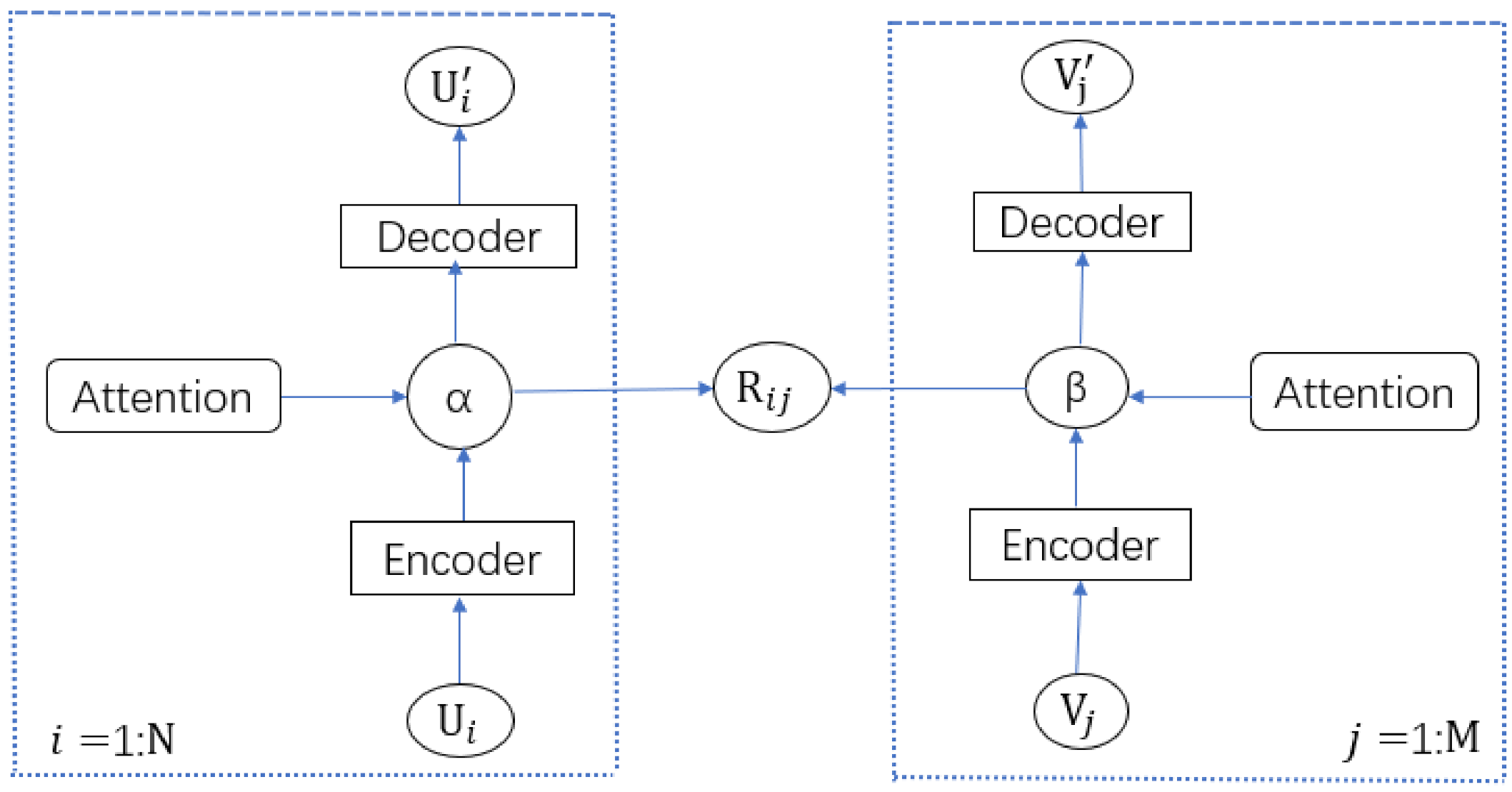
3.1. MAAMF Model Structure
Figure 1 shows the structure of the deep hybrid rating prediction model MAAMF fused with the dual-multi-head self-attention mechanism. In the figure, N is the number of users and M is the number of videos, R is the user video rating matrix, and
is the rating of the
i-th user on the
j-th video.
is the side information of the
i-th user, such as the user’s rating information and the user’s attribute information.
shows the side information of the
j-th item, such as the rating information of the video and the category information of the video. α is the compressed representation of
, and β is the compressed representation of
.
λu is the user regularization parameter,
λv is the project regularization parameter,
and
are the new approximate representations obtained by decompressing
and
through the autoencoder of the fusion multi-head attention mechanism, respectively. The purpose of MAAMF is to integrate MAA into the PMF framework and achieve rating predictions through PMF and two MAAs.
This study aims to identify the potential matrix of users and videos
)
to rebuild the rating matrix R, and the observed rating matrix is calculated as follows:
where
is the probability density function of the Gaussian normal distribution with mean
and variance
.
demonstrates the indicator function. If user
i evaluates the video
j, then it is set to 1, otherwise, it is set to 0.
3.2. MAAMF Model Principle
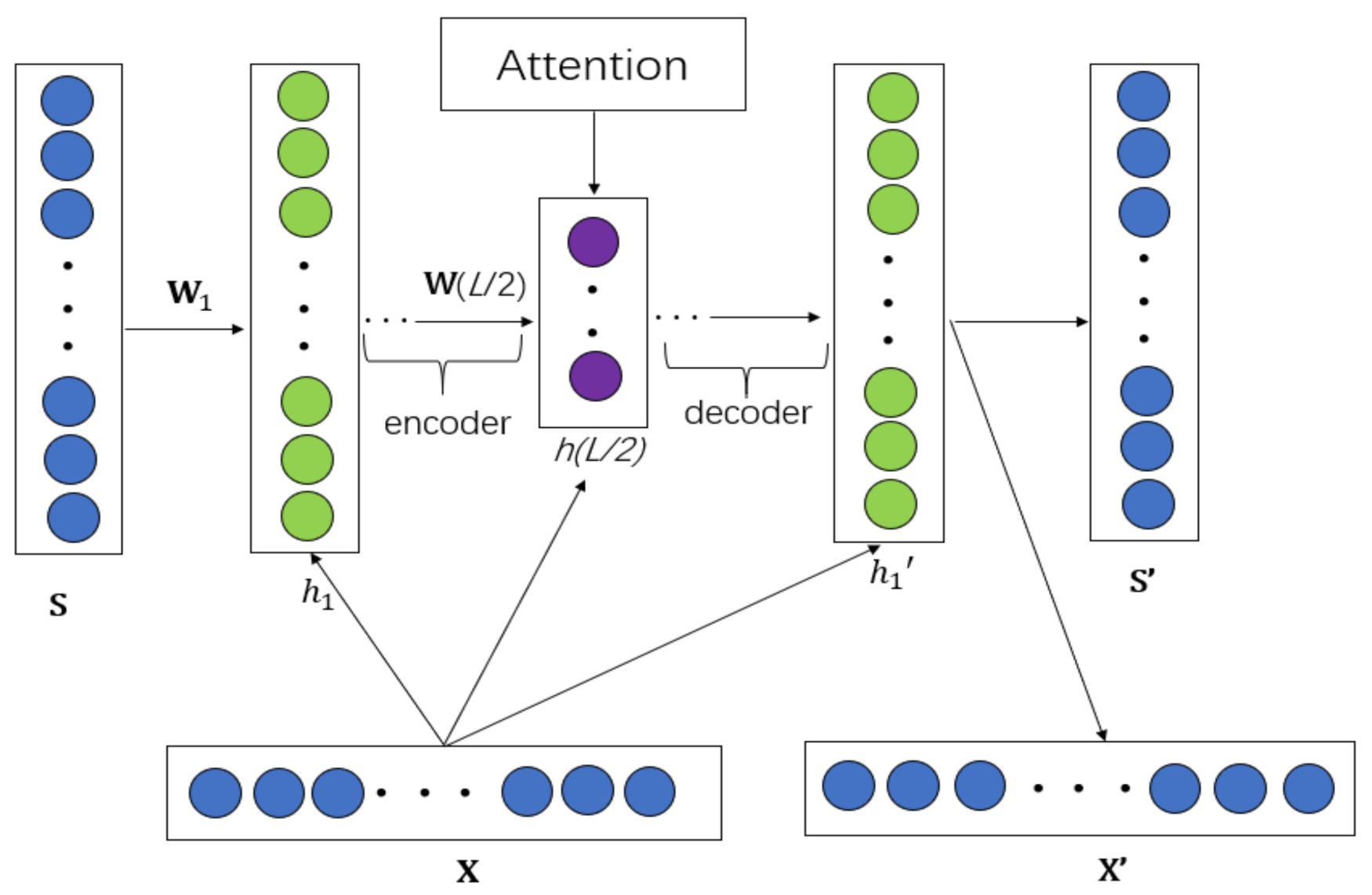
The core of our MAAMF model is the MAA module. The purpose is to use two MAA modules to obtain the potential factors of users and videos from user side information and video side information, respectively. The MAA module is shown in
Figure 2. In the figure, S represents side information, specifically user attribute information or video category information in this model. X represents user rating or item rating information. S’ represents decompressed auxiliary information, and X’ represents the scoring information after decompression. h represents the hidden layer, and
L represents the number of hidden layers.
h1 represents the first hidden layer,
h(
L/2) represents the
L/2-th hidden layer. W represents the weight parameter, and W
1 represents the first layer weight parameter, W(
L/2) represents the weight parameter of the
L/2-th layer.
The input layer uses the preprocessed tensor that is the side information as the input of the neural network. In this study, the user side information is the concatenation of the user rating matrix and the user characteristic information, and the video side information is the concatenation of the video rating matrix and the video classification information.
The coding layer contains four layers, which are compressed layer by layer from 400 to 200 to 100 to 50. After each layer passes through the fully connected layer, batch normalization is performed, and then activated by the relu activation function, and finally, dropout is performed to prevent overfitting.
The multi-head attention layer selects vital features. The multi-head attention mechanism [
55] first conducts linear transformation, and then the outcome is input to the scaled dot-Product attention, which is done h times in total. One head for each time, so it becomes multi-head.
means the
time,
means to query,
means key,
means the values.
,
, and
respectively represent the parameter matrix of
,
, and
in the mith transformation,
is the weight initialization parameter, as shown in Equations (2) and (3). The parameters are not shared among the heads, and then the h times of scaled dot-Product attention results are concatenated, and the value is calculated by performing linear transformation, which is used as the result of multi-head attention:
The multi-head attention mechanism is developed on the basis of self-attention. The calculation of self-attention involves the connection between one input and all other inputs, and the calculation process mainly involves matrix multiplication. The self-attention mechanism is to perform three linear transformations on the result matrix of the embedding layer to obtain three new matrices named query matrix , key matrix , and value matrix . The query matrix is used as the score corresponding to each key matrix . The score and the key matrix are multiplied to calculate the corresponding weight, which is then multiplied by the value matrix . After performing a weighted average on the value matrix, we can finally obtain the scaled dot-Product attention. In practice, multiple parallel self-attention mechanisms are often used to form a multi-headed attention mechanism, that is, multiple attention matrices and multiple weights are used to weight the input values, and finally the weighted average results are concatenated. The self-attention mechanism can only capture the correlation between adjacent information. If multiple self-attention mechanisms are used, it can capture the correlation between relatively distant information. The final concatenation combines multiple attention mechanisms that can better describe the relationship between information at different distances.
The decoding layer corresponds to the coding layer, decompressing layer by layer from 50 to 100 to 200 to 400. Likewise, after each layer passes through the fully connected layer, batch normalization is performed, and then activated by the relu activation function, and finally, dropout is performed to prevent overfitting.
The probability density function of the zero-mean spherical Gaussian distribution above the user potential model with a difference of
is shown in Equation (4):
Different from the traditional PMF model, we assume that the user latent vector is affected by the MAA internal weight
,
represents the ancillary information of the
i-th user, and
is the influence of Gaussian noise, and we obtain Equation (5) as follows:
Using them to optimize the rating of the user’s potential model, hence we obtain Equation (6):
where
is its variance, and
k represents the dimension of the latent factor. The user potential model based on conditional distribution is written as,
where
A represents the side information of the user, the latent vector
obtained by the MAA module is used as the mean of the Gaussian distribution, the variance
is the variance of the Gaussian distribution, I is the identity matrix, and
n is the user number.
Similarly, we can obtain the probability density function of the internal weight
W of the item as shown in Equation (8). In addition, the probability density function of the item based on conditional distribution is shown in Equation (9), where
is its variance, and
k represents the dimension of the potential factor,
C represents the ancillary information of the video, the latent vector
obtained by the MAA module is used as the mean of the Gaussian distribution, the variance
is the variance of the Gaussian distribution, I is the identity matrix, and
m is the item number:
3.3. Model Optimization
The variables
,
,
, and
are optimized by using maximum a posterior estimation. In Equation (10)
A represents user side information,
C represents project side information, and
R represents predicted rating.
U represents the user potential factor,
V represents the project potential factor, and
i and
j represent the variables of the user and the project.
n is the number of users,
m is the number of videos, W is the internal weight of each model, and
is the variance of the corresponding Gaussian distribution:
Taking the logarithm of both sides of Equation (10) we obtain Equation (11)
Substituting Equations (1), (6), (7) (8), (9) into Equation (11), and then making both sides negative we obtain Equation (12):
We utilized the coordinate descent method to minimize
, and iteratively optimize the latent variables while fixing remaining parameters. Equation (12) is the quadratic function of U. Assuming that V and W are constants, the loss function
can be obtained by
differentiation. Take the same operation on V to obtain the following expressions:
where
,
,
, and
are diagonal matrices, and
and
are balance parameters. Equation (13) shows the effect of updating
by the user potential vector
through
, and Equation (14) shows the effect of updating
by the project potential vector
through
. However, we cannot update
and
similar to U and V, because
and
are linked to the nonlinearity in the MAA architecture. When U and V are temporarily constant, the loss function
can be referred to as the regular term weighted square error function of
. We obtain
and
as given in Equations (15) and (16).
By optimizing U, V,
, and
W, we can finally obtain the predicted user’s rating Equation (17):
where
is the expected value of rating.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}