
Measuring the Energy and Performance of Scientific Workflows on Low-Power Clusters



Abstract
:1. Introduction
2. Evaluating Energy Usage in Computation
3. Experimental Setup
3.1. Cluster Hardware
3.2. Scientific Workflows
3.3. Condor Management Software
3.4. Workflow Engine
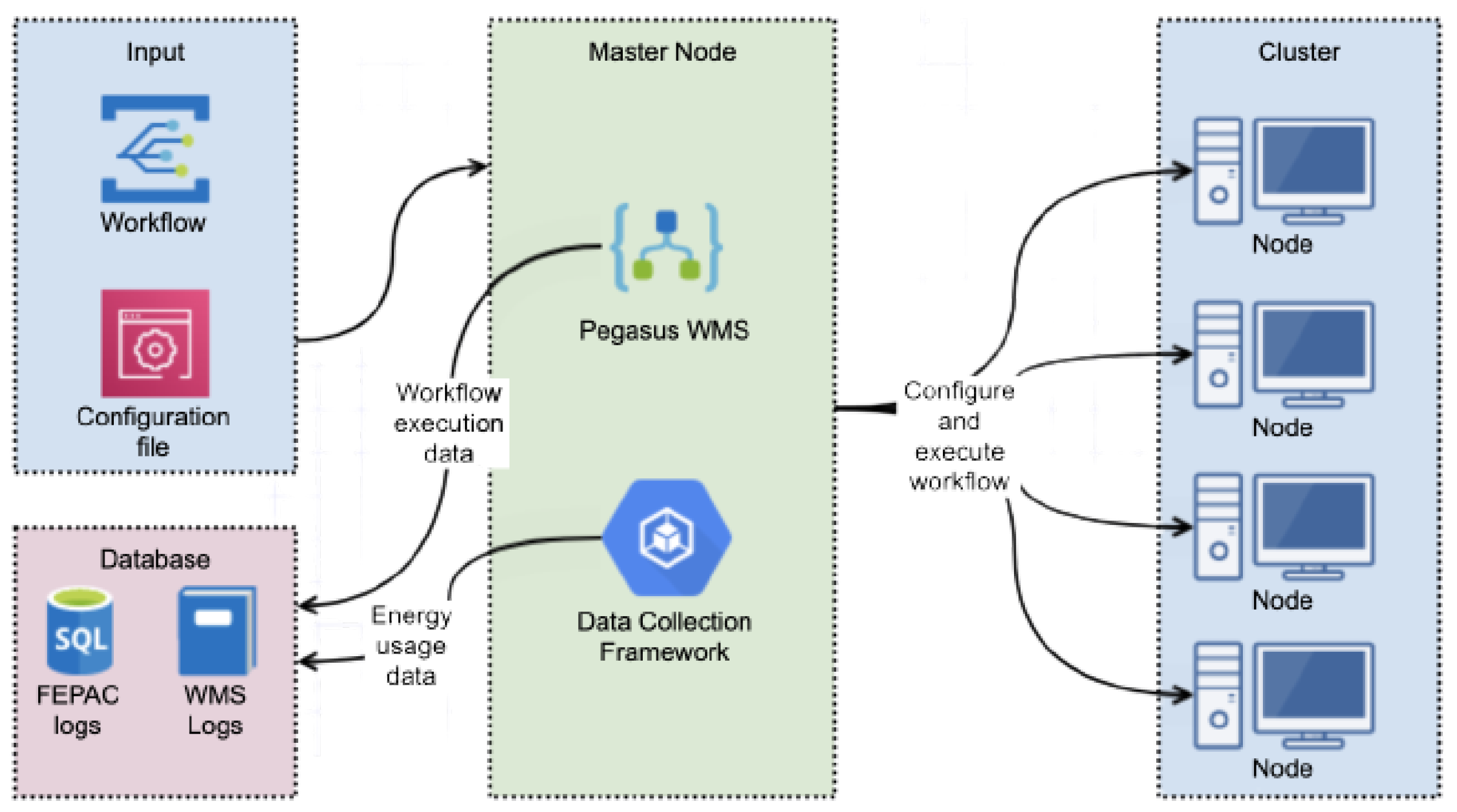
3.5. Experiment Software Setup
4. Astronomy Workflow Energy Evaluation
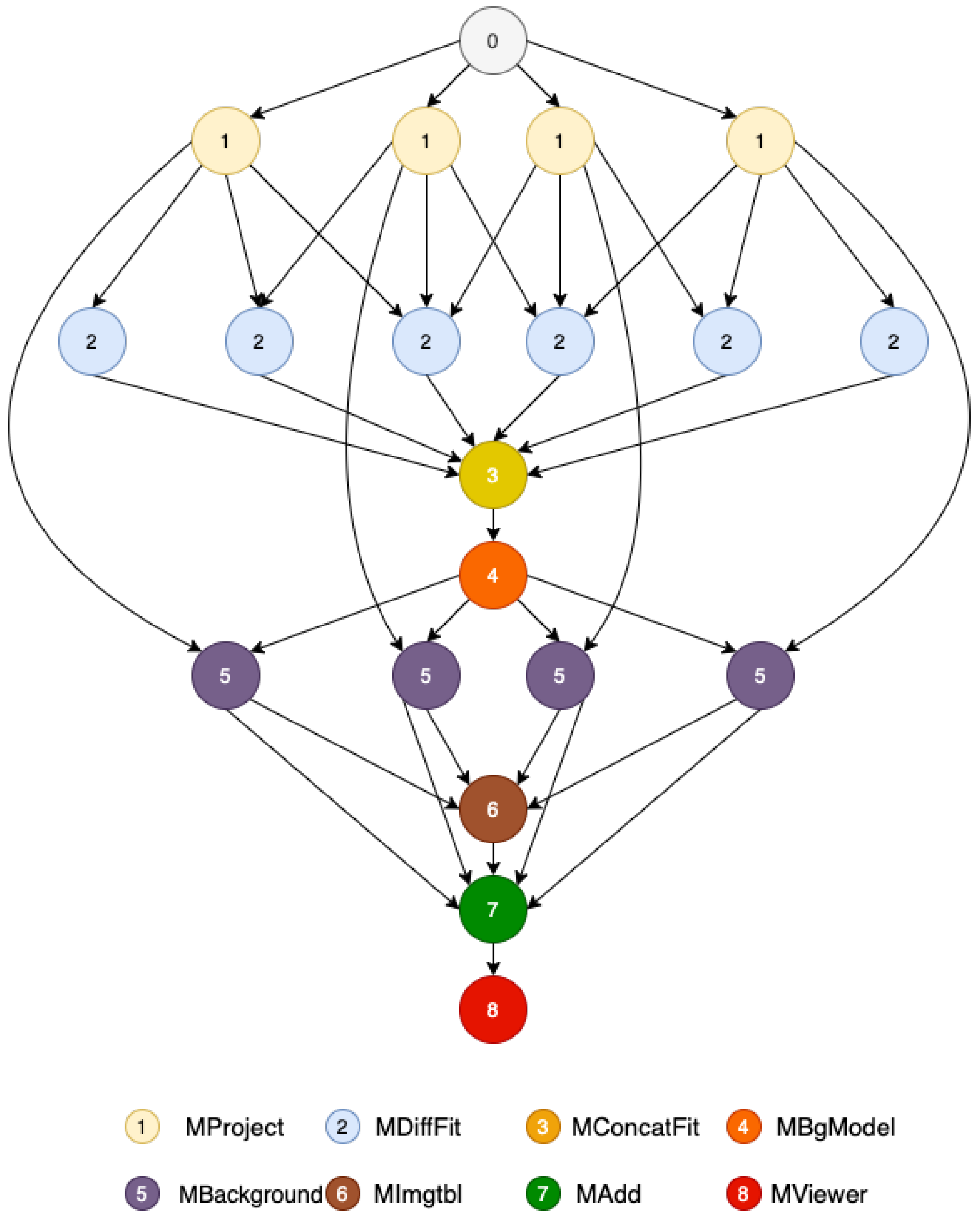
4.1. Workflow Description
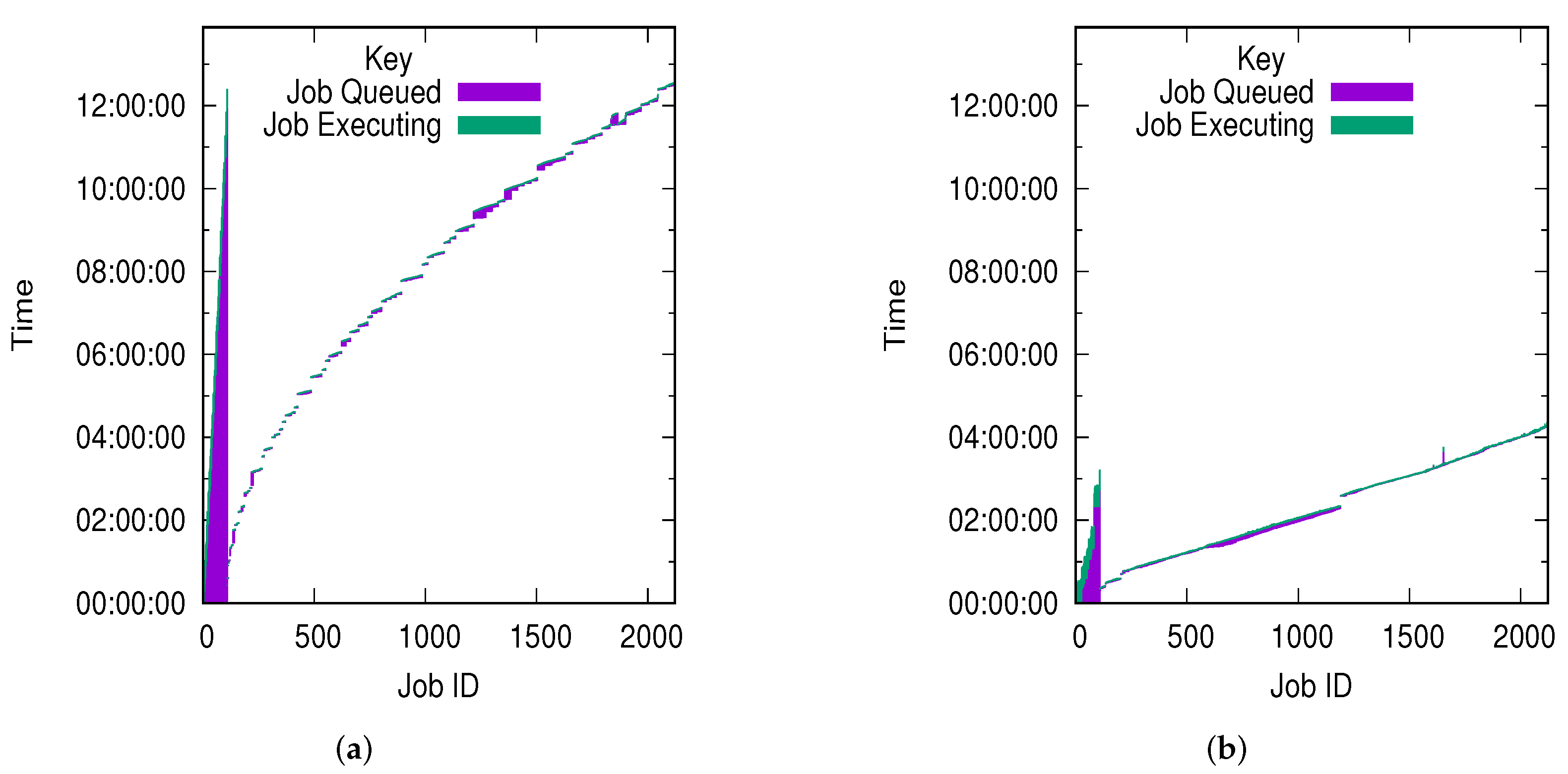
4.2. Workflow Complexity
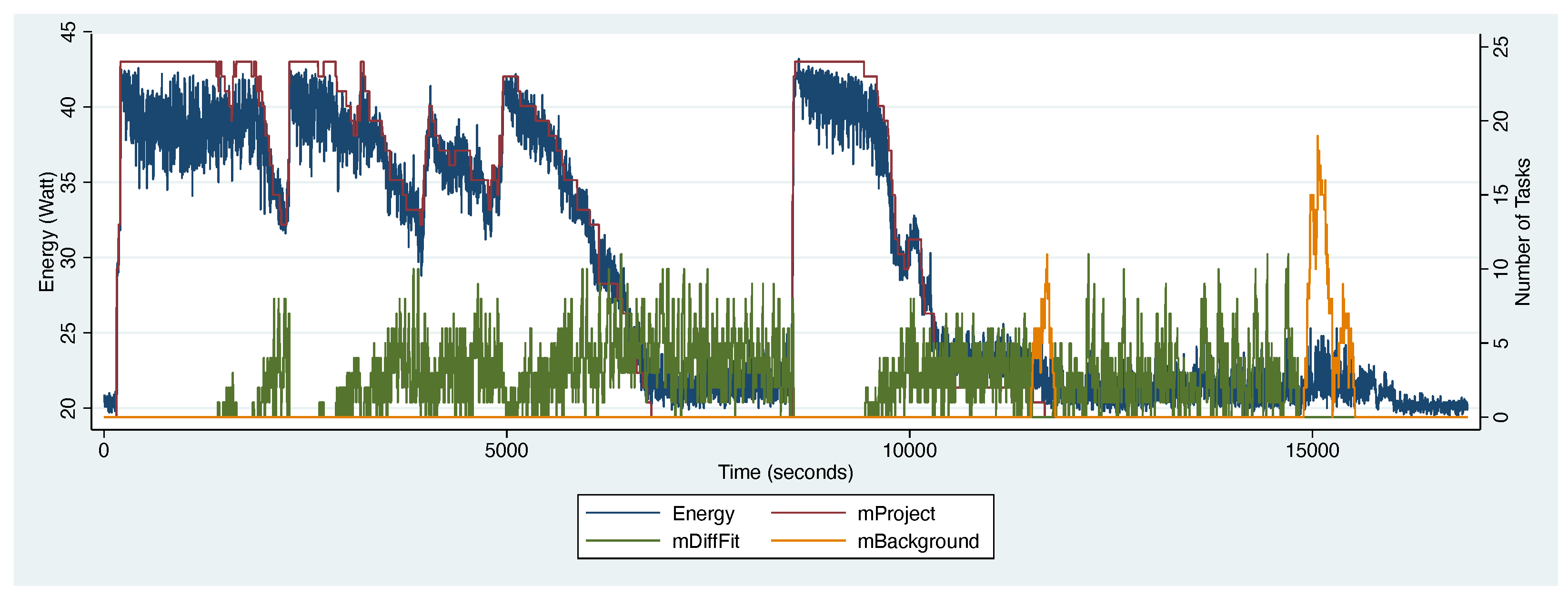
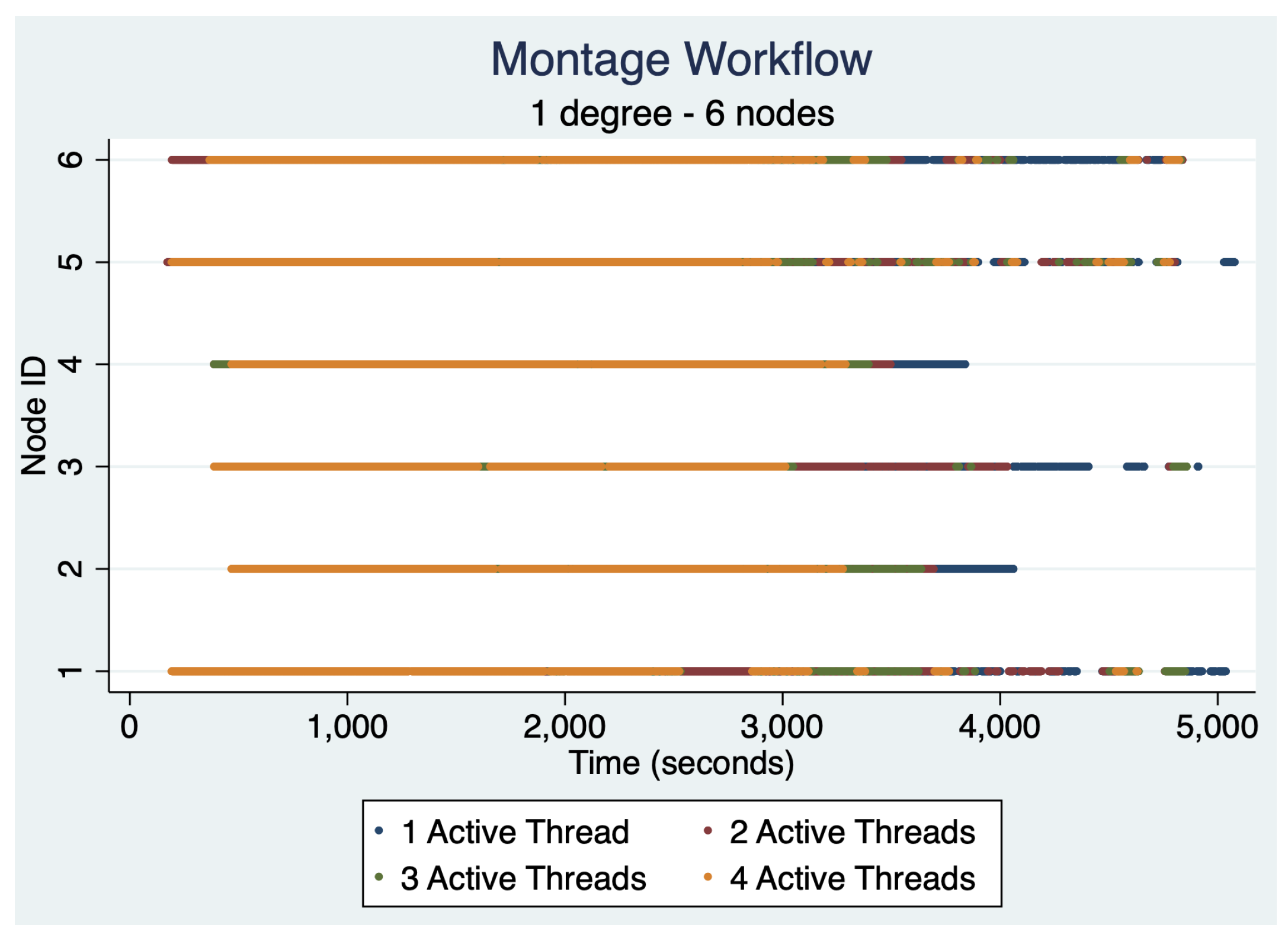
4.3. Montage Computation Characteristics
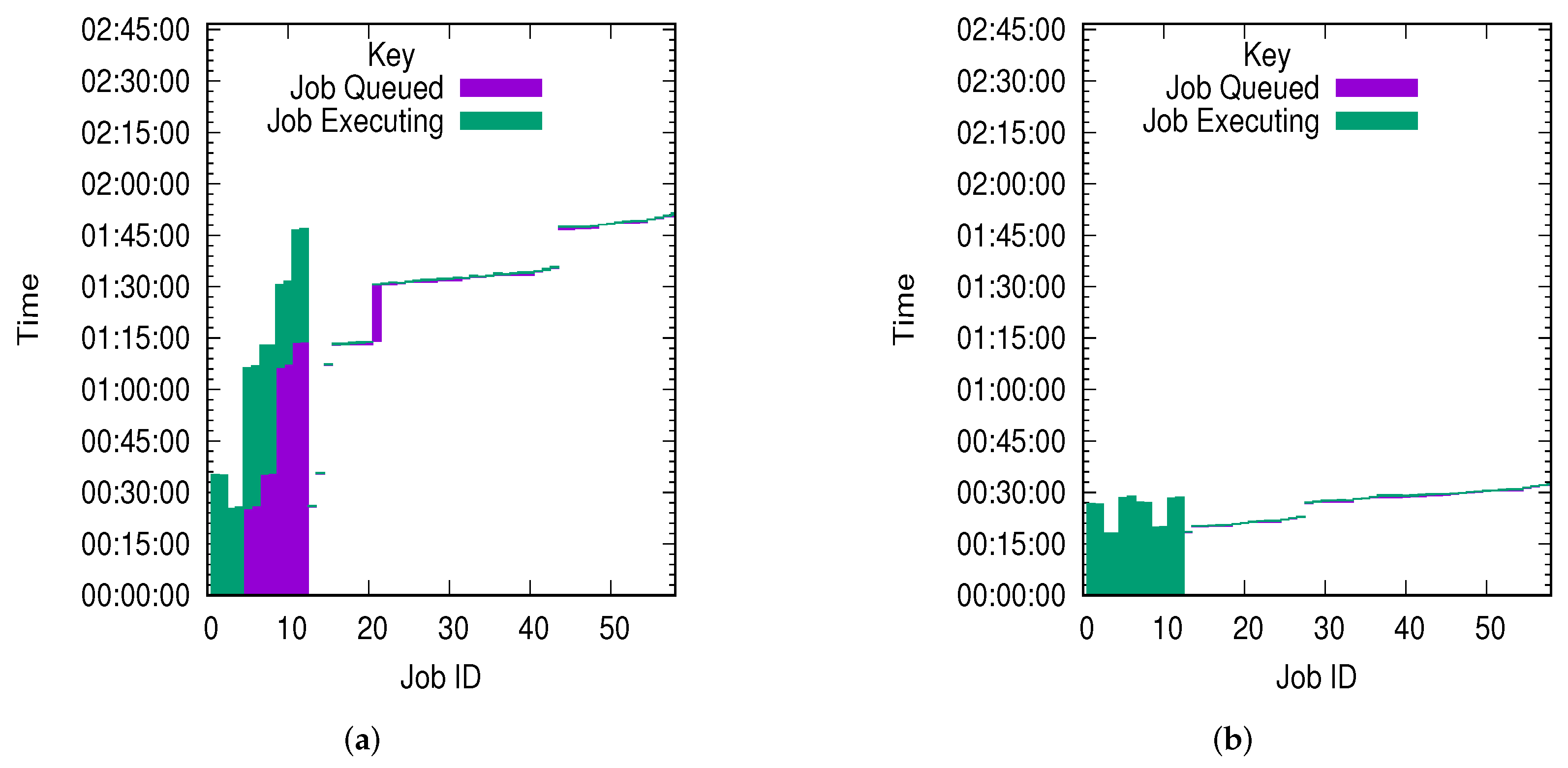
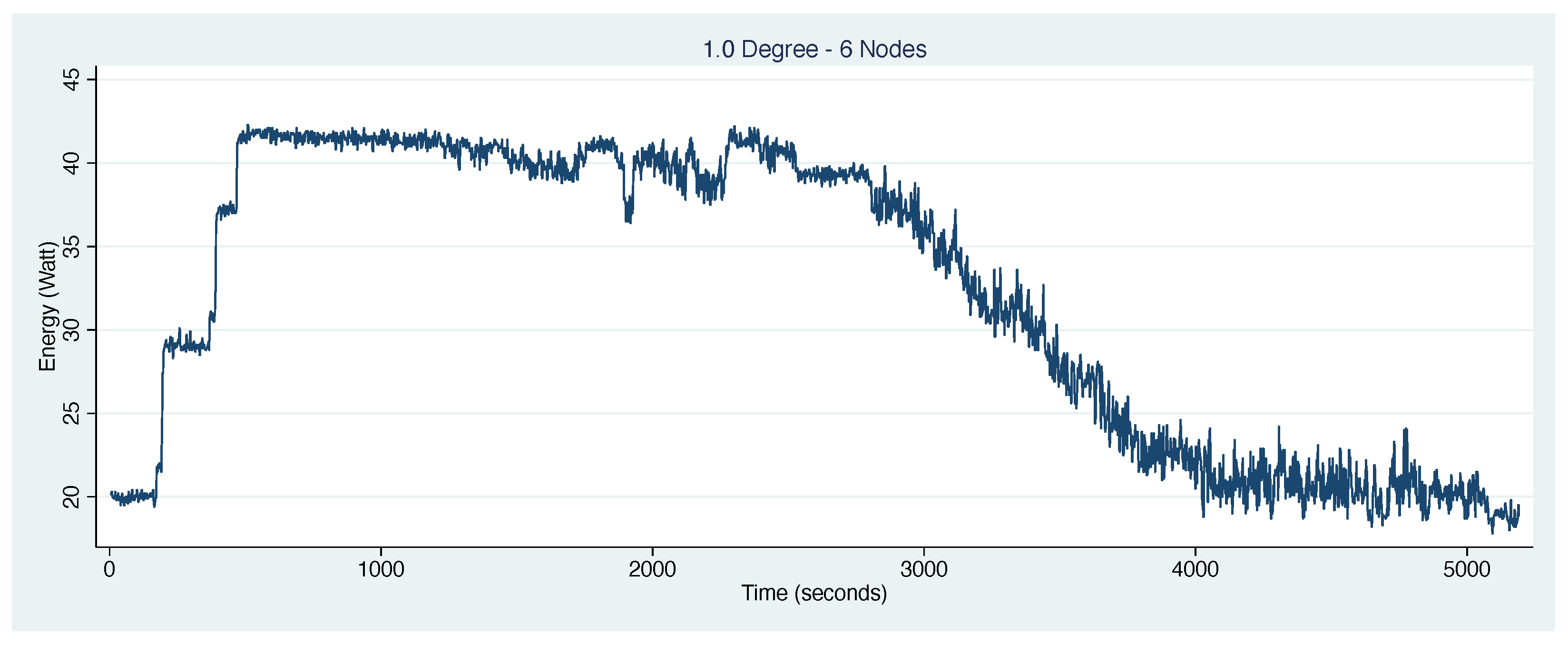
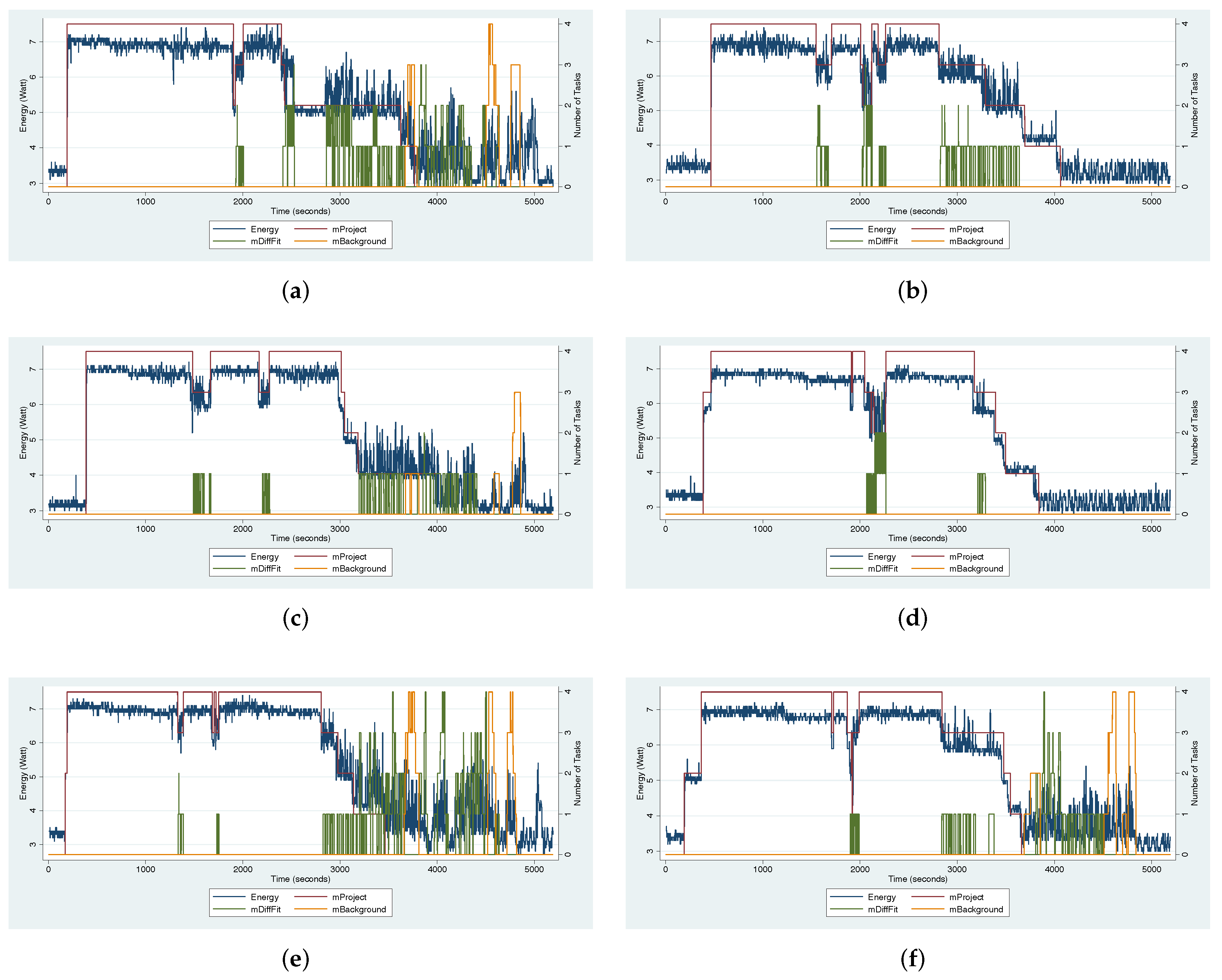
4.4. 1.0 Degree Workflow Results
4.5. 0.5 Degree Workflow Results
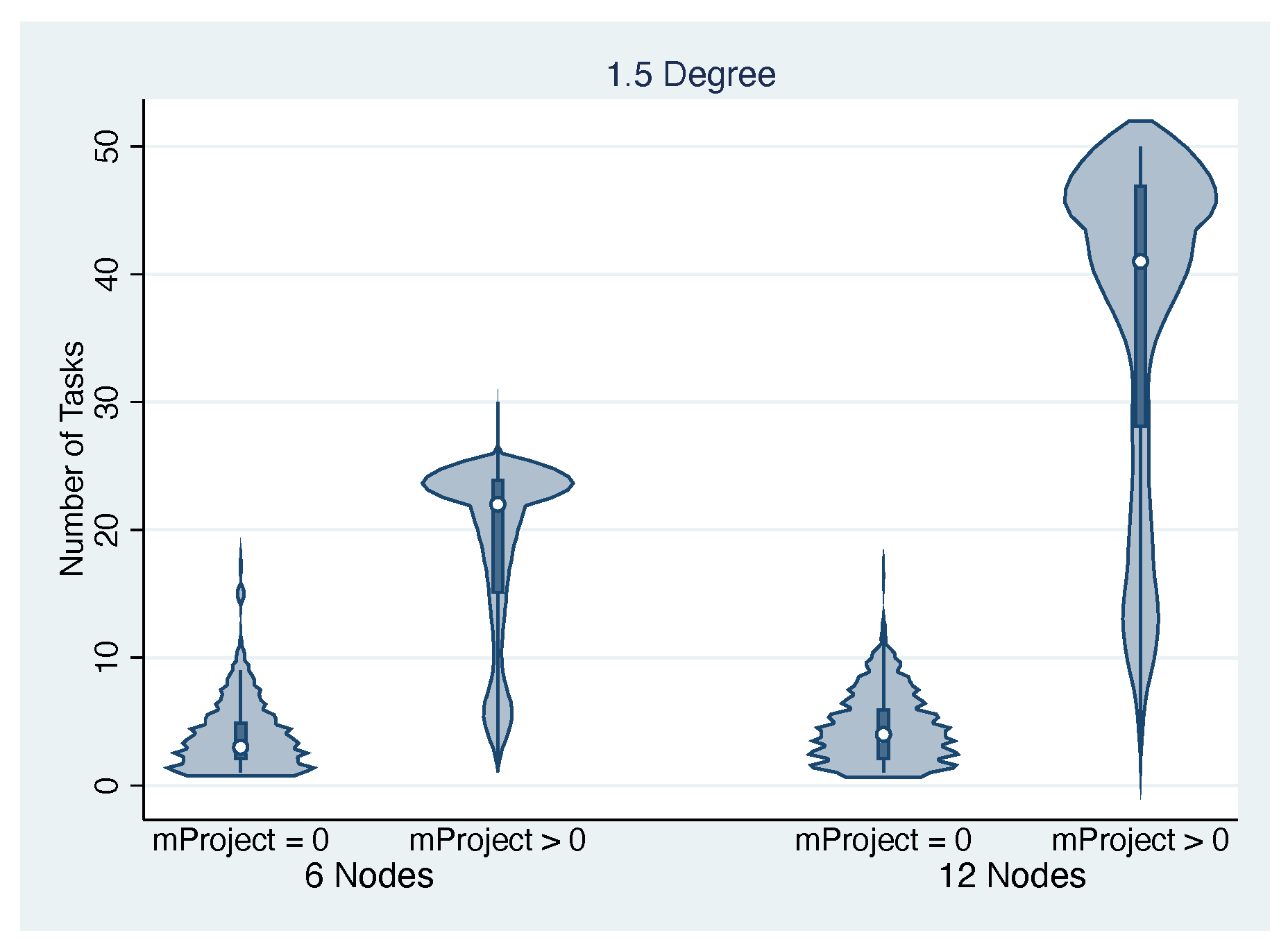
4.6. 1.5 Degree Workflow Results
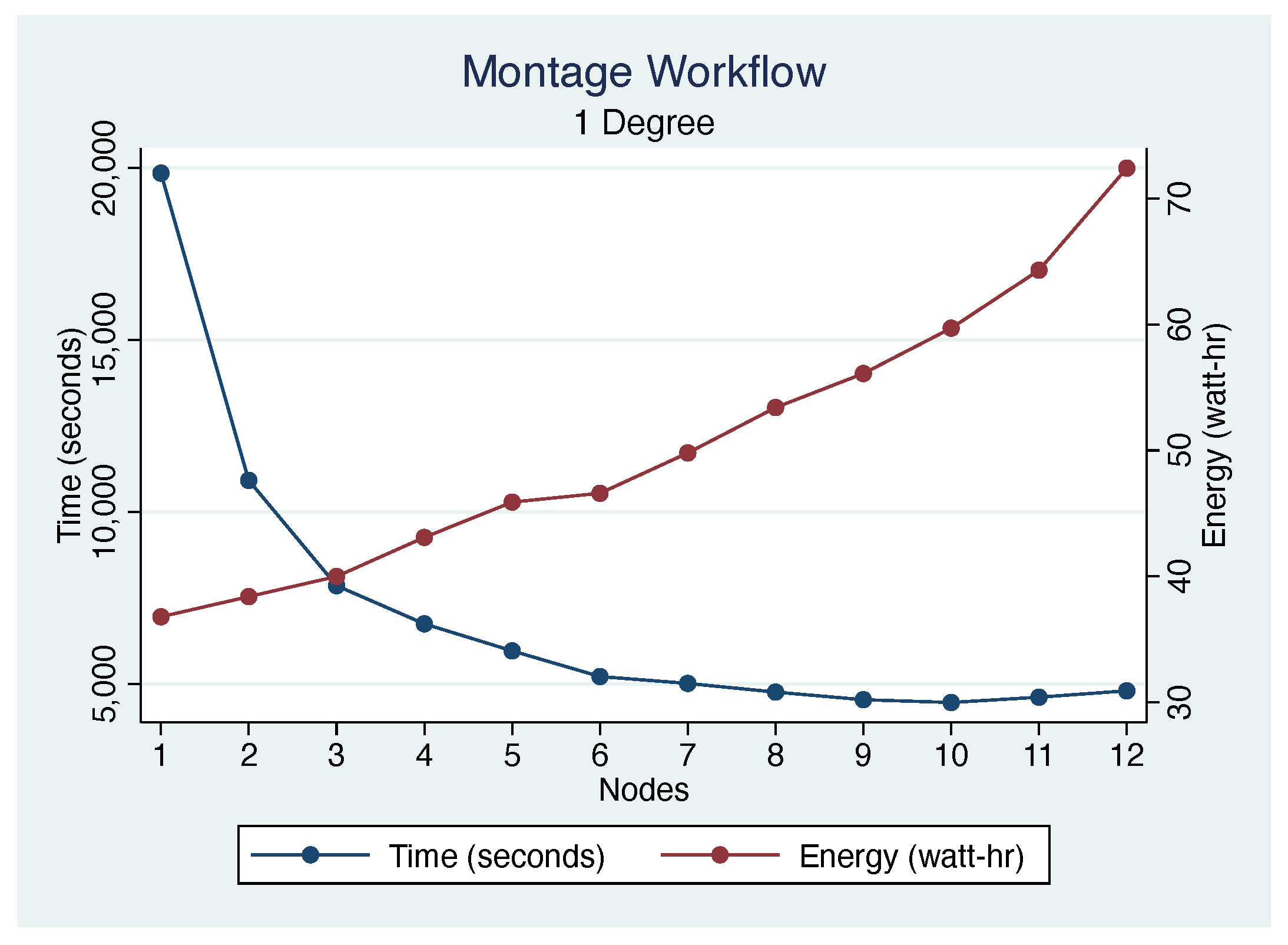
4.7. Discussion
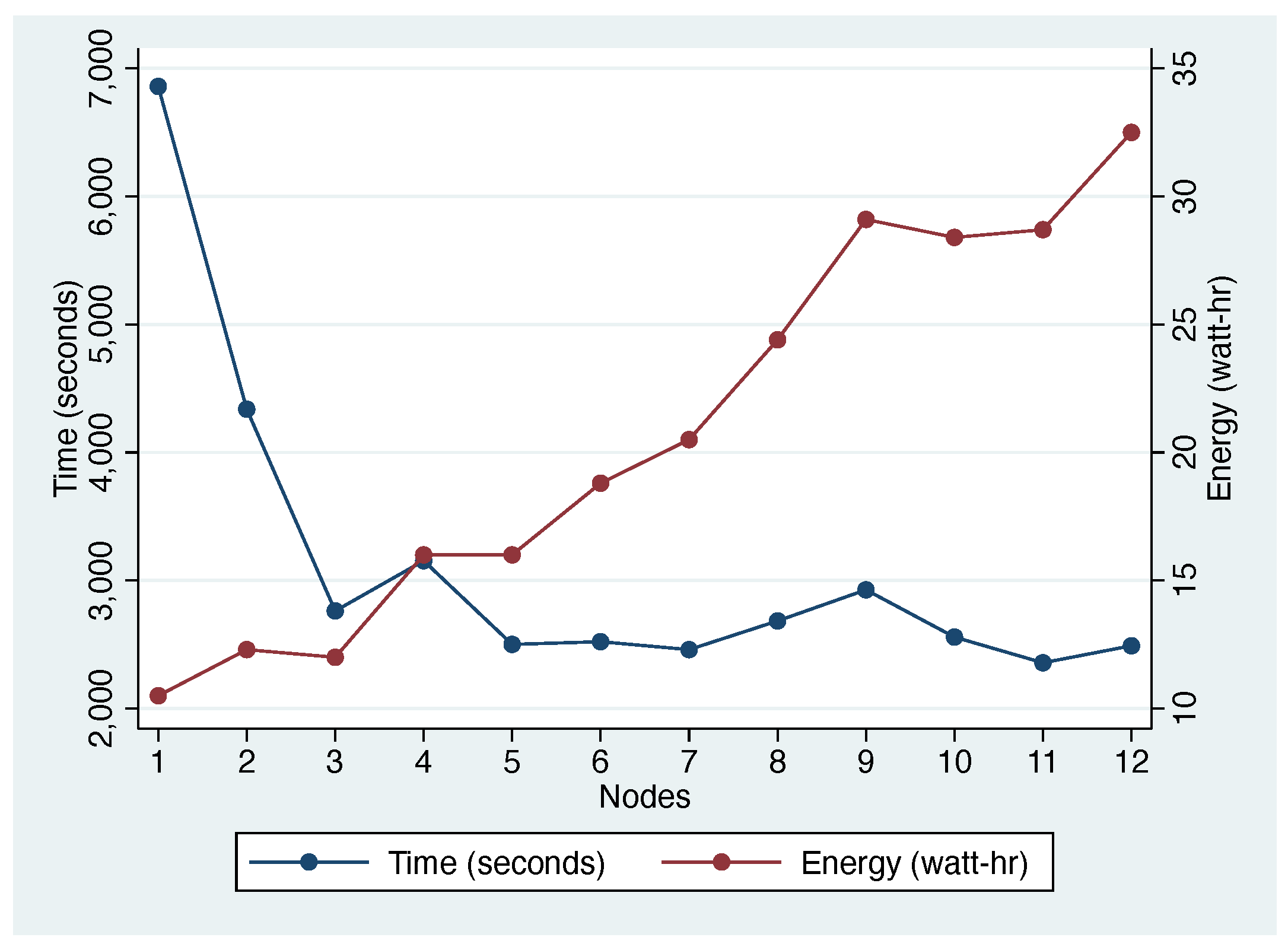
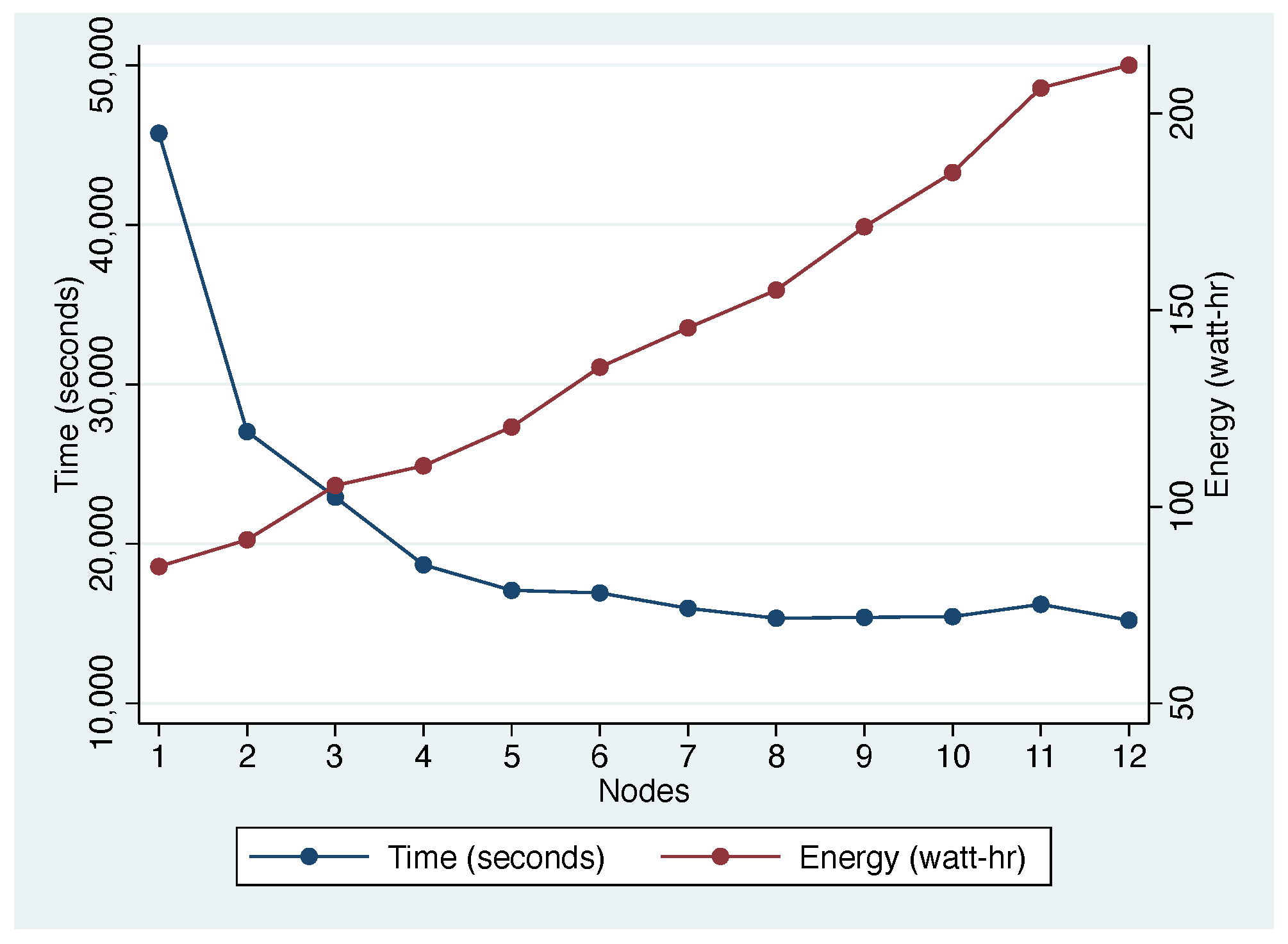
4.7.1. Impact of Cluster Size
4.7.2. Impact of Cluster Configuration
4.7.3. Impact of Workflow Structure
4.7.4. Performance vs. Energy
5. Bioinformatics Workflow Energy Evaluation
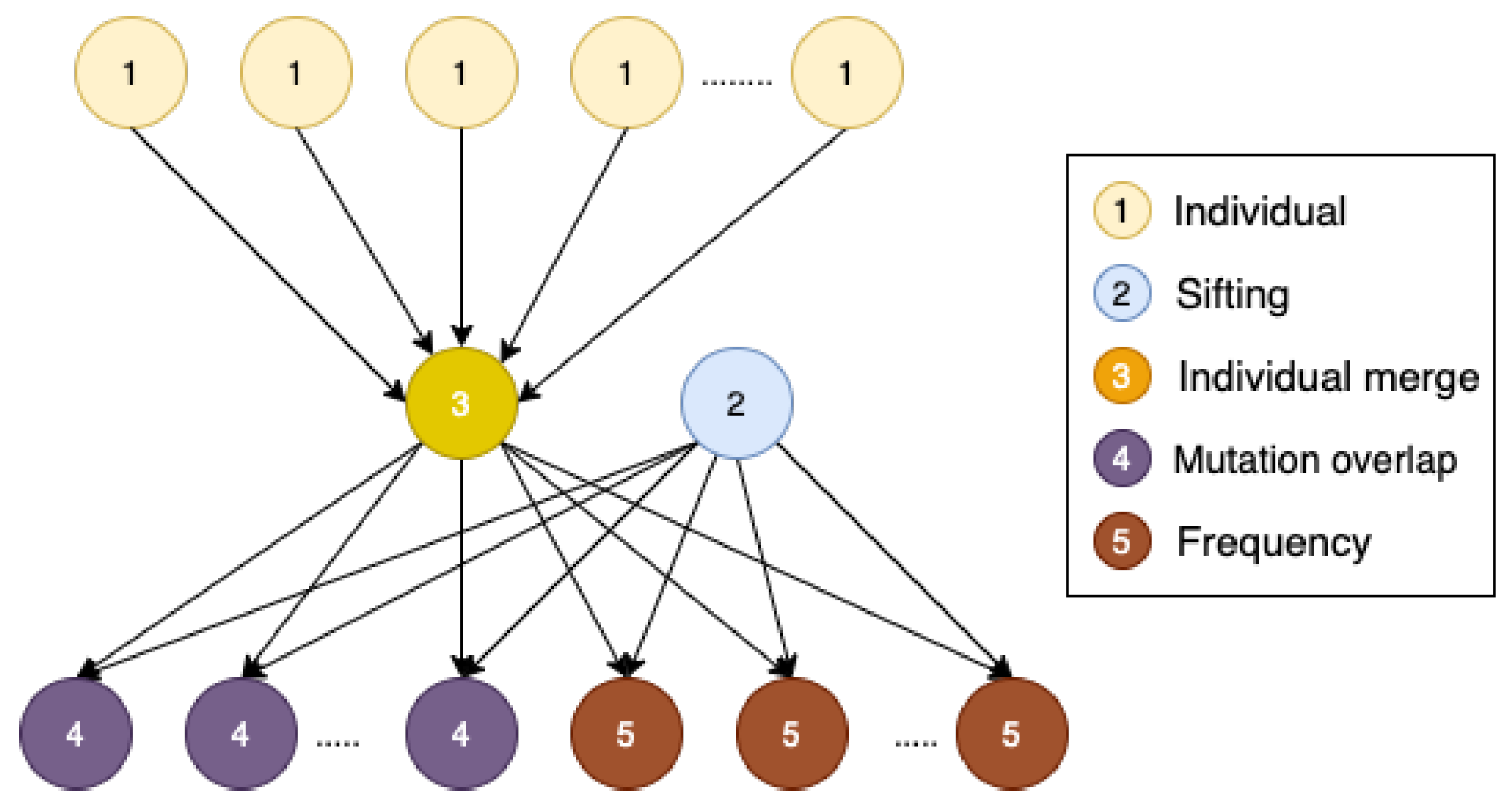
5.1. Workflow Description
5.2. Workflow Complexity
5.3. Workflow Characteristics
5.4. Bioinformatics Workflow on a Single Node—Results
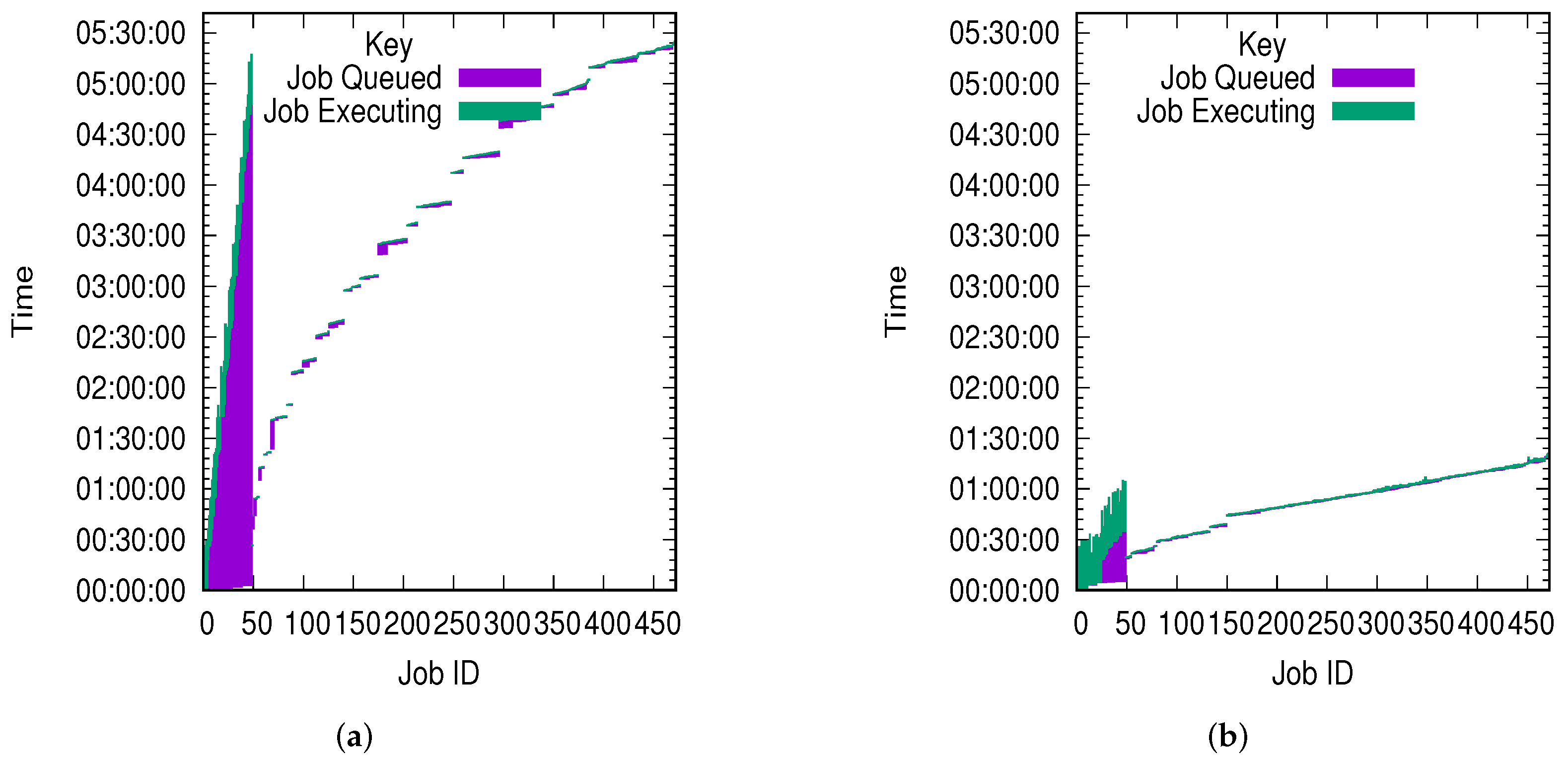
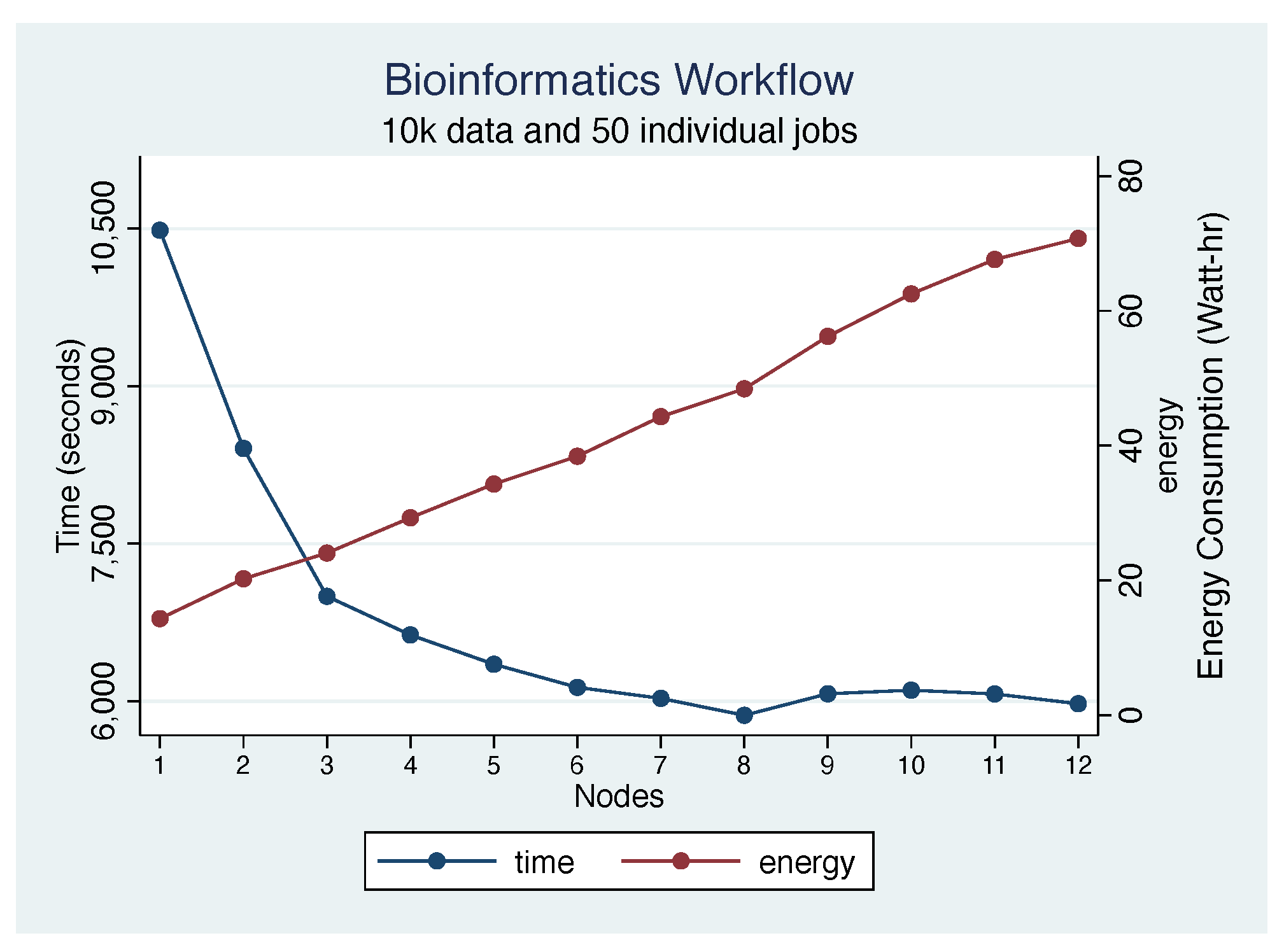
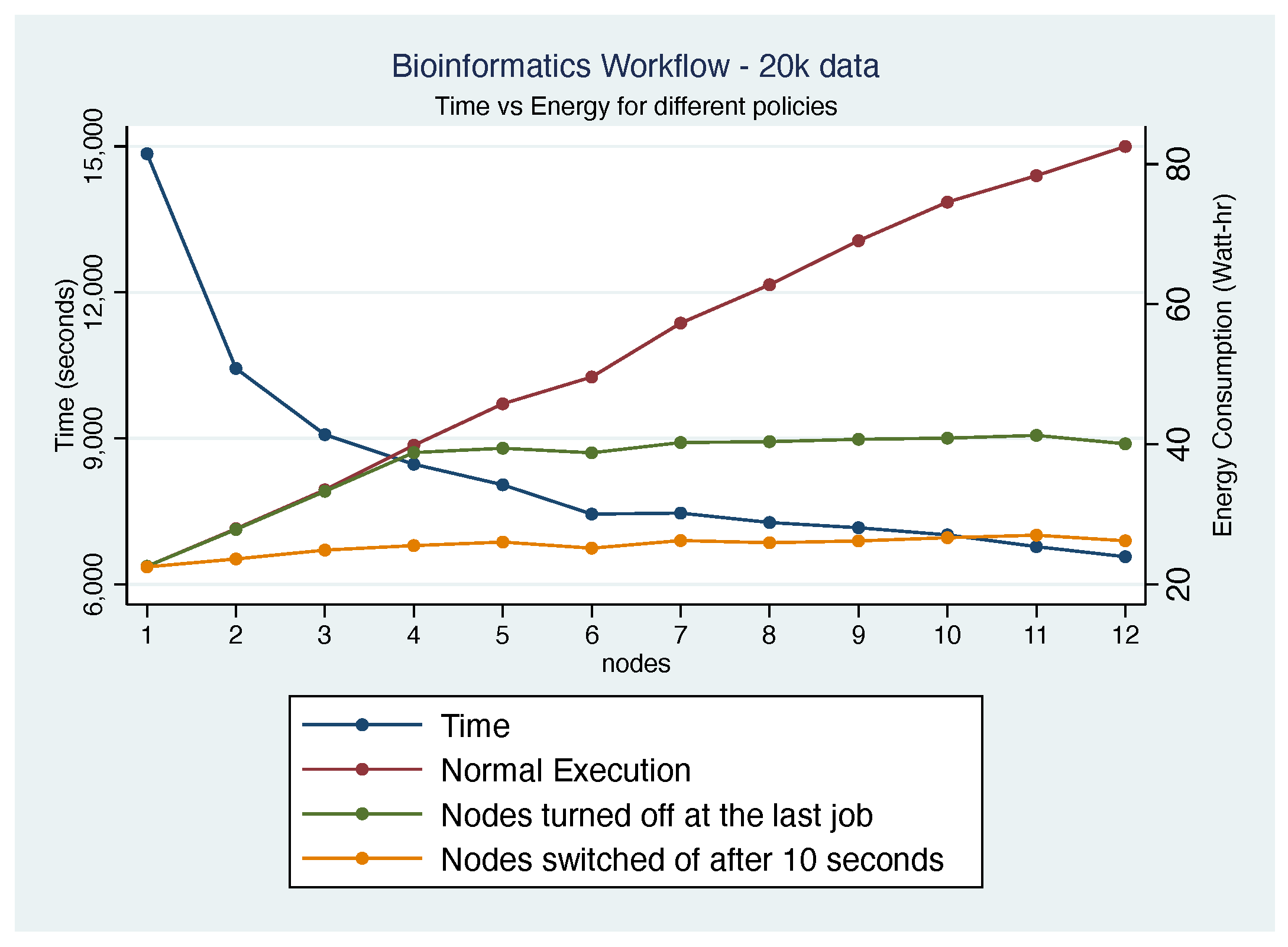
5.5. 10 k Workload Results
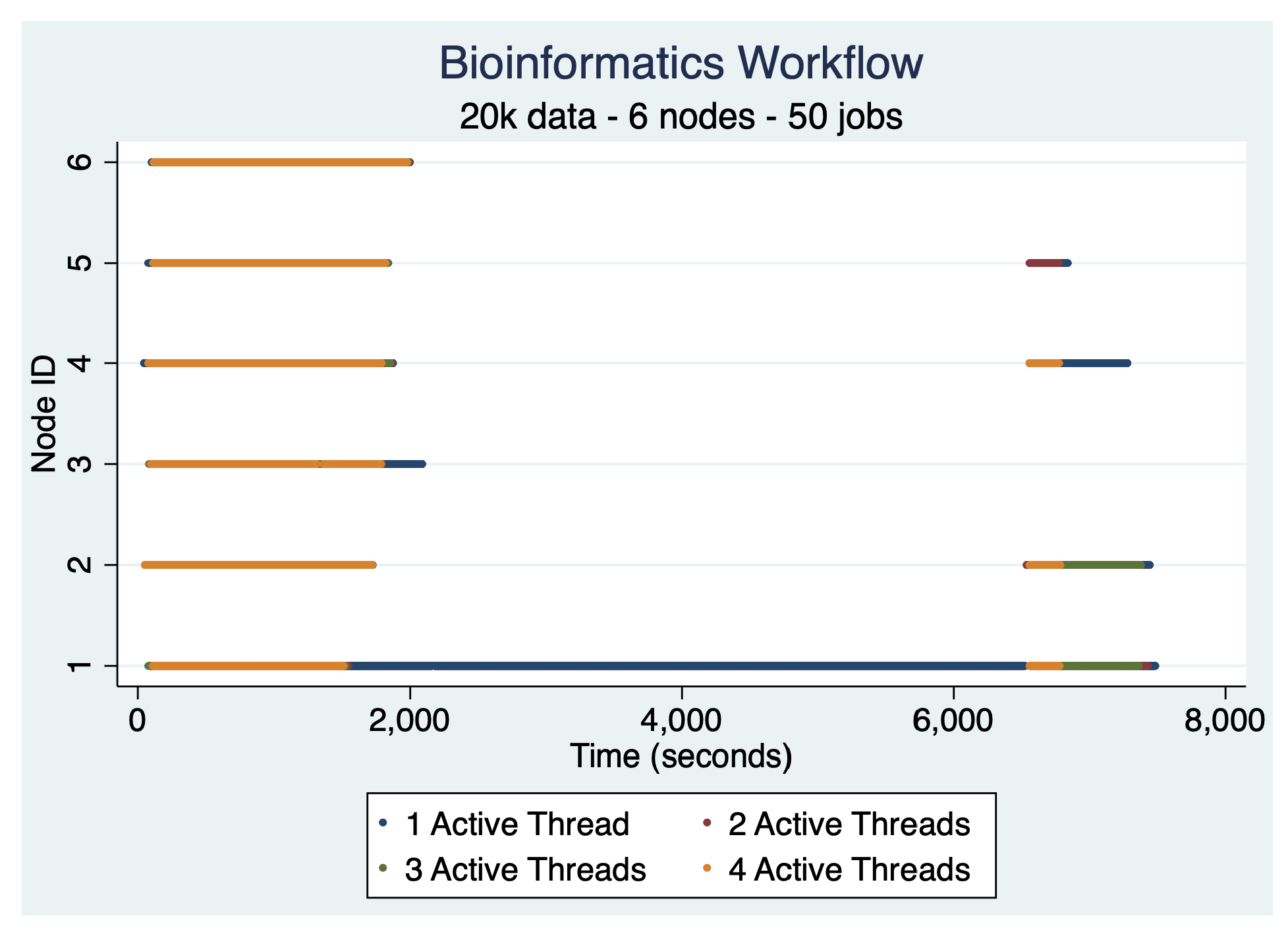
5.6. 20 k Workload Results
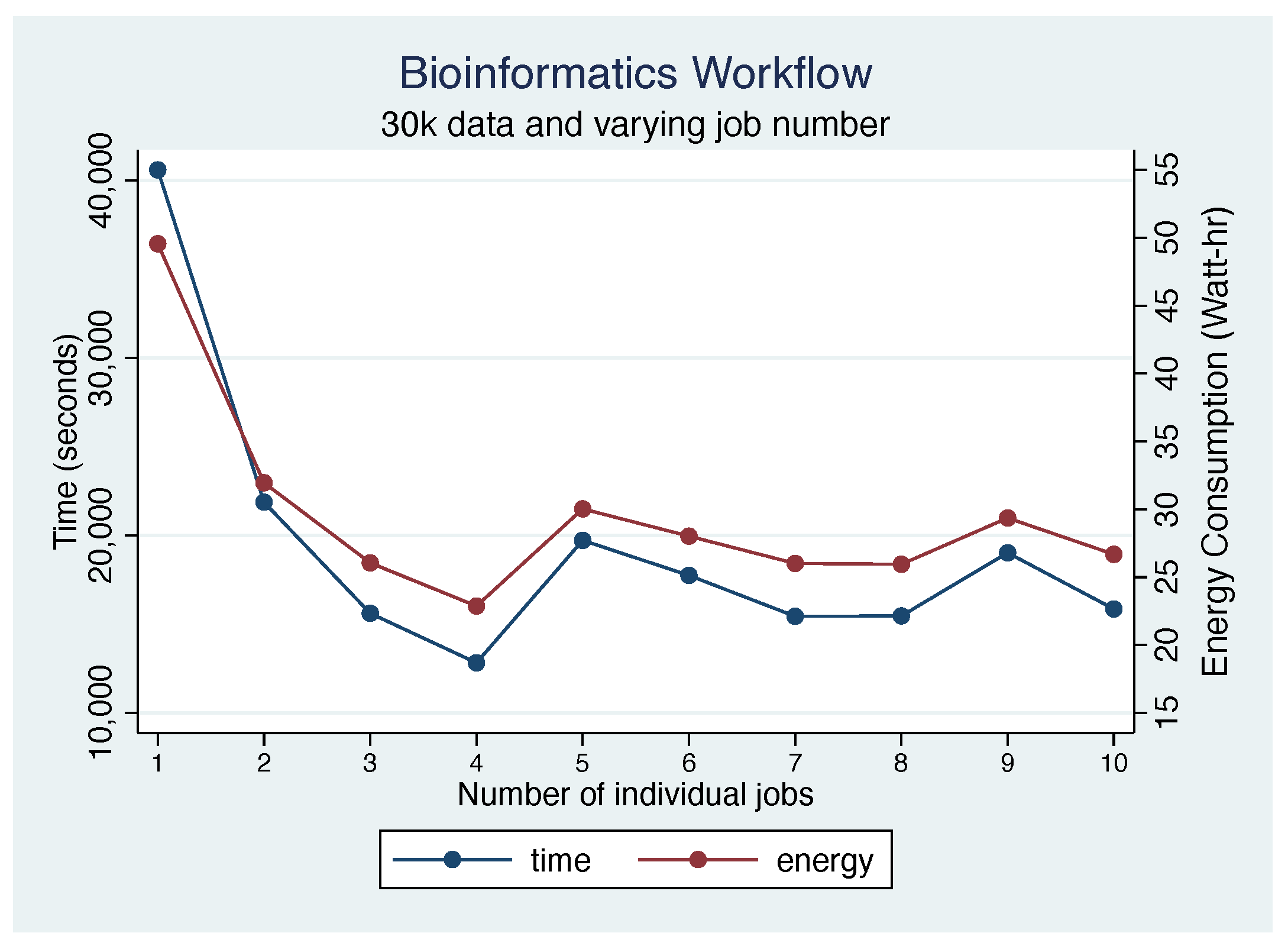
5.7. 30 k Workload Results
5.8. Discussion
5.8.1. Impact of Cluster Size and Configuration
5.8.2. Impact of Workflow Structure
5.8.3. Performance vs. Energy
5.9. Results Compared to the Literature
6. Energy-Aware Workflow Execution
6.1. Workflow Analysis
6.2. Optimising Energy Usage
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Taylor, I.J.; Deelman, E.; Gannon, D.B.; Shields, M. (Eds.) Workflows for e-Science: Scientific Workflows for Grids, 1st ed.; Springer: London, UK, 2007; Volume 1. [Google Scholar]
- Deelman, E.; Singh, G.; Su, M.H.; Blythe, J.; Gil, Y.; Kesselman, C.; Mehta, G.; Vahi, K.; Berriman, G.B.; Good, J.; et al. Pegasus: A framework for mapping complex scientific workflows onto distributed systems. Sci. Prog. 2005, 13, 219–237. [Google Scholar] [CrossRef]
- Hull, D.; Wolstencroft, K.; Stevens, R.; Goble, C.; Pocock, M.R.; Li, P.; Oinn, T. Taverna: A tool for building and running workflows of services. Nucleic Acids Res. 2006, 34, W729–W732. [Google Scholar] [CrossRef] [Green Version]
- Ludäscher, B.; Altintas, I.; Berkley, C.; Higgins, D.; Jaeger, E.; Jones, M.; Lee, E.A.; Tao, J.; Zhao, Y. Scientific workflow management and the Kepler system. Concurr. Comput. Pract. Exp. 2006, 18, 1039–1065. [Google Scholar] [CrossRef] [Green Version]
- Wang, J. Emergency healthcare workflow modeling and timeliness analysis. IEEE Trans. Syst. Man Cybern.—Part A Syst. Hum. 2012, 42, 1323–1331. [Google Scholar] [CrossRef]
- Wu, Q.; Datla, V.V. On performance modeling and prediction in support of scientific workflow optimization. In Proceedings of the 2011 IEEE World Congress on Services, Washington, DC, USA, 4–9 July 2011; pp. 161–168. [Google Scholar]
- Kim, J.; Deelman, E.; Gil, Y.; Mehta, G.; Ratnakar, V. Provenance trails in the wings/pegasus system. Concurr. Comput. Pract. Exp. 2008, 20, 587–597. [Google Scholar] [CrossRef]
- Li, J.; Fan, Y.; Zhou, M. Performance modeling and analysis of workflow. IEEE Trans. Syst. Man Cybern.—Part A Syst. Hum. 2004, 34, 229–242. [Google Scholar]
- Hoffa, C.; Mehta, G.; Freeman, T.; Deelman, E.; Keahey, K.; Berriman, B.; Good, J. On the use of cloud computing for scientific workflows. In Proceedings of the 2008 IEEE Fourth International Conference on eScience, Indianapolis, IN, USA, 7–12 December 2008; pp. 640–645. [Google Scholar]
- Liu, X.; Yuan, D.; Zhang, G.; Li, W.; Cao, D.; He, Q.; Chen, J.; Yang, Y. The Design of Cloud Workflow Systems, 1st ed.; SpringerBriefs in Computer Science, Springer Science & Business Media; Springer: New York, NY, USA, 2012; p. 97. [Google Scholar] [CrossRef]
- Lee, K.; Paton, N.W.; Sakellariou, R.; Deelman, E.; Fernandes, A.A.; Mehta, G. Adaptive workflow processing and execution in pegasus. Concurr. Comput. Pract. Exp. 2009, 21, 1965–1981. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Paton, N.W.; Sakellariou, R.; Fernandes, A.A. Utility Driven Adaptive Workflow Execution. In Proceedings of the 2009 9th IEEE/ACM International Symposium on Cluster Computing and the Grid, Shanghai, China, 18–21 May 2009; pp. 220–227. [Google Scholar]
- Lee, K.; Paton, N.W.; Sakellariou, R.; Fernandes, A. Utility functions for adaptively executing concurrent workflows. Concurr. Comput. Pract. Exp. 2011, 23, 646–666. [Google Scholar] [CrossRef] [Green Version]
- Warade, M.; Schneider, J.G.; Lee, K. FEPAC: A Framework for Evaluating Parallel Algorithms on Cluster Architectures. In Proceedings of the 2021 Australasian Computer Science Week Multiconference, Online, 1–5 February 2021; pp. 1–10. [Google Scholar]
- Bharathi, S.; Chervenak, A.; Deelman, E.; Mehta, G.; Su, M.H.; Vahi, K. Characterization of scientific workflows. In Proceedings of the 2008 Third Workshop on Workflows in Support of Large-Scale Science, Austin, TX, USA, 17 November 2008; pp. 1–10. [Google Scholar]
- Abrahamsson, P.; Helmer, S.; Phaphoom, N.; Nicolodi, L.; Preda, N.; Miori, L.; Angriman, M.; Rikkilä, J.; Wang, X.; Hamily, K.; et al. Affordable and Energy-Efficient Cloud Computing Clusters: The Bolzano Raspberry Pi Cloud Cluster Experiment. In Proceedings of the 5th International Conference on Cloud Computing Technology and Science, Bristol, UK, 2–5 December 2013. [Google Scholar]
- Basford, P.J.; Johnston, S.J.; Perkins, C.S.; Garnock-Jones, T.; Tso, F.P.; Pezaros, D.; Mullins, R.D.; Yoneki, E.; Singer, J.; Cox, S.J. Performance Analysis of Single Board Computer Clusters. Future Gener. Comput. Syst. 2020, 102, 278–291. [Google Scholar] [CrossRef]
- Qureshi, B.; Koubaa, A. On Energy Efficiency and Performance Evaluation of Single Board Computer Based Clusters: A Hadoop Case Study. Electronics 2019, 8, 182. [Google Scholar] [CrossRef] [Green Version]
- Kassab, A.; Nicod, J.M.; Philippe, L.; Rehn-Sonigo, V. Green power aware approaches for scheduling independent tasks on a multi-core machine. Sustain. Comput. Inform. Syst. 2021, 31, 100590. [Google Scholar] [CrossRef]
- Kassab, A.; Nicod, J.M.; Philippe, L. Green Power Constrained Scheduling for Sequential Independent Tasks on Identical Parallel Machines. In Proceedings of the 2019 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Xiamen, China, 16–18 December 2019; pp. 132–139. [Google Scholar]
- Ji, K.; Zhang, F.; Chi, C.; Song, P.; Zhou, B.; Marahatta, A.; Liu, Z. A Joint Energy Efficiency Optimization Scheme Based on Marginal Cost and Workload Prediction in Data Centers. Sustain. Comput. Inform. Syst. 2021, 32, 100596. [Google Scholar] [CrossRef]
- Mishra, S.K.; Puthal, D.; Sahoo, B.; Jayaraman, P.P.; Jun, S.; Zomaya, A.Y.; Ranjan, R. Energy-efficient VM-placement in cloud data center. Sustain. Comput. Inform. Syst. 2018, 20, 48–55. [Google Scholar] [CrossRef]
- Khaleel, M.; Zhu, M.M. Energy-aware job management approaches for workflow in cloud. In Proceedings of the 2015 IEEE International Conference on Cluster Computing, Chicago, IL, USA, 8–11 September 2015; pp. 506–507. [Google Scholar]
- Xu, X.; Dou, W.; Zhang, X.; Chen, J. EnReal: An energy-aware resource allocation method for scientific workflow executions in cloud environment. IEEE Trans. Cloud Comput. 2015, 4, 166–179. [Google Scholar] [CrossRef]
- Cloutier, M.F.; Paradis, C.; Weaver, V.M. A raspberry pi cluster instrumented for fine-grained power measurement. Electronics 2016, 5, 61. [Google Scholar] [CrossRef] [Green Version]
- Pietri, I.; Malawski, M.; Juve, G.; Deelman, E.; Nabrzyski, J.; Sakellariou, R. Energy-constrained provisioning for scientific workflow ensembles. In Proceedings of the 2013 International Conference on Cloud and Green Computing, Karlsruhe, Germany, 30 September–2 October 2013; pp. 34–41. [Google Scholar]
- Durillo, J.J.; Nae, V.; Prodan, R. Multi-objective workflow scheduling: An analysis of the energy efficiency and makespan tradeoff. In Proceedings of the 2013 13th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing, Delft, The Netherlands, 13–16 May 2013; pp. 203–210. [Google Scholar]
- Watanabe, E.N.; Campos, P.P.; Braghetto, K.R.; Batista, D.M. Energy saving algorithms for workflow scheduling in cloud computing. In Proceedings of the 2014 Brazilian Symposium on Computer Networks and Distributed Systems, Florianopolis, Brazil, 5–9 May 2014; pp. 9–16. [Google Scholar]
- Pietri, I.; Sakellariou, R. Energy-aware workflow scheduling using frequency scaling. In Proceedings of the 43rd International Conference on Parallel Processing Workshops, Minneapolis, MN, USA, 9–12 September 2014; pp. 104–113. [Google Scholar]
- Thanavanich, T.; Uthayopas, P. Efficient energy aware task scheduling for parallel workflow tasks on hybrids cloud environment. In Proceedings of the 2013 International Computer Science and Engineering Conference (ICSEC), Nakhonpathom, Thailand, 4–6 September 2013; pp. 37–42. [Google Scholar]
- Ghose, M.; Verma, P.; Karmakar, S.; Sahu, A. Energy efficient scheduling of scientific workflows in cloud environment. In Proceedings of the 19th International Conference on High Performance Computing and Communications, 15th International Conference on Smart City, 3rd International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Bangkok, Thailand, 18–20 December 2017; pp. 170–177. [Google Scholar]
- Juve, G.; Chervenak, A.; Deelman, E.; Bharathi, S.; Mehta, G.; Vahi, K. Characterizing and profiling scientific workflows. Future Gener. Comput. Syst. 2013, 29, 682–692. [Google Scholar] [CrossRef]
- Deelman, E.; Vahi, K.; Juve, G.; Rynge, M.; Callaghan, S.; Maechling, P.J.; Mayani, R.; Chen, W.; Da Silva, R.F.; Livny, M.; et al. Pegasus, a workflow management system for science automation. Future Gener. Comput. Syst. 2015, 46, 17–35. [Google Scholar] [CrossRef] [Green Version]
- Bux, M.N. Scientific Workflows for Hadoop. Ph.D. Thesis, Institute for Computer Science, Humboldt University, Berlin, Germany, 2018. [Google Scholar] [CrossRef]
- Litzkow, M.J.; Livny, M.; Mutka, M.W. Condor-A Hunter of Idle Workstations; Technical Report; University of Wisconsin-Madison Department of Computer Sciences: Madison, WI, USA, 1987. [Google Scholar]
- Yu, J.; Buyya, R. A Taxonomy of Scientific Workflow Systems for Grid Computing. ACM Sigmod Rec. 2005, 34, 44–49. [Google Scholar] [CrossRef]
- Couvares, P.; Kosar, T.; Roy, A.; Weber, J.; Wenger, K. Workflow management in condor. In Workflows for e-Science; Springer: Berlin/Heidelberg, Germany, 2007; pp. 357–375. [Google Scholar]
- Berriman, G.B.; Deelman, E.; Good, J.C.; Jacob, J.C.; Katz, D.S.; Kesselman, C.; Laity, A.C.; Prince, T.A.; Singh, G.; Su, M.H. Montage: A grid-enabled engine for delivering custom science-grade mosaics on demand. In Optimizing Scientific Return for Astronomy through Information Technologies; International Society for Optics and Photonics; SPIE: Bellingham, WA, USA, 2004; Volume 5493, pp. 221–232. [Google Scholar]
- Jacob, J.C.; Katz, D.S.; Berriman, G.B.; Good, J.; Laity, A.C.; Deelman, E.; Kesselman, C.; Singh, G.; Su, M.H.; Prince, T.A.; et al. Montage: An Astronomical Image Mosaicking Toolkit; Astrophysics Source Code Library, Michigan Technological University: Houghton, MI, USA, 2010; p. ascl-1010. [Google Scholar]
- Juve, G.; Deelman, E.; Vahi, K.; Mehta, G.; Berriman, B.; Berman, B.P.; Maechling, P. Scientific workflow applications on Amazon EC2. In Proceedings of the 2009 5th IEEE International Conference on e-Science Workshops, Oxford, UK, 9–11 December 2009; pp. 59–66. [Google Scholar]
- Clarke, L.; Fairley, S.; Zheng-Bradley, X.; Streeter, I.; Perry, E.; Lowy, E.; Tassé, A.M.; Flicek, P. The international Genome sample resource (IGSR): A worldwide collection of genome variation incorporating the 1000 Genomes Project data. Nucleic Acids Res. 2016, 45, D854–D859. [Google Scholar] [CrossRef] [Green Version]
- 1000 Genomes Project Consortium. A global reference for human genetic variation. Nature 2015, 526, 68. [Google Scholar] [CrossRef] [Green Version]
- McLaren, W.; Gil, L.; Hunt, S.E.; Riat, H.S.; Ritchie, G.R.; Thormann, A.; Flicek, P.; Cunningham, F. The ensembl variant effect predictor. Genome Biol. 2016, 17, 122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, W.; Deelman, E. Workflow Overhead Analysis and Optimizations. In Proceedings of the WORKS ’11 6th Workshop on Workflows in Support of Large-Scale Science, Association for Computing Machinery, Seattle, WA, USA, 14 November 2011; pp. 11–20. [Google Scholar] [CrossRef]
- Chen, W.; Deelman, E. Integration of workflow partitioning and resource provisioning. In Proceedings of the 2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (ccgrid 2012), Ottawa, ON, Canada, 13–16 May 2012; pp. 764–768. [Google Scholar]
- Maurya, A.K.; Tripathi, A.K. Deadline-constrained algorithms for scheduling of bag-of-tasks and workflows in cloud computing environments. In Proceedings of the 2nd International Conference on High Performance Compilation, Computing and Communications, Hong Kong, China, 15–17 March 2018; pp. 6–10. [Google Scholar]
- Medara, R.; Singh, R.S. Energy efficient and reliability aware workflow task scheduling in cloud environment. Wirel. Pers. Commun. 2021, 119, 1301–1320. [Google Scholar] [CrossRef]
- Konjaang, J.K.; Xu, L. Cost optimised heuristic algorithm (coha) for scientific workflow scheduling in iaas cloud environment. In Proceedings of the 2020 IEEE 6th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), Baltimore, MD, USA, 25–27 May 2020; pp. 162–168. [Google Scholar]
- Meena, J.; Vardhan, M. Cost-effective Heuristic Workflow Scheduling Algorithm in Cloud Under Deadline Constraint. Recent Adv. Comput. Sci. Commun. 2020, 13, 1302–1317. [Google Scholar] [CrossRef]
- Shishido, H.Y.; Estrella, J.C.; Toledo, C.F.M. Multi-objective optimization for workflow scheduling under task selection policies in clouds. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
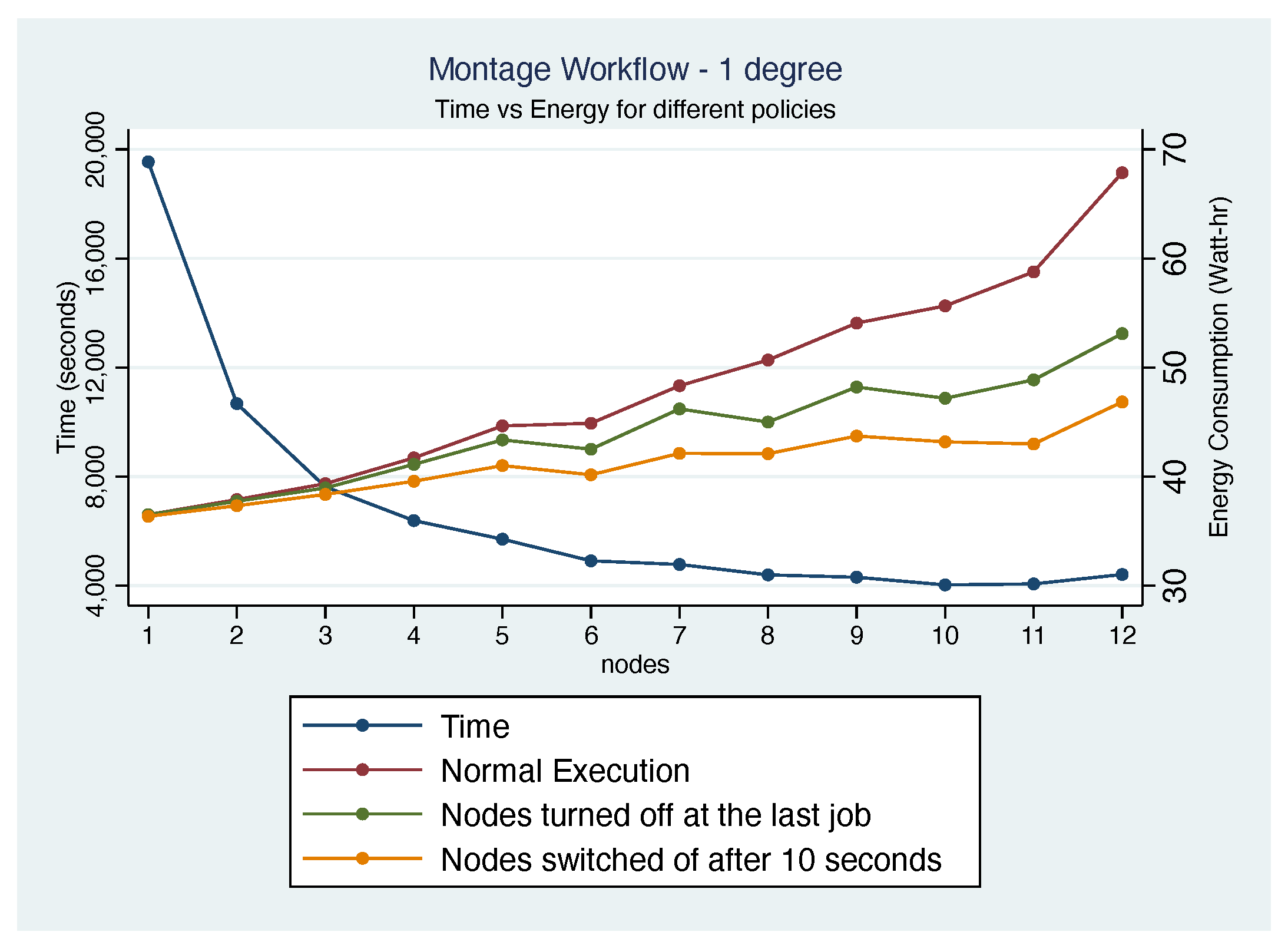{kind=link}
{kind=link}
| Montage Job | Workflow Size | |||
|---|---|---|---|---|
| 0.5 Deg. | 1 Deg. | 1.5 Deg. | 2 Deg. | |
| mProject | 12 | 48 | 108 | 192 |
| mDiffFit | 18 | 360 | 1890 | 6048 |
| mConcatFit | 3 | 3 | 3 | 3 |
| mBgmodel | 3 | 3 | 3 | 3 |
| mBackground | 12 | 48 | 108 | 192 |
| mImgtbl | 3 | 3 | 3 | 3 |
| mAdd | 3 | 3 | 3 | 3 |
| mViewer | 4 | 4 | 4 | 4 |
| Total jobs | 58 | 472 | 2122 | 6448 |
| Activities | 1 Node | 3 Nodes | 6 Nodes | 9 Nodes | 12 Nodes | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Total (seconds) | 45,584 | 22,038 | 15,868 | 13,916 | 13,654 | |||||
| mProject > 0 | 44,193 | 96.9% | 20,097 | 91.2% | 9787 | 61.7% | 6586 | 47.3% | 5600 | 41.0% |
| mProject > 0 running alone | 33,791 | 74.1% | 10,362 | 47.0% | 3643 | 23.0% | 1584 | 11.4% | 1918 | 14.0% |
| mDiffFit > 0 | 9774 | 21.4% | 10,176 | 46.2% | 10,217 | 64.4% | 10,153 | 73.0% | 9014 | 66.0% |
| mDiffFit > 0 running alone | 420 | 0.9% | 724 | 3.3% | 3852 | 24.3% | 4787 | 34.4% | 5044 | 36.9% |
| mProject > 0 and mDiffFit > 0 | 9354 | 20.5% | 9449 | 42.9% | 5970 | 37.6% | 5002 | 35.9% | 3682 | 27.0% |
| mProject > 0 or mDiffFit > 0 | 44,613 | 97.9% | 20,824 | 94.5% | 14,034 | 88.4% | 11,737 | 84.3% | 10,932 | 80.1% |
| mBackground > 0 | 1031 | 2.3% | 970 | 4.4% | 933 | 5.9% | 892 | 6.4% | 860 | 6.3% |
| mBackground > 0 running alone | 292 | 0.6% | 565 | 2.6% | 688 | 4.3% | 786 | 5.6% | 781 | 5.7% |
| Bioinformatics Workflow | Workflow Size | ||
|---|---|---|---|
| Small 10 k Data | Medium 20 k Data | Large 30 k Data | |
| individual | 50 | 50 | 50 |
| sifting | 1 | 1 | 1 |
| individual_merge | 1 | 1 | 1 |
| frequency | 7 | 7 | 7 |
| mutation_overlap | 7 | 7 | 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Warade, M.; Schneider, J.-G.; Lee, K. Measuring the Energy and Performance of Scientific Workflows on Low-Power Clusters. Electronics 2022, 11, 1801. https://doi.org/10.3390/electronics11111801
Warade M, Schneider J-G, Lee K. Measuring the Energy and Performance of Scientific Workflows on Low-Power Clusters. Electronics. 2022; 11(11):1801. https://doi.org/10.3390/electronics11111801
Chicago/Turabian StyleWarade, Mehul, Jean-Guy Schneider, and Kevin Lee. 2022. "Measuring the Energy and Performance of Scientific Workflows on Low-Power Clusters" Electronics 11, no. 11: 1801. https://doi.org/10.3390/electronics11111801