1. Introduction
Sustainable urban mobility is one of the most distinct characteristics of Smart Cities. Specifically, intelligent public urban transport planning plays an important role in the design of the future cities and in the sustainable development of the environment (in this sense, it has become one of the most powerful tools in the fight against air pollution in cities); moreover, it is well known that efficient mass transit systems have a highly beneficial impact on economic development and social integration. Particularly, the subway is the best choice in big cities since it exhibits many advantages including reducing traffic congestion, saving energy and non-renewable resources, reducing the number of traffic accidents and therefore deaths, large capacity, time reliability, etc. [
1].
Hundreds of millions of passengers commute in public transport daily in large cities, hence failures in the network can cause major problems to commuters and business activities with significant economic and social losses. In addition, the COVID-19 pandemic has changed the security measures on the transport network in order to maintain the sanitary requirements. Proper social distancing between passengers is hard to ensure in public transport if it is not well planned (taking into account the different characteristics of the different stations and lines). To avoid overcrowded stations and trains, it is crucial to know transit trip patterns. This will also allow better network planning, demand forecasting and, ultimately, a more effective use of the available resources in general.
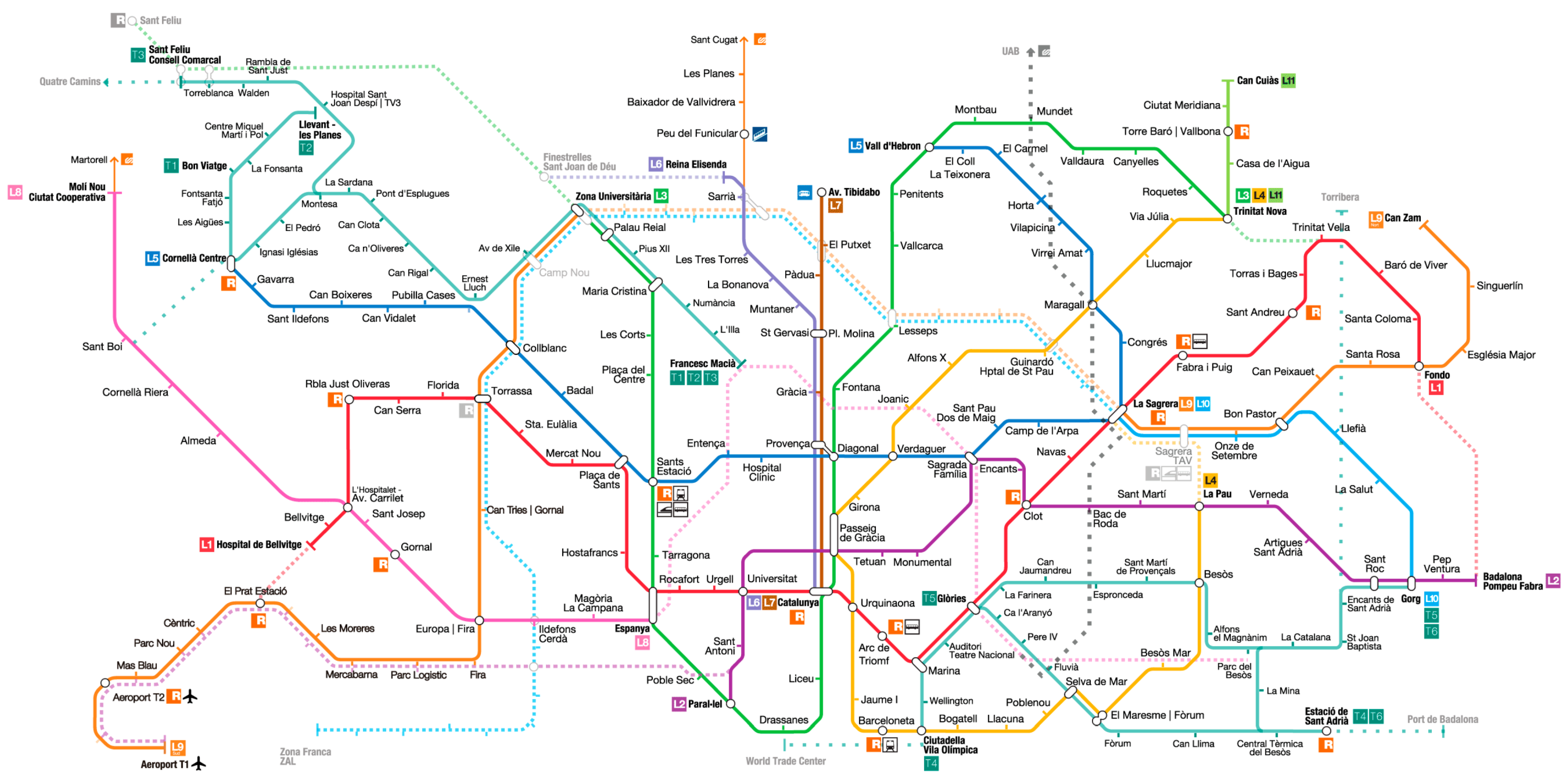
Two main goals are addressed in this work: (1) study the structural and robustness characteristics of Barcelona subway network; and (2) identify ridership patterns at its stations. In the first case, the basic techniques of Complex Network Analysis are used (centrality measures, structural indices, robustness coefficients, etc.), whereas, in the second case, a hierarchical cluster analysis is performed to group stations according to their boarding patterns. Barcelona’s metro is Spain’s second largest city subway system: there are a total of 13 lines and 151 stations in the network. Its length is 119 km, and during 2018 more than 400 million people used it.
In recent years, the complex network approach has been used to analyze the subway rail networks of several cities around the world. Since 2002, when Latora and Marchiori studied the topological properties of the Boston subway [
2], many other works have appeared. Lu and Shi found that the public transportation network in China had scale-free and small world characteristics [
3]. Zhang et al. studied the topological characteristics of some subway networks around the world and investigated network failures to discuss the vulnerability of these subway networks [
4]. Liu and Song [
5] studied the topology of Guangzhou subway network using L-space method, and the value and distribution of the network’s degree, clustering coefficient and average shortest path length were computed and analyzed. Cats [
6] conducted a longitudinal analysis of the topological evolution of a multimodal rail network by investigating the dynamics of its topology for the case of Stockholm during 1950–2025.
The robustness of subway networks has also been discussed by many other researches. For example, Derrible and Kennedy studied the complexity and robustness of 33 metro networks [
7]. Using network science and graph theory, ten theoretical and four numerical robustness metrics and their performance in quantifying the robustness of metro networks under random failures or targeted attacks were investigated by Wang et al. [
8]. Zhang et al. [
9] investigated the connectivity, robustness and reliability of the Shanghai subway network of China. Forero-Ortiz et al. [
10] gave insights for stakeholders and policymakers to enhance urban flood risk management, as a reasonable approach to tackle this issue for Metro systems worldwide. De Bona et al. [
11] proposed a novel methodology called Reduced Model as a simple method of network reduction that preserves the network skeleton (backbone structure) by properly removing 2-degree nodes of weighted and unweighted network representations. In [
12], a new perspective for understanding vulnerability of metro networks is shown with the aims of improving operation reliability and stability of the network, designing emergency strategies to protect the network, etc.
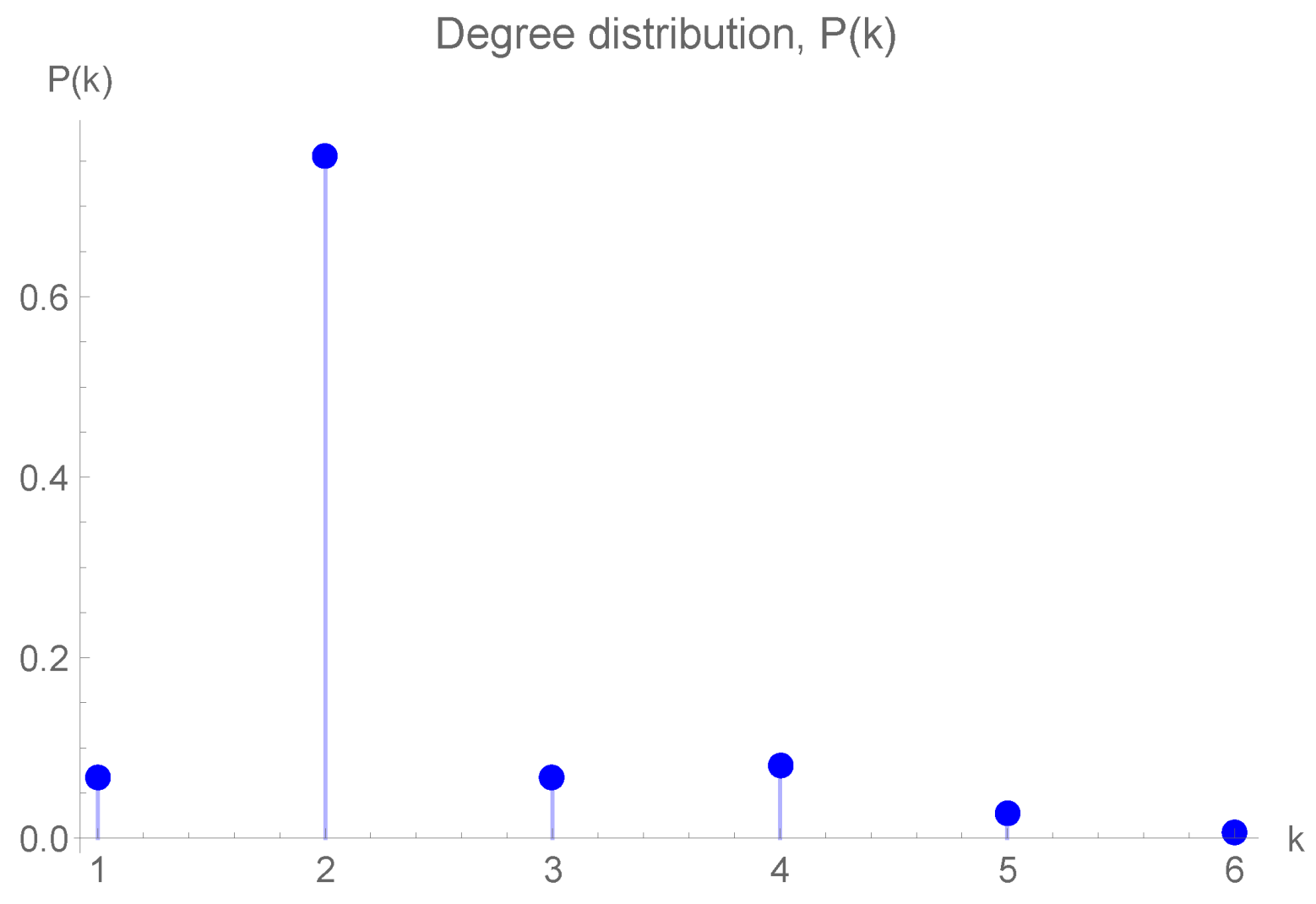
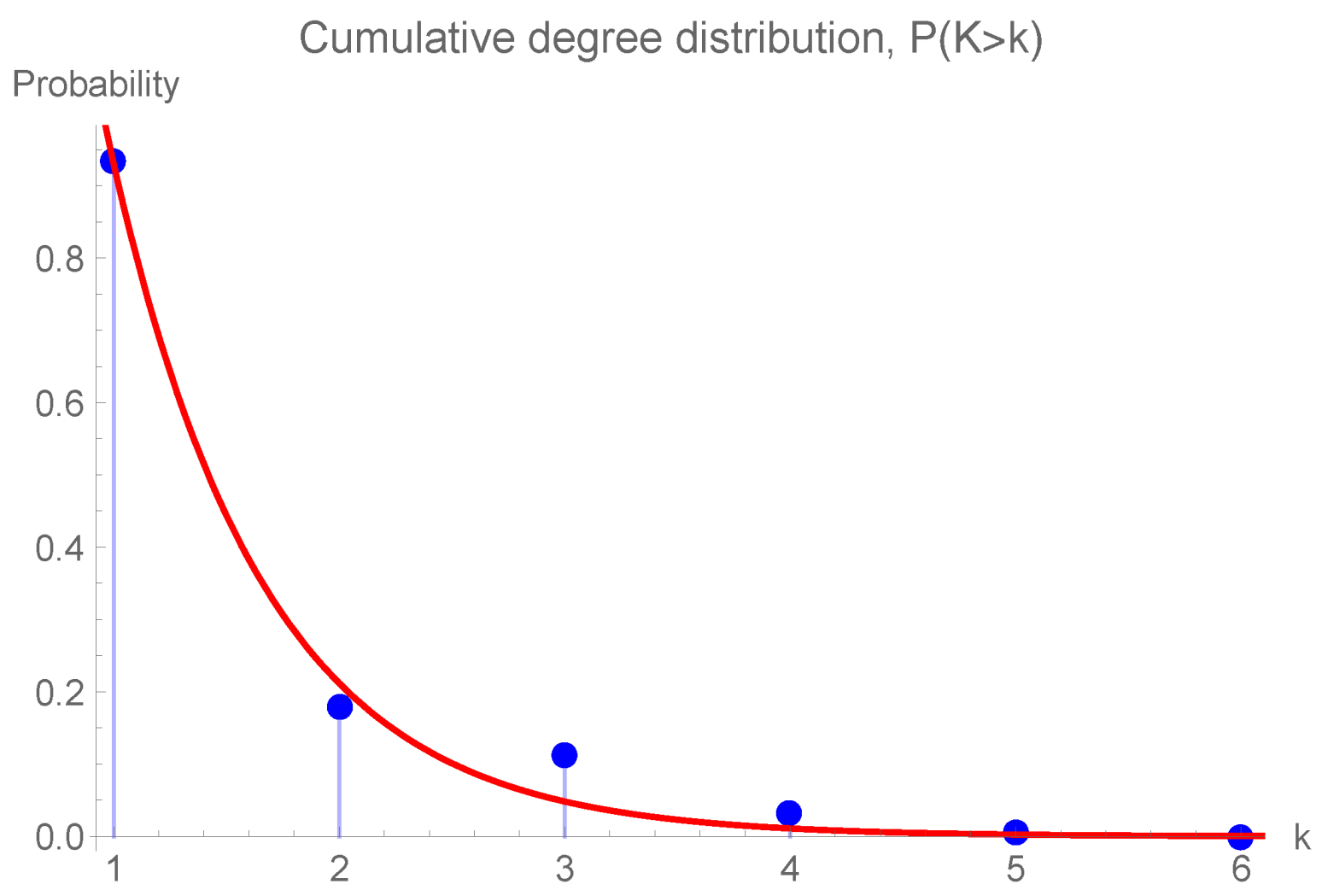
In this work, the topological characteristics of the metro network are investigated considering the complex network approach. Specifically a brief analysis of the Barcelona subway network is provided from the computation of the most important centrality measures: (i) degree centrality ; (ii) average degree ; (iii) degree distribution ; (iv) average path length L; (v) closeness centrality ; and (vi) betweenness centrality . In addition, to assess the robustness of the subway network, eight theoretical robustness metrics are investigated: (i) normalized robustness indicator ; (ii) effective graph conductance ; (iii) average efficiency ; (iv) clustering coefficient ; (v) normalized algebraic connectivity ; (vi) average degree , (vii) normalized natural connectivity ; and (viii) degree diversity .
Most public transit networks use automated fare collection (AFC) systems. The interest in this kind of technology is because it is perceived as a secure method of user validation and fare payment. Moreover, it improves the quality of the data, gives transit a more modern look and provides new opportunities for innovative and flexible fare structuring [
13]. While the main purpose of AFC systems is to collect revenue, they also produce very large quantities of very detailed data of on-board transactions. These data are very useful to transit planners, from the day-to-day operation of the transit system to the strategic long-term planning of the network [
14].
AFC systems are classified into two types according to the fare charge mode of transit: flat-rate fare systems and distance-based fare systems. In flat-rate fare systems, only entry swipes are registered, while, in distance-based fare systems, entry and exit swipes are registered. Barcelona metro uses a flat-rate fare system, therefore only metro boarding is available in this study. This has the inconvenience of not knowing where the passenger’s journey ends, e.g., the trip’s purpose. The destination of the trip helps understand peak hours. For instance, most of the work and education trips start in the morning peak from home and return back to home in the evening peak. While not within the scope of this paper, the destination estimation of public transport is one of the major concerns for the implementation of smart card data and there exist several approaches (see, e.g., [
15,
16,
17,
18]).
Every day, depending on the size of the network, millions of transactions are registered by the AFC systems, which can be used to analyze human mobility. It has been determined that human trajectories and trips generated with human mobility show a high degree of temporal and spatial regularity [
19]. Passenger flow of the urban subway varies according to time and space, including working days, holidays, seasons, residential areas, business centers, workplaces and other factors such as weather, as well as other forms of transportation that connect to the subway network. In this regard, several methods have been developed in the literature for this type of analysis, most using clustering approaches [
20].
Two viewpoints can be considered when a cluster analysis using smart card data is performed. The first one clusters stations based on the temporal-spatial distribution characteristics of subway ridership. The second one identifies groups of passengers that have similar boarding times aggregated into weekly profiles [
21].
From the first point of view, Chen et al. [
22] studied the diurnal pattern of subway ridership in New York City using the k-means algorithm. Wang et al. [
23] analyzed eight metro stations in the central area of Hong Kong using the hierarchical cluster analysis. The k-means algorithm was also employed by Kim et al. [
24] to identify the daily travel patterns at subway stations of Seoul Capital Area. Ding et al. [
25] applied gradient boosting decision trees to investigate the non-linear effects of built environment variables on station boarding in the Washington metropolitan area. Langlois et al. [
26] proposed a longitudinal representation of user’s multi-week activity and identified 11 travel patterns from London’s public transport network.
The study and analysis of different characteristics of subway networks have been tackled by means of other different paradigms. For example, risk analysis has been addressed in some recent works (see, e.g., [
10,
27,
28,
29]), the GIS-based technologies improves the analysis performed using mathematical methods [
30], modern statistical and mathematical techniques can be also applied [
31,
32,
33,
34], the study of bus–metro transfers is considered in [
35,
36], etc. Moreover, techniques based on the Artificial Intelligence paradigm have also been used to study different aspects of subway networks (see, e.g., [
37,
38,
39]).
The rest of the paper is organized as follows.
Section 2 describes the data used in the study.
Section 3 is devoted to presenting the methodology used for the analysis of travel patterns. Finally, the results obtained and the discussion are presented in
Section 4 and the conclusions in
Section 5.
5. Conclusions
In Barcelona, as in any major urban area, many people use the public transport network, which is why it is necessary to have as much information as possible to forecast and plan the subway trip.
Moreover, in the bibliography studied, there are no previous studies that analyze not only the structural and robustness characteristics but also travel patterns of the Barcelona metro network.
In this study, a detailed analysis of Barcelona subway network was done using Complex Network Analysis. To achieve this goal, the most important centrality measures and coefficients were computed. In this sense, the important role of stations such as “Diagonal” and “Verdaguer” to control the flow of passengers was shown. It was also shown that the stations “Catalunya”, “Universitat”, “Urquinaona” and “Passeig de Gràcia” have high fault tolerance in a local scale. Moreover, L5 and L3 are the most central subway lines.
In addition, the robustness of the Barcelona subway network was investigated by analyzing several robustness metrics and compared with the robustness of the Madrid subway network. The results indicate that the Barcelona subway network is slightly more robust than the Madrid subway network according to most of the robustness metrics. A previous study [
8] analyzed Barcelona subway robustness using ten theoretical robustness metrics, but only taking into account terminals and transfer stations. The results in the former study cannot be compared with ours since in our study all Barcelona subway stations are used.
The data collected at the entry of the metro stations in Barcelona provide a vast quantity of data with very valuable information about the ridership patterns in them. The set of real data was provided by the Barcelona Metropolitan Network, providing information on the number of entries per hour in each of the 151 stations. There are no data related to the passenger’s journey or personal data (age, sex, fare, etc.).
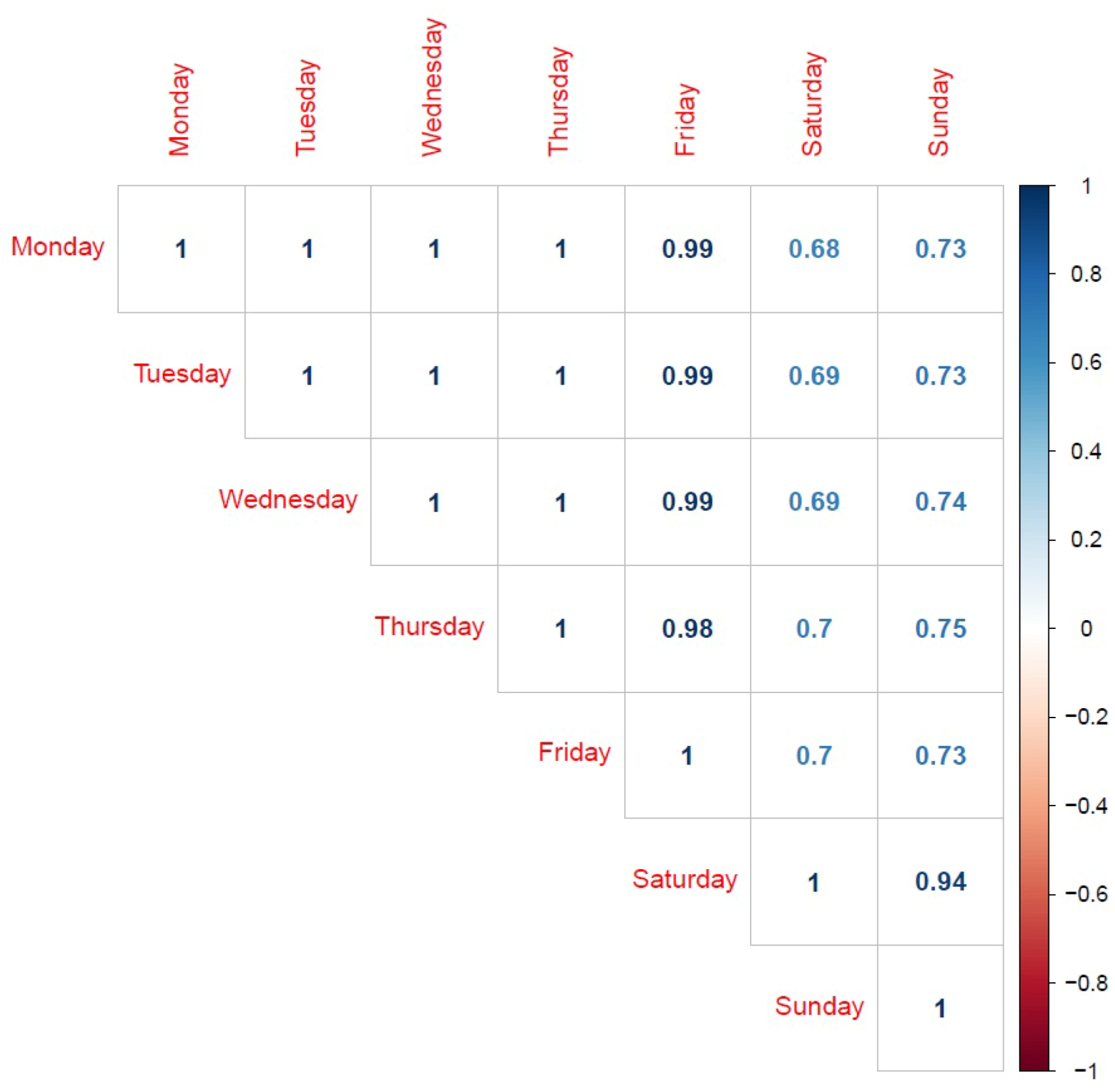
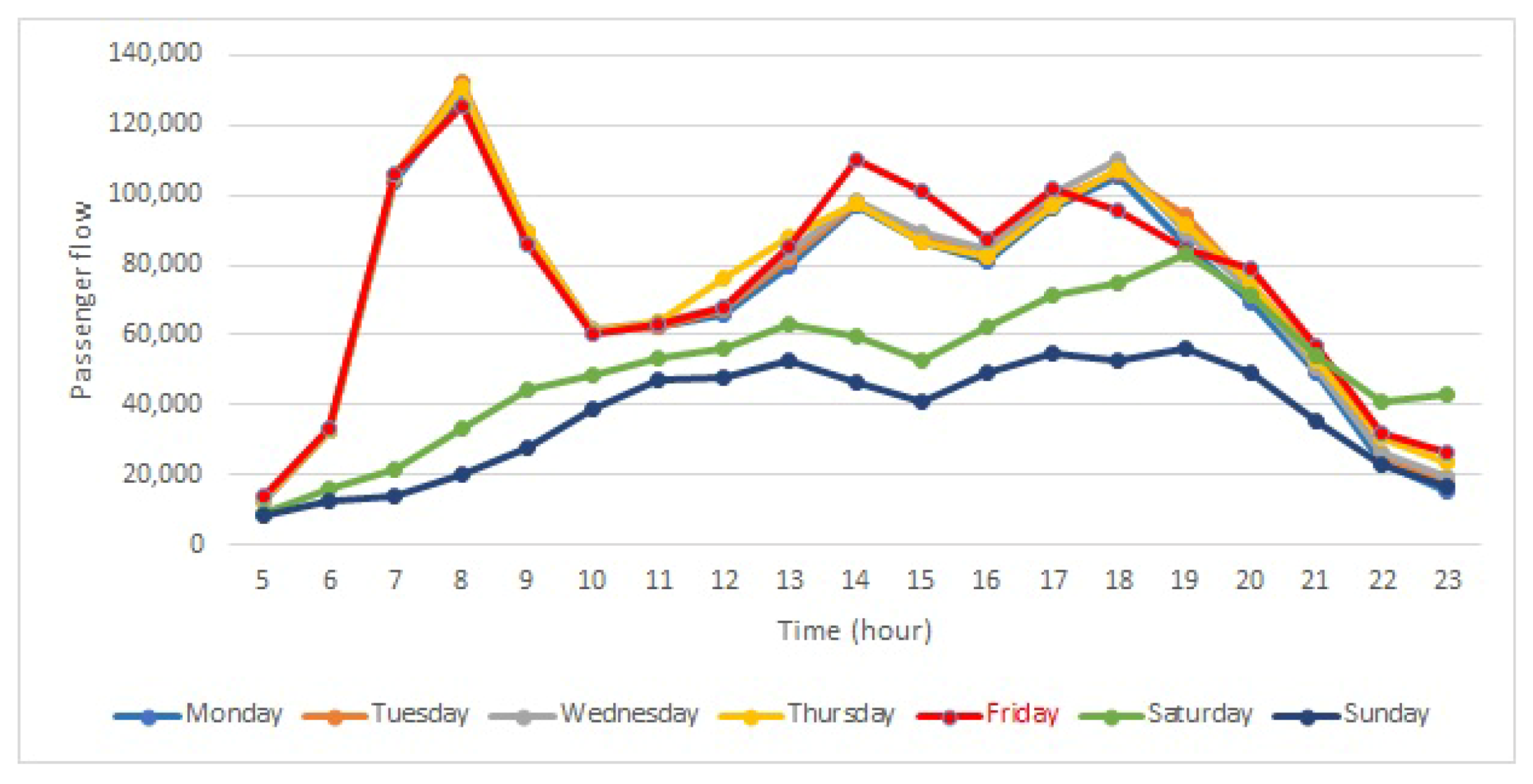
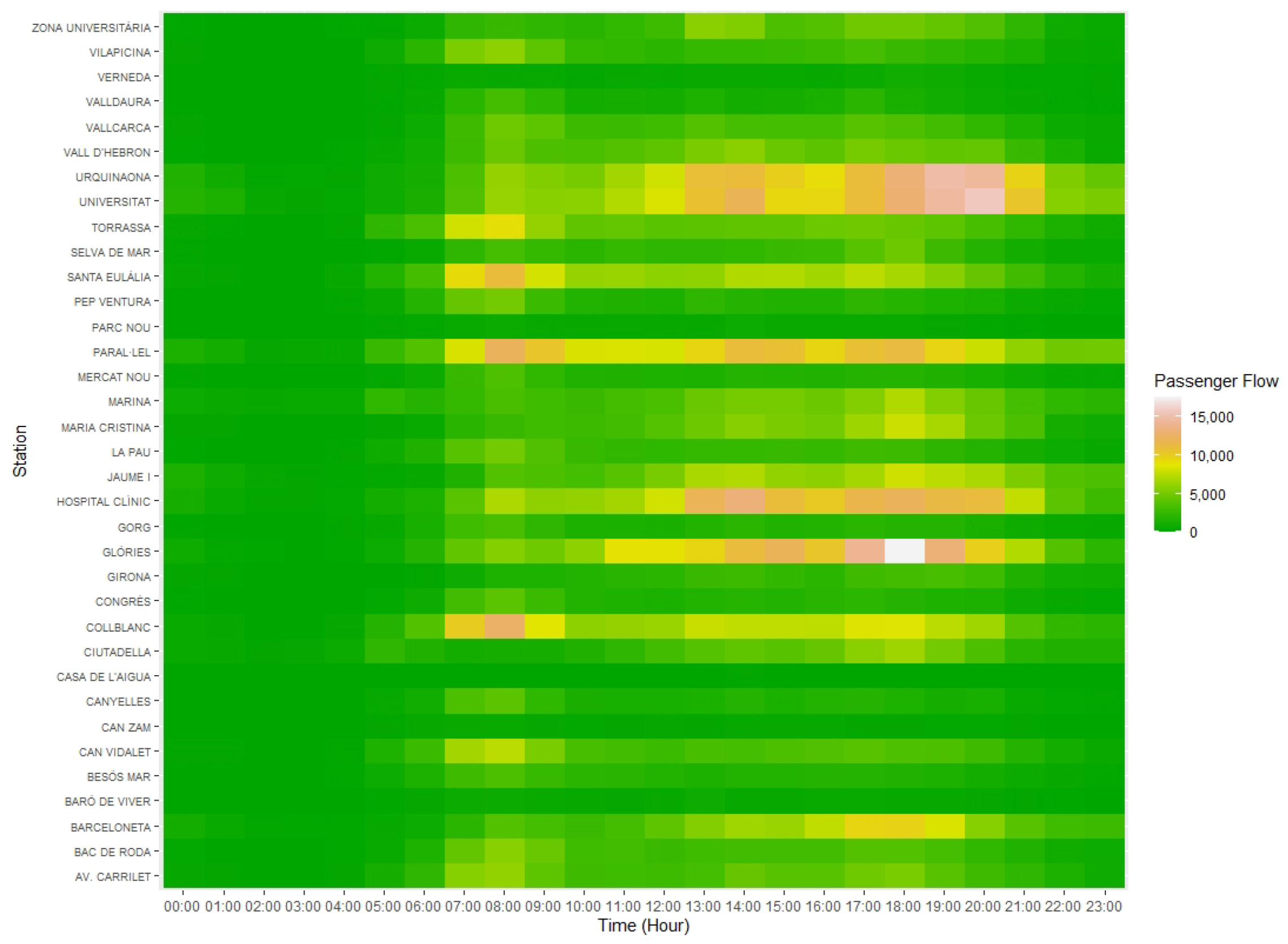
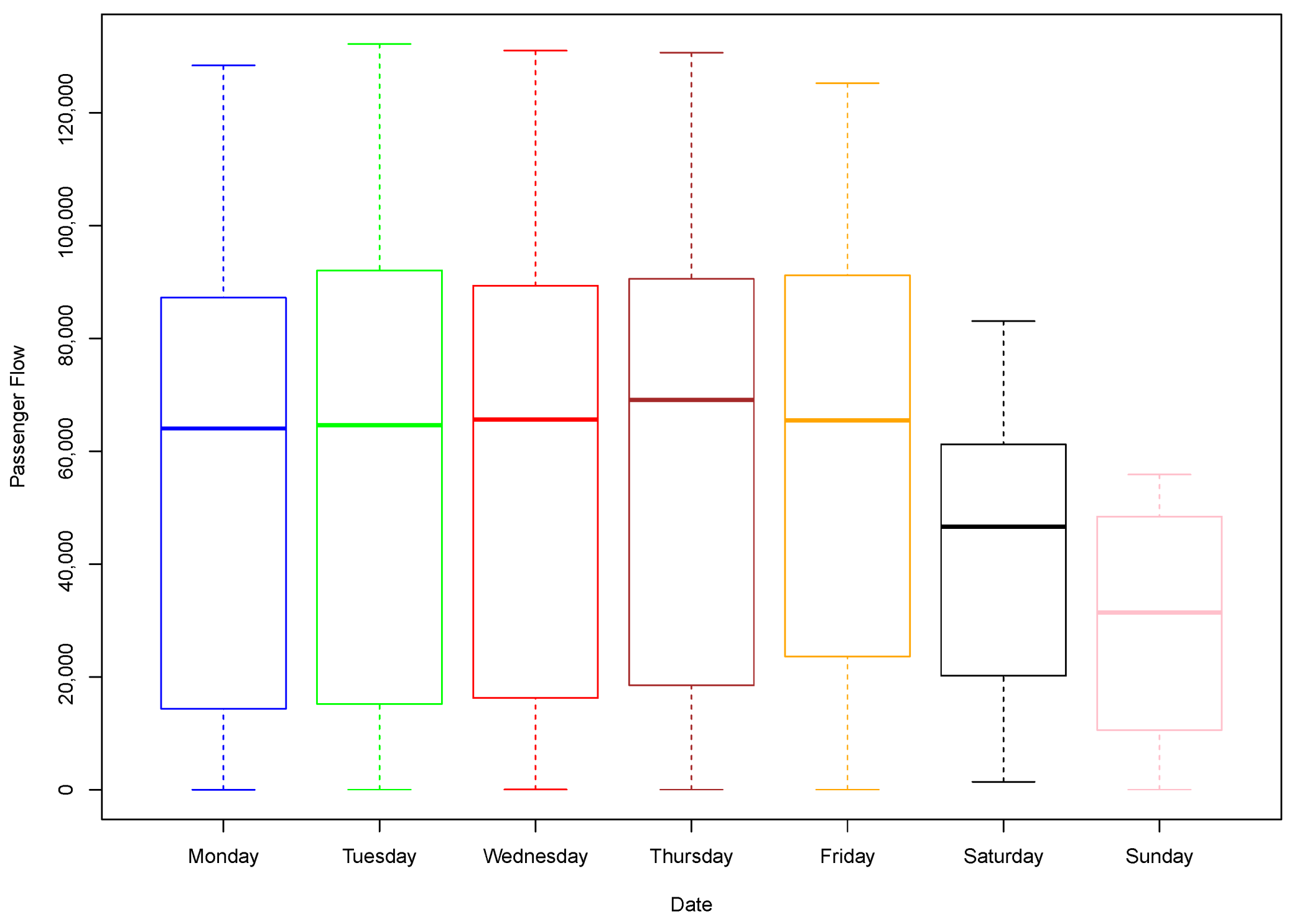
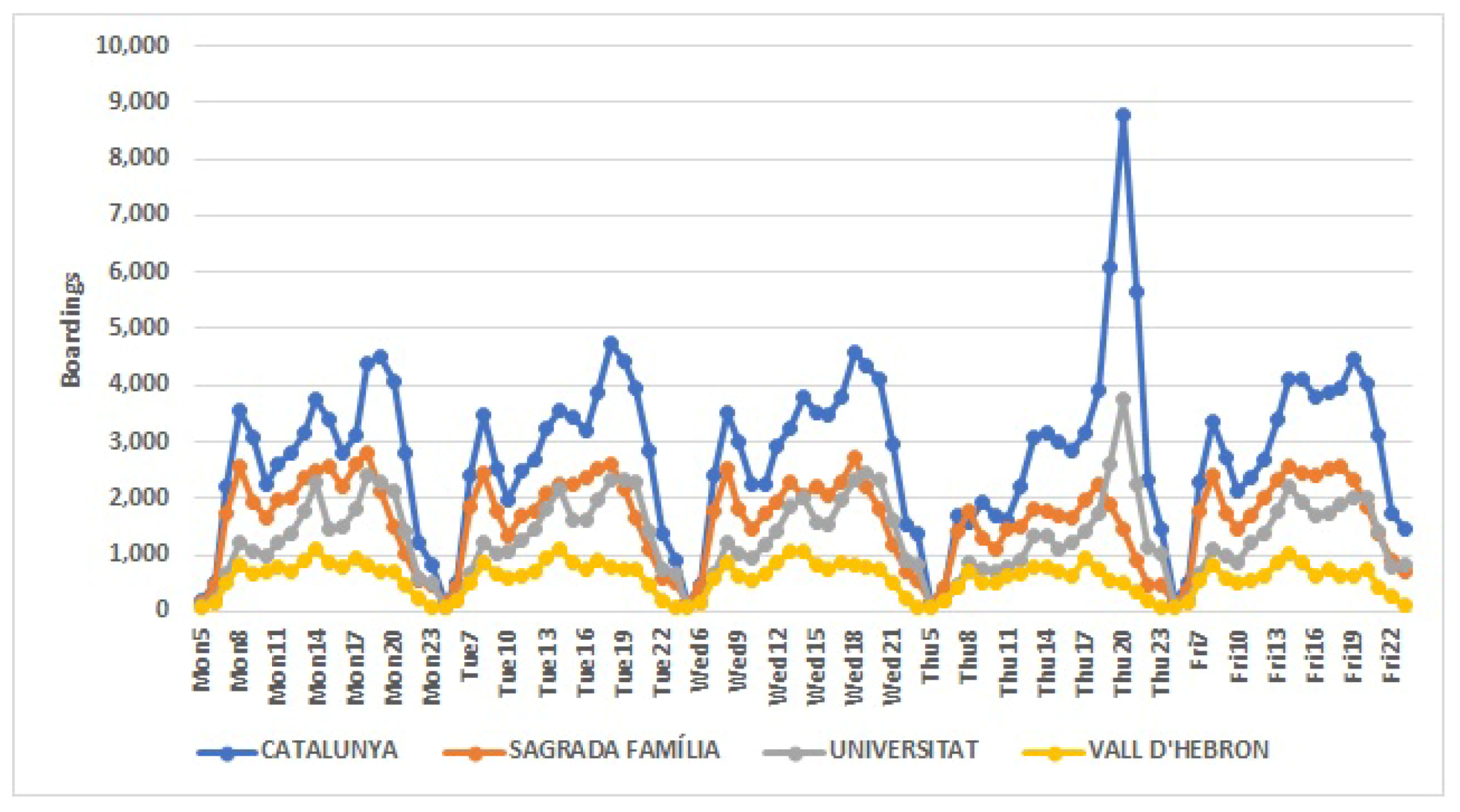
The statistical techniques used in this study allowed observing the following: in the first place, there are differences in behavior between working days, which are highly correlated with each other, and over the weekend, with which the correlation decreases. The hours with the highest number of passengers correspond mainly to the hours of entry and exit of work and school hours. However, these rush hours are not the same at all stations, nor are the number of passengers each have, reaching a difference of more than 54,000 daily entries between some stations. It is because of this reason that the data were normalized, using the proportion of passengers per hour with respect to the total number of entries in that particular day at each particular station.
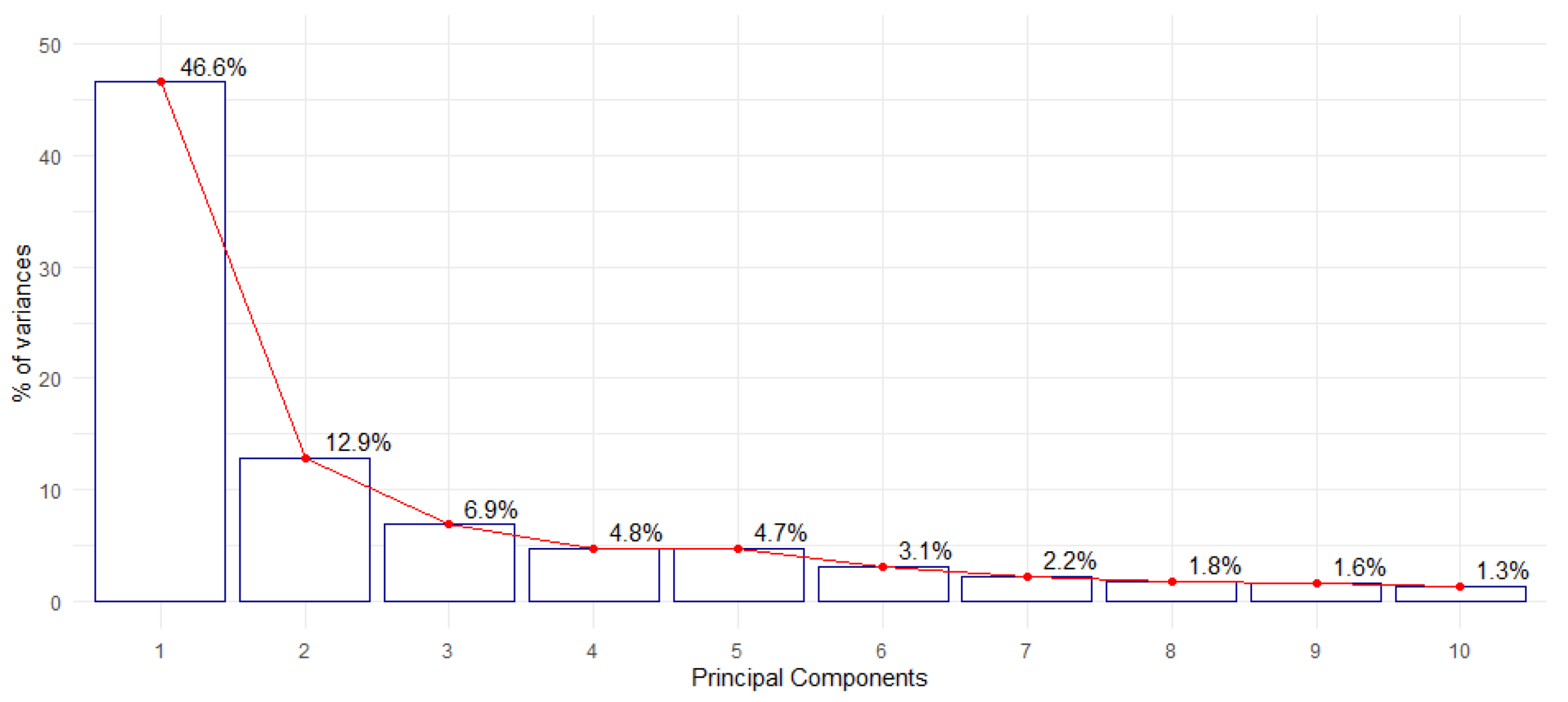
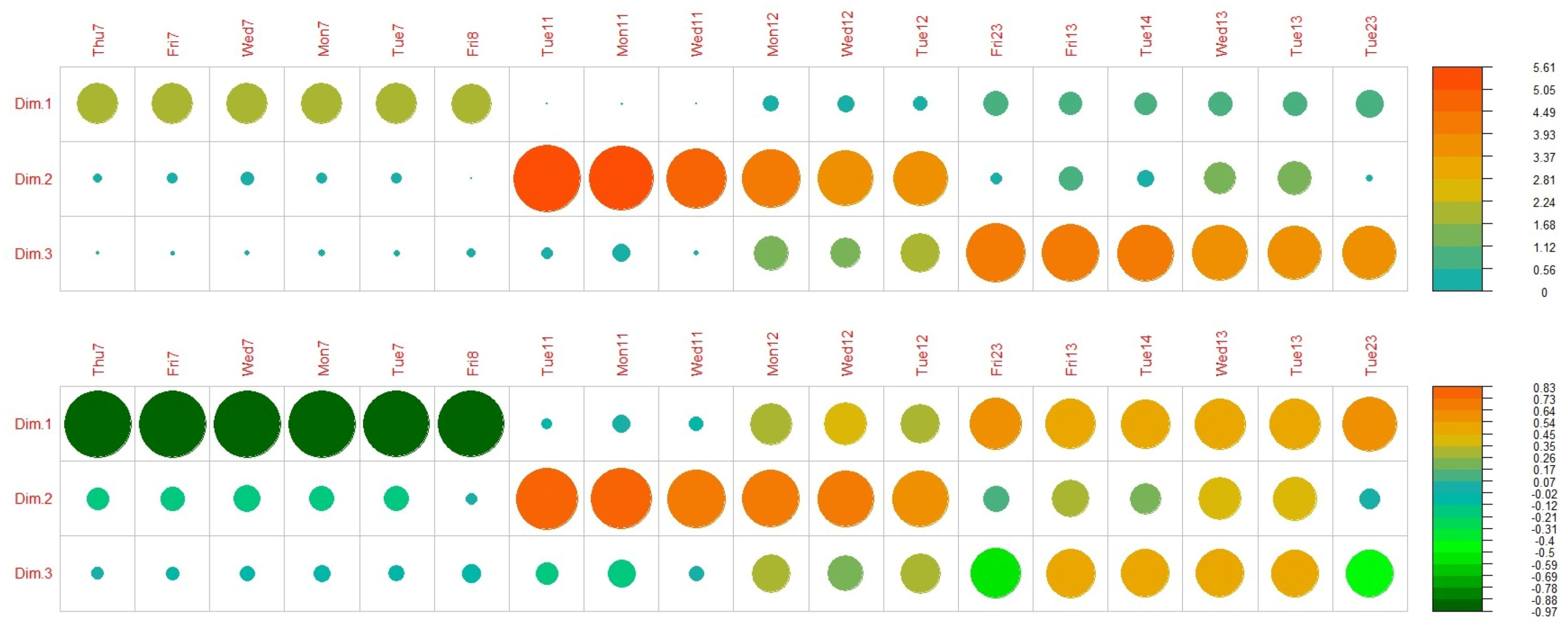
The principal component analysis performed reduced the dimensionality of the dataset. The first three principal components explain most of the variability in the data. Moreover, it was observed which hours have a higher effect in each of them.
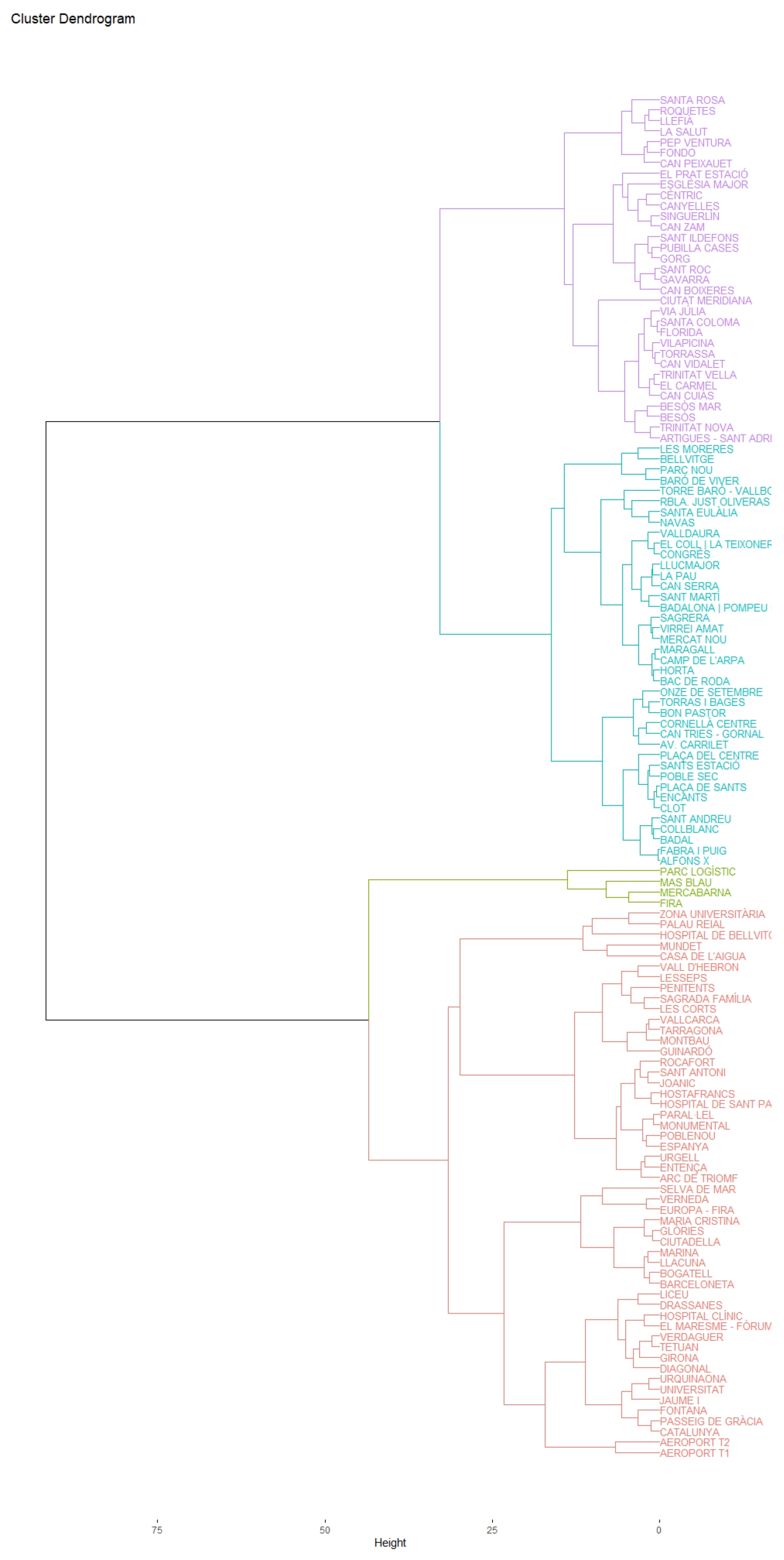
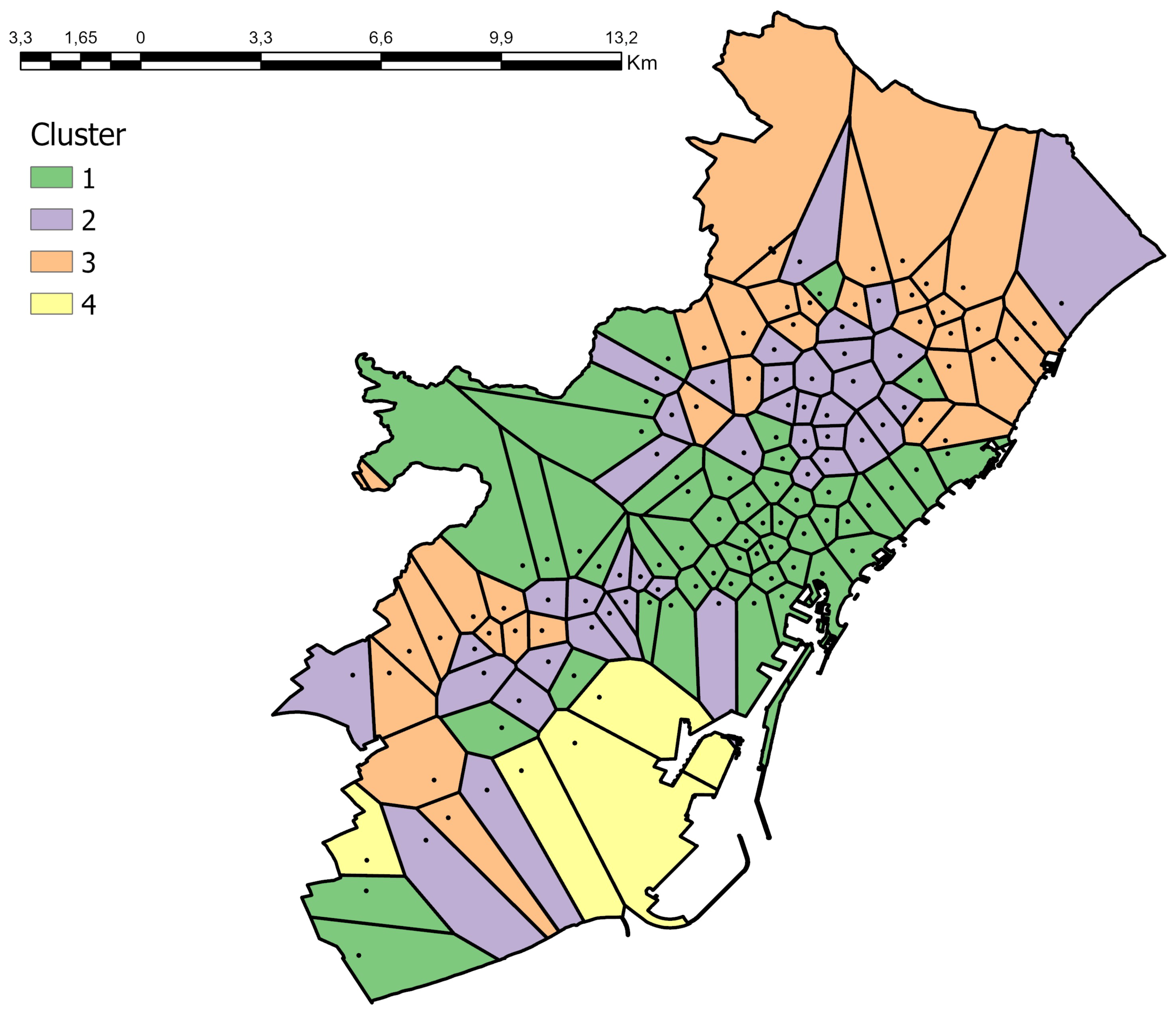
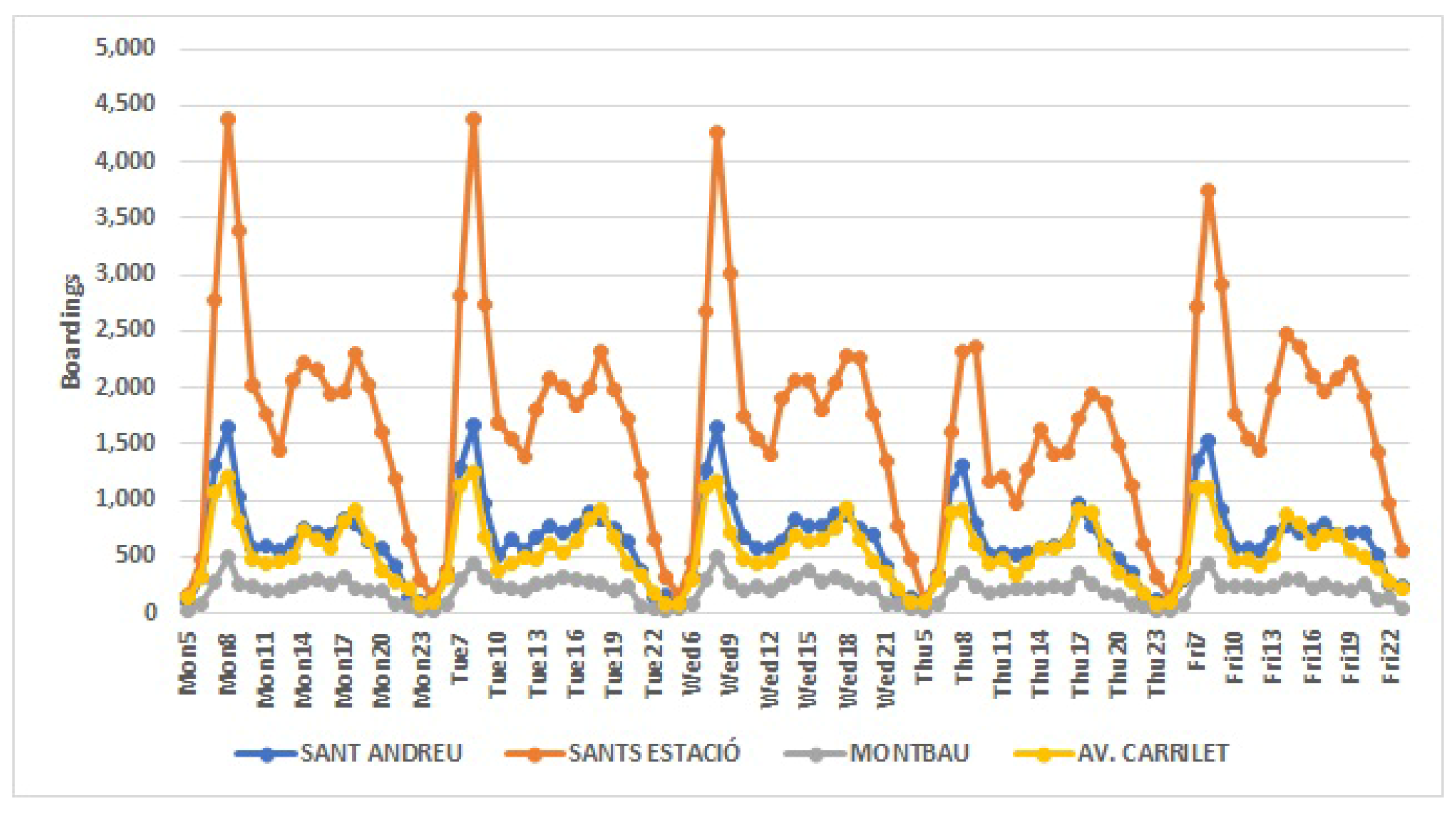
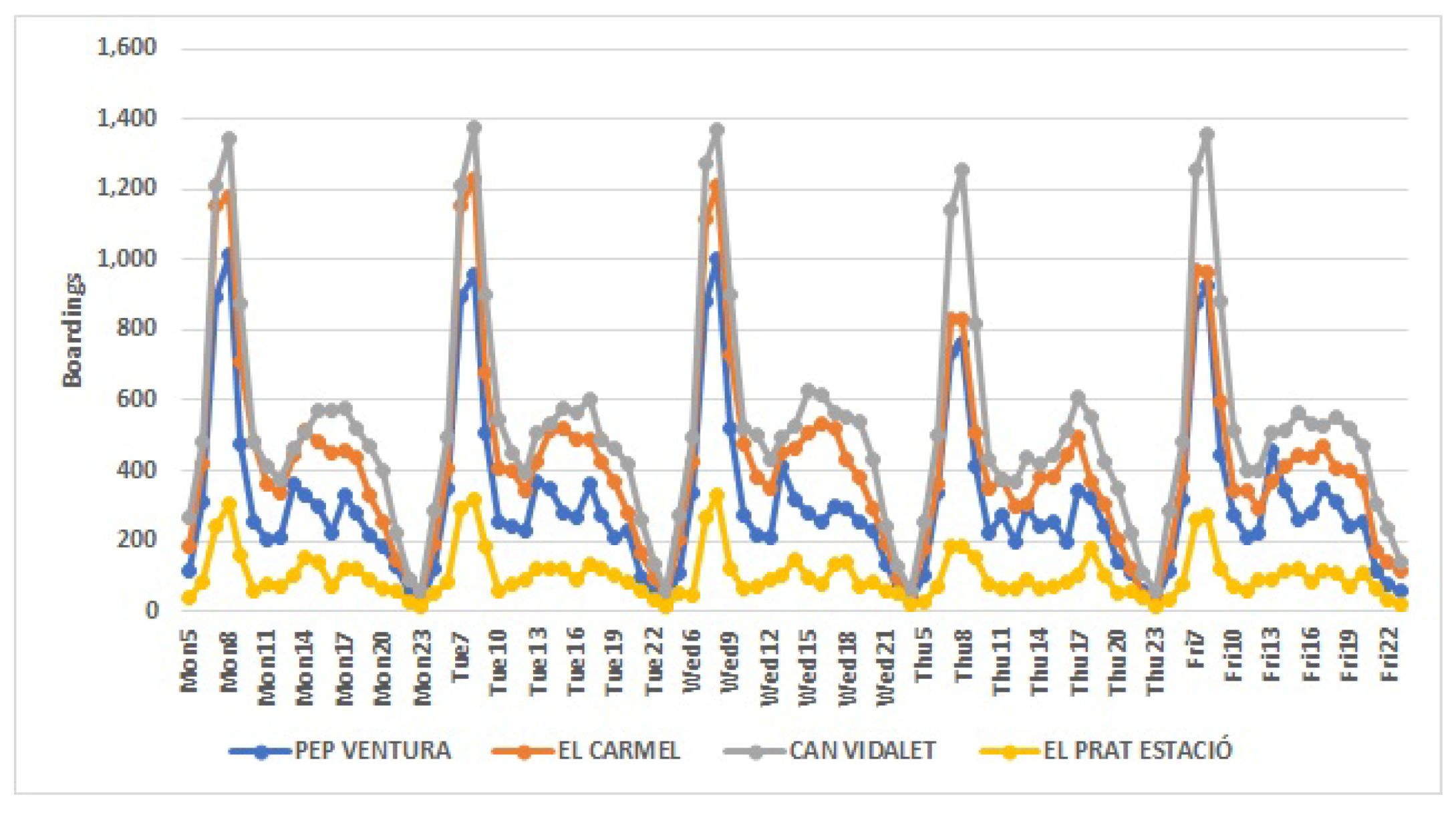
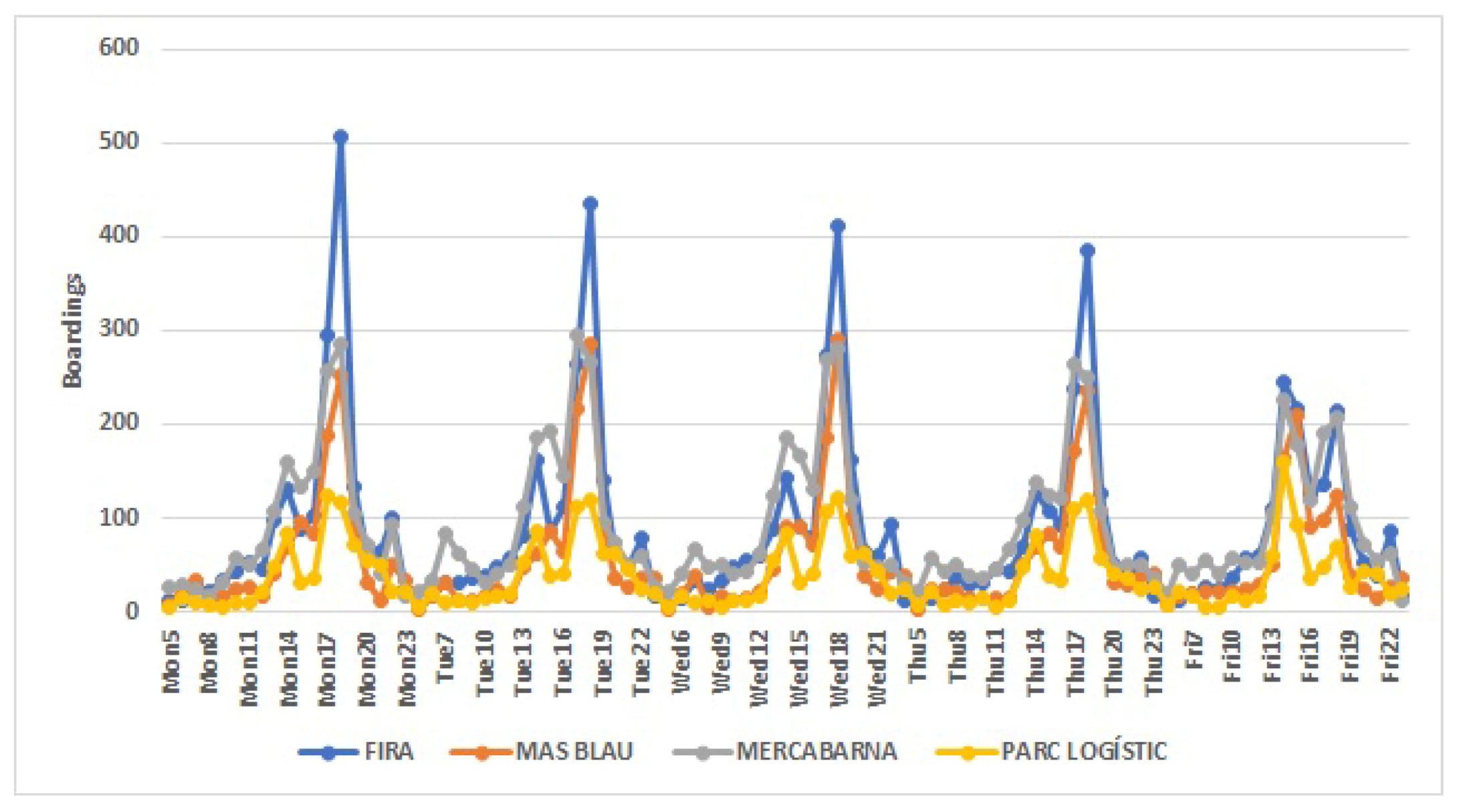
The cluster analysis carried out revealed, for working days, the existence of four groups with similar characteristics. The first conglomerate gathers the stations of the downtown area, the most touristic and monumental. In the second cluster, the stations that surround the center of Barcelona are grouped. They are, mainly, traditional and residential neighborhoods. The periphery stations, which link the center with the nearest municipalities, are those found in the third cluster. In the fourth cluster, the stations of the fairgrounds, large markets and logistics parks appear. Within each cluster, one can see the same pattern of behavior that reflects the similarities of the stations that form it, as can be seen at peak times, which differ between clusters.
The patterns observed reflect the daily activities of the urban area of Barcelona, which are related to the spatial structuring of the city and its characteristics, and are highly correlated with general daily routines.
The results of this work provide relevant information for the “Transports Metropolitan of Barcelona” company for public transport planning. These studies allow us to discover patterns of behavior needed to make decisions to improve the metro service. Nowadays, in the new post-pandemic normality, it is imperative to travel safely so as to stop the coronavirus spreading. It is important to avoid rush hours travels; people may choose to get on and off at subway stations with fewer travelers and do part of their journey by foot. Moreover, it is the task of public transport companies to increase the number of subway cars at a certain time if it gets too crowded, improve the infrastructure of stations with high passenger flow and reduce the time in-between metro services, among other security measures. For instance, the station “Sant Andreu”, from Cluster 2, has the highest number of passengers between 7:00 and 8:00 a.m., and, therefore, it is one of the stations where increasing the number of subway cars or the frequency of the service would be imperative. On the other hand, the station “Fira”, from Cluster 4, has peak hours at 14:00, 17:00 and 18:00 (p.m.), although with a much smaller number of passengers than “Sant Andreu”, and, thus, depending on the capacity of the station, the measures may not be as crucial as in the first one.
Future work involves relating these results to population, climate and economic variables that reflect other social circumstances that may influence the characteristics of the metro network stations. Moreover, annual data shall be analyzed to detect seasonality in behavior patterns. Further lines of investigations will also include a structural and robustness analysis of the network, using complex network analysis to determine critical nodes using different centrality measures. In addition, a detailed analysis of the structural characteristics of this subway network considering other different topological representations such as reduced L-space, P-space, C-space, etc. must be tackled. In addition, a theoretical framework must be proposed in which the notion of “subway line” is used as the basis to define new structural and robustness coefficients. Furthermore, additional transport lines (light rail network, bus network, etc.), can be considered in the analysis to obtain more realistic results. It would also be interesting to analyze the data post-COVID-19 and compare how the use of the public transport has changed, once the data become available.


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}