1. Introduction
Financial stock markets have an immense impact on the world economy as well as on financial and social organizations. The stock market, also called the securities market, comprises an aggregated methodology for the purchase and sale of various shares at the public or private level [
1]. While financial markets are associated with colossal gains, big gains also carry risks that can lead to misfortune. This makes stock market prediction an interesting but difficult endeavor, as it is extremely difficult to predict stock markets with high accuracy due to high instability, random fluctuations, anomalies, and turbulence. Typically, stock market intelligence involves analyzing stock-related data to predict stock value fluctuations based on time series data, i.e., a chronological compilation of relevant observations, such as daily sales figures and prices of stocks. Verifiable time series data from financial stock exchanges provide detailed information about a particular stock during given stock market cycle [
2]. This temporal data includes opening and closing prices, highs and lows, and the volume of stocks traded during a particular time period. Fundamental and technical analysis techniques typically rely on quantitative stock data such as stock costs, volumes, and portfolios, as well as subjective data about the companies involved, their profiles, and their trading strategies [
3].
The extant research on stock trend prediction has largely focused on the application of various econometric-based methods to predict stock trends based on structured and linear historical data, mainly using linear regression and parameter estimation techniques [
4,
5,
6,
7]. However, stock price fluctuations are influenced not only by historical stock trading data, but also by nonlinear factors such as political factors, investment psychology, and unexpected events. In practice, the unstructured nature of news events and their lack of linearity and consistency have rendered traditional quantitative investment analysis methods ineffective. As technology has advanced, media news has become an important signal that captures the nonlinear factors that influence stock price performance, thereby improving the accuracy of stock price forecasting. Recent studies have suggested that media news and related sentiments can influence corporate and investor behavior as well as stock market performance [
8]. Similarly, stock market trends are influenced by various events such as political influences, information security events [
9,
10], specific news or announcements [
2], and national politics [
11]. With the proliferation of stock market events, financial news, and investor decisions, it is imperative to understand how these events and sentiments influence stock market trends.
Although stock price movements are stochastic and generally involve non-random events, they can still be predicted by analyzing investor behavior and trading patterns [
12,
13,
14]. While econometrics-based statistical methods can rely on tentative premises, machine learning methods pose challenges due to limited interpretability, the need for manual feature selection, and the problem of overfitting. To address these issues, deep learning methods based on conventional neural networks (CNNs) and Recurrent Neural Networks (RNNs) have been used for predicting stock market trends [
15,
16,
17]. By extracting the underlying features of highly unstructured data, such deep learning prediction techniques can be used to explore the complex inherent patterns of stock price movements based on time series data. CNNs and RNNs generally integrate the concept of time into the network structure and are inherently suited for processing time series data. However, neural network methods encounter the problem that the gradient disappears when the sequence of input time series data becomes too long. To solve this problem, the long short-term memory (LSTM) model has been proposed as an improved version of RNN. Recent studies have shown that the LSTM outperforms the RNN and conventional machine learning algorithms such as random forest (RF), support vector machine (SVM), and decision tree (DT) in addressing stock prediction problems based on time series data [
4,
18,
19,
20,
21,
22].
Recently, researchers have applied deep learning techniques to stock prediction using LSTMs or modified LSTMs such as PSOLSTM, Stacked LSTM, and Time-Weighted LSTM [
2,
6,
23,
24]. Stock prediction models based on LSTMs analyze the sentiment polarity of textual information as well as the sentiment polarity of media news with historical trading data as input. Nevertheless, there are a number of research problems that need to be addressed to improve stock trend prediction and performance using both quantitative and qualitative stock-related data:
First, while quantitative stock data can provide insight into the performance of the respective stocks, many other factors also play a crucial role in this context. Various country-specific factors such as political events, corporate politics, splits and mergers of different companies as well as global events can have a strong impact on the stock market. However, identifying such events and their linkages to investors investing in the stock market is a challenging task. Such events do have a major impact on the stock market; thus, incorporating them into stock analysis and identifying their correlation with stock performance can greatly contribute to improving stock forecasts;
Second, in addition to fluctuations resulting from a variety of events, nonlinear stock markets are also affected by the sentiment associated with these events, which can directly or indirectly affect price movements [
25]. For example, using historical stock market data to predict performance at a given point in time can provide clues to the impact of public sentiment. However, it is unclear how unstructured news data can be merged with organized stock market information. Typically, sentiment data from news texts are combined with verifiable stock market information and company financial data to contribute to stock metrics [
26,
27,
28]. However, this method easily loses the sentiment data in the high-dimensional financial data. Stock prediction methods with additional sentiment aspects have been shown to be even less accurate than those without. It is expected that merging these data sources (factors) into a single intelligence would improve the prediction accuracy in the stock market. However, it is challenging to integrate the information from different data sources into one dataset for market analysis because they have different formats (numeric or text);
Third, while there are multiple approaches to both machine learning and deep learning, recent studies show that hybrid methods can be used to overcome inherent limitations of isolated approaches, e.g., the vanishing gradient problem in RNN can be largely avoided by deep feed-forward networks. Therefore, the effectiveness of predictive models can be improved by integrating complementary techniques. According to Alotaibi [
29], financial markets are inherently non-stationary, non-linear and chaotic. In a volatile stock market, determining inherent patterns requires appropriate data representation. Therefore, due to the adaptability of DNNs and LSTMs for nonlinear financial markets, we propose the integration of DNNs and BiLSTMs with stock market data and evaluate their suitability to provide deeper insights and improve the performance of stock market forecasts.
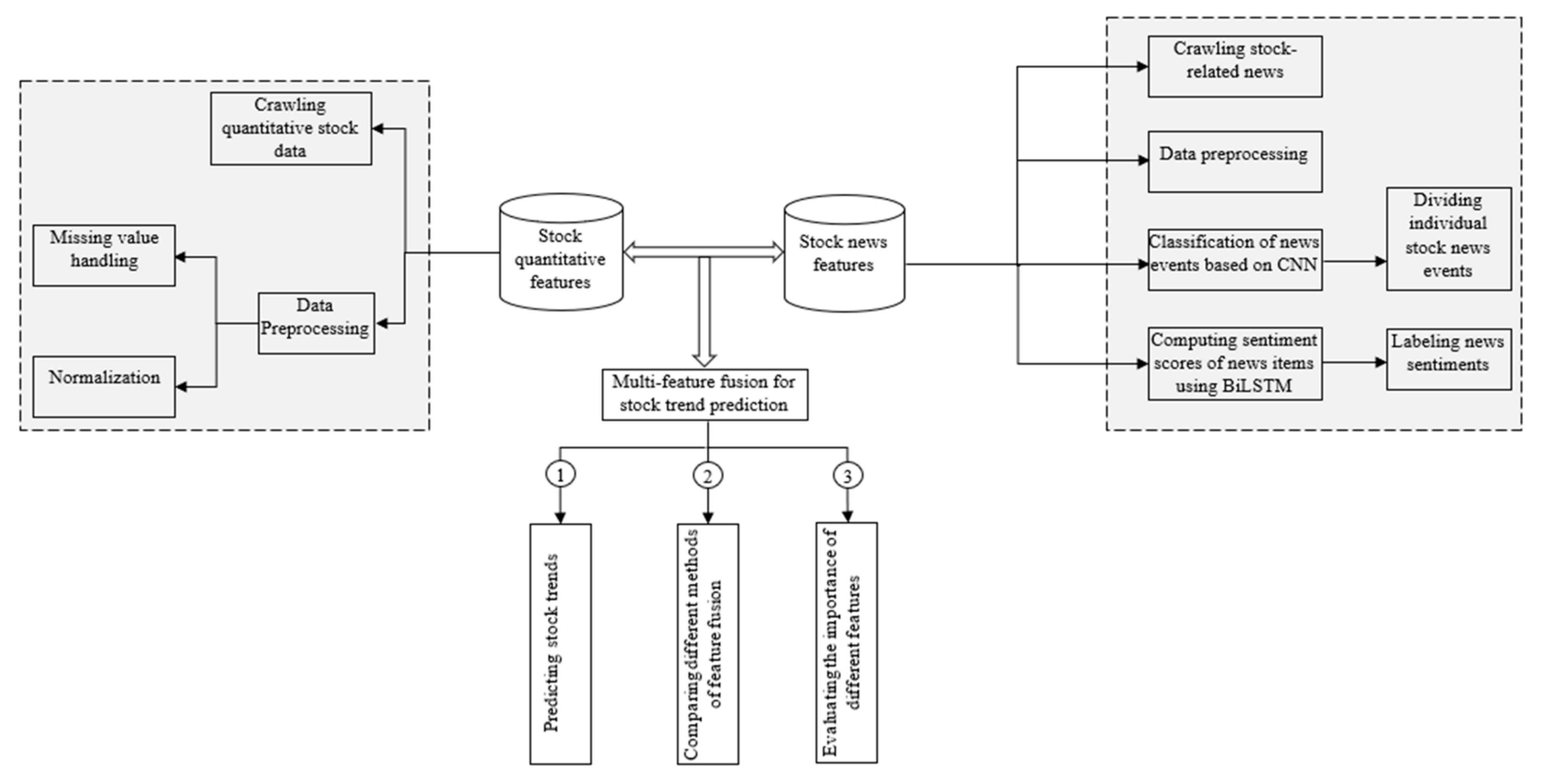
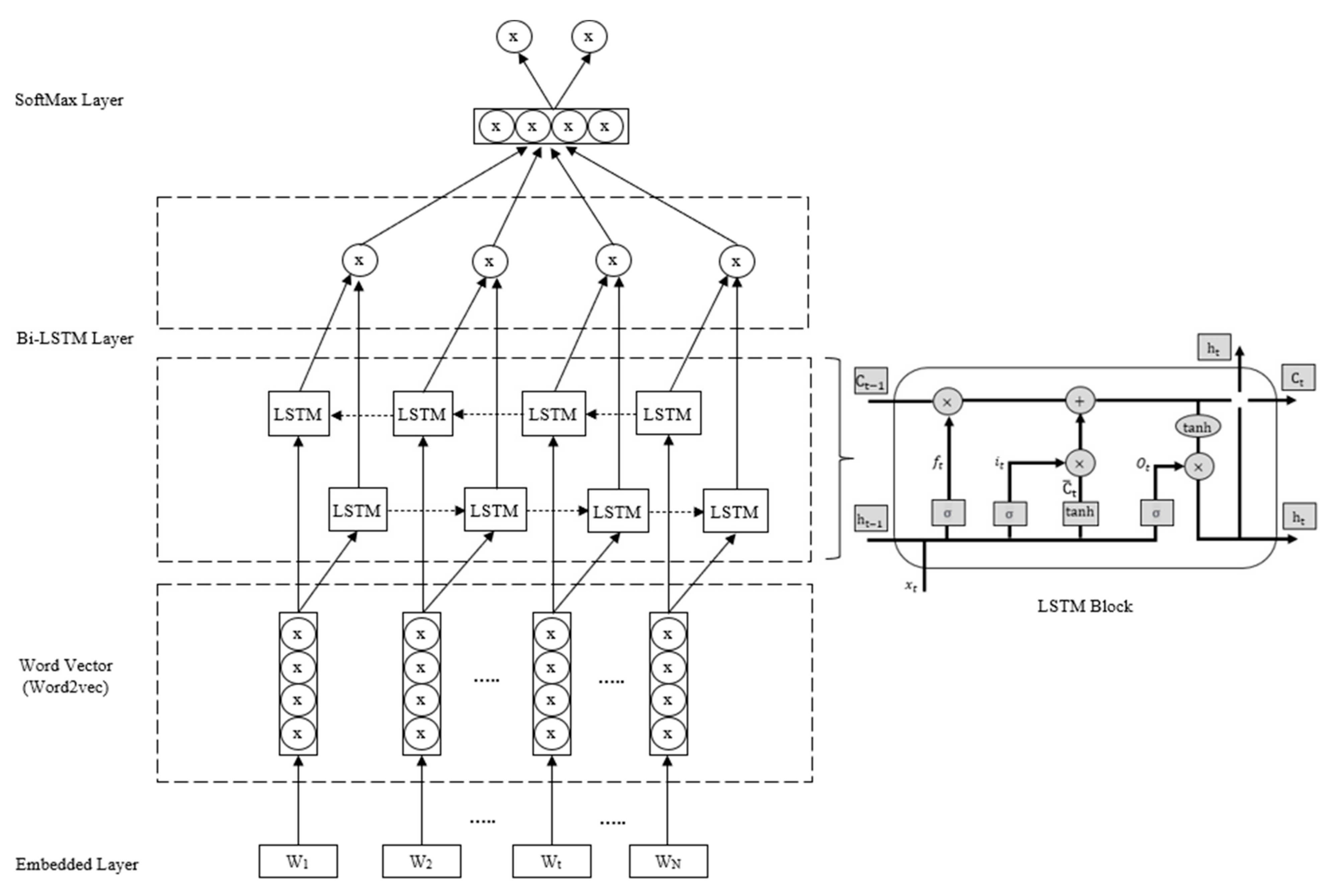
To address the above three research challenges, this study presents a hybrid data analytics framework that integrates convolutional neural networks and bidirectional long short-term memory (CNN-BiLSTM) to evaluate the impact of the convergence of news events and sentiment trends with quantitative financial data on predicting stock trends. CNN is a powerful tool for extracting event features from news text, while BiLSTM uses two LSTM networks to obtain forward and backward contextual information, which is more suitable for discriminating sentiment polarity given context and can improve sentiment analysis compared to a single LSTM [
11,
15,
24]. In this study, we used CNN and BiLSTM because these two techniques allow us to create detailed input features based on the fact that CNN can detect relevant internal structures in time series data through convolution and pooling operations [
3]. Moreover, CNN and BiLSTM algorithms have been shown to be more accurate and more resistant to perturbation than state-of-the-art methods in classifying time series data [
24,
30,
31]. CNN and BiLSTM algorithms are therefore able to learn relationships within time series without requiring large amounts of historical time series data. Similarly, BiLSTM and CNN have already been shown to provide highly accurate results for text mining tasks that require sequential modeling information [
7]. Moreover, their implementation requires less time and effort [
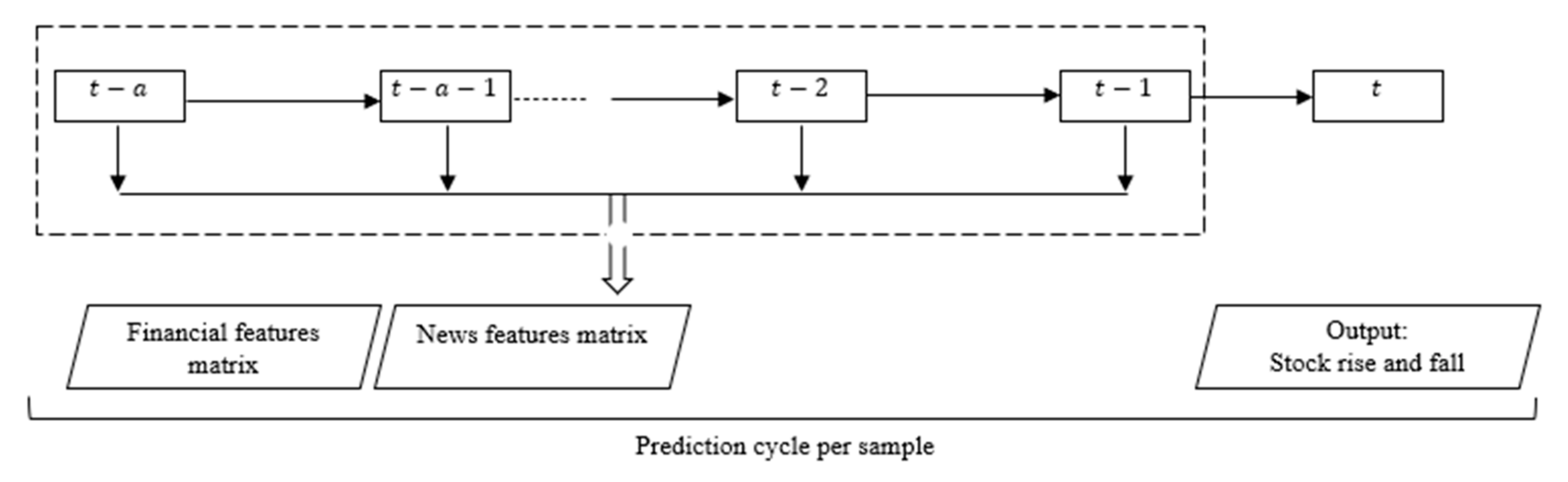
25]. The proposed model uses objective financial events extracted from news reports, such as surcharge events, stock prices and suspension events, on the one hand; on the other hand, BiLSTM is used to analyze the sentiment polarity of news reports and calculate the sentiment values of news texts. The features of stock news, including the types of news events and sentiment values, together with the numerical financial features of the stock are used as input to the LSTM network, and the historical stock information is used to predict the future rise and fall of the stock.
The main contributions of this study are as follows:
A hybrid data analytics predictive framework built on CNN and BiLSTM deep learning algorithms that combines heterogeneous stock price indicators (various categories of news events, user sentiments, historical macroeconomic variables, and historical stock price data) to predict future stock price movements. Therefore, this study demonstrates that traditional quantitative analysis techniques combined with investor and expert opinions (fundamental analysis) provide more accurate predictions of stock performance;
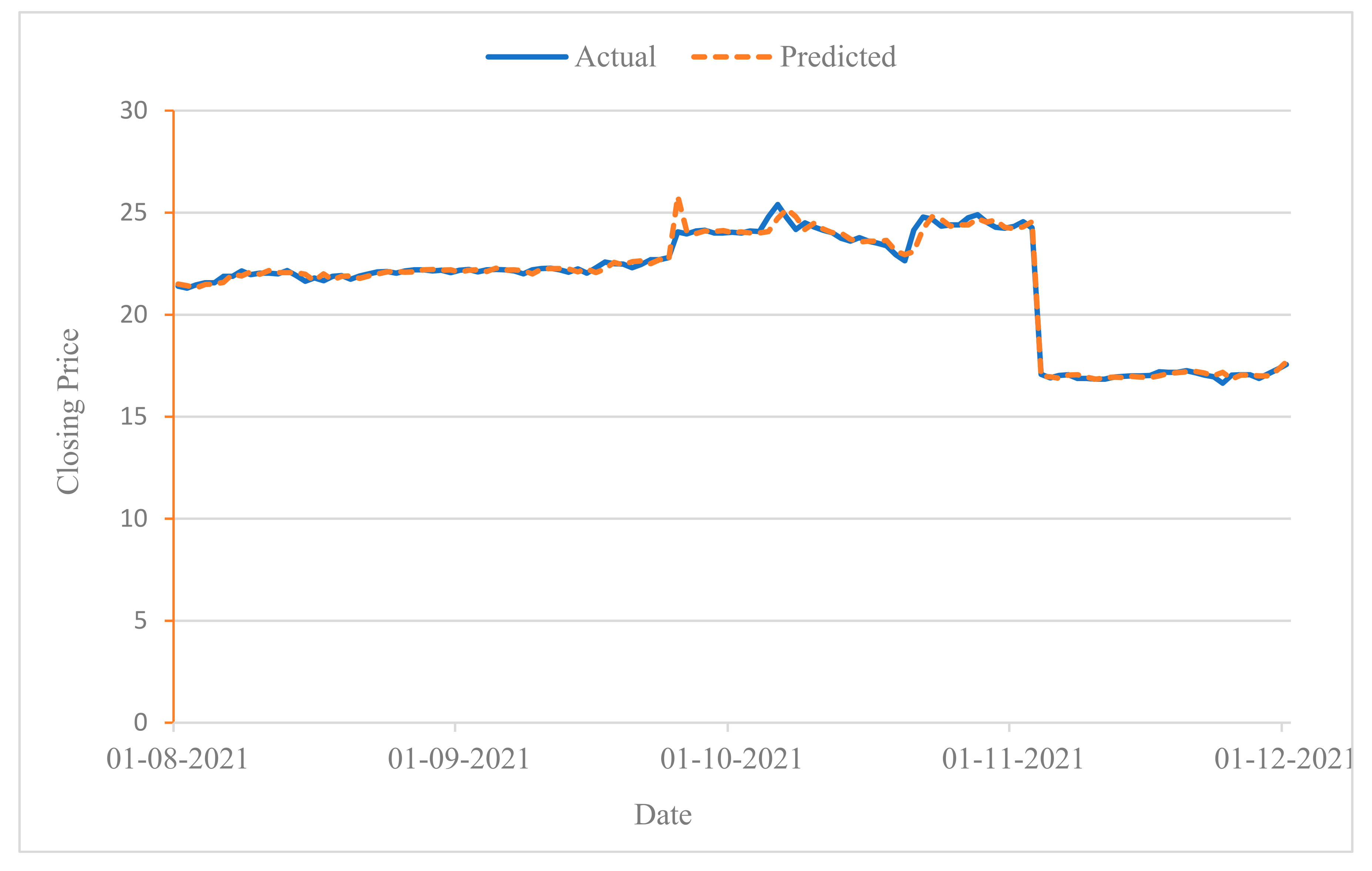
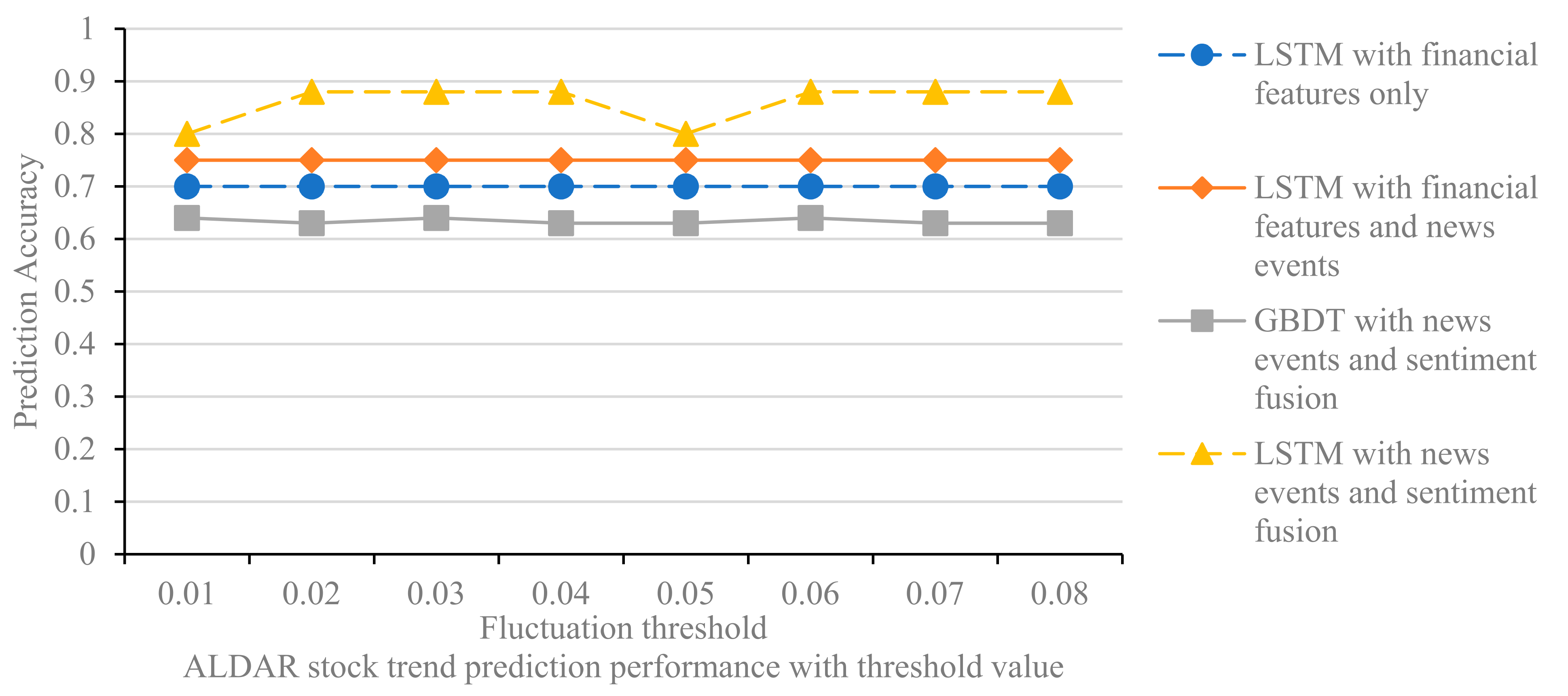
We experimentally investigated the effectiveness of the proposed framework with real stock data from the Dubai Financial Market (DFM) using two case studies from the real estate and communications sectors. We provide a comparative analysis of our approach with three basic techniques to investigate the importance of features and sentiment fusion in improving the prediction performance of stock trends. The results show that the prediction performance of machine learning models can be significantly improved by combining different stock-related information;
Since the stock market data were collected during the COVID-19 pandemic, the results of this study provide valid arguments to show how news events, and thus the stock market, can be affected by pandemic data. Analysis of news events during the COVID-19 pandemic, as well as the emotional state of the public through analysis of news events, can reveal the economic impact of COVID-19 on stock markets. These insights can then lead to accurate stock market forecasts. Given the recent advances in AI algorithms and the enormous amount of information about the pandemic, this study synthesizes the market data and trains a classifier to predict the direction of the next stock market movement.
The remainder of this paper is organized as follows.
Section 2 reviews the current and relevant literature on stock market analysis and forecasting.
Section 3 describes the techniques and methods used in this study to integrate stock-related data and analyze their impact on stock market prediction.
Section 4 presents the experimental design and case study description used to evaluate the applicability of the proposed model.
Section 5 reports the empirical results of this study and discusses its implications for research and practice. Finally,
Section 6 presents the conclusions of this work and suggests possible avenues for future research.
2. Literature Review
Stock market prediction is an important research topic that has attracted considerable interest from both researchers and investors. Previous research on stock market prediction can be broadly divided into two main categories: econometrics-based statistical methods, which involve the analysis of time series financial data; and computational intelligence-based techniques, which incorporate both quantitative stock data and textual information [
2,
3,
25].
Econometrics-based statistical analysis relies mainly on historical trading data, corporate financial data, and macro data to identify and describe patterns of change in stock data over time and predict future stock trends [
30,
32,
33]. Several machine learning algorithms were used to detect patterns in the large amount of financial information, including support vector machines (SVM), artificial neural networks (ANN), Parsimonious Bayes, and Random Forest [
24,
34]. Jiang, Liu [
35] showed that machine learning can be used to predict the future performance of individual stocks using historical stock data. Kim, Ku [
36] used SVM to predict the rise and fall of individual stocks and verified the effectiveness of SVM in classifying the rise and fall of individual stocks through empirical analysis. Lahmiri [
37] compared the performance of ANN and SVM in predicting stock movements and found that ANN outperformed SVM in terms of prediction accuracy, and feedforward ANN has been widely used due to its ability to predict both upward and downward movements of stocks as well as stock prices [
38].
However, since stock prices are inherently unpredictable in the short term, using historical trading data to analyze stock prices has its limitations and cannot further improve the prediction results. Behavioral economics theory states that investors are susceptible to personal and social emotions in complex and uncertain decision problems [
18]. The main cause of stock price changes is the reaction to new information, and news in the media can be useful as exogenous sources of information for short-term stock price prediction [
13,
19]. With advances in text analytics and the increasing prevalence of social media, blogs, and user-shared news, incorporating text content into stock market research has become an interesting topic. The combination of news events and social media messages to improve the predictive accuracy of forecasting models has led to the importance of developing appropriate techniques to analyze their impact on the market. In recent years, there has been an increase in the number of studies investigating the combined effect of a user’s social media sentiment and web news on stock price performance. For example, Zhang, Li [
39] reported a high correlation between stock price performance and public sentiment, with predictive accuracy ranging from 55% to 63%. They also proposed an extended coupled hidden Markov method to predict stock prices based on Internet news and historical stock data. Ref. [
40] proposed a multi-source multi-instance learning system based on three different data sources and found that the accuracy increased when using multiple data sources compared to single sources.
With the advancement of deep learning techniques and applications, more attention has been paid to neural network-based learning models for stock price prediction that incorporate both quantitative stock data and news data. Hiransha, Gopalakrishnan [
41] presented four types of deep learning architectures, i.e., multilayer perceptron (MLP), recurrent neural networks (RNN), long short-term memory (LSTM), and convolutional neural networks (CNN) for predicting a company’s stock price based on available historical prices. Similarly, Nabipour, Nayyeri [
20] employed RNN and LSTM to investigate whether news about stock prices and the associated sentiment polarity affect stock prices. In their study, they found that LSTM showed more accurate results with the highest model fit. They also reported that the prediction accuracy can be improved when both stock-related news texts and tweets are counted and used as input for stock price prediction. Nasir, Shaukat [
42] analyzed Dow Jones index prices based on user sentiment recorded on Twitter and showed that sentiment signals embedded in news are a reliable predictor of stock prices. Polamuri, Srinivas [
43] used an RNN model with gated recurrent units to predict stock movements and fused numerical features of stock prices to examine the sentiment polarity of financial news on Twitter. Similarly, Priya, Revadi [
26] used CNN and RNN to study the stock trend model that includes both news headlines and technical indicators, and showed that news headlines improve prediction accuracy more than news content. Shobana and Umamaheswari [
44] examined the effects of stock market signals embedded in news websites, stock bars, blogs, and other media information and found that investors responded faster and more strongly to positive sentiment.
Recently, hybrid deep learning methods have been proposed to improve the prediction performance of stock market trends. Srivastava, Zhang [
45] developed a hybrid model called RCNN, which combines RNN and CNN by exploiting the advantages of both models. Their experiments showed that the combined hybrid system had a positive impact on the performance of the model when text data and technical indicators were used as input data, and the proposed model performed better than the CNN model. Another hybrid model called RNN-boost was applied to predict stock volatility [
35]. It extracts LDA and sentiment features from social media data and combines them with stock technical indicators. The proposed model combines RNN and Adaboost to achieve an overall average accuracy of 66.54% [
41]. The RNN model uses gated recursive units (GRUs) to predict stock prices. A combination of three forecasting models, namely SVM, adaptive neuro-fuzzy inference system and artificial neural network (ANN), has been proposed for predicting stock prices using public opinion [
46]. The proposed models were evaluated using the historical stock index of the Istanbul BIST 100 index and yielded good results. Nti, Adekoya [
3] investigated the predictability of stock price movements in four countries based on sentiment in tweets and found a high correlation between stock prices and tweets.
Despite the increasing development and application of hybrid data analysis techniques based on neural network learning approaches for stock market analysis, current models incorporating quantitative stock data and news data largely consider the extraction of information sentiment polarities as a support rather than an integral part of stock trend prediction. Most previous studies have used Twitter and Twitter texts as a source of information data to better convey sentiment [
2,
5,
10,
14,
20,
21,
47]. However, considering that news reflects perceived reality and sentiment polarity is usually fuzzy, improving predictive accuracy by highlighting opinions cannot be taken for granted. Arosemena, Pérez [
30] proposed to use a latent dirichlet allocation (LDA) topic model to extract keywords from tweet texts, and then analyze the sentiment features of tweet texts based on keywords as input for stock prediction. Unlike previous studies, and considering that news events are more representative of the effects of media information on stock movements than news sentiment, this study uses a multi-feature fusion method that incorporates news events and sentiment convergence to extend the numerical features of stocks and further improve the accuracy of stock prediction.
6. Limitations and Future Research
This study has a number of limitations that should be considered when interpreting the results. First, the effects of different estimation cycles on the prediction of stock trends were not considered in the proposed CNN-BiLSTM model. Second, the current study relies on a single stock-related information source, which may limit the predictive power of the proposed model. Indeed, stock markets are typically influenced by a variety of text-based information sources, such as monetary news, online media, websites, or corporate statements [
8,
14,
31,
38,
51,
52]. These information sources differ in the way they influence monetary economic entities. Public opinion on online media, news information, and the opinion of monetary news writers, as well as the officiality of improvised statements, can influence the performance of stock prices in different ways. Therefore, it is equally important to study the combination of information from different sources to understand the impact of news information on predicting stock trends. These strategies can be used and extended to include news content from web-based media and monetary news to create a more comprehensive feature map. Sector and market-related information can additionally be used to tap into and explore the realm of organization-related texts (e.g., stock-related texts and administration-related texts) for stock market research.
Possible research and development directions to improve the accuracy of stock forecasts can be considered from two perspectives. First, given that the magnitude of the increase in stock investment has a large impact on investment profitability, the predictive accuracy of the model could be examined by classifying stock investment into four categories (small increase, large increase, small decrease, and large decrease). Second, other stock-related control variables, such as return and crash risk, can be included in the forecasting model and the effects of these control variables on stock forecasting performance can be compared. Since the BiLSTM-based commentary sentiment analysis method takes a long time to train the model, the method could be further developed in the future. In future work, the method could be investigated to effectively speed up the training process of the model. Further experiments with representations from different but related corpus, new deep learning techniques such as generative adversarial network (GAN) models and graph-based deep learning models can be investigated. The applications of graph-based deep learning not only allow us to tap into the rich values underlying existing graph data, but also help us to naturally model relational data as graphs. Hybrid models that integrate different machine learning and deep learning models can also be explored.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}