
A Hybrid Imputation Method for Multi-Pattern Missing Data: A Case Study on Type II Diabetes Diagnosis

 ,
,  , and
, and
Abstract
:1. Introduction
- -
- Introducing a four-layer model to develop hybrid imputation methods for multi-pattern missing data;
- -
- Proposing a hybrid imputation method (HIMP) using the introduced model;
- -
- Collecting a real dataset named Iran diabetes (IRDia) from private medical clinics, and identifying and categorizing its missing data patterns including MCAR, MAR, and MNAR patterns;
- -
- Evaluating the proposed HIMP by comparing its results with other imputation methods for imputing all missing data patterns of the IRDia dataset.
2. Background and Related Works
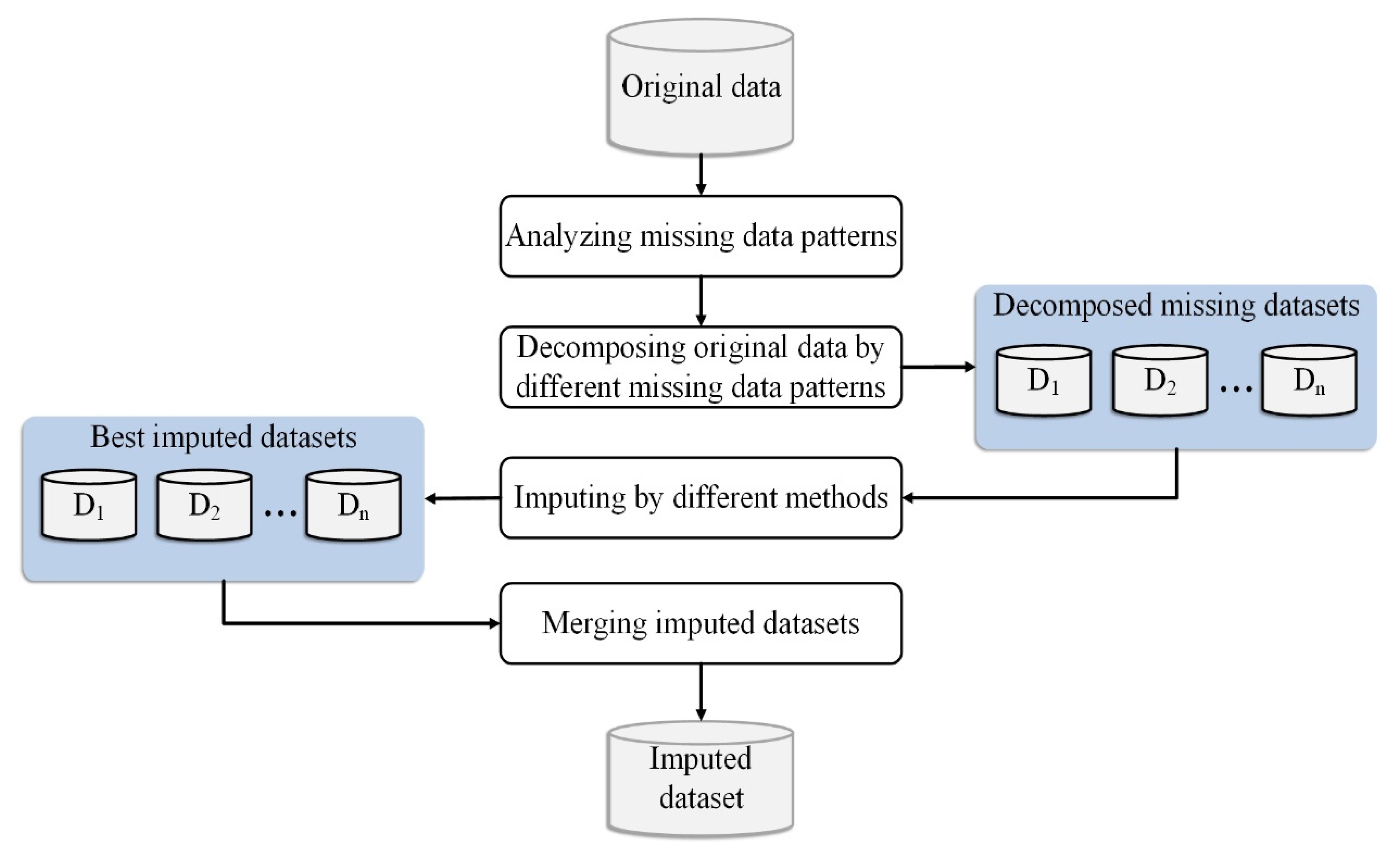
3. Proposed Hybrid Imputation (HIMP) Method for the Multi-Pattern Missing Data
| Algorithm 1. The proposed hybrid imputation (HIMP) method | |
| Input: The original dataset (IRDia) includes different missing data patterns. | |
| Output: Imputed dataset. | |
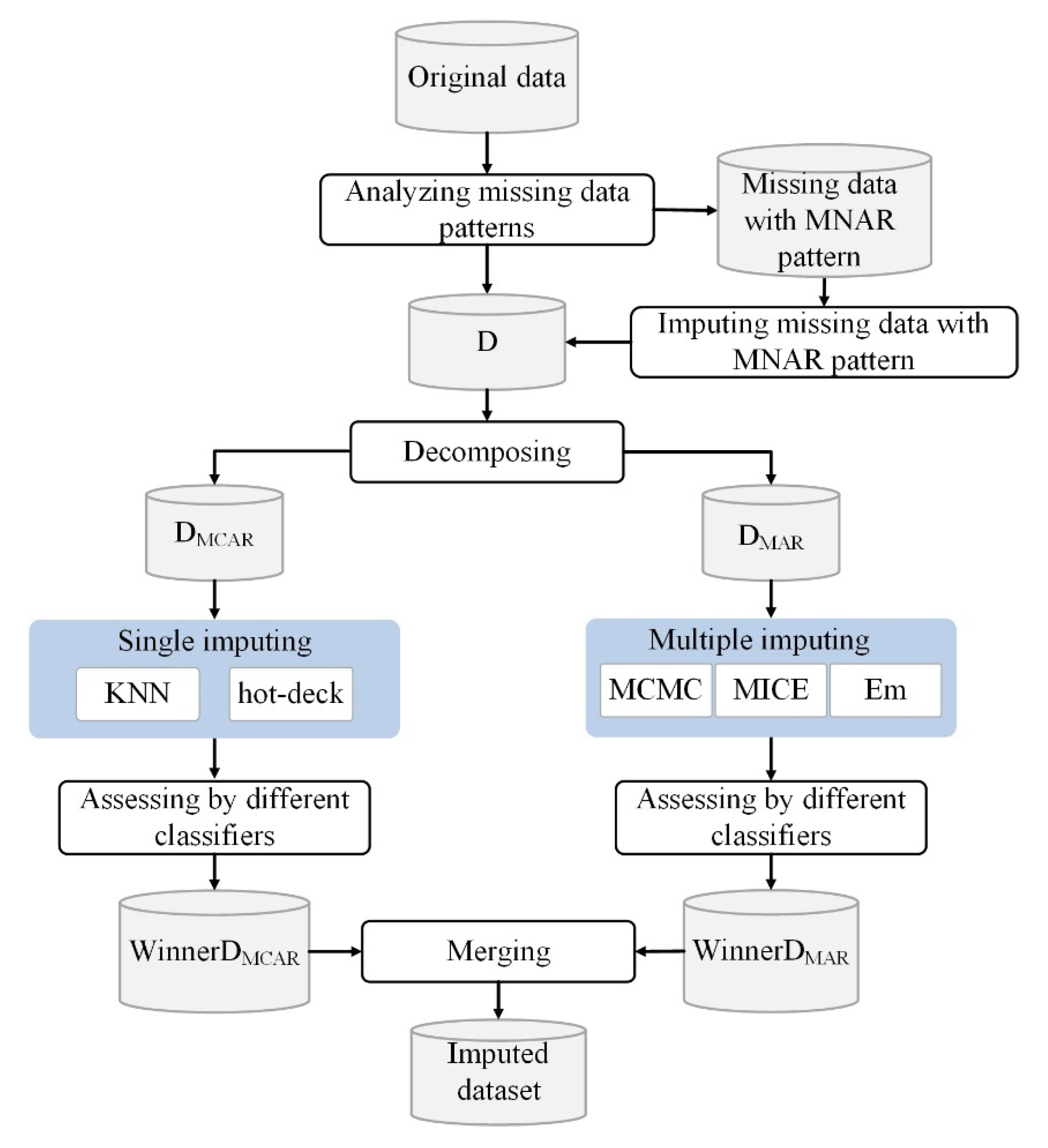
| 1. | Begin |
| 2. | Analyzing missing data patterns. |
| 3. | Imputing missing data with MNAR pattern using the appropriate constant global label. |
| 4. | D ← Original dataset with imputed MNAR pattern. |
| 5. | Decomposing D to two databases DMCAR and DMAR including MCAR and MAR patterns. |
| 6. | Single imputing DMCAR using candidate single imputation methods. |
| 7. | Assessing the results gained by candidate single imputation methods and selecting the winner. |
| 8. | WinnerDMCAR ← The imputed DMCAR gained from the winner single imputation method. |
| 9. | Multiple imputing DMAR using candidate multiple imputation methods |
| 10. | Assessing the results gained by candidate multiple methods and selecting the winner. |
| 11. | WinnerDMAR ← The imputed DMAR gained from the winner multiple imputation method. |
| 12. | Imputed dataset ←Merging WinnerDMCAR and WinnerDMAR. |
| 13. | End |
4. Experimental Evaluation
4.1. Experimental Environment and Setting
4.2. Clinical Data Collecting and Description of IRDia Dataset
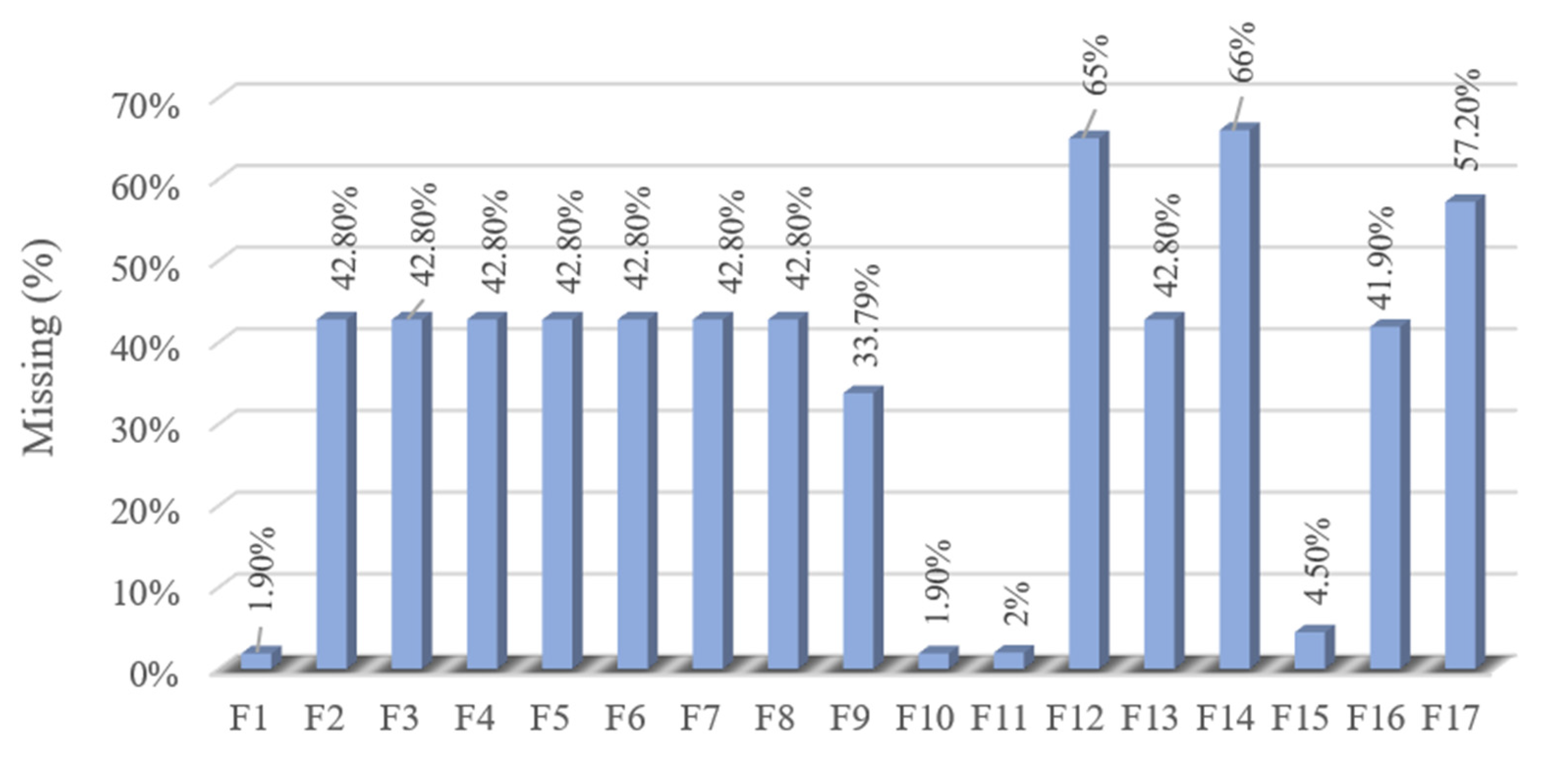
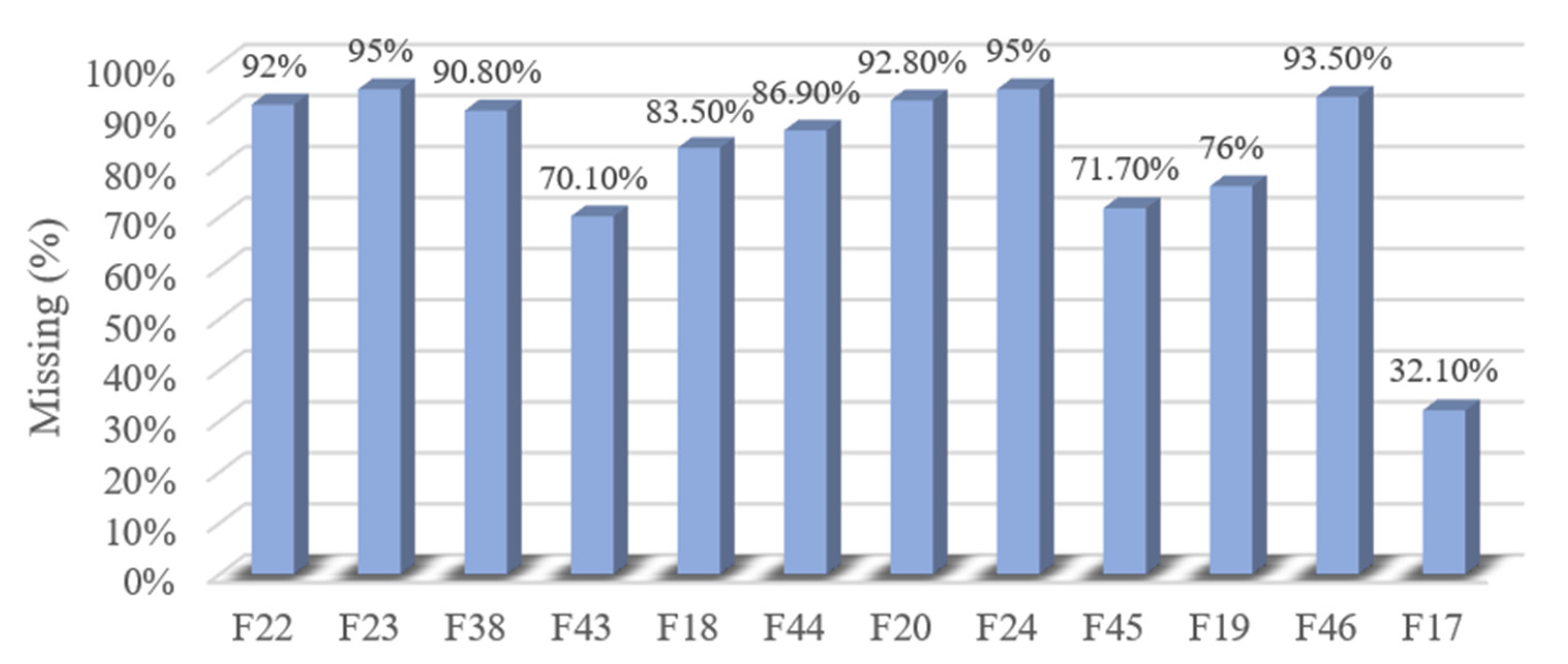
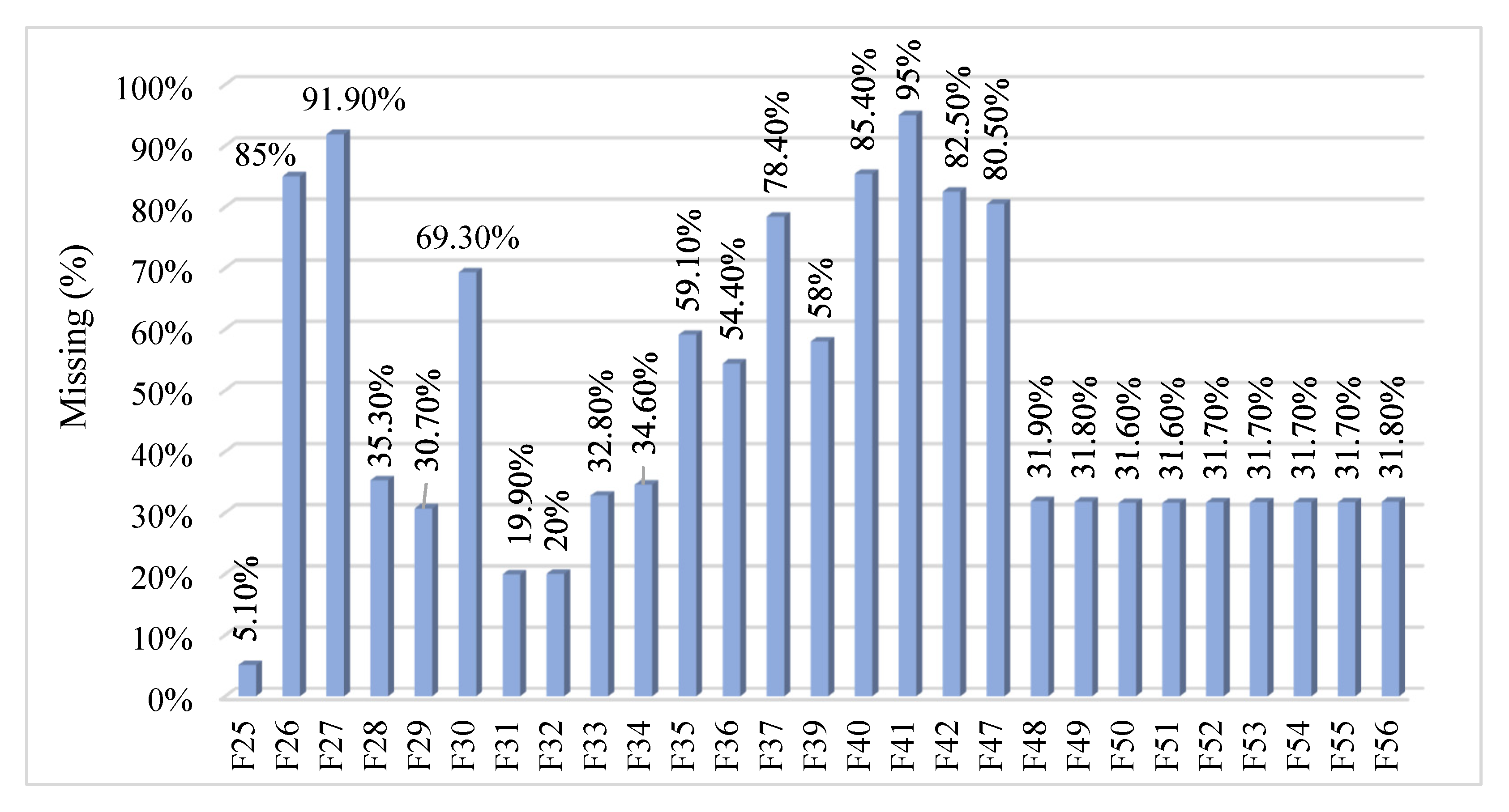
4.3. Missing Data Pattern Analysis
4.4. Experiments and Results
- -
- Single imputation experimentIn this experiment set, the single imputation methods KNN and hot-deck compete for imputing missing values with MCAR patterns to determine the WinnerDMCAR dataset. The results reported in Table 2 show that the KNN imputation method has better performance. One of the causes of low accuracy of classification in multiple imputations could be the lack of important biological factors in the diagnosis of diabetes, such as fasting blood sugar as well as the high percentage of missingness in the imputed dataset.
- -
- Multiple imputation experimentIn this experiment, the Em, MICE, and MCMC multiple imputation methods are considered to impute missing values with MAR patterns in the IRDia dataset and determine the WinnerDMAR dataset by comparing the performance of different classifiers. The multiple imputation method compensates for the imputed uncertainty relative to the unmeasured data, which results in the occurrence of missingness, by generating several datasets. The classification accuracy rate of all the imputed datasets is measured by the CART decision tree classifier. Then, the dataset with the maximum accuracy rate is selected. The selected dataset is the best-imputed dataset and contains imputed data with minimum uncertainty relative to the unmeasured data. The obtained results from this experimental evaluation are reported in Table 3. The MICE method exhibited better performance than the two other methods in the IRDia dataset.
- -
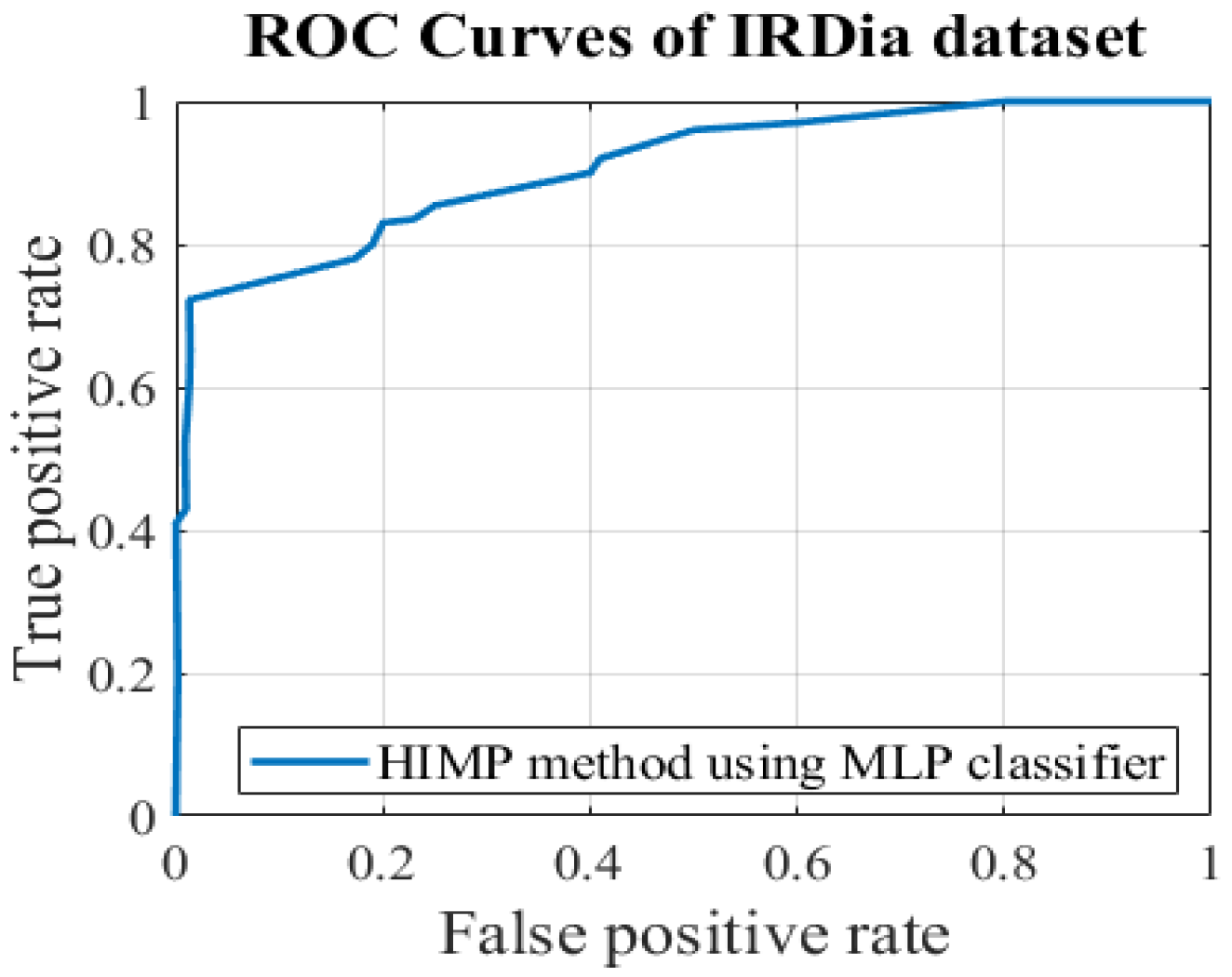
- Evaluation of the HIMP imputation methodOnce the best single and multiple imputation methods were obtained, imputed datasets WinnerDMCAR and WinnerDMAR with the best results were used to merge the final dataset. Then, the KNN and MICE methods, which yielded the best results, were implemented separately on the entire dataset with missing values. In this experimental evaluation, the hybrid imputation method is compared with MICE [71], KNN [65], fuzzy c-means SvrGa imputation (SvrFcmGa) [59], and without the applying of imputation (along with the missing values) on the IRDia dataset. The obtained results are reported in Table 4. The experimental results demonstrated that the proposed HIMP method yields more sufficient than other imputation methods.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fana, S.E.; Esmaeili, F.; Esmaeili, S.; Bandaryan, F.; Esfahani, E.N.; Amoli, M.M.; Razi, F. Knowledge discovery in genetics of diabetes in Iran, a roadmap for future researches. J. Diabetes Metab. Disord. 2021, 20, 1785–1791. [Google Scholar] [CrossRef] [PubMed]
- Nejat, N.; Hezave, A.K.M.; Pour, S.M.A.; Rezaei, K.; Moslemi, A.; Mehrabi, F. Self-care and related factors in patients with type II diabetes in Iran. J. Diabetes Metab. Disord. 2021, 20, 635–639. [Google Scholar] [CrossRef] [PubMed]
- Tigga, N.P.; Garg, S. Prediction of type 2 diabetes using machine learning classification methods. Procedia Comput. Sci. 2020, 167, 706–716. [Google Scholar] [CrossRef]
- Ogurtsova, K.; da Rocha Fernandes, J.; Huang, Y.; Linnenkamp, U.; Guariguata, L.; Cho, N.; Cavan, D.; Shaw, J.; Makaroff, L. IDF Diabetes Atlas: Global estimates for the prevalence of diabetes for 2015 and 2040. Diabetes Res. Clin. Pract. 2017, 128, 40–50. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Farshchi, A.; Esteghamati, A.; Sari, A.A.; Kebriaeezadeh, A.; Abdollahi, M.; Dorkoosh, F.A.; Khamseh, M.E.; Aghili, R.; Keshtkar, A.; Ebadi, M. The cost of diabetes chronic complications among Iranian people with type 2 diabetes mellitus. J. Diabetes Metab. Disord. 2014, 13, 4. [Google Scholar] [CrossRef] [Green Version]
- Noshad, S.; Afarideh, M.; Heidari, B.; Mechanick, J.I.; Esteghamati, A. Diabetes care in Iran: Where we stand and where we are headed. Ann. Glob. Health 2015, 81, 839–850. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Swapna, G.; Vinayakumar, R.; Soman, K. Diabetes detection using deep learning algorithms. ICT express 2018, 4, 243–246. [Google Scholar]
- Alirezaei, M.; Niaki, S.T.A.; Niaki, S.A.A. A bi-objective hybrid optimization algorithm to reduce noise and data dimension in diabetes diagnosis using support vector machines. Expert Syst. Appl. 2019, 127, 47–57. [Google Scholar] [CrossRef]
- Kamel, S.R.; Yaghoubzadeh, R. Feature selection using grasshopper optimization algorithm in diagnosis of diabetes disease. Inform. Med. Unlocked 2021, 26, 100707. [Google Scholar] [CrossRef]
- Qiao, L.; Zhu, Y.; Zhou, H. Diabetic retinopathy detection using prognosis of microaneurysm and early diagnosis system for non-proliferative diabetic retinopathy based on deep learning algorithms. IEEE Access 2020, 8, 104292–104302. [Google Scholar] [CrossRef]
- Harding, J.L.; Pavkov, M.E.; Magliano, D.J.; Shaw, J.E.; Gregg, E.W. Global trends in diabetes complications: A review of current evidence. Diabetologia 2019, 62, 3–16. [Google Scholar] [CrossRef] [Green Version]
- Taheri, H.; Rafaiee, R.; Rafaiee, R. Prevalence of Complications of Diabetes and Risk Factors Among Patients with Diabetes in the Diabetes Clinic in Southeast of Iran. Iran. J. Diabetes Obes. 2021, 13, 10–18. [Google Scholar] [CrossRef]
- Schlienger, J.-L. Type 2 diabetes complications. Presse Med. 2013, 42, 839–848. [Google Scholar] [CrossRef] [PubMed]
- Vigneri, P.; Frasca, F.; Sciacca, L.; Pandini, G.; Vigneri, R. Diabetes and cancer. Endocr.-Relat. Cancer 2009, 16, 1103–1123. [Google Scholar] [CrossRef] [Green Version]
- Ferro, M.; Katalin, M.O.; Buonerba, C.; Marian, R.; Cantiello, F.; Musi, G.; Di Stasi, S.; Hurle, R.; Guazzoni, G.; Busetto, G.M. Type 2 diabetes mellitus predicts worse outcomes in patients with high-grade T1 bladder cancer receiving bacillus Calmette-Guérin after transurethral resection of the bladder tumor. Urol. Oncol. Semin. Orig. Investig. 2020, 38, 459–464. [Google Scholar] [CrossRef] [PubMed]
- Giovannone, R.; Busetto, G.M.; Antonini, G.; De Cobelli, O.; Ferro, M.; Tricarico, S.; Del Giudice, F.; Ragonesi, G.; Conti, S.L.; Lucarelli, G. Hyperhomocysteinemia as an early predictor of erectile dysfunction: International Index of Erectile Function (IIEF) and penile Doppler ultrasound correlation with plasma levels of homocysteine. Medicine 2015, 94, e1556. [Google Scholar] [CrossRef]
- Mellitus, D. Diagnosis and classification of diabetes mellitus. Diabetes care 2006, 29, S43. [Google Scholar]
- Deshpande, A.D.; Harris-Hayes, M.; Schootman, M. Epidemiology of diabetes and diabetes-related complications. Phys. Ther. 2008, 88, 1254–1264. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahaman, S. Diabetes diagnosis decision support system based on symptoms, signs and risk factor using special computational algorithm by rule base. In Proceedings of the 2012 15th International Conference on Computer and Information Technology (ICCIT), Chittagong, Bangladesh, 22–24 December 2012; pp. 65–71. [Google Scholar]
- Omisore, O.M.; Ojokoh, B.A.; Babalola, A.E.; Igbe, T.; Folajimi, Y.; Nie, Z.; Wang, L. An affective learning-based system for diagnosis and personalized management of diabetes mellitus. Future Gener. Comput. Syst. 2021, 117, 273–290. [Google Scholar] [CrossRef]
- Qurat-Ul-Ain, F.A.; Ejaz, M.Y. A comparative analysis on diagnosis of diabetes mellitus using different approaches–A survey. Inform. Med. Unlocked 2020, 21, 100482. [Google Scholar]
- Golestan Hashemi, F.S.; Razi Ismail, M.; Rafii Yusop, M.; Golestan Hashemi, M.S.; Nadimi Shahraki, M.H.; Rastegari, H.; Miah, G.; Aslani, F. Intelligent mining of large-scale bio-data: Bioinformatics applications. Biotechnol. Biotechnol. Equip. 2018, 32, 10–29. [Google Scholar] [CrossRef] [Green Version]
- Esfandiari, N.; Babavalian, M.R.; Moghadam, A.-M.E.; Tabar, V.K. Knowledge discovery in medicine: Current issue and future trend. Expert Syst. Appl. 2014, 41, 4434–4463. [Google Scholar] [CrossRef]
- Fasihi, M.; Nadimi-Shahraki, M.H. Multi-class cardiovascular diseases diagnosis from electrocardiogram signals using 1-D convolution neural network. In Proceedings of the 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 11–13 August 2020; pp. 372–378. [Google Scholar]
- Bai, B.M.; Nalini, B.; Majumdar, J. Analysis and detection of diabetes using data mining techniques—a big data application in health care. In Emerging Research in Computing, Information, Communication and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 443–455. [Google Scholar]
- Zamani, H.; Nadimi-Shahraki, M.-H. Swarm intelligence approach for breast cancer diagnosis. Int. J. Comput. Appl. 2016, 151, 40–44. [Google Scholar] [CrossRef]
- Fasihi, M.; Nadimi-Shahraki, M.H.; Jannesari, A. A Shallow 1-D Convolution Neural Network for Fetal State Assessment Based on Cardiotocogram. SN Comput. Sci. 2021, 2, 287. [Google Scholar] [CrossRef]
- Dagliati, A.; Marini, S.; Sacchi, L.; Cogni, G.; Teliti, M.; Tibollo, V.; De Cata, P.; Chiovato, L.; Bellazzi, R. Machine learning methods to predict diabetes complications. J. Diabetes Sci. Technol. 2018, 12, 295–302. [Google Scholar] [CrossRef]
- Hasan, M.K.; Alam, M.A.; Das, D.; Hossain, E.; Hasan, M. Diabetes prediction using ensembling of different machine learning classifiers. IEEE Access 2020, 8, 76516–76531. [Google Scholar] [CrossRef]
- Kavakiotis, I.; Tsave, O.; Salifoglou, A.; Maglaveras, N.; Vlahavas, I.; Chouvarda, I. Machine learning and data mining methods in diabetes research. Comput. Struct. Biotechnol. J. 2017, 15, 104–116. [Google Scholar] [CrossRef]
- Zheng, T.; Xie, W.; Xu, L.; He, X.; Zhang, Y.; You, M.; Yang, G.; Chen, Y. A machine learning-based framework to identify type 2 diabetes through electronic health records. Int. J. Med. Inform. 2017, 97, 120–127. [Google Scholar] [CrossRef] [Green Version]
- Nadimi-Shaharaki, M.H.; Ghahramani, M. Efficient data preparation techniques for diabetes detection. In Proceedings of the IEEE EUROCON 2015-International Conference on Computer as a Tool (EUROCON), Salamanca, Spain, 8–11 September 2015; pp. 1–6. [Google Scholar]
- Eisemann, N.; Waldmann, A.; Katalinic, A. Imputation of missing values of tumour stage in population-based cancer registration. BMC Med. Res. Methodol. 2011, 11, 129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yoo, I.; Alafaireet, P.; Marinov, M.; Pena-Hernandez, K.; Gopidi, R.; Chang, J.-F.; Hua, L. Data mining in healthcare and biomedicine: A survey of the literature. J. Med. Syst. 2012, 36, 2431–2448. [Google Scholar] [CrossRef]
- Nadimi-Shahraki, M.H.; Banaie-Dezfouli, M.; Zamani, H.; Taghian, S.; Mirjalili, S. B-MFO: A Binary Moth-Flame Optimization for Feature Selection from Medical Datasets. Computers 2021, 10, 136. [Google Scholar] [CrossRef]
- Zamani, H.; Nadimi-Shahraki, M.H. Feature selection based on whale optimization algorithm for diseases diagnosis. Int. J. Comput. Sci. Inf. Secur. 2016, 14, 1243. [Google Scholar]
- Ramli, M.N.; Yahaya, A.; Ramli, N.; Yusof, N.; Abdullah, M. Roles of imputation methods for filling the missing values: A review. Adv. Environ. Biol. 2013, 7, 3861–3870. [Google Scholar]
- Nadimi-Shahraki, M.H.; Taghian, S.; Mirjalili, S. An improved grey wolf optimizer for solving engineering problems. Expert Syst. Appl. 2021, 166, 113917. [Google Scholar] [CrossRef]
- Zamani, H.; Nadimi-Shahraki, M.H.; Gandomi, A.H. QANA: Quantum-based avian navigation optimizer algorithm. Eng. Appl. Artif. Intell. 2021, 104, 104314. [Google Scholar] [CrossRef]
- Nadimi-Shahraki, M.H.; Fatahi, A.; Zamani, H.; Mirjalili, S.; Abualigah, L. An Improved Moth-Flame Optimization Algorithm with Adaptation Mechanism to Solve Numerical and Mechanical Engineering Problems. Entropy 2021, 23, 1637. [Google Scholar] [CrossRef]
- Zamani, H.; Nadimi-Shahraki, M.H.; Gandomi, A.H. CCSA: Conscious neighborhood-based crow search algorithm for solving global optimization problems. Appl. Soft Comput. 2019, 85, 105583. [Google Scholar] [CrossRef]
- Enders, C.K. Applied Missing Data Analysis; Guilford Press: New York, NY, USA, 2010. [Google Scholar]
- Fazakis, N.; Kostopoulos, G.; Kotsiantis, S.; Mporas, I. Iterative robust semi-supervised missing data imputation. IEEE Access 2020, 8, 90555–90569. [Google Scholar] [CrossRef]
- McKnight, P.E.; McKnight, K.M.; Sidani, S.; Figueredo, A.J. Missing Data: A Gentle Introduction; Guilford Press: New York, NY, USA, 2007. [Google Scholar]
- Lin, W.-C.; Tsai, C.-F. Missing value imputation: A review and analysis of the literature (2006–2017). Artif. Intell. Rev. 2020, 53, 1487–1509. [Google Scholar] [CrossRef]
- Cismondi, F.; Fialho, A.S.; Vieira, S.M.; Reti, S.R.; Sousa, J.M.; Finkelstein, S.N. Missing data in medical databases: Impute, delete or classify? Artif. Intell. Med. 2013, 58, 63–72. [Google Scholar] [CrossRef]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons: Hoboken, NJ, USA, 2019; Volume 793. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data preprocessing. In Data Mining Concepts and Techniques; Morgan Kaufmann: San Francisco, CA, USA, 2006; pp. 47–97. [Google Scholar]
- Graham, J.W. Missing data analysis: Making it work in the real world. Ann. Rev. Psychol. 2009, 60, 549–576. [Google Scholar] [CrossRef] [Green Version]
- Marwala, T. Computational Intelligence for Missing Data Imputation, Estimation, and Management: Knowledge Optimization Techniques; IGI Global: Hershey, PA, USA, 2009. [Google Scholar]
- Thomas, R.M.; Bruin, W.; Zhutovsky, P.; van Wingen, G. Dealing with missing data, small sample sizes, and heterogeneity in machine learning studies of brain disorders. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 249–266. [Google Scholar]
- Carpenter, J.; Kenward, M. Multiple Imputation and Its Application; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Van der Heijden, G.J.; Donders, A.R.T.; Stijnen, T.; Moons, K.G. Imputation of missing values is superior to complete case analysis and the missing-indicator method in multivariable diagnostic research: A clinical example. J. Clin. Epidemiol. 2006, 59, 1102–1109. [Google Scholar] [CrossRef] [PubMed]
- Raghunathan, K.; Soundarapandian, R.K.; Gandomi, A.H.; Ramachandran, M.; Patan, R.; Madda, R.B. Duo-stage decision: A framework for filling missing values, consistency check, and repair of decision matrices in multicriteria group decision making. IEEE Trans. Eng. Manag. 2019, 68, 1773–1785. [Google Scholar] [CrossRef]
- Masconi, K.L.; Matsha, T.E.; Echouffo-Tcheugui, J.B.; Erasmus, R.T.; Kengne, A.P. Reporting and handling of missing data in predictive research for prevalent undiagnosed type 2 diabetes mellitus: A systematic review. EPMA J. 2015, 6, 7. [Google Scholar] [CrossRef] [Green Version]
- Rezvan, P.H.; Lee, K.J.; Simpson, J.A. The rise of multiple imputation: A review of the reporting and implementation of the method in medical research. BMC Med. Res. Methodol. 2015, 15, 30. [Google Scholar]
- Gómez-Carracedo, M.; Andrade, J.; López-Mahía, P.; Muniategui, S.; Prada, D. A practical comparison of single and multiple imputation methods to handle complex missing data in air quality datasets. Chemom. Intell. Lab. Syst. 2014, 134, 23–33. [Google Scholar] [CrossRef]
- Rubin, D.B.; Schenker, N. Multiple imputation in health-are databases: An overview and some applications. Stat. Med. 1991, 10, 585–598. [Google Scholar] [CrossRef]
- Aydilek, I.B.; Arslan, A. A hybrid method for imputation of missing values using optimized fuzzy c-means with support vector regression and a genetic algorithm. Inf. Sci. 2013, 233, 25–35. [Google Scholar] [CrossRef]
- Li, D.; Zhang, H.; Li, T.; Bouras, A.; Yu, X.; Wang, T. Hybrid Missing Value Imputation Algorithms Using Fuzzy C-Means and Vaguely Quantified Rough Set. IEEE Trans. Fuzzy Syst. 2021. accepted. [Google Scholar] [CrossRef]
- Purwar, A.; Singh, S.K. Hybrid prediction model with missing value imputation for medical data. Expert Syst. Appl. 2015, 42, 5621–5631. [Google Scholar] [CrossRef]
- Rani, P.; Kumar, R.; Jain, A. HIOC: A hybrid imputation method to predict missing values in medical datasets. Int. J. Intell. Comput. Cybern. 2021, 14, 598–661. [Google Scholar] [CrossRef]
- Tian, J.; Yu, B.; Yu, D.; Ma, S. Missing data analyses: A hybrid multiple imputation algorithm using gray system theory and entropy based on clustering. Appl. Intell. 2014, 40, 376–388. [Google Scholar] [CrossRef]
- Vazifehdan, M.; Moattar, M.H.; Jalali, M. A hybrid Bayesian network and tensor factorization approach for missing value imputation to improve breast cancer recurrence prediction. J. King Saud Univ. Comput. Inf. Sci. 2019, 31, 175–184. [Google Scholar] [CrossRef]
- Malarvizhi, R.; Thanamani, A.S. K-nearest neighbor in missing data imputation. Int. J. Eng. Res. Dev. 2012, 5, 5–7. [Google Scholar]
- Ford, B.L. An overview of hot-deck procedures. In Incomplete Data in Sample Surveys; Academic Press: New York, NY, USA, 1983; Volume 2, pp. 185–207. [Google Scholar]
- Neal, R.M. Probabilistic Inference Using Markov Chain Monte Carlo Methods; Department of Computer Science, University of Toronto: Toronto, ON, Canada, 1993. [Google Scholar]
- Roth, P.L.; Switzer, F.S., III. A Monte Carlo analysis of missing data techniques in a HRM setting. J. Manag. 1995, 21, 1003–1023. [Google Scholar] [CrossRef]
- Roth, P.L.; Switzer, F.S., III; Switzer, D.M. Missing data in multiple item scales: A Monte Carlo analysis of missing data techniques. Organ. Res. Methods 1999, 2, 211–232. [Google Scholar] [CrossRef]
- Raghunathan, T.E.; Lepkowski, J.M.; Van Hoewyk, J.; Solenberger, P. A multivariate technique for multiply imputing missing values using a sequence of regression models. Surv. Methodol. 2001, 27, 85–96. [Google Scholar]
- Van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate imputation by chained equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef] [Green Version]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B Methodol. 1977, 39, 1–22. [Google Scholar]
- Dixon, J.K. Pattern recognition with partly missing data. IEEE Trans. Syst. Man Cybern. 1979, 9, 617–621. [Google Scholar] [CrossRef]
- García-Laencina, P.J.; Sancho-Gómez, J.-L.; Figueiras-Vidal, A.R. Pattern classification with missing data: A review. Neural Comput. Appl. 2010, 19, 263–282. [Google Scholar] [CrossRef]
- Norazian, M.N.; Shukri, A.; Yahaya, P.; Azam, N.; Ramli, P.; Fitri, N.F.; Yusof, M.; Mohd Mustafa Al Bakri, A. Roles of imputation methods for filling the missing values: A review. Adv. Environ. Biol. 2013, 7, 3861–3869. [Google Scholar]
- Chowdhury, M.H.; Islam, M.K.; Khan, S.I. Imputation of missing healthcare data. In Proceedings of the 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–24 December 2017; pp. 1–6. [Google Scholar]
- Feng, R.; Grana, D.; Balling, N. Imputation of missing well log data by random forest and its uncertainty analysis. Comput. Geosci. 2021, 152, 104763. [Google Scholar] [CrossRef]
- Hegde, H.; Shimpi, N.; Panny, A.; Glurich, I.; Christie, P.; Acharya, A. MICE vs. PPCA: Missing data imputation in healthcare. Inform. Med. Unlocked 2019, 17, 100275. [Google Scholar] [CrossRef]
- Jerez, J.M.; Molina, I.; García-Laencina, P.J.; Alba, E.; Ribelles, N.; Martín, M.; Franco, L. Missing data imputation using statistical and machine learning methods in a real breast cancer problem. Artif. Intell. Med. 2010, 50, 105–115. [Google Scholar] [CrossRef]
- Liu, Z.-g.; Pan, Q.; Dezert, J.; Martin, A. Adaptive imputation of missing values for incomplete pattern classification. Pattern Recognit. 2016, 52, 85–95. [Google Scholar] [CrossRef] [Green Version]
- Zhong, C.; Pedrycz, W.; Wang, D.; Li, L.; Li, Z. Granular data imputation: A framework of granular computing. Appl. Soft Comput. 2016, 46, 307–316. [Google Scholar] [CrossRef]
- Jeong, D.; Park, C.; Ko, Y.M. Missing data imputation using mixture factor analysis for building electric load data. Appl. Energy 2021, 304, 117655. [Google Scholar] [CrossRef]
- Lin, T.H. A comparison of multiple imputation with EM algorithm and MCMC method for quality of life missing data. Qual. Quant. 2010, 44, 277–287. [Google Scholar] [CrossRef]
- Poolsawad, N.; Moore, L.; Kambhampati, C.; Cleland, J.G. Handling missing values in data mining—A case study of heart failure dataset. In Proceedings of the 2012 9th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Chongqing, China, 29–31 May 2012; pp. 2934–2938. [Google Scholar]
- Azur, M.J.; Stuart, E.A.; Frangakis, C.; Leaf, P.J. Multiple imputation by chained equations: What is it and how does it work? Int. J. Methods Psychiatr. Res. 2011, 20, 40–49. [Google Scholar] [CrossRef]
- Rahman, S.A.; Huang, Y.; Claassen, J.; Heintzman, N.; Kleinberg, S. Combining Fourier and lagged k-nearest neighbor imputation for biomedical time series data. J. Biomed. Inform. 2015, 58, 198–207. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Del Giudice, F.; Glover, F.; Belladelli, F.; De Berardinis, E.; Sciarra, A.; Salciccia, S.; Kasman, A.M.; Chen, T.; Eisenberg, M.L. Association of daily step count and serum testosterone among men in the United States. Endocrine 2021, 72, 874–881. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Yu, M.; Graubard, B.I.; Troiano, R.P.; Schenker, N. Multiple imputation of completely missing repeated measures data within person from a complex sample: Application to accelerometer data in the National Health and Nutrition Examination Survey. Stat. Med. 2016, 35, 5170–5188. [Google Scholar] [CrossRef] [PubMed]
- Saint-Maurice, P.F.; Troiano, R.P.; Bassett, D.R.; Graubard, B.I.; Carlson, S.A.; Shiroma, E.J.; Fulton, J.E.; Matthews, C.E. Association of daily step count and step intensity with mortality among US adults. Jama 2020, 323, 1151–1160. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S. Nearest neighbor selection for iteratively kNN imputation. J. Syst. Softw. 2012, 85, 2541–2552. [Google Scholar] [CrossRef]
- Lakshminarayan, K.; Harp, S.A.; Samad, T. Imputation of missing data in industrial databases. Appl. Intell. 1999, 11, 259–275. [Google Scholar] [CrossRef]
- Rubin, D.B. Multiple Imputation for Nonresponse in Surveys; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 81. [Google Scholar]
- Zhang, Z. Missing data imputation: Focusing on single imputation. Ann. Transl. Med. 2016, 4, 9. [Google Scholar]
- Khan, S.I.; Hoque, A.S.M.L. SICE: An improved missing data imputation technique. J. Big Data 2020, 7, 1–21. [Google Scholar] [CrossRef]
- Giardina, M.; Huo, Y.; Azuaje, F.; McCullagh, P.; Harper, R. A missing data estimation analysis in type II diabetes databases. In Proceedings of the 2005 18th IEEE Symposium on Computer-Based Medical Systems, Dublin, Ireland, 23–24 June 2005; pp. 347–352. [Google Scholar]
- Aljuaid, T.; Sasi, S. Proper imputation techniques for missing values in data sets. In Proceedings of the 2016 International Conference on Data Science and Engineering (ICDSE), Cochin, India, 23–25 August 2016; pp. 1–5. [Google Scholar]
- Mirkes, E.M.; Coats, T.J.; Levesley, J.; Gorban, A.N. Handling missing data in large healthcare dataset: A case study of unknown trauma outcomes. Comput. Biol. Med. 2016, 75, 203–216. [Google Scholar] [CrossRef] [Green Version]
- Sovilj, D.; Eirola, E.; Miche, Y.; Björk, K.-M.; Nian, R.; Akusok, A.; Lendasse, A. Extreme learning machine for missing data using multiple imputations. Neurocomputing 2016, 174, 220–231. [Google Scholar] [CrossRef]
- Faisal, S.; Tutz, G. Multiple imputation using nearest neighbor methods. Inf. Sci. 2021, 570, 500–516. [Google Scholar] [CrossRef]
- Blazek, K.; van Zwieten, A.; Saglimbene, V.; Teixeira-Pinto, A. A practical guide to multiple imputation of missing data in nephrology. Kidney Int. 2021, 99, 68–74. [Google Scholar] [CrossRef] [PubMed]
- Yoon, S.; Sull, S. GAMIN: Generative adversarial multiple imputation network for highly missing data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8456–8464. [Google Scholar]
- Takahashi, M. Multiple imputation regression discontinuity designs: Alternative to regression discontinuity designs to estimate the local average treatment effect at the cutoff. Commun. Stat. Simul. Comput. 2021, 50, 1–20. [Google Scholar] [CrossRef]
- Shin, K.; Han, J.; Kang, S. MI-MOTE: Multiple imputation-based minority oversampling technique for imbalanced and incomplete data classification. Inf. Sci. 2021, 575, 80–89. [Google Scholar] [CrossRef]
- Gautam, C.; Ravi, V. Data imputation via evolutionary computation, clustering and a neural network. Neurocomputing 2015, 156, 134–142. [Google Scholar] [CrossRef]
- Aleryani, A.; Wang, W.; De La Iglesia, B. Multiple Imputation Ensembles (MIE) for dealing with missing data. SN Comput. Sci. 2020, 1, 134. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Chong, W.; Li, S.; Arabo, A.; Xiao, J. MIAEC: Missing data imputation based on the evidence chain. IEEE Access 2018, 6, 12983–12992. [Google Scholar] [CrossRef]
- Tsai, C.-F.; Li, M.-L.; Lin, W.-C. A class center based approach for missing value imputation. Knowl.-Based Syst. 2018, 151, 124–135. [Google Scholar] [CrossRef]
- González-Vidal, A.; Rathore, P.; Rao, A.S.; Mendoza-Bernal, J.; Palaniswami, M.; Skarmeta-Gómez, A.F. Missing data imputation with bayesian maximum entropy for internet of things applications. IEEE Internet Things J. 2020, 8, 16108–16120. [Google Scholar] [CrossRef]
- Mostafa, S.M.; Eladimy, A.S.; Hamad, S.; Amano, H. CBRL and CBRC: Novel Algorithms for Improving Missing Value Imputation Accuracy Based on Bayesian Ridge Regression. Symmetry 2020, 12, 1594. [Google Scholar] [CrossRef]
- Li, L.; Zhou, H.; Liu, H.; Zhang, C.; Liu, J. A hybrid method coupling empirical mode decomposition and a long short-term memory network to predict missing measured signal data of SHM systems. Struct. Health Monit. 2020, 20, 1778–1793. [Google Scholar] [CrossRef]
- Park, S.-W.; Ko, J.-S.; Huh, J.-H.; Kim, J.-C. Review on Generative Adversarial Networks: Focusing on Computer Vision and Its Applications. Electronics 2021, 10, 1216. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, B.; Cai, X.; Guo, W.; Ding, X.; Yuan, X. Missing value imputation in multivariate time series with end-to-end generative adversarial networks. Inf. Sci. 2021, 551, 67–82. [Google Scholar] [CrossRef]
- Faisal, S.; Tutz, G. Imputation Methods for High-Dimensional Mixed-Type Datasets by Nearest Neighbors. Comput. Biol. Med. 2021, 135, 104577. [Google Scholar] [CrossRef]
- Wan, D.; Razavi-Far, R.; Saif, M.; Mozafari, N. COLI: Collaborative Clustering Missing Data Imputation. Pattern Recognit. Lett. 2021, 152, 420–427. [Google Scholar] [CrossRef]
- Shahjaman, M.; Rahman, M.R.; Islam, T.; Auwul, M.R.; Moni, M.A.; Mollah, M.N.H. rMisbeta: A robust missing value imputation approach in transcriptomics and metabolomics data. Comput. Biol. Med. 2021, 138, 104911. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Pedrycz, W.; Wu, K.; Shen, Y. Information granule-based classifier: A development of granular imputation of missing data. Knowl.-Based Syst. 2021, 214, 106737. [Google Scholar] [CrossRef]
- Nugroho, H.; Utama, N.P.; Surendro, K. Class center-based firefly algorithm for handling missing data. J. Big Data 2021, 8, 37. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature Name | MP | LI | CARR | LCTV | CRM | CMC | MDPs |
|---|---|---|---|---|---|---|---|---|
| F1 | Body fat | ✓ | - | - | ✓ | ✓ | ✓ | MNAR |
| F2 | Pregnancy | ✓ | - | ✓ | - | - | ✓ | MNAR |
| F3 | The total number of pregnancies | ✓ | - | ✓ | - | - | ✓ | MNAR |
| F4 | Pregnancy diabetes | ✓ | - | ✓ | - | - | ✓ | MNAR |
| F5 | Background of miscarriage | ✓ | - | ✓ | - | - | ✓ | MNAR |
| F6 | Background of birthing dead baby | ✓ | - | ✓ | - | - | ✓ | MNAR |
| F7 | Background of a premature baby | ✓ | - | ✓ | - | - | ✓ | MNAR |
| F8 | Macrosomia (babies weighing > 4kg) | ✓ | - | ✓ | - | - | ✓ | MNAR |
| F9 | Forearm measurement | ✓ | - | - | ✓ | ✓ | ✓ | MNAR |
| F10 | Muscle | ✓ | - | - | ✓ | ✓ | ✓ | MNAR |
| F11 | Visceral fat level | ✓ | - | - | ✓ | ✓ | ✓ | MNAR |
| F12 | Mid upper arm circumference (MUAC) | ✓ | - | - | ✓ | ✓ | ✓ | MNAR |
| F13 | Polycystic ovary syndrome (PCOS) | ✓ | - | ✓ | - | - | ✓ | MNAR |
| F14 | Leg width measurement | ✓ | - | - | ✓ | ✓ | ✓ | MNAR |
| F15 | Basal metabolic rate (BMR) | ✓ | - | - | ✓ | ✓ | ✓ | MNAR |
| F16 | Blood types | ✓ | - | - | ✓ | ✓ | ✓ | MNAR |
| F17 | Prostate-specific antigen (PSA) | ✓ | - | ✓ | - | - | ✓ | MNAR-MCAR |
| F18 | Calcium (Ca) | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F19 | Vitamin d 25-hydroxy test | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F20 | Iron | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F21 | Phosphorus (PO4) | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F22 | Sodium (NA) | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F23 | Folic acid | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F24 | Total iron-binding capacity (TIBC) | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F25 | Fasting blood sugar (FBS) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F26 | 2-h post-prandial blood glucose (2hPG) test | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F27 | Glucose 5pm (G 5pm) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F28 | Blood urea nitrogen (BUN) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F29 | Creatinine blood test (Cr) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F30 | Uric acid blood test | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F31 | Triglycerides blood test | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F32 | Cholesterol | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F33 | High-density lipoprotein (HDL) cholesterol | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F34 | Low-density lipoprotein (LDL) cholesterol | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F35 | Serum glutamic oxaloacetic transaminase (SGOT) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F36 | Serum glutamic pyruvic transaminase (SGPT) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F37 | Hemoglobin A1c (HbA1c) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F38 | Potassium blood test | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F39 | Thyroid stimulating hormone (TSH) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F40 | Triiodothyronine (T3) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F41 | T3 uptake (T3RU) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F42 | Total thyroxine (T4) test | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F43 | Erythrocyte sedimentation rate (ESR 1hr) | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F44 | C-reactive protein (CRP) | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F45 | Alkaline phosphatase (ALP) | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F46 | Ferritin | - | ✓ | - | ✓ | ✓ | - | MCAR |
| F47 | Urine culture | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F48 | Urine color | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F49 | Urine appearance | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F50 | Urine specific gravity | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F51 | Urine pH test | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F52 | Urine nitrate test (NT) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F53 | Urine glucose test | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F54 | Urine ketones test | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F55 | Urine protein test | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| F56 | Hemoglobin in the urine (hemoglobinuria) | ✓ | ✓ | ✓ | ✓ | - | ✓ | MAR |
| Assessing Metrics (%) | Classifiers | Hot-Deck | KNN |
|---|---|---|---|
| Imputation Method | Imputation Method | ||
| Accuracy | MLP | 75.01% | 78.56% |
| KNN | 70.40% | 74.05% | |
| CART | 71.26% | 79.05% | |
| Precision | MLP | 76.21% | 77.01% |
| KNN | 69.34% | 70.91% | |
| CART | 68.71% | 71.55% | |
| Recall | MLP | 75.28% | 77.21% |
| KNN | 67.63% | 69.18% | |
| CART | 70.92% | 72.45% | |
| F1-score | MLP | 75.74% | 77.11% |
| KNN | 68.47% | 70.03% | |
| CART | 69.80% | 71.80% |
| Assessing Metrics (%) | Classifiers | Em Imputation | MCMC Imputation | MICE Imputation |
|---|---|---|---|---|
| Accuracy | MLP | 86.34% | 85.01% | 91.04% |
| KNN | 82.66% | 79.61% | 83.23% | |
| CART | 83.77% | 82.95% | 84.67% | |
| Precision | MLP | 82.47% | 87.16% | 90.50% |
| KNN | 81.42% | 78.80% | 82.23% | |
| CART | 80.66% | 79.57% | 83.26% | |
| Recall | MLP | 81.09% | 80.65% | 86.97% |
| KNN | 79.65% | 71.27% | 85.53% | |
| CART | 80.79% | 79.15% | 81.23% | |
| F1-score | MLP | 81.77% | 83.78% | 88.70% |
| KNN | 80.53% | 74.85% | 83.85% | |
| CART | 80.73% | 79.36% | 82.23% |
| Assessing Metrics | Classifiers | Without-Imputation | MICE Imputation | KNN Imputation | SvrFcmGa Imputation | HIMP Method |
|---|---|---|---|---|---|---|
| Accuracy | MLP | 75.43% | 91.56% | 78.56% | 90.21% | 94.23% |
| KNN | 72.31% | 83.20% | 74.95% | 83.91% | 85.91% | |
| CART | 74.82% | 84.67% | 79.52% | 82.49% | 86.38% | |
| Precision | MLP | 73.45% | 90.50% | 77.01% | 89.54% | 91.68% |
| KNN | 71.59% | 82.23% | 70.91% | 80.25% | 86.47% | |
| CART | 72.87% | 83.26% | 71.55% | 81.12% | 85.27% | |
| Recall | MLP | 71.95% | 86.97% | 77.21% | 88.94% | 96.36% |
| KNN | 69.53% | 85.53% | 69.18% | 79.48% | 83.94% | |
| CART | 68.28% | 81.23% | 72.45% | 80.67% | 84.57% | |
| F1-score | MLP | 72.69% | 88.70% | 77.11% | 89.24% | 93.97% |
| KNN | 70.55% | 83.85% | 70.03% | 79.86% | 85.19% | |
| CART | 70.50% | 82.23% | 71.80% | 80.89% | 84.92% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nadimi-Shahraki, M.H.; Mohammadi, S.; Zamani, H.; Gandomi, M.; Gandomi, A.H. A Hybrid Imputation Method for Multi-Pattern Missing Data: A Case Study on Type II Diabetes Diagnosis. Electronics 2021, 10, 3167. https://doi.org/10.3390/electronics10243167
Nadimi-Shahraki MH, Mohammadi S, Zamani H, Gandomi M, Gandomi AH. A Hybrid Imputation Method for Multi-Pattern Missing Data: A Case Study on Type II Diabetes Diagnosis. Electronics. 2021; 10(24):3167. https://doi.org/10.3390/electronics10243167
Chicago/Turabian StyleNadimi-Shahraki, Mohammad H., Saeed Mohammadi, Hoda Zamani, Mostafa Gandomi, and Amir H. Gandomi. 2021. "A Hybrid Imputation Method for Multi-Pattern Missing Data: A Case Study on Type II Diabetes Diagnosis" Electronics 10, no. 24: 3167. https://doi.org/10.3390/electronics10243167