Figure 1.
Datasets. (a) SDUST dataset. (b) FYO dataset. (c) NCUT dataset.
Figure 1.
Datasets. (a) SDUST dataset. (b) FYO dataset. (c) NCUT dataset.
Figure 2.
Fusion Dataset.
Figure 2.
Fusion Dataset.
Figure 3.
ROI images from different datasets. (a) ROI of SDUST dataset. (b) ROI of FYO dataset. (c) ROI of NCUT dataset.
Figure 3.
ROI images from different datasets. (a) ROI of SDUST dataset. (b) ROI of FYO dataset. (c) ROI of NCUT dataset.
Figure 4.
Images after adding Gaussian noise. (a) SDUST dataset after adding Gaussian noise. (b) FYO dataset after adding Gaussian noise. (c) NCUT dataset after adding Gaussian noise.
Figure 4.
Images after adding Gaussian noise. (a) SDUST dataset after adding Gaussian noise. (b) FYO dataset after adding Gaussian noise. (c) NCUT dataset after adding Gaussian noise.
Figure 5.
Divided into 28 × 28 cell images of veins.
Figure 5.
Divided into 28 × 28 cell images of veins.
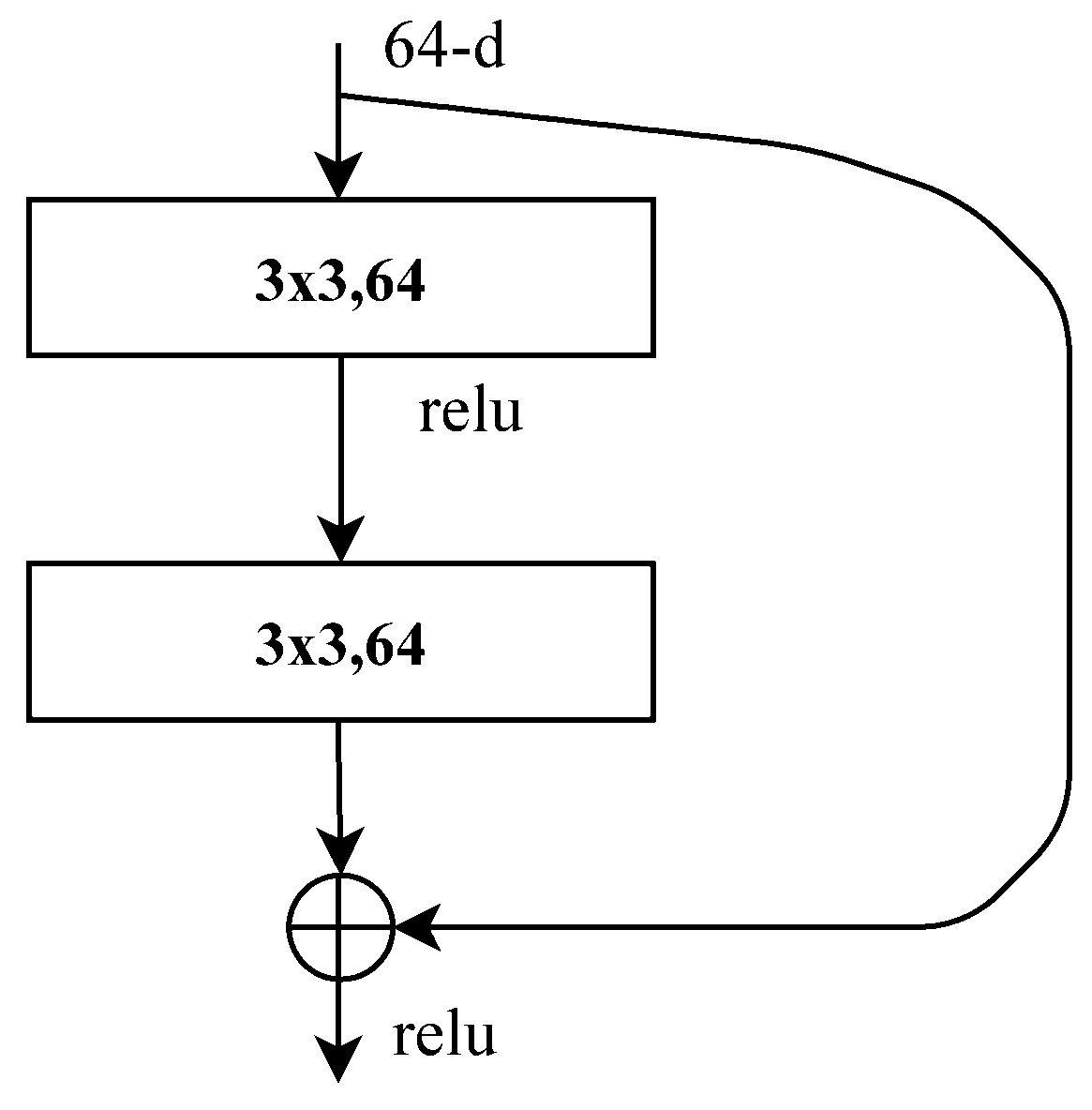
Figure 6.
Residual structure.
Figure 6.
Residual structure.
Figure 7.
ResNet34 residual structure.
Figure 7.
ResNet34 residual structure.
Figure 8.
ResNet and HOG feature fusion methods. (1.) Feature Fusion. This part obtains the HOG feature and shallow semantic information of the image, respectively, and then performs spatial feature fusion. (2.) Training and classification. The features after feature fusion are input into the residual architecture of ResNet for training, then input into the average pooling layer for dimensionality reduction, and finally input into the fully connected layer for classification.
Figure 8.
ResNet and HOG feature fusion methods. (1.) Feature Fusion. This part obtains the HOG feature and shallow semantic information of the image, respectively, and then performs spatial feature fusion. (2.) Training and classification. The features after feature fusion are input into the residual architecture of ResNet for training, then input into the average pooling layer for dimensionality reduction, and finally input into the fully connected layer for classification.
Figure 9.
ResNet and HOG fusion factor take values.
Figure 9.
ResNet and HOG fusion factor take values.
Figure 10.
The most misclassified tags in the FYO dataset.
Figure 10.
The most misclassified tags in the FYO dataset.
Figure 11.
The misclassification of most categories of texture information. (a) Registration characteristics of category 52. (b) Registration characteristics of category 131. (c) Testing characteristics of category 131. (d) Registration characteristics of category 170. (e) Testing characteristics of category 170.
Figure 11.
The misclassification of most categories of texture information. (a) Registration characteristics of category 52. (b) Registration characteristics of category 131. (c) Testing characteristics of category 131. (d) Registration characteristics of category 170. (e) Testing characteristics of category 170.
Figure 12.
Fusion dataset part identifies the worst class.
Figure 12.
Fusion dataset part identifies the worst class.
Figure 13.
The most misclassified categories.
Figure 13.
The most misclassified categories.
Figure 14.
HOG feature visualization for misclassification.
Figure 14.
HOG feature visualization for misclassification.
Figure 15.
Data volume vs. feature fusion. (a) Results of ResNet, HOG, and ResNet_HOG on FYO dataset. (b) Results of ResNet, HOG, and ResNet_HOG on SDUST dataset. (c) Results of ResNet, HOG, and ResNet_HOG on NCUT dataset. (d) Results of ResNet, HOG, and ResNet_HOG on Fusion dataset.
Figure 15.
Data volume vs. feature fusion. (a) Results of ResNet, HOG, and ResNet_HOG on FYO dataset. (b) Results of ResNet, HOG, and ResNet_HOG on SDUST dataset. (c) Results of ResNet, HOG, and ResNet_HOG on NCUT dataset. (d) Results of ResNet, HOG, and ResNet_HOG on Fusion dataset.
Table 1.
The ResNet34 network parameters in this paper. (* represents the number of categories classified.).
Table 1.
The ResNet34 network parameters in this paper. (* represents the number of categories classified.).
| Layer Name | Network Parameters | Input Size | Output Size |
|---|
| conv1 | 7 × 7, 64, stride2 | 224 × 224 × 3 | 56 × 56 × 3 |
| Conv_block1 | , stride2 | 56 × 56 × 64 | 56 × 56 × 64 |
| Conv_block2 | , stride2 | 56 × 56 × 64 | 28 × 28 × 128 |
| Conv_block3 | , stride2 | 28 × 28 × 128 | 14 × 14 × 256 |
| Conv_block4 | , stride2 | 14 × 14 × 256 | 7 × 7 × 512 |
| AdaptiveAvgPool2d (H, W) | H = 1, W = 1 | 7 × 7 × 512 | 1 × 1 × 512 |
| FC | \ | 512 | * |
Table 2.
Different Cell identification results.
Table 2.
Different Cell identification results.
| Number of Cells | Evaluation Methods |
|---|
| Recognition Rate (%) | Train Time (s) |
|---|
| 196 | 85.94 | 250 |
| 256 | 86.12 | 267 |
| 784 | 86.53 | 330 |
| 3136 | 86.46 | 694 |
Table 3.
ResNet and HOG feature fusion recognition rate.
Table 3.
ResNet and HOG feature fusion recognition rate.
| Methods | Recognition Rate (%) |
|---|
| SDUST | FYO | NCUT |
|---|
| Twenty | Thirty | Forty | Fifty | Twenty | Thirty | Forty | Fifty | Twenty | Thirty | Forty | Fifty |
|---|
| HOG | 83.06 | 83.13 | 83.15 | 83.16 | 82.01 | 82.04 | 82.08 | 82.10 | 81.30 | 81.32 | 81.34 | 81.35 |
| ResNet | 84.97 | 90.47 | 90.86 | 92.30 | 86.60 | 89.59 | 91.93 | 93.43 | 83.93 | 87.70 | 89.13 | 90.06 |
| ResNet_HOG (ours) | 86.57 | 91.03 | 92.70 | 93.27 | 90.46 | 92.40 | 94.60 | 95.36 | 86.53 | 90.10 | 91.67 | 93.40 |
Table 4.
Recognition rate on the fused dataset after feature fusion.
Table 4.
Recognition rate on the fused dataset after feature fusion.
| Methods | Recognition Rate (%) |
|---|
| Twenty | Thirty | Forty | Fifty |
|---|
| HOG | 67.34 | 67.36 | 67.37 | 67.39 |
| ResNet | 83.70 | 86.83 | 90.46 | 91.16 |
| ResNet_HOG (ours) | 85.70 | 89.46 | 92.27 | 93.47 |
Table 5.
Comparison of different methods.
Table 5.
Comparison of different methods.
| Methods | Recognition Rate (%) |
|---|
| SDUST | FYO | NCUT | Fusion Dataset |
|---|
| PLBP | 60.09 | 55.50 | 70.19 | 61.07 |
| HOG | 83.16 | 82.10 | 81.35 | 67.39 |
| ResNet | 92.30 | 93.43 | 90.06 | 91.16 |
| ResNet_HOG (ours) | 93.27 | 95.36 | 93.40 | 93.47 |
Table 6.
Recognition rates of different feature fusion methods on a single database.
Table 6.
Recognition rates of different feature fusion methods on a single database.
| Methods | Recognition Rate (%) |
|---|
| SDUST | FYO | NCUT |
|---|
| Twenty | Thirty | Forty | Fifty | Twenty | Thirty | Forty | Fifty | Twenty | Thirty | Forty | Fifty |
|---|
| ResNet_PLBP | 85.40 | 90.87 | 91.77 | 92.76 | 90.27 | 91.77 | 94.17 | 95.20 | 85.96 | 89.73 | 90.17 | 92.50 |
| VeinNet [17] | 92.28 | \ | \ |
| Skeleton [27] | \ | \ | 92.75 |
| CNN Model [18] | \ | 98.90 | \ |
| CNN [26] | \ | \ | 99.61 |
| ResNet_HOG (ours) | 86.57 | 91.03 | 92.70 | 93.27 | 90.46 | 92.40 | 94.60 | 95.36 | 86.53 | 90.10 | 91.67 | 93.40 |
Table 7.
Recognition rates of different feature fusion methods on fusion dataset.
Table 7.
Recognition rates of different feature fusion methods on fusion dataset.
| Methods | Recognition Rate (%) |
|---|
| Twenty | Thirty | Forty | Fifty |
|---|
| ResNet_PLBP | 84.47 | 89.26 | 92.13 | 92.63 |
| Improved SIFT [15] | 88.50 |
| SIFT [28] | 90.17 |
| Two-stage Coarse-to-fine Matching [16] | 96.80 |
| ResNet_HOG (ours) | 85.70 | 89.46 | 92.27 | 93.47 |
Table 8.
The influence of different gamma values on the experiment.
Table 8.
The influence of different gamma values on the experiment.
| Dataset | Gamma Value |
|---|
| 0.2 | 0.4 | 0.5 (ours) | 0.6 | 0.8 |
|---|
| NCUT | 86.52 | 86.61 | 86.53 | 86.58 | 86.60 |
| FYO | 90.26 | 90.35 | 90.46 | 90.38 | 90.42 |
| SDUST | 86.59 | 86.51 | 86.57 | 86.44 | 86.49 |
Table 9.
Influence of Gaussian noise intensity model.
Table 9.
Influence of Gaussian noise intensity model.
| Noise Range | 0.1–0.3 | 0.3–0.5 | 0.5–0.7 |
|---|
| Recognition Rate (%) | 77.45 | 72.94 | 66.81 |
Table 10.
Experimental comparison with and without convolution blocks.
Table 10.
Experimental comparison with and without convolution blocks.
| Methods | Recognition Rate (%) |
|---|
| NCUT | FYO | SDUST |
|---|
| With convolution blocks | 86.53 | 90.46 | 86.57 |
| No convolution blocks | 83.60 | 90.23 | 85.74 |
Table 11.
Experimental comparison of different data volumes.
Table 11.
Experimental comparison of different data volumes.
| Methods | Recognition Rate (%) |
|---|
| One Hundred Samples | One Hundred and Fifty Samples | Two Hundred Samples | Two Hundred and Fifty Samples |
|---|
| ResNet | 96.93 | 98.07 | 98.92 | 99.54 |
| ResNet_HOG | 97.89 | 98.84 | 99.27 | 99.93 |


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}