1. Introduction
Electromagnetic (EM) simulation approaches, such as method of moments (MoM), which is a numerical computational method that transforms Maxwell’s equations into integral matrix equations, obtain the EM performance by solving the dense matrix equation. The finite-difference time-domain (FDTD) method solved Maxwell’s equations in an explicit way. Because of its simple, robust nature and ability to incorporate a broad range of non-linear materials and devices, FDTD is often used to study a wide range of applications, including antenna design, microwave circuits, bio/EM effects, and photonics. The finite element method (FEM) transforms Maxwell’s equations into differential equations. The FEM solver can handle arbitrary shaped structures, like bond wires, conical shape vias, and solder bumps, and dielectric bricks or finite-size substrates. Although these EM simulation methods are powerful for RF device analyses these approaches suffer from a severe problem, i.e., they are very time consuming. Some studies have used artificial neural network (ANN) for assessment of electromagnetic field radiating by electrostatic discharges [
1] or design of microwave circuits [
2]. In these studies, shallow neural networks (with only one hidden layer in neural network) have been used. Some recent studies [
3,
4] revealed that the capability of shallow neural networks is very limited by comparison with deep neural networks (DNNs). Neural networks that contain only one or two hidden layers cannot fit complex training data well, especially when the dataset is non-uniform or contains missing values. On the other hand, optimization algorithms, such as stochastic gradient descent (SGD), Newton’s method, or Levenberg–Marquardt (LM) algorithm, have been used for the training process. However, these optimization methods are still unsuitable for deep learning training, in which there are a large amount of training data and complex neural network structures. The datasets used by these previous studies have been collected by uniform sampling or dense sampling. Whether the neural networks have enough generalization ability for non-uniform sampling training data has not been discussed.
With the continuous upgrading of the equipment needed to train neural networks and the advent of the big data era, traditional shallow ANN has been gradually transforming into DNN, such as basely fully connected network, convolutional neural network (CNN), and recurrent neural network (RNN). DNN is able to model RF devices with the data collected from accurate EM simulations by mapping the geometry information and frequency of the RF devices to the scattering parameters (or S-parameters, they describe the electrical behavior of linear electrical networks when undergoing various steady state stimuli by electrical signals [
5]). DNN can extract more features in each layer from the training data by comparison with shallow ANN. The model generated from DNN can be used for rapidly generating the S parameters of the parameterized RF device, which can avoid the long CPU time of performing the rigorous EM simulation.
On the other hand, there are many classic optimization algorithms to training the neural network, such as stochastic gradient descent (SGD) [
6], Newton’s method [
7] or Levenberg–Marquardt (LM) algorithm [
8]. However, they all have some drawbacks, which cause them not suitable for training DNN in various ways.
The SGD algorithm can guarantee the global optimal solution only when the loss function is a convex function [
9]. However, the ideal convex function is almost impossible in realistic. Moreover, the SGD also cannot adjust the learning rate automatically. As a consequence, the SGD has poor training speed if the learning rate is set too small. On the other hand, if the learning rate has been set too large, the training process may never reach to the minimum. In addition, the SGD is also prone to be trapped in a saddle point and local minima. Newton’s method needs to calculate Hessian matrix and inverse matrix, implying that it needs more computational resources. If the number of the training data and the size of the neural network are very large, the Jacobian matrix can become huge [
10]. Therefore, the Levenberg–Marquardt algorithm is not suitable for big data models.
As a recently proposed optimization algorithm, advanced optimization algorithm (Adam) [
11] has advantages in memory requirements, adaptive learning rates for different parameters, and non-convex optimizations for large datasets and high dimensional spaces.
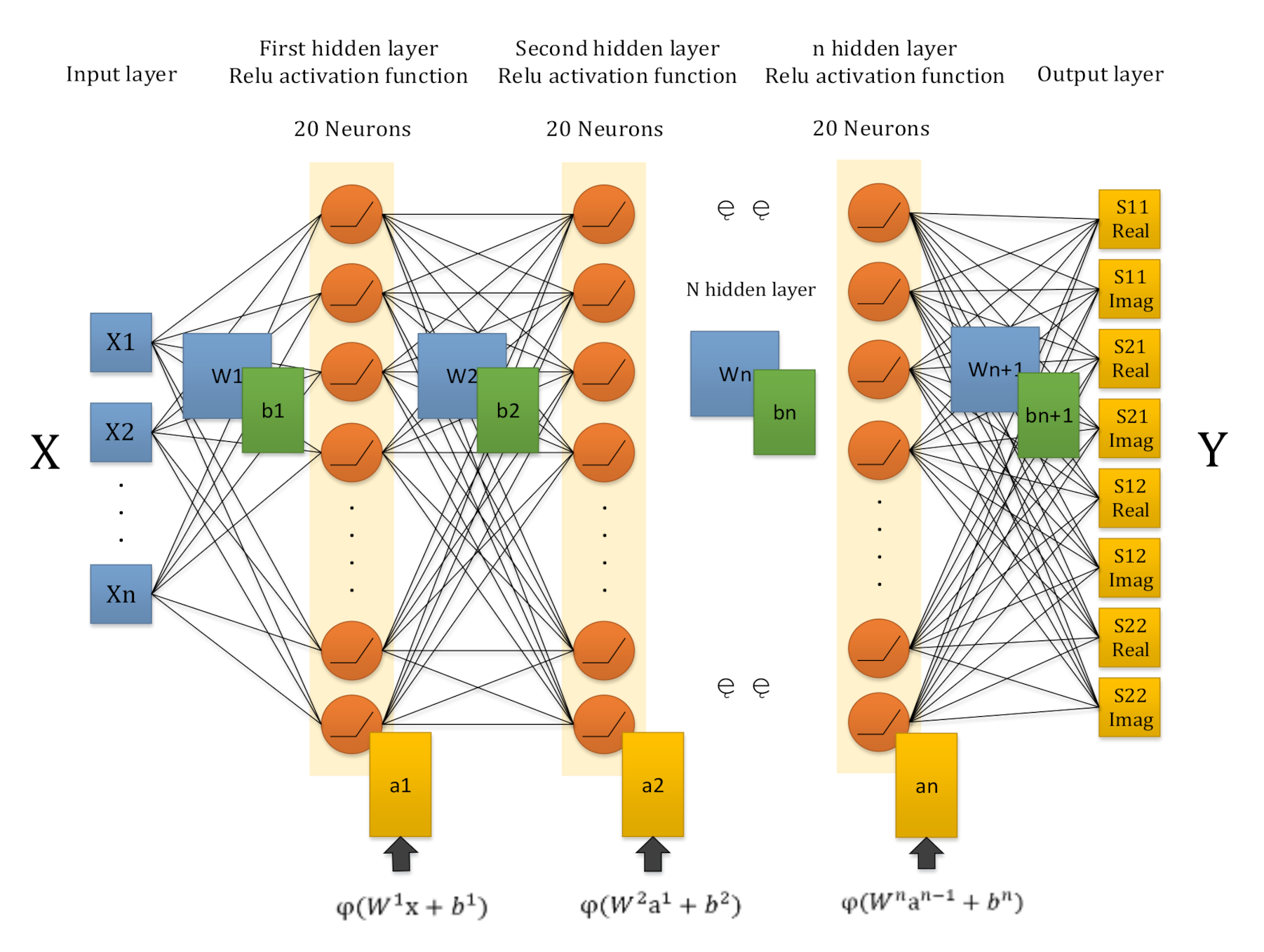
In this work, the DNN modeling approach, which combines Tensorflow deep learning structure and the training by Adam, is proposed. Not only the metallic geometry of the structure, but also the permittivity and thickness of the dielectric layers are revised during the sweeping process. Accurate prediction of the frequency response can be obtained by this proposed method. During the training procedure, a novel selection method of training data considering critical points is introduced, especially when the training dataset is too large, to enhance the training efficiency. In addition, the layers of the neural networks are adaptively chosen based on the frequency response of the RF devices to generate an optimal model for the RF devices. Three RF devices are used as examples to illustrate this modeling approach. A rectangular inductor is used to build and train the DNN, while an interdigital capacitor is used for validating the generalization ability of the DNN. Finally, an example of two coupled transmission lines is used to validate the accuracy of this method in a very wide frequency band range.
3. Modeling of RF Devices
In order to illustrate the DNN-based modeling procedure, two classic RF devices are used: rectangular inductor and interdigital capacitor. The geometrical parameters of the RF device are used as the input data of the neural network, while the S parameters of the RF device is the output of the neural network.
3.1. RF Devices
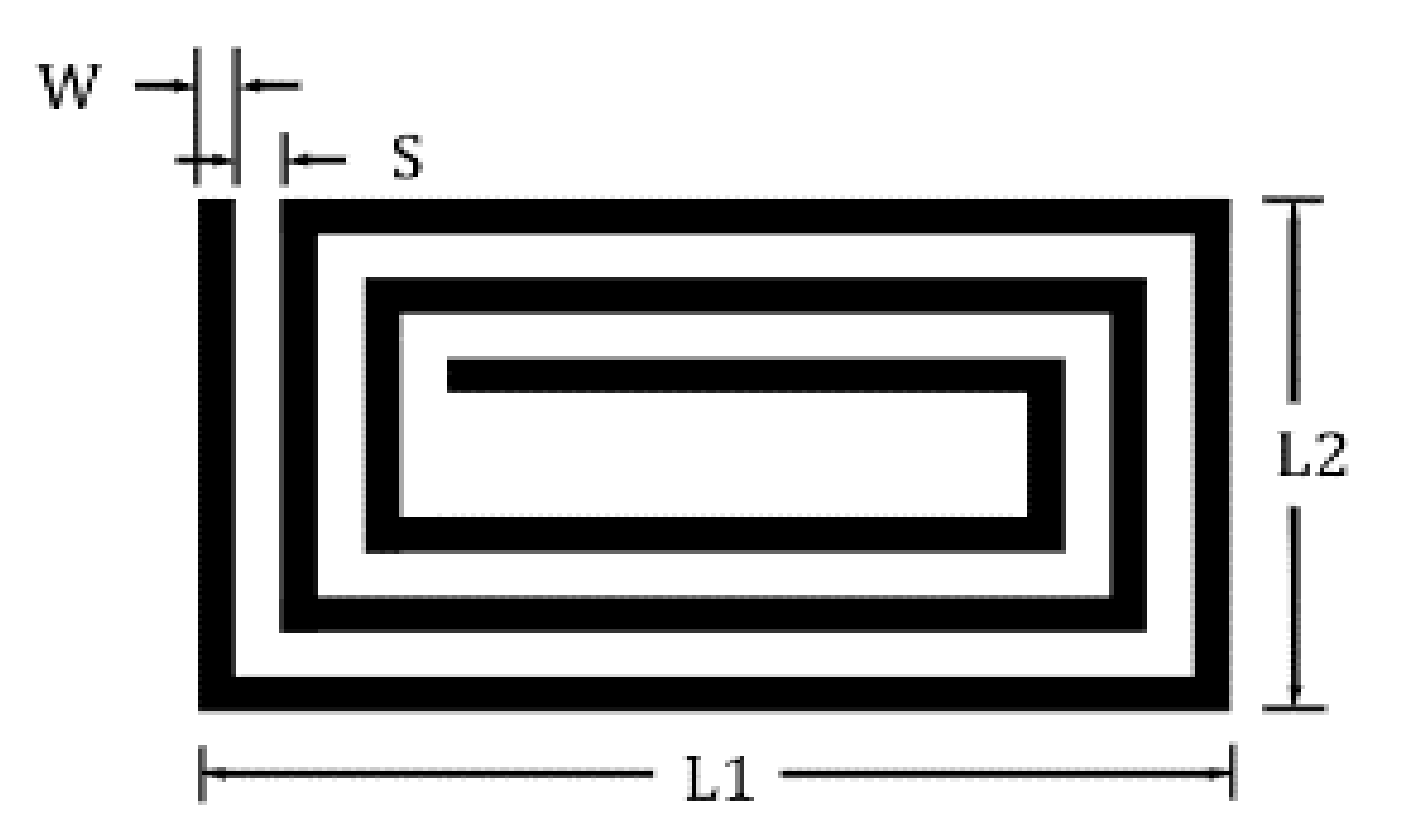
A rectangular inductor, shown in
Figure 3, is firstly used to establish the neural network. Its geometrical parameters are listed in
Table 1.
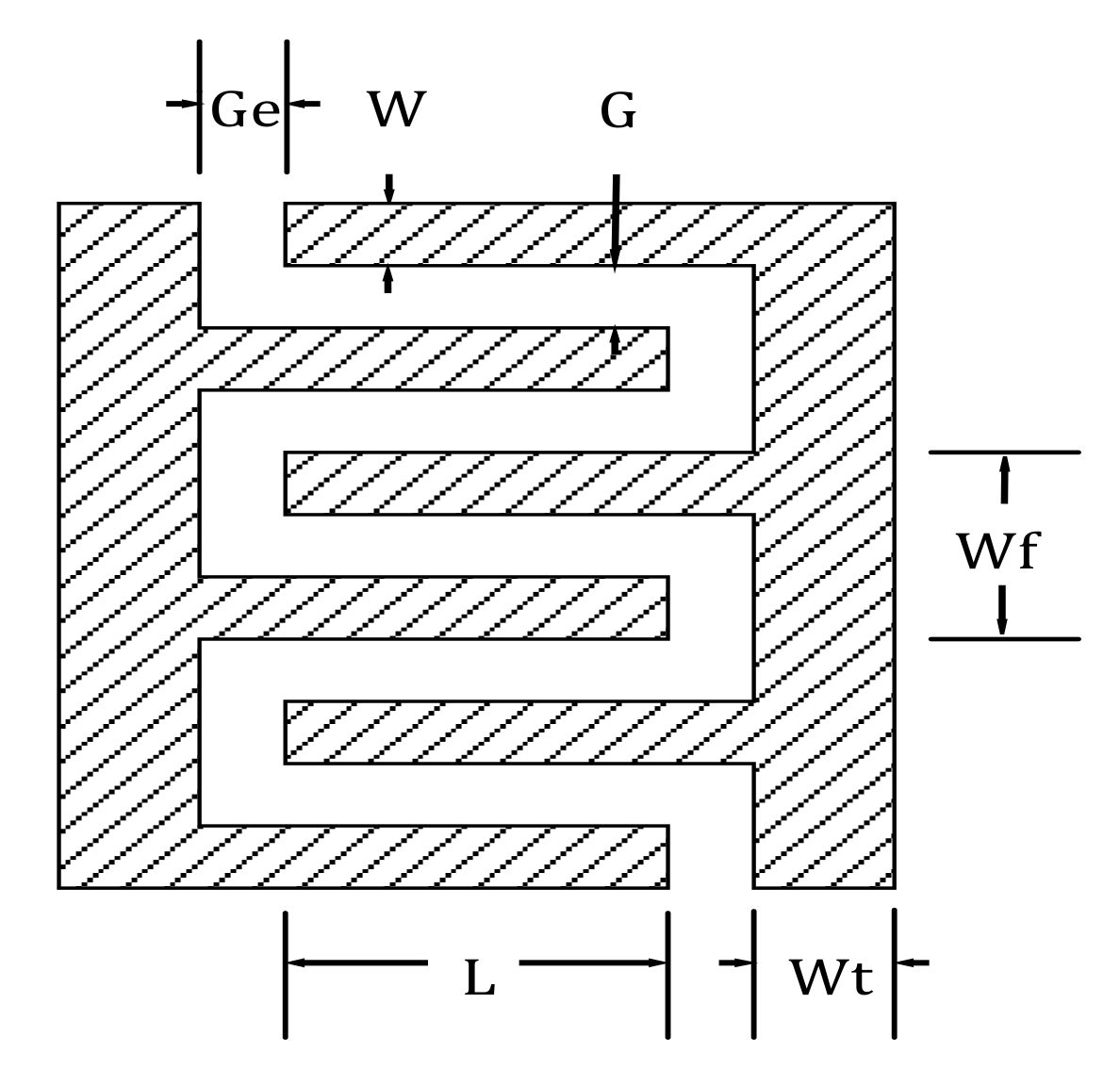
Interdigital capacitor, as shown in
Figure 4, is used to test and verify the accuracy and generalization of the neural network. Its geometrical parameters are listed in
Table 2.
The input and output parameters of the deep neural network with these two RF devices is shown in the
Table 3.
3.2. Dataset and Feature Scaling
In order to verify the accuracy and generalization ability of the trained model, two training datasets are taken from the EM simulation. The first dataset uses uniform sampling data (see
Table 4) the total number of instances is 2421, whereas the second dataset uses non-uniform sampling data (see
Table 5) the total number of instances is 1156.
In order to prove deep learning has the capability to handle complex dataset and make accurate prediction, the step and gap in the second dataset are chosen randomly. Before applying the training data to the neural network, the original dataset needs to be preprocessed. In
Table 4 and
Table 5, the range of the input parameters are different from one another. Thus, normalization is highly necessary for the training data. If no normalization is performed, some parameters vary greatly while other parameters have very small ranges of variations. As a consequence, the parameters have different effects on the weighting term and the bias term, thereby leading to continuous adjustment of the learning rate during optimization and causing the training gradient to fall in a “zigzag” manner, which results in very low training efficiency and even makes the training difficult to perform.
Pretreated by the normalization, the speed of the optimization algorithm for training the deep neural network can be effectively accelerated, and the accuracy can be also highly improved. The min–max normalization, which is often known as the feature scaling, is used herein, in which the values of a numeric range of a feature of data, i.e., a property, are compressed to a scale between −1 and 1.
Moreover, the original dataset needs to be divided into a training data and a testing data. The raw dataset is randomly shuffled and then 80% of it is assigned as a training data while 20% as a testing data [
12].
Table 6 lists a randomly chosen test data for the rectangular inductor.
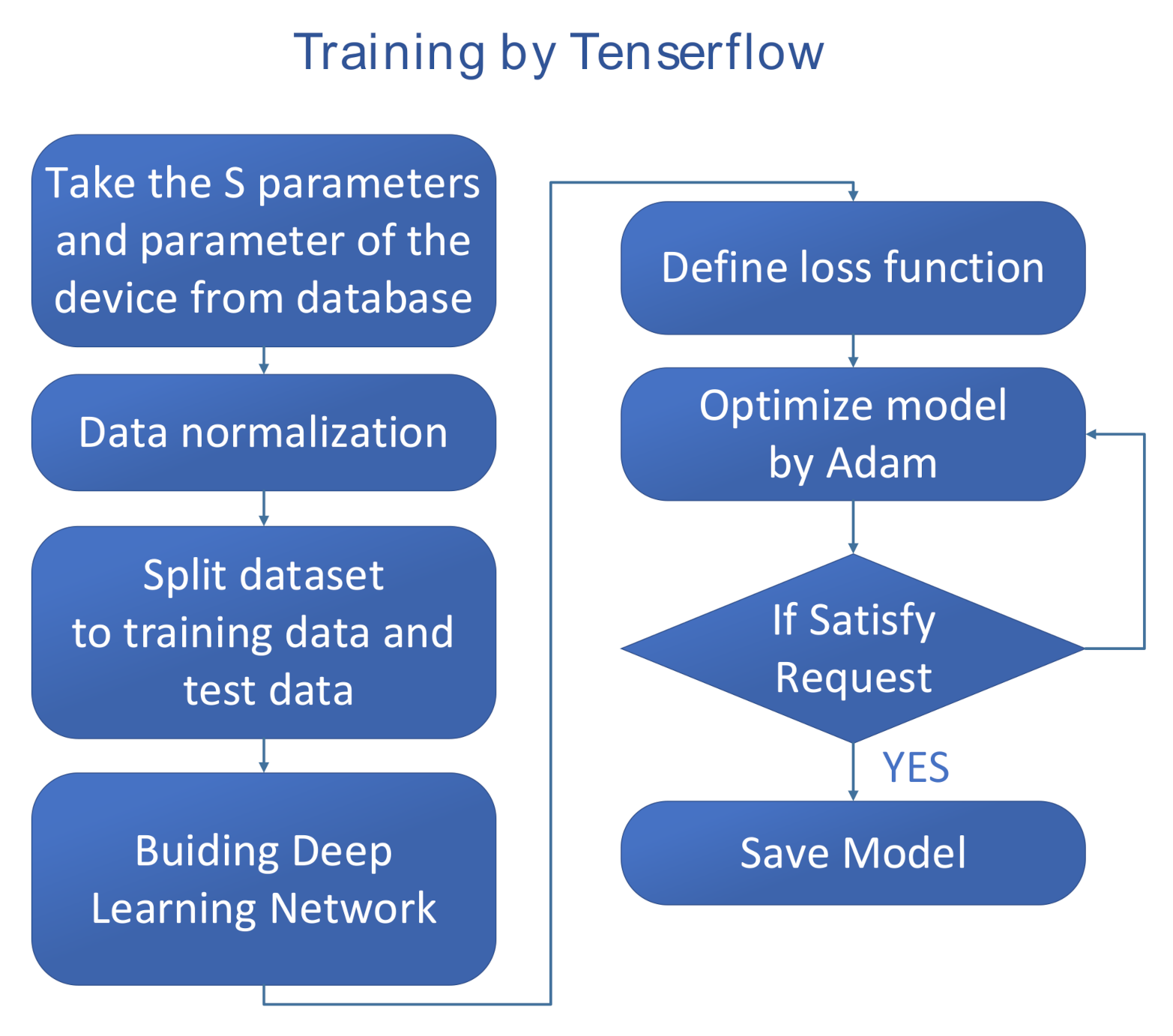
3.3. Training Process
The backpropagation is the core method to training the neural network. It can optimize the weights and biases in the neural network according to the defined loss function in each epoch, so that the resulted loss function can reach a small value.
As mentioned before, many advanced optimization algorithms have been proposed. Herein, the Adam algorithm is used for optimization, which is formulated as follows:
where
is the gradient of the loss function at the
t-th iteration,
and
are the delay factors,
and
are the biased first moment estimate and the biased second raw moment estimate of the gradient, respectively,
and
are the bias-corrected first moment estimate and the bias-corrected second raw moment estimate, respectively,
is the updated parameter of
, and
and
are two constants.
In the optimization of the loss function, the Adam optimization algorithm uses the iteration number and the delay factor to correct the gradient mean and the gradient square mean, accelerate the learning speed and efficiency, and adjust the learning rate automatically. Good default settings for the tested machine learning problems are = 0.001, = 0.9, = 0.999 and = .
The Adam optimization algorithm combines Adagrad’s [
13] advantage in dealing with sparse gradients and RMSprop’s ability to handle non-stationary targets. With less memory requirements, it calculates different adaptive learning rates for different parameters, and is also suitable for most non-convex optimizations for large datasets and high dimensional spaces.
5. Conclusions
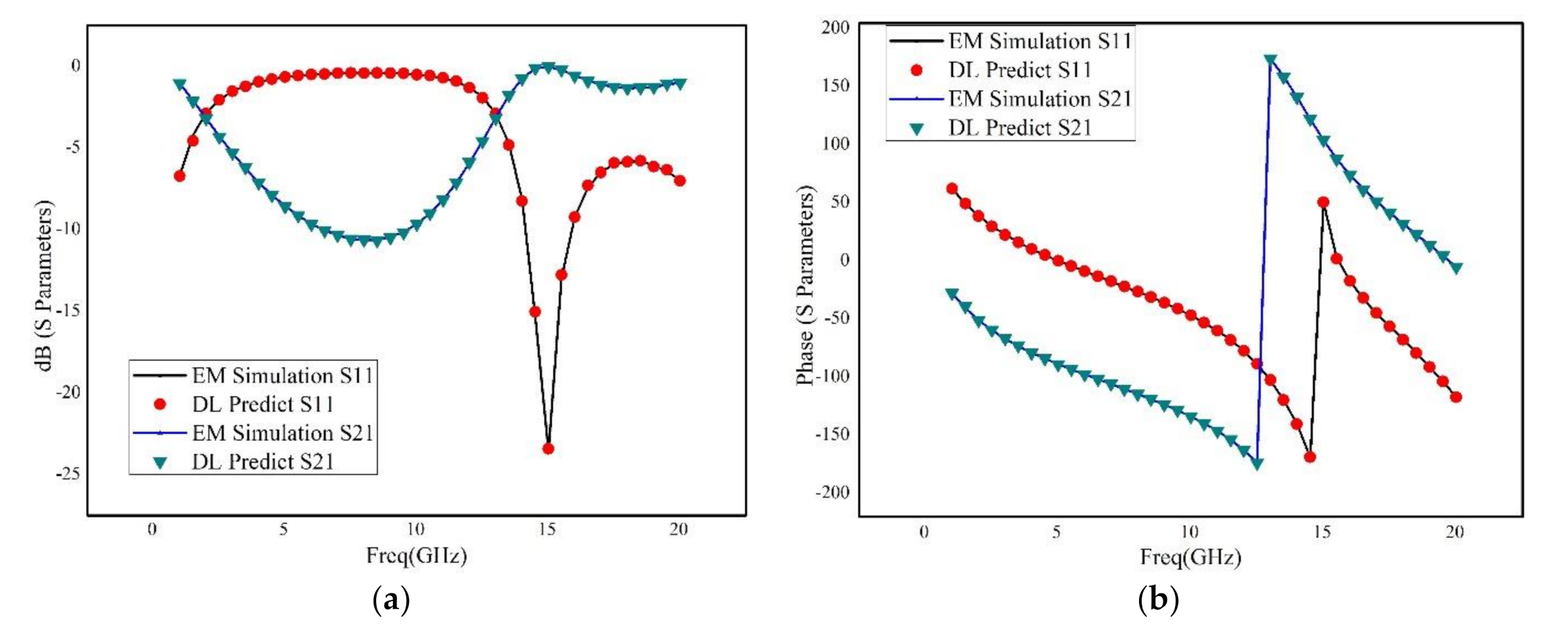
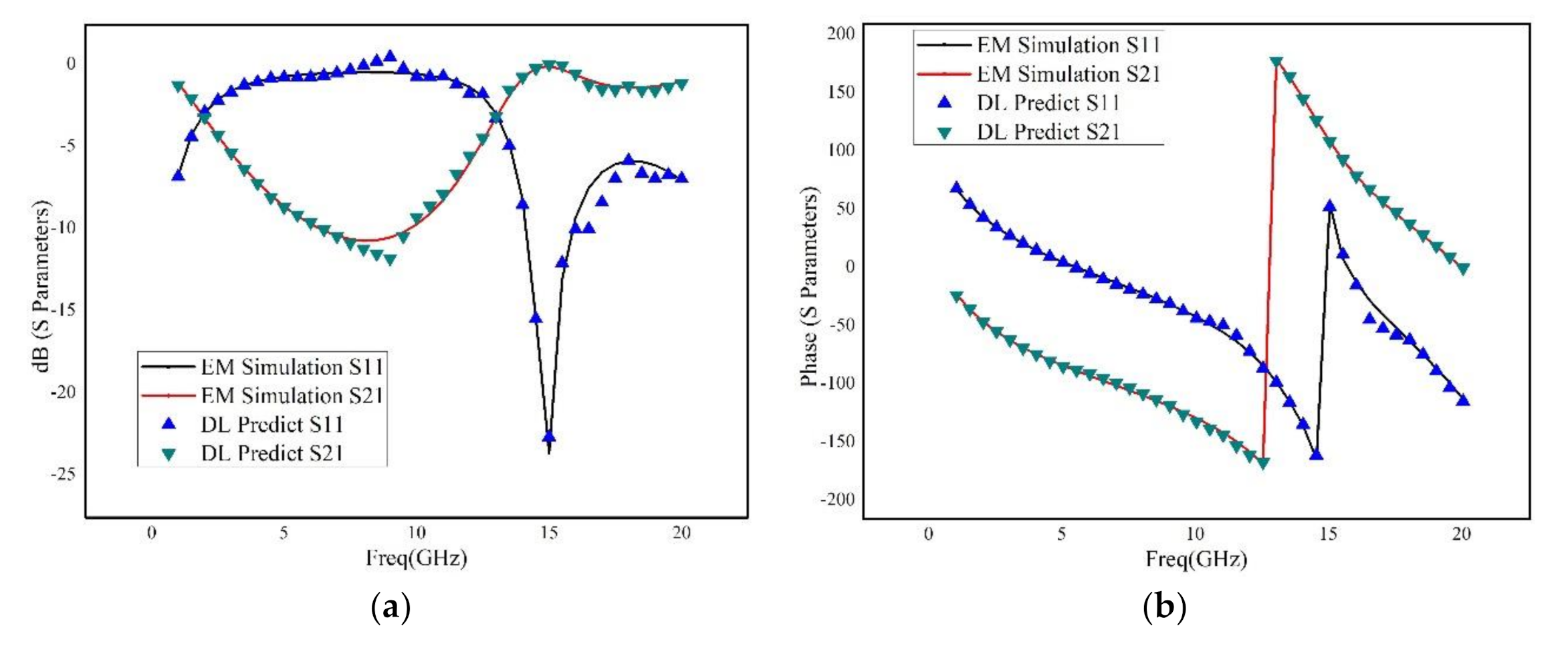
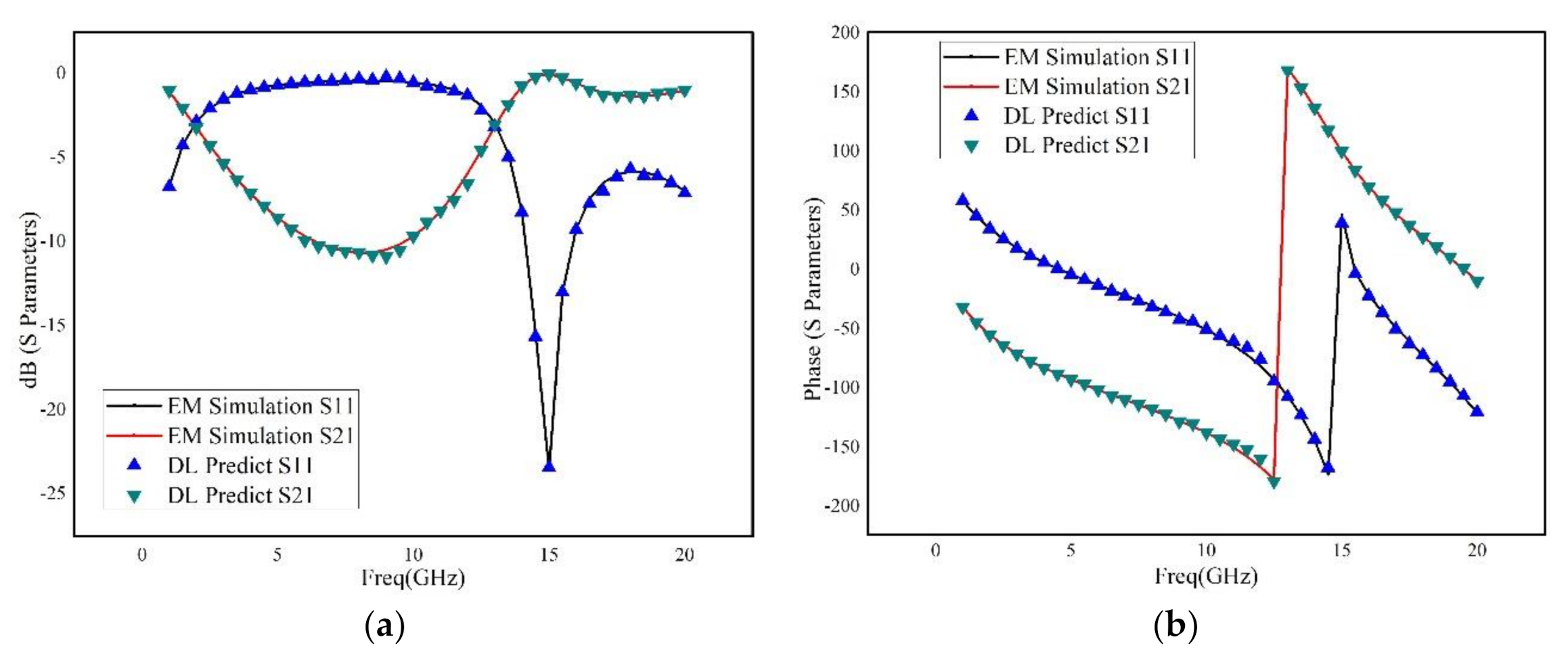
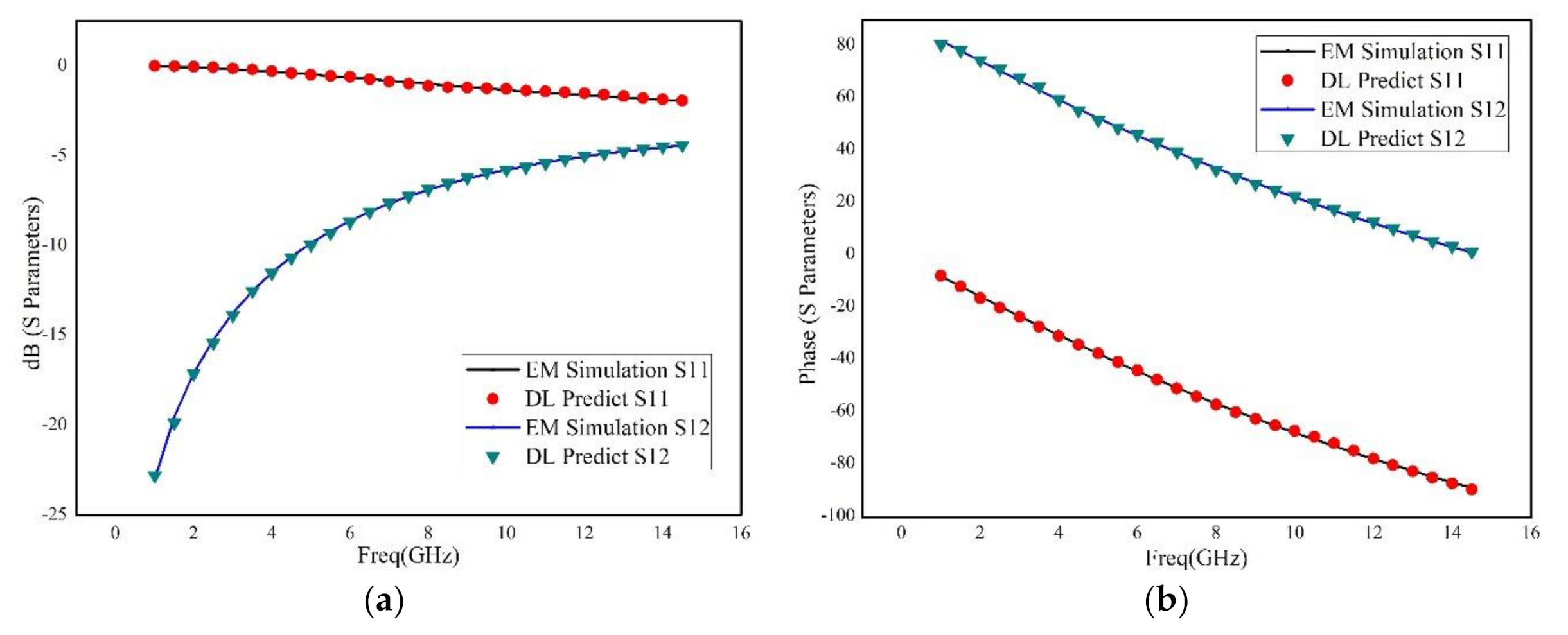
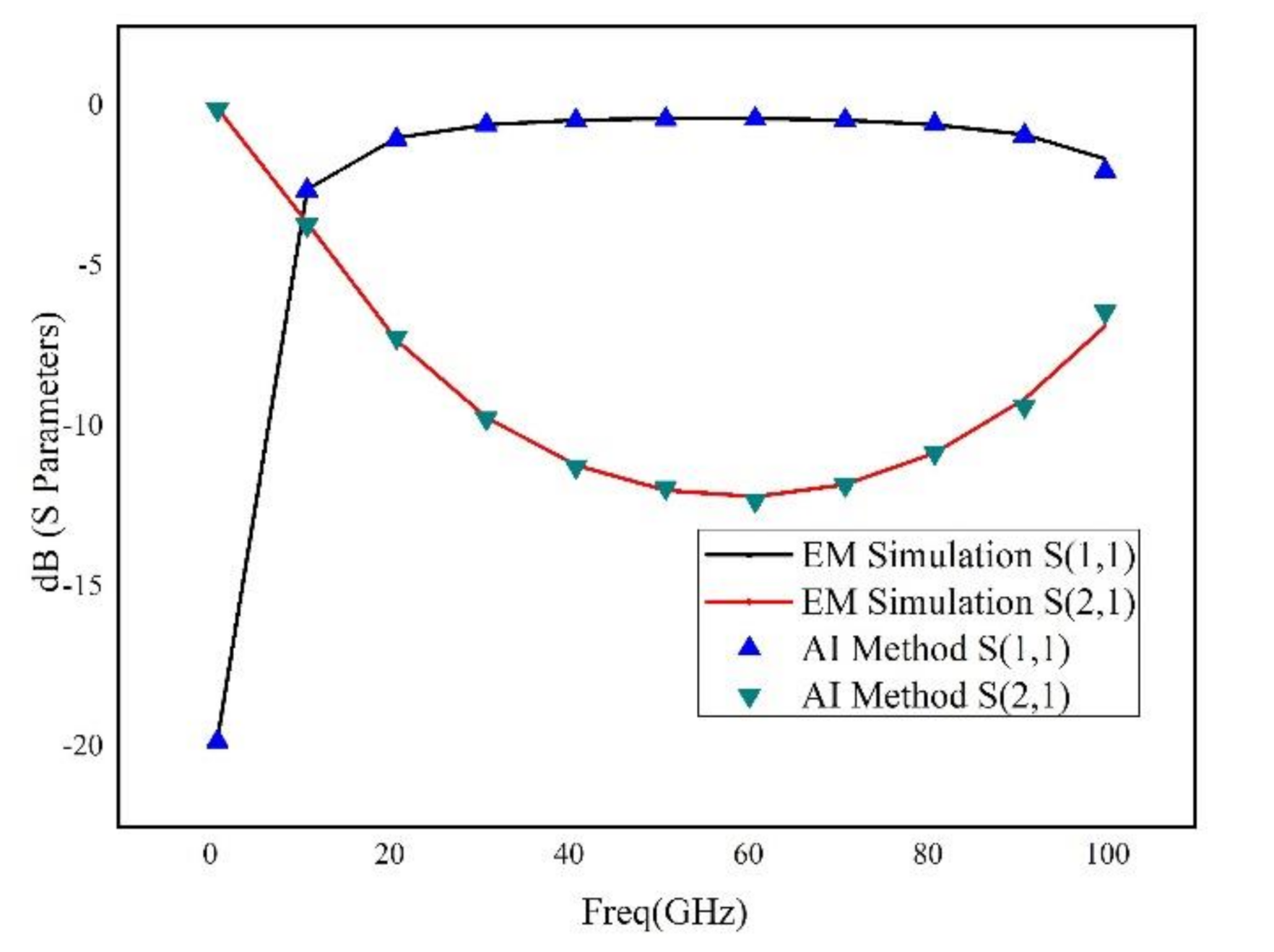
An advanced method of modeling RF devices based on deep learning has been proposed. Using Tensorflow deep learning structure, the deep neural network has been constructed, which has significant advantage over the shallow neural network. The Adam optimization algorithm has been adopted, which makes the training more effectively and accurately. In addition, not only the metallic geometry of the structure, but also the permittivity and thickness of the dielectric layers are revised during the sweeping process. Moreover, a novel selection method of training data considering critical points was introduced, and an adaptive method for adjusting the number of hidden-layer of the neural networks based on the frequency response was proposed, which can significantly reduce the time of training procedure and guarantee the accuracy of generated model. Three RF devices, including a rectangular inductor, an interdigital capacitor and two coupled transmission lines, are used for building and verifying the deep neural network. The results illustrated that the deep neural network has good robustness and excellent generalization ability. Even for very wide frequency band prediction, the proposed method has very small relative error by comparison to the brute-force full-wave results.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}