1. Introduction
With the development of mobile communication technologies [
1,
2], such as the Internet and the Internet of Things, people can access large volumes of network information through intelligent mobile terminals. At the same time, mobile communication devices such as intelligent computers and smartphones are gradually becoming an indispensable part of people’s daily life. The creation and application of 5G technology manifest that the current network technology has risen to a new level. The opportunity network [
3,
4] is crucial for mobile communication in the new era. It has a broader application with the promotion of 5G.
Opportunity network is a self-organizing network that uses the encounter opportunities brought by node movement to achieve network communication. Opportunity networks do not require a complete path between the source and destination nodes. They rely on nodes to store data and move with it, exchanging and forwarding data when nodes meet [
5,
6]. With the development of social networks [
7,
8], nodes establish social relationships based on interest preferences, attributes. Interest communities followed, forming the current social networks of opportunity [
9,
10,
11].
Opportunity social network is a new type of mobile social network. As a particular self-organizing network that combines the mobile attributes possessed by social nodes and the communication attributes of network nodes, it can alleviate the problem of excessive load on base stations to a certain extent. However, because the opportunity network has overall sparse and local dense characteristics, the nodes do not move regularly. The communication relationship is easy to change, leading to network topology and uncertain routing complexity. At the same time, nodes serve as transmission roles and need to perform calculations, so the energy of nodes is small very quickly. If the nodes are not appropriately selected, the data transmission efficiency will be significantly reduced. Therefore, based on the above problems, we improve the current chance network algorithm and propose the concept of time-varying relational clusters, and construct time-varying relational clusters by comparing the correlation and regularity of nodes in the clusters in time and space. Comparing the migratory routes and dwell time, the most suitable message relay node is selected within the cluster to improve the success rate of message transmission and reduce the load pressure.
This paper proposes a query message routing algorithm (Time-varying Relationship Groups, TVRGs) based on time-varying relationship groups. This algorithm has the following three main contributions.
- (1)
According to the regularity of node movement and the social relationship between nodes, define node relationship group. Based on the time-varying characteristics of nodes and their interests, we classify nodes into relationship groups and predict the likelihood of nodes joining other groups.
- (2)
Based on (1), we a routing query algorithm based on Time-varying Relationship Group (TVRGs). The model compares the similarity of the moving sequence of nodes between groups and selects the node with the highest similarity as the message relay node. After that, transmit the information to find the responding node in the group to which it belongs and return it to the source node.
- (3)
Based on (2), we provide a query message routing algorithm and Binary Search Tree [
12] on time-varying groups of relations between groups are used to determine the time complexity as
. To evaluate the algorithm’s performance, we conduct simulation experiments. The simulation results show that the model has good performance compared with existing models.
In this paper, there are five parts. The first part is the introduction, which mainly introduces the general backdrop of the current 5G and the Internet of Things and the growth, presents drawbacks of mobile social networks. The second part is the related work. By introducing the message transmission mechanism of the opportunistic social network, divide the existing routing mechanism into three aspects and expound the main routing algorithm of each routing type. The time-varying Relationship Groups (TVRGs) algorithm is part three. Part four is the algorithm’s performance evaluation. The summary and outlook are part five.
2. Related Works
This section focuses on the rationale and features of available routing query algorithms and new algorithms’ design based on their advantages and disadvantages. In current years, professionals in academic and actual usage areas have extensively studied opportunistic social network algorithms and have tried multi-domain applications.
As opportunistic social networks continue to evolve, it is also essential to consider whether there are unique relationships between communities. Furthermore, nodes will form based on the social attributes of the nodes. According to many studies, the communication frequency of nodes in the same community will be higher. In reference [
13], Chen et al. improved the cache utilization by limiting the number of copies and deleting the useless data packets in the node cache in time. Simulations indicate that this improvement can improve the message delivery rate and solve the network load problem. However, the algorithm does not consider the various social attributes of nodes.
Aiming at the social attributes of nodes, in reference [
14], Alrfaay combined the attributes of social nodes with prediction schemes and used social attributes to predict the possibility of node data transmission. Simulation results demonstrate that the problems of cost and average hop count are greatly improved. Regarding node transmission delay, Liu proposed a fuzzy routing and forwarding algorithm (FCNS) [
15] that uses node social attributes and movement trajectories to determine the similarity between nodes. The scheme creatively selects the following two-hop relay nodes, which effectively reduces node transmission delay and dramatically enhances message delivery effectiveness. In reference [
16], to solve opportunistic social networks’ inequitable messaging success rate problem, Mtibaa proposed a real-time distributional framework, FOG. It can weigh efficiency, and equity implements two A real-time distributed fairness, algorithm PFA and algorithm MCFA. The algorithm is based on forwarding efficiency, cost, and node fairness in real-time choice, to ensure low overhead whereas achieving fairness–the trade-off of efficiency.
How to coordinate between nodes and how to distribute traffic is also the focus of current research. In reference [
17] in 2019, Xu et al. designed the fair and social-aware message forwarding (FSMF) algorithm in order to solve the problem of unfair traffic distribution and introduced the Markov chain model to assess the user’s social relationship. Thus the number of copies and the frequency of forwarding are limited. This algorithm dramatically improves the success rate of message transmission, and its overhead is relatively small. The efficiency of node transmission in opportunity social networks can also be improved by enhancing the cooperation between nodes. Li et al. designed a data forwarding algorithm based on group structure DDMGS is based on the user’s behavior attributes and relies on the topological structure of their interest relationships in reference [
18]. Construct groups and introduce cooperative game theory on this basis to strengthen the cooperation ability between nodes. In reference [
19], Wu et al. predicted the possibility of node data transmission through personal social attributes and social relationships and proposed that they could predict data transmission’s cooperation opportunities between nodes. According to the two parties’ predictions, it is determined whether to pass the message to the next node.
The above opportunity social network algorithm improves node community properties, message transmission fairness, and enhancing node cooperation, resulting in partial improvement in the algorithm’s transmission effectiveness and success rate. Our algorithm’s key point is to improve the query success rate of messages by comparing the similarity of mobile sequences between nodes to enable finding message transit nodes between different groups.
3. Model Design
3.1. Definition of Relationship Groups in Social Networks
In social networks, users can join relevant relationship groups according to their interests and preferences. The group members have many similarities, and the possibility of the meeting is increased to achieve more efficient message transmission. In the same group, users can timely pay attention to the update of the exciting content, and participate in the discussion, to better find friends. Within the same network, the attributes of an unknown node can refer to the attributes of the nodes closely connected to the group to analyze and predict the similarity of individual preferences, integrate into different groups, and help to transmit messages between different groups.
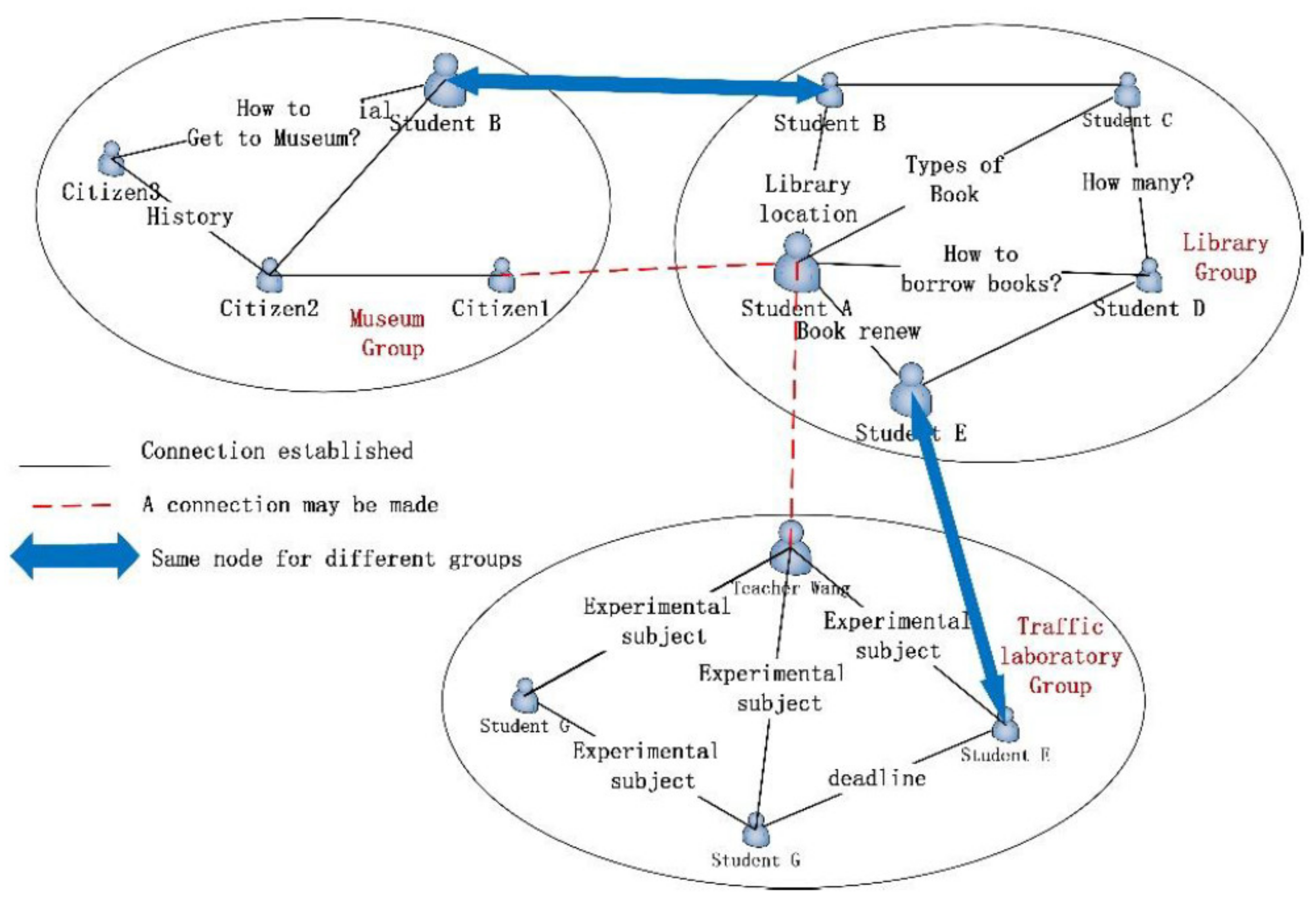
Figure 1 shows a possible network of user relationships in a current school. When student A joined the library topic and established A connection with group member B and member E, the likelihood of joining other topic groups of B and E increased. For example, if student B’s interests and hobbies also join the relationship group of the museum, student A may choose to join the information group related to the museum. Then, student A and student B have high similarity, and message transmission efficiency will be improved.
If a relational group needs to be constructed, a node must be selected as the center to explore its relationship with other nodes.
Figure 2 shows the main steps of constructing a relational cluster. First, node A needs to establish a communication relationship with node B and then derive their interests based on A and B attributes. Compare the similarity of interests of two nodes. If the similarity is high, then A and B are classified into the same cluster. Otherwise, the two nodes are nodes of different clusters. The same operation is performed for the remaining nodes except A to construct an entire relational group among all nodes. Nodes that are not classified into this relationship group are regrouped according to the above operation to complete the classification of all related groups. After that, the feature approximation is determined by calculating the message transmission probability between nodes and predicting the probability of establishing a pathway. Among them, the transmission probability indicates whether there is a possibility of establishing a transmission line between two nodes. Since nodes have more of the same attributes, the probability that a node can establish a pathway can be indicated by prediction. Both are derived from calculations on the one hand and predict by comparing the exact attributes.
3.2. Relationship Group Construction Based on Time-Varying Properties
The TVRGs routing algorithm is applied in a practical working scenario, as shown in
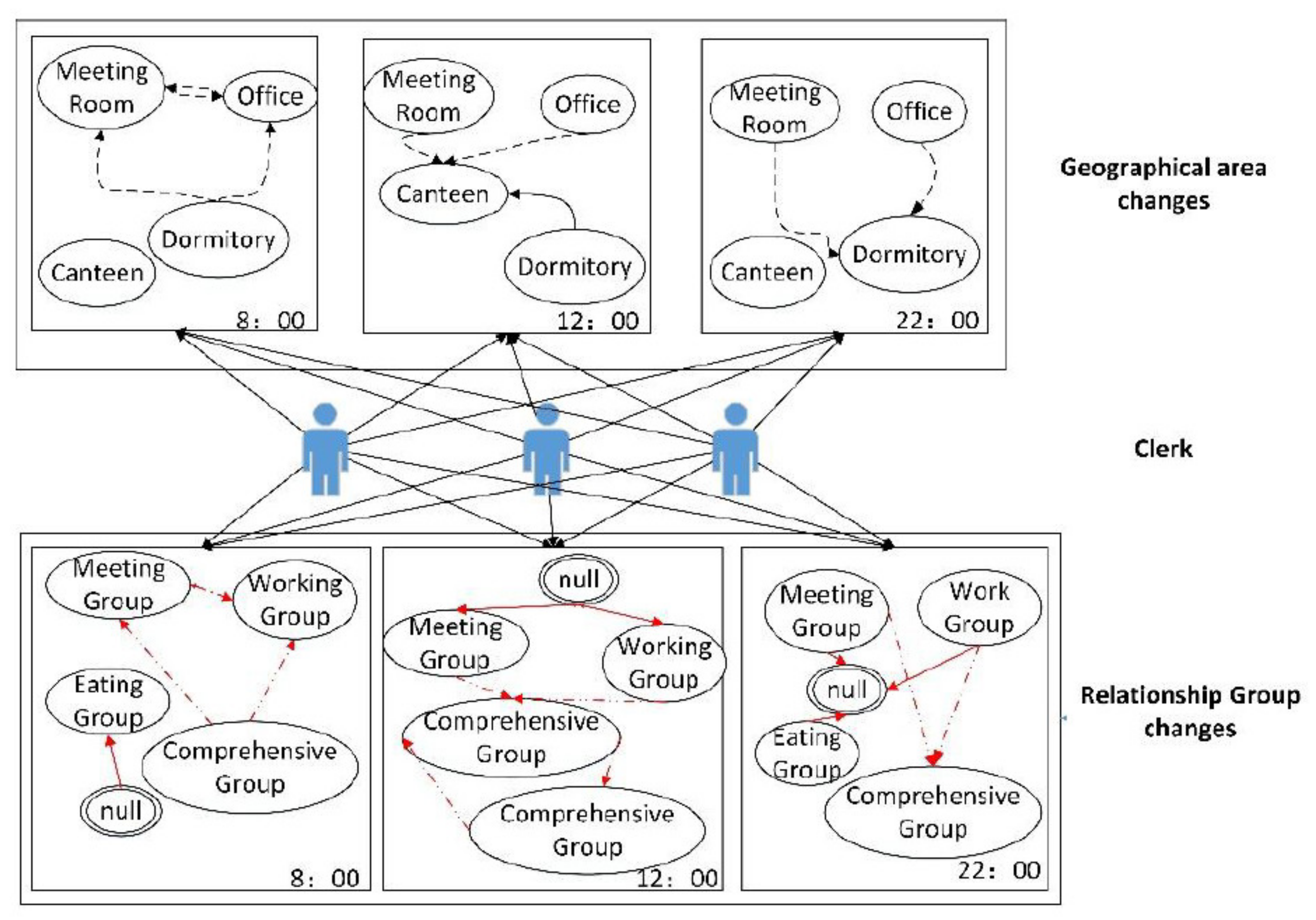
Figure 3 below. Set in the same group, when everyone’s activities are exact, the group is named directly by the activity, and the naming method does not affect the algorithm’s operation. If there is a non-single activity within the cluster at this time, set it as a comprehensive cluster. When no one in the group is involved in the activity, set it as an idle state. For example: at 8:00 a.m., when all members in the office area are working, the workgroup is built in the office area, and at this time, the activities of members in the dormitory area are more complex, the comprehensive group is built in the dormitory, and the meeting group is built in the conference room, and at this time there is no one in the cafeteria group, then the group is set to idle state. At 12:00 a.m., when employees enter the canteen to eat, the canteen can be set as a comprehensive group at this moment. The number of people in the working group and meeting group will significantly reduce and even enter an idle state. At 22:30 p.m., employees return to the dormitory to rest, and a dormitory is a comprehensive group at this time, while the other three groups are idle.
First of all, suppose that the constructed relationship group is converted between three-time states. The three-time states are the initial state, the transfer state, and the idle state (Null). The dynamic relationship group that changes over time is built as follows:
First, define two state matrices
and
, as shown in (1):
where
denotes the time matrix of state transfer between groups, subscripts
and
identify the state of the element state transition. For example, element
indicates the time required for the current group to transfer from state
to state
, and
is used to indicate the Boolean matrix of whether the transfer of the relational group is flourishing. From Equation (2), when
, it means that in unit time n (unit time can be hours, etc.), the relationship group successfully transfers state
to state
. The element
in
matrix is set to 1. Otherwise,
is 0, indicating that the state has not changed and remains
.
Then, after the end of the unit time
(
can be an hour or more, that is, not an instantaneous state), the probability of the relationship group transitioning from state
to state
is shown in (3).
Among them, represents the probability of the relational group transitioning from state to state . is derived from a large amount of data statistics. This is not discussed in this article. is obtained from the matrix .
Suppose the state transition of the relational group is not from
direct
to but through an intermediate state
, after the end of the unit time
(
can be an hour or more, that is, not an instantaneous state). In this case, the transition probability is as follows (4).
In summary, the expression of the state transition probability of the relational group is shown in the following (5).
3.3. Group Construction Based on the Closeness of Communication Relationships
Changes in a person’s lifestyle, circle of friends, circle of study, and work will lead to changes in the communication relationship between a person and other people in social life. Therefore, if needed to consider a person’s social relationship, time needs to be cycled. It can be divided into gender, and the significance of the nodes in the network is analyzed to calculate the communication affiliation and communicative intensity. First, communication closeness is defined. The closeness of communicative intimacy between nodes mainly includes the connection time, idle time, and communication frequency of nodes. According to the network, knots are directly linked or not; the communicating intimacy is divided into direct communicating intimacy and indirect communicating intimacy.
Definition 1. Direct communication relationship closeness relies on the average communication time between nodesandto expresses its closeness by its inverse. Its physical meaning is that the shorter the idle time of two nodes and the faster the subsequent encounter, the higher the direct communication relationship closeness, whose expression is shown in (6). Among them, represents the intimacy of the direct communication relationship between nodesand, represents the average contact time interval between nodesand. represents the frequency of contact between nodes within time, andrepresents the function of waiting time for the next meeting of two nodes after.
Definition 2. Indirect communication relationship closeness is between two nodes,and, which need a relay nodefor secondary communication. That closeness is described by the inverse accumulation of the average contact time between the three. The expression is shown in (7). Among them,represents the frequency of contact between nodeand nodein time, represents the frequency of contact between nodeand nodein time. represents the next time nodeand nodemeet aftertime. The waiting time,represents the function of waiting time for nodeand nodeto meet next time aftertime.
Assuming that there are a total of
nodes in the network, the social intimacy between each node can be calculated after obtaining the communication data information between the previous nodes. After that, the corresponding byte matrix
can be listed, which records the node and other nodes, the closeness value of the communication relationship. Then, input
as the numerical matrix of social intimacy, use the K-Means [
20,
21,
22] clustering algorithm to get the
K value, and then divide the best group according to the
K value.
3.4. Query Routing Algorithm Based on Time-Varying Dynamic Relational Groups
The time-varying relational group-based query message routing algorithm TVRGs includes intra-cluster queries and inter-cluster queries. The intra-cluster queries are mainly found using the dichotomous algorithm of the Binary Search Tree, the details of which are not described in this paper. The intergroup query algorithm will be described in detail in the following.
Definition 3. Communication location.
Correspondence location indicates the current moment of node . The coordinates of the latitude and the time information of this moment need to be provided with .
Definition 4. Stay time and Stay activity area.
The stay time is equal to , where represents the time to enter a particular area, and represents the time to leave a specific area.
The stay activity area represents the activity area of the node within the stay time , where represents node at time . represents the location of node at , and represents the straight-line distance between two points.
Definition 5. Movement route.
The node’s movement route refers to the node’s movement route in the staying activity area during the stay time, which is mainly composed of the position of each stay and is represented by the following (8) and (9).
Among them, represents the node’s moving route, represents the location of the node at time , represents the time the node stays in area , represents node ’s the importance of , that is, the node weight which is calculated from . represents the frequency with which the node visits the area, which is from the statistics.
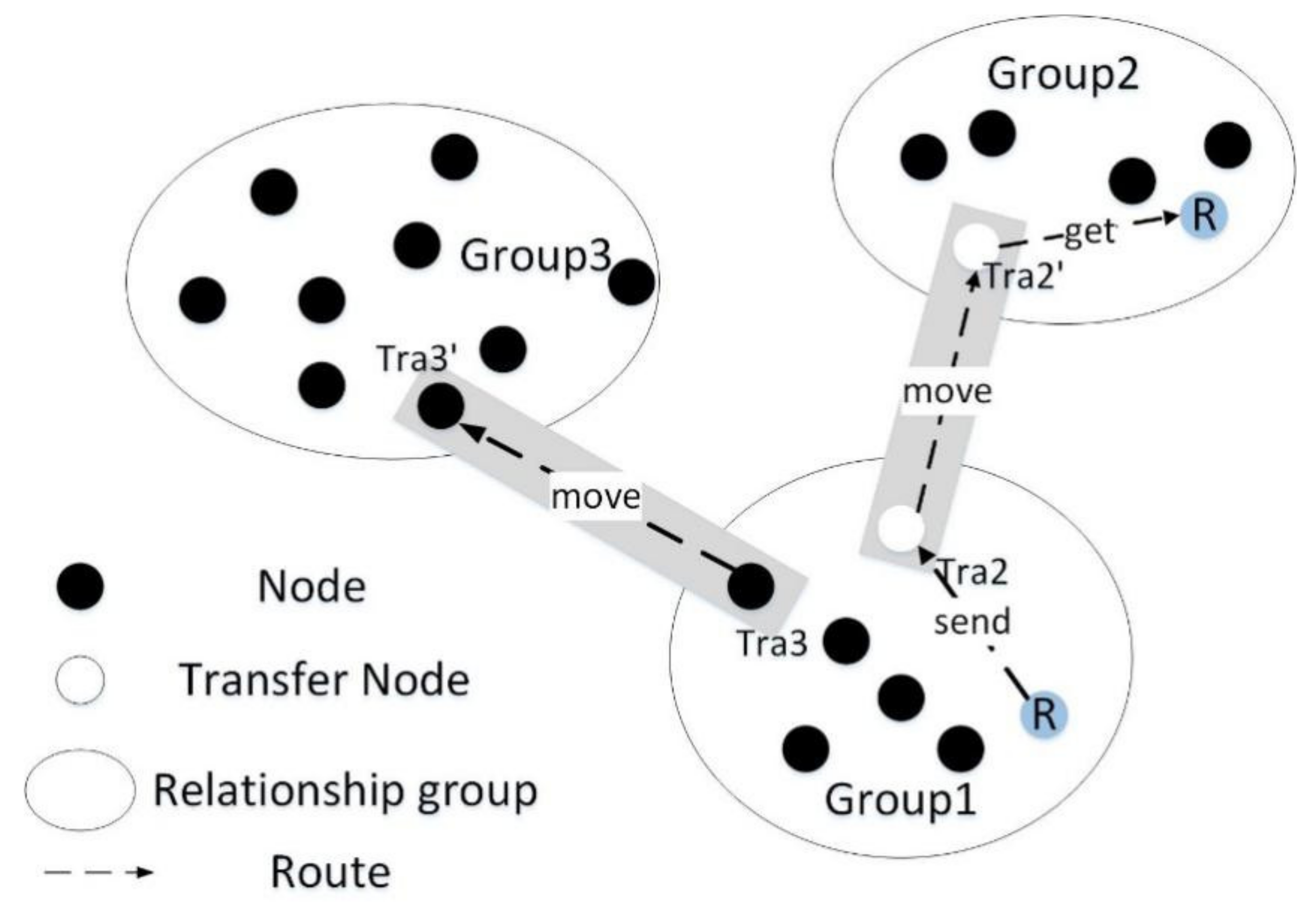
Next, it is necessary to update the moving route and moving position sequence of the node according to the importance of each node in each area. According to the previous definition, when the activity routes of two nodes overlap more, it proves that the highest interest similarity of the two nodes. Nodes with high-interest similarity and frequent activities between different relationship groups are selected as message relay nodes to help message forwarding between different groups. The following algorithm will describe an inter-group message query algorithm in detail based on the node’s moving route position sequence similarity.
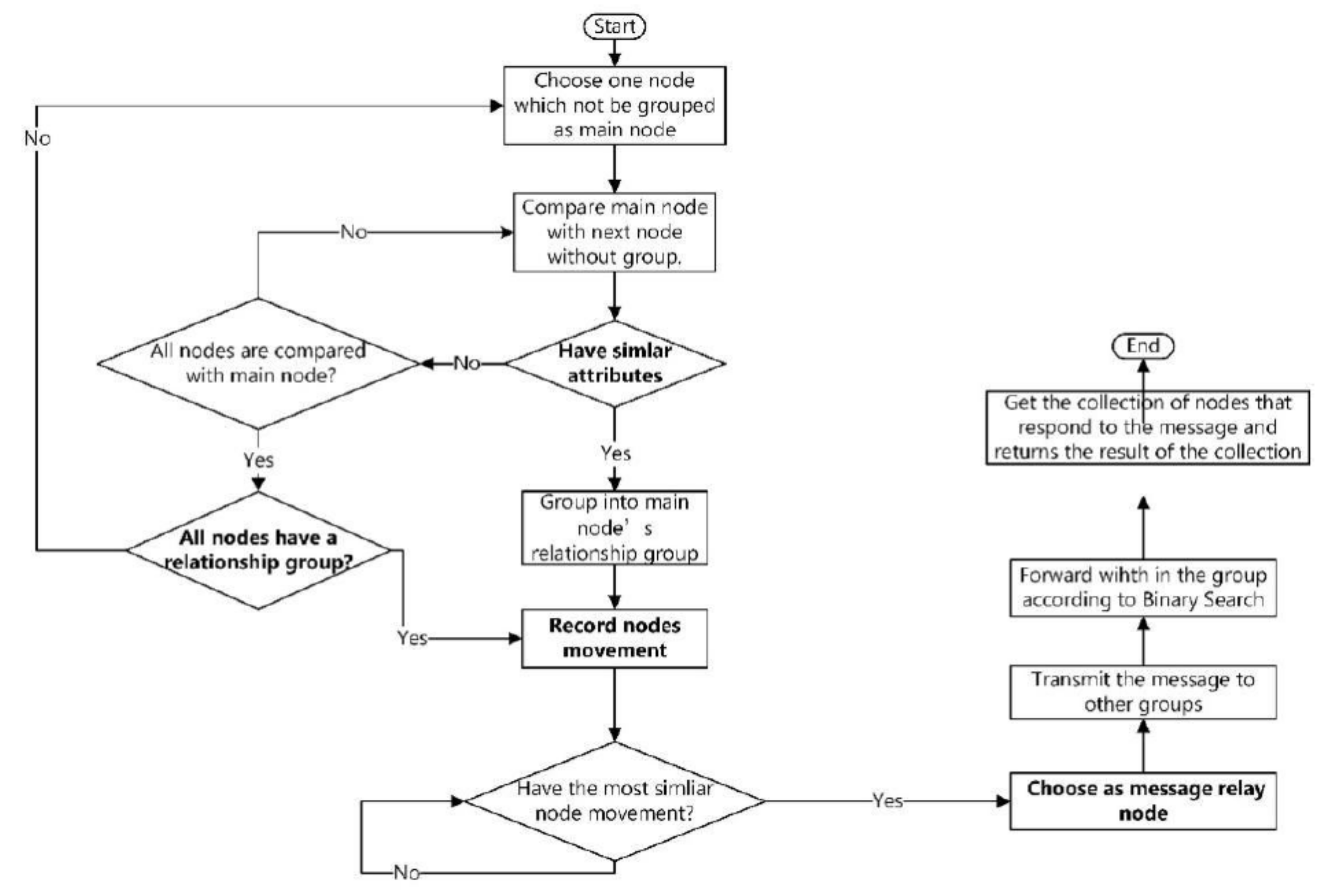
Figure 4 is the execution of the algorithm. When the node
carrying the message in Algorithm 1 has no response to the query message, it finds a message relay node
in the other two clusters, respectively. Then by comparing the similarity of the sequence of mobile nodes with the message relay node, it finds that the higher similarity with
, so it sends the query message to the relay node
, and then
uses the Binary Search Tree algorithm to forward and finally find the response node
.
| Algorithm 1. Inter-cluster message query algorithm based on the similarity of nodes’ mobile route location sequences algorithm. |
| Input: Mobile Area m, Arrival Area collection The query node carries a total of messages |
| Output: Optimal Relay node ; |
Begin
The node which carry the message moves to each region;
for(i = 0; i < m; i++){
for(j = 0; j < m; j++){
If(The rest region of node ){
Add to i’s moving route sequence
}
End If
}
End for
}
End for
when(no node response){
Count the sequence reached by i;
Make i as relay node;
}
The message is transmitted to the transit node of each group;
Forward within the group according to Binary Search Tree algorithm;
Get response;
End Begin |
The time complexity of the TVRGs of this algorithm is analyzed in the following. It is assumed that in the scenario of the above Algorithm 1, that is, there are the mobile areas of nodes in the group. The message shares carried by the nodes is queried. The selection of mobile location sequence generation and message transfer node in Algorithm 1 is , the best time complexity for finding the optimal message transfer node is , and the worst time complexity is . The Binary Search Tree algorithm is used within the community. The best algorithm’s time complexity is , and the worst is . is a constant so that is a constant. So, within the community, the time complexity can be set to . In summary, the overall time complexity is . Since is a constant, , its time complexity is .
4. Experimental Design
In this paper, we use the ONE simulation platform to simulate the improved algorithm and compare the performance with the FSMF algorithm of [
16], the DDMGS algorithm of [
17], and the classical Epidemic algorithm of [
23,
24,
25] mentioned in related works. In the simulation, we chose to use Shortest Path Map-Based Movement (SPMBM) method in an existing city map street to record the movement trajectory of user nodes by simulating the experiment in a natural environment and collecting the coordinate data of the nodes. In addition, the simulation uses an open street map to edit the Helsinki city map [
26], in which real application scenarios are established, including stores, parks, neighborhoods, which can show the natural environment [
27,
28]. The relational clusters are established according to the above method. According to the recorded node coordinate positions, the trajectory similarity is compared to find the best message relay node in the cluster. The parameters of this simulation experiment are shown in
Table 1 below, and the simulation scene is shown in Figure 9.
The performance of the TVRGs algorithm is compared with the classical Epidemic algorithm and the FSMF and DDMGS algorithms mentioned in related works in terms of transmission success rate, average delay, and average overhead in different cases to verify their performance. In this paper, we can design the source node that needs to send query messages. We first compare the nodes and their neighbors during the simulation to derive the number of neighboring nodes in TVRGs at which the node best suits message transmission. In the experiments, we calculated the average value over a total of 2000 nodes.
During the simulation, we first divide each node into corresponding relationship clusters. Then the number of encounters of each node with other nodes is recorded to derive how many nodes are suitable as message relay nodes for inter-cluster message delivery.
Figure 5 represents the relationship between the success rate of message delivery and the number of node encounters. It can be seen that when the total number of encounter nodes increases to four, its message delivery success rate is close to 90%. However, when the number of encounter nodes exceeds four, there is a large amount of redundancy in its messages, which causes a waste of resources and thus makes the delivery rate decrease.
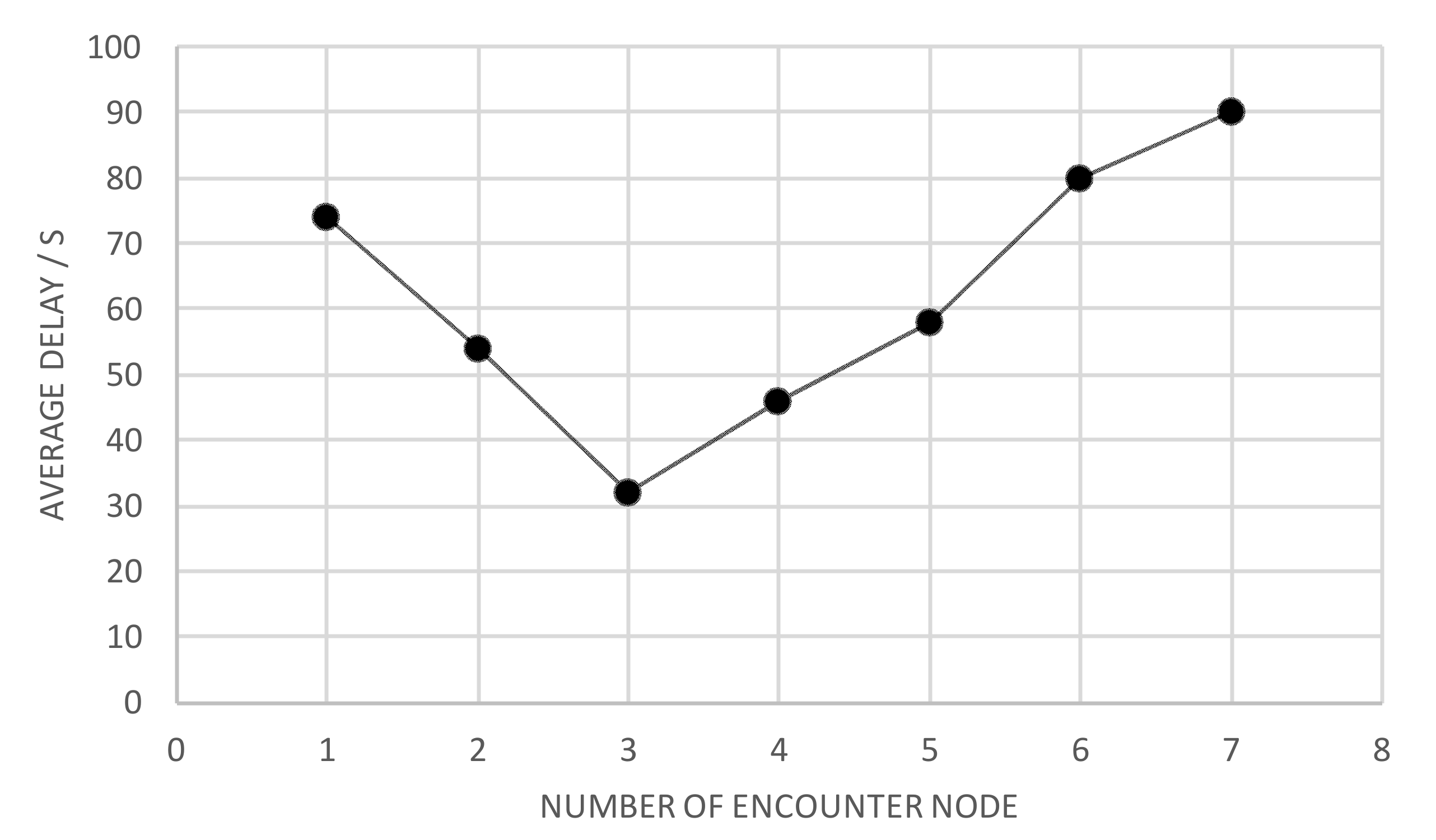
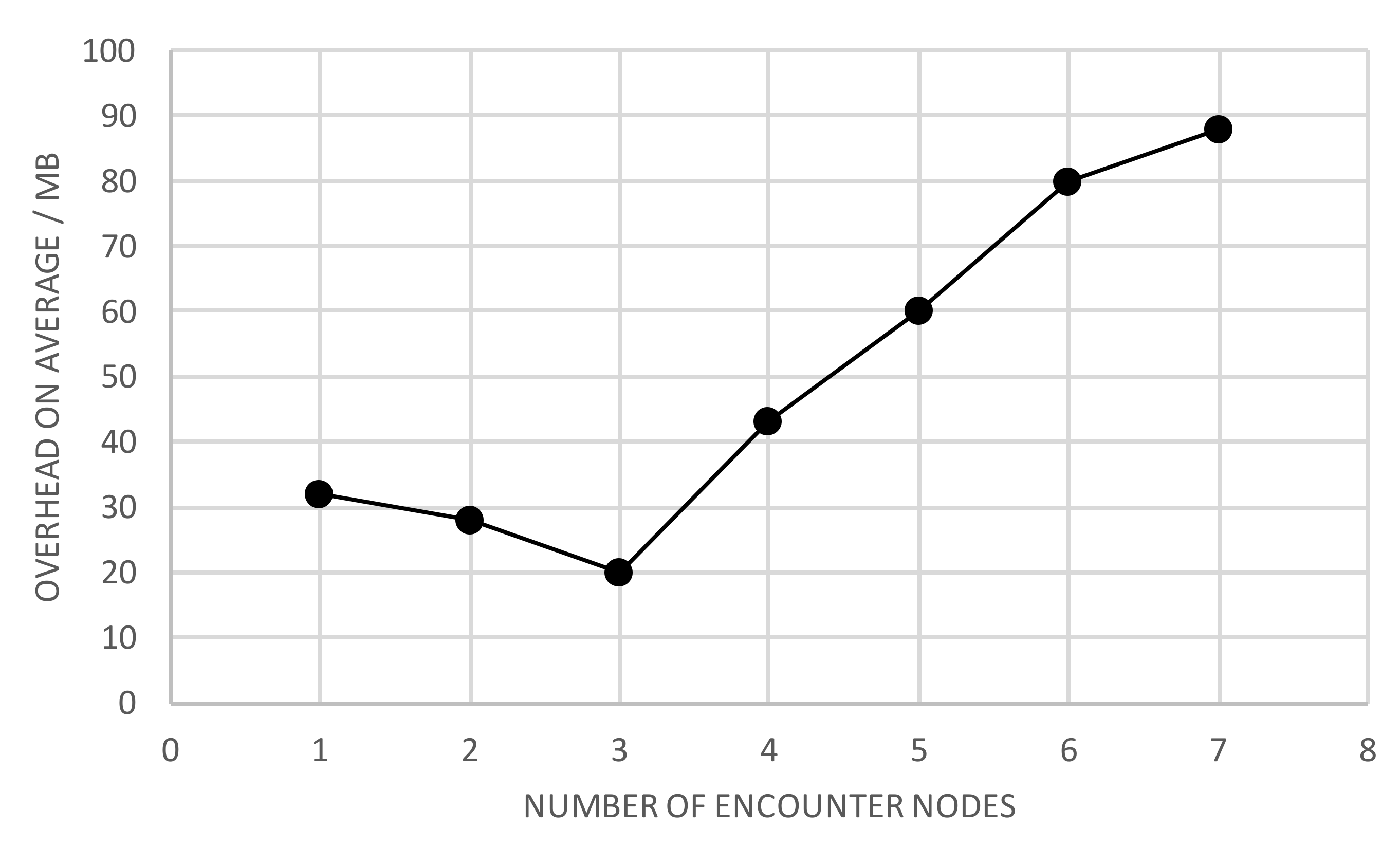
Figure 6 shows the average latency versus the number of encounter nodes. If the number of encounter nodes is relatively small, the node with better performance in all aspects can be selected as the message relay node, thus reducing the latency. With more than three encounter nodes, selecting the relay node increases, and the number of packet copies also increases. Similarly, the resulting overhead also increases, as shown in
Figure 7.
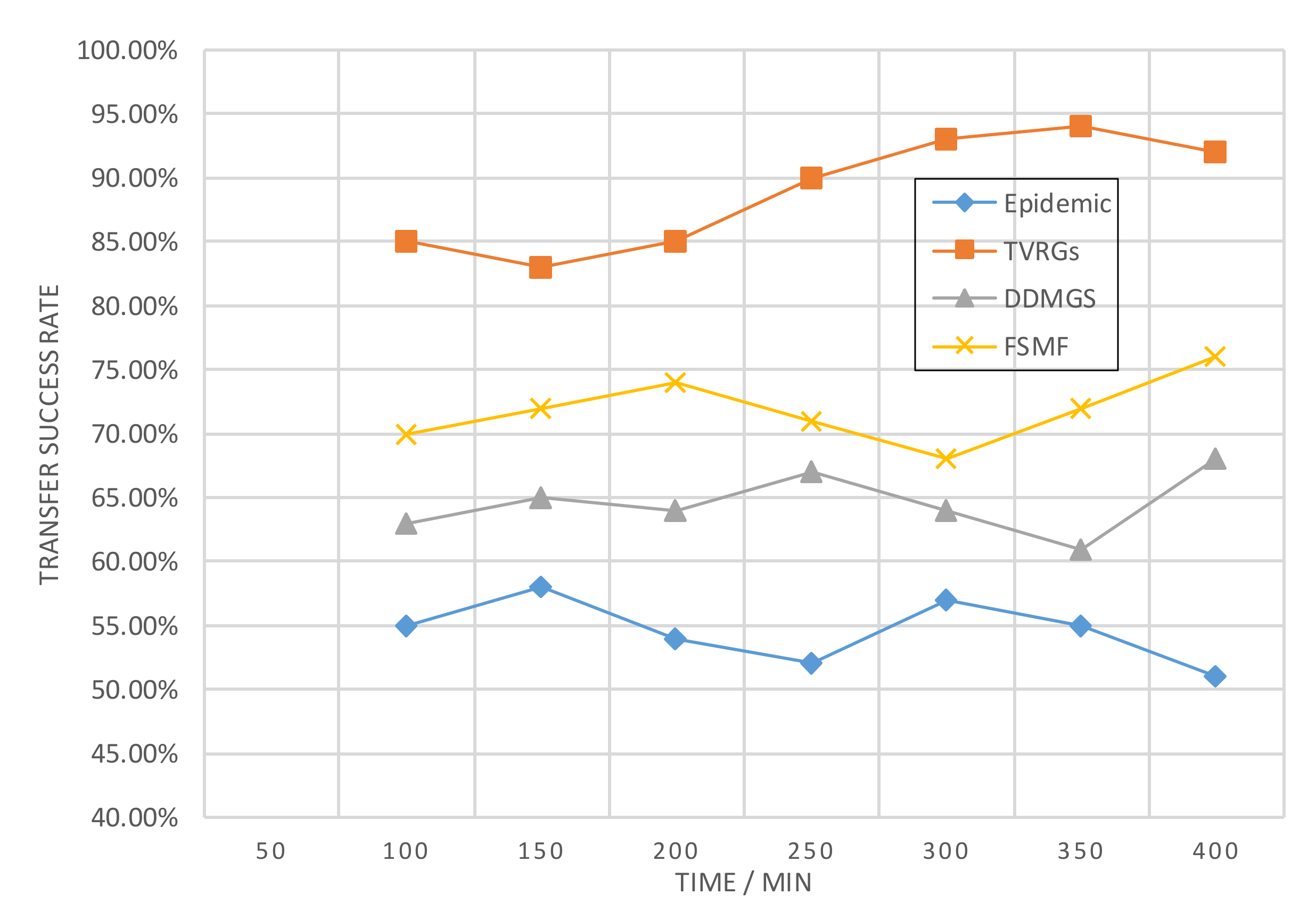
Figure 8 shows the relationship between message delivery success rate and delivery time. The success rate of FSMF is around 70%, and adjusting the delivery order according to the social attributes of users so that nodes with complex social relationships can send messages in a limited way can also improve the success rate to some extent. The lowest success rate of Epidemic messaging is less than 60%. Because the algorithm calculates the priority of nodes to determine the order of delivery copies, it can avoid network congestion to some extent. However, the comparison accuracy of node priority is low, which causes its transmission success rate to be lower. The message delivery success rate of DDMGS is around 65%. Its introduction of cooperative game theory avoids the selfish behavior of nodes, which increases the message delivery success rate. It is better than the Epidemic algorithm is better than the Epidemic algorithm. The overall success rate of the TVRGs algorithm designed in this paper is the best. The delivery success rate above 85% indicates that the algorithm designed in this paper is practical and reasonable.
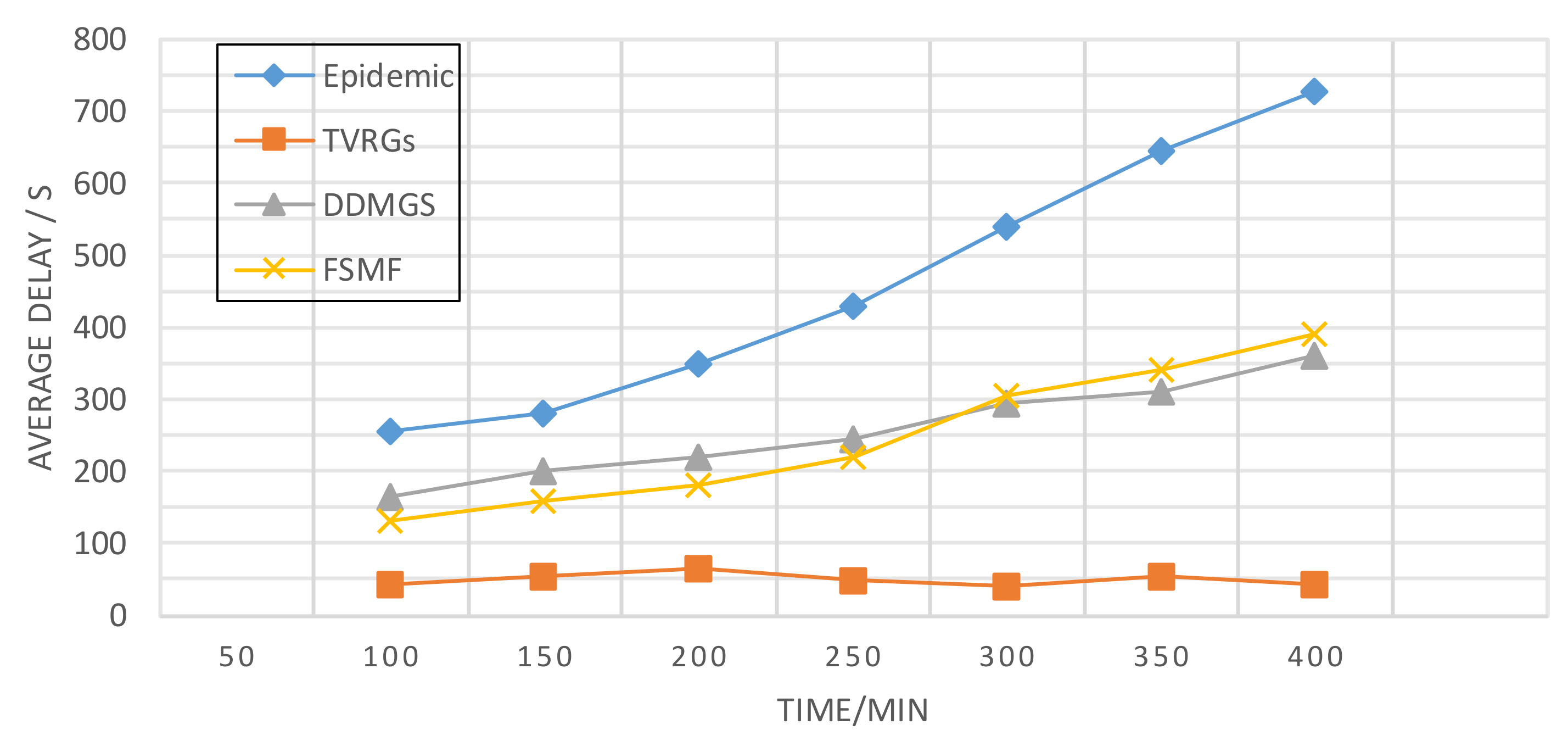
Figure 9 gives the average latency versus simulation time. The average latency is a critical metric used to measure the superiority of the algorithm, and according to the existing theory, the longer the average query latency, the more the number of messages stored in the nodes, which may lead to node overload and make the performance degraded. Among the four algorithms, the EPIDEMIC algorithm has the highest average delay. After 400 minutes, it even reaches more than 700. In the process of message forwarding, using the flooding network, packets are delivered, generating multiple query copies, and as time increases, more and more packets are transmitted. The resources are consumed heavily. The DDMGS algorithm needs to fully consider the social attributes such as the nodes’ movement trajectory and interest behavior. Too many factors need to be evaluated when selecting the next-hop node, resulting in its relatively sizeable average latency. The latency of the FSMF algorithm is similar to that of DDMGS. The average latency of the TVRGs algorithm is the lowest, around 50, because the nodes are selected by choosing the nodes with the most similar action trajectories to find the best message relay node, avoiding much redundancy.
In this article, query overhead mainly refers to the consumption of cache space from the beginning of a query to the successful delivery of messages. As shown in
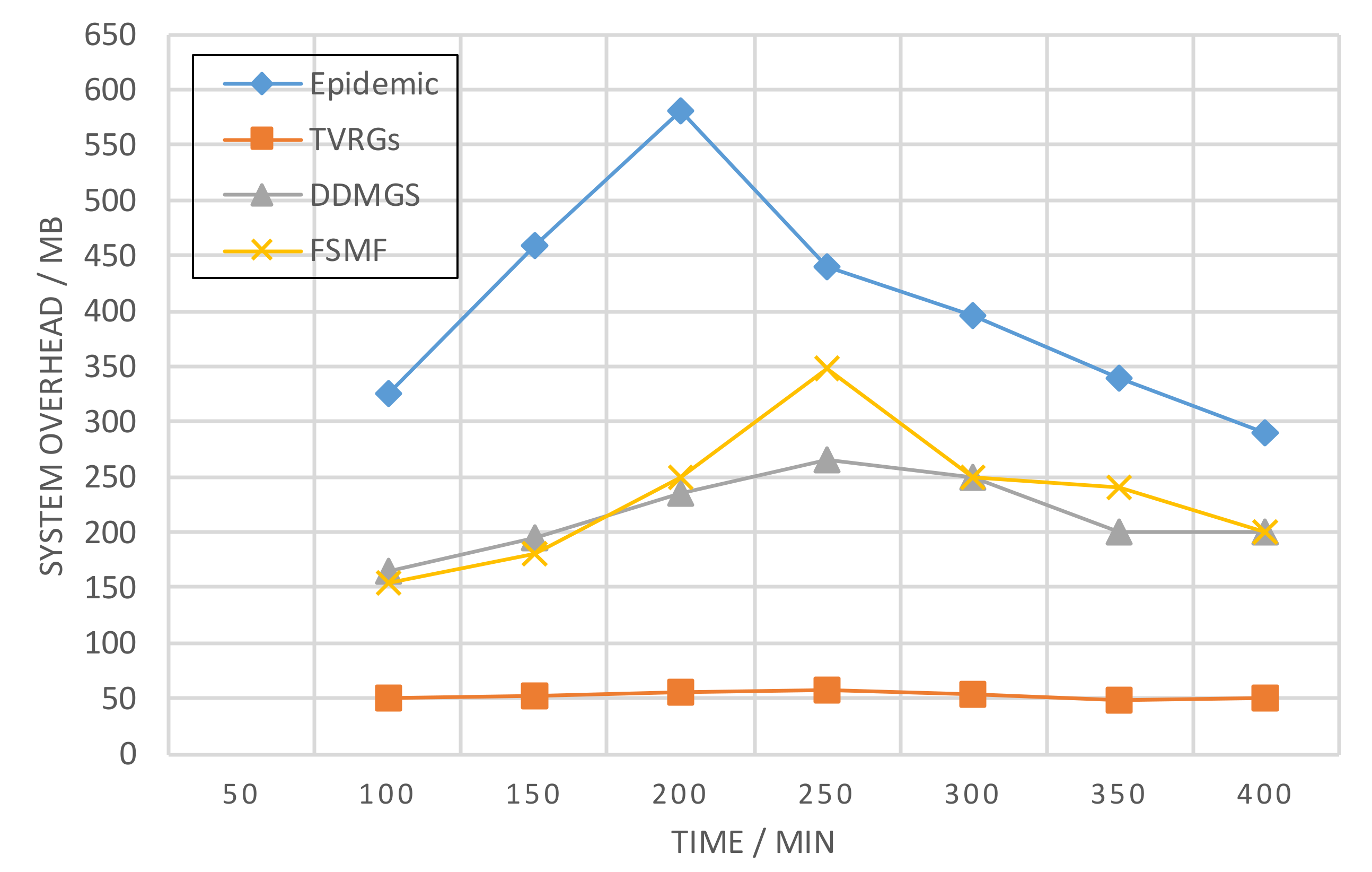
Figure 10 below, the EPIDEMIC algorithm uses about 20 replicas on average to complete a query. It issues the most significant number of replicas, so it takes up more memory space, with a peak of nearly 600 MB, and has the most enormous query overhead. Compared with the above three algorithms, the TVRGs algorithm always has the lowest query overhead, with a stable system overhead of 50 MB, indicating that its overhead is not affected by time. The TVRGS algorithm in which nodes issue copies is the most targeted and outperforms all the compared algorithms in overhead.
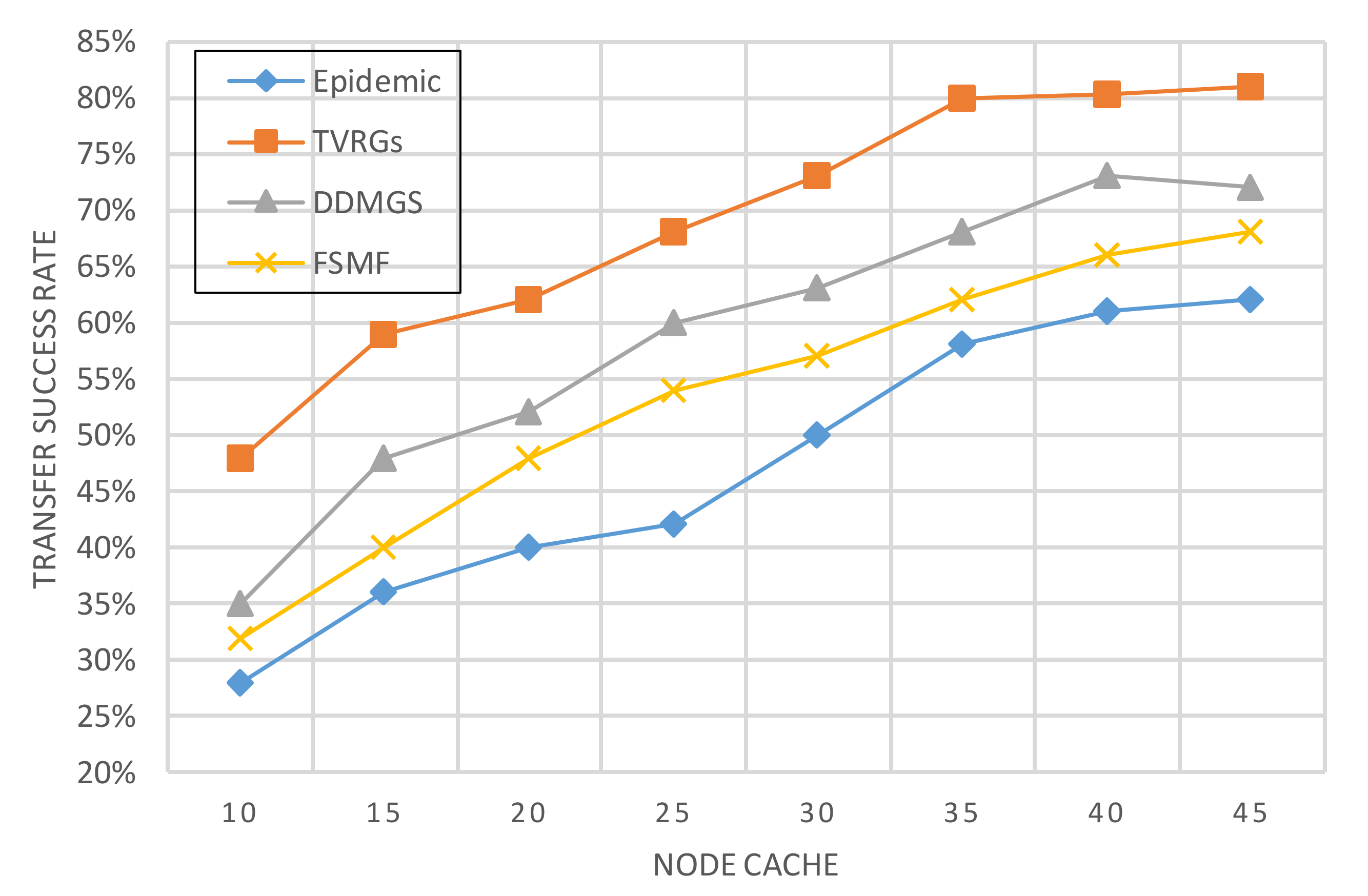
Figure 11 shows the relationship between node cache and message transmission success rate. When the node cache is small, we can get that it has a more significant impact on the message transmission success rate. As the node cache increases, the overall message transmission success rate will increase. The transmission success rate of the TVRGs algorithm is much higher than other algorithms in the same case. It tends to stabilize when the cache capacity reaches 35M. For the Epidemic algorithm, which is based on flooding delivery of messages, its cache size has a more significant impact on the message delivery success rate. When the amount of data is large, data congestion is minor, and the success rate increases faster.
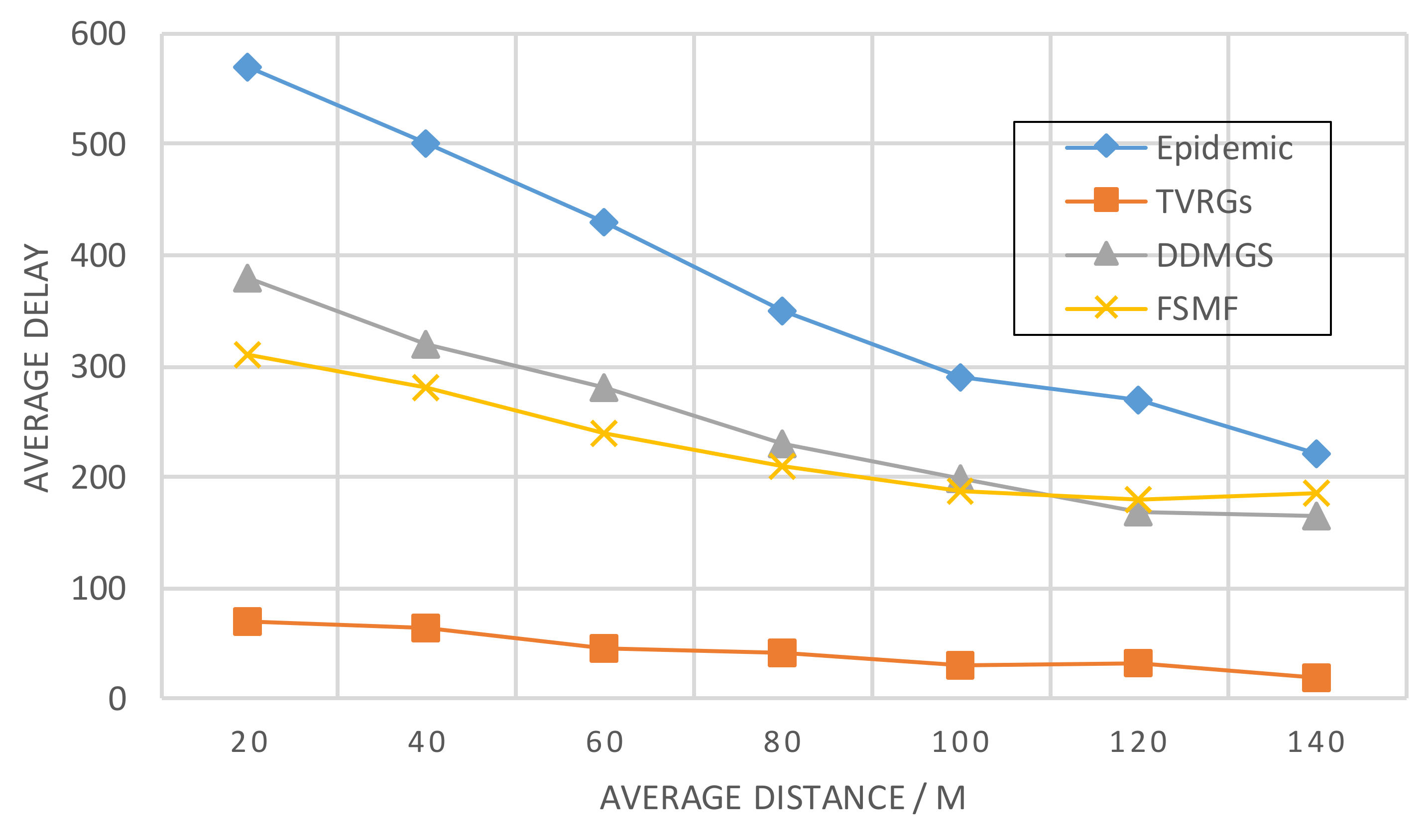
The relationship between the average maximum transmission distance between nodes and the average delay is given in
Figure 12. From the current findings, it is clear that nodes can increase the probability of encountering message relay nodes and target nodes by increasing the distance of sending data packets, thus reducing the data transmission time. That is, the average transmission distance increases, and the average delay decreases. From the figure, it can be obtained that the delay of the Epidemic algorithm is always maximum in the same case. The excessive number of packets sent causes a large amount of data redundancy to the network. The average delay of the TVRGs algorithm is less affected by the transmission range, mainly by filtering nodes with similar action trajectories, which is less correlated with the transmission distance.
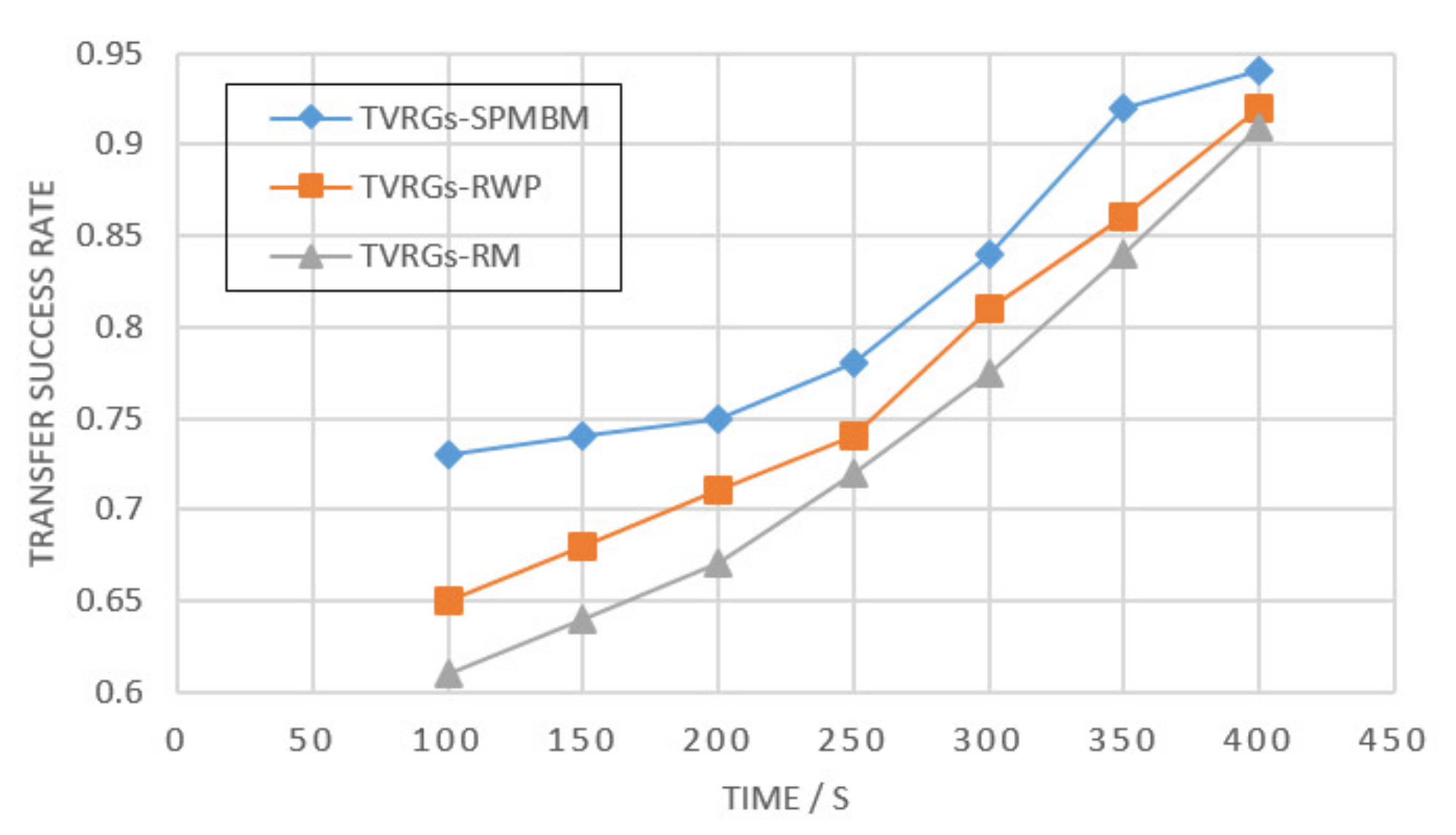
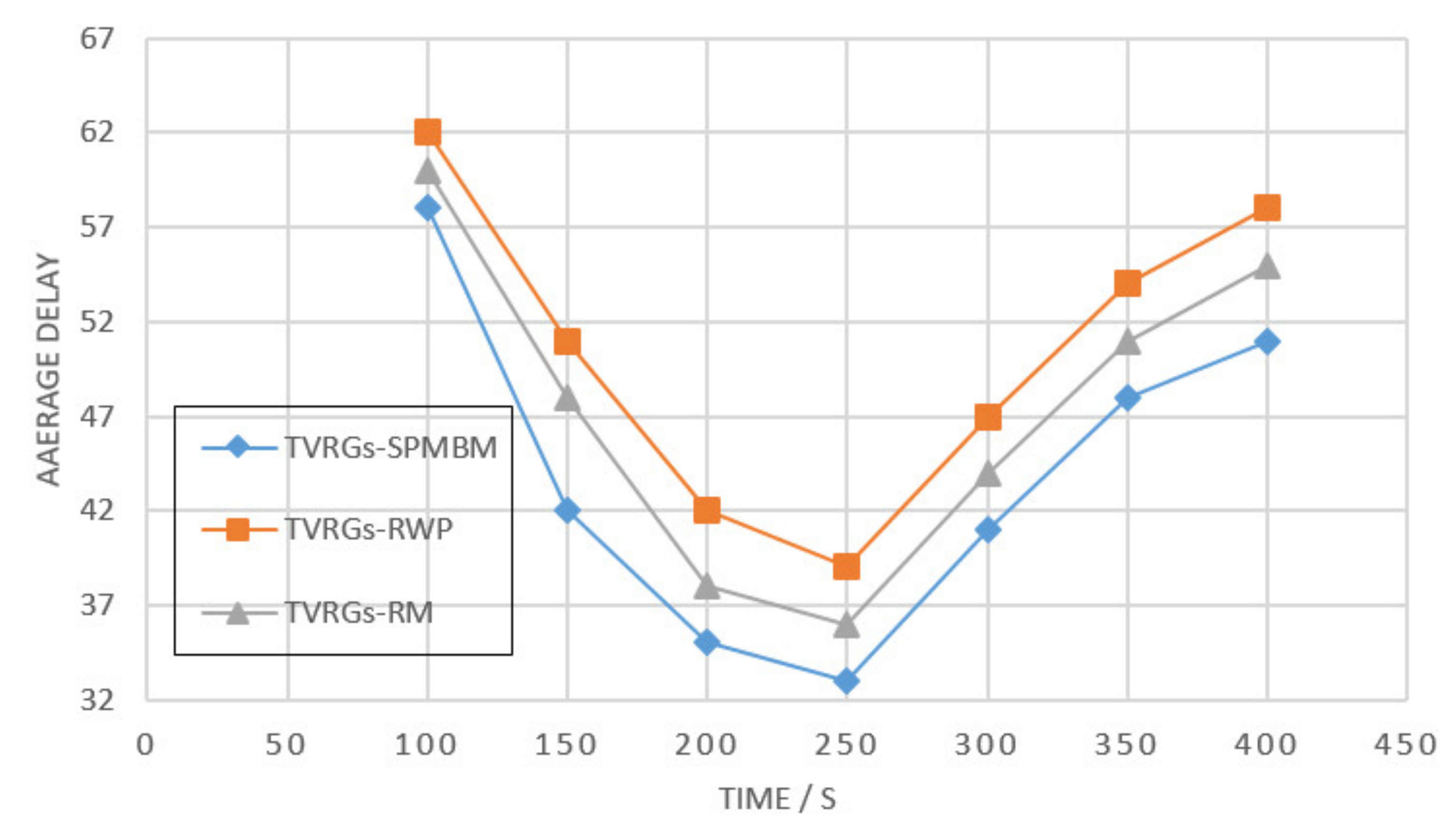
Figure 13 explains the performance comparison of the algorithms under three different mobility models in the map. The RM model has a sparse structure and relatively limited delivery performance, making it possible for the destination node to fail to receive the data; therefore, the message delivery success rate of RM is around 60%. In the RWP model, the higher density of nodes on the map makes the packet transmission more efficient, around 0.75. However, both RM and RWP models are straightforward models with no direction, and the weights of nodes depend more on the number of node movements and encounters, which can lead to delays in packet transmission. As shown in
Figure 14, the transmission delay of RWP and RM is higher than that of SPMBM. In this simulation experiment, the TVRGs algorithm uses the SPMBM model, which directly records the trajectory routes of nodes moving in reality.
In summary, the evaluation results show that the proposed TVRGs algorithm for constructing relational clusters is effective, and the relay nodes can deliver data faster between different clusters. After that, based on the Binary Search Tree algorithm, the appropriate response nodes are found within the clusters. Therefore, it can be concluded that the TVRGs algorithm has some application space in improving the efficiency of data delivery between clusters.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}