
A Data Mining and Analysis Platform for Investment Recommendations

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
- Analysis and data mining. The initial objective was to draw up a document that breaks down the functioning of the Spanish continuous market. The goal of this analysis was to determine the needs to be met by the prediction and recommendation model. Therefore, the market analysis has served as a starting point for the development of the platform. Regarding data extraction, given that the operation of the prediction and recommendation platform is based on a dataset containing the historical data of the companies in the continuous market, it has been necessary to create a system that is in charge of extracting the data in real time. Thus, this implies the need to find a reliable data source that contains the information that is required by the platform. It is possible to either make use of an Application Programming Interface (API) to allow for data retrieval, or to develop a system based on Web Scraping for the extraction and formatting of data. The analysis of the data greatly facilitates the subsequent development of a forecasting and recommendation system and the calculation of the technical analysis factors.
- The forecasting system. The objective of this system is to predict the closing value of a share in the Spanish continuous market from its opening value on the same day. This minimizes the error of the prediction model as much as possible, which will be presumably based on Machine Learning regression algorithms. The forecasting system will be developed on the basis of the extracted historical data of the shares of the Spanish continuous market companies.
- The technical analysis. On the basis of the premise that the forecasting system relies on a series of historical market opening values to predict its closing values, the addition of a system that is based on the calculation of technical analysis factors (widely used in economics, specifically in the field of investment) is proposed, in order to combine Artificial Intelligence with the human calculation of technical factors. This brings a distinctive value to the prediction system, which is based on the combination of a series of techniques to determine the recommendation that is to be made to the user.
- The recommendation system. It is proposed to create a recommender system, which, based on the values that result from the aforementioned objectives, is capable of recommending the decision to buy or sell a share in the Spanish continuous market to the user. Therefore, the recommender system is based on calculating the outputs of the rest of the modules and combining them in order to abstract a decision that benefits the user. Thus, the recommendation system is the most crucial and delicate phase of all the modules that make up the platform.
- The visualization platform. In addition, we propose the creation of a platform that allows for the visualization of the information, recommendations, and predictions for each company in the Spanish continuous market that the end user wishes to consult. The visualization platform graphs the previously made calculations and predictions, so that the end user can consult how the platform operates.
2. State of the Art
3. Proposed Model
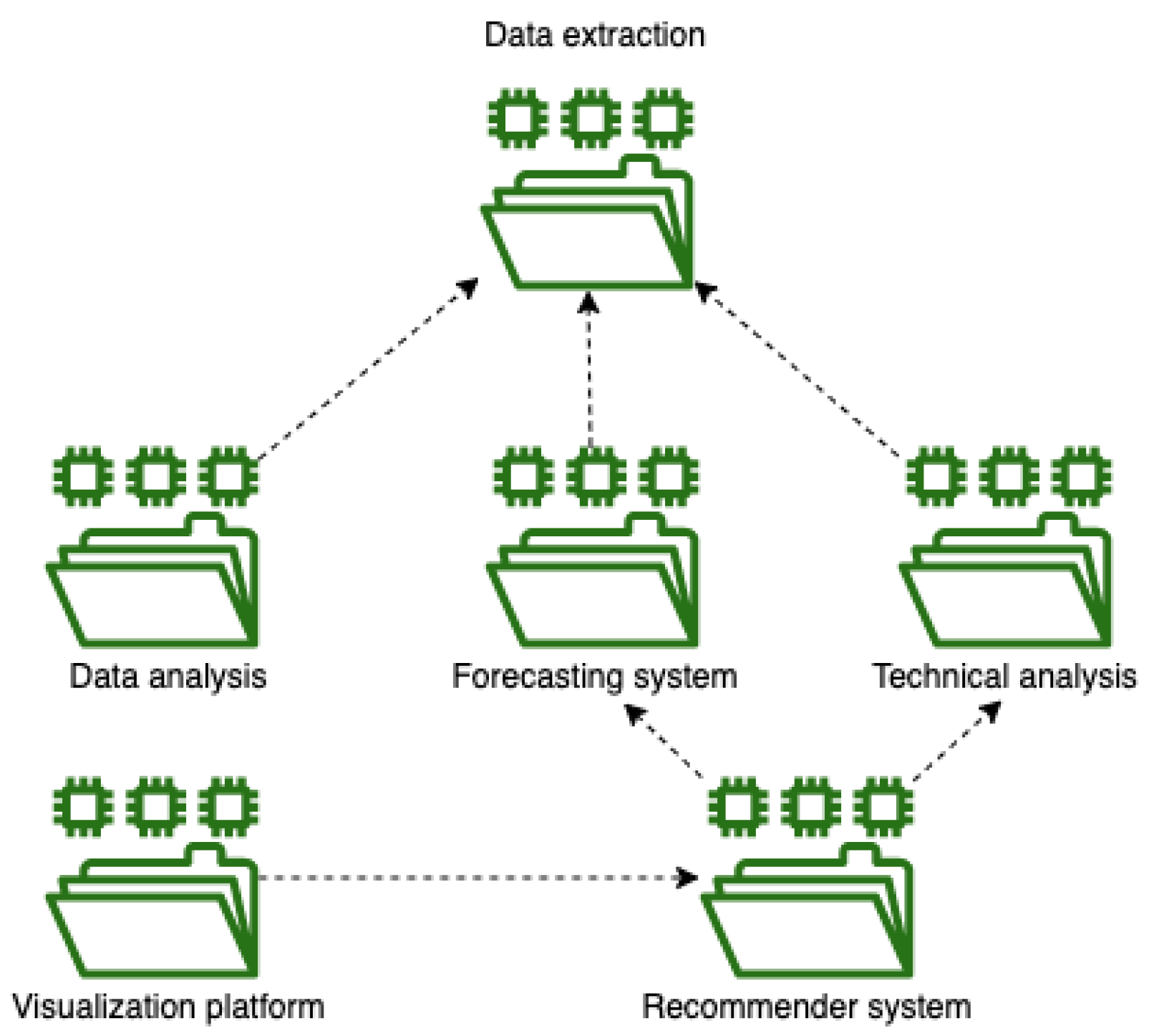
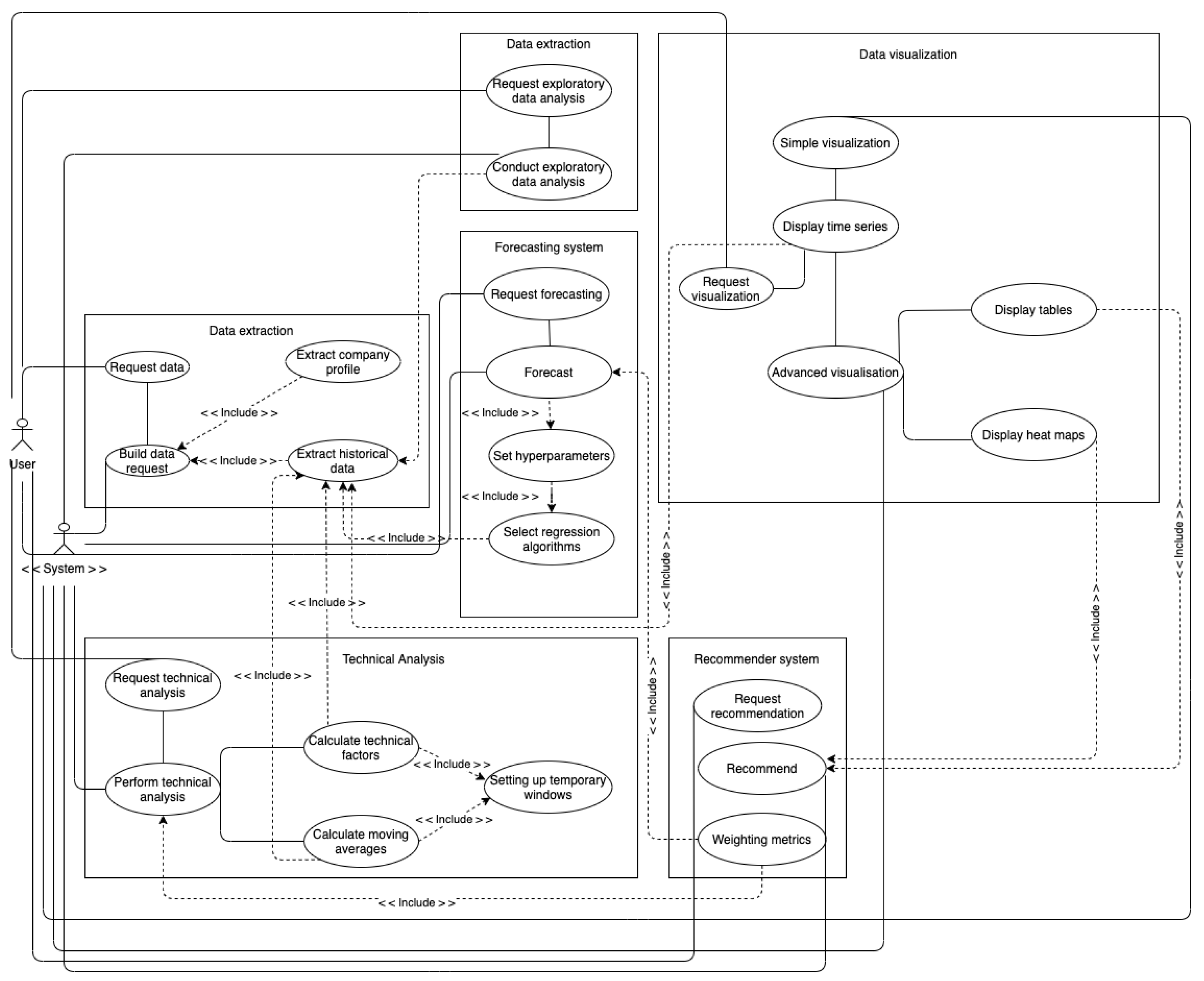
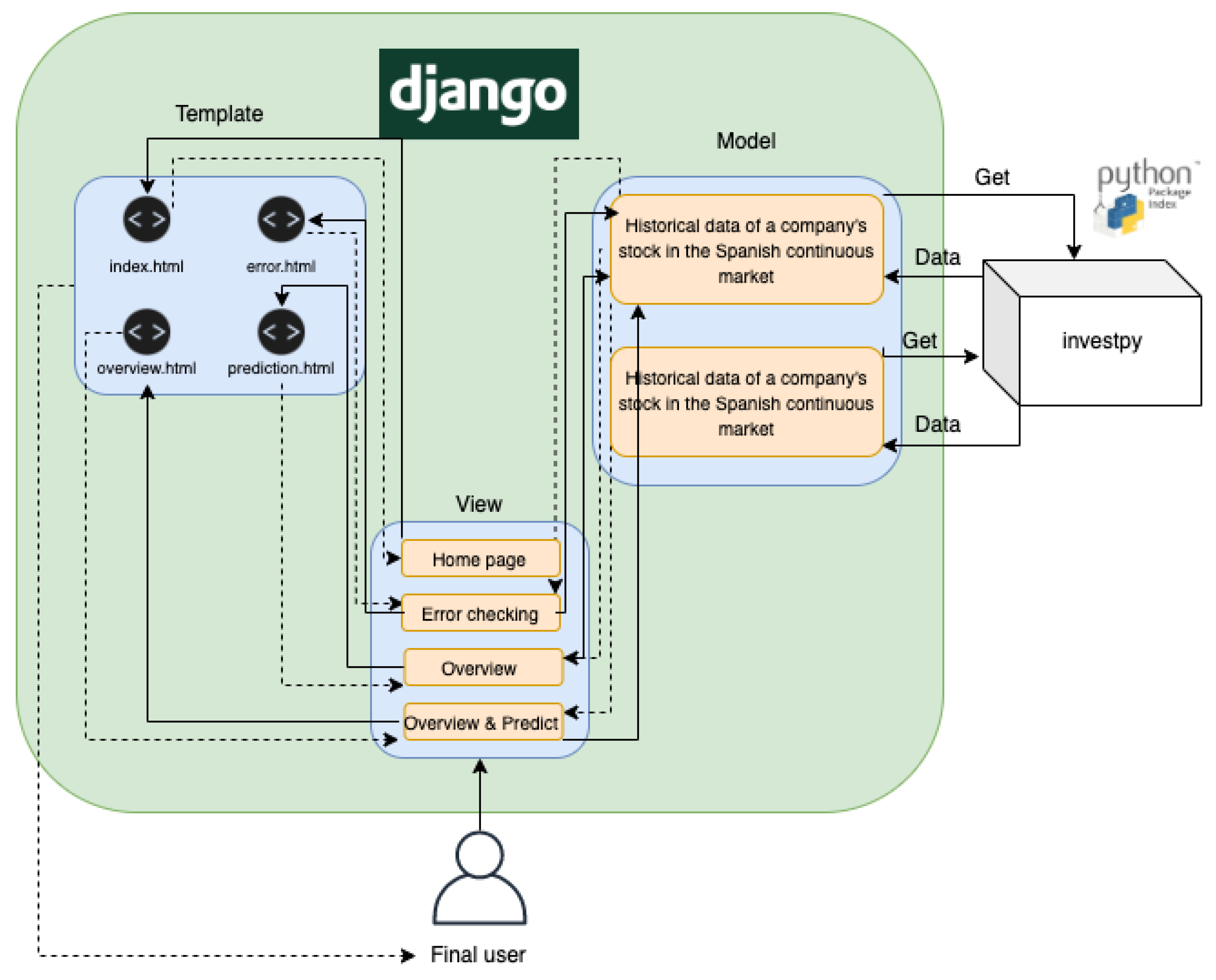
3.1. Software Architecture
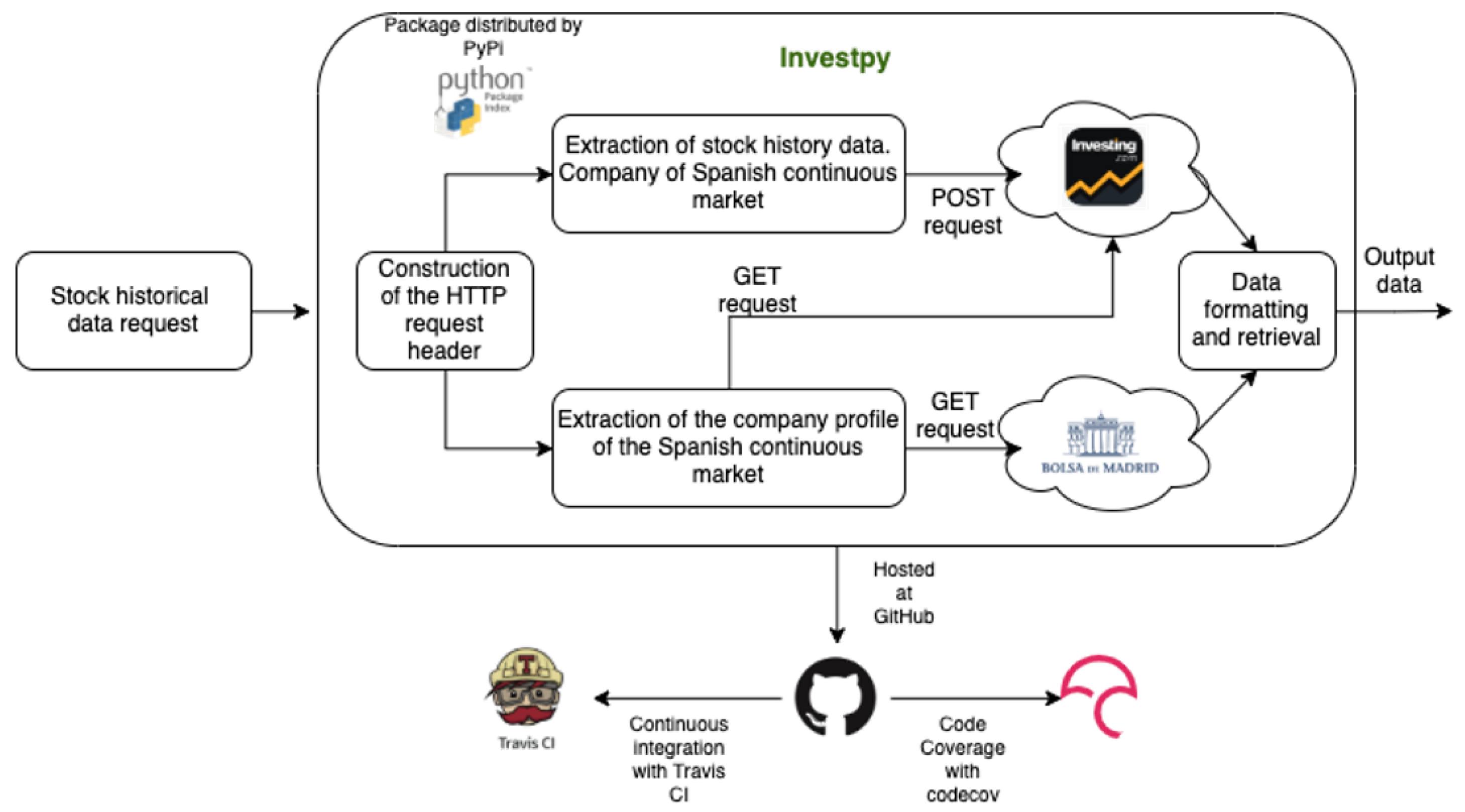
3.1.1. Data Extraction Package
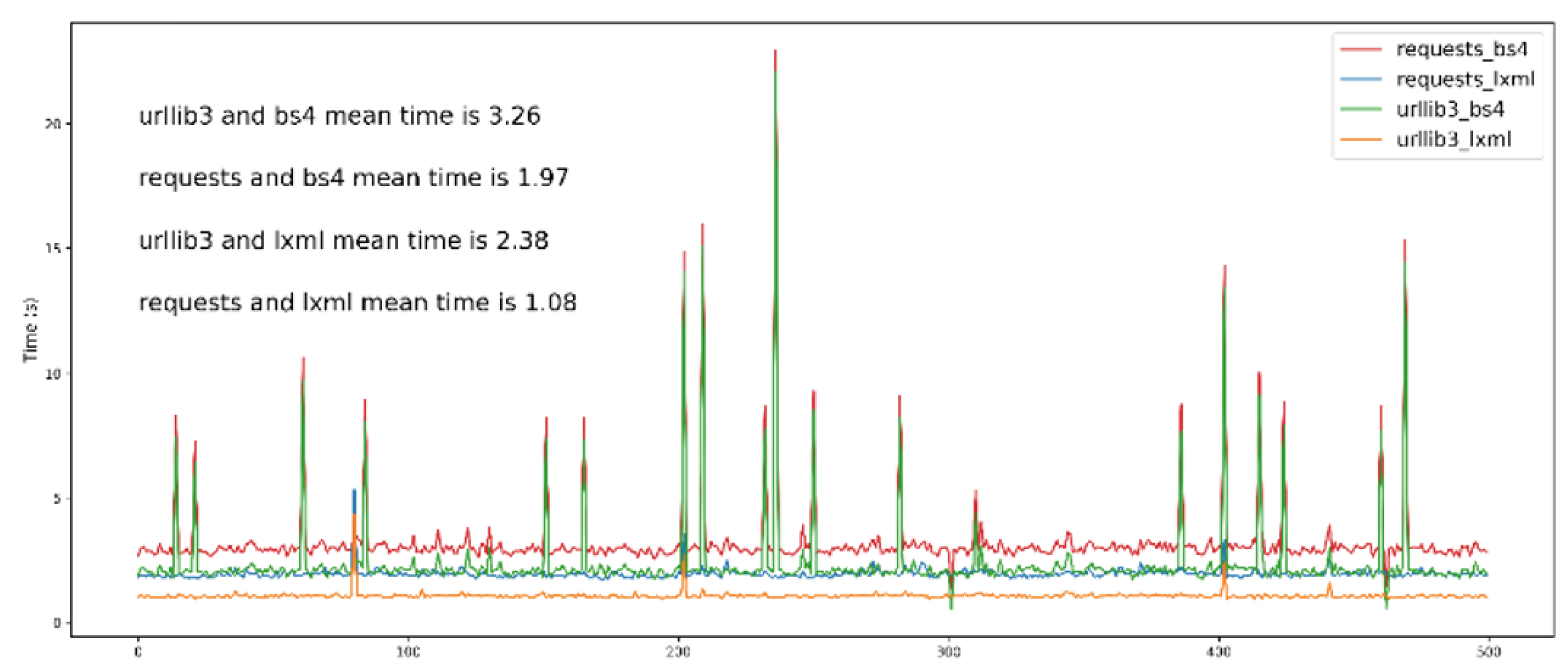
- Web request: The HTML of the web have been retrieved and also requests of GET or POST type have been made; principally, urllib314 and requests15.
- HTML parsing: consisted in recovering and formatting the data from the previously retrieved HTML. To parse and obtain the information from the HTML, two Python utilities have been employed, beautifulsoup416 and lxml17.
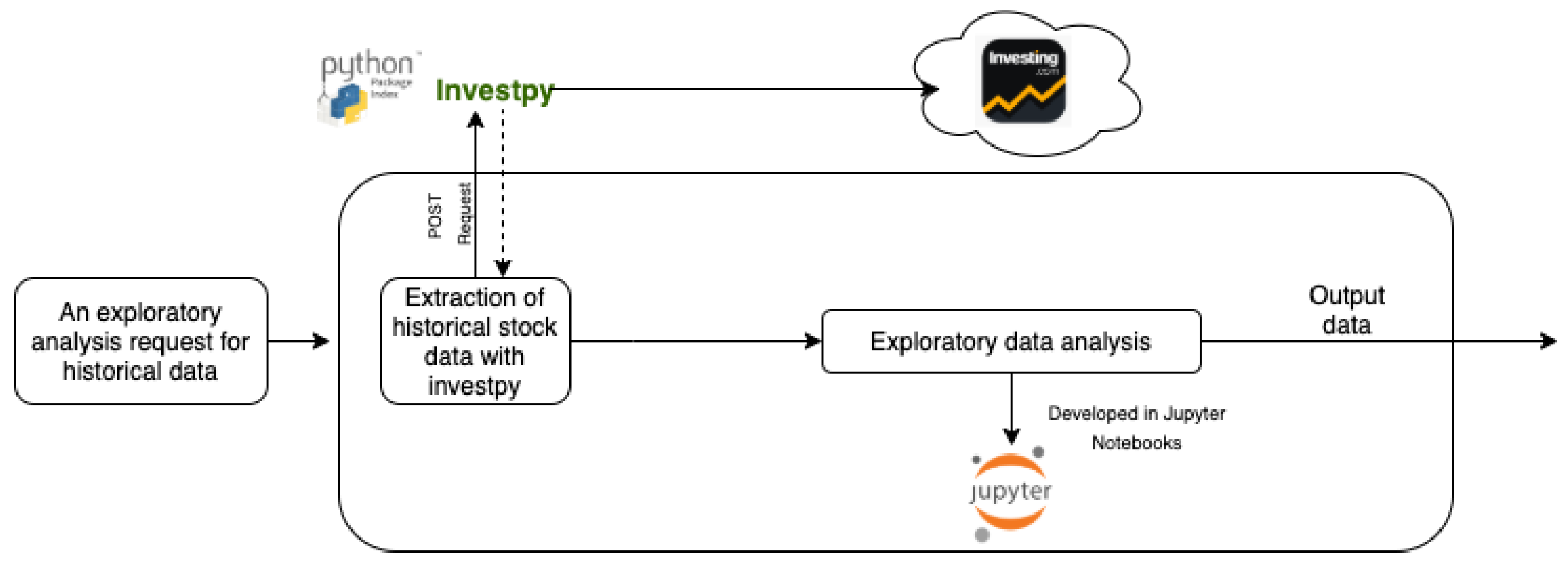
3.1.2. Data Analysis Package
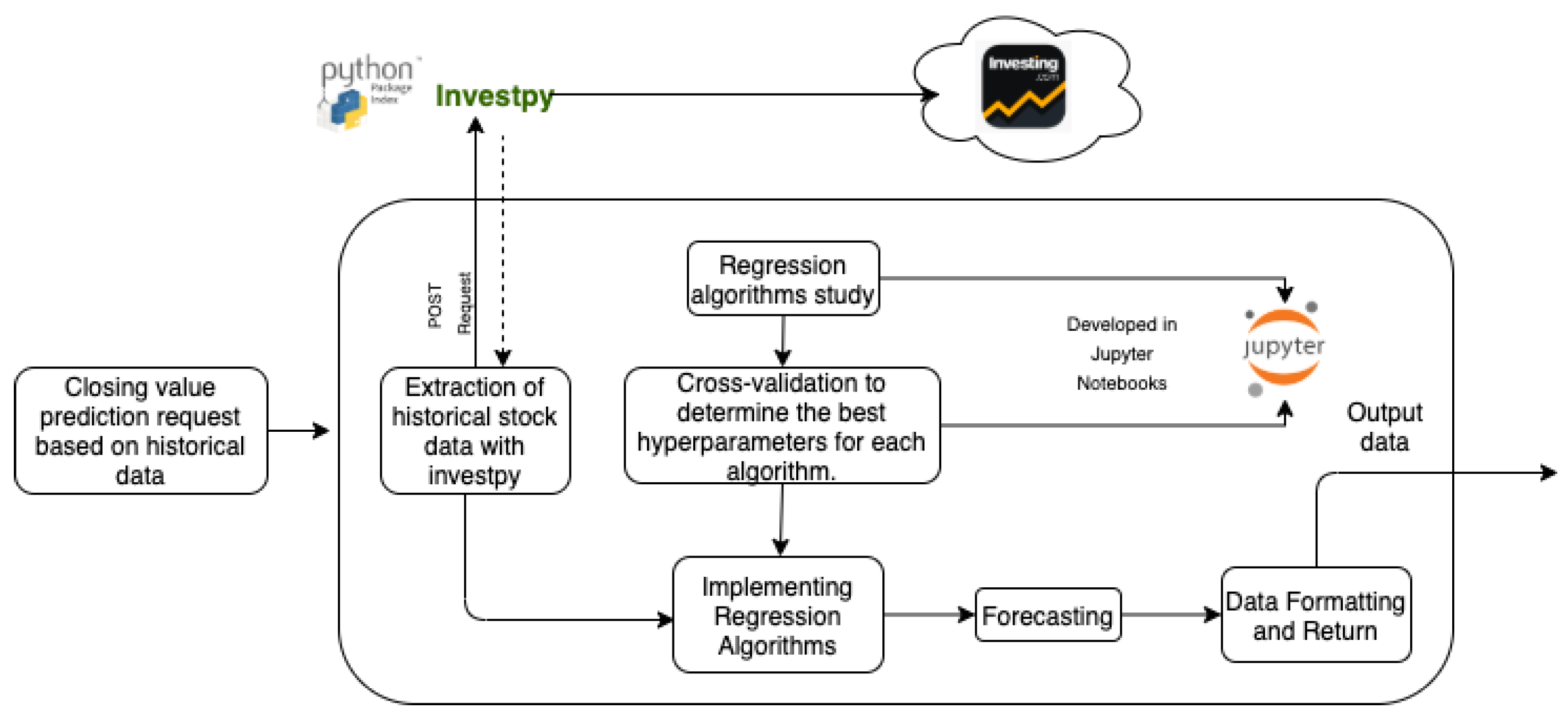
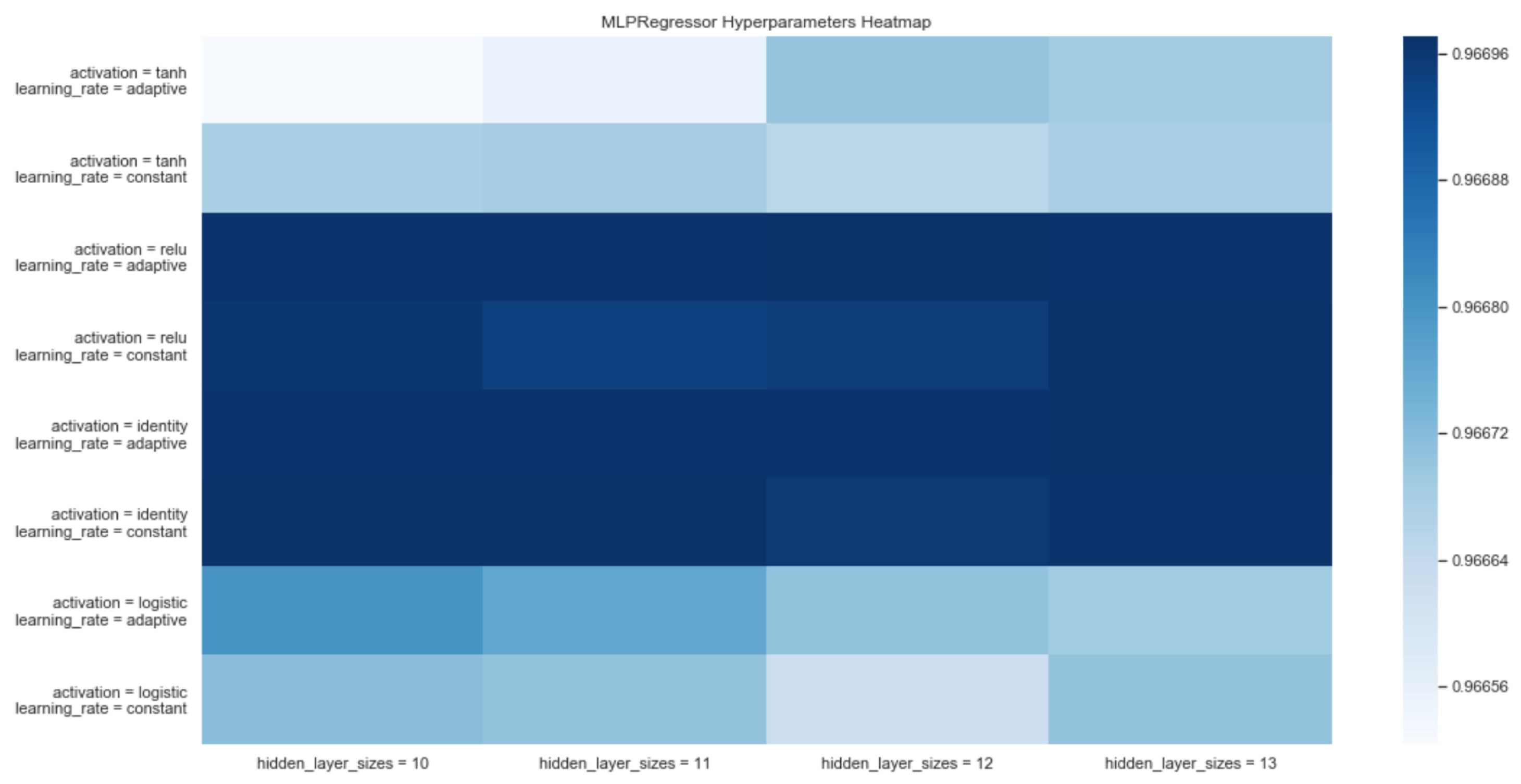
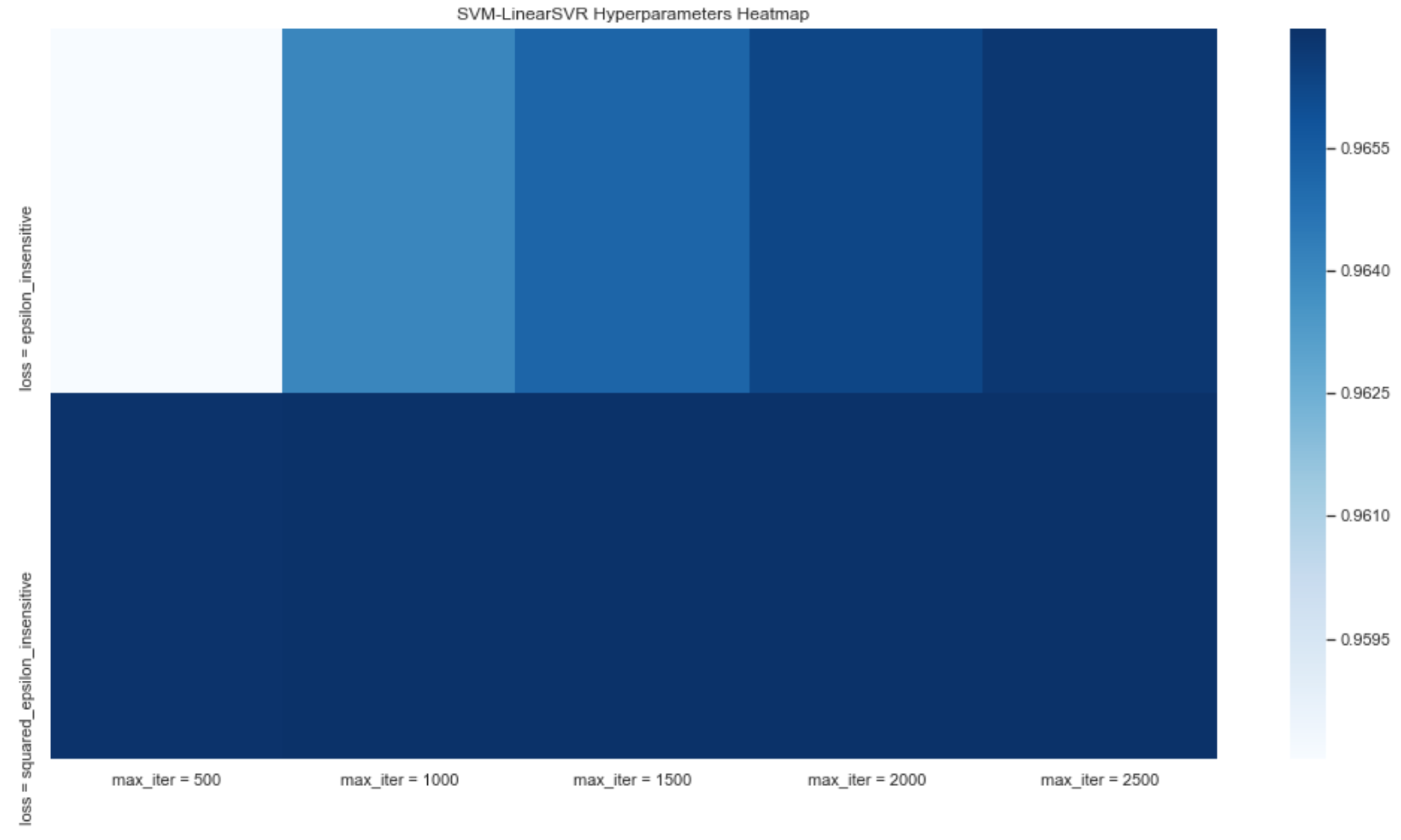
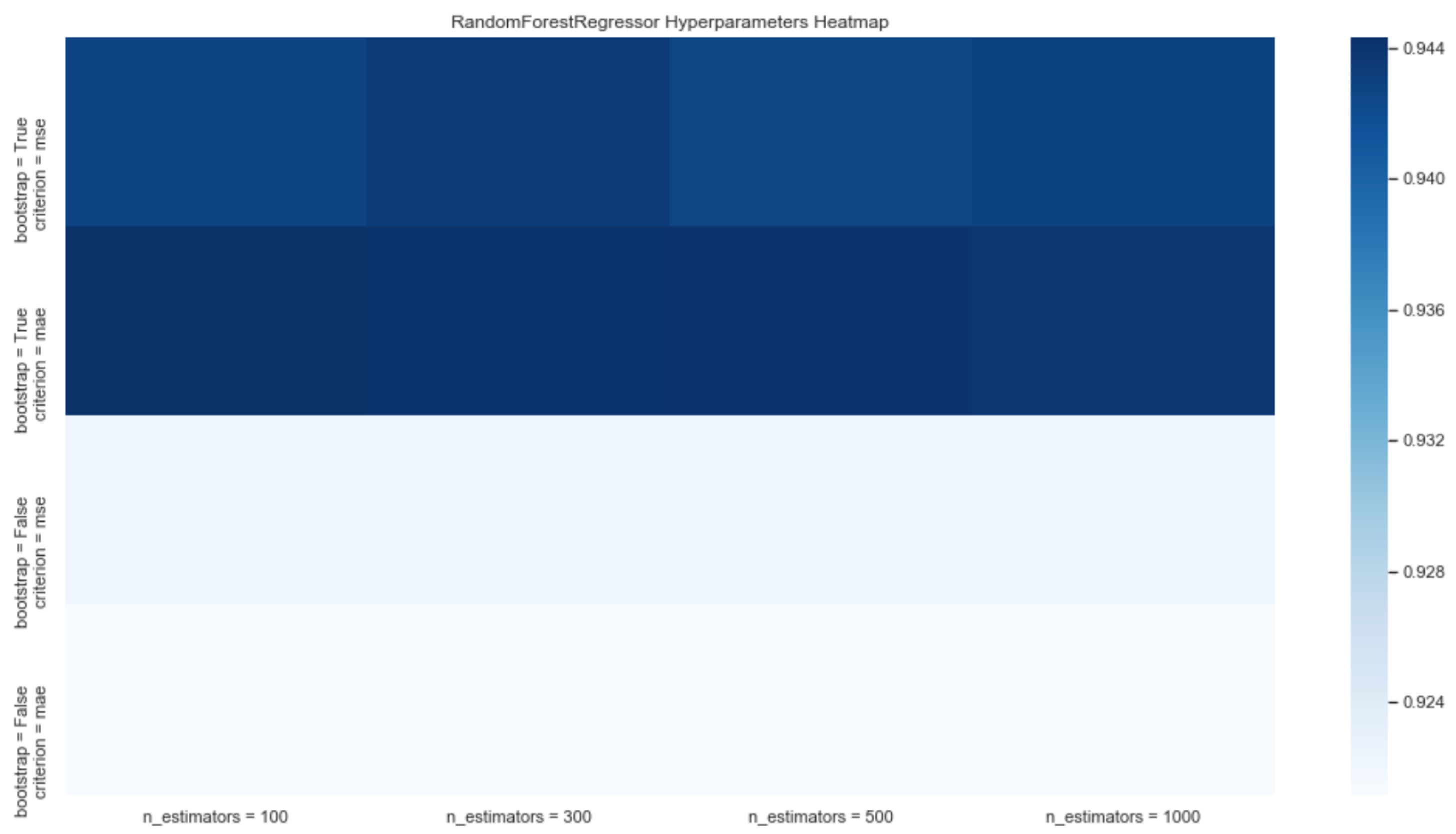
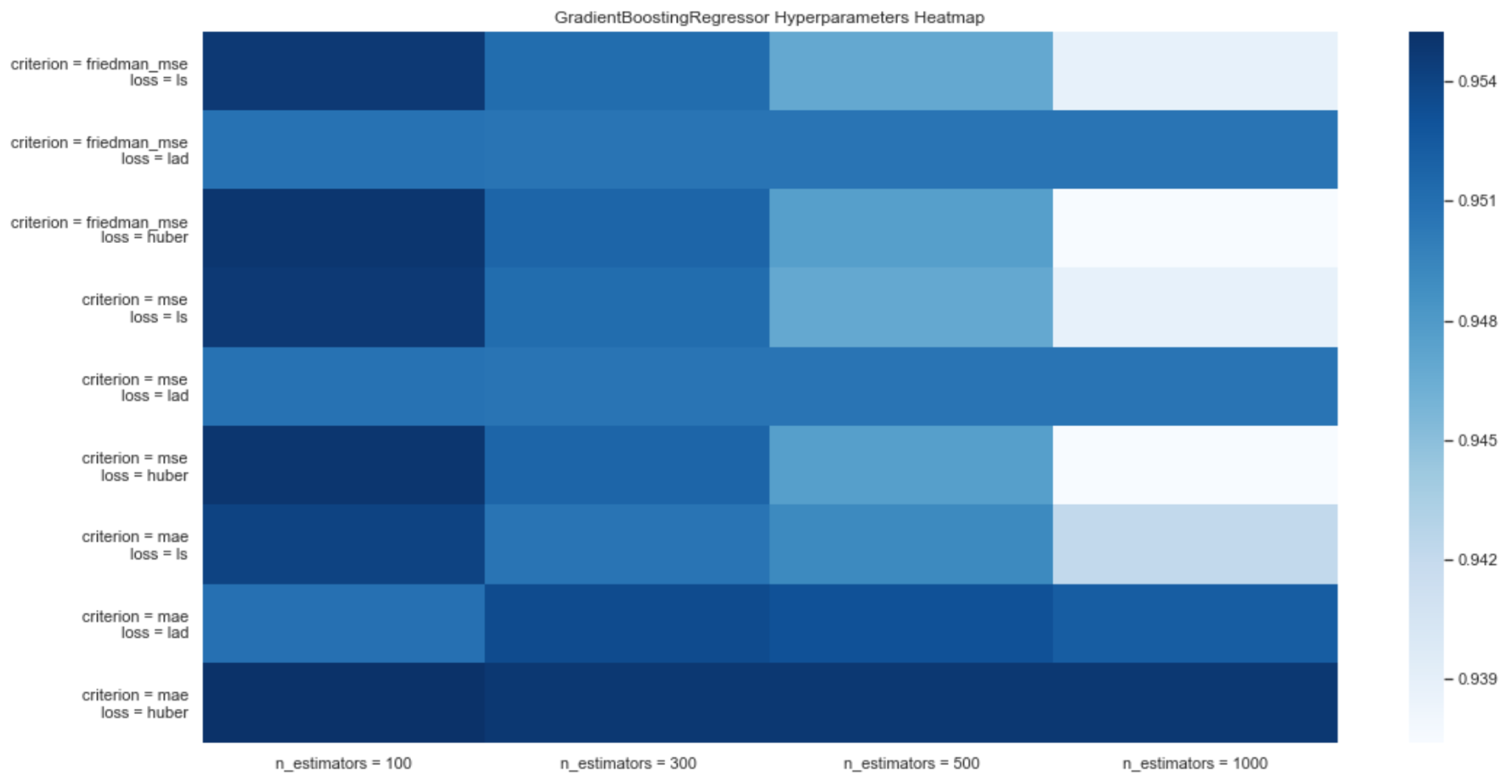
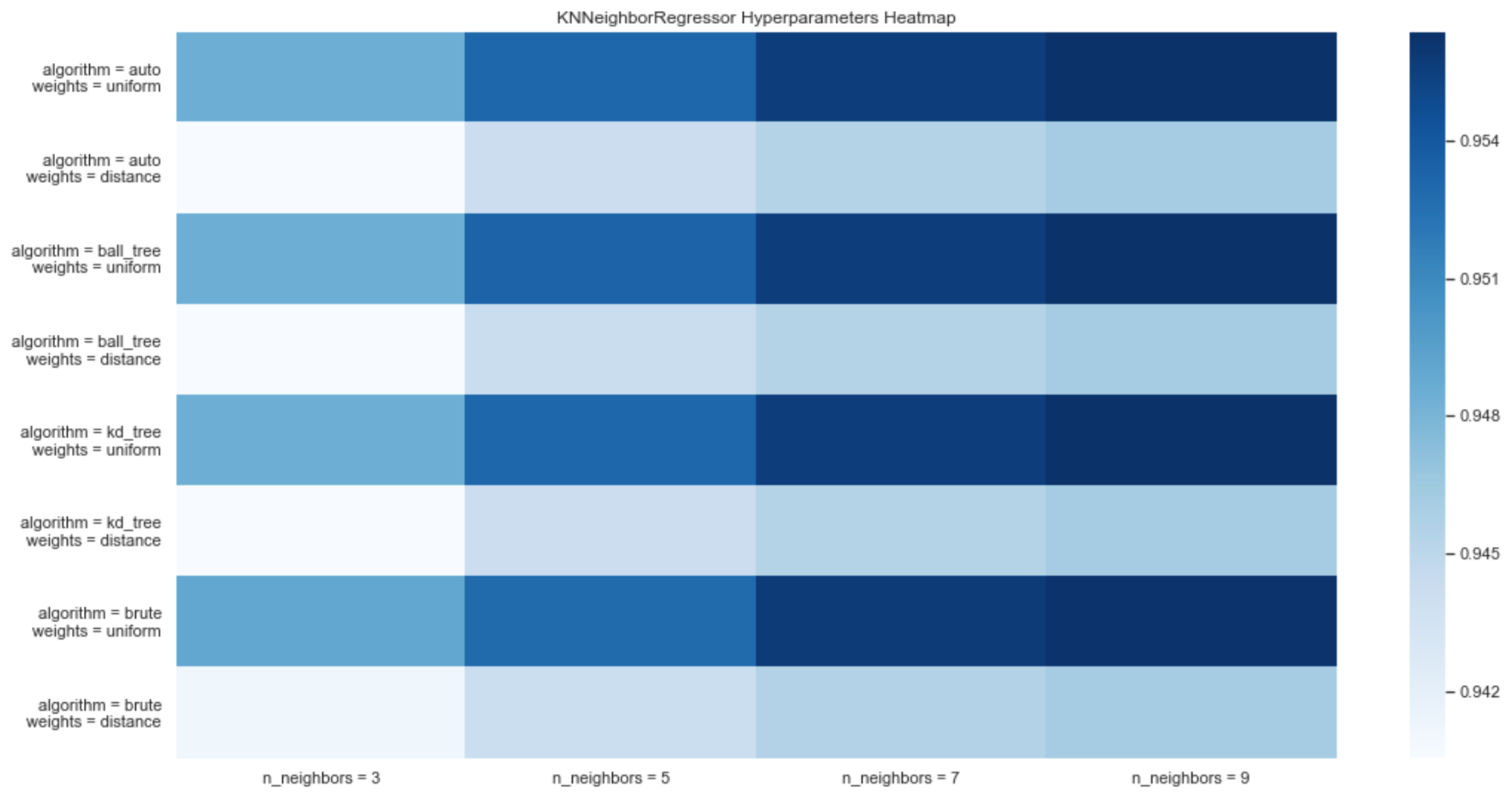
3.1.3. Forecasting System
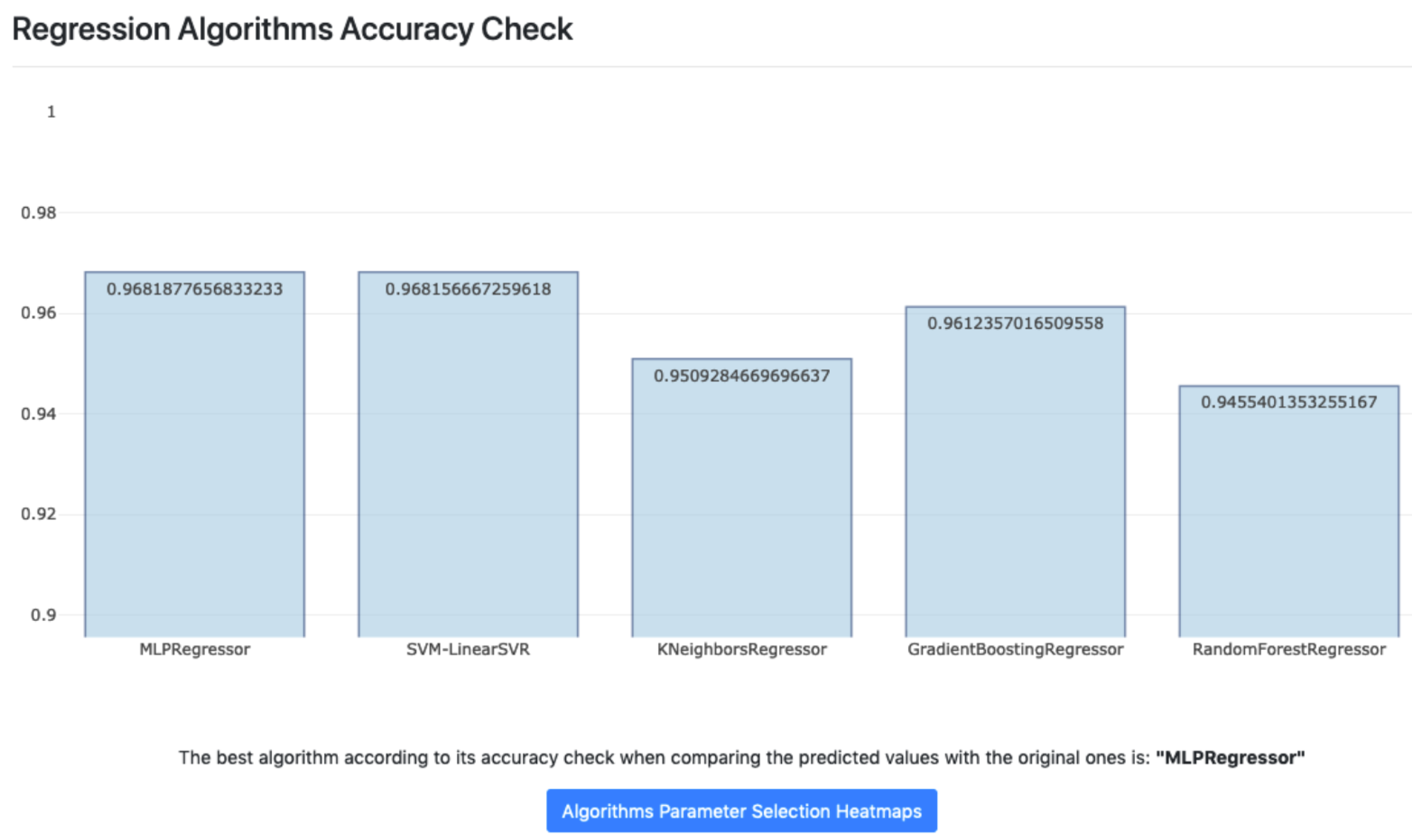
- Random Forest Regressor: these algorithms are an automated learning method for classification, regression, and other tasks. A random forest is a meta-stimulus that fits a series of classification decision trees into various sub-samples of the data set and uses the means to improve productive accuracy and control over fit.
- Gradient Boosting Regressor: it is an automated learning technique that builds the model in a scenic way, just like methods that are based on reinforcement. It generalizes models allowing for the optimization of an arbitrary and differentiable loss function.
- SVM-LinearSVR: learning models that analyze data for classification and regression analysis. An SVM training algorithm builds a model that assigns new examples to one or another category, which makes it a non-probabilistic binary linear classifier. In SVR we try to adjust the error within a certain threshold. In this case, it is similar to SVR with the kernel = linear parameter.
- MLP Regressor: a kind of artificial feedback neural network. MLP uses a supervised learning technique, called backpropagation, for the construction of the network. In addition, its multiple layers and non-linear activation distinguish MLP from a linear perceptron. It also allows for distinguishing data that are not linearly separable.
- KNNeighbors Regressor: non-parametric method used for classification and regression
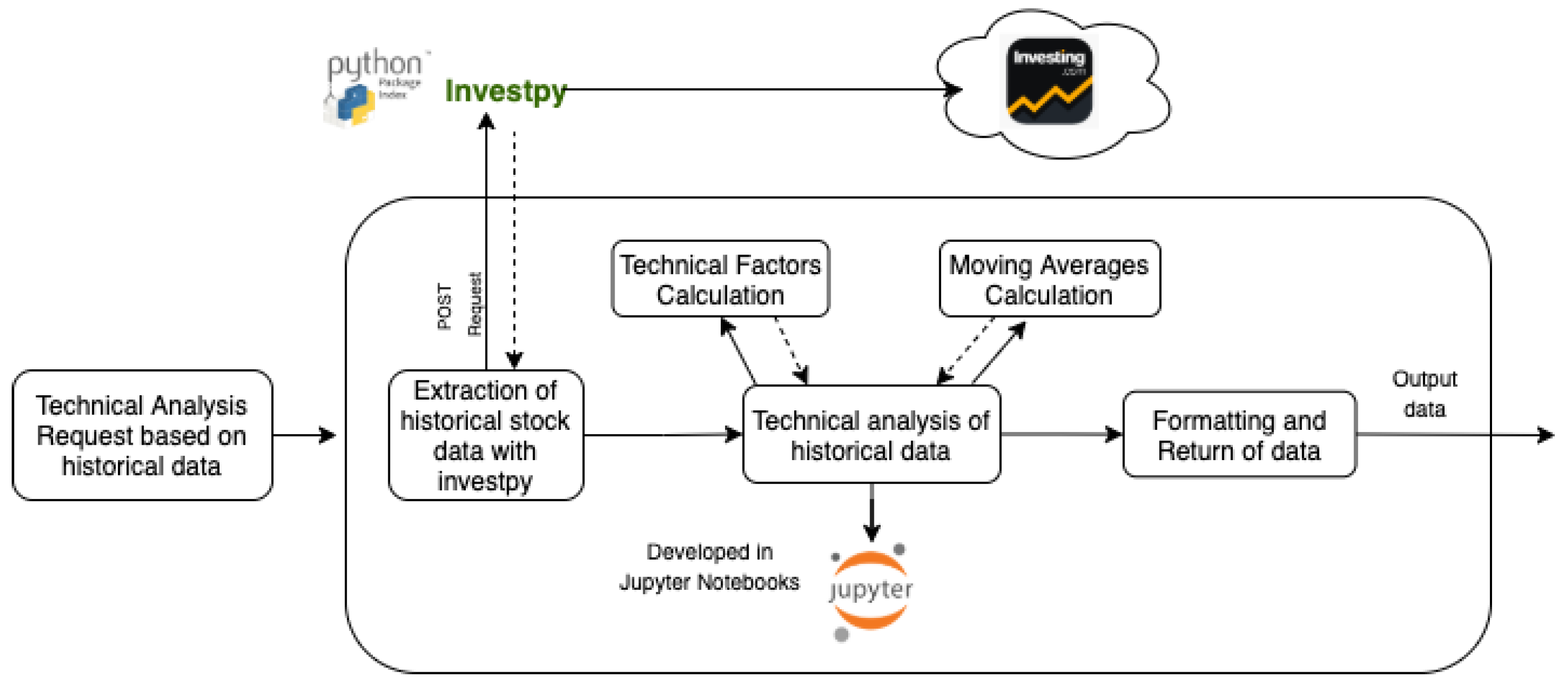
3.1.4. Technical Analysis
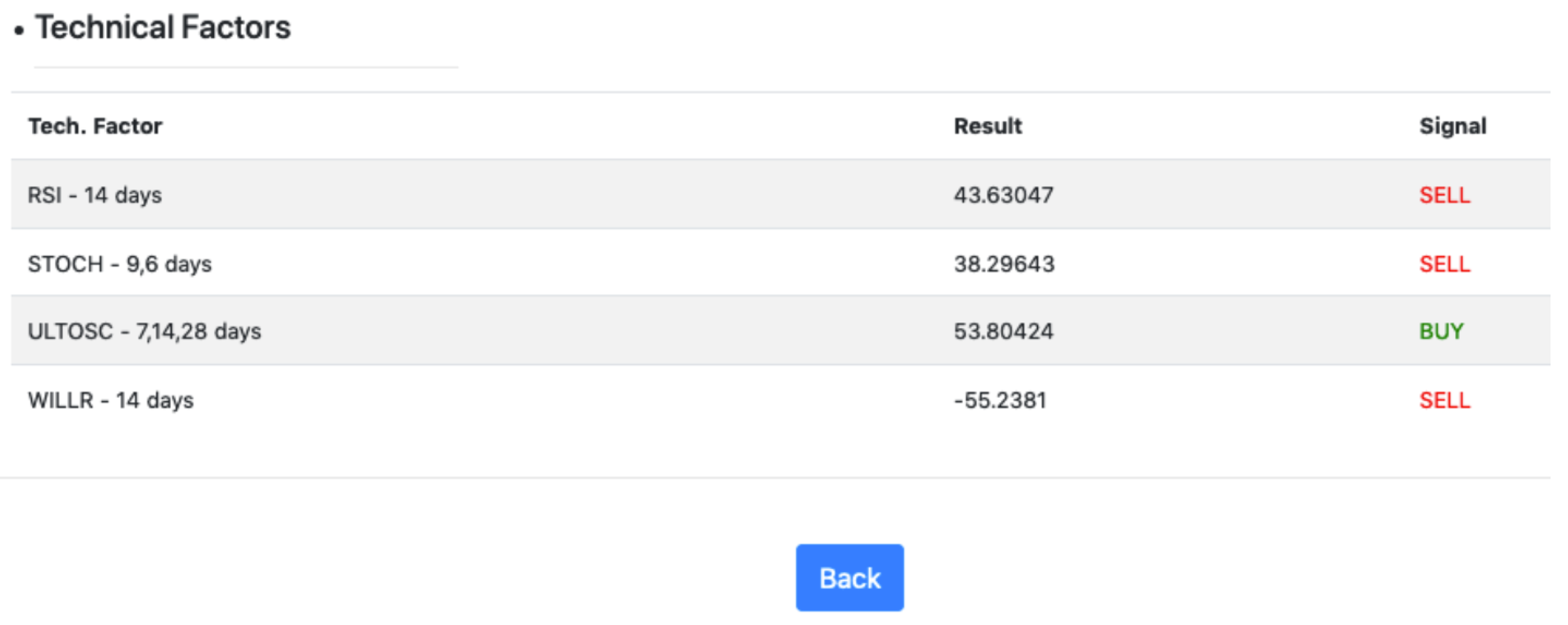
- Relative Strength Index (RSI): it is a Momentum Indicator (these indicators reflect the difference between the current closing price and the closing price of the previous N days), which measures the impact of frequent changes in the price of a stock, identifying the signs of overbuying or overselling. The representation of the RSI is shown on an oscillator, which is, a line whose value oscillates between two extremes, which, in this case, is between 0 and 100.
- Stochastic Oscillator (STOCH): it is a Momentum Indicator that compares the closing price of a stock on a given day with the range of closing values of that stock over a certain period of time, defined by the time window. It also allows to adjust the sensitivity of the oscillator either by adjusting the time window or by calculating the moving average of the STOCH result. Like RSI, it identifies the signals of over-bought or oversold stock within a range of 0 to 100 possible values.where C is the most recent closing price, L14 is the lowest price traded of the 14 previous trading sessions, H14 is the highest price traded during the same 14-day period, and %K is the current value of the stochastic indicator.
- Ultimate Oscillator (ULTOSC): it is a Momentum Indicator used to measure the evolution of a stock over a series of time frames using a weighted average of three different windows or time frameworks. Therefore, it acquires a lower volatility and identifies fewer buy-sell signals than other oscillators that only depend on a single time frame. When the lines generated by ULTOSC diverge from the closing values of a stock, buy and sell signals are identified for it.where UO is the Ultimate Oscillator and A is the average. The average calculation follows the next formulas.where BP is the Buying Pressure and PC is the Prior Closewhere TR is the Ture Rangewhere TR is the Ture Range.
- Williams %R (WILLR): also known as the Williams Percent Range, is a Momentum Indicator that fluctuates between −100 and 0 and measures and identifies levels of stock overbuying or overselling. WILLR is very similar to the STOCH in its use, as it is used for the same purpose. This indicator compares the closing value of a stock with the range between the maximum and minimum values within a given time frame.where the Highest High is the highest price in the look-back period, typically 14 days, Close is the most recent closing price, and Lowest Low is the lowest price in the look-back period, typically 14 days.
- Simple Moving Average (SMA): it is an arithmetic moving average. It is calculated by adding the recent closing values of an action for a window of size N and dividing that sum by the size of the window. Thus, when the size of the timeframe N is low, it responds quickly to changes in the value of the stock; if the size of the window N is high, it responds more slowly.where the price of an asset at period n and n is the number of total periods.
- Exponential Moving Average (EMA): also called Exponentially Weighted Moving Average, since it weights recent observations, i.e., closing prices of a stock closer to the current one. It can be said that EMAs respond better than SMAs to recent changes in a share’s price.where EMA is the exponential moving average. The smoothing factor is calculated, as follows:where n represents the number of periods the EMA uses.
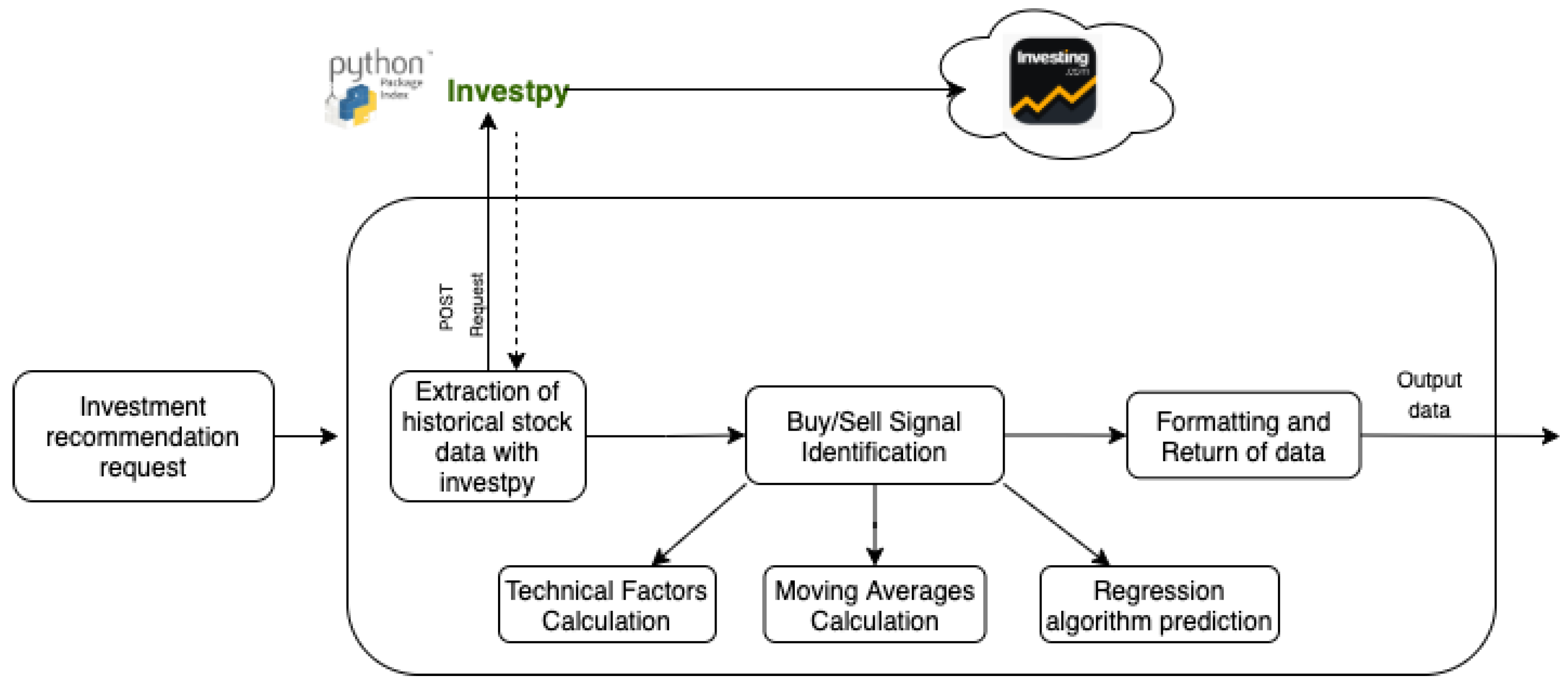
3.1.5. Recommender System
- Random Forest Regressor
- Gradient Boosting Regressor
- SVM-LinearSVR
- MLP Regressor
- KNNeighbors Regressor
4. Platform Visualization
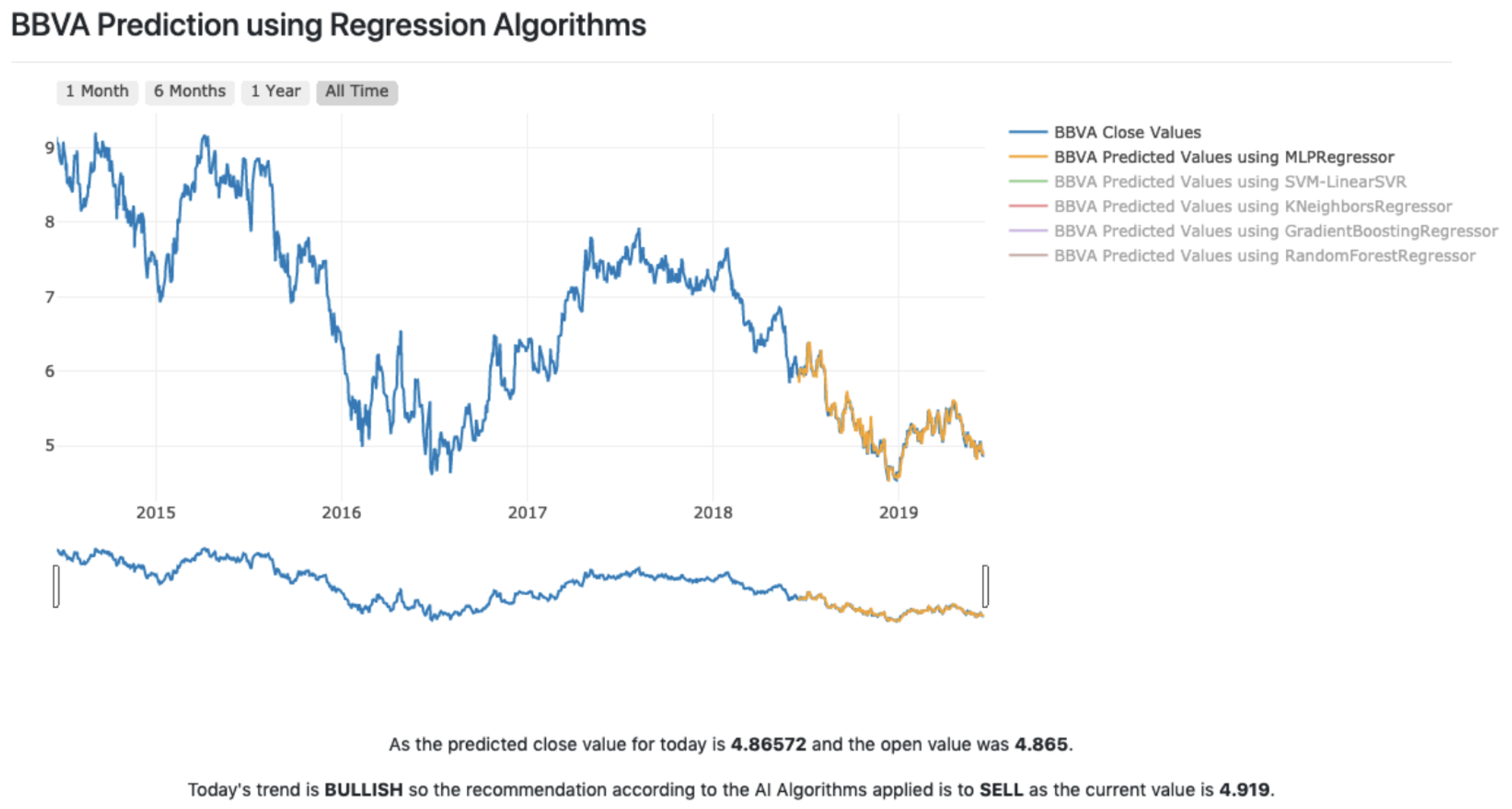
- Time series: offers a graphic representation of the retrieved historical data, where the X and Y axes represent the value of the stock in euros, and the date on which the stock reached that value, respectively.
- Candlestick chart: this representation shows the opening and closing values for each date and the difference between the maximum and minimum values for the same date.
- Data table: represents the available values. They are called OHLC (Open-High-Low-Close).
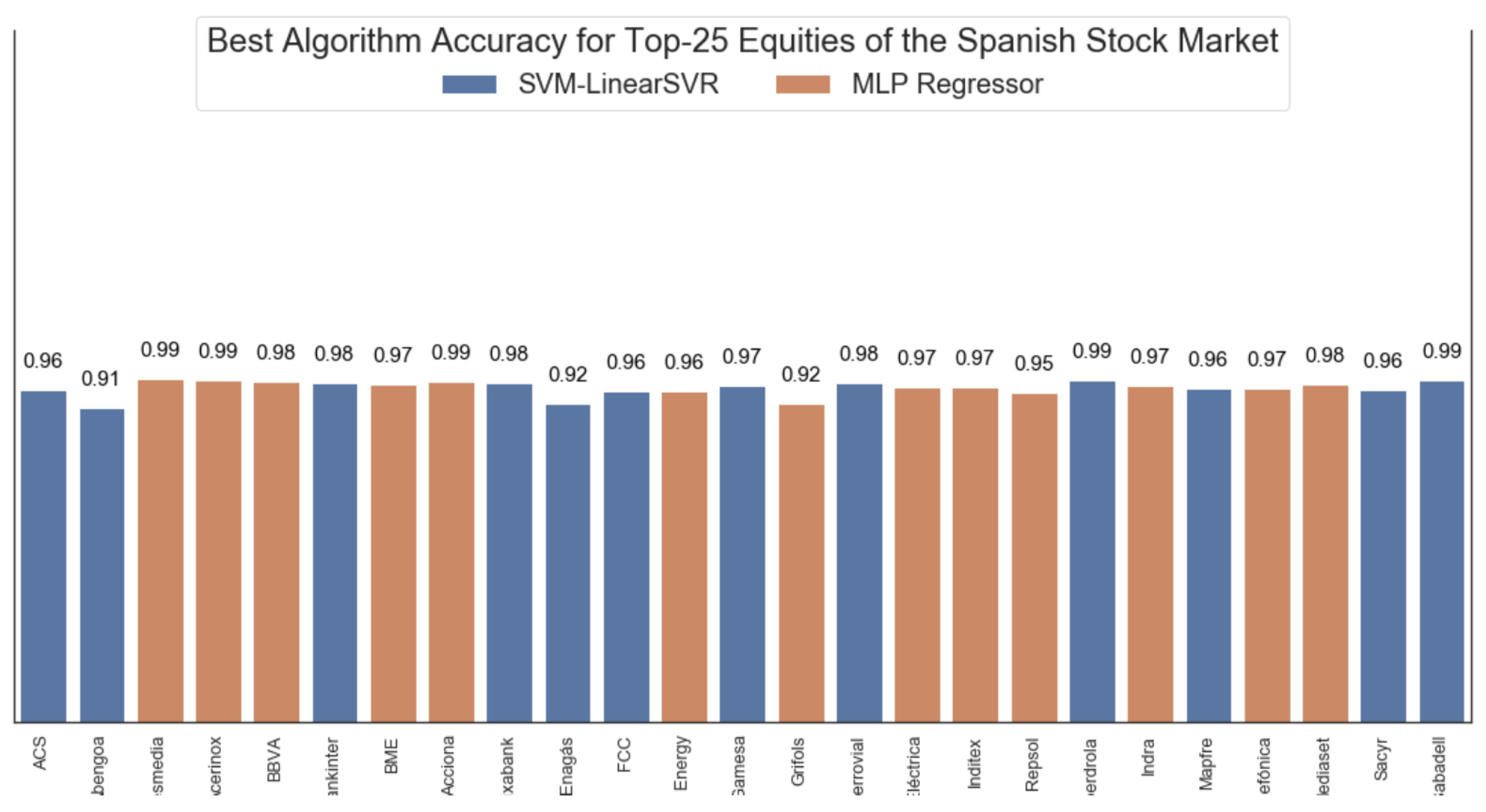
5. Discussion and Results
Author Contributions
Funding
Conflicts of Interest
References
- Atsalakis, G.S.; Valavanis, K.P. Surveying stock market forecasting techniques–Part II: Soft computing methods. Expert Syst. Appl. 2009, 36, 5932–5941. [Google Scholar] [CrossRef]
- Nicoletti, B.; Nicoletti, W.; Weis. Future of FinTech; Palgrave Studies in Financial Services Technology: Rome, Italy, 2017. [Google Scholar]
- Patel, J.; Shah, S.; Thakkar, P.; Kotecha, K. Predicting stock and stock price index movement using trend deterministic data preparation and machine learning techniques. Expert Syst. Appl. 2015, 42, 259–268. [Google Scholar] [CrossRef]
- Soni, S. Applications of ANNs in stock market prediction: A survey. Int. J. Comput. Sci. Eng. Technol. 2011, 2, 71–83. [Google Scholar]
- Yoo, P.D.; Kim, M.H.; Jan, T. Machine learning techniques and use of event information for stock market prediction: A survey and evaluation. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06), Vienna, Austria, 28–30 November 2005; Volume 2, pp. 835–841. [Google Scholar]
- Taghavi, M.; Bakhtiyari, K.; Scavino, E. Agent-based computational investing recommender system. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 455–458. [Google Scholar]
- Nair, B.B.; Mohandas, V. An intelligent recommender system for stock trading. Intell. Decis. Technol. 2015, 9, 243–269. [Google Scholar] [CrossRef]
- Del Canto, A. Investpy—Financial Data Extraction from Investing.com with Python. Available online: https://github.com/alvarobartt/investpy (accessed on 4 April 2020).
- Arora, N. Financial analysis: Stock market prediction using deep learning algorithms. In Proceedings of the International Conference on Sustainable Computing in Science, Technology and Management (SUSCOM), Amity University Rajasthan, Jaipur, India, 26–28 February 2019. [Google Scholar]
- Khaidem, L.; Saha, S.; Dey, S.R. Predicting the direction of stock market prices using random forest. arXiv 2016, arXiv:1605.00003. [Google Scholar]
- Pimprikar, R.; Ramachadran, S.; Senthilkumar, K. Use of machine learning algorithms and twitter sentiment analysis for stock market prediction. Int. J. Pure. Appl. Math. 2017, 115, 521–526. [Google Scholar]
- Edwards, R.D.; Magee, J.; Bassetti, W.C. Technical Analysis of Stock Trends; Routledge, Taylor & Francis Group: New York, NY, USA, 2018. [Google Scholar]
- Dash, R.; Dash, P.K. A hybrid stock trading framework integrating technical analysis with machine learning techniques. J. Financ. Data Sci. 2016, 2, 42–57. [Google Scholar] [CrossRef] [Green Version]
- Ravindran, A. Django Design Patterns and Best Practices; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Di Girolamo, R.; Esposito, C.; Moscato, V.; Sperlí, G. Evolutionary game theoretical on-line event detection over tweet streams. Knowl. Based Syst. 2021, 211, 106563. [Google Scholar] [CrossRef]
- Mercorio, F.; Mezzanzanica, M.; Moscato, V.; Picariello, A.; Sperli, G. DICO: A graph-db framework for community detection on big scholarly data. IEEE Trans. Emerg. Top. Comput. 2019. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Approaches |
|---|---|
| [1] | Stock forecasting through soft computing techniques. The authors concluded that ANNs and neuro fuzzy models were valid for predicting stock market values |
| [4] | compiled various studies applying machine learning and artificial intelligence techniques |
| [5] | Highlighted the need for historical stock market data after reviewing various machine learning techniques for stock prediction. |
| [3] | The author provided a mixed approach that uses both machine learning algorithms and fundamental and technical analysis. |
| [6] | The authors proposal mixed collaborative and content-based filtering techniques. |
| [7] | The research concerns the use of a decision tree of technical indicators optimised by GA-SVM. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernández-Nieves, E.; Parra-Domínguez, J.; Chamoso, P.; Rodríguez-González, S.; Corchado, J.M. A Data Mining and Analysis Platform for Investment Recommendations. Electronics 2021, 10, 859. https://doi.org/10.3390/electronics10070859
Hernández-Nieves E, Parra-Domínguez J, Chamoso P, Rodríguez-González S, Corchado JM. A Data Mining and Analysis Platform for Investment Recommendations. Electronics. 2021; 10(7):859. https://doi.org/10.3390/electronics10070859
Chicago/Turabian StyleHernández-Nieves, Elena, Javier Parra-Domínguez, Pablo Chamoso, Sara Rodríguez-González, and Juan M. Corchado. 2021. "A Data Mining and Analysis Platform for Investment Recommendations" Electronics 10, no. 7: 859. https://doi.org/10.3390/electronics10070859