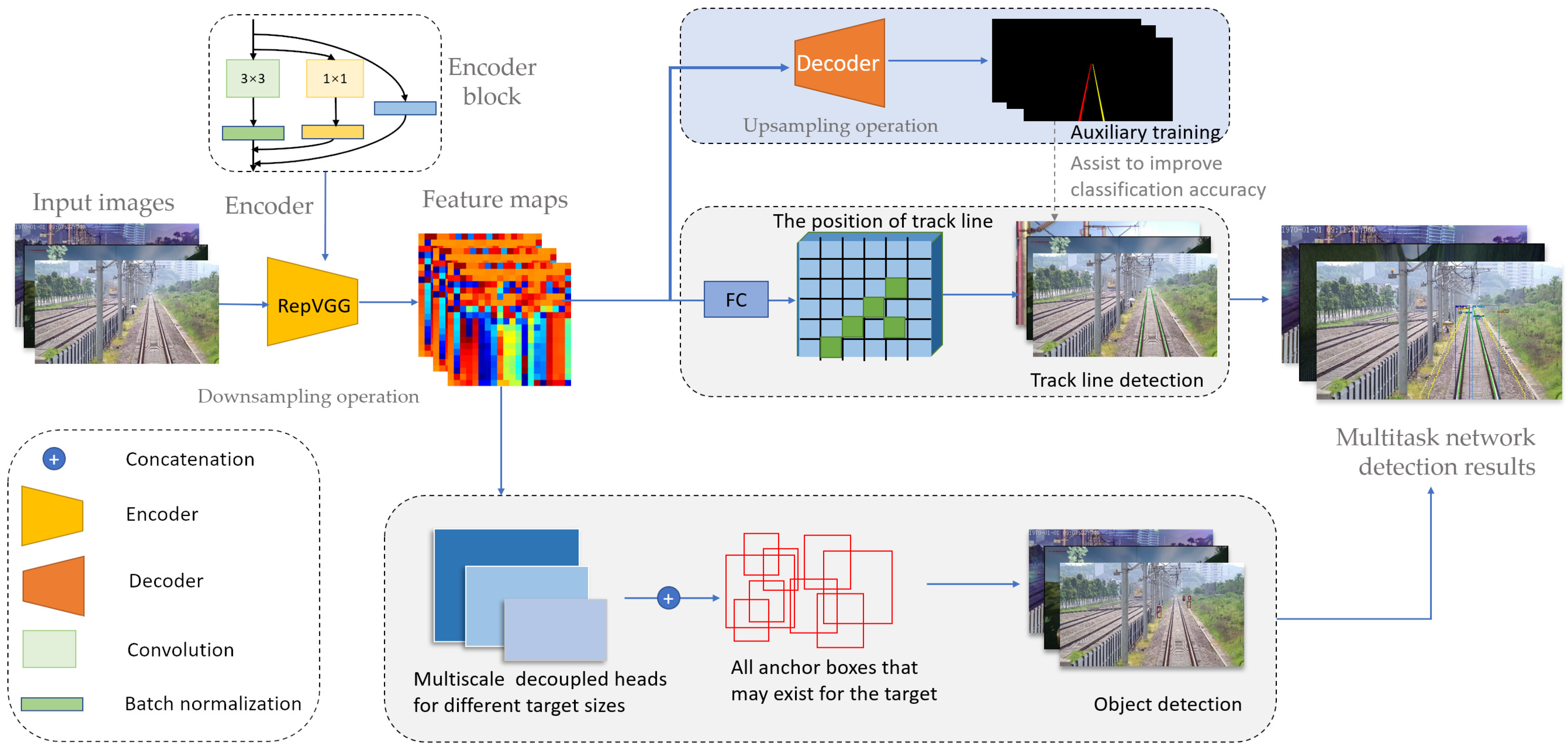
3.1. The Network of Multitask Learning
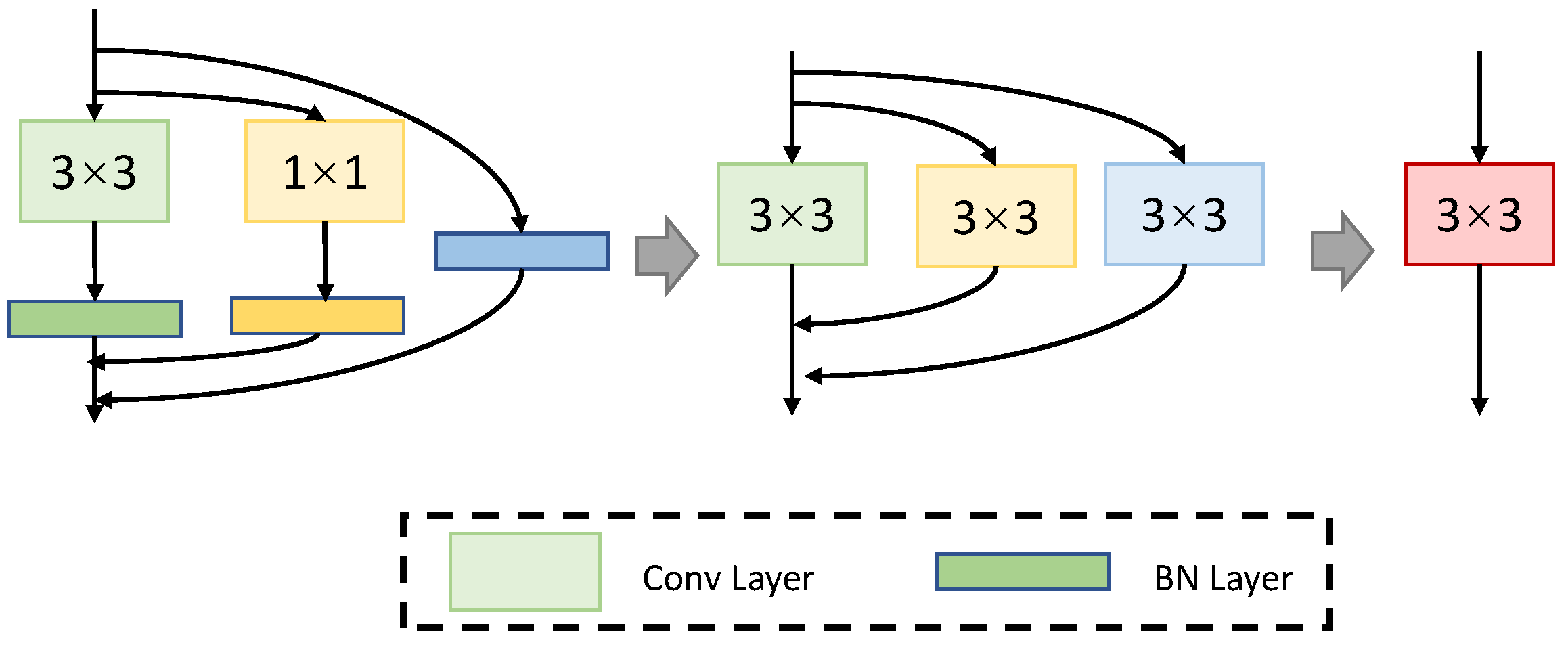
In this part, we go through the whole system used in our work from the backbone, neck, and head parts. We designed a network that contains one shared encoder and two subsequent decoders to solve specific tasks. There are no complex and redundant shared blocks between different decoders, which reduces computational consumption and allows our network to be easily trained end-to-end. The backbone network is used to extract the features of the input image. The neck is used to fuse the features generated by the backbone. Different decoders perform lane line detection and obstacle detection, respectively. Our backbone network used RepVGG [
26], which adopted the idea of structural reparameterization to improve the speed and accuracy of the network. The structural reparameterization is shown in
Figure 3.
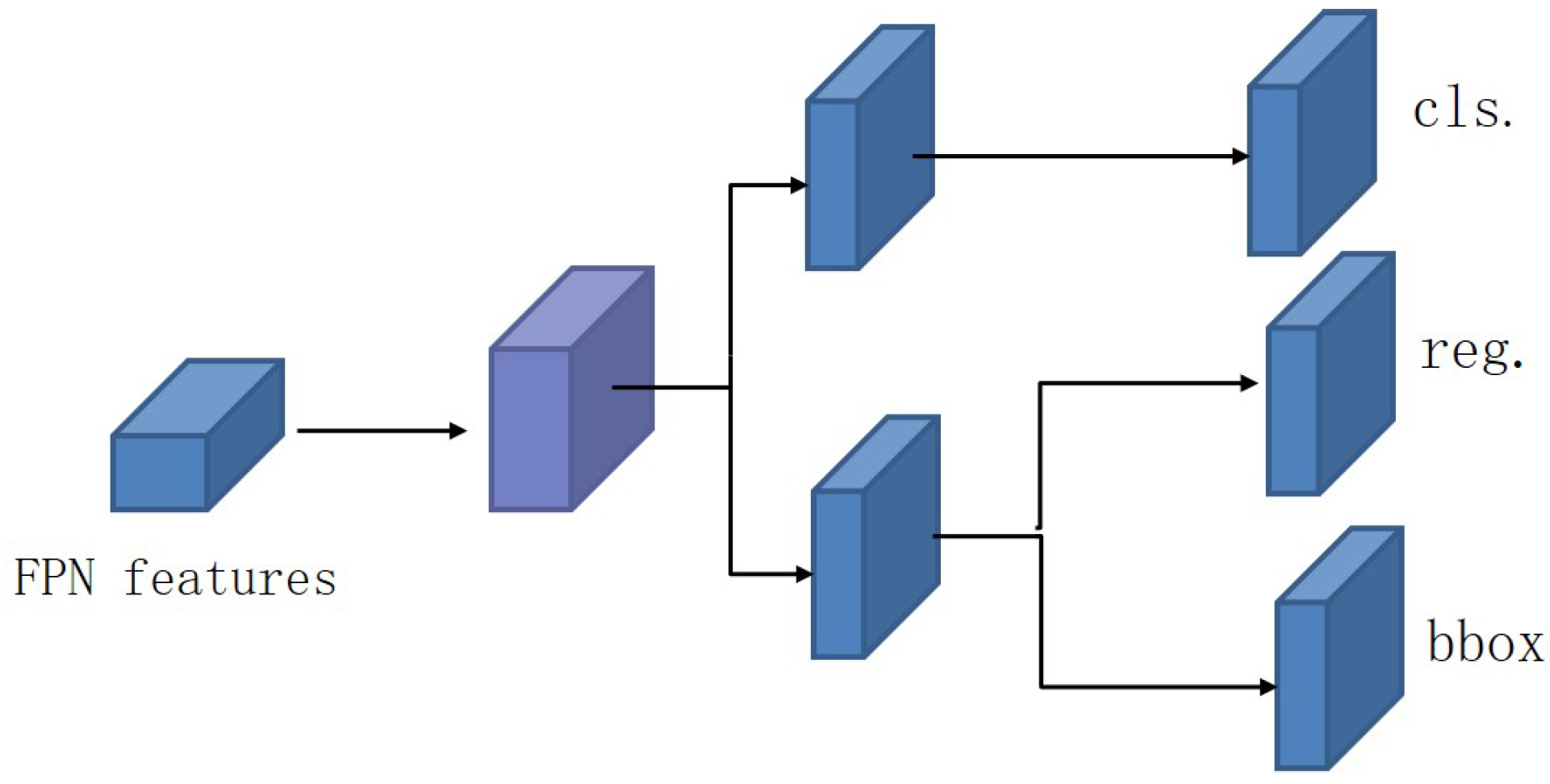
The target obstacle detection network and the train track line detection network share the backbone network which uses structural reparameterization. In the design of the head network used to detect objects, considering that the two tasks of target detection and target classification have different focal points and interesting parts, our network selects the decoupling head which is shown in
Figure 4. Considering that the anchor-frame-based method not only increases the complexity of the detection head, but also needs to migrate the prediction frame generated in the detection to the GPU when generating a large number of prediction frames, the application of some edge devices can lead to unsupported device performance and cannot be used in the actual landing scene. The anchor-frame-based target detection algorithm is also easily affected by the preset anchor frame. At the same time, based on the accuracy of small target detection in the detection process and the lightweight requirements of the target detection algorithm when the algorithm is deployed, the target detection network in this paper adopted an anchor-free target detection algorithm to improve the coupling degree of the target detection algorithm to a greater extent and enhance the generalization performance of object detection results on small object data.
In the process of intrusion detection, it is not only necessary to find the location and type of the obstacle, but also to clarify the location of the obstacle. If the obstacle is in the safe area, it is not necessary to issue an alarm frequently to affect the train staff. Furthermore, if the obstacle is in the alarm area, different levels of alarms need to be issued based on the intrusion degree of the obstacle. Therefore, the network needs to establish the encroachment area by detecting the track line and performs the expansion processing as needed based on the coordinates of the detected track line. For the segmentation algorithm, if the size of the lane line image is , then the classification problem needs to be dealt with when performing the segmentation. However, the slender structure of the lane line occupies a small proportion of the overall image. Pixel classification will generate a lot of unnecessary burdens and have a great impact on network performance.
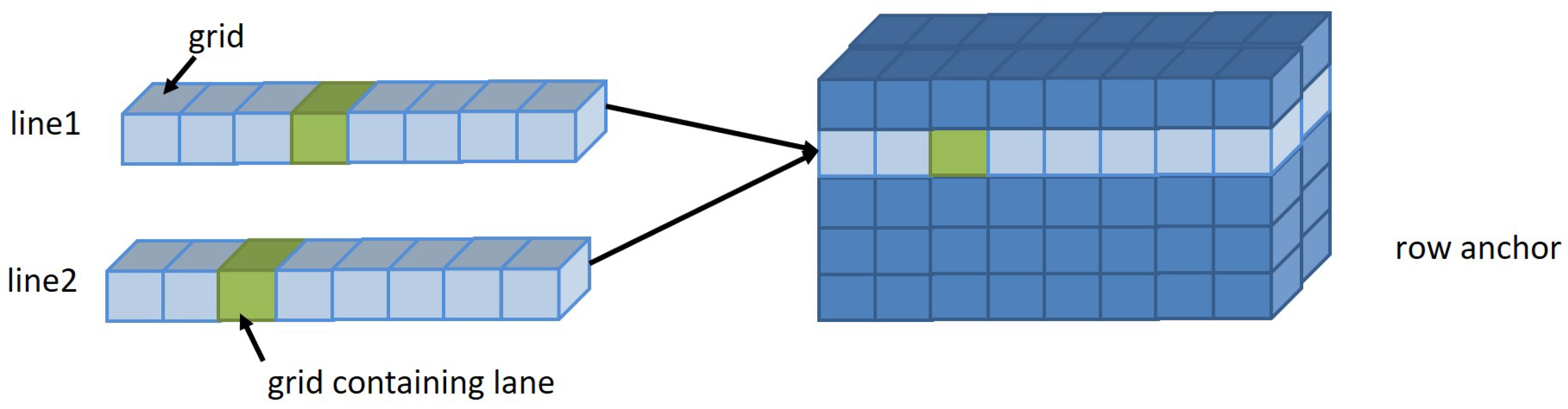
Therefore, based on the special structure of the track line, the row anchor method proposed in [
19] was adopted. The line classification method is used to judge whether the line has a track line on some preset lines. Line classification is a line direction selection strategy that only needs to deal with the classification problem on a given row. The classification problem on each row is
w-dimensional. Therefore, the original classification of the whole image becomes a classification problem based on a given line, and since the positioning on each line can be manually set, the size of h
can be set as needed, which greatly reduces the amount of network computation.
Considering that the track line itself has a certain thickness, a certain track line in a row can be regarded as a whole and can be divided into a grid. The network performs classification algorithm training and infers where this grid is located to determine where the track lines are located. Therefore, the network only needs to select the corresponding row anchor, whose schematic diagram is
Figure 5, in the given row anchor, when classifying and dividing the data in each row into corresponding grids, whose number is
w . Considering that there may be no track line in the target row anchor, one-dimensional data are added to indicate that the row has no lane lines, and the number of grids is
. So the number of classifications that the network needs to perform is
, which can greatly reduce the computational complexity of the network. At the same time, to improve the detection speed, the segmentation method is used to learn the shape, structure, and position distribution of the rail area in the network only during training. The segmentation result is classified based on the row anchor to determine the grid where the rail exists.
3.2. New Formulation for Multitask Learning
The formulation for obstacle detection. The detection loss
is a weighted sum of classification loss, object loss, and bounding box loss as follows:
where
and
are utilized to reduce the loss of well-classified examples, thus forcing the network to focus on the hard ones.
,
, and
are coefficients of these loss functions.
is used for penalizing classification and
for the confidence of one prediction. All of them use BCEWithLogitsLoss, whose formula expression is:
where
n represents the number of labels predicted per batch, and
can use formula
to map
x to the interval (0, 1).
, which is calculated by IoU, represents the intersection loss between the predicted box and the ground-truth box.
The formulation for line detection. For the lane line detection loss, the loss function generally consists of the loss of classification and the loss of segmentation. In order to better allow the network to learn the structural features of the lane lines and make sure that a relatively continuous track line maintaining a linear trend is identified, an additional structural loss was added. The loss function of the lane lines was as follows:
where
represents the loss of classification,
represents the structural loss used to constrain track line shapes, and
represents the loss of segmentation.
,
, and
are coefficients of these loss functions. In the classification loss,
X is used to represent the input image, and
is used to represent a classifier that can find the grid position where the
ith lane is located from the
jth row anchor. As a result,
represents the probability that each grid in the
jth row anchor had the
ith lane, and there are
w grids in total. Moreover,
indicates whether there is a lane line in the
jth row anchor and the grid position where the lane line is located. Both
and
are
-dimensional (a grid is used to indicate that the row has no track lines) vectors that satisfies one-hot encoding. We can get the loss function as follows:
where
represents the cross-entropy loss used here. According to this function, the probability distribution of all positions on each row of anchor points can be predicted based on the global features. Therefore, the correct location can be selected based on the probability distribution.
In addition to the classification loss, two loss functions are proposed to model the positional relationship of the lane line points. Because the lane lines are continuous, even if it is a curve, it can be approximated as a straight railway from a distance. Therefore, the lane lines between adjacent row anchors need to be close to each other. Furthermore, the distribution of the classification vector on the adjacent row anchors needs to be constrained to ensure that the predicted probabilities of the two adjacent row anchors are as close as possible, thereby ensuring the smoothness of the overall line. The predicted similarity loss function is as follows:
where
represents the probability that each grid in the
jth row anchor has the
ith lane. To account for the shape, the position of the lane on each row anchor needs to be calculated. Furthermore, the track line position is obtained from the classification prediction by finding the maximum response peak. Substituting differentiable
for
can get the second-order difference equation constraint
, which is obtained to ensure that the overall detected track line structure is relatively smooth and the slope is relatively similar. The formula expression is:
where
represents the expected value that the
jth orbital line in the
ith row anchor appears in the
kth grid.
in
is used as an approximation which chooses the probability of occurrence of lane lines in each grid instead of where the track lines are located.
Based on the rail shape constraints and the rail position similarity constraints, the rail structural loss can be obtained:
where
and
represents coefficients of different loss functions.
In addition to the and introduced above, we used the cross-entropy loss as the . The loss function of the lane line detection problem can then be obtained.
The formulation for the whole network. In the multitask learning process, the learning speed of different tasks is different. Based on the same input feature representation, some tasks have a low learning difficulty and fast convergence speed, while some tasks have a high learning difficulty and slow convergence speed. When the learning speed of tasks is unbalanced, it is easy to cause tasks with fast learning speed to dominate the learning process of the model, resulting in the phenomenon of self-reinforcing, which leads to the insufficient representation ability of the model and affects the results.
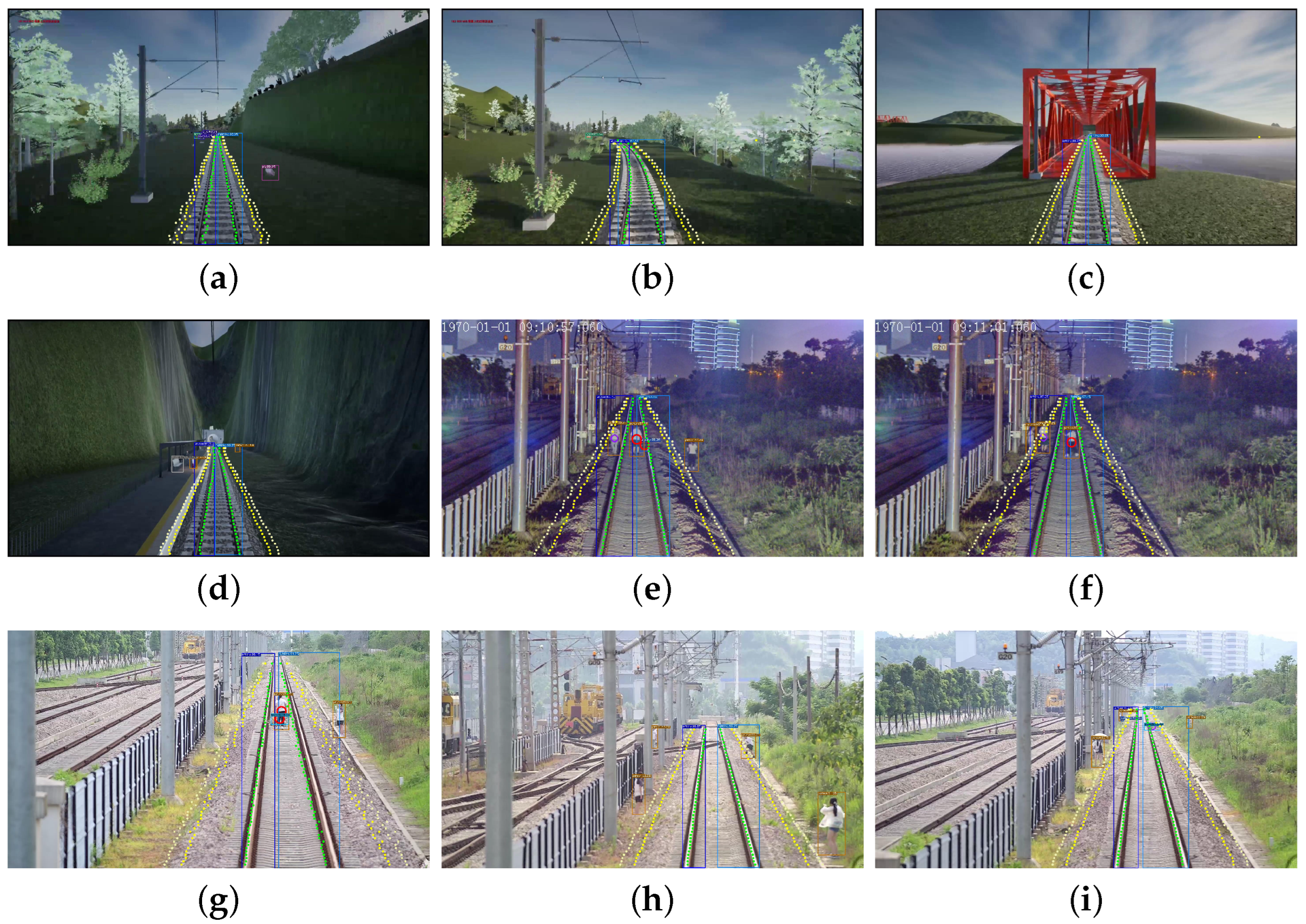
Due to the particularity of railway scenes, there are small target obstacles in both obstacle detection and track line detection tasks. Most of the pixels belong to the background area, and the target obstacles and track lines only occupy a very small part of the pixel area. At the same time, combined with the particularity of railway scenes, we pay more attention to medium- and long-distance obstacles during detection, which are more difficult to classify. These belong to the common features of the different tasks of this work. The labeled data can be seen in
Figure 6. Therefore, the target detection task has problems such as unbalanced proportion of obstacle categories and unbalanced sample distribution, since the obstacle detection work needs to be able to detect all possible target obstacles in the area, and the track line detection work only needs to identify and extract the two rail lines of the current train running. Because there are position offsets of the train track lines collected in different videos, the track line detection task also has the problem of unbalanced sample distribution when performing line classification.
Multitask networks need to study how to reasonably use the characteristics of different tasks to adjust the importance of tasks, so that the importance of tasks matches the update degree of the model parameters. Then, it can ensure the learning speed remains relatively balanced, and alleviate the problem of task advantages. Based on this, we propose a new calculation method, which dynamically adjusts the coefficients of the loss function of different tasks according to the number of categories and the difficulty of sample classification for different tasks.
When designing the task, we paid more attention to the samples with low confidence in the task, which are prone to misclassification during the training process and challenge the model. We used
as a judgment parameter for the difficulty of training samples, in which
p references the probability that the network predicts this task objective correctly. Because the confidence range of
p is (0,1], the more difficult the sample is to be predicted, the smaller the
is, and the larger the
is. At the same time, we also considered the impact of negative samples on the results and used
to represent the proportion of negative samples in the task weight. So the coefficient expression formula was:
where
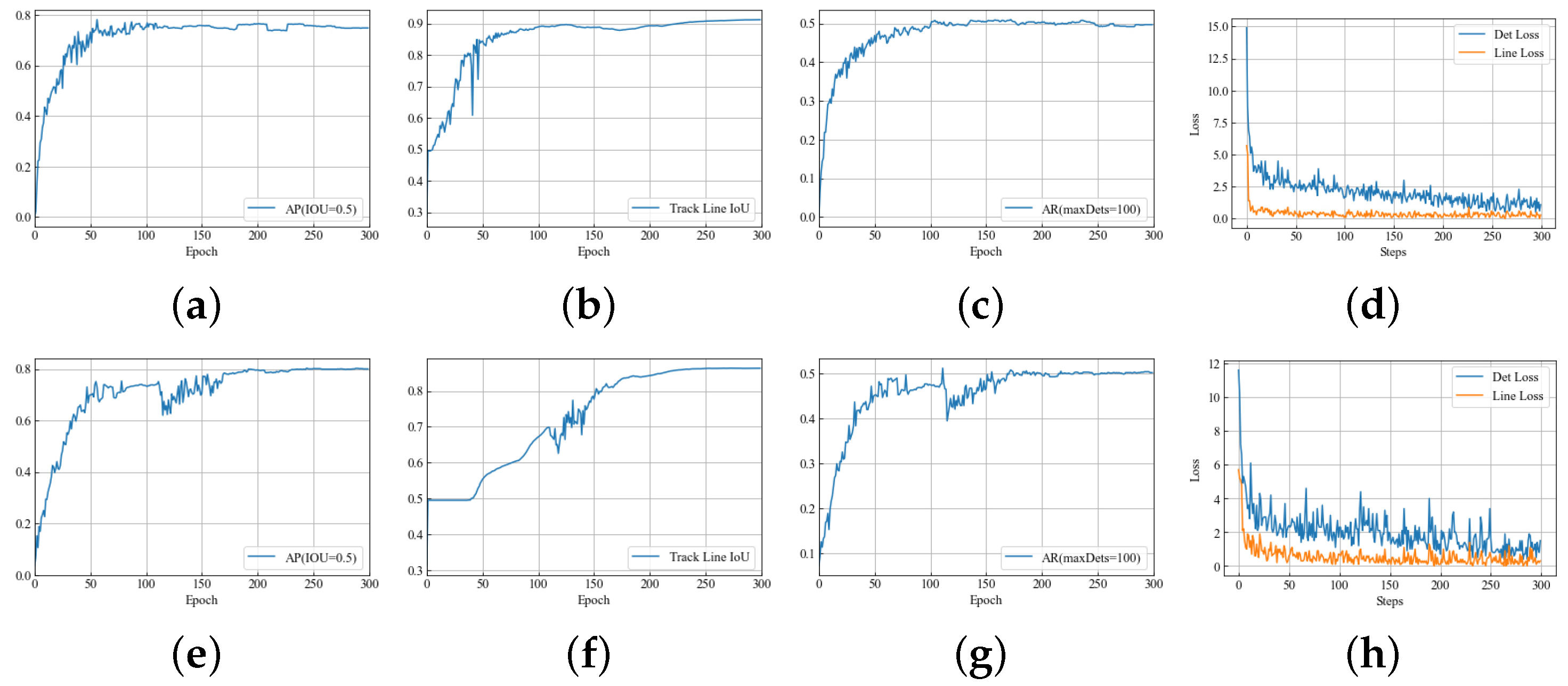
was set to 2. As shown in
Figure 7d, the line detection task is relatively simpler and has a faster convergence speed. In order to be able to balance two different tasks, it is necessary to relatively balance the two different tasks through the task coefficient. Therefore, the task coefficient designed above was substituted into the multitask network adaptive loss function formula
. The overall multitask network task formula was:
Figure 7h shows the loss function results after the multiobjective coefficient trade-off. The comparison of the training results proves that the algorithm proposed by this network is beneficial to trade-off tasks with multiple objectives. Weighted by this coefficient, different tasks can converge at a relatively balanced rate.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}