
Automatic Melody Harmonization via Reinforcement Learning by Exploring Structured Representations for Melody Sequences


Abstract
:1. Introduction
- to employ reinforcement learning, for the first time, to discover substructures in melody for symbolic melody harmonization;
- based on the discovery of substructures, to deal with the tasks of segmentation and harmonization by learning structured representations of the given symbolic melody;
- through experiments using our processed dataset to show that our proposed method outperforms other baseline methods.
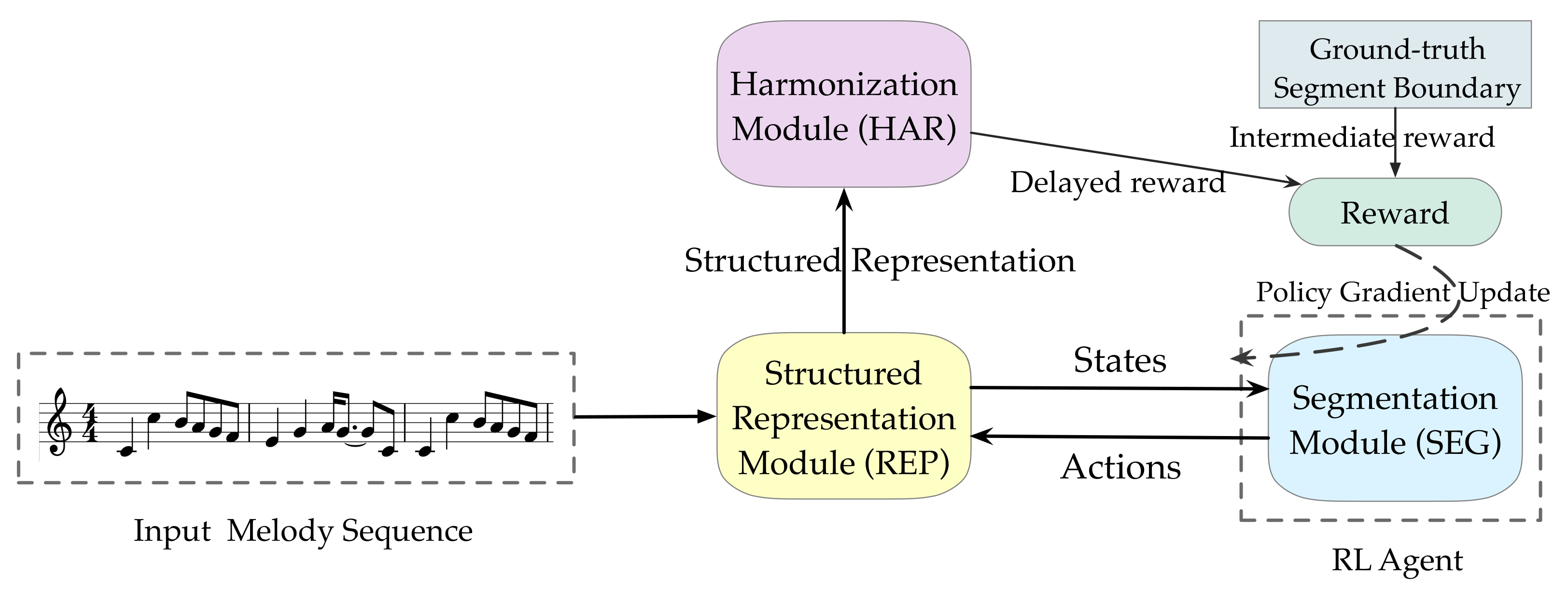
2. Model
2.1. Symbolic Melody Encoding
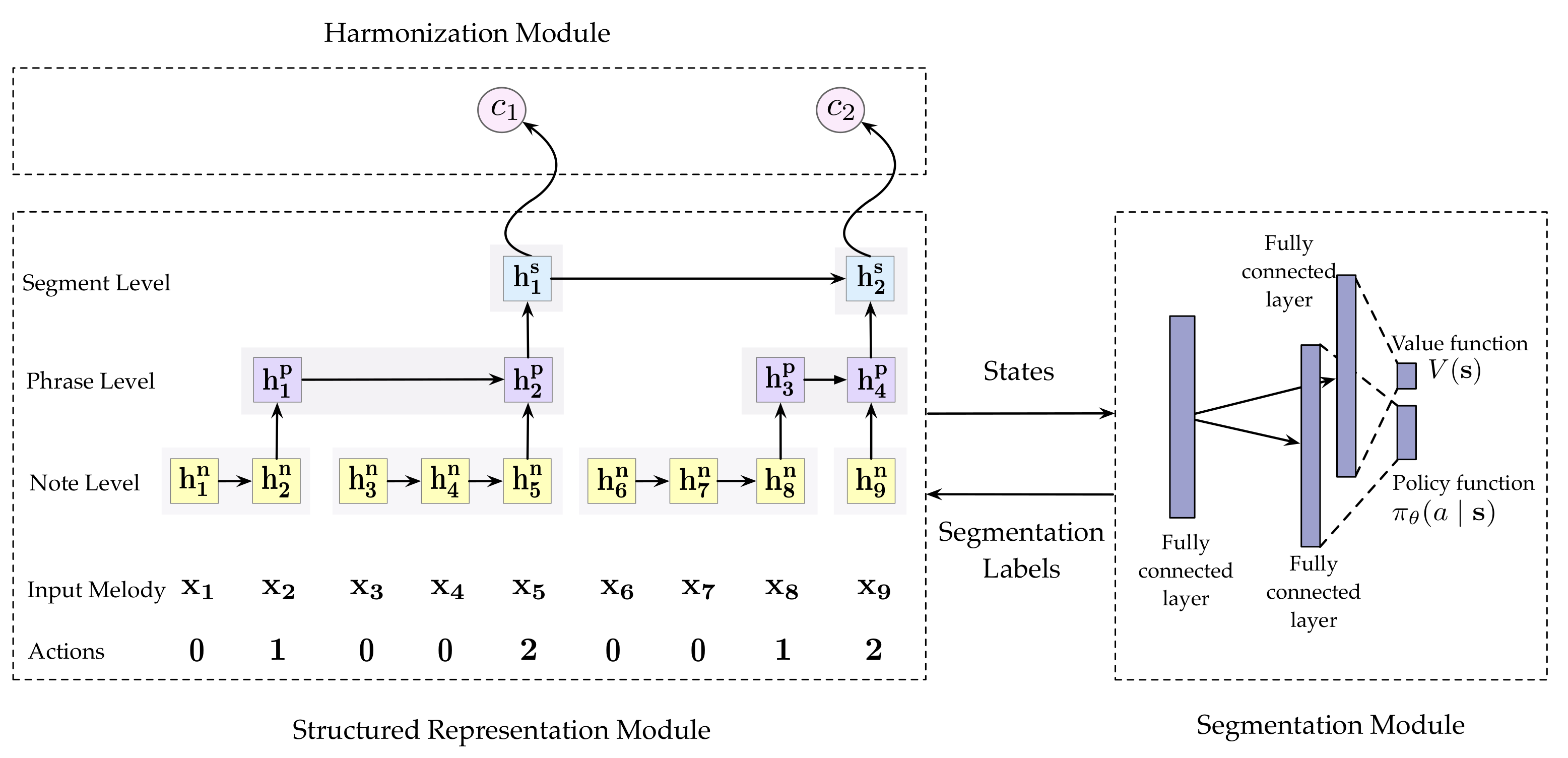
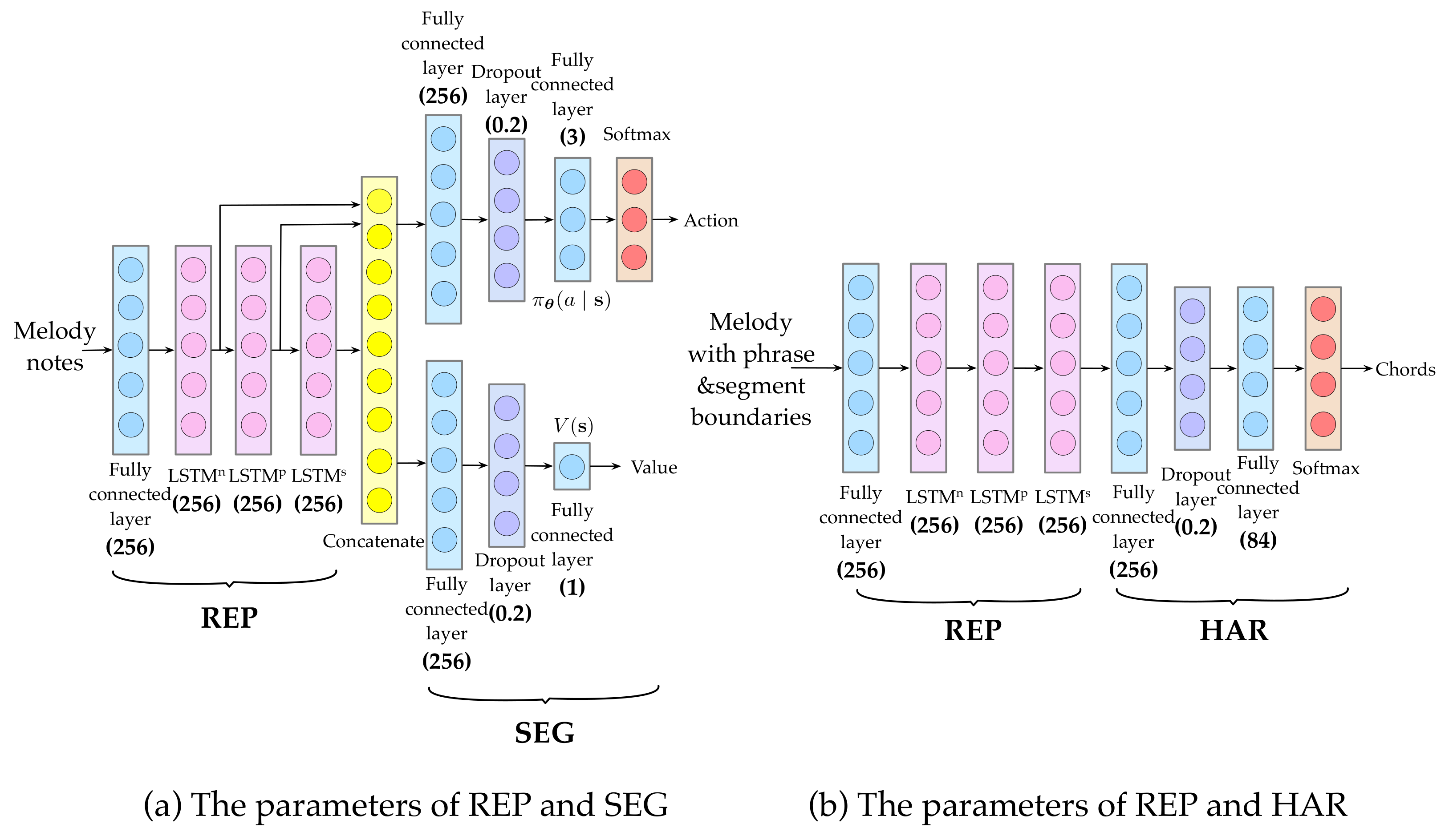
2.2. Structured Representation Module
2.3. Segmentation Module
| Algorithm 1: Training Process of Segmentation Policy Module with A2C |
|
2.4. Melody Harmonization Module
2.5. Training Details
3. Experiments and Results
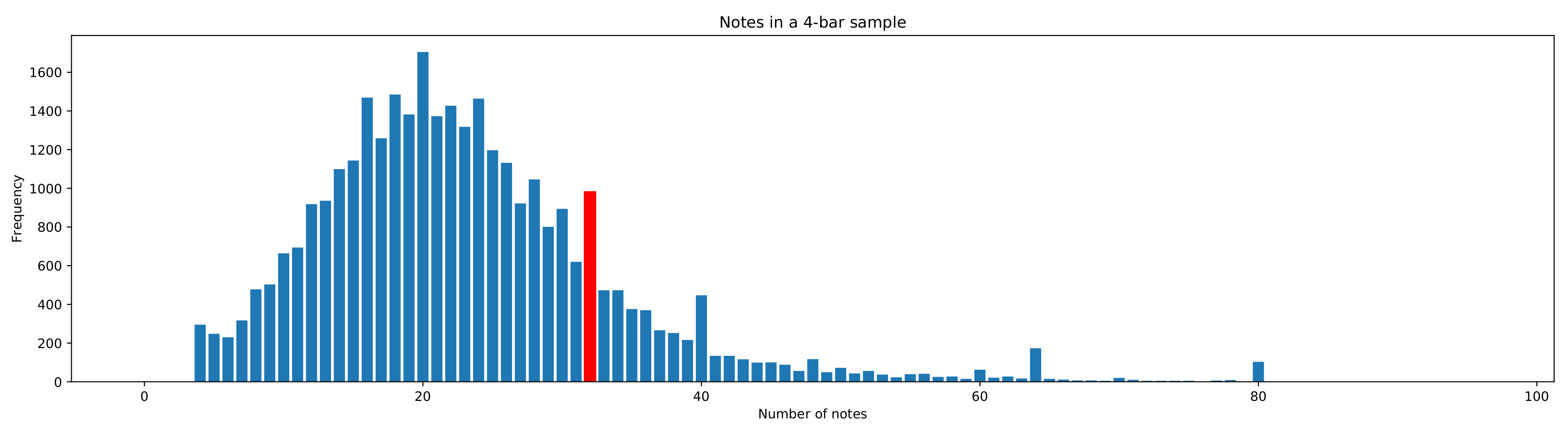
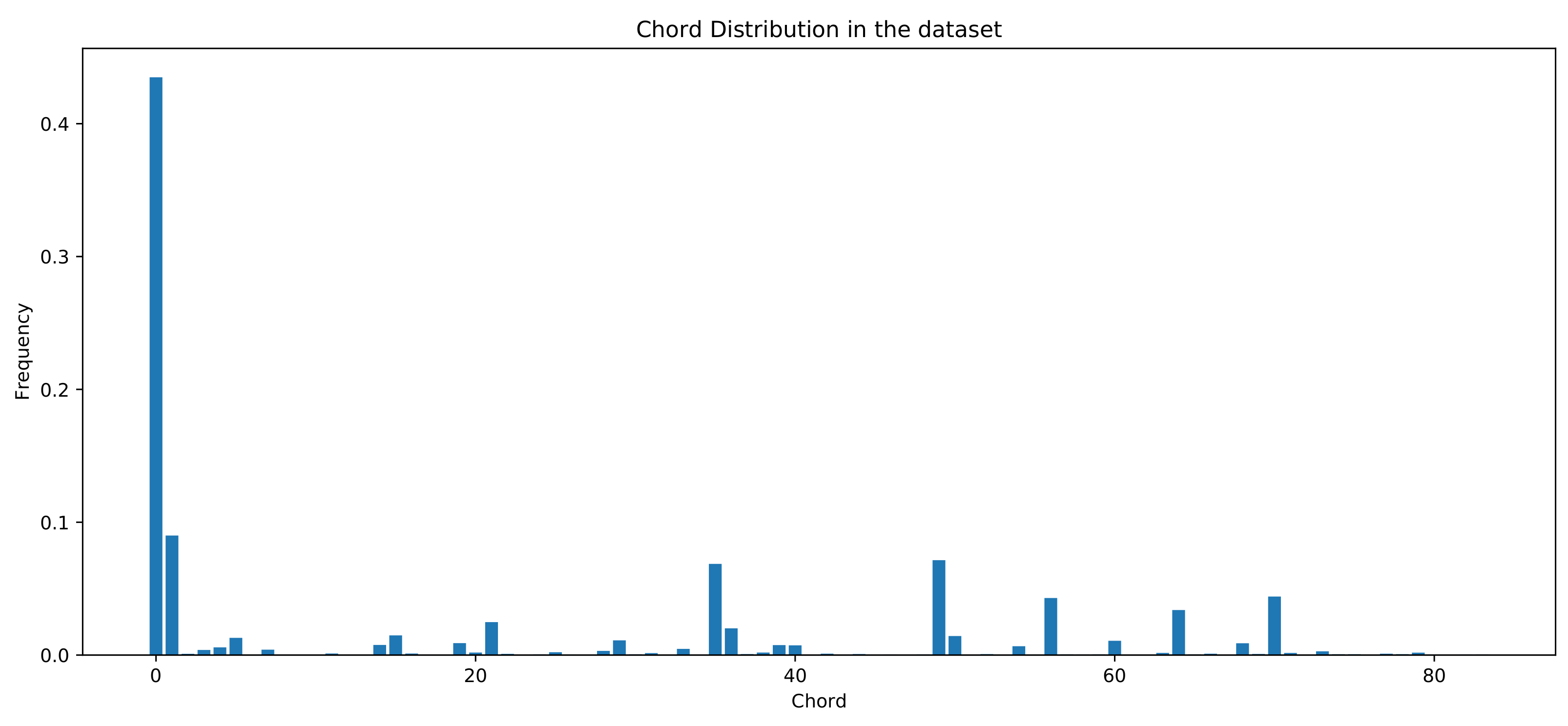
3.1. Dataset
3.2. Experiment Settings
3.3. Harmonization Results
3.3.1. Baselines
- SVM: Support Vector Machines (SVMs) [33] are a traditional machine learning method for classification problems. We applied the C-Support Vector Classification (SVC) algorithm in our harmonization task with its default configurations provided by the scikit-learn library [34]. As we have 84 possible classes when generating the target chords, the decision function type is set as “ovo” (one versus one strategy) in SVC, which is always employed in multi-class strategy.
- CNN: Convolution Neural Networks have been widely used in music generation tasks. We built the CNN architecture with two 2D convolution layers. The first one is constructed with a kernel size of and followed by a pooling layer of size . The second one has a kernel size of , also followed by a pooling layer of size .
- LSTM: LSTM is specialized for processing sequential data. For the experimental setting, a time-distributed input layer is built before the LSTM layer. The input layer has 13 units, representing the sequence of note feature vectors. The one-layer baseline LSTM network has 128 units (to be compared with BiLSTM+BGS), whose output is then fed into a fully-connected output layer with 84 units, representing the generated chord sequence.
- BiLSTM+BGS: A BiLSTM-based model with blocked Gibbs sampling was proposed in [15] for melody harmonization. In their work, the melody and partially masked chord sequences were fed into the model and the model was expected to learn the masked chord ground truth. We adopted the blocked Gibbs sampling strategy, which was used in [15] to mask the chord sequences. The sampling process uses an annealed masking probability as the proportion to randomly select chords to be masked. Formally,where is the proportion of variables that remain unchanged at iteration i, N is the total number of iterations and set to 128 (the averaged length of chord sequences in each batch) and . We employed the architecture proposed in their work with our proposed melody feature representation (13-dimensional vector). The masked chord ground truth and melody context are fed into their model and concatenated together. The concatenated context is then sent to a two-layer BiLSTM with hidden size of 64 (the same as [15]), followed by a dropout layer and a fully-connected output layer with 84 units.
3.3.2. Metrics
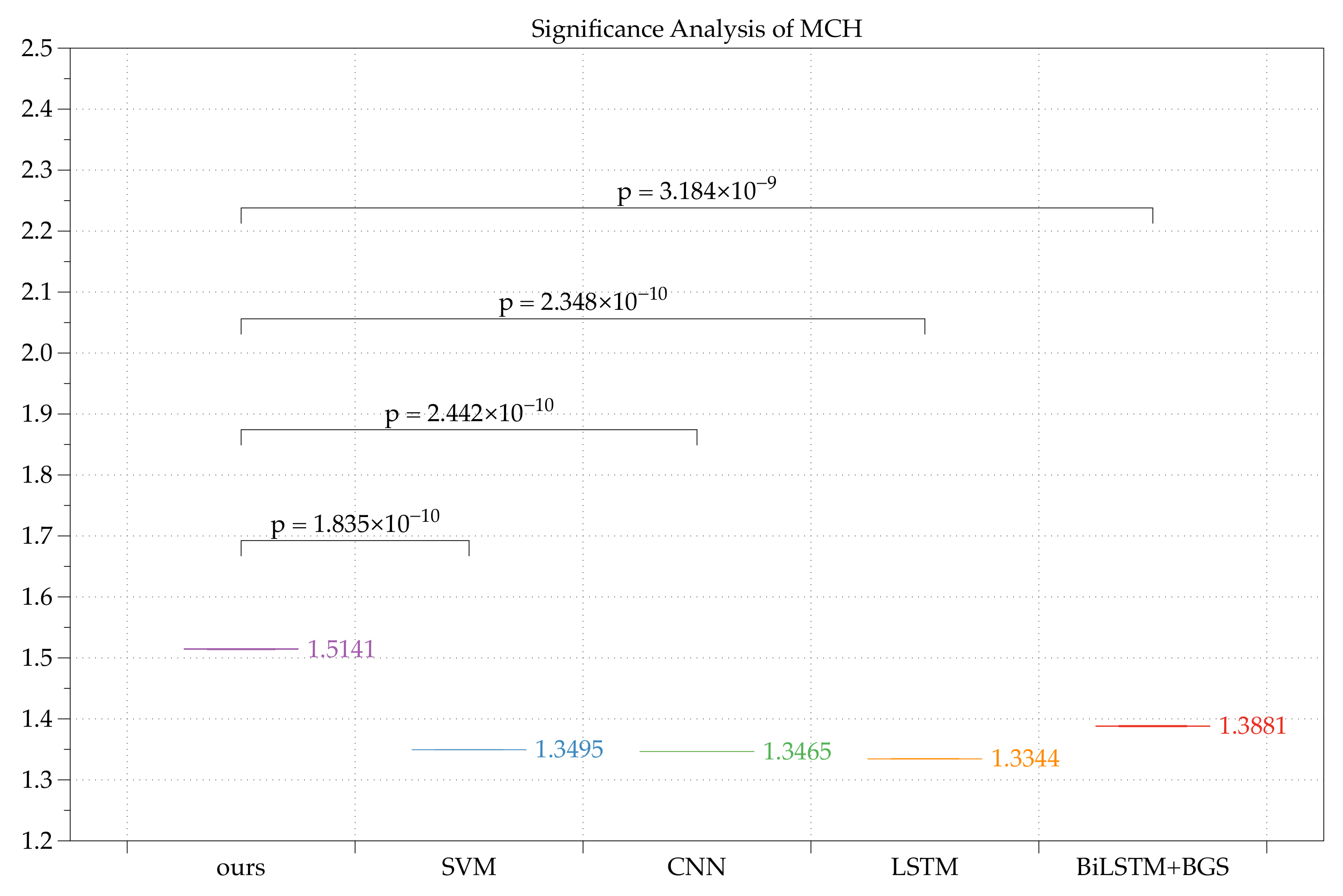
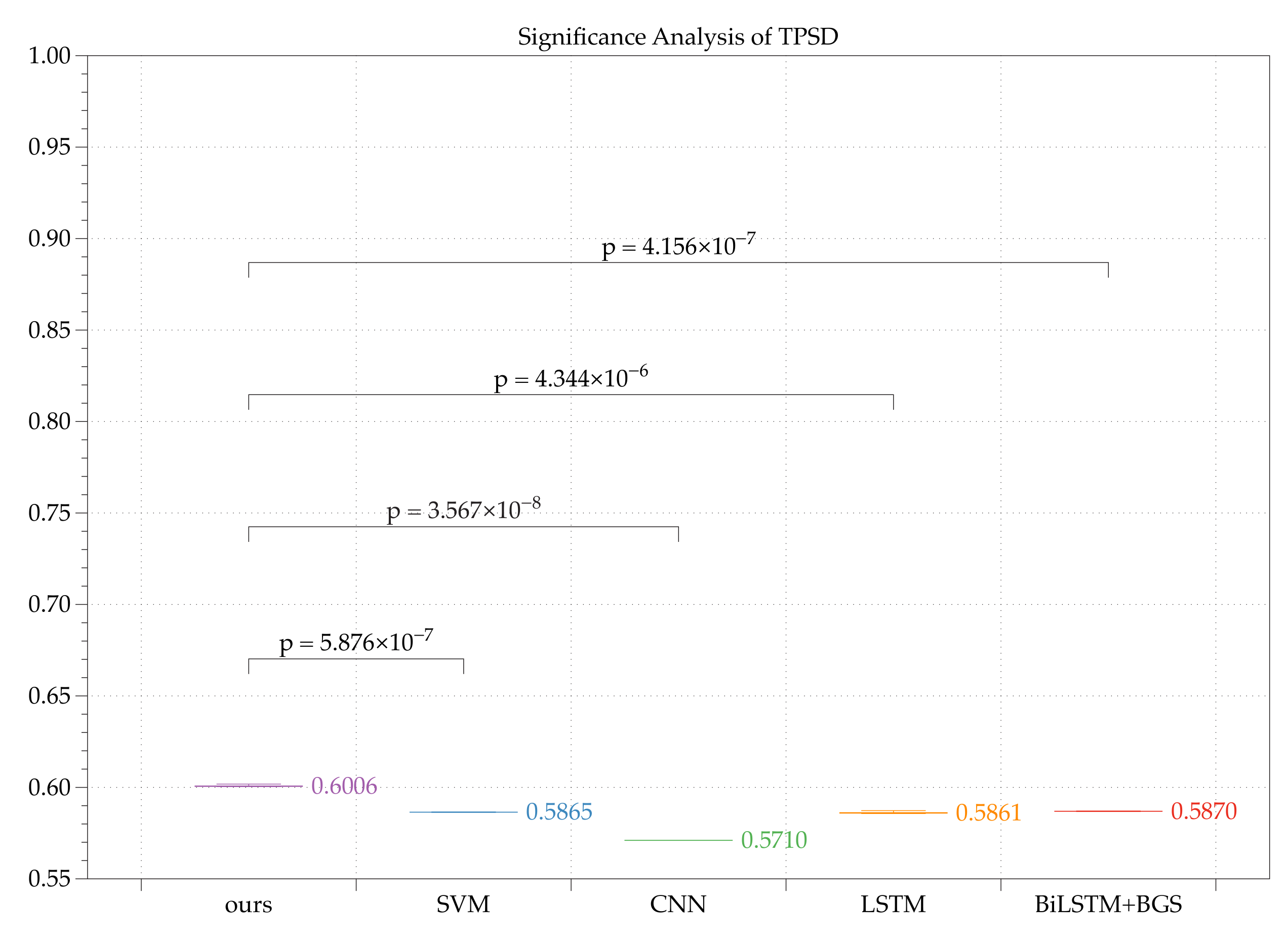
3.3.3. Results
3.4. Structure Analysis
3.4.1. Baselines
3.4.2. Metrics
3.4.3. Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jackson, R. The computer as a “student” of harmony. In Proceedings of the Tenth Congress of the International Musicological Society, Ljubljana, Yugoslavia, 3–8 September 1967. [Google Scholar]
- Ebcioglu, K. An Expert System for Chorale Harmonization. In Proceedings of the Fifth National Conference on Artificial Intelligence, Philadelphia, PA, USA, 11–15 August 1986; pp. 784–788. [Google Scholar]
- Evans, B.; Fukayama, S.; Goto, M.; Munekata, N.; Ono, T. Autochoruscreator: Four-part chorus generator with musical feature control, using search spaces constructed from rules of music theory. In Proceedings of the 40th International Computer Music Conference, Athens, Greece, 14–20 September 2014. [Google Scholar]
- Sarabia, M.; Lee, K.; Demiris, Y. Towards a synchronised Grammars framework for adaptive musical human-robot collaboration. In Proceedings of the 2015 24th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Kobe, Japan, 31 August–4 September 2015; pp. 715–721. [Google Scholar]
- Jaques, N.; Gu, S.; Bahdanau, D.; Hernández-Lobato, J.M.; Turner, R.E.; Eck, D. Sequence tutor: Conservative fine-tuning of sequence generation models with kl-control. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 1645–1654. [Google Scholar]
- Hadjeres, G.; Pachet, F.; Nielsen, F. Deepbach: A steerable model for bach chorales generation. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1362–1371. [Google Scholar]
- Brunner, G.; Wang, Y.; Wattenhofer, R.; Wiesendanger, J. JamBot: Music theory aware chord based generation of polyphonic music with LSTMs. In Proceedings of the 2017 IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), Boston, MA, USA, 6–8 November 2017; pp. 519–526. [Google Scholar]
- Shukla, S.; Banka, H. An automatic chord progression generator based on reinforcement learning. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 55–59. [Google Scholar]
- Simon, I.; Morris, D.; Basu, S. MySong: Automatic accompaniment generation for vocal melodies. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Florence, Italy, 5–10 April 2008; pp. 725–734. [Google Scholar]
- Tsushima, H.; Nakamura, E.; Itoyama, K.; Yoshii, K. Interactive Arrangement of Chords and Melodies Based on a Tree-Structured Generative Model. In Proceedings of the 19th International Society for Music Information Retrieval Conference will take place, Paris, France, 23–27 September 2018. [Google Scholar]
- Tsushima, H.; Nakamura, E.; Yoshii, K. Bayesian Melody Harmonization Based on a Tree-Structured Generative Model of Chord Sequences and Melodies. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2020, 28, 1644–1655. [Google Scholar] [CrossRef]
- Raczyński, S.A.; Fukayama, S.; Vincent, E. Melody harmonization with interpolated probabilistic models. J. New Music. Res. 2013, 42, 223–235. [Google Scholar] [CrossRef]
- Lim, H.; Rhyu, S.; Lee, K. Chord generation from symbolic melody using BLSTM networks. arXiv 2017, arXiv:1712.01011. [Google Scholar]
- Yeh, Y.C.; Hsiao, W.Y.; Fukayama, S.; Kitahara, T.; Genchel, B.; Liu, H.M.; Dong, H.W.; Chen, Y.; Leong, T.; Yang, Y. Automatic Melody Harmonization with Triad Chords: A Comparative Study. arXiv 2020, arXiv:abs/2001.02360. [Google Scholar]
- Sun, C.E.; Chen, Y.W.; Lee, H.S.; Chen, Y.H.; Wang, H.M. Melody Harmonization Using Orderless NADE, Chord Balancing and Blocked Gibbs Sampling. arXiv 2020, arXiv:2010.13468. [Google Scholar]
- Ahlbäck, S. Melody beyond Notes: A Study of Melody Cognition. Ph.D. Thesis, Göteborgs Universitet, Göteborgs, Sweden, 2004. [Google Scholar]
- Deliege, I. Grouping Conditions in Listening to Music: An Approach to Lerdahl & Jackendoff’s Grouping Preference Rules. Music. Perception Interdiscip. J. 1987, 4, 325–359. [Google Scholar]
- Lerdahl, F.; Jackendoff, R. A Generative Theory of Tonal Music; The MIT Press: Cambridge, MA, USA, 1983. [Google Scholar]
- Stein, L. Structure and Style: The Study and Analysis of Musical Forms; Summy-Birchard Company: Evanston, IL, USA, 1962. [Google Scholar]
- Temperley, D. End-accented phrases: An analytical exploration. J. Music Theory 2003, 47, 125–154. [Google Scholar] [CrossRef] [Green Version]
- Moore, A. The so-called ‘flattened seventh’in rock. Pop. Music. 1995, 14, 185–201. [Google Scholar] [CrossRef]
- Guan, Y.; Zhao, J.; Qiu, Y.; Zhang, Z.; Xia, G. Melodic Phrase Segmentation By Deep Neural Networks. 2018. Available online: https://arxiv.org/abs/1811.05688 (accessed on 4 October 2021).
- Hirai, T.; Sawada, S. Melody2vec: Distributed representations of melodic phrases based on melody segmentation. J. Inf. Process. 2019, 27, 278–286. [Google Scholar] [CrossRef] [Green Version]
- Sawada, S.; Yoshii, K.; Hirata, K. Unsupervised Melody Segmentation Based on a Nested Pitman-Yor Language Model. In Proceedings of the 1st Workshop on NLP for Music and Audio (NLP4MusA), Online, 16–17 October 2020; pp. 59–63. [Google Scholar]
- Jiang, N.; Jin, S.; Duan, Z.; Zhang, C. RL-Duet: Online Music Accompaniment Generation Using Deep Reinforcement Learning. Proc. Aaai Conf. Artif. Intell. 2020, 34, 710–718. [Google Scholar] [CrossRef]
- Zhang, T.; Huang, M.; Zhao, L. Learning structured representation for text classification via reinforcement learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Jiang, N.; Jin, S.; Duan, Z.; Zhang, C. When Counterpoint Meets Chinese Folk Melodies. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Barcelona, Spain, 2020; Volume 33, pp. 16258–16270. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Greensmith, E.; Bartlett, P.L.; Baxter, J. Variance Reduction Techniques for Gradient Estimates in Reinforcement Learning. J. Mach. Learn. Res. 2004, 5, 1471–1530. [Google Scholar]
- Cenkerová, Z.; Hartmann, M.; Toiviainen, P. Crossing phrase boundaries in music. In Proceedings of the Sound and Music Computing Conferences, Limassol, Cyprus, 4–7 July 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Harte, C.; Sandler, M.; Gasser, M. Detecting harmonic change in musical audio. In Proceedings of the 1st ACM Workshop on Audio and Music Computing Multimedia, Santa Barbara, CA, USA, 27 October 2006; pp. 21–26. [Google Scholar]
- Lerdahl, F. Tonal Pitch Space. Music. Perception: Interdiscip. J. 1988, 5, 315–349. [Google Scholar] [CrossRef]
- Sleator, D.; Temperley, D. The Melisma Music Analyzer. Available online: https://www.link.cs.cmu.edu/music-analysis/. (accessed on 4 October 2021).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Acc. | MCH↓ | TPSD↑ |
|---|---|---|---|
| original dataset | 100.00% | 1.5262 | 1.0000 |
| SVM | 25.16% | 1.3495 | 0.5865 |
| CNN | 26.64% | 1.3465 | 0.5710 |
| LSTM | 28.02% | 1.3344 | 0.5860 |
| BiLSTM+BGS [15] | 29.33% | 1.3881 | 0.5870 |
| REP+HAR(ours) | 37.42% | 1.5141 | 0.6006 |
| Method | WA↑ | WAR↑ | P↑ | R↑ | F1↑ |
|---|---|---|---|---|---|
| Melisma | — | 26.81% | 35.93% | 20.12% | 25.80% |
| REP+HAR+REINFORCE | 23.96% | 30.85% | 86.36% | 54.18% | 66.58% |
| REP+HAR+A2C | 25.76% | 34.63% | 86.56% | 54.13% | 66.61% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, T.; Lau, F.C.M. Automatic Melody Harmonization via Reinforcement Learning by Exploring Structured Representations for Melody Sequences. Electronics 2021, 10, 2469. https://doi.org/10.3390/electronics10202469
Zeng T, Lau FCM. Automatic Melody Harmonization via Reinforcement Learning by Exploring Structured Representations for Melody Sequences. Electronics. 2021; 10(20):2469. https://doi.org/10.3390/electronics10202469
Chicago/Turabian StyleZeng, Te, and Francis C. M. Lau. 2021. "Automatic Melody Harmonization via Reinforcement Learning by Exploring Structured Representations for Melody Sequences" Electronics 10, no. 20: 2469. https://doi.org/10.3390/electronics10202469