1. Introduction
The Internet is now an essential part of modern society and has surpassed the conventional ways of gathering information and knowledge from television and newspapers. Social media platforms have significantly changed the ways in which people receive news and current affairs around the globe. With social networking sites like Facebook and Twitter experiencing unprecedented growth in their user base, society is largely dependent on such platforms for acquiring news and information.
The ease of accessing social media platforms helps people to instantly share ideas and news without checking the legitimacy of the news source. Consequently, social media is being used for spreading misinformation and fake news [
1]. Social media is capable of propagating unverified content, creating an ecosystem of misinformation that may increase the likelihood of changing people’s perspectives of reality through the spread of fake news.
Fake news is information with false content, spread intentionally to manipulate public perspective on a specific agenda for political, social or economic gains or simply for fun. A concerning aspect of fake news is that it draws more public attention than legitimate sources of information [
2]. Moreover, fake news propagates much faster and penetrates deep into people’s minds to influence their perception than legitimate news does [
1]. Consequently, people usually accept and forward such news content without inspecting the authenticity of the source of news. This result in an exponential spread of fake news, either intentionally or knowingly, by many people. The repercussions of the spread of fake news are varied, with grave consequences such as compromised decision-making, cyberbullying, social hostility and violence.
The alarming impact of the spread of false news has come into the limelight in the current COVID-19 pandemic. The ongoing pandemic is considered one of the biggest current public health emergencies, affecting millions of humans in a number of ways [
3]. Throughout the pandemic, fake news has been circulating on digital platforms that has created panic among the public. Governments have had to step in to verify the authenticity of news, in order to alleviate panic and fear in the population and to maintain law and order. The pandemic has already disrupted human lives in unprecedented ways. The misinformation regarding COVID-19 has prompted many individuals to commit suicide after being diagnosed with the deadly virus [
4]. As COVID-19 is still a pandemic across many countries of the world, it would be necessary to work on controlling fake news about COVID-19 from being spread on social media platforms. Therefore, researchers are striving to control this menace by developing intelligent and automated techniques for identifying fake news content. To achieve this task, machine learning techniques are being applied to predict fake news content.
Machine learning (ML) techniques enable a computer system to automatically learn patterns and relationships from input data, using various algorithms to solve problems without being specifically programmed. Deep learning (DL) is a specialized type of ML employing artificial neural networks that imitates the human brain having multiple layers of neurons to solve complex problems. DL models are known to outperform ML models in solving several complex problems [
5].
The labeled data can be categorized using a supervised machine learning technique called classification [
6]. The classification technique can be used to classify the information as either true or false given a labeled dataset [
7]. Many researchers have made efforts to improve the classification accuracy on several datasets, however, more analysis is required to evaluate the effectiveness of the classification models in detecting the fake news content. This problem can be expressed as a text classification problem [
8,
9].
The identification of COVID-19 fake news is a binary classification problem. The present work intends to search the best classification model among several candidates for predicting fake news on COVID-19. The conventional ML models and recent DL models for text classification are evaluated for this task.
The main contributions are: The evaluation of six ML classifiers and two DL classifiers for the identification of fake news on two publicly available datasets. Secondly, comparing the best performing ML models with the DL models.
The rest of the paper is organized as follows:
Section 2 explore the related work on fake news prediction.
Section 3 describes the various classifiers used in this work.
Section 4 discusses the experimental setup.
Section 5 contains the results and discussion. Finally,
Section 6 contains conclusion and future work.
2. Related Work
This section will discuss several studies on the prediction of fake news. A study was specifically undertaken to discuss intelligent techniques for the identification of clickbait. The authors discussed the relevance of combining textual features like the semantics of news content, and non-textual features like graphics and user behavior for detecting fake news content [
10]. Another study on clickbait detection utilizes the clickbait headlines. The researchers have performed the experiments on a public dataset of fake news, and obtained accuracy of 89.59 percent on the logistic regression learning model [
11]. The credibility of news was also checked using text analysis techniques, where different features (such as user profiles) and content-specific attributes (such as comments, replies, external links etc.) were used. The authors employed Naïve Bayes, Random Forest and decision tree classifiers to implement their techniques [
12]. Similarly, another work on fake news detection used four types of features: textual, user profile-based, content-specific and message propagation. These features were extracted from a Twitter dataset, and the models were trained to achieve a precision of around 70 to 80 percent [
13].
The stylometry features such as writing style and grammar used in the news content were utilized to label the information as true or false [
14]. The experimental results on several datasets have shown that the use of such features could provide better results than using simple textual features. Linguistic features have been extensively used in several works for the identification of misleading content. Sixteen linguistic features divided into four categories were used in a study, and the decision tree classifier achieved 60 percent accuracy on the selected features [
15]. Similarly, several classifiers were used on various linguistic features from the Facebook dataset, and more than 90 percent accuracy was obtained by the linear regression model [
16].
In another attempt to classify Twitter posts as either fake or real, the authors created four categories of features that contain 45 different features [
17]. The selected features represent different attributes of the Twitter posts, such as the length and polarity of the posts, user characteristics and other content-based features. The models were trained on the PHEME and CREDBANK datasets, while testing was performed on the BuzzFeed dataset. The model achieved 65.29 percent of accuracy on the test dataset. Similarly, in another study, the authors used 29 features for training the logistic regression classifier that obtained an accuracy of around 60 percent [
18]. Zhou et al. [
19] have proposed nine classes containing 20 features for identifying fake news content. Gravanis et al. [
20] have introduced a new dataset called UNBiased, which contained 3004 instances by taking samples from four publicly available datasets. They achieved 95 percent accuracy on their dataset using the support vector machine classifier. Another study [
21] introduced a deep learning model for the identification of false information. The Kaggle dataset was utilized for the experiment, and GloVe vectors were used for embedding textual features. The author proposed a hybrid model based on convolutional and recurrent neural networks.
In a recent study, the authors explored several embedding models for detection of Arabic fake news. The authors developed transformer-based classifiers for the task. They constructed a dataset of fake news in the Arabic language for evaluating their proposed models, and achieved an accuracy score of more than 98 percent [
22].
The existing work discussed in the preceding section indicates that no single methodology or classification model can provide the best results. No single model can claim to always perform better for every problem. Therefore, in this work, we have tried to figure out the performance of several models and their parameter tuning for the prediction of news containing false information about COVID-19. The proposed work is different from the study [
22] discussed above in the sense that it evaluates eight DL classifiers for detecting fake news in the Arabic language. Whereas, our work evaluates six ML and two DL classifiers for the same task in the English language.
6. Conclusions
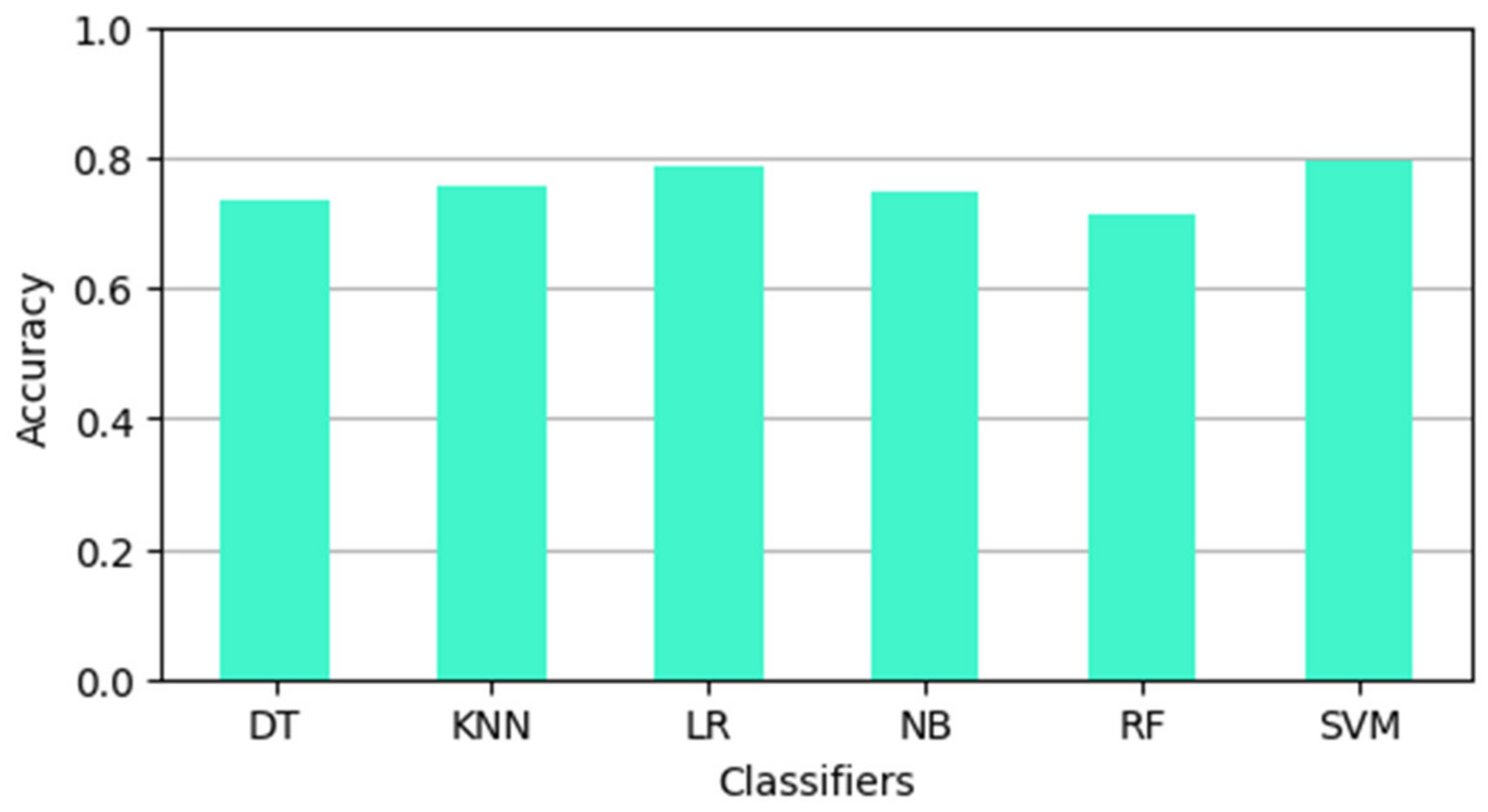
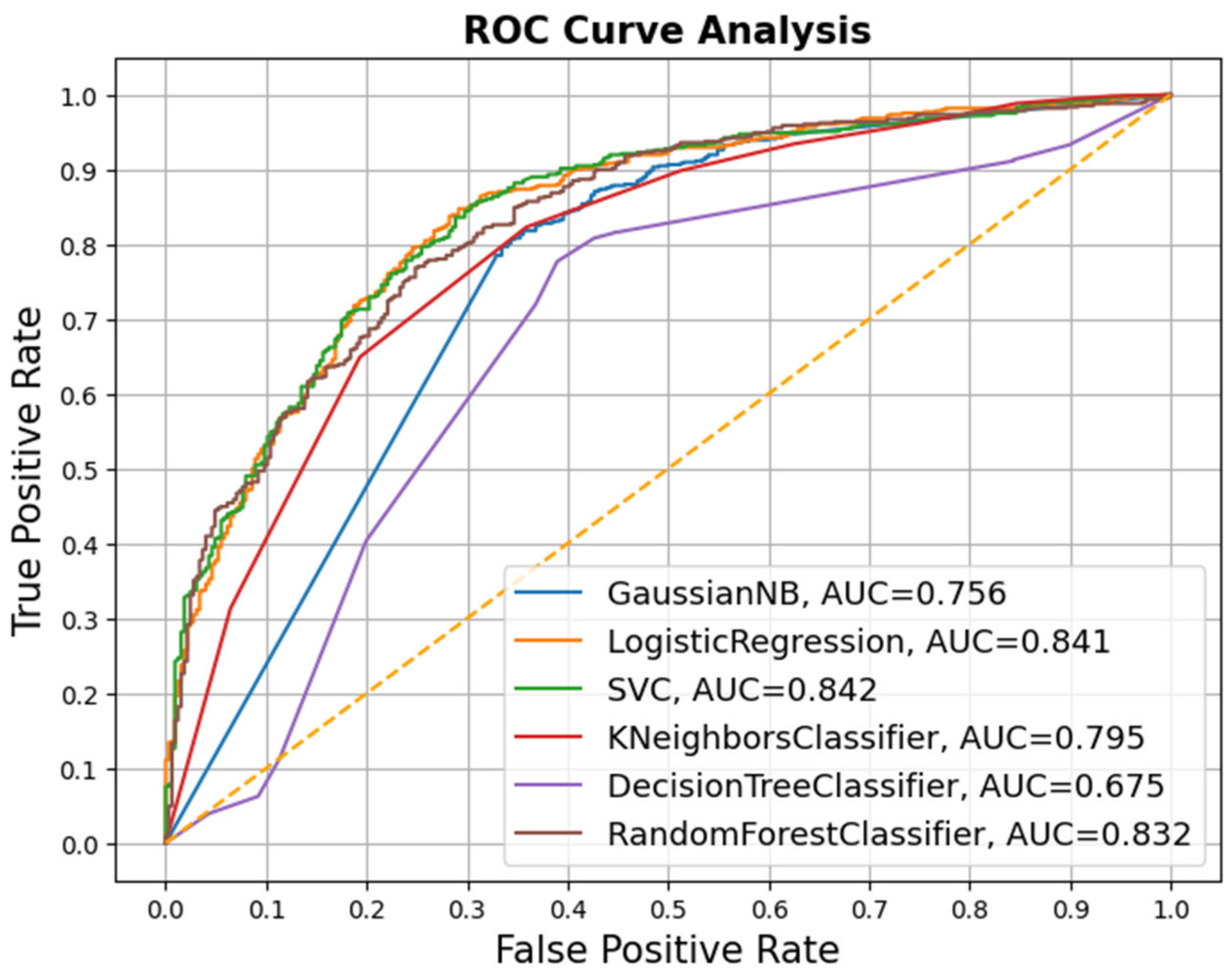
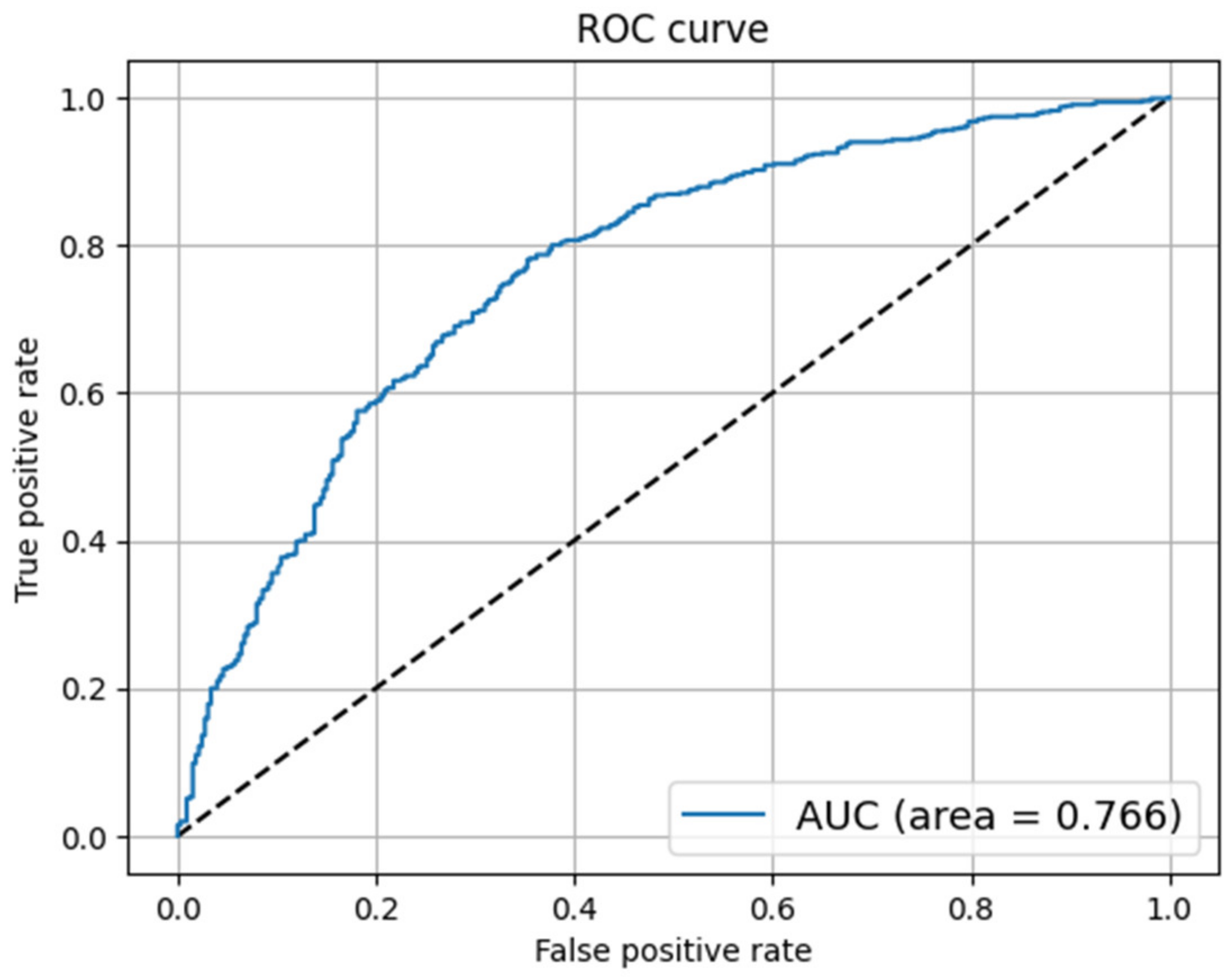
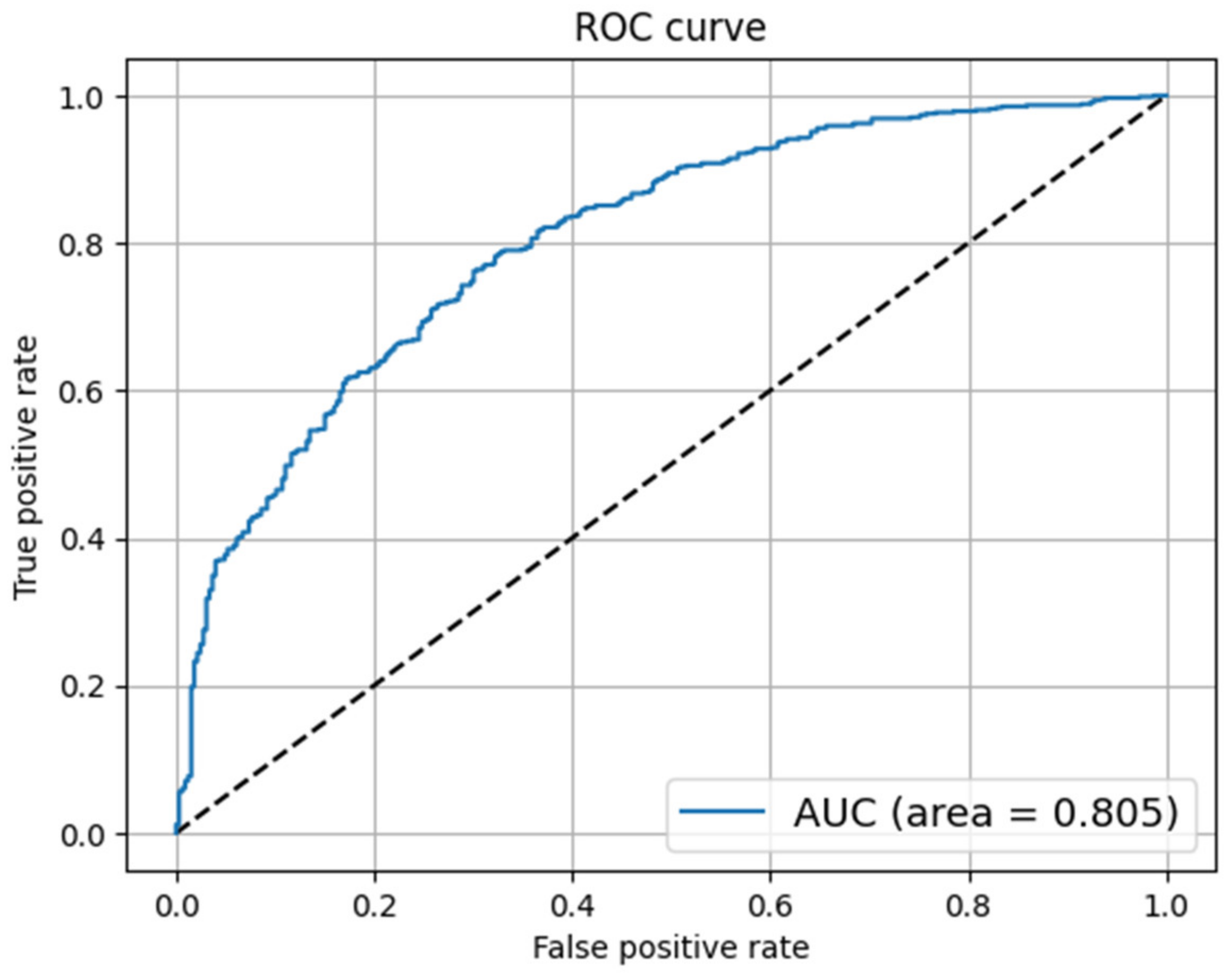
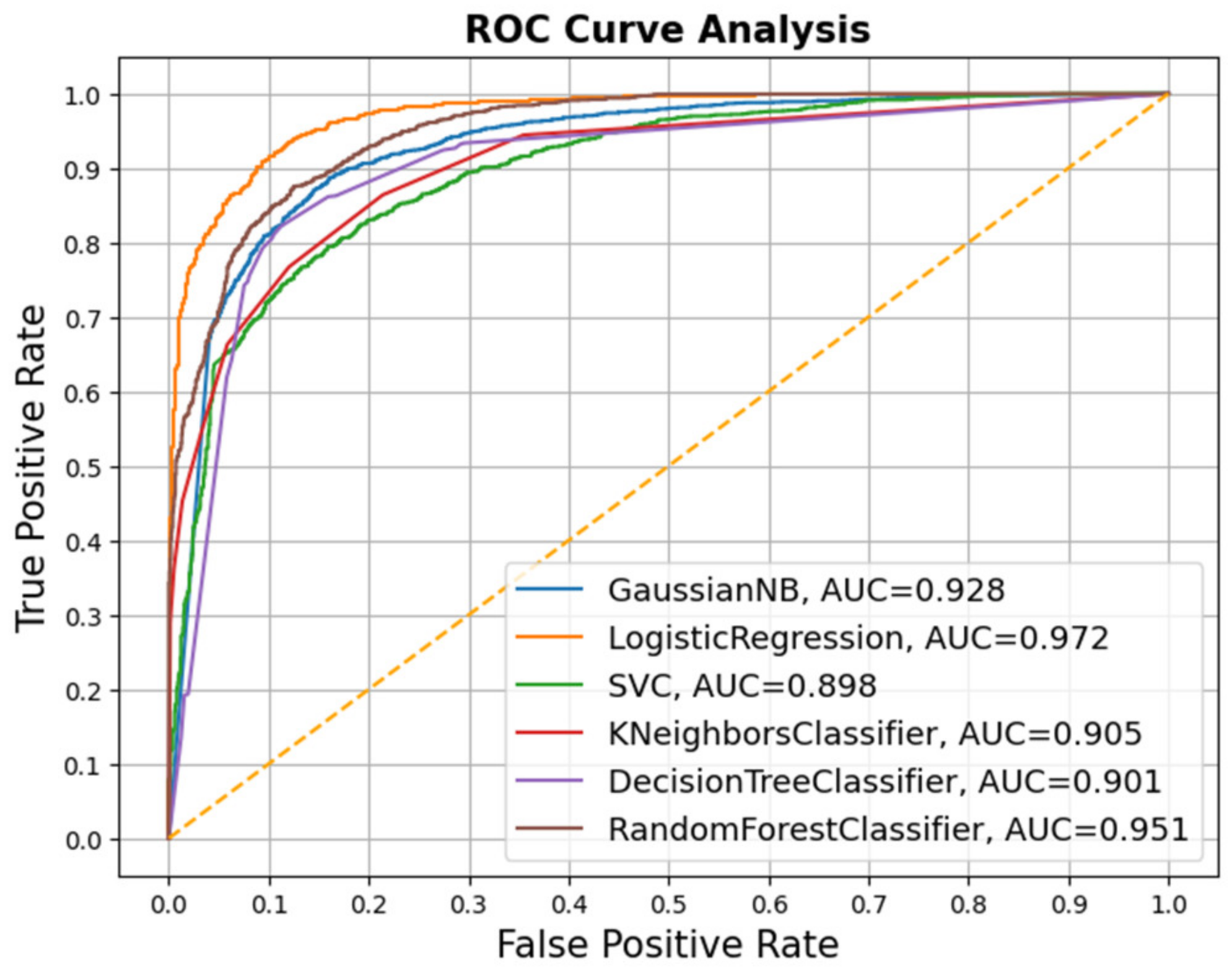
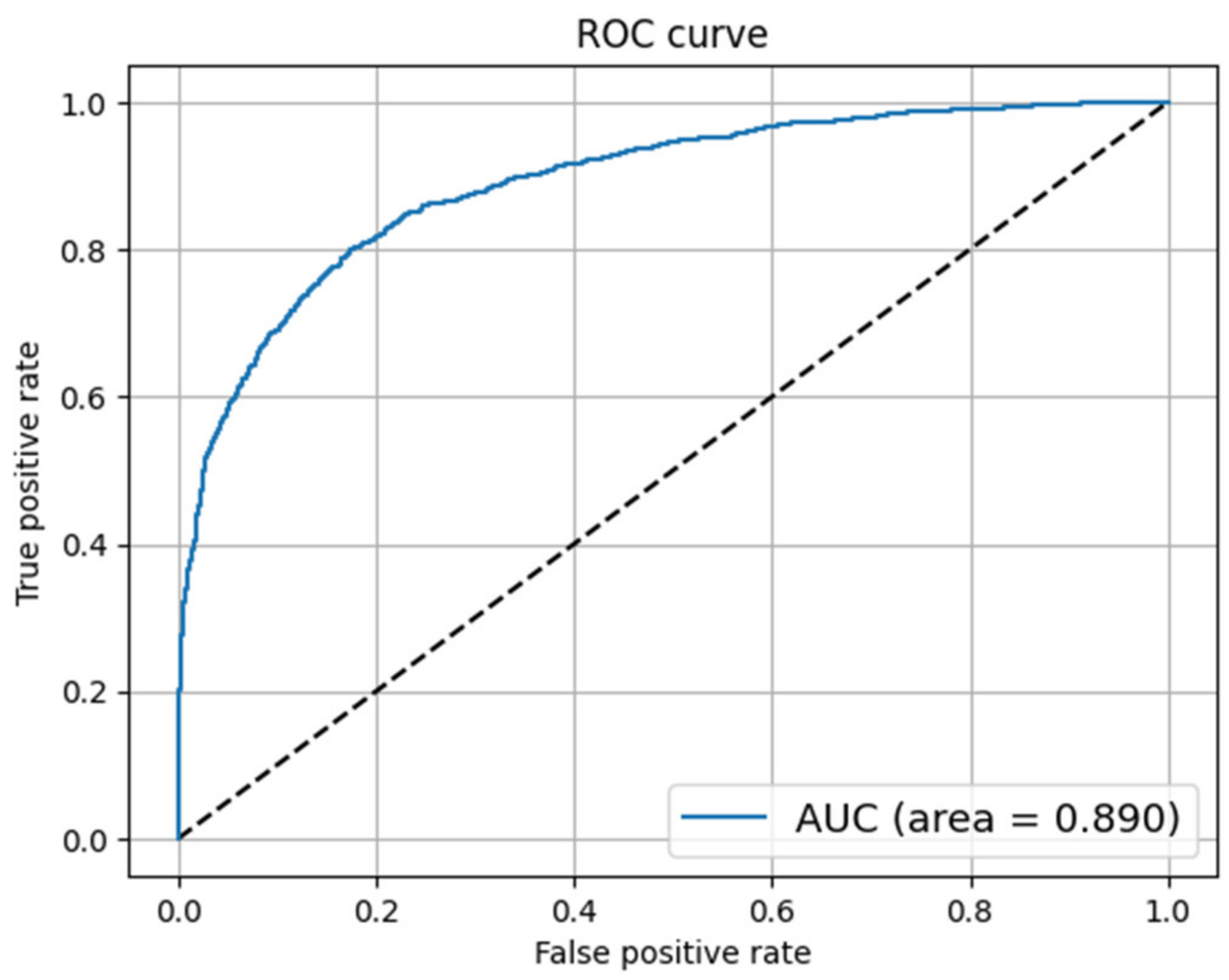
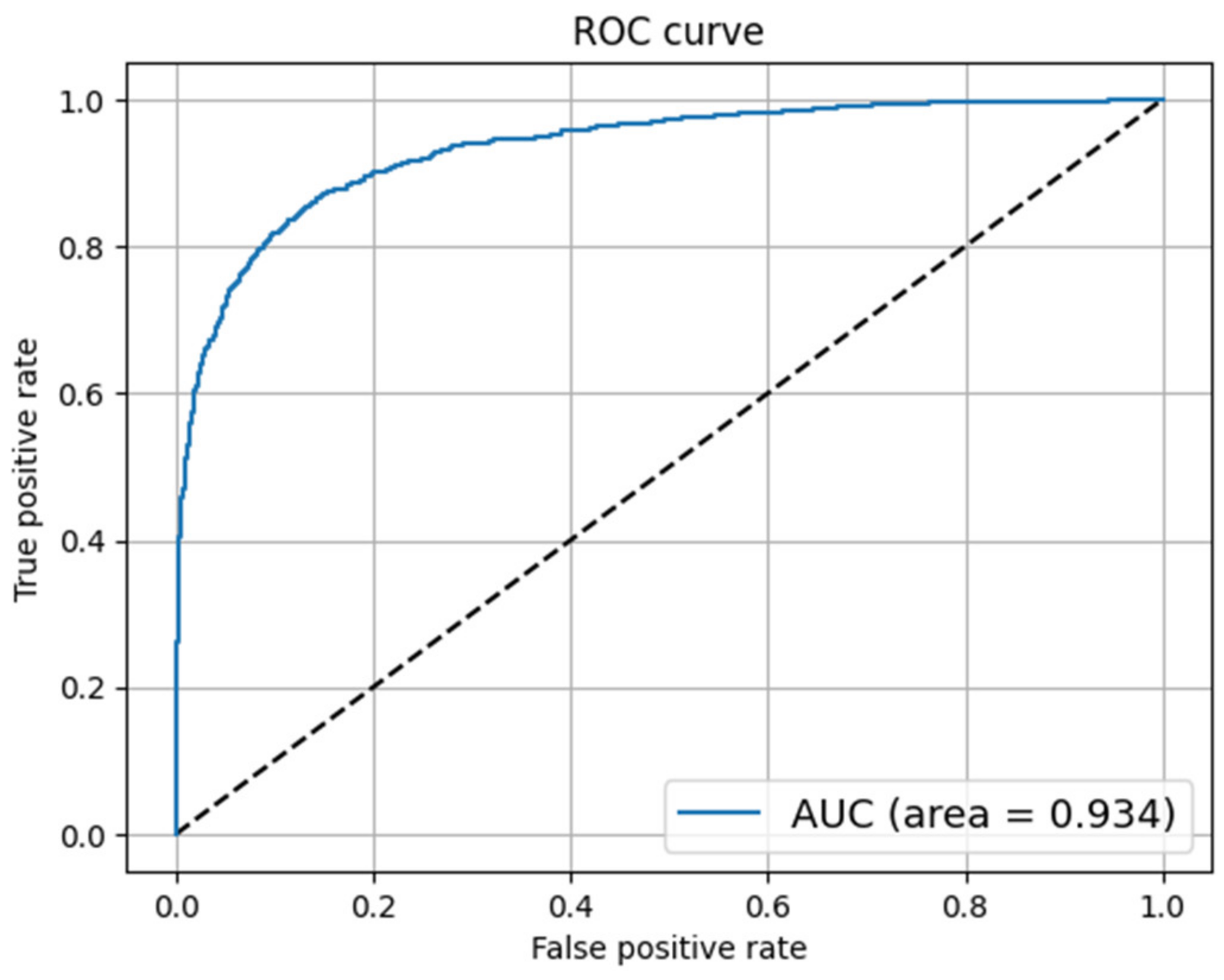
Fake news has become a challenging task for government agencies while handling the COVID-19 epidemic. The spread of unverified news regarding the novel virus has aggravated the pandemic situation around the world. Therefore, curbing this type of misinformation has become inevitable during these challenging times. In this work, we have analyzed several ML and DL models for detecting fake news content. The experiments were performed on two publicly available datasets containing fake news articles on COVID-19. The classification models were evaluated on different evaluation metrics. The LR and NB models were the best performing among all models in terms of accuracy and FPR, respectively. As discussed in the related work section, the LR classifier has shown a good classification performance. Therefore, the LR model could be taken up to develop advanced models, supplemented with feature engineering techniques for enhanced results. However, the DL models did not show any significant performance improvement. It was also observed that adding a layer of word embedding in the DL models did not show any significant performance improvement over the ML models.
There are some limitations to this work which can be taken into account in future works. In this work, we have not applied any feature selection technique. The reduced feature set may further improve the classification performance. Secondly, we have not explored the transformer-based deep learning models that are known for their excellent performance. The above limitations could be addressed to evaluate their effects on the overall performance of the models. In future works, the results obtained from these experiments could be utilized to build classification models with a greater improvement in performance. Moreover, the ensemble model could also be applied to further enhance the results.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}