The number of successful applications of machine learning algorithms is constantly growing. Unlike classic approaches, deep neural networks (DNNs) are naturally predisposed to efficiently handle vast amounts of data. They successfully cope with inaccurate or noisy data, different sizes and orientations of objects, as well as, varying lighting conditions. Moreover, if these algorithms are properly selected and trained, they have a high capacity to generalise the acquired knowledge. The latter is extremely important in practical applications where we have to struggle with a variety of cases, small, yet significant differences between classes, and a large diversity of objects within a class or an insufficient number of appropriately labelled unbalanced data.
1.2. Problem Statement and Related Works
The problem of CMB detection has been considered in a number of publications in recent years. Based on their analysis, several important challenges and conclusions regarding data, approaches and algorithms can be indicated.
Despite the great success of ML-based systems in the medical field, which outperforms other classic methods, there are many problems related to the use of algorithms. Among others: insufficient number of publicly available, labelled datasets; different quality and resolution of data; uneven class balance within the datasets; still poor ability to generalise results in some cases; and inconsistent evaluation of results, hindering their analysis [
13,
14,
15,
16,
17,
18,
19,
20].
In this paper, we try to discuss and find a solution to some of them in the case of CMB detection. Our extensive analysis and experiments were conducted to propose a way of synthesis the suitable DNN-based system for reliable CMB detection, which shows high performance and generalisation ability.
The problem of data shortage is common in the analysis of medical data. In radiology, class annotations alone are hardly enough for most prediction tasks. CMB similarly requires manually annotated bounding boxes or segmentation masks, which have to be done by medical experts. Such a precise manual data annotation is not only expensive and time-consuming, but also requires data anonymisation, and still, the CMBs are labelled only by a single point. Mostly, new datasets are created for specific research carried out by research teams. They are not later published due to complicated privacy regulations.
Moreover, existing datasets are prepared by different groups with different measurement equipment, medical procedures and also, for different purposes (e.g., strictly for the needs of physicians, data analysts, ML specialists). For instance, there are differences between the labelling methodology or the examination parameters. Not only the MRI machines specification depends on their producer, but also during the MRI examination technician set parameters depending on a case. The differences between patient origin are also crucial, as the human anatomical structure is different.
Therefore, although datasets seem similar, especially for non-specialists in the medical field, to design a data-driven decision-support system able to efficiently operate in very different conditions, it is essential to have scans as diversified as possible.
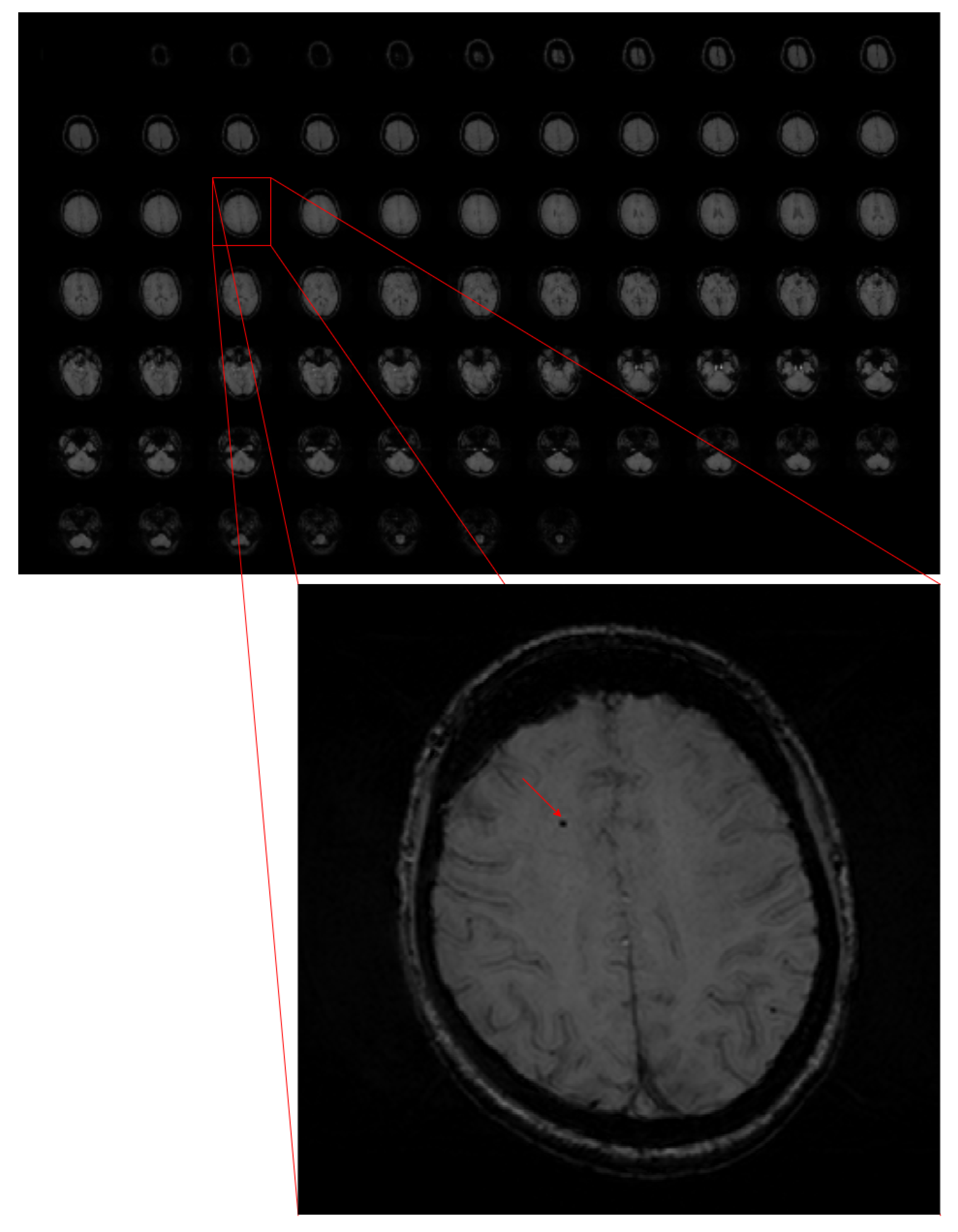
In the case of automatic detection systems, it is fairly easy to mistake microbleeds with other objects, mainly because of their small size compared to the whole image, their similarity to the background, and lesion mimics (see
Figure 1). For instance, an oval cross-section through a vessel or calcification is very similar to a CMB. The differences between microbleeds and other objects can be observed when rating the whole MRI altogether.
Sometimes, it is difficult to objectively compare the research results because, as mentioned earlier, there is a lack of objective benchmark databases. Besides, different metrics are used to evaluate the systems. For example, sensitivity is sometimes the only metric reported. However, it is relatively easy to obtain high sensitivity scores, but at the price of a large number of false positives. To avoid this, other metrics should also be provided—for instance, precision or FPavg (average number of false positives per subject). Of course, the goal is to have as high sensitivity as possible with a low false-positives score.
The development of ML methods has caused that traditional methods of image processing and analysis have been replaced by methods using mainly different types of tools based on deep neural networks.
Generally, ML-based solutions for object detection tasks may be divided into two groups: one-stage and two-stage detectors. In one-stage detectors, both detecting an object and assigning it to the predefined class are done at the same time, while in the two-stage approach, these two sub-tasks are carried out separately by producing the regions of interest (RoI) and then its classification.
The most popular representative of the one-stage approach is the family of YOLO (You Only Look Once) networks, the most recent ones are YOLOv4 [
21], scaled YOLO [
22] and YOLOv5 [
23]. Although such approaches are much faster than two-stage ones, they produce a larger number of false positives and have significantly worse results for detecting small objects. This problem is clearly visible in the work [
24]. The YOLO detector produces dozens of false-positive CMBs for one subject; hence, another stage is needed to reduce them.
Although new and better architectures are emerging, such as EfficientDet [
25] and Vision Transformer [
26], the above-mentioned issues related to the one-step approach have not been diminished.
The most popular architecture from the family of two-stage detectors is R-CNN [
27,
28] and its successors. The idea was based on defining regions of the proposal using selective search [
29]. Then, scale them to a fixed size and apply them to a CNN network for feature extraction and finally to assign them the proper category using a linear SVM classifier. The biggest issue in this approach was the detection speed. Although computational capabilities continue to grow, creating more efficient algorithms makes them more usable in everyday life.
This led to an improvement called Fast R-CNN [
30] combining RCNN with Spatial Pyramid Pooling Network (SPPNet) [
31] that did not require the fixed size of the region of the proposal passed to CNN.
Another proposed solution to speed up the computation process was Faster RCNN [
32]. The novelty was in the generation of regions of interest by applying the Region Proposal Network (RPN). The interesting proposal was Feature Pyramid Networks (FPN) [
33] enabling usage of the whole CNN network, instead of just its top layer for the detection task. That enabled achieving significantly better results. These days, the mentioned architecture is often used in object detection problems with different backbone variants.
Regarding the detection of microbleeds, we can generally distinguish between two approaches, two-dimensional (2D) [
34,
35] and three-dimensional (3D) [
36,
37,
38]. However, three-dimensional convolutional networks have significantly more parameters. For instance, 2D ResNet-50 has 23.9M parameters, while 3D ResNet-50 46.4M has almost twice as much [
39]. That leads to high computational costs, without a significant improvement in sensitivity and precision.
Most of the proposed methods were based on a two-stage approach [
24,
36,
37,
40]. The first stage aimed to detect CMB candidates and was implemented in different ways, not always using neural networks; for example, the authors of [
37,
40] used fast radial symmetry transform (FRST). As a result, at this stage, it was possible to detect CMBs with high sensitivity, but the price for that is an enormous number of false-positives, which should be reduced in the next stage.
The challenge in 2D cerebral microbleeds detection is the fact that CMBs are mistaken with objects, like vessels, which are similar in two-dimensional space. The features to effectively distinguish CMBs from CMB mimics become apparent when analysing the sequence of adjacent slices and different types of images from the SWI sequence. Although cerebral microbleeds are best visible in the SWI, other ones also can be used to detect CMB. While most authors [
34,
35,
36,
37,
40] used only SWI, others used also Phase [
24], GRE [
41,
42], or QSM [
43]. The results reported in these papers and a comparison with our approach can be found in
Section 4.
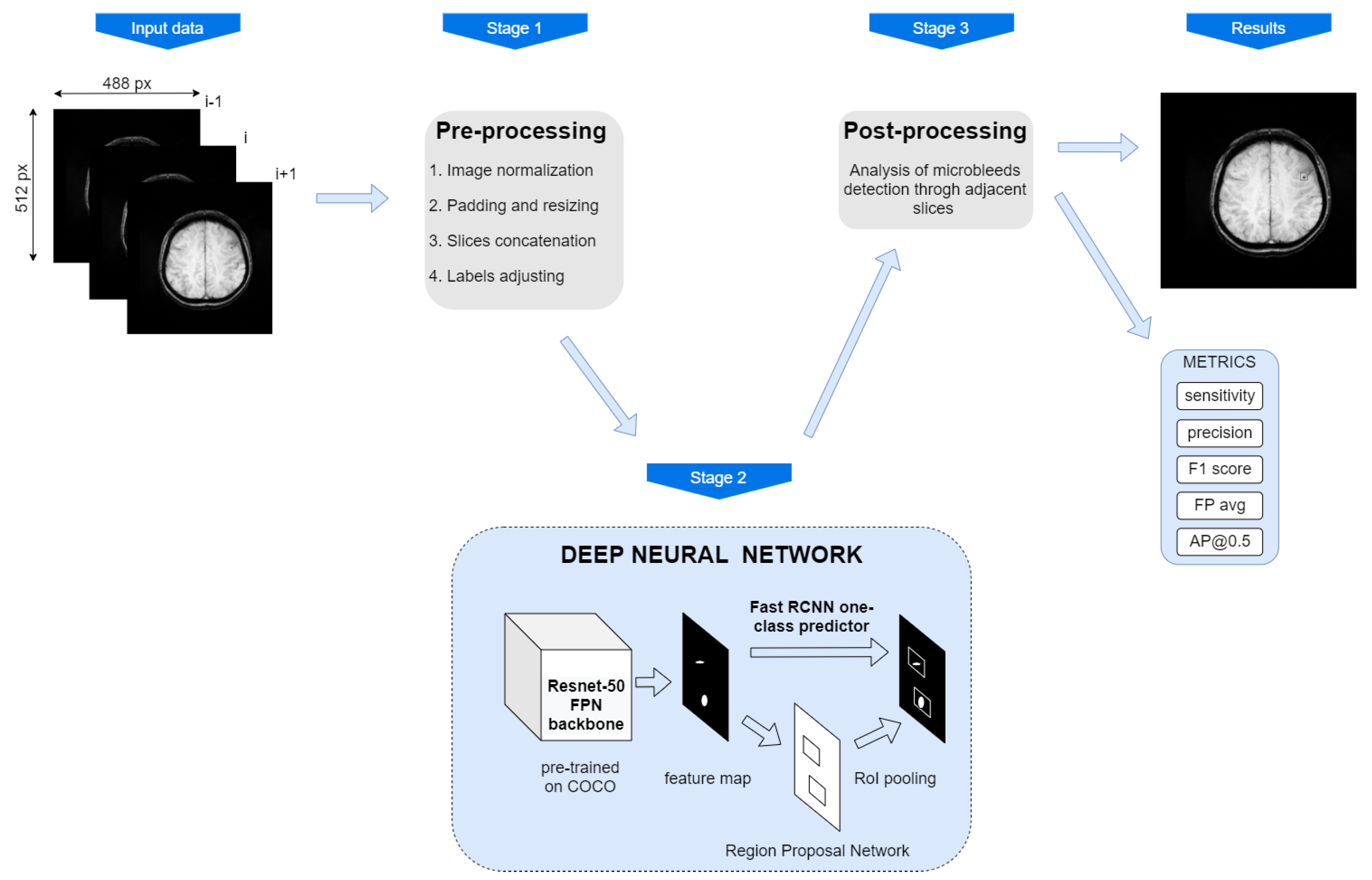
In this paper, we present the results of our efforts put into the synthesis of a cerebral microbleeds detection system. We aimed to achieve a reliable system, i.e., one characterised by both high sensitivity and precision. Therefore, we have researched and analysed, among others, the impact of the way the training data are provided to the system, their resolution, the way of input images pre-processing, the choice of model and its structure, and also the ways of regularisation. Finally, we proposed a new algorithm for the system’s predictions post-processing, which enabled us to partially take into account the three-dimensional nature of the analysed problem, despite using a 2D detector.
The results of the most interesting research are presented in Tables 3–7. The system with the most suitable structure was compared with the results reported by other research groups (see Table 8). Its performance was also tested on a different dataset, completely different from the data used to train, validate and test the system (see Table 7).


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}