
Depth Estimation Method for Monocular Camera Defocus Images in Microscopic Scenes

 , , , and
, , , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Depth Estimation Method Based on Markov Random Field
2.1.1. Markov Random Field Theory
2.1.2. Markov Random Field Defocusing Feature Model
2.1.3. Algorithm Implementation
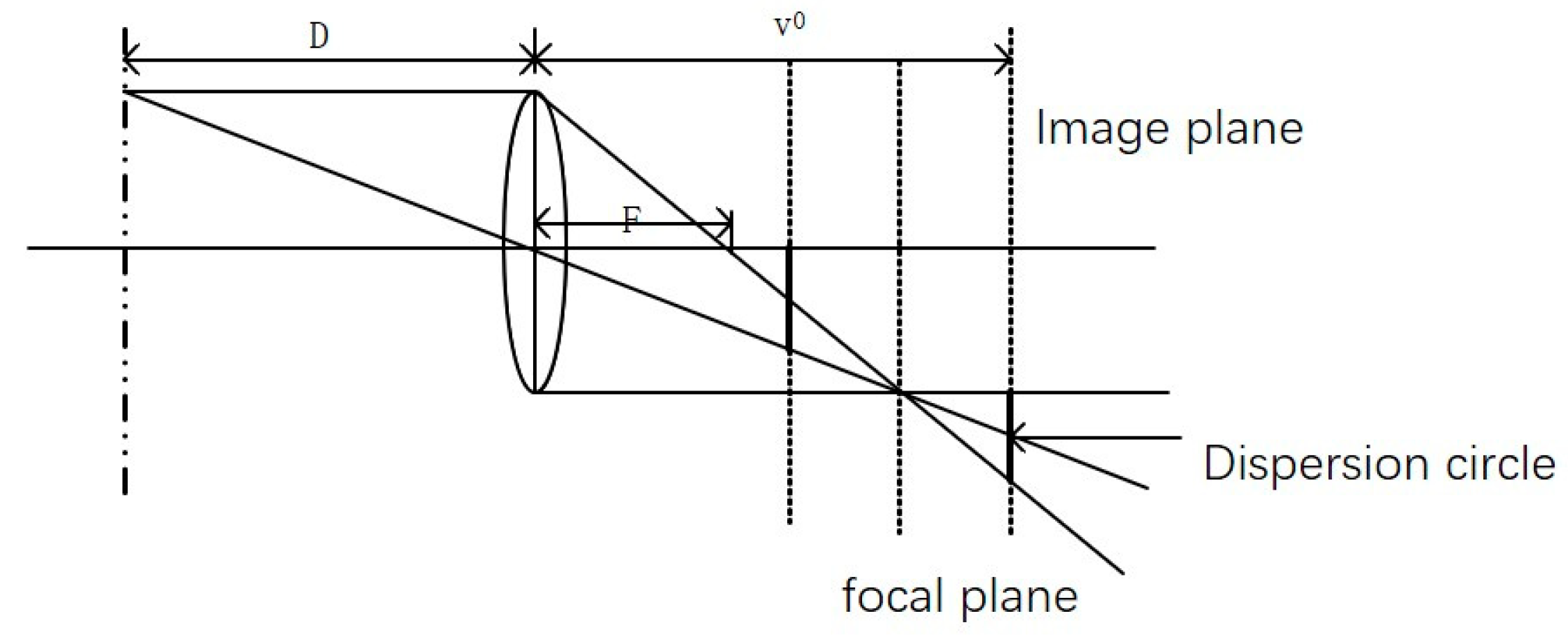
2.2. Modeling Depth Estimation Method Based on Geometric Constraints
2.2.1. Geometric Derivation of the Depth Estimation Model
- (1)
- When , we can obtain Equations (30) and (31):
- (2)
- When . The inequality relationship of is shown in Equation (33):
- (3)
- When . The inequality relationship of is shown in Equation (34):
- (4)
- When . The inequality relationship of is shown in Equation (35):
2.2.2. An Improved Depth Estimation Algorithm for Defocused Images
- (1)
- According to the four types of imaging geometric relationships described in the previous section (Equations (30)–(35)), for the two acquired defocused images that determine the camera parameters, determine the preliminary interval ;
- (2)
- The interval for determining camera parameters is discretized according to points, as shown in Equation (38):
- (3)
- For the in Equation (25), obtain the make obtain the smallest value;
- (4)
- For the two points on the left and right of , let and respectively; according to the set threshold , judge . If its value is true, then cycle (2)–(4) steps; if it is false, take it as the minimum value of Equation (25).
- (5)
- The depth information is estimated according to Equation (37).
3. Results
- One PC with: CPU: i7-9700K, GPU: RTX2060S, RAM: 16G, ROM: 516GSSD;
- One ByslorPylon industrial camera, model: acA640-120 uc;
- A monocular microscope with a magnification of 0.5 × (0.7~4.5), a lens radius of 35 mm, and an F number of 4.
- (1)
- The sequence of collected images are numbered as , , , …, Set a value K so that the collected image sequence, according to , , ……, respectively. Estimate depth information according to the algorithm in the previous section;
- (2)
- For the estimated results , , ……, , the depth value of each pixel in n-k matrices is used as the histogram. Then, the greatest depth value (or the most concentrated value) is selected as the point’s depth. Thus, the new fusion depth information is finally obtained.
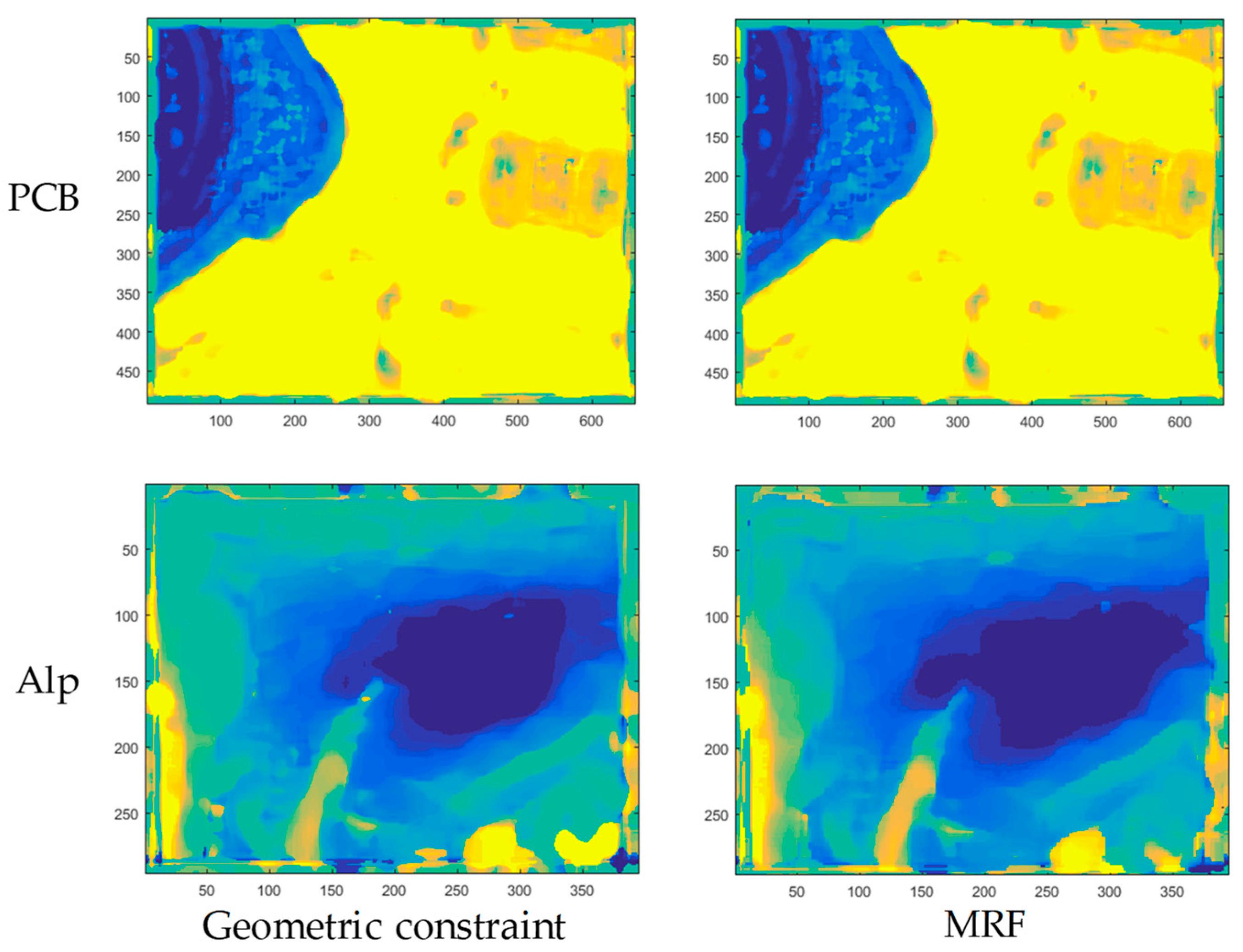
3.1. The Effects of Geometric Constraint-Based Method and MRF Method
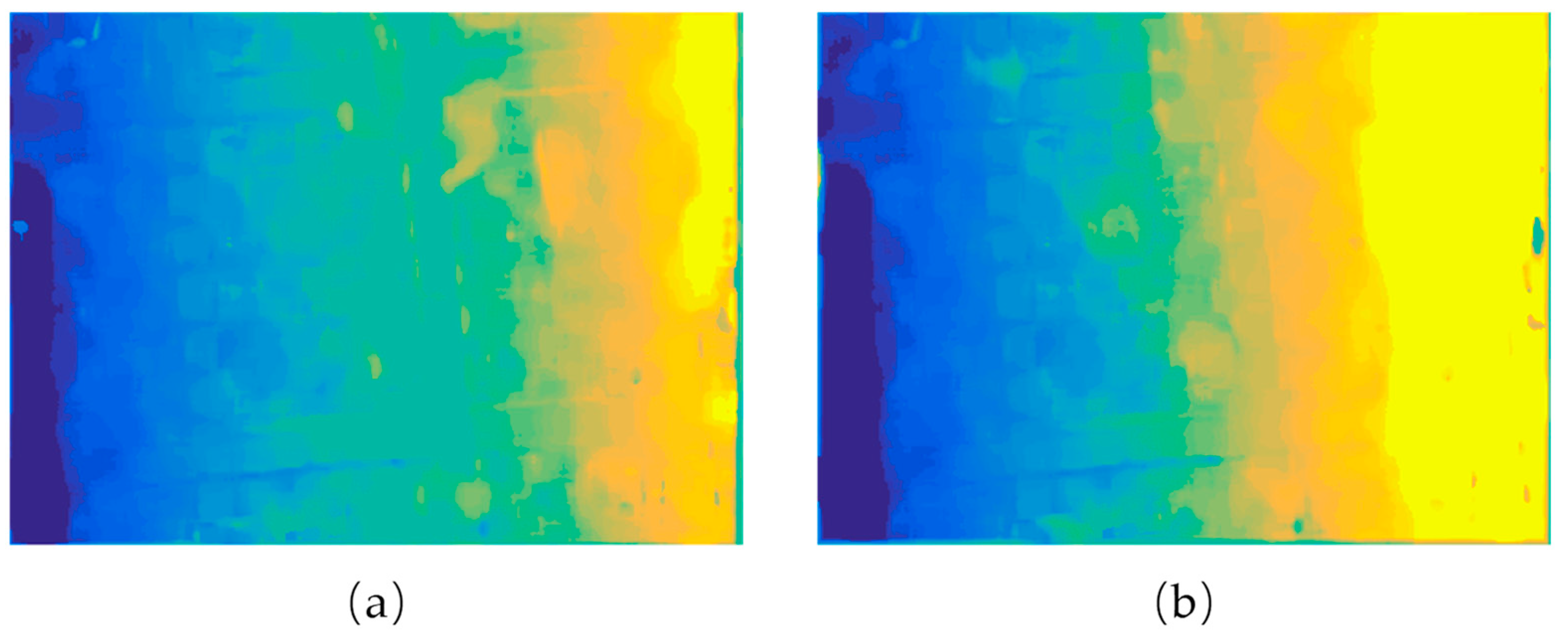
3.2. Gradient Characteristics Simulation
3.3. Accuracy and Efficiency Analysis
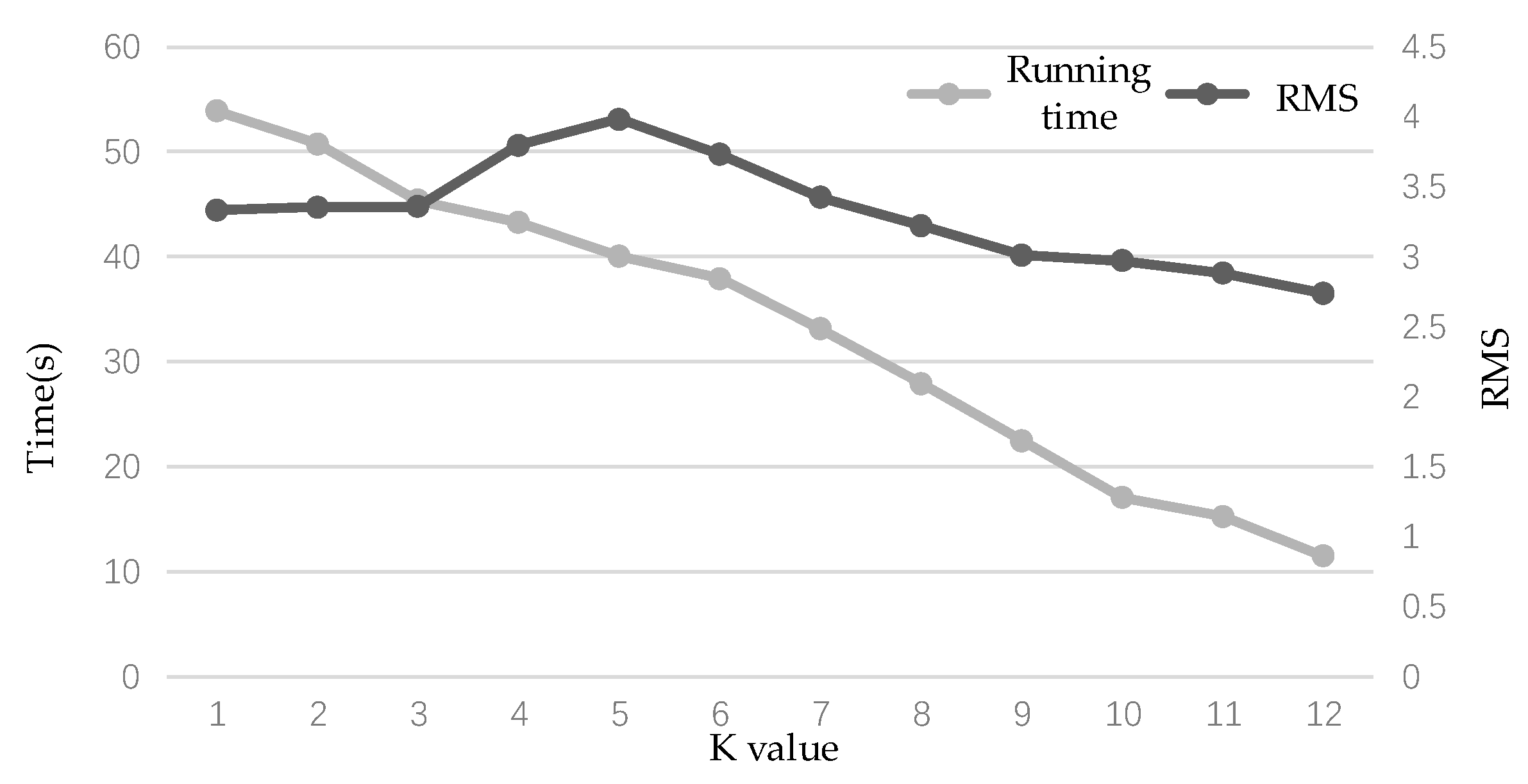
3.4. Selection of K Value in the Geometrically Constrained Improved Depth Estimation Algorithm
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Roberts, L.G. Machine Perception of Three-Dimensional Solids; Massachusetts Institute of Technology: Cambridge, MA, USA, 1963. [Google Scholar]
- Ni, X.; Yin, L.; Chen, X.; Liu, S.; Yang, B.; Zheng, W. Semantic representation for visual reasoning. MATEC Web Conf. EDP Sci. 2019, 277, 02006. [Google Scholar] [CrossRef]
- Huang, W.; Zheng, W.; Mo, L. Distributed robust H∞ composite-rotating consensus of second-order multi-agent systems. Int. J. Distrib. Sens. Netw. 2017, 13, 1550147717722513. [Google Scholar] [CrossRef]
- Liu, S.; Wang, L.; Liu, H.; Su, H.; Li, X.; Zheng, W. Deriving bathymetry from optical images with a localized neural network algorithm. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5334–5342. [Google Scholar] [CrossRef]
- Esteban, C.H.; Schmitt, F. Silhouette and stereo fusion for 3D object modeling. Comput. Vis. Image Underst. 2004, 96, 367–392. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Chai, Y.; Li, Z. Multi-focus image fusion based on nonsubsampled contourlet transform and focused regions detection. Optik 2013, 124, 40–51. [Google Scholar] [CrossRef]
- Marr, D. Vision: A Computational Investigation into the Human Representation and Processing of Visual Information; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Ding, Y.; Tian, X.; Yin, L.; Chen, X.; Liu, S.; Yang, B.; Zheng, W. Multi-scale relation network for few-shot learning based on meta-learning. In Computer Vision Systems, Proceedings of the International Conference on Computer Vision Systems, Thessaloniki, Greece, 23–25 September 2019; Springer: Cham, Switzerland, 2019; pp. 343–352. [Google Scholar]
- Li, S.; Kang, X.; Hu, J.; Yang, B. Image matting for fusion of multi-focus images in dynamic scenes. Inf. Fusion 2013, 14, 147–162. [Google Scholar] [CrossRef]
- Tang, Y.; Liu, S.; Deng, Y.; Zhang, Y.; Yin, L.; Zheng, W. Construction of force haptic reappearance system based on Geomagic Touch haptic device. Comput. Methods Programs Biomed. 2020, 190, 105344. [Google Scholar] [CrossRef]
- Subbarao, M.; Surya, G. Depth from defocus: A spatial domain approach. Int. J. Comput. Vis. 1994, 13, 271–294. [Google Scholar] [CrossRef]
- Surya, G.; Subbarao, M. Depth from defocus by changing camera aperture: A spatial domain approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE, New York, NY, USA, 15–17 June 1993; pp. 61–67. [Google Scholar]
- Subbarao, M.; Wei, T.-C. Depth from defocus and rapid autofocusing: A practical approach. In Proceedings of the 1992 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Champaign, IL, USA, 15–18 June 1992; pp. 773–776. [Google Scholar]
- Zhou, C.; Lin, S.; Nayar, S.K. Coded aperture pairs for depth from defocus and defocus deblurring. Int. J. Comput. Vis. 2011, 93, 53–72. [Google Scholar] [CrossRef] [Green Version]
- Costeira, J.; Kanade, T. A multi-body factorization method for motion analysis. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 1071–1076. [Google Scholar]
- Irani, M. Multi-frame optical flow estimation using subspace constraints. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 626–633. [Google Scholar]
- Torresani, L.; Hertzmann, A.; Bregler, C. Nonrigid structure-from-motion: Estimating shape and motion with hierarchical priors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 878–892. [Google Scholar] [CrossRef]
- Brand, W. Morphable 3D models from video. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; p. II. [Google Scholar]
- Li, Y.; Zheng, W.; Liu, X.; Mou, Y.; Yin, L.; Yang, B. Research and improvement of feature detection algorithm based on FAST. Rend. Lincei. Sci. Fis. E Nat. 2021, 32, 775–789. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J. Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Washington, DC, USA, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Xu, C.; Yang, B.; Guo, F.; Zheng, W.; Poignet, P. Sparse-view CBCT reconstruction via weighted Schatten p-norm minimization. Opt. Express 2020, 28, 35469–35482. [Google Scholar] [CrossRef] [PubMed]
- Marr, D.; Poggio, T. A computational theory of human stereo vision. Proc. R. Soc. London Ser. B Biol. Sci. 1979, 204, 301–328. [Google Scholar]
- Huang, W.; Jing, Z. Evaluation of focus measures in multi-focus image fusion. Pattern Recognit. Lett. 2007, 28, 493–500. [Google Scholar] [CrossRef]
- Huang, W.; Jing, Z. Multi-focus image fusion using pulse coupled neural network. Pattern Recognit. Lett. 2007, 28, 1123–1132. [Google Scholar] [CrossRef]
- Tian, J.; Chen, L. Adaptive multi-focus image fusion using a wavelet-based statistical sharpness measure. Signal. Process. 2012, 92, 2137–2146. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, Y.; Gu, J. Multi-focus image fusion using PCNN. Pattern Recognit. 2010, 43, 2003–2016. [Google Scholar] [CrossRef]
- Yang, B.; Liu, C.; Huang, K.; Zheng, W. A triangular radial cubic spline deformation model for efficient 3D beating heart tracking. Signal. Image Video Process. 2017, 11, 1329–1336. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Liu, C.; Zheng, W.; Liu, S. Motion prediction via online instantaneous frequency estimation for vision-based beating heart tracking. Inf. Fusion 2017, 35, 58–67. [Google Scholar] [CrossRef]
- Zhou, Y.; Zheng, W.; Shen, Z. A New Algorithm for Distributed Control Problem with Shortest-Distance Constraints. Math. Probl. Eng. 2016, 2016, 1604824. [Google Scholar] [CrossRef]
- Zheng, W.; Li, X.; Yin, L.; Wang, Y. The retrieved urban LST in Beijing based on TM, HJ-1B and MODIS. Arab. J. Sci. Eng. 2016, 41, 2325–2332. [Google Scholar] [CrossRef]
- Chaudhuri, S.; Rajagopalan, A.N. Depth from Defocus: A Real Aperture Imaging Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Schechner, Y.Y.; Kiryati, N. Depth from defocus vs. stereo: How different really are they? Int. J. Comput. Vis. 2000, 39, 141–162. [Google Scholar] [CrossRef]
- Ziou, D.; Deschenes, F. Depth from defocus estimation in spatial domain. Comput. Vis. Image Underst. 2001, 81, 143–165. [Google Scholar] [CrossRef]
- Nourbakhsh, I.R.; Andre, D. Generating Categorical Depth Maps Using Passive Defocus Sensing. US Patents US5793900A, 11 August 1998. [Google Scholar]
- Christiansen, E.M.; Yang, S.J.; Ando, D.M.; Javaherian, A.; Skibinski, G.; Lipnick, S.; Mount, E.; O’Neil, A.; Shah, K.; Lee, A.K.; et al. In silico labeling: Predicting fluorescent labels in unlabeled images. Cell 2018, 173, 792–803.e719. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Longuet-Higgins, H.C. A computer algorithm for reconstructing a scene from two projections. Nature 1981, 293, 133–135. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Geometric Constraints | MRF | ||
|---|---|---|---|
| RMS | Running Time | RMS | Running Time |
| 3.3318 | 53.93 | 5.0129 | 197.4923 |
| Value of K | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| RMS | 3.3318 | 3.3533 | 3.3597 | 3.7966 | 3.9827 | 3.7321 |
| Running time | 53.93 | 50.77 | 45.39 | 43.29 | 40.08 | 37.92 |
| Value of K | 7 | 8 | 9 | 10 | 11 | 12 |
| RMS | 3.4251 | 3.2219 | 3.0121 | 2.9739 | 2.8847 | 2.7396 |
| Running time | 33.19 | 27.91 | 22.49 | 17.11 | 15.29 | 11.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ban, Y.; Liu, M.; Wu, P.; Yang, B.; Liu, S.; Yin, L.; Zheng, W. Depth Estimation Method for Monocular Camera Defocus Images in Microscopic Scenes. Electronics 2022, 11, 2012. https://doi.org/10.3390/electronics11132012
Ban Y, Liu M, Wu P, Yang B, Liu S, Yin L, Zheng W. Depth Estimation Method for Monocular Camera Defocus Images in Microscopic Scenes. Electronics. 2022; 11(13):2012. https://doi.org/10.3390/electronics11132012
Chicago/Turabian StyleBan, Yuxi, Mingzhe Liu, Peng Wu, Bo Yang, Shan Liu, Lirong Yin, and Wenfeng Zheng. 2022. "Depth Estimation Method for Monocular Camera Defocus Images in Microscopic Scenes" Electronics 11, no. 13: 2012. https://doi.org/10.3390/electronics11132012