
Edge Container for Speech Recognition


Abstract
:1. Introduction
- Architecture of speech-controlled solution using edge computing and containerization;
- Solution running in Linux containers with a focus on automatic setup of all required dependencies and libraries;
- Simple adaptation of voice commands using a configuration file;
- Easy deployment and management of the solution;
- Portability, low latency and data privacy.
2. Background of Speech Recognition, Edge Computing and Containerization
2.1. Speech-to-Text Libraries
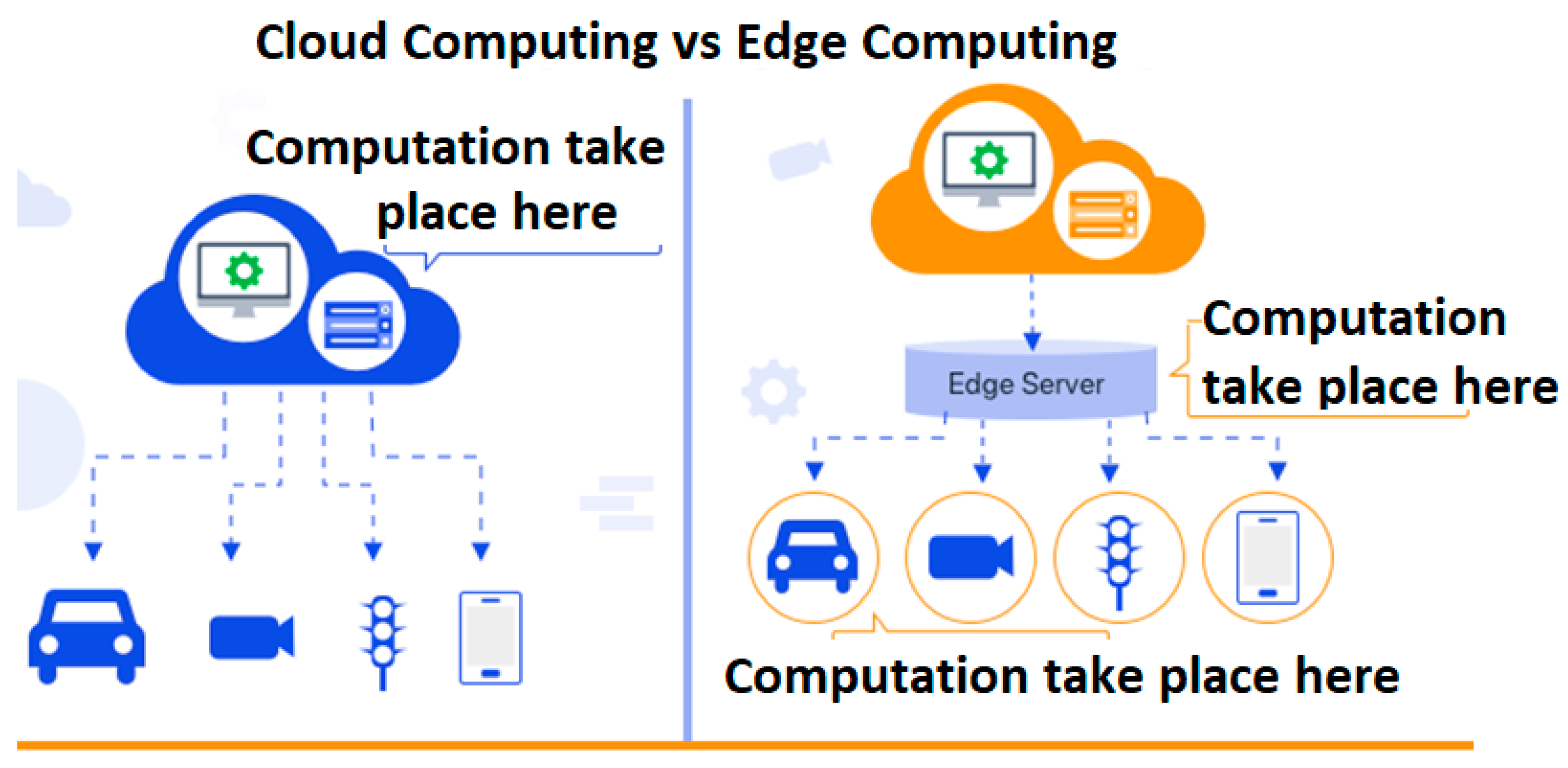
2.2. Edge Computing vs. Cloud Computing
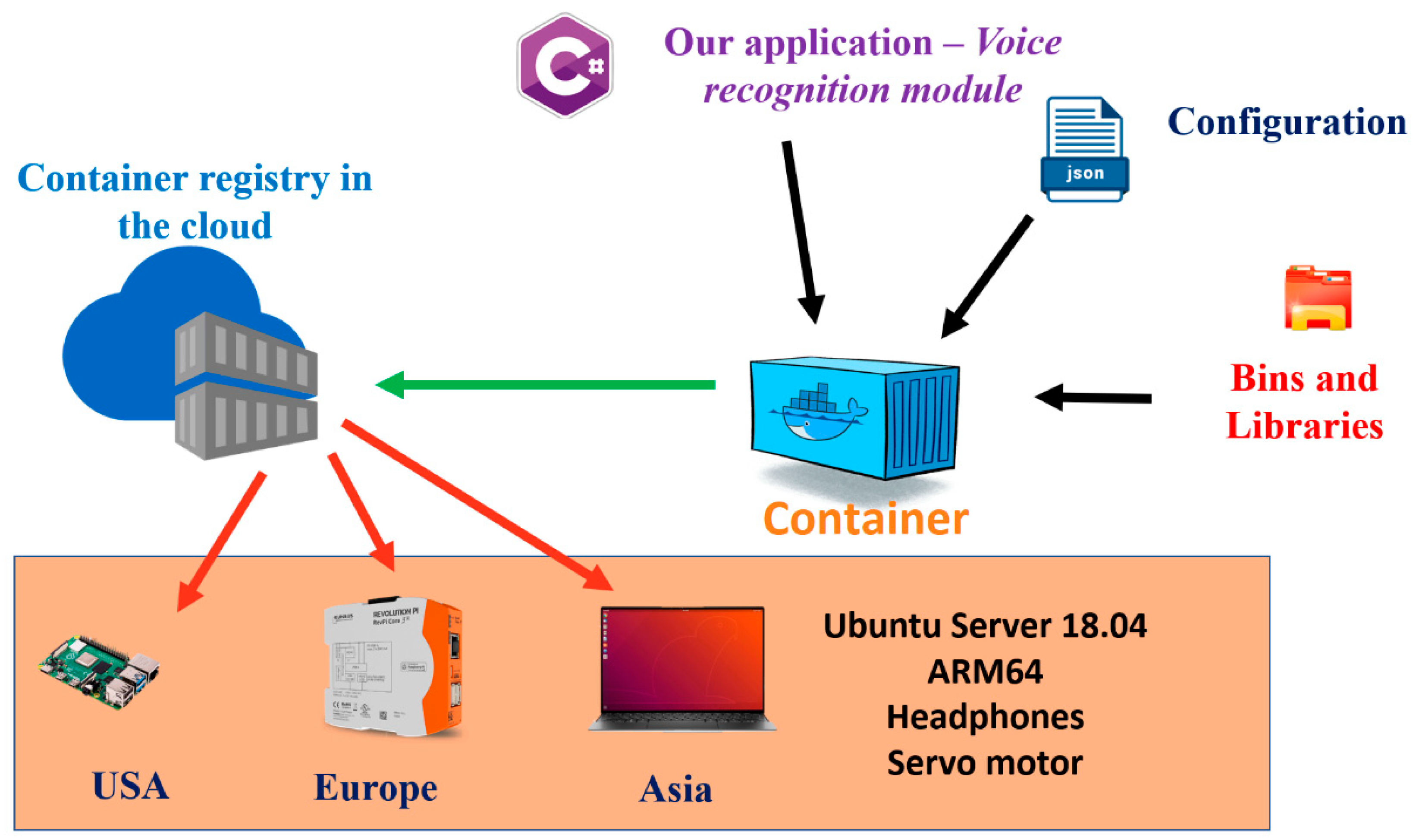
2.3. Containerization and Docker
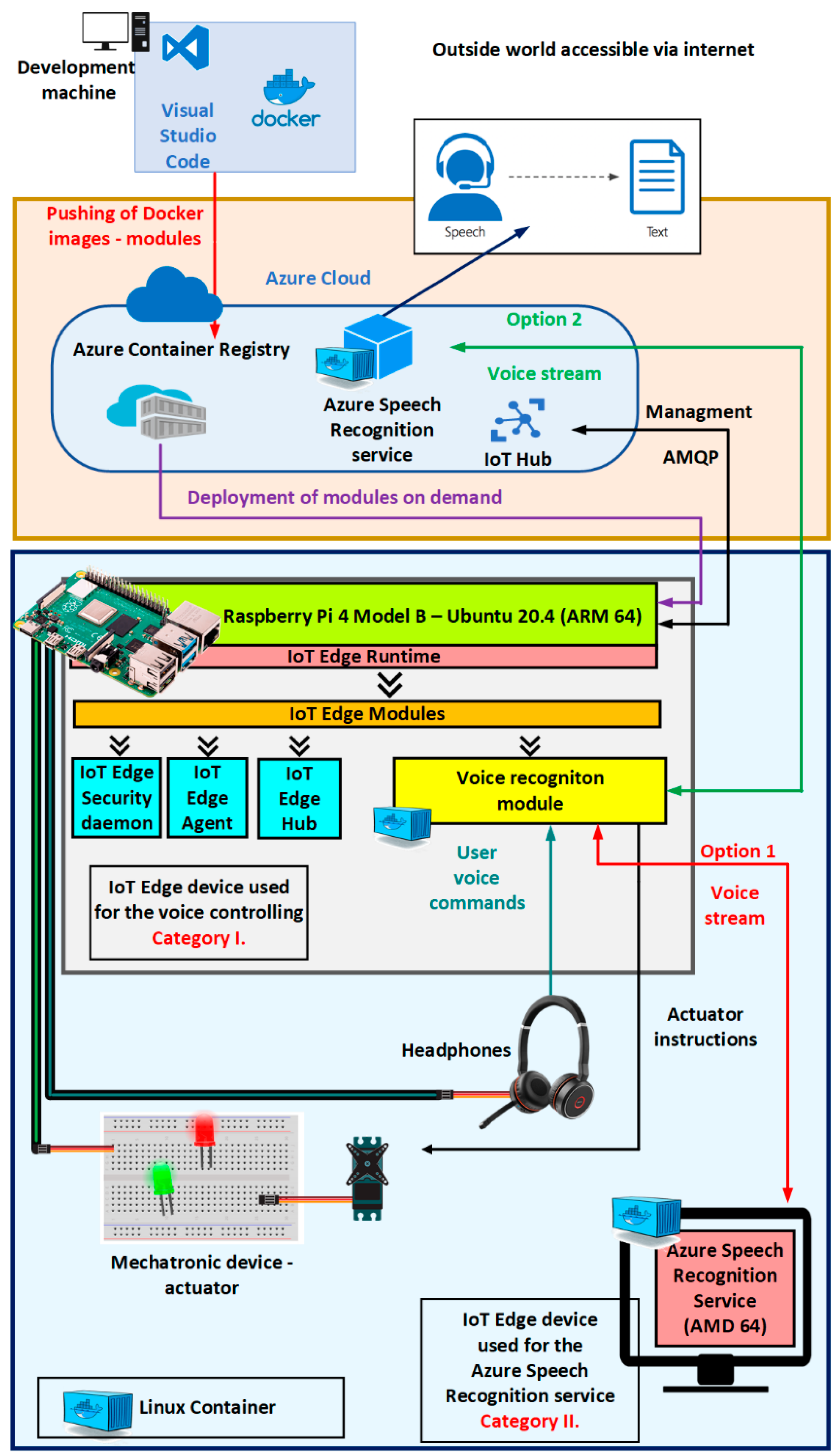
3. Designed Architecture and Methodology of the Voice-Controlled Actuator
- IoT Hub and the cloud Azure—contains information about used services from the cloud Azure and the IoT Hub running in the cloud Azure. These are used for management and deployment.
- IoT edge devices using the runtime Azure IoT edge—describes the two categories of edge devices and the runtime Azure IoT edge used in the proposed architecture.
- Containers for the speech control of the actuator running on the IoT edge devices—describes the functionality of the developed and used Linux containers for the control of the actuator by speech generated commands and an integrated development environment, Visual Studio Code. This architecture was created by two types of Linux containers:
- A.
- Configured container for Azure Speech Recognition service—transformation of voice to text.
- B.
- Created container for Voice recognition module—controlling of mechatronic device and processing of voice.
3.1. IoT Edge Devices Using the Runtime Azure IoT Edge
3.1.1. The Runtime Azure IoT Edge
- Installation, updating of modules and securing that edge modules are always running, and the latest security updates;
- Communication between the edge modules—acting as a local message broker;
- Reporting the status of edge modules to the cloud for remote monitoring.
- IoT edge agent is one of the modules that creates the Azure IoT edge runtime. The agent is responsible for instantiating, starting, and running the modules. In the same way, it is responsible for reporting the status of individual modules to the IoT Hub. The Azure IoT edge module (in further text abbreviated as module) is the smallest computing unit deployed and controlled by the IoT edge. The module can contain Azure services (such as Azure Cognitive Speech Services) or its own project-specific code. For modules, it is necessary to mention two points [27]:
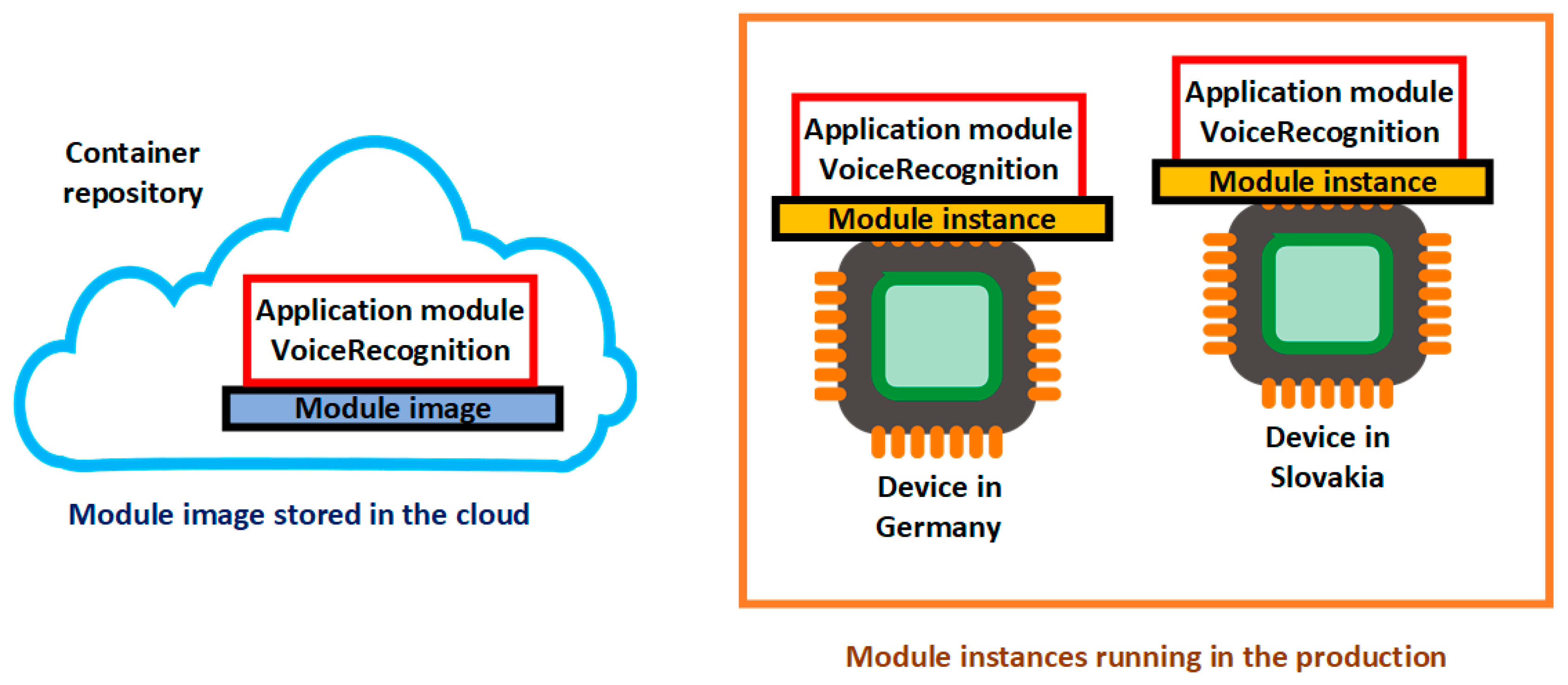
- Module image—A package of the software that defines a module. Module images exist as container images and they are stored in a container repository in the cloud, and module instances are containers on devices (Figure 5).
- Module instance—Specific running module image on the IoT edge device (Figure 5). Module instances are independent. Both modules have their own identity in the cloud Azure.
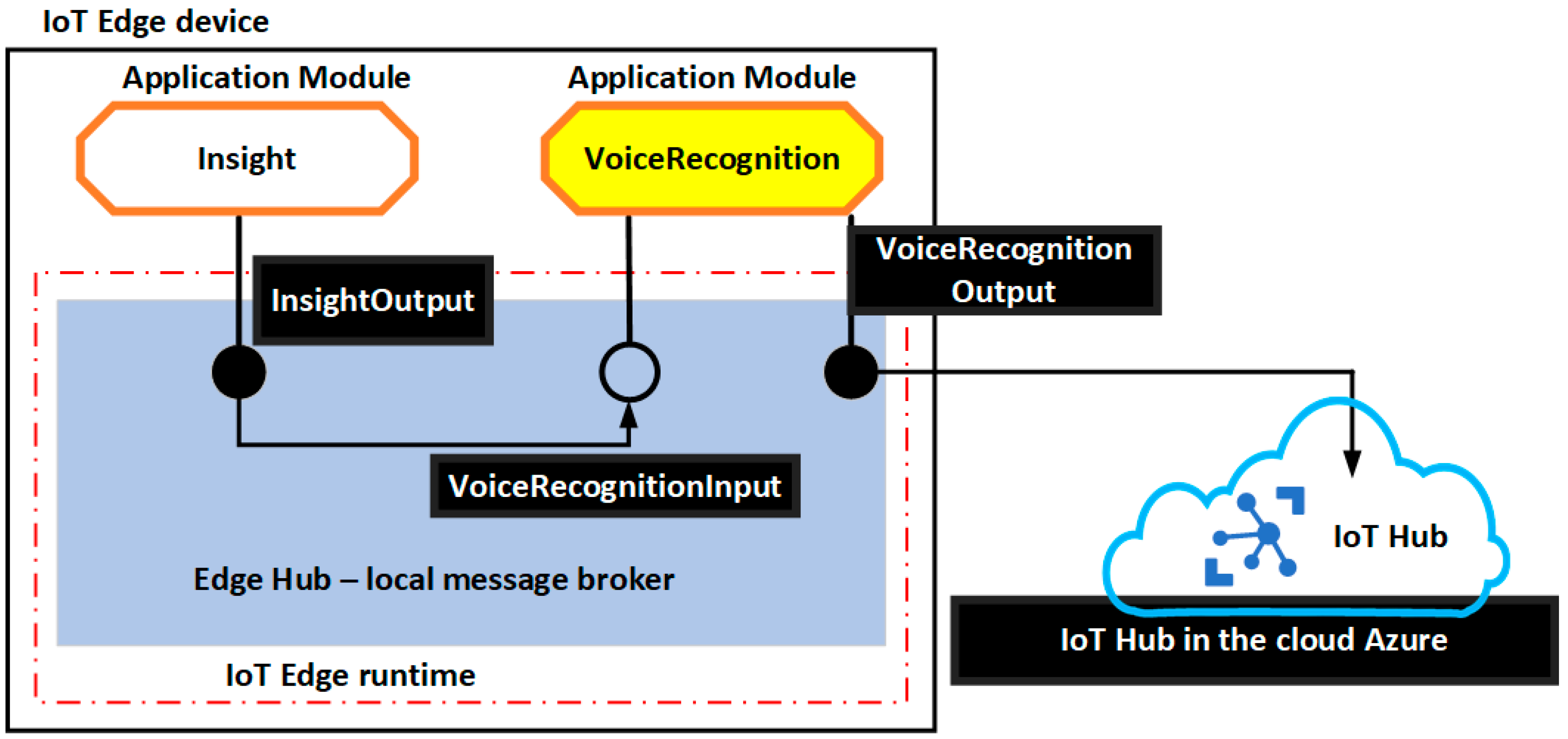
- IoT Edge Hub acts as the local message broker, so it keeps the modules independent. Communication between IoT Edge Hub and IoT Hub in the cloud Azure is performed via protocols Message Queuing Telemetry Transport (MQTT) and Advanced Message Queuing Protocol (AMQP). Modules need to specify the inputs where they listen for the messages and the outputs where they write the messages. Inputs and outputs are defined as “routes”:
- Connection between the VoiceRecognition and Insight module (Figure 6) can be defined as:
From/modules/VoiceRecognition/outputs/VoiceRecognitionOutputTo BrokenEndpoint(\”/modules/insight/insightInput”)- Connection between the VoiceRecognition module and IoT Hub in the cloud Azure (Figure 6) can be defined as:
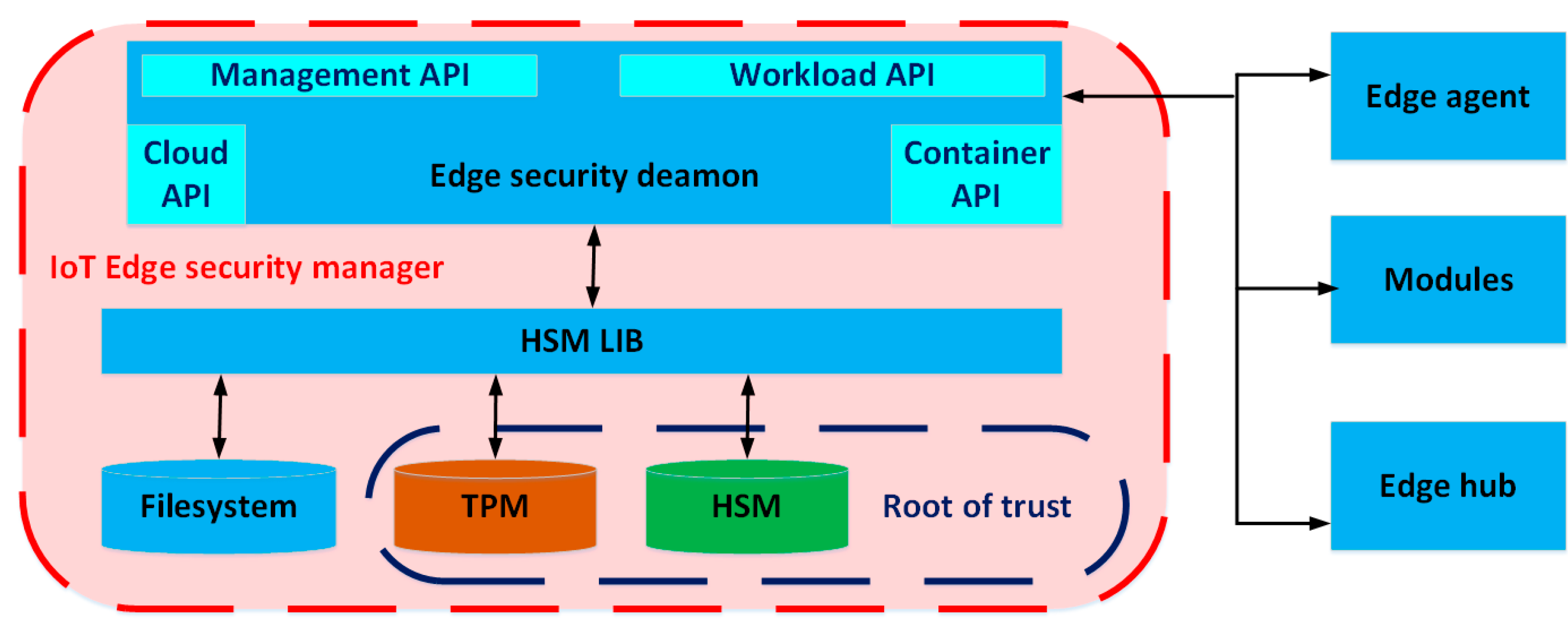
From/modules/VoiceRecognition/outputs/VoiceRecognitionOutput TO $upstream - IoT edge security manager (Figure 7) is the security core that protects the IoT edge device, and it is responsible for performing the logical operations such as encryption, decryption, hashing, generation of digital signatures and signature verification. The IoT edge security daemon starts when the IoT edge device is turned on, and its responsibility is the initialization of the IoT edge agent. The edge IoT security daemon provides access to application programming interfaces (APIs) such as [28] (Figure 7):
- Container API—offers an interface for interacting with container systems, such as Docker and Moby.
- Management API—only the IoT edge agent can access it. It is used to create, start, stop and remove the modules.
3.1.2. Supported Systems for IoT Edge Runtime
- Tier 1 systems—Operation systems officially supported by Microsoft. Microsoft has automated tests and provides installation packages for them. The latest version of Azure IoT edge supports only the Linux containers. These operating systems include Raspberry Pi OS Stretch (ARM32v7) and Ubuntu Server 18.04 (AMD64 and ARM64 in the Preview version).
- Tier 2 systems—can be considered compatible with Azure IoT edge. Testing on these platforms has been performed at least once but continuous testing is not performed. Tier 2 systems are CentOS 7.5, Debian 8, 9 and 10, RHEL 7.5, Ubuntu 16.04 and 18.04, Wind River 8, Yocto and Raspbian Buster 1.
3.1.3. IoT Edge Devices
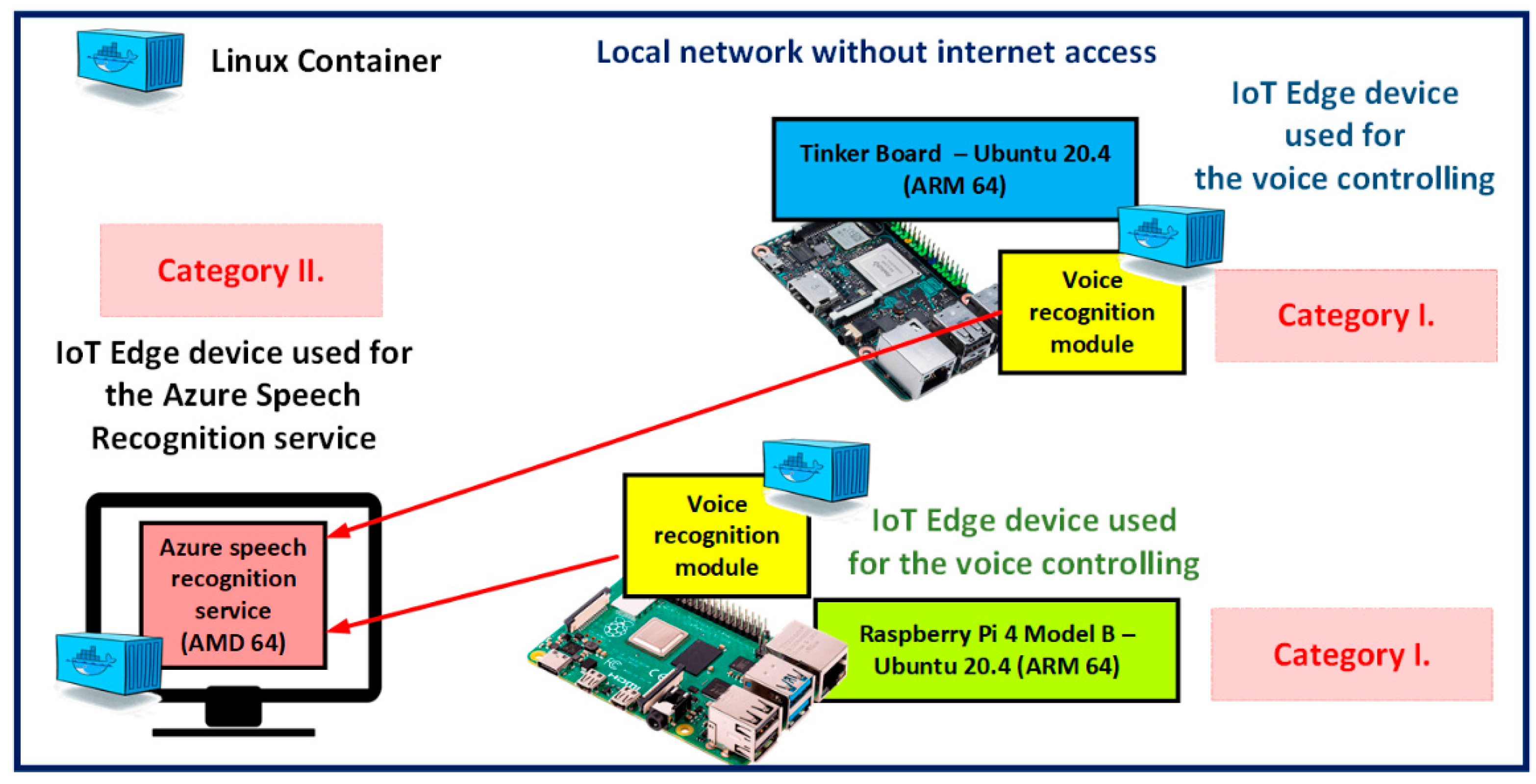
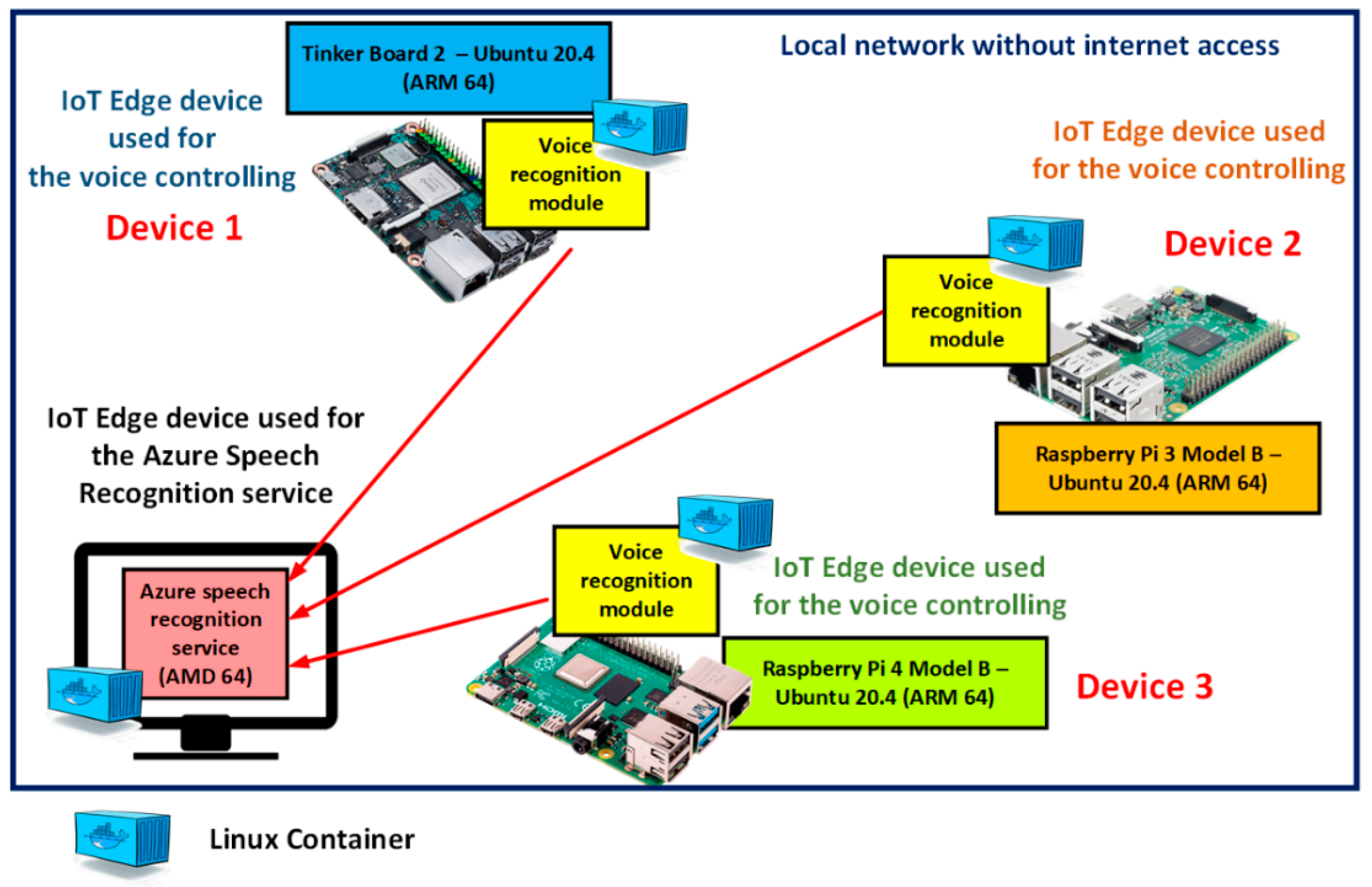
- Category I—Edge device where the actuator and the Bluetooth headphones are connected and it is used for running the Voice recognition module—it can be a device such as Tinker Board 2, PC, Raspberry Pi 3 or 4.
- Category II—Edge device where Azure Speech Recognition service is running—this device must be more powerful, as it is used for the transformation of voice to text, and many devices from Category I can be connected to this device.
3.2. IoT Hub and the Cloud Azure
- Monitoring whether the IoT edge device is up and running;
- Deployment of modules;
- Checking the health of deployed modules;
- Launching an update of modules;
- Connection and authentication of the new devices with the same or modified configuration.
3.3. Containers for the Speech Control of the Actuator Running on the IoT Edge Devices
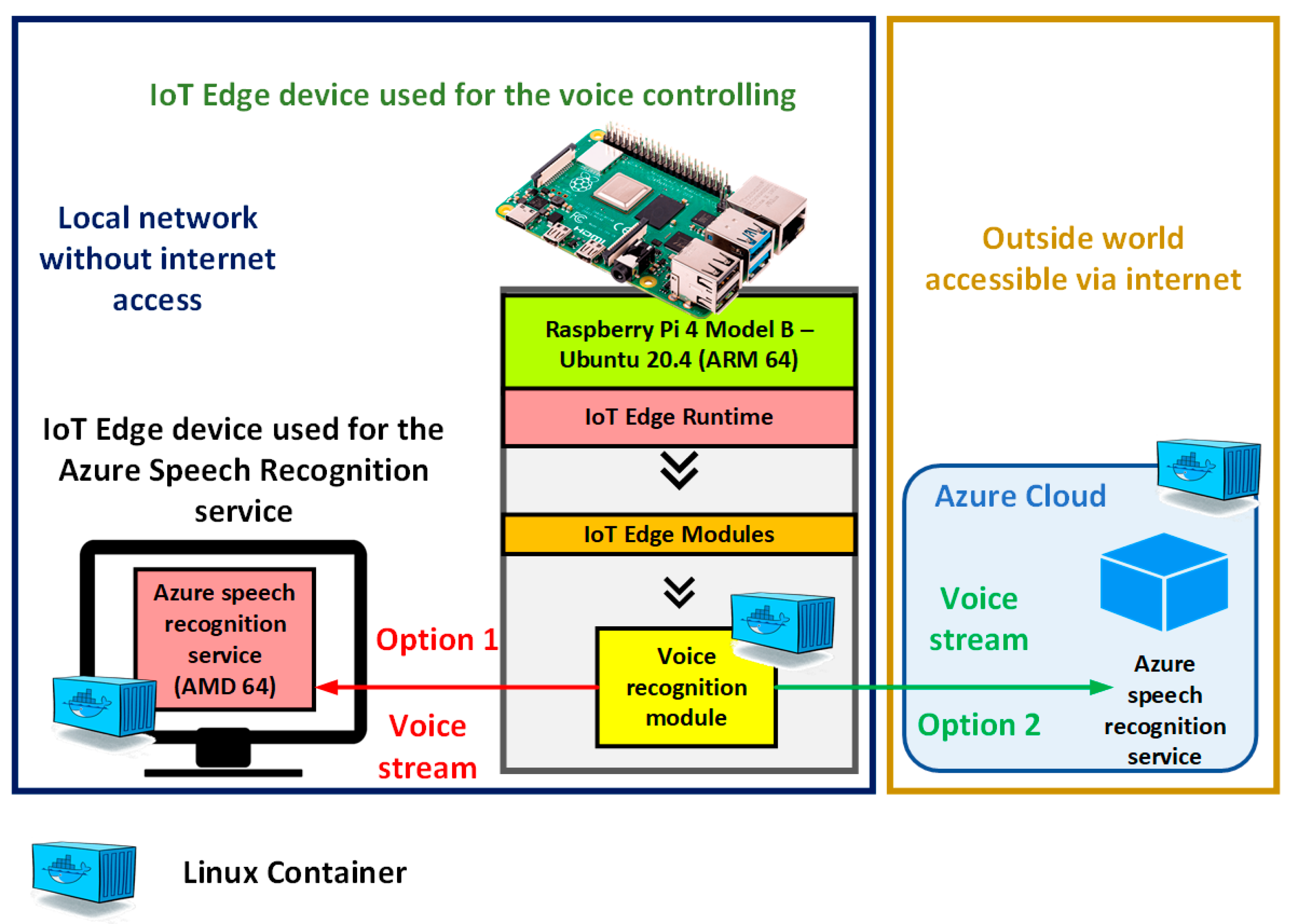
- Verification of the system requirements on the IoT edge device for the Azure Speech Recognition service. For the transformation of voice into text and better recognition, Azure Speech Recognition service with artificial intelligence was used. This service can run directly on the IoT edge device or remotely in the cloud Azure. If the Azure Speech Recognition service runs locally, it does not need a completely stable internet connection. Only every 15 min, the Azure Speech Recognition service must connect to the cloud Azure and provide information about the usage.
- 2.
- Configuration and setup of prerequisites for the Linux Voice recognition module—The created Linux container is prepared to automatically take the USB headset that is connected to the IoT edge device. It also contains all libraries and configuration, which are needed to access a microphone from the underlying system. No input is required from the end user to make the Voice recognition module functional.
- 3.
- Transformation of the human voice to actuator commands—Described in Figure 4, and it consists of three main components:
- I.
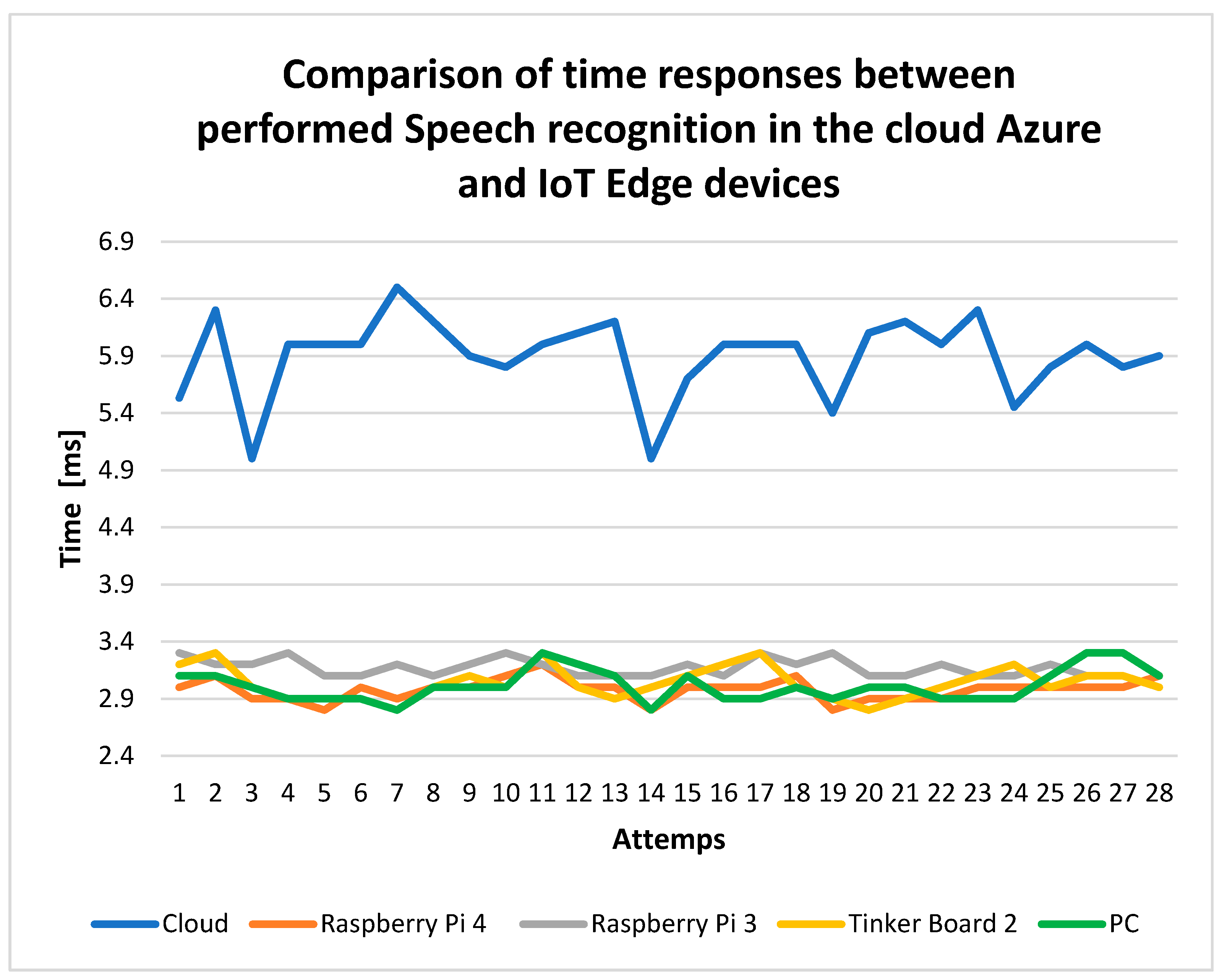
- Azure Speech Recognition service—responsible for the transformation of voice into text. The time for the speech recognition, which is performed remotely in the cloud Azure, is approximately about 5.9 ms when using an internet connection with the speed of 15 Mbps. When using the Azure Speech Recognition service on the edge device in a local network, the time of transformation of voice into text is approximately the same, as the cloud Azure option.
- II.
- Actuator Command Recognizer function—part of the Voice recognition module is responsible for the extraction of keywords from the transformed voice into text and the matching of keywords to specific actuator commands. To use voice commands, it is always necessary to trigger voice control by using the phrase “Hey Bennie”—similar to “Hey Alexa” for Amazon, “Hey Siri” for Apple or “Hey Mercedes” for Mercedes-Benz. The triggering phrase should always be unique in voice recognition systems. Actuator Command Recognizer function, meaning the proposed architecture currently supports four voice commands:
- “Connect to the motor”—Used for connecting to the actuator, signalized by the Green Led turning on and the Red Led turning off.
- “Disconnect from the motor”—Used for disconnecting from the actuator, signalized by the Red Led turning on and the Green Led turning off.
- “Turn off everything”—Used to turn off the whole controlled system.
- “Move the motor”—Actuator is going to be moved.
- Command One
- ○
- First matching word,
- ○
- Second matching word,
- ○
- …
- Command Two
- ○
- First matching word,
- ○
- Second matching word,
- ○
- Third matching word,
- ○
- …
- III
- Controlling of the actuator connected to the IoT edge device—Voice recognition module is using predefined general-purpose input/output (GPIO) pins for the controlling of the actuator to make the solution more universal and flexible. If default PINs have already been taken, there is a possibility to overwrite the default values with their own specified values, as the configuration of the PINs is stored in the JSON file. Configuration in the JSON file can be easily changed by the end user. To apply the changes, it is enough to only modify the JSON file and restart the system. There is no need to create or rebuild the program inside the Voice recognition module.
3.4. Methodology of the Implementation
- Create Azure IoT Hub [31] in the cloud Azure for management and deployment of containers on the IoT edge devices.
- Create the Azure Speech recognition service in the cloud Azure. The result of this action is the endpoint, which is later used for the cloud and edge computing. To perform this step, it is required to have a subscription, even though the Azure Speech recognition service offers free usage for limited requests for the speech recognition.
- Register the IoT edge devices in the Azure IoT Hub [31].
- Configure the IoT edge devices and connect them to the IoT Edge Hub in the cloud Azure.
- Connect the actuator and the microphone to the IoT edge device from Category I.
- Define a deployment JSON file in the Azure IoT Hub portal with the containers Voice recognition module (Device from Category I) and Azure Speech recognition service (Device from Category II)
- Trigger the deployment of mentioned containers, in other words, modules.
- Wait for the initialization of the modules and use the system. During the initialization of the Voice recognition module, necessary configuration steps are performed automatically to allow connection and usage of the microphone.
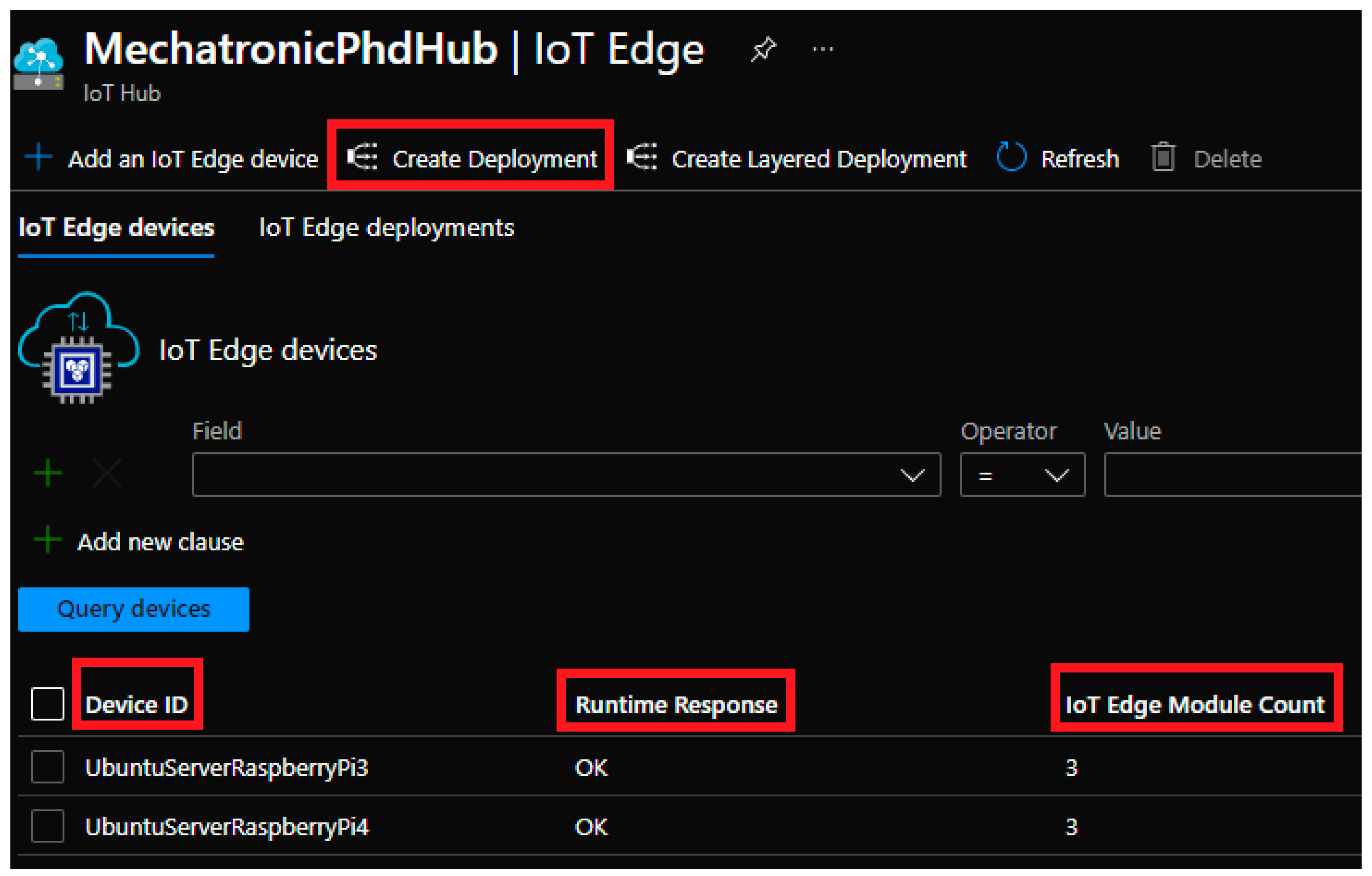
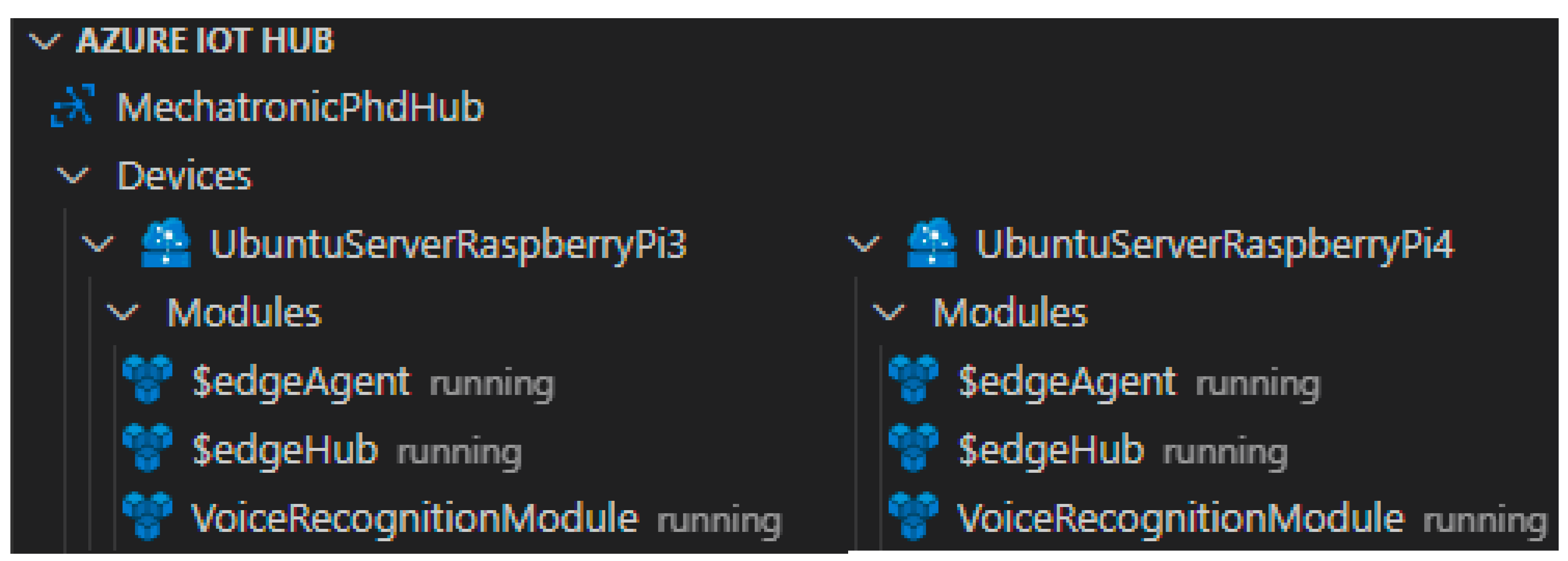
- Deployment of the mentioned modules can be verified through the Azure Iot Hub portal [31]. In the portal can be seen:
- ○
- If the IoT edge devices are online,
- ○
- If the deployment of mentioned modules were successful,
- ○
- Error message in case an error occurs.
4. Experimental Verification
- Category I—PC with 4 GB RAM and processor Intel Core i3-2330M, Thinker Board 2, Raspberry Pi 3 and 4;
- Category II—PC with 12 GB RAM and processor Intel Core i7-8850h.
5. Results
- Stability and low latency—As described in Section 4, the response time is shorter when the processing is performed by the IoT edge device and not in the cloud Azure. Speech recognition performed by the IoT edge devices was around 2.97 ms, meaning an approximately 58.37% better response time than the cloud Azure response time (Figure 14). Even if the Azure Speech Recognition service runs in the cloud Azure, the voice transformation into text is around 5.9 ms when using an internet connection with the speed of 15 Mbps.
- 2.
- Portability—Developed Voice recognition module can be deployed on Windows or Linux operating systems thanks to the framework. NET Core. As the Voice recognition module is a Linux container, it can be reused in other IoT solutions such as AWS IoT Greengrass [34] or Siemens MindSphere (currently available only for developers) [35]. These solutions use Linux containers as well. The usage of the proposed modules in the solutions from Amazon or Siemens will require modification of communication routers, but the core functionality of modules will stay the same. Furthermore, the usage on the operation system Windows will require a small adaption, the Voice recognition module would have to be rebuilt as a Windows container.
- 3.
- Data privacy—Increased data privacy when running the Azure Speech Recognition service locally on the IoT edge devices.
- 4.
- Distribution and maintenance—The solution can be easily distributed to many other IoT edge devices in a short time. It is only necessary to have the IoT edge device that will fulfill the requirements and it is connected to the Azure IoT Hub in the cloud Azure. Updates of modules are performed remotely by the cloud Azure. There is no need to have physical access to the devices. Furthermore, migration to different devices with similar architecture is quick and smooth. The migration from old Raspberry Pi 3 to 4 was completed approximately in 15 min.
- 5.
- The endpoint for the Azure Speech Recognition service can be easily adjusted in the JSON file in the Voice recognition module without a code change. The endpoint for the Azure Speech Recognition service can be a local Hostname, such as “LocalAzureSpeechRecognition” or a local static IP address. Furthermore, the commands for the voice recognition can be easily adjusted in the JSON file in the Voice recognition module, without code changes, and the same for the PINs configuration. All of the mentioned adjustments can be performed while the Voice recognition module is up and running. Containers can be simply pulled and run from the following repositories:
- 1.
- Container for the Voice recognition module (designed and created module, the latest stable version is 1.7.11) for Category I:Commands: docker pull researchphd.azurecr.io/voicerecognitionmodule:1.7.11-arm64v8 docker run researchphd.azurecr.io/voicerecognitionmodule:1.7.11-arm64v8
- 2.
- Container for the Azure Speech Recognition service (official container from Microsoft, always the latest version is downloaded) [36]:
- 6.
- Voice recognition module—The created Linux container is prepared to automatically take the USB headset that is connected to the IoT edge device. It contains all libraries and the configuration that is needed to access the microphone from the underlying system. No input is required from the end user to make Voice recognition module functional. By default, Linux container image does not support the usage of the microphone from the underlying system; therefore, it was necessary to set up this functionality in the Voice recognition module. The Voice recognition module is always running locally as it is responsible for the control of the actuator. As mentioned above, the module also supports the phrase triggering. The phrase triggering leads to bigger reliability of the architecture, as the voice control is only performed when desired.
- Dependency on the operation system Linux with the architecture ARM64. Note: Linux container can be transformed to Windows container. This option requires recompilation of the Voice recognition module with a proper base image [43].
- Setup of the Azure Speech Recognition service and the IoT Hub in the cloud Azure. This setup requires knowledge about cognitive services [44] and IoT [31] in the cloud Azure. Furthermore, in other implementations, it was possible to see the usage of speech services from the different cloud providers, where it is necessary to set up these services in the cloud.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alexa. Available online: https://developer.amazon.com/en-US/alexa (accessed on 2 June 2021).
- Siri. Available online: https://www.apple.com/siri/ (accessed on 2 June 2021).
- Cortana. Available online: https://www.microsoft.com/en-us/cortana (accessed on 2 June 2021).
- Google Assistant. Available online: https://assistant.google.com (accessed on 2 June 2021).
- 73% of Drivers Will Use an In-Car Voice Assistant by 2022: Report. Available online: https://voicebot.ai/2019/11/17/73-of-drivers-will-use-an-in-car-voice-assistant-by-2022-report (accessed on 1 May 2021).
- Voice Assistant Market Size USD 7.30 Billion by 2025, Registering a 24.32% CAGR—Report by Market Research Future (MRFR). Available online: https://www.globenewswire.com/en/news-release/2021/06/23/2252069/0/en/Voice-Assistant-Market-Size-USD-7-30-Billion-by-2025-Registering-a-24-32-CAGR-Report-by-Market-Research-Future-MRFR.html (accessed on 10 July 2021).
- From the Cloud to the Edge. Available online: https://rtview.com/from-the-cloud-to-the-edge/ (accessed on 11 July 2021).
- 100 ms of Latency Cost This Company 1% in Sales. Available online: https://www.presstitan.com/100ms-latency/ (accessed on 15 July 2021).
- Internet of Things (IoT) Connected Devices Installed Base Worldwide from 2015 to 2025. Available online: https://www.statista.com/statistics/471264/iot-number-of-connected-devices-worldwide/ (accessed on 16 July 2021).
- 10 Reasons Why Privacy Rights Are Important. Available online: https://www.humanrightscareers.com/issues/reasons-why-privacy-rights-are-important/ (accessed on 20 July 2021).
- Valera Román, A.; Pato Martínez, D.; Lozano Murciego, Á.; Jiménez-Bravo, D.M.; de Paz, J.F. Voice Assistant Application for Avoiding Sedentarism in Elderly People Based on IoT Technologies. Electronics 2021, 10, 980. [Google Scholar] [CrossRef]
- Yvanoff-Frenchin, C.; Ramos, V.; Belabed, T.; Valderrama, C. Edge Computing Robot Interface for Automatic Elderly Mental Health Care Based on Voice. Electronics 2020, 9, 419. [Google Scholar] [CrossRef] [Green Version]
- Speech. Available online: https://azure.microsoft.com/en-us/services/cognitive-services/speech-services/ (accessed on 30 July 2021).
- Cloud Computing vs. Edge Computing: Friends or Foes? Available online: https://www.forbes.com/sites/forbestechcouncil/2020/03/05/cloud-computing-vs-edge-computing-friends-or-foes/ (accessed on 2 August 2021).
- Cloud vs. Edge. Available online: https://www.redhat.com/en/topics/cloud-computing/cloud-vs-edge (accessed on 2 August 2021).
- Memon, K.S.; Nisar, K.; Hijazi, M.H.A.; Chowdhry, B.S.; Sodhro, A.H.; Pirbhulal, S.; Rodrigues, J.P.C.J. A survey on 802.11 MAC industrial standards, architecture, security & supporting emergency traffic: Future directions. J. Ind. Inf. Integr. 2021, 24, 100225. [Google Scholar] [CrossRef]
- Difference between Edge Computing vs. Cloud Computing? Available online: https://www.akira.ai/blog/edge-computing-vs-cloud-computing/ (accessed on 2 July 2021).
- What Is Containerization? Available online: https://www.redhat.com/en/topics/cloud-native-apps/what-is-containerization (accessed on 3 August 2021).
- Zhang, Q.; Liu, L.; Pu, C.; Dou, Q.; Wu, L.; Zhou, W. A Comparative Study of Containers and Virtual Machines in Big Data Environment. In Proceedings of the 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), San Francisco, CA, USA, 2–7 July 2018; Available online: https://arxiv.org/pdf/1807.01842.pdf (accessed on 3 August 2021).
- Yadav, A.K.; Garg, M.L.; Mehra, R. Docker Containers Versus Virtual Machine-Based Virtualization: Proceedings of IEMIS 2018. In Emerging Technologies in Data Mining and Information Security; Springer: Singapore, 2019; Volume 3. [Google Scholar] [CrossRef]
- Docker. Available online: https://www.ibm.com/cloud/learn/docker (accessed on 3 August 2021).
- Azure IoT Edge. Available online: https://azure.microsoft.com/en-us/services/iot-edge (accessed on 27 March 2021).
- Raspberry Pi 3. Available online: https://www.raspberrypi.org/products/raspberry-pi-3-model-b-plus/ (accessed on 7 September 2021).
- Raspberry Pi 4. Available online: https://www.raspberrypi.org/products/raspberry-pi-4-model-b/ (accessed on 7 September 2021).
- Tinker Board 2. Available online: https://tinker-board.asus.com/product/tinker-board-2.html (accessed on 8 September 2021).
- Understand the Azure IoT Edge Runtime and Its Architecture. Available online: https://docs.microsoft.com/en-us/azure/iot-edge/iot-edge-runtime (accessed on 15 April 2021).
- Understand Azure IoT Edge Modules. Available online: https://docs.microsoft.com/en-us/azure/iot-edge/iot-edge-modules (accessed on 15 April 2021).
- Azure IoT Edge Security Manager. Available online: https://docs.microsoft.com/en-us/azure/iot-edge/iot-edge-security-manager (accessed on 25 April 2021).
- Azure IoT Edge Supported Systems. Available online: https://docs.microsoft.com/en-us/azure/iot-edge/support?view=iotedge-2020-11 (accessed on 25 June 2021).
- Container Registry. Available online: https://azure.microsoft.com/en-us/services/container-registry/ (accessed on 9 September 2021).
- Create an IoT Hub Using the Azure Portal. Available online: https://docs.microsoft.com/en-us/azure/iot-hub/iot-hub-create-through-portal (accessed on 25 June 2021).
- Ubuntu 18.04.5 LTS (Bionic Beaver). Available online: https://releases.ubuntu.com/18.04.5/ (accessed on 25 June 2021).
- Install or uninstall Azure IoT Edge for Linux. Available online: https://docs.microsoft.com/en-us/azure/iot-edge/how-to-install-iot-edge?view=iotedge-2020-11 (accessed on 26 June 2021).
- AWS IoT Greengrass 1.10 Provides Support for Docker Containers and Management of Data Streams. Available online: https://aws.amazon.com/about-aws/whats-new/2019/11/aws-iot-greengrass-supports-docker-containers-management-data-streams (accessed on 8 May 2021).
- Cloud Foundry How Tos—Docker Container in Cloud Foundry. Available online: https://developer.mindsphere.io/paas/howtos/howtos-docker-in-cloudfoundry.html (accessed on 29 April 2021).
- Install and Run Docker Containers for the Speech Service APIs. Available online: https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/speech-container-howto?tabs=stt%2Ccsharp%2Csimple-format (accessed on 29 July 2021).
- Tahseen Ali, A.; Abdullah, H.S.; Fadhil, M.N. Voice recognition system using machine learning techniques. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Martinek, R.; Vanus, J.; Nedoma, J.; Fridrich, M.; Frnda, J.; Kawala-Sterniuk, A. Voice Communication in Noisy Environments in a Smart House Using Hybrid LMS+ICA Algorithm. Sensors 2020, 20, 6022. [Google Scholar] [CrossRef] [PubMed]
- Benítez-Guijarro, A.; Callejas, Z.; Noguera, M.; Benghazi, K. Coordination of Speech Recognition Devices in Intelligent Environments with Multiple Responsive Devices. Proceedings 2019, 31, 54. [Google Scholar] [CrossRef] [Green Version]
- Nasef, M.; Sauber, A.; Nabil, M. Voice gender recognition under unconstrained environments using self-attention. Appl. Acoust. 2021, 175, 107823. [Google Scholar] [CrossRef]
- Koložvari, A.; Stojanović, R.; Zupan, A.; Semenkin, E.; Stanovov, V.; Kofjač, D.; Škraba, A. Speech-recognition cloud harvesting for improving the navigation of cyber-physical wheelchairs for disabled persons. Microprocess. Microsyst. 2019, 69, 179–187. [Google Scholar] [CrossRef]
- Magsi, H.; Sodhro, A.H.; Al-Rakhami, M.S.; Zahid, N.; Pirbhulal, S.; Wang, L. A Novel Adaptive Battery-Aware Algorithm for Data Transmission in IoT-Based Healthcare Applications. Electronics 2021, 10, 367. [Google Scholar] [CrossRef]
- Create a Base Image. Available online: https://docs.docker.com/develop/develop-images/baseimages/ (accessed on 10 September 2021).
- Azure Cognitive Services. Available online: https://azure.microsoft.com/en-us/services/cognitive-services/ (accessed on 10 September 2021).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Multilanguage Support | Certifications | Own Dictionary-Slang | Removal of Background Noises |
|---|---|---|---|---|
| Google Cloud Speech | Yes | Yes * | Yes | Yes |
| Microsoft Cognitive Services Speech | Yes | Yes * | Yes | Yes |
| Amazon Transcribe | Yes | Yes * | Yes | Yes |
| System Speech | Yes | No | Yes | No |
| DeepSpeech | No | No | Yes | No |
| Kaldi | No | No | Yes | No |
| Annyang | No | No | Yes | No |
| Voice-commands.js | No | No | Yes | No |
| Name | Owner | Programming Languages | Running in the Cloud | Docker Image-Container * |
|---|---|---|---|---|
| Google Cloud Speech | C# (Core), Go, Node.js, PHP, Ruby ** | Yes | No (Necessity to run the Container in K8s infrastructure) | |
| Microsoft Cognitive Speech Service | Microsoft | C# (Core), C++, JavaScript, Objective-C/Swift ** | Yes | Yes |
| Amazon Transcribe | Amazon | Java SDK, Ruby SDK, and C++ SDK | Yes | No |
| System Speech | Microsoft | C# (.NET Framework) | No | No |
| DeepSpeech | Mozilla | C, JavaScript and ** | No | No |
| Kaldi | Kaldi | C++ | No | No |
| Annyang | Annyang | JavaScript | No | No |
| Voice-commands.js | Jimmy Byrum | JavaScript | No | No |
| Speech Recognition Performed on the Edge Device | Containerized Solution | Easy Update and Distribution of Solution to Many Devices | Multilanguage Support | Phrase Triggering | |
|---|---|---|---|---|---|
| Created architecture from the article | Yes | Yes | Yes | Yes | Yes |
| Valera Román [11] | No | No | No | Yes | Yes |
| Yvanoff-Frenchin [12] | No | No | No | Yes | Not mentioned |
| Tahseen Ali [37] | Yes | No | No | No | Not mentioned |
| Martinek [38] | Yes | No | No | Not mentioned | Not mentioned |
| Benítez-Guijarro [39] | No | No | No | Not mentioned | Yes |
| Nasef [40] | No | No | No | Yes | Not mentioned |
| Koložvari [41] | No | No | No | Yes | Not mentioned |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beňo, L.; Pribiš, R.; Drahoš, P. Edge Container for Speech Recognition. Electronics 2021, 10, 2420. https://doi.org/10.3390/electronics10192420
Beňo L, Pribiš R, Drahoš P. Edge Container for Speech Recognition. Electronics. 2021; 10(19):2420. https://doi.org/10.3390/electronics10192420
Chicago/Turabian StyleBeňo, Lukáš, Rudolf Pribiš, and Peter Drahoš. 2021. "Edge Container for Speech Recognition" Electronics 10, no. 19: 2420. https://doi.org/10.3390/electronics10192420