
Traffic Police Gesture Recognition Based on Gesture Skeleton Extractor and Multichannel Dilated Graph Convolution Network


Abstract
:1. Introduction
2. Related Work
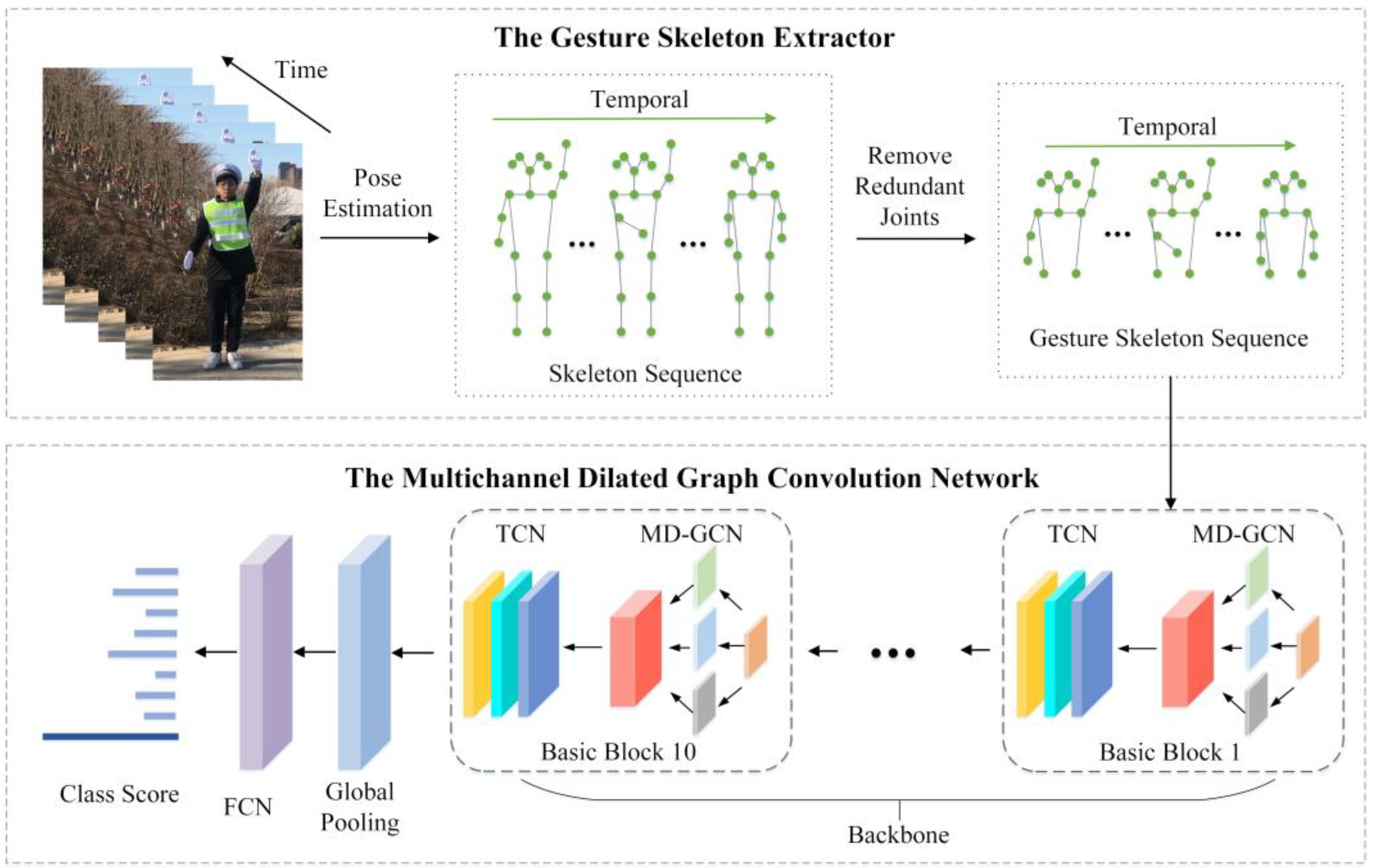
3. Overview of the Proposed Method
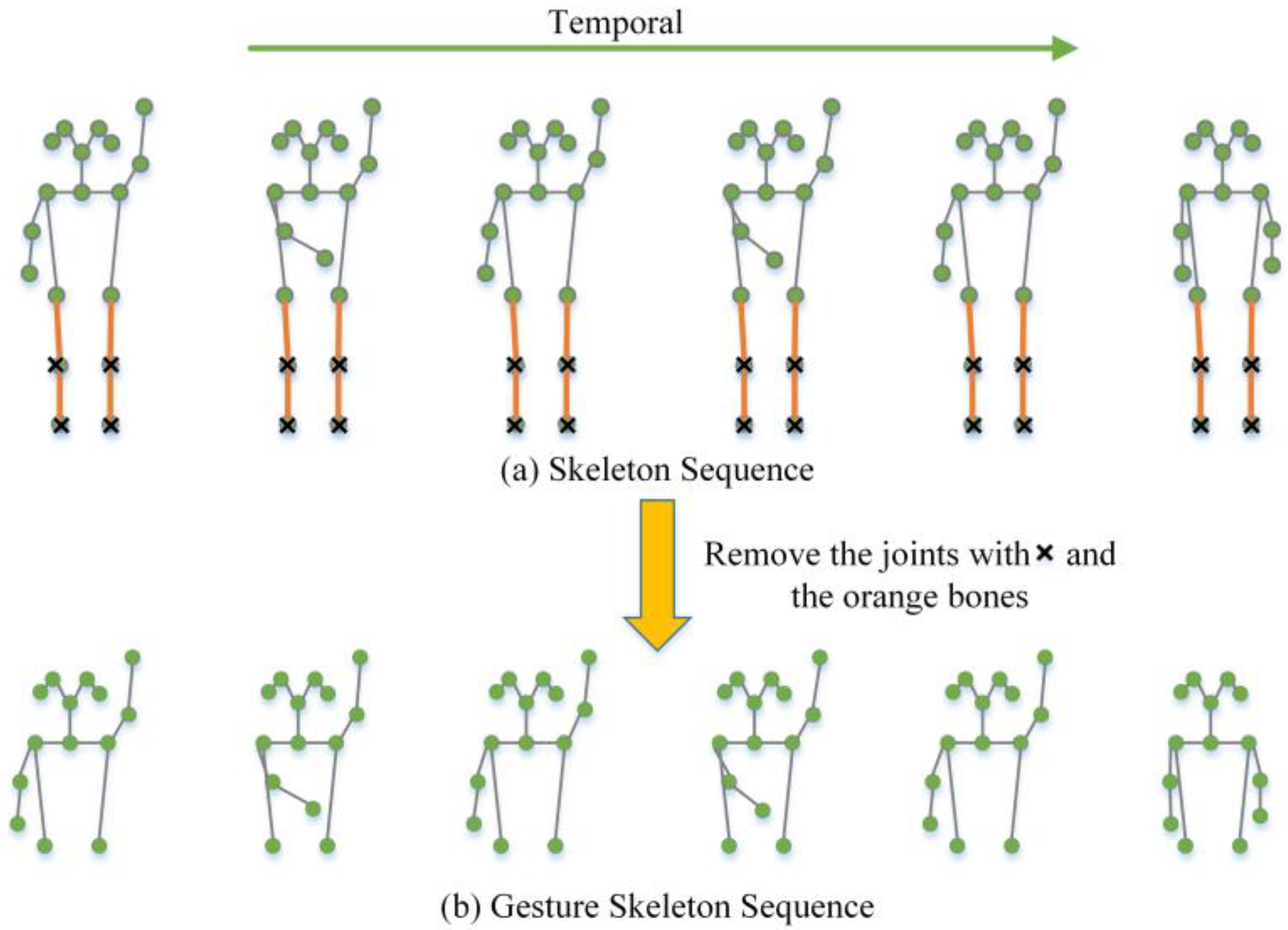
4. Gesture Skeleton Extractor
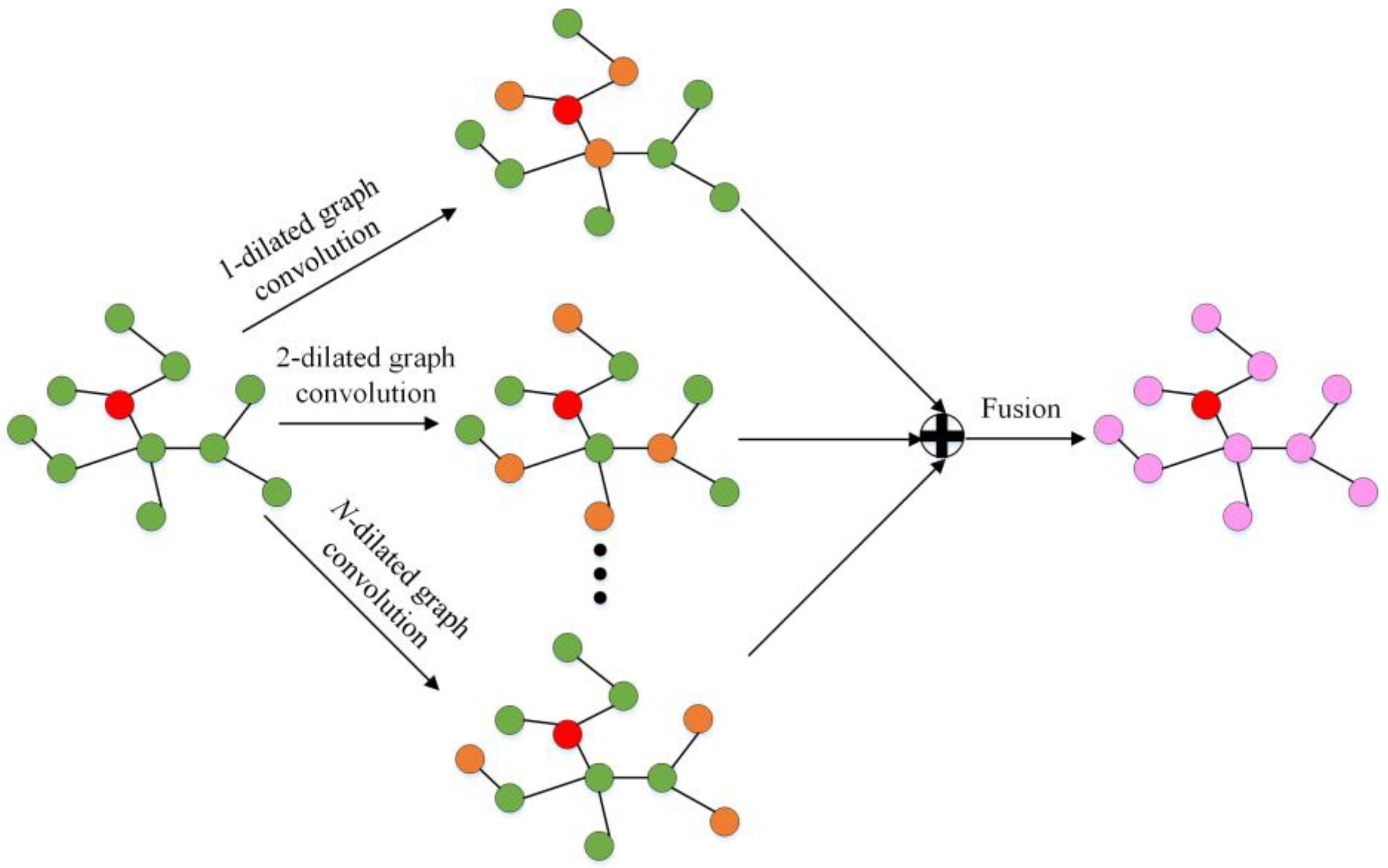
5. Multichannel Dilated Graph Convolution Network
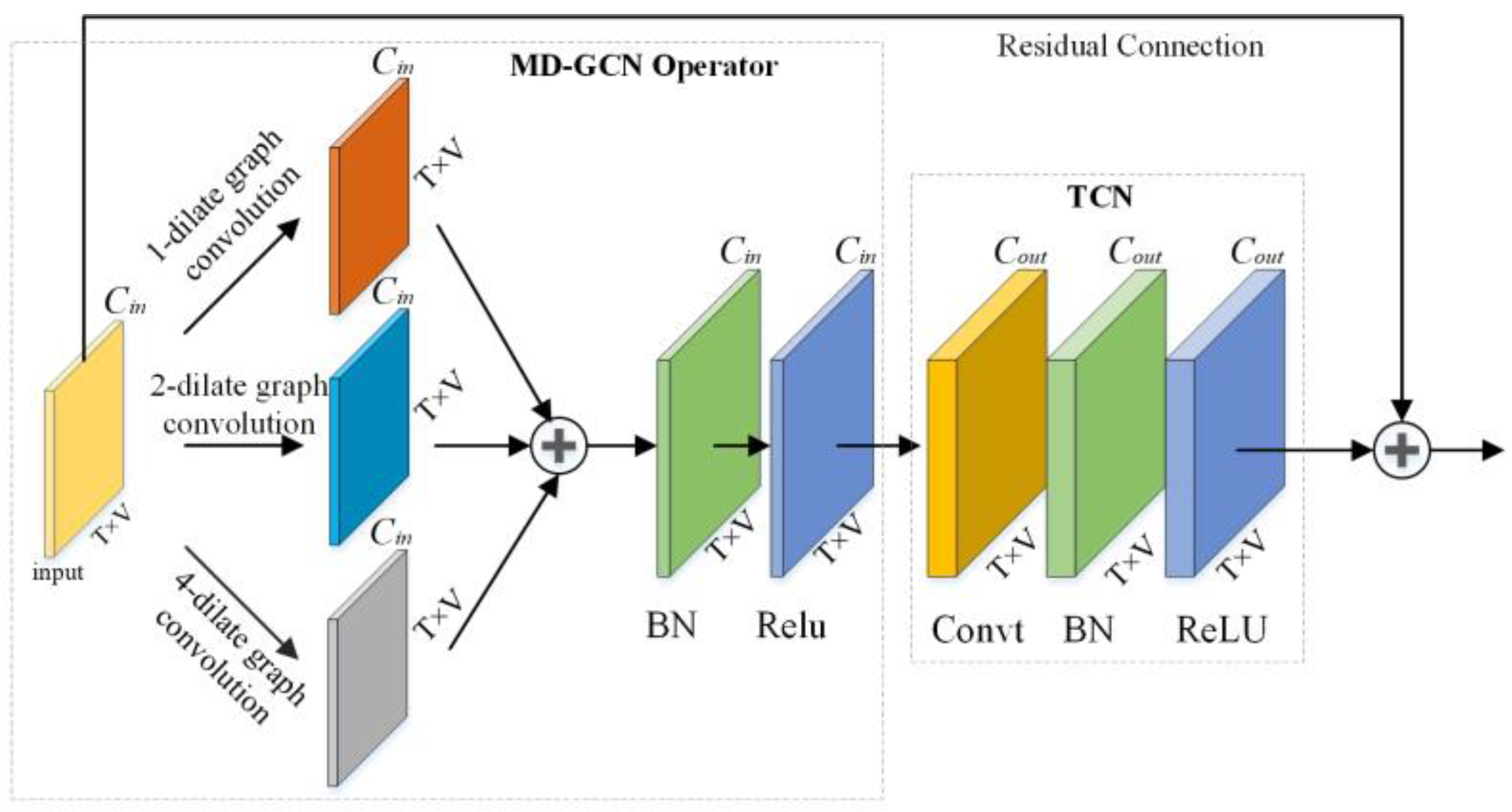
5.1. MD-GCN Operator
5.2. MD-GCN Classification Network
6. Experiments
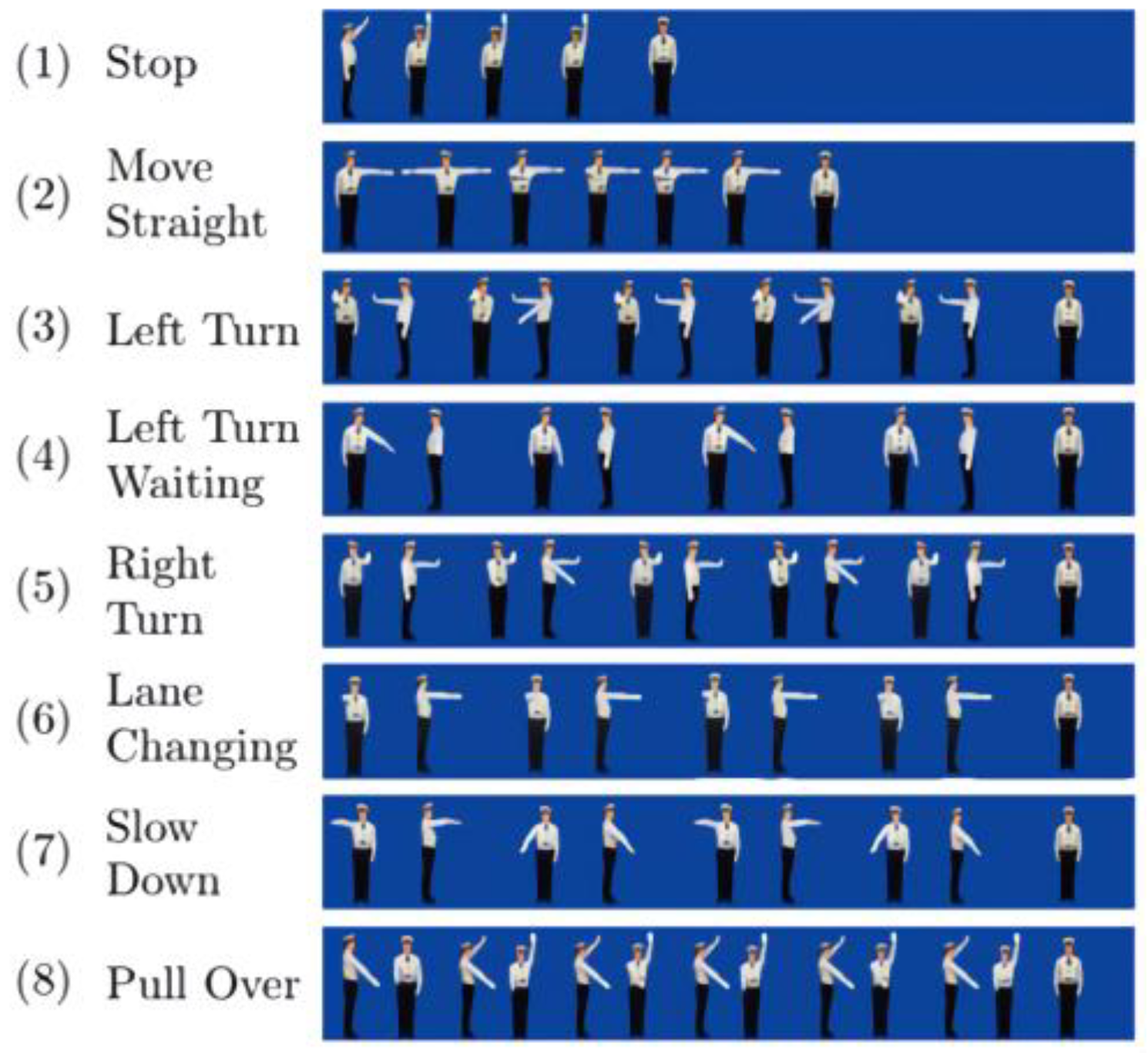
6.1. Dataset and Training Details
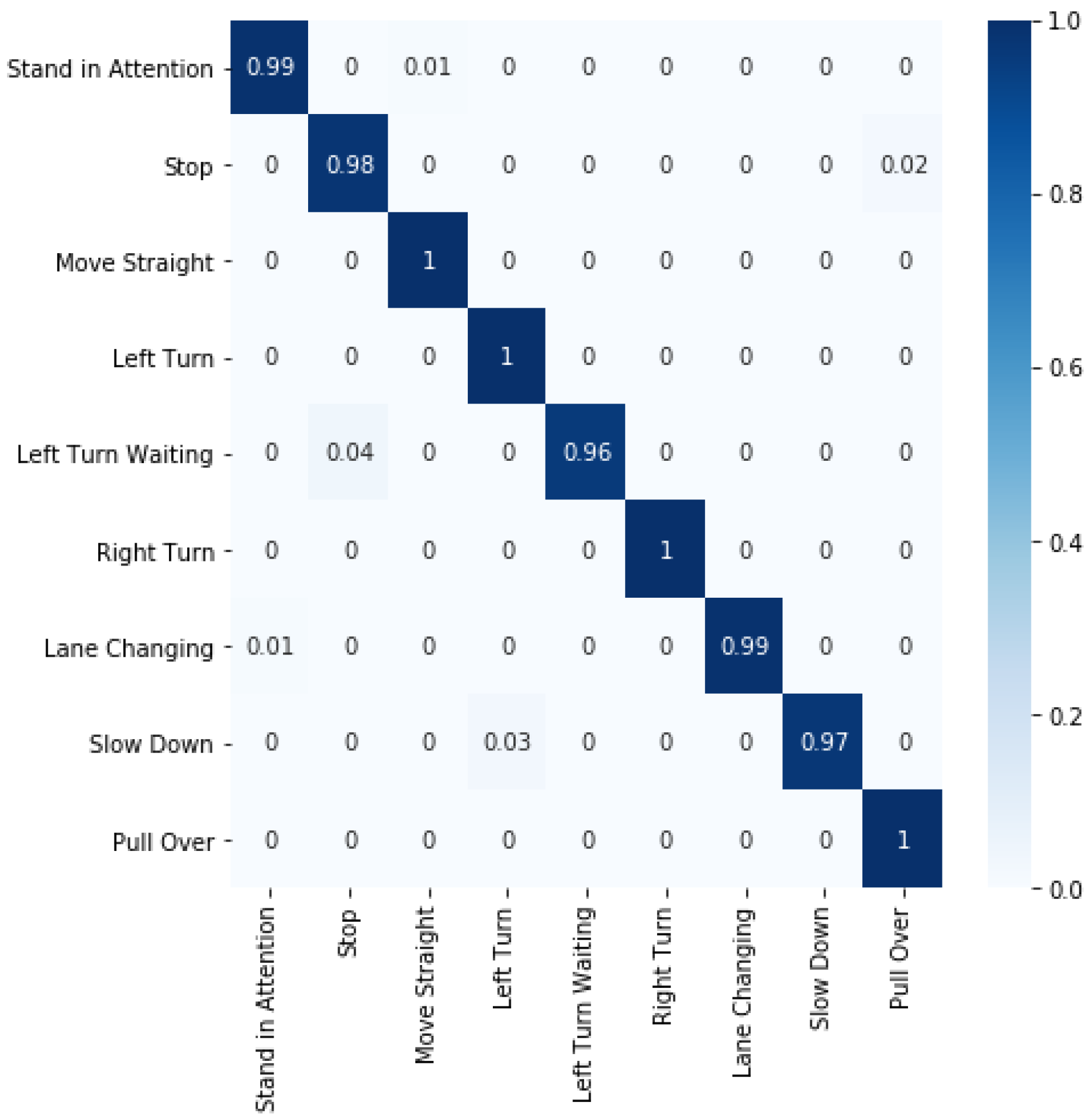
6.2. Evaluation of the Proposed Method
6.3. Comparison with State-of-the-Art Methods
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yang, H.; Liu, L.; Min, W.; Yang, X.; Xiong, X. Driver Yawning Detection Based on Subtle Facial Action Recognition. IEEE Trans. Multimed. 2021, 23, 572–583. [Google Scholar] [CrossRef]
- Zhou, L.; Min, W.; Lin, D.; Han, Q.; Liu, L. Detecting Motion Blurred Vehicle Logo in IoV Using Filter-DeblurGAN and VL-YOLO. IEEE Technol. 2020, 69, 3604–3614. [Google Scholar] [CrossRef]
- Xiong, X.; Min, W.; Zheng, W.S.; Liao, P.; Yang, H.; Wang, S. S3D-CNN: Skeleton-based 3D Consecutive-low-pooling Neu-ral Network for Fall Detection. Appl. Intell. 2020, 50, 3521–3534. [Google Scholar] [CrossRef]
- Sun, S.-W.; Liu, B.-Y.; Chang, P.-C. Deep Learning-Based Violin Bowing Action Recognition. Sensors 2020, 20, 5732. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Li, J.; Zhu, A.; Xu, Y.; Yin, H.; Hua, G. Enhanced Spatial and Extended Temporal Graph Convolutional Network for Skeleton-Based Action Recognition. Sensors 2020, 20, 5260. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Chen, E.; Gao, L.; Liang, C.; Liu, H. Energy-Guided Temporal Segmentation Network for Multimodal Human Action Recognition. Sensors 2020, 20, 4673. [Google Scholar] [CrossRef] [PubMed]
- Tsai, J.-K.; Hsu, C.-C.; Wang, W.-Y.; Huang, S.-K. Deep Learning-Based Real-Time Multiple-Person Action Recognition System. Sensors 2020, 20, 4758. [Google Scholar] [CrossRef] [PubMed]
- Ma, C.; Zhang, Y.; Wang, A.; Wang, Y.; Chen, G. Traffic Command Gesture Recognition for Virtual Urban Scenes Based on a Spatiotemporal Convolution Neural Network. ISPRS Int. J. Geo-Inf. 2018, 7, 37. [Google Scholar] [CrossRef] [Green Version]
- He, J.; Zhang, C.; He, X.; Dong, R. Visual Recognition of traffic police gestures with convolutional pose machine and handcrafted features. Neurocomputing 2020, 390, 248–259. [Google Scholar] [CrossRef]
- Li, C.; Yang, S. Traffic Police Gesture Recognition for Autonomous Driving. In Proceedings of the 2018 IEEE 4th International Conference on Computer and Communications (ICCC), Chengdu, China, 7–10 December 2018; pp. 1413–1418. [Google Scholar]
- Guan, W.; Ma, X. Traffic Police Gesture Recognition using RGB-D and Faster R-CNN. In Proceedings of the International Conference on Intelligent Informatics and Biomedical Sciences, Bangkok, Thailand, 21–24 October 2018; Volume 3, pp. 78–81. [Google Scholar]
- Hang, C.; Zhang, R.; Chen, Z.; Li, C.; Li, Z. Dynamic Gesture Recognition Method Based on Improved DTW Algorithm. In Proceedings of the 2017 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII), Wuhan, China, 2–3 December 2017; Volume 1, pp. 71–74. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised Classification with Graph Convolutional Networks. Available online: https://openreview.net/forum?id=SJU4ayYgl (accessed on 22 February 2017).
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Wu, J.; Zhong, S.-H.; Liu, Y. Dynamic graph convolutional network for multi-video summarization. Pattern Recognit. 2020, 107, 107382. [Google Scholar] [CrossRef]
- Yang, L.; Guo, Y.; Gu, J.; Jin, D.; Yang, B.; Cao, X. Probabilistic Graph Convolutional Network via Topology-Constrained Latent Space Model. IEEE Trans. Cybern. 2021, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Henrickson, K.; Ke, R.; Wang, Y. Traffic Graph Convolutional Recurrent Neural Network: A Deep Learning Frame-work for Network-Scale Traffic Learning and Forecasting. IEEE Intell. Transp. 2020, 21, 4883–4894. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Yuan, T. Traffic Police Gesture Recognition using Accelerometer. In Proceedings of the IEEE Sensors Conference, Lecce, Italy, 26–29 October 2008; pp. 1080–1083. [Google Scholar]
- Tao, Y.; Ben, W. Accelerometer-based Chinese Traffic Police Gesture Recognition System. Chin. J. Electron. 2010, 19, 270–274. [Google Scholar]
- Le, Q.K.; Pham, C.H.; Le, T.H. Road Traffic Control Gesture Recognition using Depth Images. IEIE Trans. Smart Process. Comput. 2020, 1, 1–7. [Google Scholar]
- Guo, F.; Tang, J.; Wang, X. Gesture recognition of traffic police based on static and dynamic descriptor fusion. Multimed. Tools Appl. 2017, 76, 8915–8936. [Google Scholar] [CrossRef]
- Guo, F.; Tang, J.; Cai, Z. Automatic Recognition of Chinese Traffic Police Gesture Based on Max-Covering Scheme. Int. J. Adv. Inf. Sci. Serv. Sci. 2013, 5, 428–436. [Google Scholar] [CrossRef]
- Cai, Z.; Guo, F. Max-covering scheme for gesture recognition of Chinese traffic police. Pattern Anal. Appl. 2014, 18, 403–418. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar]
- Wei, S.-E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional Pose Machines. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Volume 1, pp. 4724–4732. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-person Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Su, K.; Yu, D.; Xu, Z.; Geng, X.; Wang, C. Multi-Person Pose Estimation with Enhanced Channel-Wise and Spatial Information. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 9 May 2019; pp. 5667–5675. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5686–5696. [Google Scholar]
- Nie, X.; Feng, J.; Zhang, J.; Yan, S. Single-Stage Multi-Person Pose Machines. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–3 November 2019; pp. 6950–6959. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.-T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. Available online: https://arxiv.org/abs/1705.06950 (accessed on 19 May 2017).
- Hara, K.; Kataoka, H.; Satoh, Y. Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 3154–3160. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Net-works. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5534–5542. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K. Convolutional Lstm Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Pigou, L.; Oord, A.V.D.; Dieleman, S.; Van Herreweghe, M.; Dambre, J. Beyond Temporal Pooling: Recurrence and Temporal Convolutions for Gesture Recognition in Video. Int. J. Comput. Vis. 2018, 126, 430–439. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.S.; Reiter, A. Interpretable 3D Human Action Analysis with Temporal Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1623–1631. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A New Representation of Skeleton Sequences for 3D Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4570–4579. [Google Scholar]
- Tang, Y.; Tian, Y.; Lu, J.; Li, P.; Zhou, J. Deep Progressive Reinforcement Learning for Skeleton-Based Action Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5323–5332. [Google Scholar]
- Wen, Y.-H.; Gao, L.; Fu, H.; Zhang, F.-L.; Xia, S. Graph CNNs with Motif and Variable Temporal Block for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence; Association for the Advancement of Artificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8989–8996. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-Structural Graph Convolutional Networks for Skele-ton-based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3590–3598. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MD-GCN Operator | Accuracy (%) | Model Size | Training Time (s) | Inference Time (s) |
|---|---|---|---|---|
| With dilated rate = 1 | 97.32 | 10 M | 532 | 2.5 |
| With dilated rate = 2 | 96.35 | 10 M | 537 | 2.8 |
| With dilated rate = 3 | 96.13 | 10 M | 534 | 2.5 |
| With dilated rate = 4 | 95.38 | 10 M | 528 | 2.3 |
| With dilated rate = 1, 2, 3 | 98.05 | 11.7 M | 603 | 3.0 |
| With dilated rate = 1, 2, 4 | 98.95 | 11.7 M | 602 | 3.0 |
| With dilated rate = 1, 3, 4 | 97.76 | 11.7 M | 620 | 3.3 |
| With dilated rate = 2, 3, 4 | 96.71 | 11.7 M | 617 | 3.1 |
| With dilated rate = 1, 2, 3, 4 | 98.08 | 12.5 M | 718 | 3.9 |
| Method | Accuracy (%) | Training Time (s) | Inference Time (s) |
|---|---|---|---|
| With GSE | 98.95 | 603 | 3.0 |
| Without GSE | 98.01 | 691 | 3.3 |
| Method | Accuracy (%) |
|---|---|
| Hara [33] | 81.16 |
| Tran [34] | 87.12 |
| Qiu [35] | 92.21 |
| Xing [36] | 82.40 |
| Zhang [9] | 91.18 |
| Pigou [37] | 91.04 |
| The proposed method | 98.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, X.; Wu, H.; Min, W.; Xu, J.; Fu, Q.; Peng, C. Traffic Police Gesture Recognition Based on Gesture Skeleton Extractor and Multichannel Dilated Graph Convolution Network. Electronics 2021, 10, 551. https://doi.org/10.3390/electronics10050551
Xiong X, Wu H, Min W, Xu J, Fu Q, Peng C. Traffic Police Gesture Recognition Based on Gesture Skeleton Extractor and Multichannel Dilated Graph Convolution Network. Electronics. 2021; 10(5):551. https://doi.org/10.3390/electronics10050551
Chicago/Turabian StyleXiong, Xin, Haoyuan Wu, Weidong Min, Jianqiang Xu, Qiyan Fu, and Chunjiang Peng. 2021. "Traffic Police Gesture Recognition Based on Gesture Skeleton Extractor and Multichannel Dilated Graph Convolution Network" Electronics 10, no. 5: 551. https://doi.org/10.3390/electronics10050551