
Anatomical Landmark Detection Using a Feature-Sharing Knowledge Distillation-Based Neural Network

Abstract
:1. Introduction
- Focusing on the issue of anatomical landmark detection model deployment, we propose a model-training method named feature-sharing fast landmark detection (FSF-LD), which enables a lightweight model to approximately achieve high performance as good as that of a heavy but strong model. Our proposed FSF-LD outperforms state-of-the-art KD methods on landmark detection.
- Moreover, we propose a multi-task learning (MTL) method to pretrain the teacher network and improve its ability to exploit features and represent knowledge. We carry out some extensive experiments to validate the efficiency and superiority of our MTL methods.
2. Related Work
2.1. Anatomical Landmark Detection
2.2. Knowledge Distillation
2.3. Multi-Task Learning
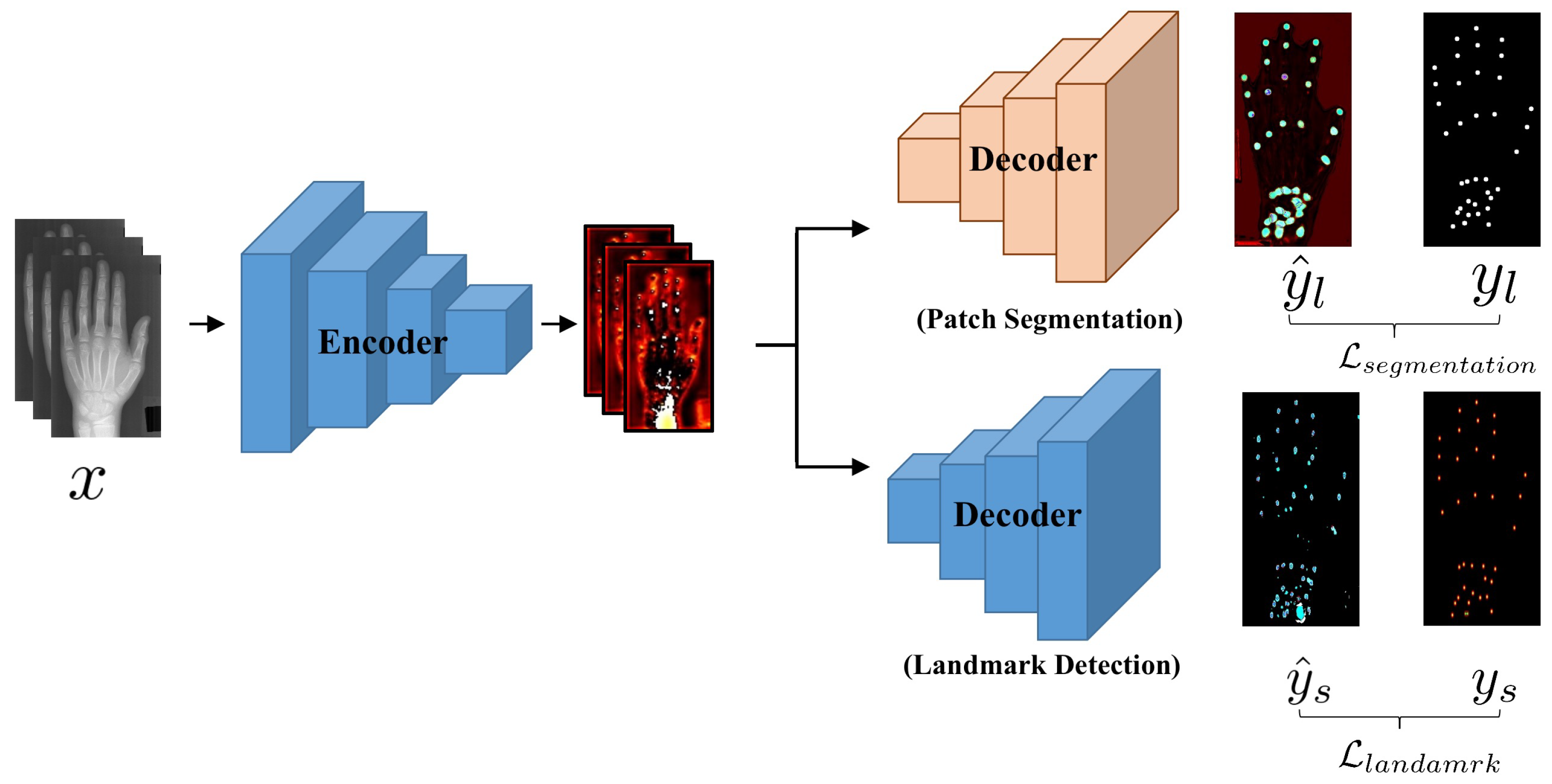
3. Feature-Sharing Fast Landmark Detection Strategy
3.1. Anatomical Landmark Detection Task
3.2. Student Model and Original Teacher Model
3.3. Our Proposed FSF-LD Training Procedure

3.4. Pretrain Teacher Model
3.5. Feature-Sharing Knowledge Distillation
4. Experiments
4.1. Dataset
4.1.1. 2D Hand Radiograph Dataset
4.1.2. 2D Cephalometric Radiograph Dataset
4.1.3. 2D Hip Radiograph Dataset
4.2. Evaluation Metrics
4.2.1. MRE
4.2.2. SDR
4.2.3. GFLOPs
4.3. The Effect of the Multi-Task Pretraining Structure
4.4. Compared with Other KD Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Beichel, R.; Bischof, H.; Leberl, F.; Sonka, M. Robust active appearance models and their application to medical image analysis. IEEE Trans. Med Imaging 2005, 24, 1151–1169. [Google Scholar] [CrossRef]
- Heimann, T.; Meinzer, H.P. Statistical shape models for 3D medical image segmentation: A review. Med. Image Anal. 2009, 13, 543–563. [Google Scholar] [CrossRef]
- Johnson, H.J.; Christensen, G.E. Consistent landmark and intensity-based image registration. IEEE Trans. Med. Imaging 2002, 21, 450–461. [Google Scholar] [CrossRef] [PubMed]
- Štern, D.; Likar, B.; Pernuš, F.; Vrtovec, T. Parametric modelling and segmentation of vertebral bodies in 3D CT and MR spine images. Phys. Med. Biol. 2011, 56, 7505. [Google Scholar] [CrossRef] [PubMed]
- Kwon, H.J.; Koo, H.I.; Park, J.; Cho, N.I. Multistage Probabilistic Approach for the Localization of Cephalometric Landmarks. IEEE Access 2021, 9, 21306–21314. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Y.; Jiang, T.; Chi, Y.; Zhang, L.; Hua, X.S. Landmarks Detection with Anatomical Constraints for Total Hip Arthroplasty Preoperative Measurements. In Proceedings of the 2020–23rd International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Lima, Peru, 4–8 October 2020; pp. 670–679. [Google Scholar]
- Payer, C.; Štern, D.; Bischof, H.; Urschler, M. Integrating spatial configuration into heatmap regression based CNNs for landmark localization. Med. Image Anal. 2019, 54, 207–219. [Google Scholar] [CrossRef]
- Qian, J.; Luo, W.; Cheng, M.; Tao, Y.; Lin, J.; Lin, H. CephaNN: A Multi-Head Attention Network for Cephalometric Landmark Detection. IEEE Access 2020, 8, 112633–112641. [Google Scholar] [CrossRef]
- Zeng, M.; Yan, Z.; Liu, S.; Zhou, Y.; Qiu, L. Cascaded convolutional networks for automatic cephalometric landmark detection. Med. Image Anal. 2021, 68, 101904. [Google Scholar] [CrossRef]
- Yang, Z.; Li, Z.; Jiang, X.; Gong, Y.; Yuan, Z.; Zhao, D.; Yuan, C. Focal and Global Knowledge Distillation for Detectors. CoRR2021, abs/2111.11837. Available online: http://xxx.lanl.gov/abs/2111.11837 (accessed on 26 November 2021).
- Li, Z.; Ye, J.; Song, M.; Huang, Y.; Pan, Z. Online Knowledge Distillation for Efficient Pose Estimation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 11720–11730. [Google Scholar] [CrossRef]
- Zhang, F.; Zhu, X.; Ye, M. Fast human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3517–3526. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Kwon, H.; Kim, Y. BlindNet backdoor: Attack on deep neural network using blind watermark. Multimed. Tools Appl. 2022, 81, 6217–6234. [Google Scholar] [CrossRef]
- Kwon, H. Medicalguard: U-net model robust against adversarially perturbed images. Secur. Commun. Netw. 2021, 2021, 5595026:1–5595026:8. [Google Scholar] [CrossRef]
- Kwon, H.; Lee, J. AdvGuard: Fortifying Deep Neural Networks against Optimized Adversarial Example Attack. IEEE Access 2020, 4, 2016. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4133–4141. [Google Scholar]
- Ahn, S.; Hu, S.X.; Damianou, A.; Lawrence, N.D.; Dai, Z. Variational information distillation for knowledge transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9163–9171. [Google Scholar]
- Wang, L.; Yoon, K.J. Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3048–3068. [Google Scholar] [CrossRef]
- Hwang, D.H.; Kim, S.; Monet, N.; Koike, H.; Bae, S. Lightweight 3D human pose estimation network training using teacher-student learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2020; pp. 479–488. [Google Scholar]
- Zhang, Y.; Yang, Q. A Survey on Multi-Task Learning. arXiv 2021. [Google Scholar] [CrossRef]
- Liu, C.; Xie, H.; Zhang, S.; Mao, Z.; Sun, J.; Zhang, Y. Misshapen Pelvis Landmark Detection With Local-Global Feature Learning for Diagnosing Developmental Dysplasia of the Hip. IEEE Trans. Med. Imaging 2020, 39, 3944–3954. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 483–499. [Google Scholar]
- Liu, Y.C.; Tan, D.S.; Chen, J.C.; Cheng, W.H.; Hua, K.L. Segmenting hepatic lesions using residual attention U-Net with an adaptive weighted dice loss. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3322–3326. [Google Scholar]
- Viterbi School of Engineering Digital Hand Atlas. 2017. Available online: https://ipilab.usc.edu/research/baaweb/ (accessed on 27 July 2017).
- Wang, C.W.; Huang, C.T.; Hsieh, M.C.; Li, C.H.; Chang, S.W.; Li, W.C.; Vandaele, R.; Maree, R.; Jodogne, S.; Geurts, P. Evaluation and Comparison of Anatomical Landmark Detection Methods for Cephalometric X-Ray Images: A Grand Challenge. IEEE Trans. Med. Imaging 2015, 34, 1890–1900. [Google Scholar] [CrossRef]
- Zhu, L. THOP: PyTorch-OpCounter. Available online: https://github.com/Lyken17/pytorch-OpCounter (accessed on 2 April 2018).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Test1 | Test2 | FLOPs(G) | Total Parameters | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SDR (%) | MRE (mm) | SDR (%) | MRE (mm) | |||||||||
| r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | |||||
| HRNet | 44.0 | 56.2 | 65.3 | 76.6 | 3.0683 | 41.4 | 53.4 | 61.8 | 73.1 | 4.1372 | 7.9211886 | 9,318,595 |
| UNet4 | 80.0 | 81.7 | 82.6 | 83.3 | 4.6741 | 79.5 | 81.8 | 82.7 | 83.5 | 4.9473 | 19.9375 | 1,948,069 |
| UNet5 | 95.4 | 97.3 | 98.3 | 99.3 | 0.9982 | 94.4 | 97.2 | 98.5 | 99.4 | 0.9683 | 104.0 | 31,381,285 |
| SEG-UNet5 | 95.8 | 97.7 | 98.6 | 99.4 | 0.8628 | 95.1 | 97.5 | 98.5 | 99.4 | 0.9034 | 177.35156 | 46,022,154 |
| Model | Test1 | Test2 | GFLOPs | Total Parameters | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SDR (%) | MRE (mm) | SDR (%) | MRE (mm) | |||||||||
| r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | |||||
| HRNet | 11.8 | 19.8 | 29.6 | 48.2 | 5.4197 | 15.4 | 25.8 | 35.4 | 55.2 | 4.8275 | 7.9167938 | 9,317,987 |
| UNet4 | 64.1 | 74.7 | 82.4 | 89.6 | 2.1110 | 62.7 | 70.6 | 78.6 | 88.9 | 2.5568 | 19.8125 | 1,948,069 |
| UNet5 | 70.1 | 80.5 | 86.3 | 92.8 | 1.8879 | 67.5 | 77.8 | 84.6 | 92.8 | 2.2486 | 103.78125 | 31,381,285 |
| SEG-UNet5 | 69.9 | 81.7 | 87.7 | 94.7 | 1.8555 | 95.1 | 97.5 | 98.5 | 99.4 | 2.2127 | 176.8516 | 46,022,154 |
| Model | Test1 | Test2 | GFLOPs | Total Parameters | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SDR (%) | MRE (mm) | SDR (%) | MRE (mm) | |||||||||
| r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | |||||
| HRNet | 7.4 | 13.8 | 20.6 | 39.6 | 70.1222 | 7.4 | 12.3 | 17.8 | 36.1 | 72.8118 | 7.9187164 | 9,318,253 |
| UNet4 | 52.3 | 66.7 | 78.3 | 89.8 | 2.1110 | 61.6 | 76.1 | 85.4 | 93.9 | 2.8010 | 19.8125 | 1,948,069 |
| UNet5 | 63.5 | 76.5 | 84.6 | 93.9 | 1.9557 | 72.7 | 84.8 | 90.4 | 96.6 | 1.6668 | 103.78125 | 31,381,285 |
| SEG-UNet5 | 63.7 | 76.0 | 84.6 | 93.9 | 1.9274 | 74.0 | 85.5 | 92.1 | 96.6 | 1.6663 | 176.8516 | 46,022,154 |
| Teacher Model | Knowledge Distillation Method | Test1 | Test2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SDR (%) | MRE (mm) | SDR (%) | MRE (mm) | ||||||||
| r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | ||||
| - | HRNet | 44.0 | 56.2 | 65.3 | 76.6 | 3.0683 | 41.4 | 53.4 | 61.8 | 73.1 | 4.1372 |
| - | UNet-4 | 80.1 | 81.7 | 82.6 | 83.3 | 4.6741 | 83.0 | 85.4 | 86.4 | 87.3 | 3.5670 |
| UNet5 | Fast-KD [12] | 84.4 | 86.7 | 87.7 | 88.7 | 3.9785 | 84.7 | 86.5 | 87.4 | 88.4 | 3.9494 |
| FSF-LD(ours) | 88.0 | 90.9 | 92.4 | 93.8 | 2.5480 | 88.3 | 90.8 | 92.1 | 93.2 | 2.9257 | |
| SEG-UNet5 | Fast-KD [12] | 93.3 | 96.1 | 97.3 | 98.2 | 1.5257 | 93.4 | 95.7 | 96.9 | 97.8 | 1.6445 |
| FSF-LD(ours) | 94.3 | 97.2 | 98.2 | 98.8 | 1.2912 | 94.1 | 96.2 | 97.3 | 98.1 | 1.3585 | |
| Teacher Model | Knowledge Distillation Method | Test1 | Test2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SDR (%) | MRE (mm) | SDR (%) | MRE (mm) | ||||||||
| r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | ||||
| - | HRNet | 11.8 | 19.8 | 29.6 | 48.2 | 5.4197 | 15.4 | 25.8 | 35.4 | 55.2 | 4.8275 |
| - | UNet-4 | 64.1 | 74.7 | 82.4 | 89.6 | 2.1110 | 62.7 | 70.6 | 78.6 | 88.9 | 2.5568 |
| UNet5 | Fast-KD [12] | 63.4 | 74.0 | 80.2 | 89.4 | 2.4609 | 62.2 | 74.9 | 80.0 | 91.1 | 2.3546 |
| FSF-LD(ours) | 61.2 | 72.0 | 81.0 | 89.4 | 2.3665 | 63.6 | 74.2 | 81.2 | 91.8 | 2.1146 | |
| SEG-UNet5 | Fast-KD [12] | 64.3 | 75.6 | 81.7 | 90.6 | 2.2257 | 64.7 | 76.0 | 82.1 | 90.6 | 2.2347 |
| FSF-LD(ours) | 66.3 | 77.1 | 83.9 | 91.8 | 1.9821 | 66.7 | 76.1 | 83.1 | 91.3 | 1.9710 | |
| Teacher Model | Knowledge Distillation Method | Test1 | Test2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SDR (%) | MRE (mm) | SDR (%) | MRE (mm) | ||||||||
| r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | r = 2 mm | r = 2.5 mm | r = 3 mm | r = 4 mm | ||||
| - | HRNet | 7.4 | 13.8 | 20.6 | 39.6 | 70.1222 | 7.4 | 12.3 | 17.8 | 36.1 | 72.8118 |
| - | UNet-4 | 52.3 | 66.7 | 78.3 | 89.8 | 3.5213 | 61.6 | 76.1 | 85.4 | 93.9 | 2.8010 |
| UNet5 | Fast-KD [12] | 54.7 | 68.9 | 79.5 | 90.7 | 2.2899 | 62.0 | 77.6 | 86.3 | 93.6 | 2.5698 |
| FSF-LD(ours) | 55.1 | 69.5 | 79.5 | 91.2 | 2.2267 | 63.2 | 78.1 | 87.4 | 94.4 | 2.1396 | |
| SEG-UNet5 | Fast-KD [12] | 55.3 | 72.7 | 81.1 | 91.5 | 2.2752 | 64.1 | 78.2 | 86.7 | 94.7 | 2.0041 |
| FSF-LD(ours) | 62.0 | 77.6 | 86.4 | 93.6 | 2.1899 | 64.6 | 78.7 | 87.4 | 95.2 | 1.9798 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, D.; Wang, Y.; Wang, Y.; Gu, G.; Bai, T. Anatomical Landmark Detection Using a Feature-Sharing Knowledge Distillation-Based Neural Network. Electronics 2022, 11, 2337. https://doi.org/10.3390/electronics11152337
Huang D, Wang Y, Wang Y, Gu G, Bai T. Anatomical Landmark Detection Using a Feature-Sharing Knowledge Distillation-Based Neural Network. Electronics. 2022; 11(15):2337. https://doi.org/10.3390/electronics11152337
Chicago/Turabian StyleHuang, Di, Yuzhao Wang, Yu Wang, Guishan Gu, and Tian Bai. 2022. "Anatomical Landmark Detection Using a Feature-Sharing Knowledge Distillation-Based Neural Network" Electronics 11, no. 15: 2337. https://doi.org/10.3390/electronics11152337