

FAC-V: An FPGA-Based AES Coprocessor for RISC-V

Abstract
:1. Introduction
- An AES coprocessor for low-end reconfigurable IoT devices that can be deployed following two different coupling approaches;
- A user-friendly Application Programming Interface (API) that provides a complete abstraction from the accelerator and can be easily integrated with different IoT OSes or baremetal applications;
- A complete evaluation and benchmarking of the FAC-V accelerator in terms of FPGA resources, latency, performance, and power consumption;
- The integration and performance evaluation of FAC-V with RIOT, which is a well-known OS tailored for low-end IoT devices.
2. Background and Related Work
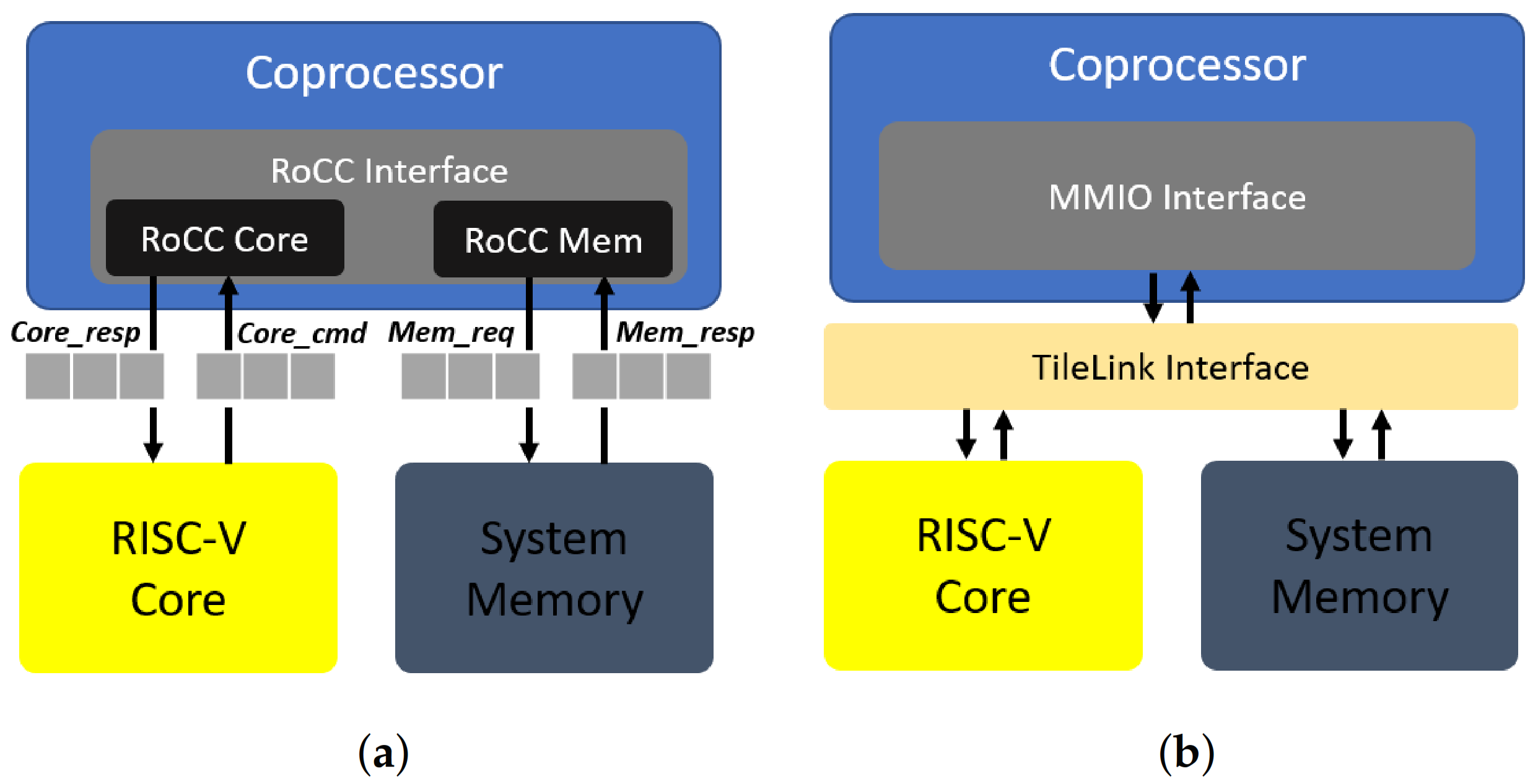
2.1. Loosely and Tightly-Coupling Approaches in RISC-V
2.2. AES Accelerators
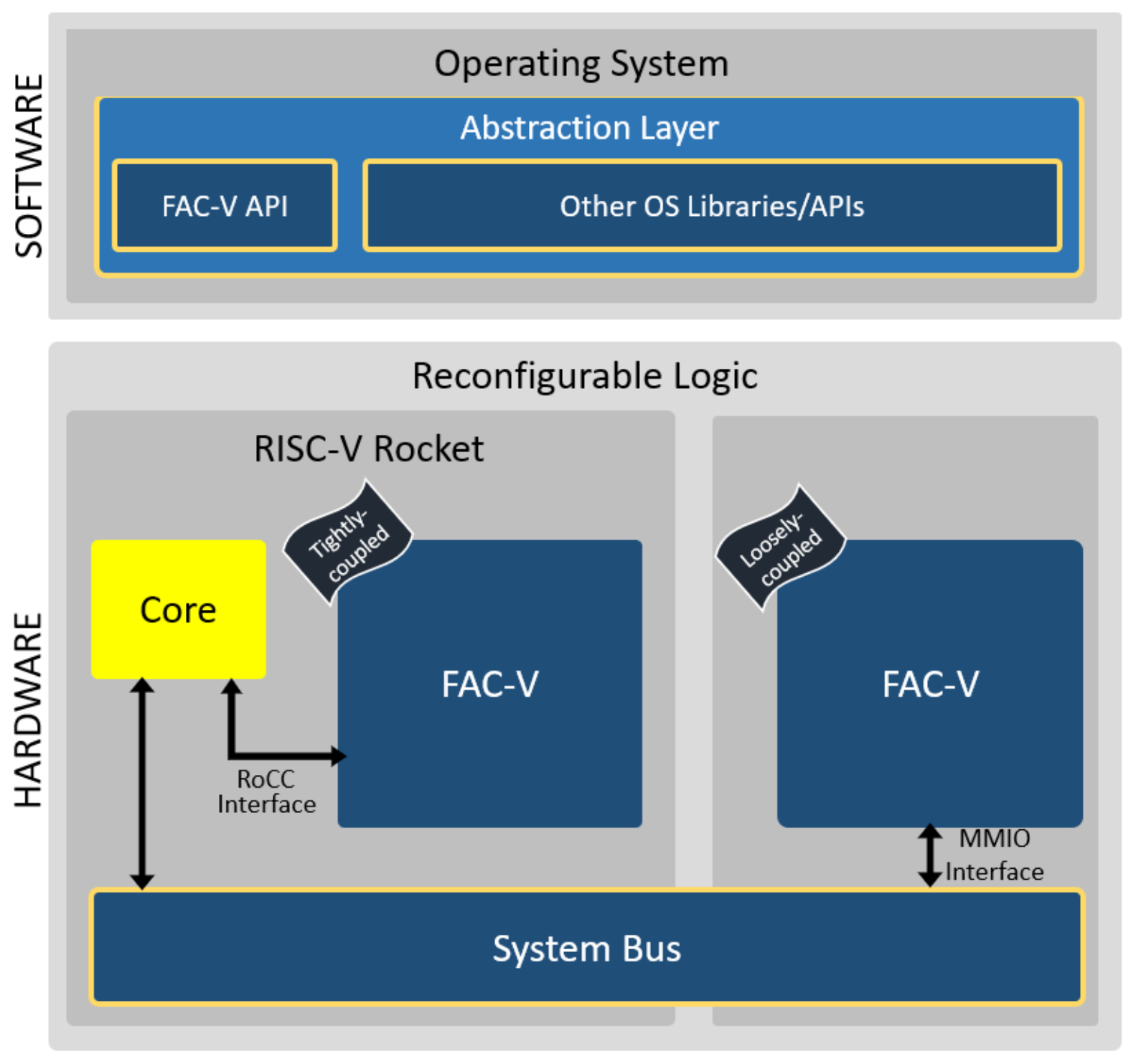
3. FAC-V Design and Implementation
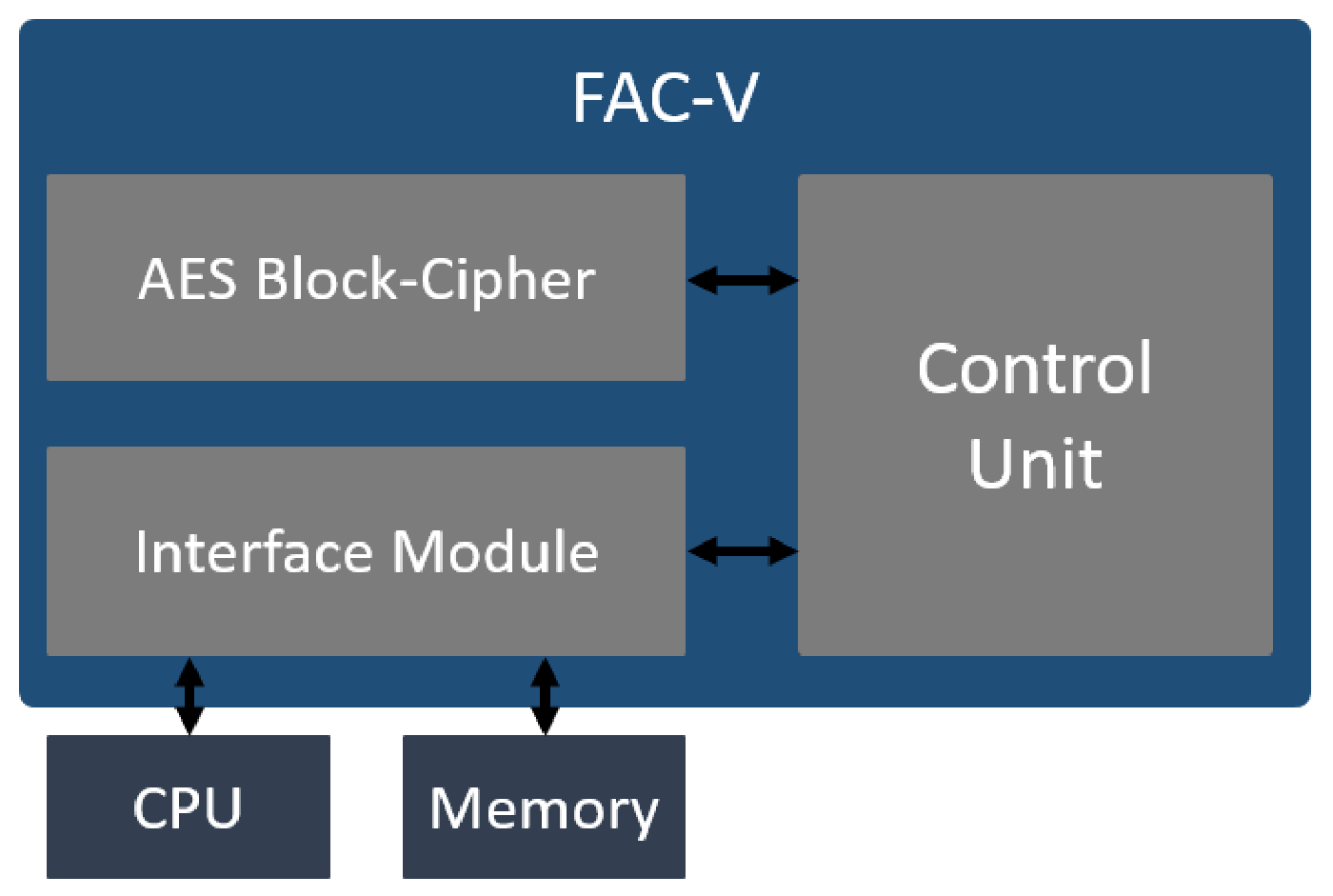
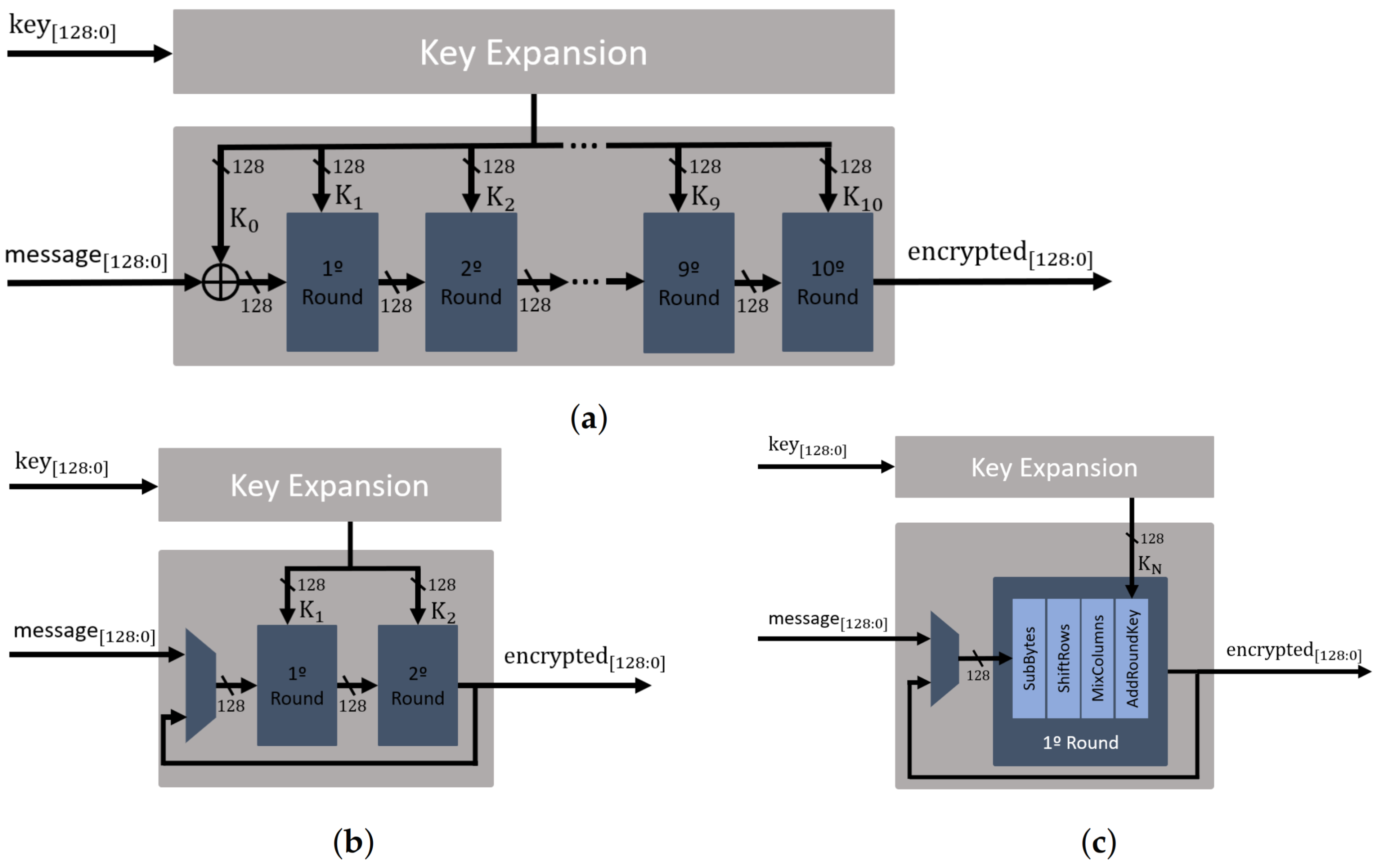
3.1. FAC-V Coprocessor Architecture
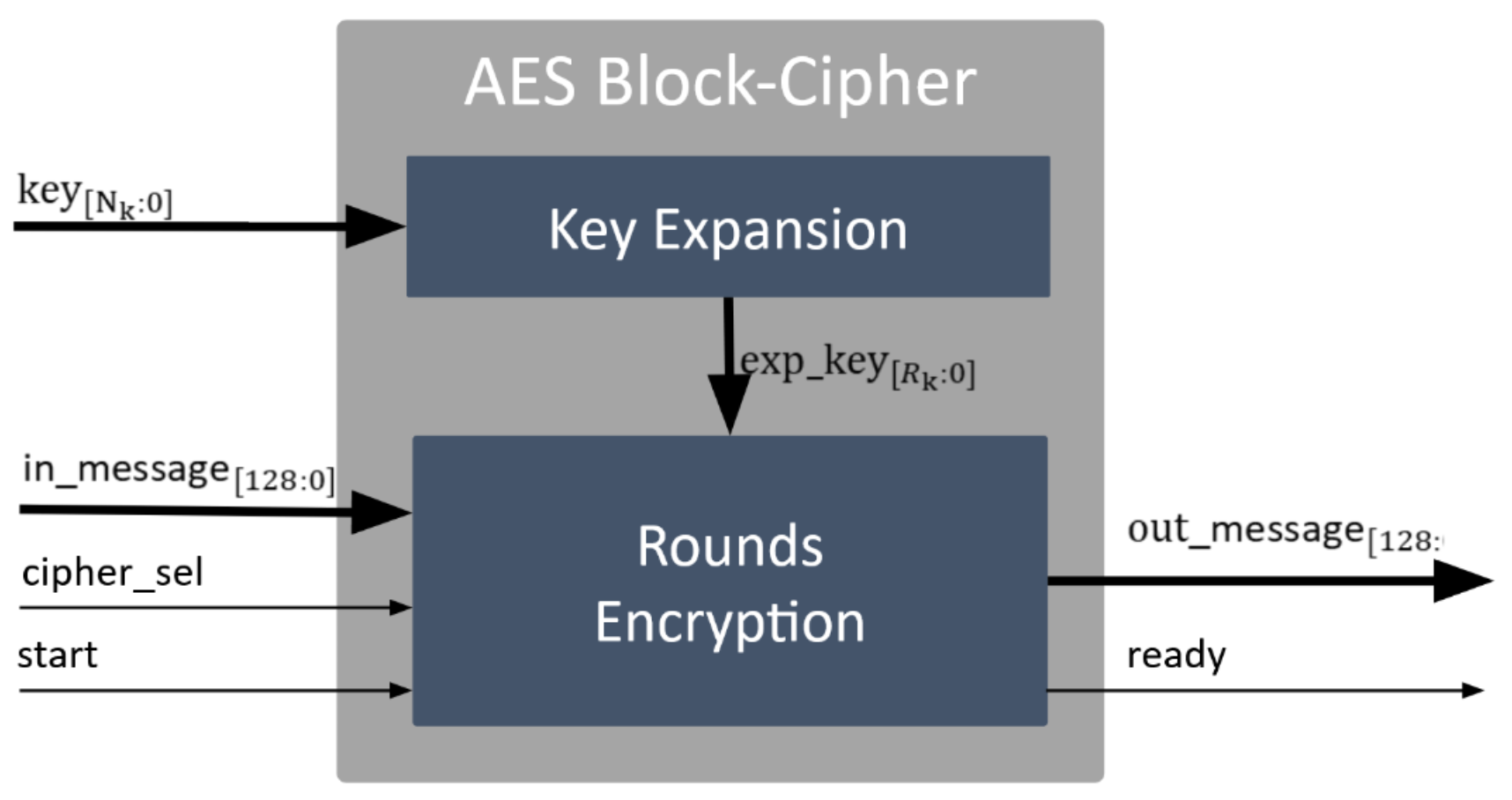
AES Block Cipher
3.2. Tightly Coupled FAC-V
| Listing 1. API RoCC instruction format. |
 |
3.3. Loosely Coupled FAC-V
4. FAC-V Evaluation
4.1. Hardware Resources
4.2. API Latency
4.2.1. AES Initialization
4.2.2. AES Encryption
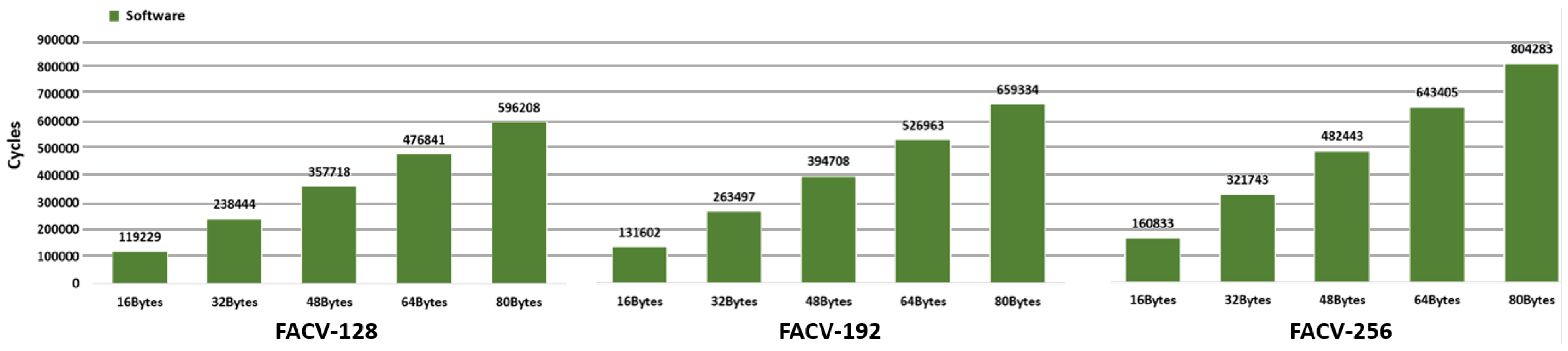
- Software Version:Table 7 shows the results of the AES encryption task for the different secret key sizes and message payloads of 16, 32, 48, 64, and 80 bytes (one to five 128-bit message blocks). These results are supported by Figure 7, which displays the latency results for the software version, and Figure 8, which corresponds to the hardware implementations. Regarding the software-only implementation, the FACV-128 required around 119,229 clock cycles (SD of 620 clock cycles) to handle a 16-byte message and 596,208 clock cycles (SD of 1355) for a message size of 80 bytes. These values increase when the key size also increases, e.g., for the FACV-192, the number of clock cycles required to encrypt a 16 and 80 bytes message is, respectively, 131,602 (SD of 701) and 659,334 (SD of 1090), while for the FACV-256, the number of clock cycles is 160,833 (SD of 659) for a message size of 16 bytes and 804,283 (SD of 1420) for an 80-byte message.
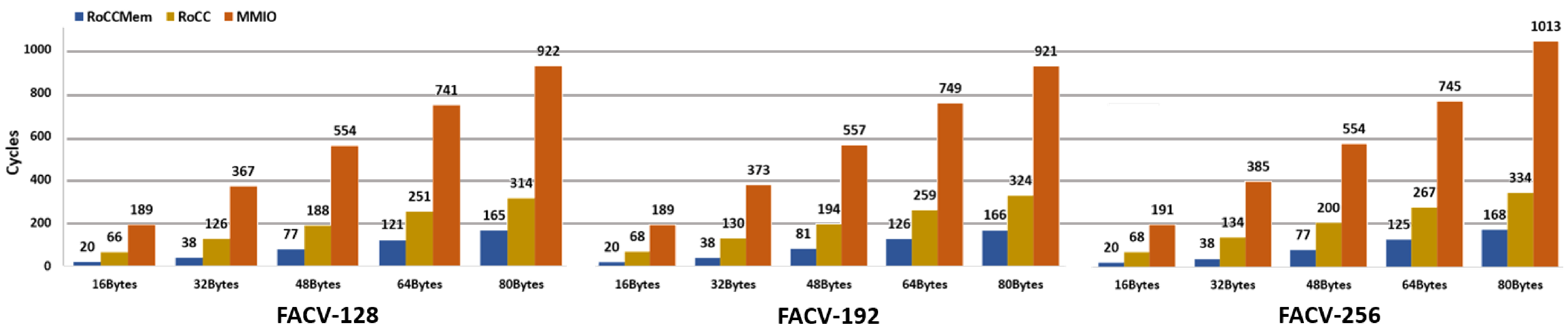
- RoCC Mem: When performing the encryption task with the FAC-V coprocessor, the number of clock cycles required to encrypt different message sizes (for the three values of the secret key) greatly decreases. These values are present in Table 7 and supported by Figure 8. Regarding the RoCC Mem implementation, the FACV-128 requires 20 clock cycles to execute the encryption of a message size of 16 bytes and 165 clock cycles when the message size is 80 bytes. When compared with the software-only version, it corresponds to a performance increase of 5961× and 3613×, respectively. In the FACV-192 and FACV-256, these remain the same when the message size is 16 bytes, i.e., 20 clock cycles, but they slightly increase to 166 and 168 clock cycles when the message size increases to 80 bytes. Despite presenting similar values when varying the message size, the performance gains in comparison to the software implementation are considerably higher, i.e., 6580× and 3972× for the FACV-192 and 8042× and 4787× for the FACV-256.
- RoCC: The number of clock cycles required by the FACV-128 to encrypt a 16-byte and an 80-byte message is, respectively, 66 and 314, which corresponds to a performance increase of 1807× and 1899×. The FACV-192 requires 68 and 324 clock cycles to encrypt a message of 16 and 80 bytes, respectively, which corresponds to a performance increase of 6580× and 3972×. Regarding the FACV-256, these values are nearly the same as the FACV-192, corresponding to a performance gain of 1935× and 2035× for a message size of 16 and 80 bytes in the FACV-192 configuration and a performance increase of 2401× and 2408× for a respective message size of 16 and 80 bytes in the FACV-256 implementation. Overall, the performance gains for both the FACV-192 and the FACV-256 for the different message sizes increase when compared with the corresponding software version.
- MMIO: Regarding the MMIO configuration, the FAC-128 requires 189 clock cycles to encrypt a 16-byte message and 922 clock cycles to encrypt a message with a payload of 80 bytes, corresponding to a performance gain of 631× and 647×, respectively. When using a key size of 192 bits, FACV-192, encrypting a message of 16 and 80 bytes requires 189 and 921 clock cycles, respectively, representing a performance gain of 696× and 716×. For the FACV-256, the number of clock cycles to encrypt a message of 16 and 80 bytes is, respectively, 385 and 1013, representing a performance increase of 842× and 794×. Again, comparative to the respective software version, the performance gains increase when the key size also increases.
- Discussion: Regarding the software implementation, the latency increase results are directly related to the message and key sizes, which require more clock cycles to execute when a higher number of encryption rounds need to be performed. The different hardware approaches, from a macro perspective, provide nearly the same performance results for the different message sizes in the different sizes of the encryption key. However, the performance gains provided by MMIO and RoCC configurations follow a different behavior than the RoCC Mem implementation. While for the MMIO and RoCC, the performance gains keep increasing when the message size also increases, this is not always true for the RoCC Mem configuration. The main reason for this behavior is related to the required memory accesses used by this configuration, which is affected when the message size increases from 32 to 48 bytes. This may be caused by two different situations: (i) since the implemented RoCC memory sub-interface needs to wait for the “ready to use” memory validation signal, some unexpected delays can occur, which are mainly caused by concurrent system bus masters, which can increase the overall latency of the encryption task; and (ii) since there are more data blocks to process, the additional function calls may also cause extra bus contention during the prologue and epilogue execution. Considering the standard deviation in the hardware configurations, this value is zero or nearly zero, showing that the encryption task in the different versions of the FAC-V is fully deterministic. In the software setup, the standard deviation values are mainly related to the extensive multiple mathematical and arithmetic operations that need to be performed, resulting in more memory accesses and processing time, which is susceptible to change due to other software tasks being executed by the CPU in the OS thread scheduling, interrupts, etc. Lastly, it is possible to conclude that the tightly coupled versions of the FAC-V, i.e., RoCC and RoCC Mem, perform better than the loosely coupled approach deployed through the MMIO configuration.
4.3. OS Performance
- Basic Processing: A single thread performs mathematical operations in a loop.
- Cooperative Scheduling: Five threads with the same priority execute concurrently, yielding in a loop.
- Preemptive Scheduling: Five threads with increasing priorities, each resuming the next thread with a higher priority and suspending themselves in a loop.
- Interrupt Processing: A single thread is interrupted each time it executes, being resumed afterwards.
- Interrupt Preemption Processing: Two threads with different priorities, where one of them triggers an interrupt responsible for resuming the other suspended thread.
- Message Processing: A thread sends a message to itself through a queue in a loop.
- Synchronization Processing: A single thread gives and takes a semaphore in a loop.
- Memory Allocation: A thread allocates and de-allocates memory blocks in a loop.
- Basic Processing: In this test, the OS performance decreased by 36.7% when using the software libraries of the AES algorithm. However, when resorting to the FAC-V coprocessor, this value can be reduced to 3.7% when using the RoCC Mem configuration.
- Cooperative and Preemptive Scheduling: Regarding the Cooperative Scheduling and the Preemptive Scheduling tests, the Cooperative achieved lower performance degradation than the Preemptive, which is mainly explained by the microkernel architecture used by RIOT. While in the Cooperative Scheduling test, the executing task yields itself, in the Preemptive Scheduling test, the executing task resumes to a different one, which involves more system calls and more processing from the scheduler due to the tasks having different priorities. When using the pure software version of the AES algorithm, the performance decrease is around 39.9% for the Cooperative Scheduling and 46.9% for the Preemptive Scheduling. However, resorting to the FAC-V coprocessor, the performance decrease can be reduced to 0.4% for the Cooperative test using the MMIO interface and 4.5% for the Preemptive test in the RoCC Mem configuration.
- Interrupt Processing and Preemptive: When resorting to the AES in software, the Interrupt Processing test shows a performance decrease of 53.6%, while the Interrupt Preemptive achieved a performance decrease of 40.5%. This is mainly explained by the fact that the Interrupt Processing test, since it involves more hardware interrupts, requires more system calls and more processing time from the scheduler. When resorting to the FAC-V, the performance decrease of the Interrupt Processing is around 4.5% in the MMIO configuration and 6.6% in the Interrupt Preemptive when the RoCC Mem configuration is used.
- Message Processing, Synchronization Processing, and Memory Allocation: For these tests, the results show the lowest performance decrease. The Message Processing has a 26.1% performance decrease, while the Synchronization Processing and the Memory Allocation show performance decreases of 28.5% and 25.5%, respectively. This shows that the memory management system implemented in RIOT has less impact on the overall system’s performance in contrast to the tests that require preemption and interrupts. For the hardware configurations, the lowest performance decreases were 5.4%for Message Processing, 8.8% for Synchronization Processing, and 3.5% for Memory Allocation.
4.4. FAC-V Power Estimation
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Oliveira, D.; Costa, M.; Pinto, S.; Gomes, T. The Future of Low-End Motes in the Internet of Things: A Prospective Paper. Electronics 2020, 9, 111. [Google Scholar] [CrossRef]
- Sundmaeker, H.; Guillemin, P.; Friess, P.; Woelfflé, S. Vision and Challenges for Realizing the Internet of Things. Clust. Eur. Res. Proj. Internet Things EU Commision 2010, 3, 34–36. [Google Scholar] [CrossRef]
- Perera, C.; Liu, C.H.; Chen, M. A Survey on Internet of Things From Industrial Market Perspective. IEEE Access 2014, 2, 1660–1679. [Google Scholar] [CrossRef]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A Survey on the Edge Computing for the Internet of Things. IEEE Access 2018, 6, 6900–6919. [Google Scholar] [CrossRef]
- Elnawawy, M.; Farhan, A.; Nabulsi, A.; Al-Ali, A.; Sagahyroon, A. Role of FPGA in Internet of Things Applications. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Ajman, United Arab Emirates, 10–12 December 2019. [Google Scholar] [CrossRef]
- Valdés, M.; Rodriguez-Andina, J.; Manic, M. The Internet of Things: The Role of Reconfigurable Platforms. IEEE Ind. Electron. Mag. 2017, 11, 6–19. [Google Scholar] [CrossRef]
- Waterman, A.S. Design of the RISC-V Instruction Set Architecture; University of California: Berkeley, CA, USA, 2016. [Google Scholar]
- Waterman, A.; Lee, Y.; Patterson, D.A.; Asanovi, K. The RISC-V Instruction Set Manual. Volume 1: User-Level ISA, version 2.0; Technical Report; California Univ Berkeley Dept of Electrical Engineering and Computer Sciences: Berkeley, CA, USA, 2014. [Google Scholar]
- Asanović, K.; Patterson, D.A. Instruction Sets Should Be Free: The Case for RISC-V; Tech. Rep. UCB/EECS-2014-146; EECS Department, University of California: Berkeley, CA, USA, 2014. [Google Scholar]
- Azad, Z.; Yang, G.; Agrawal, R.; Petrisko, D.; Taylor, M.; Joshi, A. RACE: RISC-V SoC for En/Decryption Acceleration on the Edge for Homomorphic Computation. In Proceedings of the ACM/IEEE International Symposium on Low Power Electronics and Design, Boston, MA, USA, 1–3 August 2022; Association for Computing Machinery: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Costa, M.; Costa, D.; Gomes, T.; Pinto, S. Shifting Capsule Networks from the Cloud to the Deep Edge. arXiv 2022, arXiv:2110.02911. [Google Scholar] [CrossRef]
- Wu, N.; Jiang, T.; Zhang, L.; Zhou, F.; Ge, F. A Reconfigurable Convolutional Neural Network-Accelerated Coprocessor Based on RISC-V Instruction Set. Electronics 2020, 9, 1005. [Google Scholar] [CrossRef]
- De, A.; Basu, A.; Ghosh, S.; Jaeger, T. Hardware Assisted Buffer Protection Mechanisms for Embedded RISC-V. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 4453–4465. [Google Scholar] [CrossRef]
- Silva, M.; Gomes, T.; Pinto, S. Agnostic Hardware-Accelerated Operating System for Low-End IoT. In Proceedings of the 2022 IEEE 28th International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA), Taipei, Taiwan, 23–25 August 2022; pp. 21–30. [Google Scholar] [CrossRef]
- Asanović, K.; Avizienis, R.; Bachrach, J.; Beamer, S.; Biancolin, D.; Celio, C.; Cook, H.; Dabbelt, P.; Hauser, J.; Izraelevitz, A.M.; et al. The Rocket Chip Generator; EECS Department, University of California: Berkeley, CA, USA, 2016; UCB/EECS-2016-17; Available online: http://www2.eecs.berkeley.edu/Pubs/TechRpts/2016/EECS-2016-17.html (accessed on 4 September 2022).
- Oikonomou, G.; Duquennoy, S.; Elsts, A.; Eriksson, J.; Tanaka, Y.; Tsiftes, N. The Contiki-NG open source operating system for next generation IoT devices. SoftwareX 2022, 18, 101089. [Google Scholar] [CrossRef]
- Baccelli, E.; Hahm, O.; Günes, M.; Wählisch, M.; Schmidt, T.C. RIOT OS: Towards an OS for the Internet of Things. In Proceedings of the 2013 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Turin, Italy, 14–19 April 2013; pp. 79–80. [Google Scholar] [CrossRef]
- Hahm, O.; Baccelli, E.; Petersen, H.; Tsiftes, N. Operating Systems for Low-End Devices in the Internet of Things: A Survey. IEEE Internet Things J. 2016, 3, 720–734. [Google Scholar] [CrossRef]
- Silva, M.; Cerdeira, D.; Pinto, S.; Gomes, T. Operating Systems for Internet of Things Low-End Devices: Analysis and Benchmarking. IEEE Internet Things J. 2019, 6, 10375–10383. [Google Scholar] [CrossRef]
- Fritzmann, T.; Sigl, G.; Sepúlveda, J. RISQ-V: Tightly Coupled RISC-V Accelerators for Post-Quantum Cryptography. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2020, 239–280. [Google Scholar] [CrossRef]
- Surendran, S.; Nassef, A.; Beheshti, B.D. A survey of cryptographic algorithms for IoT devices. In Proceedings of the 2018 IEEE Long Island Systems, Applications and Technology Conference (LISAT), Farmingdale, NY, USA, 4 May 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Henriques, M.S.; Vernekar, N.K. Using symmetric and asymmetric cryptography to secure communication between devices in IoT. In Proceedings of the 2017 International Conference on IoT and Application (ICIOT), Nagapattinam, India, 19–20 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Goyal, T.K.; Sahula, V. Lightweight security algorithm for low power IoT devices. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 1725–1729. [Google Scholar] [CrossRef]
- Bachrach, J.; Vo, H.; Richards, B.; Lee, Y.; Waterman, A.; Avižienis, R.; Wawrzynek, J.; Asanović, K. Chisel: Constructing hardware in a Scala embedded language. In Proceedings of the DAC Design Automation Conference 2012, San Francisco, CA, USA, 3–7 June 2012; pp. 1212–1221. [Google Scholar] [CrossRef]
- Cook, H.; Terpstra, W.; Lee, Y. Diplomatic design patterns: A TileLink case study. In Proceedings of the 1st Workshop on Computer Architecture Research with RISC-V, Boston, MA, USA, 14 October 2017. [Google Scholar]
- Canright, D.; Osvik, D.A. A More Compact AES. In Proceedings of the Selected Areas in Cryptography; Jacobson, M.J., Rijmen, V., Safavi-Naini, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 157–169. [Google Scholar]
- Singh, A.; Prasad, A.; Talwar, Y. Compact and Secure S-Box Implementations of AES—A Review; Springer: Berlin/Heidelberg, Germany, 2020; pp. 857–871. [Google Scholar] [CrossRef]
- Dhede, O.S.; Shah, S.K. A review: Hardware Implementation of AES using minimal resources on FPGA. In Proceedings of the 2015 International Conference on Pervasive Computing (ICPC), Pune, India, 8–10 January 2015; pp. 1–3. [Google Scholar] [CrossRef]
- Mohurle, M.; Panchbhai, V.V. Review on realization of AES encryption and decryption with power and area optimization. In Proceedings of the 2016 IEEE 1st International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES), Delhi, India, 4–6 July 2016; pp. 1–3. [Google Scholar] [CrossRef]
- Lu, M.; Fan, A.; Xu, J.; Shan, W. A Compact, Lightweight and Low-Cost 8-Bit Datapath AES Circuit for IoT Applications in 28nm CMOS. In Proceedings of the 2018 17th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 1464–1469. [Google Scholar] [CrossRef]
- Banerjee, U.; Wright, A.; Juvekar, C.; Waller, M.; Arvind; Chandrakasan, A.P. An Energy-Efficient Reconfigurable DTLS Cryptographic Engine for Securing Internet-of-Things Applications. IEEE J. Solid-State Circuits 2019, 54, 2339–2352. [Google Scholar] [CrossRef]
- Marshall, B.; Newell, G.R.; Page, D.; Saarinen, M.J.O.; Wolf, C. The design of scalar AES Instruction Set Extensions for RISC-V. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2021, 109–136. [Google Scholar] [CrossRef]
- Pan, L.; Tu, G.; Liu, S.; Cai, Z.; Xiong, X. A Lightweight AES Coprocessor Based on RISC-V Custom Instructions. Secur. Commun. Netw. 2021, 2021, 9355123. [Google Scholar] [CrossRef]
- Agwa, S.; Yahya, E.; Ismail, Y. Power efficient AES core for IoT constrained devices implemented in 130nm CMOS. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Bui, D.H.; Puschini, D.; Bacles-Min, S.; Beigné, E.; Tran, X.T. AES Datapath Optimization Strategies for Low-Power Low-Energy Multisecurity-Level Internet-of-Things Applications. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 3281–3290. [Google Scholar] [CrossRef]
- Shahbazi, K.; Ko, S.B. High throughput and area-efficient FPGA implementation of AES for high-traffic applications. IET Comput. Digit. Tech. 2020, 14, 344–352. [Google Scholar] [CrossRef]
- Zgheib, A.; Potin, O.; Rigaud, J.B.; Dutertre, J.M. Extending a RISC-V core with an AES hardware accelerator to meet IOT constraints. In Proceedings of the SMACD/PRIME 2021; International Conference on SMACD and 16th Conference on PRIME, Online, 19–22 July 2021; pp. 1–4. [Google Scholar]
- Al-Gailani, M.F.; Al-Khafaji, A.Q. Loop Unrolling Implementation of an AES Algorithm Using Xilinx System Generator. Iraqi J. Inf. Commun. Technol. 2019, 2, 38–45. [Google Scholar] [CrossRef]
- Dworkin, M. Recommendation for Block Cipher Modes of Operation: Methods and Techniques; National Inst of Standards and Technology (NIST), Computer Security Div.: Gaithersburg, MD, USA, 2001. [Google Scholar] [CrossRef]
- Microsoft Corporation. Azure RTOS ThreadX. 2022. Available online: https://github.com/azure-rtos/threadx (accessed on 4 September 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Year | Technology | AES Architecture * | Frequency (MHz) | Cycles/ Encryption ** | Throughput ** |
|---|---|---|---|---|---|---|
| Agwa et al. [34] | 2017 | ASIC (Loosely) | Rolling | 666 | - | 2.601 Gbps |
| Bui et al. [35] | 2017 | ASIC (Loosely) | Rolling | 10 | 44 | 28 Mbps |
| Lu et al. [30] | 2018 | ASIC (-) | Rolling | 50 | 213 | 30.05 Mbps |
| Banerjee et al. [31] | 2019 | ASIC (Loosely) | Rolling | 16 | 11 | - |
| Al-Gailani et al. [38] | 2019 | FPGA (-) | Unrolling | 158 | 1 | 20.3 Gbps |
| Shahbazi et al. [36] | 2020 | FPGA (-) | Unrolling | 622.4 | 1 | 79.7 Gbps |
| Marshall et al. [32] | 2020 | ASIC (Tightly) | Rolling and Unrolling | - | 18–30 | - |
| Pan et al. [33] | 2021 | FPGA and ASIC (Tightly) | Rolling | 100 | 11–19 | 471–695 Mbps |
| Function (funct7) | Input1 (rs1) | Input2 (rs2) | Output (rd) | Description |
|---|---|---|---|---|
| Send Key | Key | Key | Null | Sends 2 × 32-bit of the AES key |
| Send Size | Size | Null | Null | Sends the message size |
| Send Message | Message | Message | Null | Sends 2 × 32-bit of the message |
| Send Addresses EN | Message address | Result address | Null | Sends the addresses, and sets load and encryption |
| Send Addresses DE | Message address | Result address | Null | Sends the addresses, and sets load and decryption |
| Start Encryption | 1 | Null | Null | Sets the start encryption flag on |
| Start Decryption | Null | 1 | Null | Sets the start decryption flag on |
| Read Result | Null | Null | Result | Reads one word of the result |
| Registers | Default Address |
|---|---|
| Status | 0 × 2000 |
| Key | 0 × 2004 |
| Message | 0 × 2024 |
| Cipher_sel | 0 × 2034 |
| Function | Input1 | Input2 | Ouput | Description |
|---|---|---|---|---|
| Read Status | Status Address | Null | Null | Reads the Status register for checking the ready signal |
| Write Key | Key Address | Key | Null | Writes 32 bits of the key in the specified memory address |
| Write Message | Message Address | Message | Null | Writes 32 bits of the message in the specified memory address |
| Read Message | Message Address | Null | Message | Reads 32 bits message from the specified memory address |
| Write Cipher_sel | Cipher_sel Address | Cipher_sel | Null | Writes to the Cipher_sel register, true for encryption and false for decryption. |
| FACV-128 | FACV-192 | FACV-256 | Unrolled FACV-128 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rocket Core | RoCC | RoCC Mem | MMIO | RoCC | RoCC Mem | MMIO | RoCC | RoCC Mem | MMIO | RoCC 2-Rounds | RoCC 9-Rounds | |
| LUTs | 17,903 | +4056 | +4086 | +4174 | +4328 | +4464 | +4432 | +4824 | +4923 | +4913 | +8845 | +18,452 |
| +22.7% | +22.8% | +23.3% | +24.2% | +24.9% | +24.8% | +26.9% | +27.5% | +27.4% | +49.4% | +103.1% | ||
| Muxes | 714 | +172 | +168 | +129 | +301 | +297 | +258 | +351 | +332 | +340 | +1339 | +6297 |
| +24.1% | +23.5% | +18.1% | +35.6% | +35.1% | +32.9% | +49.2% | +46.5% | +47.6% | +187.5% | +881.9% | ||
| Flip-Flops | 10,161 | +1864 | +2169 | +1822 | +2187 | +2496 | +2146 | +2507 | +2818 | +2465 | +3718 | +4638 |
| +18.3% | +21.3% | +17.9% | +21.5% | +24.6% | +21.1% | +24.7% | +27.7% | +24.3% | +36.6% | +45.6% | ||
| Logic Gates | 181,955 | +29,894 | +32,621 | +32,621 | +33,269 | +35,835 | +28,867 | +36,526 | +39,710 | +32,392 | +197,924 | +322,450 |
| +16.43% | +17.93% | +17.93% | +18.28% | +19.69% | +15.86% | +20.07% | +21.82% | +17.80% | +108.77% | +177.21% | ||
| FACV-128 | FACV-192 | FACV-256 | ||
|---|---|---|---|---|
| Clock Cycles | Software | 163 | 183 | 244 |
| RoCC Mem | 34 | 39 | 45 | |
| RoCC | 34 | 39 | 45 | |
| MMIO | 83 | 113 | 142 | |
| Standard Deviation | Software | 0 | 0 | 0 |
| RoCC Mem | 0 | 0 | 0 | |
| RoCC | 0 | 0 | 0 | |
| MMIO | 0 | 0 | 0 | |
| Performance Increase | RoCC Mem | 4.8× | 4.7× | 5.4× |
| RoCC | 4.8× | 4.7× | 5.4× | |
| MMIO | 1.9× | 1.6× | 1.7× |
| FACV-128 | FACV-192 | FACV-256 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Size of Message | 16 Bytes | 32 Bytes | 48 Bytes | 64Bytes | 80 Bytes | 16 Bytes | 32 Bytes | 48 Bytes | 64 Bytes | 80 Bytes | 16 Bytes | 32 Bytes | 48 Bytes | 64 Bytes | 80 Bytes | |
| Clock Cyles | Software | 119,229 | 238,444 | 357,718 | 476,841 | 596,208 | 131,602 | 263,497 | 394,708 | 526,963 | 659,334 | 160,833 | 321,743 | 482,443 | 643,405 | 804,283 |
| RoCC Mem | 20 | 38 | 77 | 121 | 165 | 20 | 38 | 81 | 126 | 166 | 20 | 38 | 77 | 125 | 168 | |
| RoCC | 66 | 126 | 188 | 251 | 314 | 68 | 130 | 194 | 259 | 324 | 68 | 134 | 200 | 267 | 334 | |
| MMIO | 189 | 367 | 554 | 741 | 922 | 189 | 373 | 557 | 749 | 921 | 191 | 385 | 554 | 745 | 1013 | |
| Standard Deviation | Software | 620 | 886 | 757 | 1024 | 1355 | 701 | 763 | 1104 | 1090 | 1606 | 659 | 1032 | 1121 | 1123 | 1420 |
| RoCC Mem | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| RoCC | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| MMIO | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 7 | 1 | 0 | 3 | |
| Performance Increase | RoCC Mem | 5961× | 6275× | 4646× | 3941× | 3613× | 6580× | 6934× | 4873× | 4182× | 3972× | 8042× | 8467× | 6265× | 5147× | 4787× |
| RoCC | 1807× | 1892× | 1903× | 1900× | 1899× | 1935× | 2027× | 2035× | 2035× | 2035× | 2365× | 2401× | 2412× | 2410× | 2408× | |
| MMIO | 631× | 650× | 646× | 644× | 647× | 696× | 706× | 709× | 704× | 716× | 842× | 836× | 871× | 864× | 794× | |
| Version | Basic Processing | Cooperative Scheduling | Preemptive Scheduling | Interrupt Processing | Interrupt Preemptive | Message Processing | Synchronization Processing | Memory Allocation |
|---|---|---|---|---|---|---|---|---|
| (i) Baseline (no network) | 73,012 | 4,049,986 | 1,552,968 | 5,746,523 | 3,051,415 | 5,480,340 | 5,676,620 | 2,810,406 |
| (ii) Echo | 38,994 | 2,145,623 | 869,367 | 3,212,352 | 1,707,203 | 3,013,826 | 3,180,201 | 1,489,664 |
| (iii) Echo + SW | 24,678 | 1,288,700 | 461,632 | 1,490,272 | 1,015,795 | 2,227,820 | 2,275,369 | 1,109,816 |
| (iv) Echo + RoCC Mem | 37,560 | 2,100,921 | 830,111 | 3,035,100 | 1,594,133 | 2,779,515 | 2,895,005 | 1,411,679 |
| (v) Echo + RoCC | 35,546 | 2,053,071 | 817,707 | 2,955,054 | 1,586,991 | 2,778,290 | 2,901,002 | 1,412,516 |
| (vi) Echo + MMIO | 37,060 | 2,137,461 | 806,495 | 3,066,915 | 1,566,676 | 2,849,630 | 2,849,586 | 1,437,321 |
| Version | Basic Processing | Cooperative Scheduling | Preemptive Scheduling | Interrupt Processing | Interrupt Preemptive | Message Processing | Synchronization Processing | Memory Allocation |
|---|---|---|---|---|---|---|---|---|
| (i) Baseline (no network) | −46.6% | −47.0% | −44.0% | −44.1% | −44.1% | −45.0% | −44.0% | −47.0% |
| (ii) Echo | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% |
| (iii) Echo + SW | 36.7% | 39.9% | 46.9% | 53.6% | 40.5% | 26.1% | 28.5% | 25.5% |
| (iv) Echo + RoCC Mem | 3.7% | 2.1% | 4.5% | 5.5% | 6.6% | 7.8% | 9.0% | 5.2% |
| (v) Echo + RoCC | 8.8% | 4.3% | 5.9% | 8.0% | 7.0% | 7.8% | 8.8% | 5.2% |
| (vi) Echo + MMIO | 5.0% | 0.4% | 7.2% | 4.5% | 8.2% | 5.4% | 10.4% | 3.5% |
| FACV-128 | FACV-192 | FACV-256 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rocket Core | +RoCC | +RoCC Mem | +MMIO | +RoCC | +RoCC Mem | +MMIO | +RoCC | +RoCC Mem | +MMIO | |
| Static Power (W) | 0.099 | 0.100 | 0.100 | 0.100 | 0.100 | 0.100 | 0.100 | 0.100 | 0.100 | 0.100 |
| +1.0% | +1.0% | +1.0% | +1.0% | +1.0% | +1.0% | +1.0% | +1.0% | +1.0% | ||
| Dynamic Power (W) | 0.196 | 0.218 | 0.220 | 0.221 | 0.218 | 0.217 | 0.215 | 0.232 | 0.231 | 0.217 |
| +11.2% | +12.3% | +12.7% | +11.2% | +10.7% | +9.7% | +18.4% | +17.9% | +10.7% | ||
| Total Power (W) | 0.295 | 0.318 | 0.320 | 0.321 | 0.318 | 0.317 | 0.315 | 0.332 | 0.331 | 0.317 |
| +7.8% | +8.5% | +8.8% | +7.8% | +7.5% | +6.8% | +12.5% | +12.2% | +7.5% | ||
| FACV-128 | FACV-192 | FACV-256 | |||||
|---|---|---|---|---|---|---|---|
| Size of Message | 16 Bytes | 80 Bytes | 16 Bytes | 80 Bytes | 16 Bytes | 80 Bytes | |
| Energy/ Message (J) | Software | 541.12 | 2705.87 | 597.27 | 2992.36 | 729.93 | 3650.21 |
| RoCC Mem | 0.10 | 0.81 | 0.10 | 0.81 | 0.10 | 0.86 | |
| RoCC | 0.32 | 1.55 | 0.33 | 1.58 | 0.35 | 1.70 | |
| MMIO | 0.93 | 4.55 | 0.93 | 4.46 | 0.93 | 4.94 | |
| Work | Year | Technology | AES Architecture | Frequency (MHz) | Cycles/ Encryption * | Throughput * |
|---|---|---|---|---|---|---|
| Agwa et al. [34] | 2017 | ASIC (Loosely) | Rolling | 666 | - | 2.601 Gbps |
| Bui et al. [35] | 2017 | ASIC (Loosely) | Rolling | 10 | 44 | 28 Mbps |
| Lu et al. [30] | 2018 | ASIC (-) | Rolling | 50 | 213 | 30.05 Mbps |
| Banerjee et al. [31] | 2019 | ASIC (Loosely) | Rolling | 16 | 11 | - |
| Al-Gailani et al. [38] | 2019 | FPGA (-) | Unrolling | 158 | 1 | 20.3 Gbps |
| Shahbazi et al. [36] | 2020 | FPGA (-) | Unrolling | 622.4 | 1 | 79.7 Gbps |
| Marshall et al. [32] | 2020 | ASIC (Tightly) | Rolling and Unrolling | - | 18–30 | - |
| Pan et al. [33] | 2021 | FPGA & ASIC (Tightly) | Rolling | 100 | 11–19 | 471–695 Mbps |
| FAC-V | 2022 | FPGA (Loosely and Tightly) | Fully Unrolled and Partly Unrolled and Rolled | 65 | 1 5 10 | 8.32 Gbps 1.66 Gbps 832 Mbps |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomes, T.; Sousa, P.; Silva, M.; Ekpanyapong, M.; Pinto, S. FAC-V: An FPGA-Based AES Coprocessor for RISC-V. J. Low Power Electron. Appl. 2022, 12, 50. https://doi.org/10.3390/jlpea12040050
Gomes T, Sousa P, Silva M, Ekpanyapong M, Pinto S. FAC-V: An FPGA-Based AES Coprocessor for RISC-V. Journal of Low Power Electronics and Applications. 2022; 12(4):50. https://doi.org/10.3390/jlpea12040050
Chicago/Turabian StyleGomes, Tiago, Pedro Sousa, Miguel Silva, Mongkol Ekpanyapong, and Sandro Pinto. 2022. "FAC-V: An FPGA-Based AES Coprocessor for RISC-V" Journal of Low Power Electronics and Applications 12, no. 4: 50. https://doi.org/10.3390/jlpea12040050