
Three-Dimensional Reconstruction Method for Bionic Compound-Eye System Based on MVSNet Network

Abstract
:1. Introduction
- The nine-eye bionic compound-eye system with partial overlap of fields was proposed to capture images of the target scene with fewer shots, and the image quality was improved.
- CES-MVSNet for 3D reconstruction using the bionic compound-eye system was proposed to improve the reconstruction results.
- The efficiency and reliability of using the bionic compound-eye system for 3D reconstruction were proved.
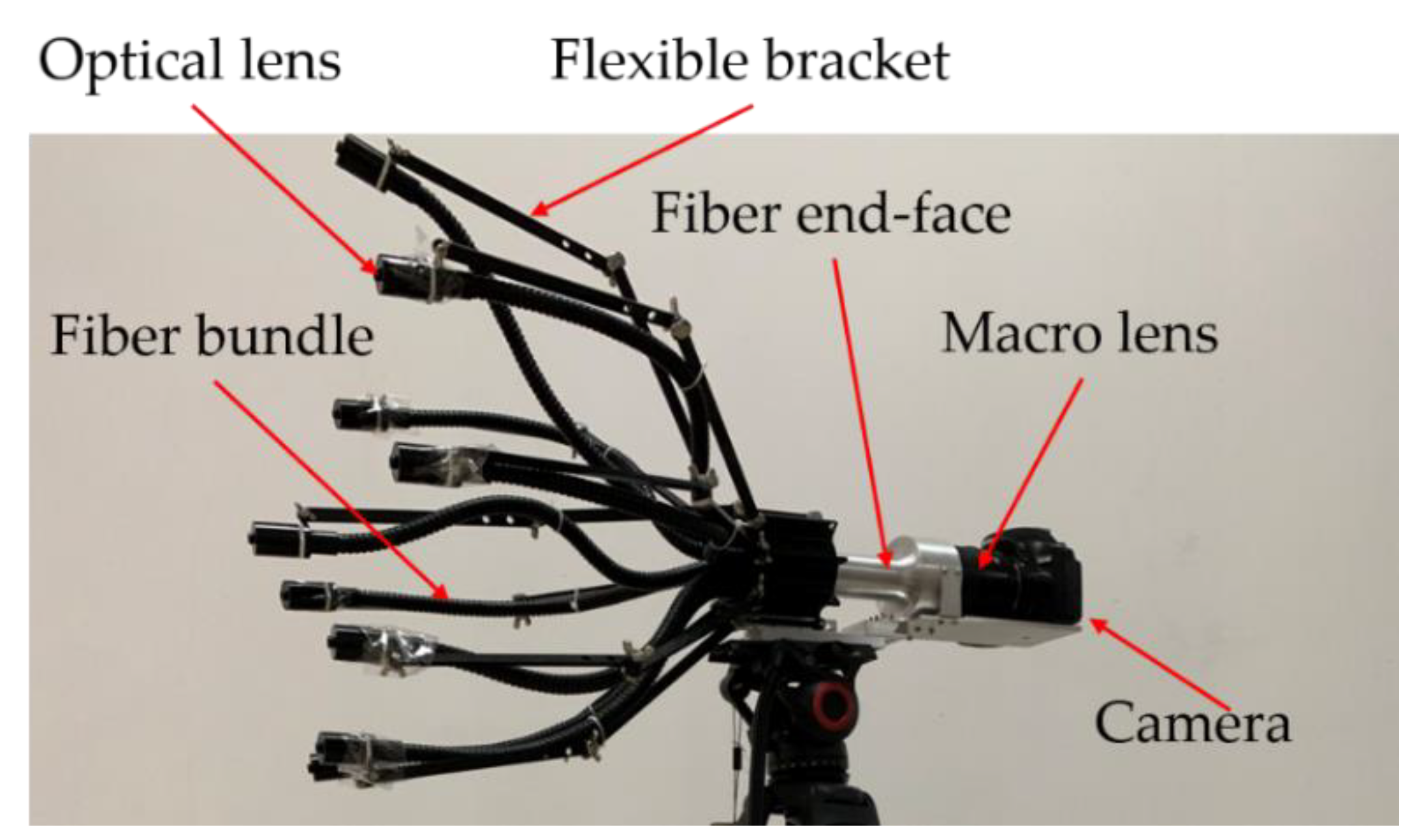
2. Nine-Eye Bionic Compound-Eye System
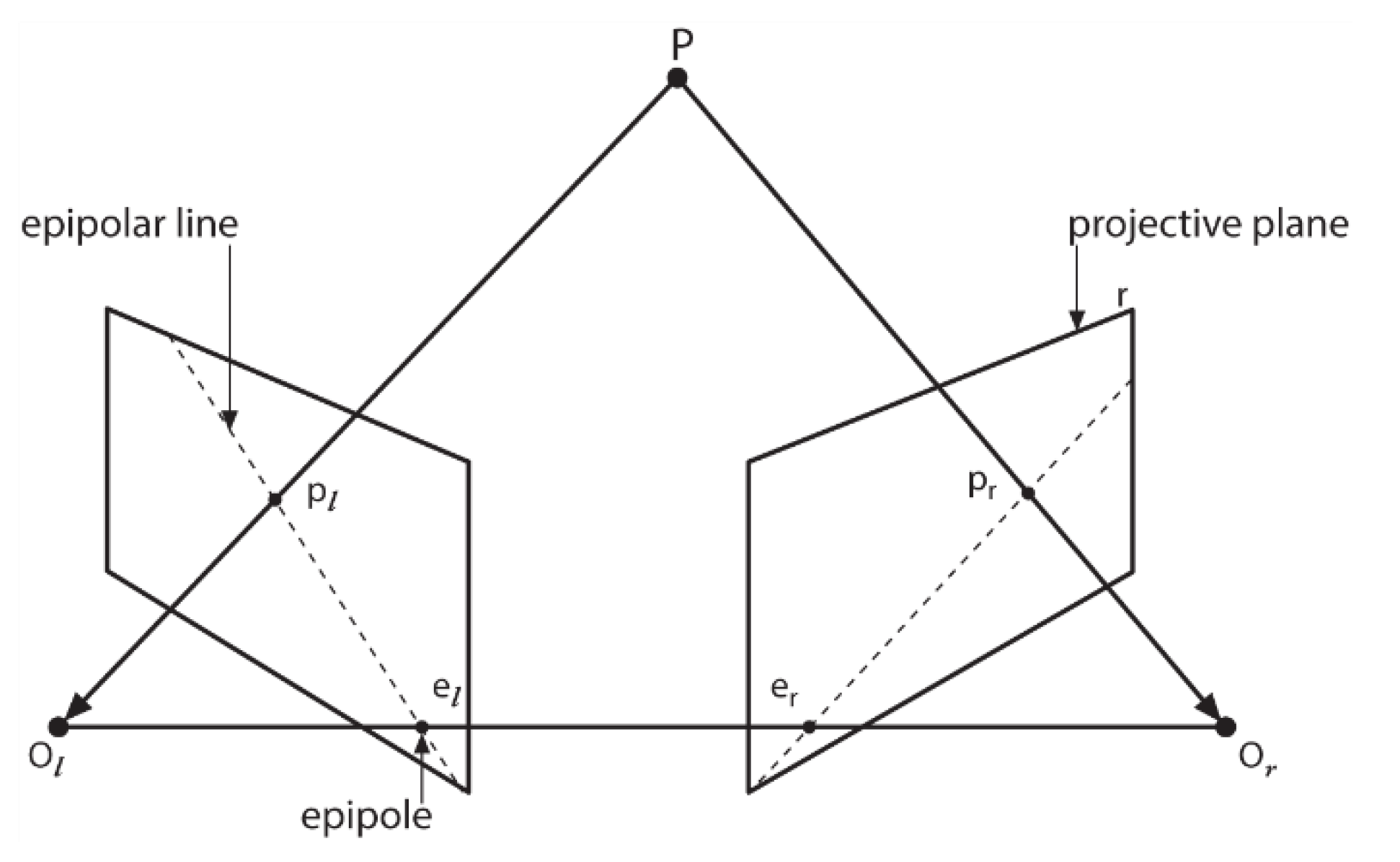
3. Method of 3D Reconstruction Using a Bionic Compound-Eye System
3.1. Traditional Method
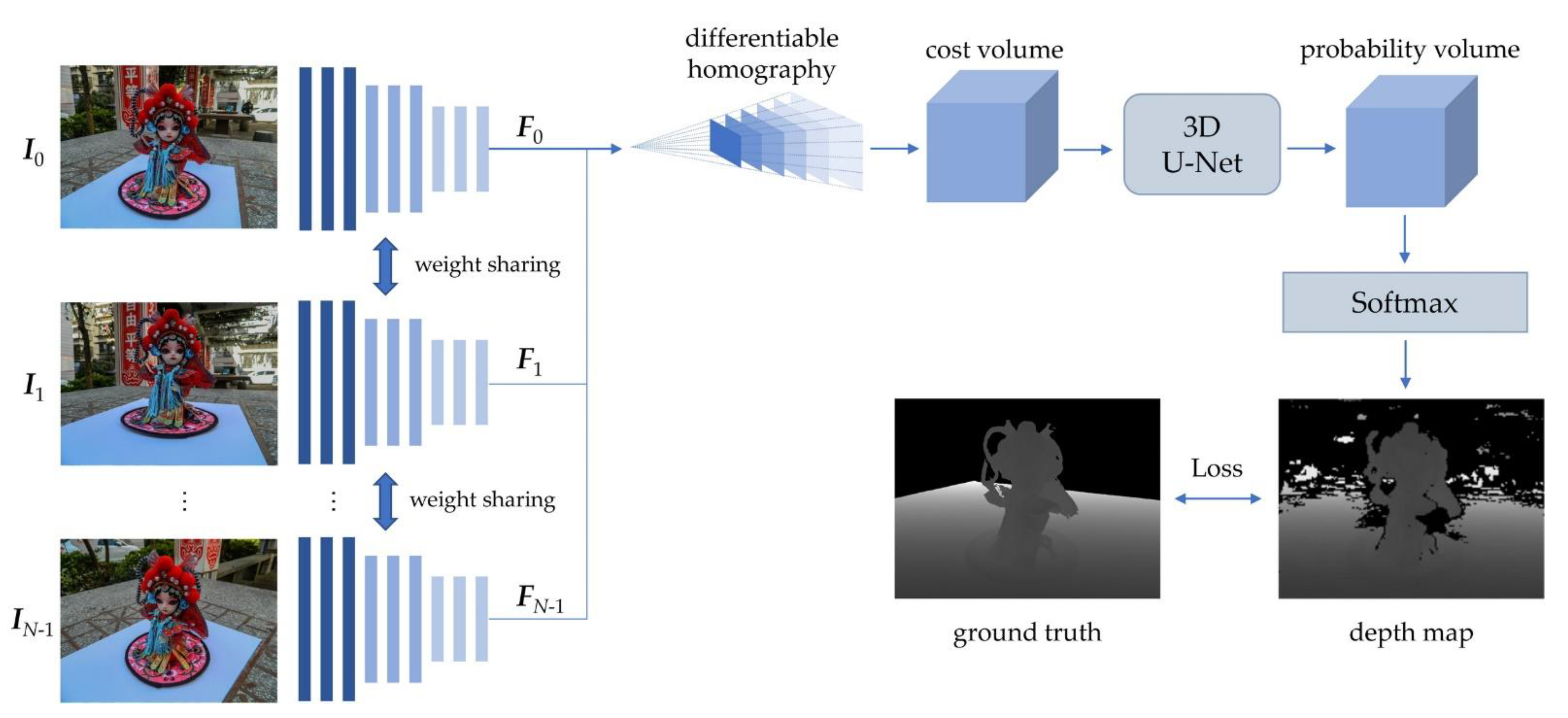
3.2. CES-MVSNet: Method of 3D Reconstruction Using a Nine-Eye Bionic Compound-Eye System
3.2.1. Feature Extraction
3.2.2. Build Cost Volume
3.2.3. Depth Map Estimation
3.2.4. Loss Function
4. Experiments
4.1. System and Scene
4.2. Training
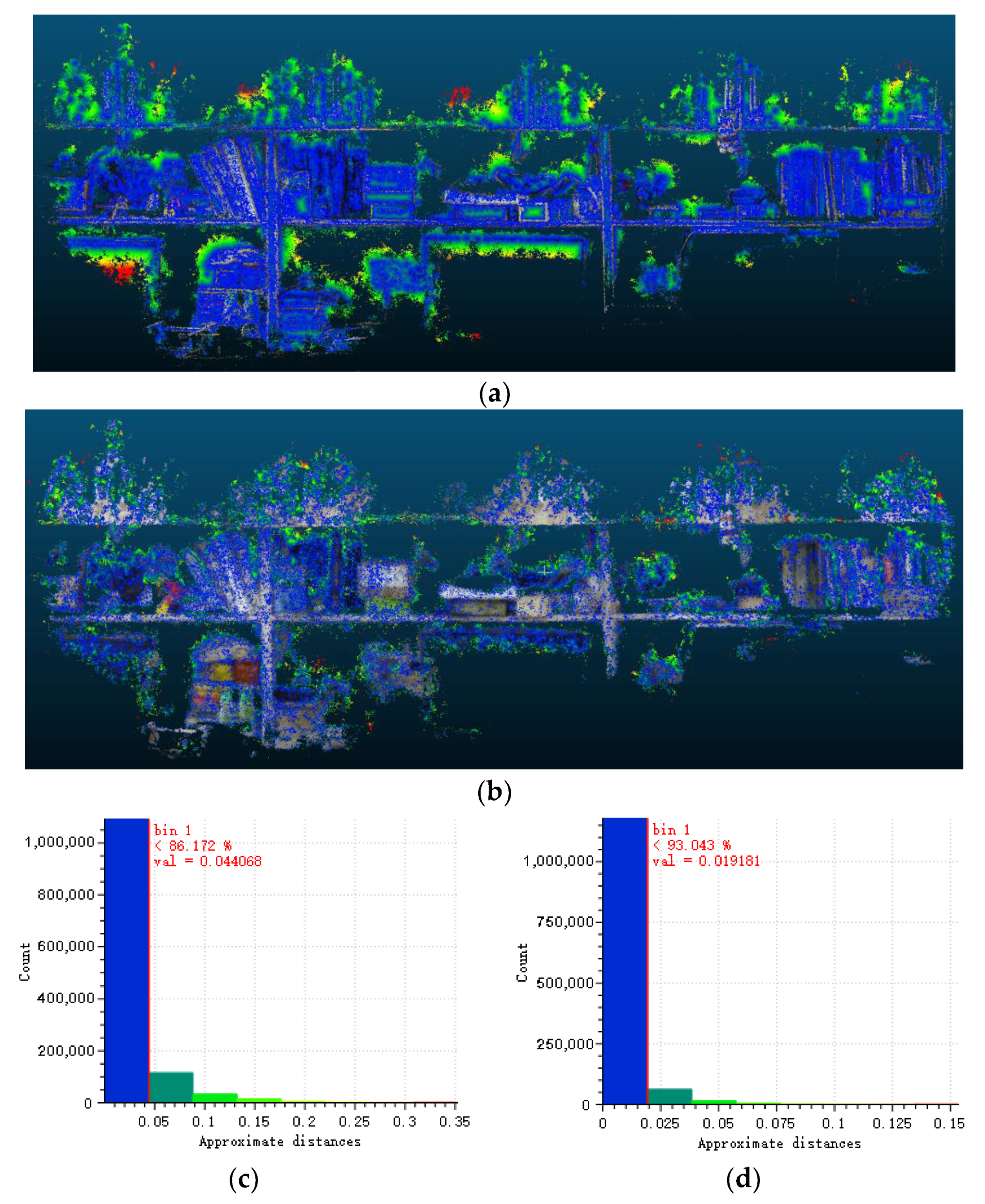
4.3. Experiment with Compound-Eye System and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Arie-Nachimson, M.; Kovalsky, S.Z.; Kemelmacher-Shlizerman, I.; Singer, A.; Basri, R. Global Motion Estimation from Point Matches. In Proceedings of the 2012 Second International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 81–88. [Google Scholar]
- Shah, R.; Deshpande, A.; Narayanan, P.J. Multistage SFM: A Coarse-to-Fine Approach for 3D Reconstruction. arXiv 2015, arXiv:1512.06235. [Google Scholar]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Photo Tourism: Exploring image collections in 3D. ACM Trans. Graph. 2006, 25, 835–846. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Chen, Y.; Chan, A.B.; Lin, Z.; Suzuki, K.; Wang, G. Efficient tree-structured SfM by RANSAC generalized Procrustes analysis. Comput. Vis. Image Underst. 2017, 157, 179–189. [Google Scholar] [CrossRef]
- Cui, H.; Gao, X.; Shen, S.; Hu, Z. HSfM: Hybrid Structure-from-Motion. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2393–2402. [Google Scholar]
- Zhu, S.; Zhang, R.; Zhou, L.; Shen, T.; Fang, T.; Tian, P.; Quan, L. Very Large-Scale Global SfM by Distributed Motion Averaging. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4568–4577. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth Map Prediction from a Single Image using a Multi-Scale Deep Network. In Proceedings of the 27th International Conference on Neural Information Processing System (NIPS), Montreal, QC, Canada, 8–13 December 2014; Volume 2, pp. 2366–2374. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. MVSNet: Depth Inference for Unstructured Multi-view Stereo. Lect. Notes Comput. Sci. 2018, 8, 785–801. [Google Scholar]
- Chen, R.; Han, S.; Xu, J.; Su, H. Point-Based Multi-View Stereo Network. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1538–1547. [Google Scholar]
- Yi, H.; Wei, Z.; Ding, M.; Zhang, R.; Chen, Y.; Wang, G.; Tai, Y. Pyramid multi-view stereo net with self-adaptive view aggregation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 766–782. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; Quan, L. Recurrent mvsnet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5525–5534. [Google Scholar]
- Yan, J.; Wei, Z.; Yi, H.; Ding, M.; Zhang, R.; Chen, Y.; Wang, G.; Tai, Y. Dense hybrid recurrent multi-view stereo net with dynamic consistency checking. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 674–689. [Google Scholar]
- Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; Tan, P. Cascade cost volume for high-resolution multi-view stereo and stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2495–2504. [Google Scholar]
- Cheng, S.; Xu, Z.; Zhu, S.; Li, Z.; Li, E.; Ramamoorthi, R.; Su, H. Deep stereo using adaptive thin volume representation with uncertainty awareness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2524–2534. [Google Scholar]
- Goldman, D.B.; Chen, J. Vignette and Exposure Calibration and Compensation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 2276–2288. [Google Scholar] [CrossRef] [PubMed]
- Lopez-Fuentes, L.; Oliver, G.; Massanet, S. Revisiting Image Vignetting Correction by Constrained Minimization of Log-Intensity Entropy. Adv. Comput. Intell. 2015, 9095, 450–463. [Google Scholar]
- Rohlfing, T. Single-Image Vignetting Correction by Constrained Minimization of log-Intensity Entropy. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2012; pp. 450–463. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2003; pp. 239–241. [Google Scholar]
- Zhang, Z. A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Nister, D. An efficient solution to the five-point relative pose problem. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 756–770. [Google Scholar] [CrossRef] [PubMed]
- Snavely, N.; Simon, I.; Goesele, M.; Szeliski, R.; Seitz, S. Scene Reconstruction and Visualization from Internet Photo Collections. IPSJ Trans. Comput. Vis. Appl. 2011, 3, 1370–1390. [Google Scholar] [CrossRef] [Green Version]
- Wu, C. Towards Linear-Time Incremental Structure from Motion. In Proceedings of the 2013 International Conference on 3DV-Conference, Seattle, WA, USA, 29 June–1 July 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 127–134. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016; Springer: Cham, Switzerland, 2016; Volume 9901, pp. 424–432. [Google Scholar]
- Luo, K.; Guan, T.; Ju, L.; Huang, H.; Luo, Y. P-MVSNet: Learning Patch-Wise Matching Confidence Aggregation for Multi-View Stereo. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 10451–10460. [Google Scholar]
- Galliani, S.; Lasinger, K.; Schindler, K. Massively Parallel Multiview Stereopsis by Surface Normal Diffusion. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 873–881. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Zhang, J.; Ren, Y.; Zhou, L.; Fang, T.; Quan, L. BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Networks. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1790–1799. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Layer | Output | Output Size |
|---|---|---|---|
| Ii | Conv2D + BN + ReLU, K = 3 × 3, S = 1, F = 8 | 2D_0 | H × W × 8 |
| 2D_0 | Conv2D + BN + ReLU, K = 3 × 3, S = 1, F = 8 | 2D_1 | H × W × 8 |
| 2D_1 | Conv2D + BN + ReLU, K = 5 × 5, S = 2, F = 16 | 2D_2 | ½H × ½W × 16 |
| 2D_2 | Conv2D + BN+ReLU, K = 3 × 3, S = 1, F = 16 | 2D_3 | ½H × ½W × 16 |
| 2D_3 | Conv2D + BN + ReLU, K = 3 × 3, S = 1, F = 16 | 2D_4 | ½H × ½W × 16 |
| 2D_4 | Conv2D + BN + ReLU, K = 5 × 5, S = 2, F = 32 | 2D_5 | ¼H × ¼W × 32 |
| 2D_5 | Conv2D + BN + ReLU, K = 3 × 3, S = 1, F = 32 | 2D_6 | ¼H × ¼W × 32 |
| 2D_6 | Conv2D + BN + ReLU, K = 3 × 3, S = 1, F = 32 | 2D_7 | ¼H × ¼W × 32 |
| 2D_7 | Conv2D + BN + ReLU, K = 3 × 3, S = 1, F = 32 | Fi | ¼H × ¼W × 32 |
| Input | Layer | Output | Output Size |
|---|---|---|---|
| C | Conv3D + BN + ReLU, K = 3 × 3 × 1, S = 1, F = 8 | 3D_0 | ¼H × ¼W × D × 8 |
| 3D_0 | Conv3D + BN + ReLU, K = 1 × 1 × 7, S = 2, F = 16 | 3D_1 | ⅛H × ⅛W × ½D × 16 |
| 3D_1 | Conv3D + BN + ReLU, K = 5 × 5 × 1, S = 1, F = 16 | 3D_2 | ⅛H × ⅛W × ½D × 16 |
| 3D_2 | Conv3D + BN + ReLU, K = 1 × 1 × 7, S = 2, F = 32 | 3D_3 | 1/16H × 1/16W × ¼D × 32 |
| 3D_3 | Conv3D + BN + ReLU, K = 3 × 3 × 1, S = 1, F = 32 | 3D_4 | 1/16H × 1/16W × ¼D × 32 |
| 3D_4 | Conv3D + BN + ReLU, K = 1 × 1 × 7, S = 2, F = 64 | 3D_5 | 1/32H × 1/32W × ⅛D × 64 |
| 3D_5 | Conv3D + BN + ReLU, K = 3 × 3 × 3, S = 1, F = 64 | 3D_6 | 1/32H × 1/32W × ⅛D × 64 |
| 3D_6 | Deconv3D + BN + ReLU, K = 3 × 3 × 3, S = 2, F = 32 | 3D_7 | 1/16H × 1/16W × ¼D × 32 |
| 3D_7 + 3D_4 | Addition | 3D_8 | 1/16H × 1/16W × ¼D × 32 |
| 3D_8 | Deconv3D + BN + ReLU, K = 1 × 1 × 7, S = 2, F = 16 | 3D_9 | ⅛H × ⅛W × ½D × 16 |
| 3D_9 + 3D_2 | Addition | 3D_10 | ⅛H × ⅛W × ½D × 16 |
| 3D_10 | Deconv3D + BN + ReLU, K = 3 × 3 × 1, S = 2, F = 16 | 3D_11 | ¼H × ¼W × D × 8 |
| 3D_11 + 3D_0 | Addition | 3D_12 | ¼H × ¼W × D × 8 |
| 3D_12 | Conv3D, K = 3 × 3 × 3, S = 1, F = 1 | P | ¼H × ¼W × D |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, X.; Qiu, S.; Jin, W.; Xue, J. Three-Dimensional Reconstruction Method for Bionic Compound-Eye System Based on MVSNet Network. Electronics 2022, 11, 1790. https://doi.org/10.3390/electronics11111790
Deng X, Qiu S, Jin W, Xue J. Three-Dimensional Reconstruction Method for Bionic Compound-Eye System Based on MVSNet Network. Electronics. 2022; 11(11):1790. https://doi.org/10.3390/electronics11111790
Chicago/Turabian StyleDeng, Xinpeng, Su Qiu, Weiqi Jin, and Jiaan Xue. 2022. "Three-Dimensional Reconstruction Method for Bionic Compound-Eye System Based on MVSNet Network" Electronics 11, no. 11: 1790. https://doi.org/10.3390/electronics11111790