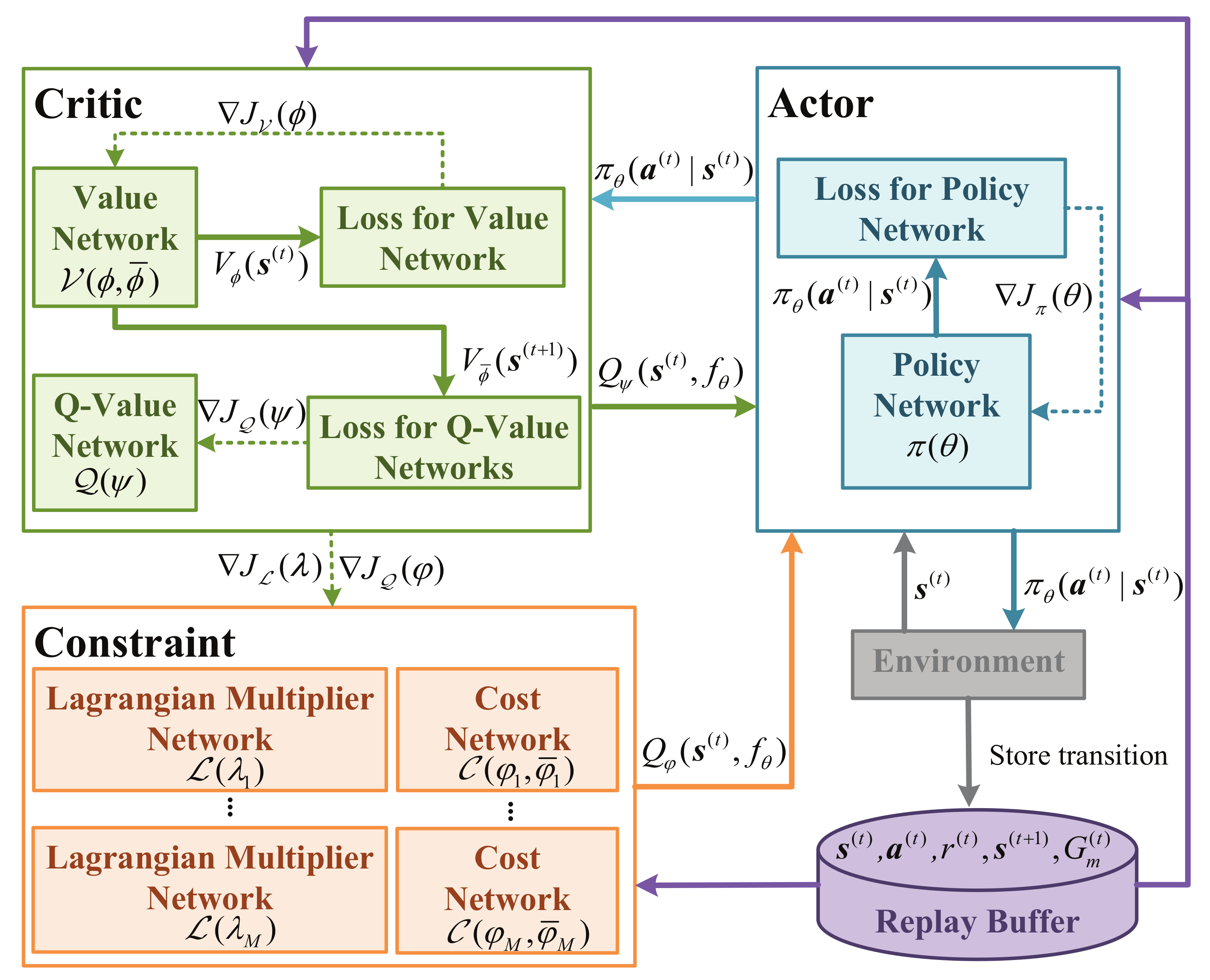
3.3. Proposed AL-SAC Algorithm
- Actor part: it deploys a policy network denoted by , which generates the policy of device association and bandwidth allocation;
- Critic part: it deploys a value network and a Q-value network, denoted by and , estimating the value of state and state-action, respectively;
- Constraint part: it deploys Lagrangian multiplier networks and cost networks, denoted by and , estimates the cost value of constraints and adjusting the Lagrangian multipliers accordingly.
- Replay buffer: it is used in DRL to store the tuples, i.e., , from which the sampled tuples are used in neural network training.
3.3.1. Value Network
3.3.2. Q-Value Network
3.3.3. Constraint Networks
3.3.4. Lagrangian Multiplier Network
3.3.5. Policy Network
| Algorithm 1 Augmented Lagrangian-based soft actor–critic (AL-SAC) |
|
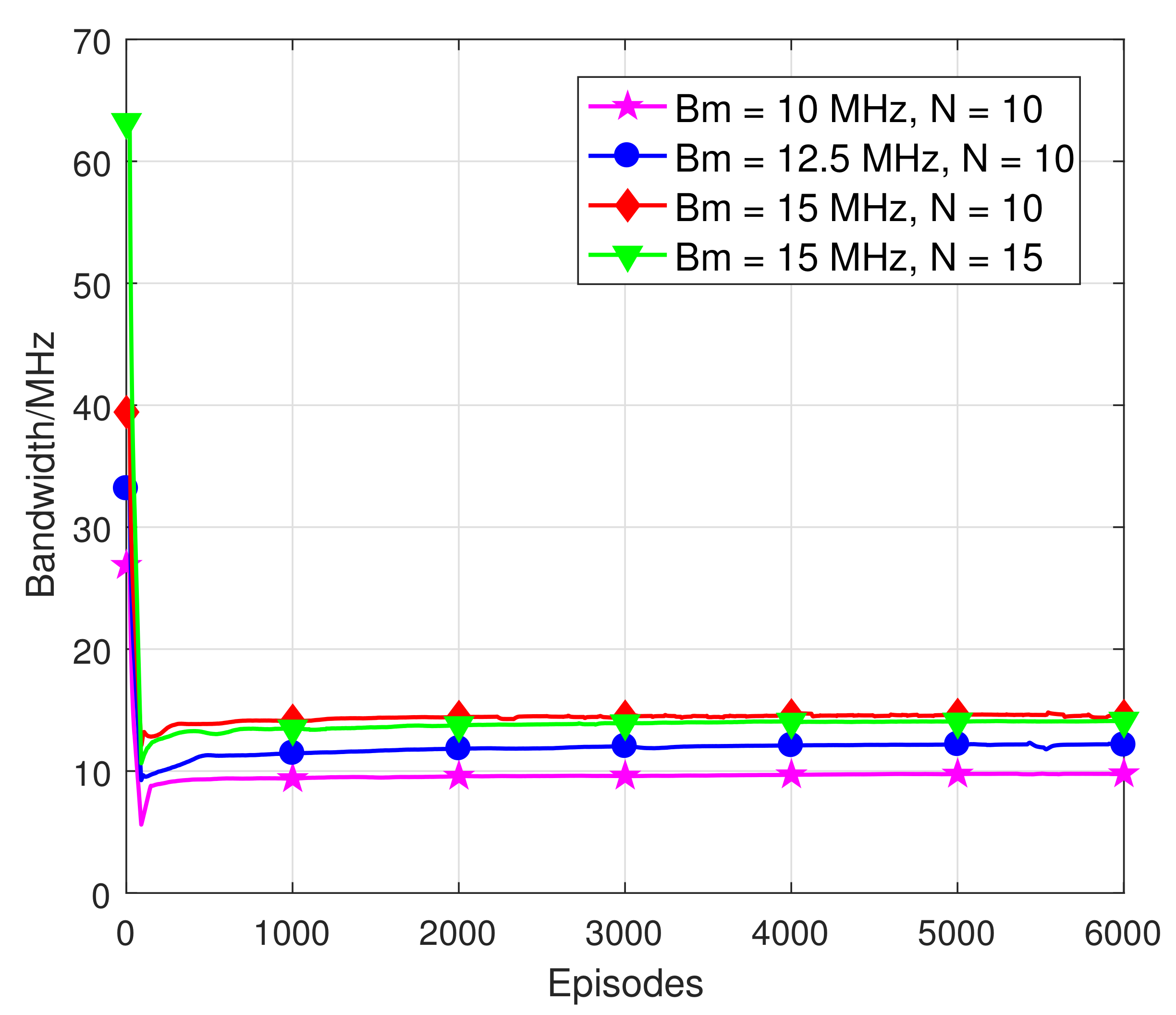
4. Simulation
4.1. Parameter Setting
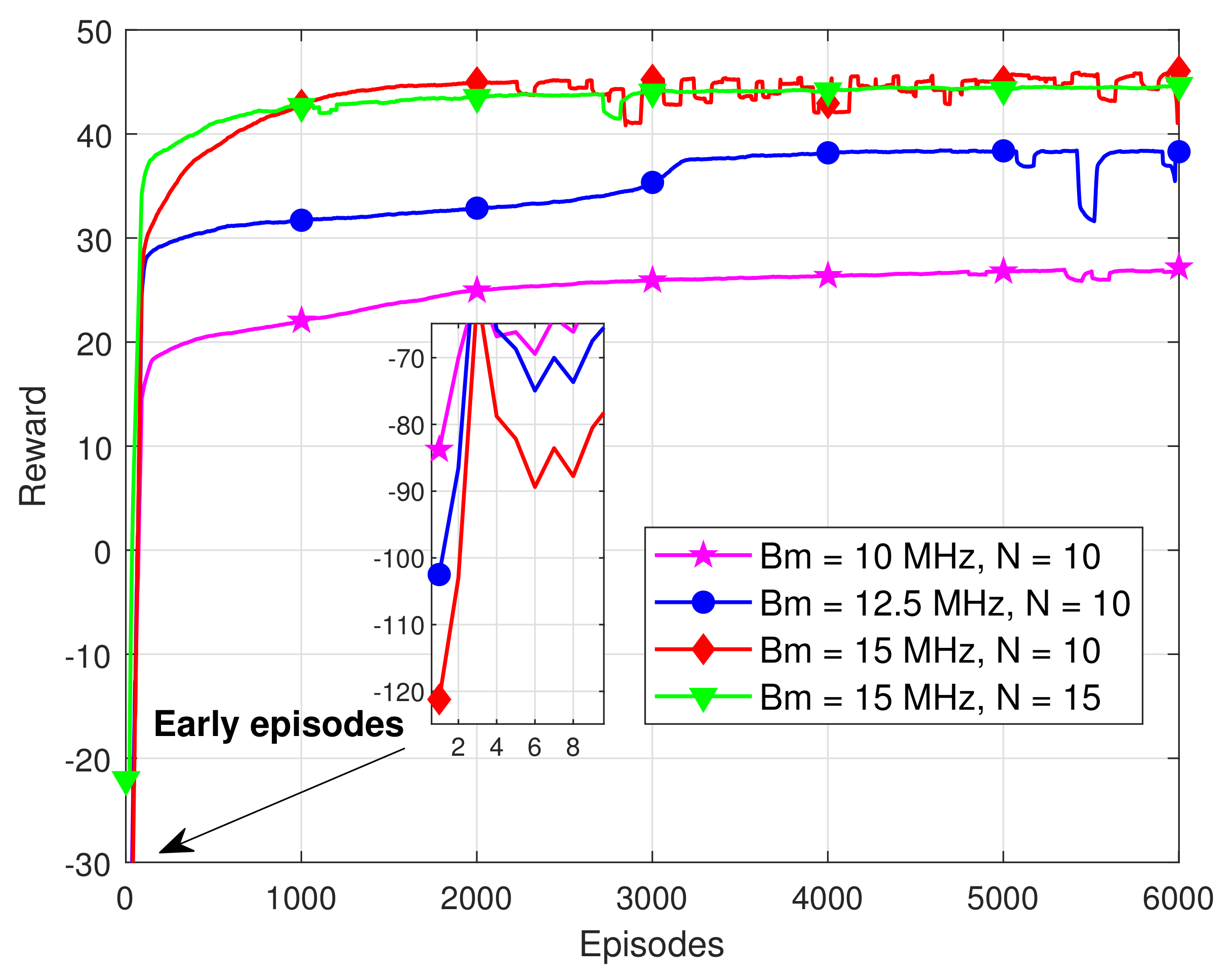
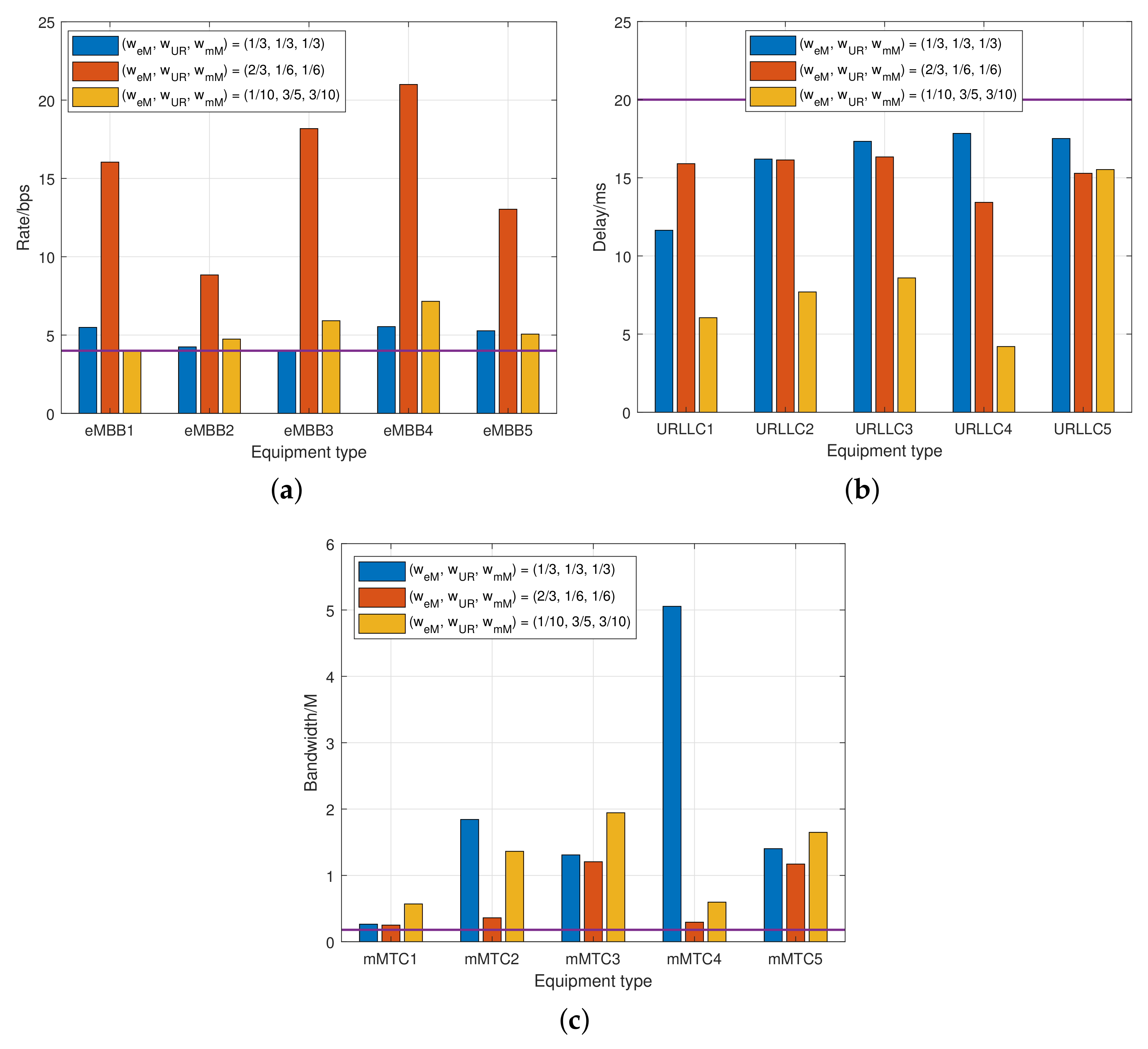
4.2. Results and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Costanzo, S.; Fajjari, I.; Aitsaadi, N.; Langar, R. Dynamic network slicing for 5G IoT and eMBB services: A new design with prototype and implementation results. In Proceedings of the 2018 3rd Cloudification of the Internet of Things (CIoT), Paris, France, 2–4 July 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Costanzo, S.; Cherrier, S.; Langar, R. Network slicing orchestration of IoT-BeC3 applications and eMBB services in C-RAN. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April–2 May 2019; pp. 975–976. [Google Scholar] [CrossRef]
- Setayesh, M.; Bahrami, S.; Wong, V.W. Resource Slicing for eMBB and URLLC Services in Radio Access Network Using Hierarchical Deep Learning. IEEE Trans. Wirel. Commun. 2022, 17, 1–11. [Google Scholar] [CrossRef]
- Popovski, P.; Trillingsgaard, K.F.; Simeone, O.; Durisi, G. 5G Wireless Network Slicing for eMBB, URLLC, and mMTC: A Communication-Theoretic View. IEEE Access 2018, 6, 55765–55779. [Google Scholar] [CrossRef]
- Chen, W.E.; Fan, X.Y.; Chen, L.X. A CNN-based packet classification of eMBB, mMTC and URLLC applications for 5G. In Proceedings of the 2019 International Conference on Intelligent Computing and its Emerging Applications (ICEA), Tainan, Taiwan, 30 August–1 September 2019; pp. 140–145. [Google Scholar] [CrossRef]
- Wijethilaka, S.; Liyanage, M. Survey on Network Slicing for Internet of Things Realization in 5G Networks. IEEE Commun. Surv. Tutorials 2021, 23, 957–994. [Google Scholar] [CrossRef]
- Tang, J.; Shim, B.; Quek, T.Q.S. Service Multiplexing and Revenue Maximization in Sliced C-RAN Incorporated With URLLC and Multicast eMBB. IEEE J. Sel. Areas Commun. 2019, 37, 881–895. [Google Scholar] [CrossRef]
- Xia, W.; Shen, L. Joint resource allocation using evolutionary algorithms in heterogeneous mobile cloud computing networks. China Commun. 2018, 15, 189–204. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Z.; Yang, L. Learning-Based Resource Allocation in Heterogeneous Ultra Dense Network. IEEE Internet Things J. 2022, 9, 20229–20242. [Google Scholar] [CrossRef]
- Manogaran, G.; Ngangmeni, J.; Stewart, J.; Rawat, D.B.; Nguyen, T.N. Deep Learning-based Concurrent Resource Allocation for Enhancing Service Response in Secure 6G Network-in-Box Users using IIoT. IEEE Internet Things J. 2021, 9, 1–11. [Google Scholar] [CrossRef]
- Deng, Z.; Du, Q.; Li, N.; Zhang, Y. RL-based radio Rresource slicing strategy for software-defined satellite networks. In Proceedings of the 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi’an, China, 16–19 October 2019; pp. 897–901. [Google Scholar] [CrossRef]
- Kim, Y.; Lim, H. Multi-Agent Reinforcement Learning-Based Resource Management for End-to-End Network Slicing. IEEE Access 2021, 9, 56178–56190. [Google Scholar] [CrossRef]
- He, Y.; Wang, Y.; Lin, Q.; Li, J. Meta-Hierarchical Reinforcement Learning (MHRL)-Based Dynamic Resource Allocation for Dynamic Vehicular Networks. IEEE Trans. Veh. Technol. 2022, 71, 3495–3506. [Google Scholar] [CrossRef]
- Alwarafy, A.; Çiftler, B.S.; Abdallah, M.; Hamdi, M.; Al-Dhahir, N. Hierarchical Multi-Agent DRL-Based Framework for Joint Multi-RAT Assignment and Dynamic Resource Allocation in Next-Generation HetNets. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2481–2494. [Google Scholar] [CrossRef]
- Wang, Y.; Shang, F.; Lei, J. Reliability Optimization for Channel Resource Allocation in Multi-hop Wireless Network: A multi-granularity Deep Reinforcement Learning Approach. IEEE Internet Things J. 2022, 9, 19971–19987. [Google Scholar] [CrossRef]
- Liu, Y.; Ding, J.; Liu, X. IPO: Interior-point policy optimization under constraints. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 Febraury–1 March 2020; Volume 34, pp. 4940–4947. [Google Scholar]
- Tessler, C.; Mankowitz, D.J.; Mannor, S. Reward constrained policy optimization. arXiv 2018, arXiv:1805.11074. [Google Scholar]
- Ding, D.; Zhang, K.; Basar, T.; Jovanovic, M. Natural policy gradient primal-dual method for constrained markov decision processes. Adv. Neural Inf. Process. Syst. 2020, 33, 8378–8390. [Google Scholar]
- Achiam, J.; Held, D.; Tamar, A.; Abbeel, P. Constrained policy optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 22–31. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1889–1897. [Google Scholar]
- Yang, T.Y.; Rosca, J.; Narasimhan, K.; Ramadge, P.J. Projection-based constrained policy optimization. arXiv 2020, arXiv:2010.03152. [Google Scholar]
- Dalal, G.; Dvijotham, K.; Vecerik, M.; Hester, T.; Paduraru, C.; Tassa, Y. Safe exploration in continuous action spaces. arXiv 2018, arXiv:1801.08757. [Google Scholar]
- Ding, M.; López-Pérez, D.; Chen, Y.; Mao, G.; Lin, Z.; Zomaya, A.Y. Ultra-Dense Networks: A Holistic Analysis of Multi-Piece Path Loss, Antenna Heights, Finite Users and BS Idle Modes. IEEE Trans. Mob. Comput. 2021, 20, 1702–1713. [Google Scholar] [CrossRef]
- Alsenwi, M.; Tran, N.H.; Bennis, M.; Pandey, S.R.; Bairagi, A.K.; Hong, C.S. Intelligent resource slicing for eMBB and URLLC coexistence in 5G and beyond: A deep reinforcement learning based approach. IEEE Trans. Wirel. Commun. 2021, 20, 4585–4600. [Google Scholar] [CrossRef]
- Ghanem, W.R.; Jamali, V.; Sun, Y.; Schober, R. Resource allocation for multi-user downlink MISO OFDMA-URLLC systems. IEEE Trans. Commun. 2020, 68, 7184–7200. [Google Scholar] [CrossRef]
- She, C.; Yang, C.; Quek, T.Q. Joint uplink and downlink resource configuration for ultra-reliable and low-latency communications. IEEE Trans. Commun. 2018, 66, 2266–2280. [Google Scholar] [CrossRef]
- Suh, K.; Kim, S.; Ahn, Y.; Kim, S.; Ju, H.; Shim, B. Deep Reinforcement Learning-Based Network Slicing for Beyond 5G. IEEE Access 2022, 10, 7384–7395. [Google Scholar] [CrossRef]
- Liu, Q.; Han, T.; Zhang, N.; Wang, Y. DeepSlicing: Deep reinforcement learning assisted resource allocation for network slicing. In Proceedings of the GLOBECOM 2020–2020 IEEE Global Communications Conference, Virtual, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Li, M. A Spectrum Allocation Algorithm Based on Proportional Fairness. In Proceedings of the 2020 6th Global Electromagnetic Compatibility Conference (GEMCCON), Xi’an, China, 20–23 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Andreani, R.; Birgin, E.G.; Martínez, J.M.; Schuverdt, M.L. On augmented Lagrangian methods with general lower-level constraints. SIAM J. Optim. 2008, 18, 1286–1309. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International conference on machine learning, PMLR, Jinan, China, 19–21 May 2018; pp. 1861–1870. [Google Scholar]
- Access, E. Further advancements for E-UTRA physical layer aspects. 3GPP Tech. Specif. TR 2010, 36, V2. [Google Scholar]
- Bouhamed, O.; Ghazzai, H.; Besbes, H.; Massoud, Y. Autonomous UAV Navigation: A DDPG-Based Deep Reinforcement Learning Approach. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Monterey, CA, USA, 21–25 May 2020; pp. 1–5. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of BSs, M | 2 |
| Number of devices, N | 10 or 15 |
| Number of devices in different slices, , , | 3,3,4 or 5,5,5 |
| Transmission power, | 2 W |
| Path loss exponent, | 3.09 |
| Noise power, | W |
| Minimum bandwidth allocated for mMTC devices, | W |
| Minimum transmission rate for eMBB devices, | 4 Mbps |
| Maximum delay for URLLC devices, | 20 ms |
| Maximum bandwidth for each BS, | MHz |
| Weight, | , , . |
| Batch size, K | 256 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, Q.; Lin, W.; Guo, B.; Chen, J.; Deng, C.; Lin, G.; Sun, X.; Chen, Y. Augmented Lagrangian-Based Reinforcement Learning for Network Slicing in IIoT. Electronics 2022, 11, 3385. https://doi.org/10.3390/electronics11203385
Qi Q, Lin W, Guo B, Chen J, Deng C, Lin G, Sun X, Chen Y. Augmented Lagrangian-Based Reinforcement Learning for Network Slicing in IIoT. Electronics. 2022; 11(20):3385. https://doi.org/10.3390/electronics11203385
Chicago/Turabian StyleQi, Qi, Wenbin Lin, Boyang Guo, Jinshan Chen, Chaoping Deng, Guodong Lin, Xin Sun, and Youjia Chen. 2022. "Augmented Lagrangian-Based Reinforcement Learning for Network Slicing in IIoT" Electronics 11, no. 20: 3385. https://doi.org/10.3390/electronics11203385