
Weibull Regression and Machine Learning Survival Models: Methodology, Comparison, and Application to Biomedical Data Related to Cardiac Surgery
 ,
,  ,
,  ,
,  and
and 
Abstract
:Simple Summary
Abstract
1. Introduction
2. Survival Analysis
2.1. Kaplan–Meier Estimator
2.2. Nelson–Aalen Estimator
3. Weibull Regression Model
3.1. Formulation
3.2. Point Estimation
3.3. Adequacy of the Fitted Model
4. Random Survival Forest Method
4.1. Algorithm
| Algorithm 1: Random survival forest method. |
 |
4.2. Node Splitting and Prediction
4.3. Cumulative Hazard Function for the OOB Set
4.4. Prediction Error and Variable Importance
5. Application to Biomedical Data
5.1. Description of the Data Set and Exploratory Analysis
5.2. Survival Analysis
- (i)
- Group 1: white and congenital patients in the fast-track care protocol.
- (ii)
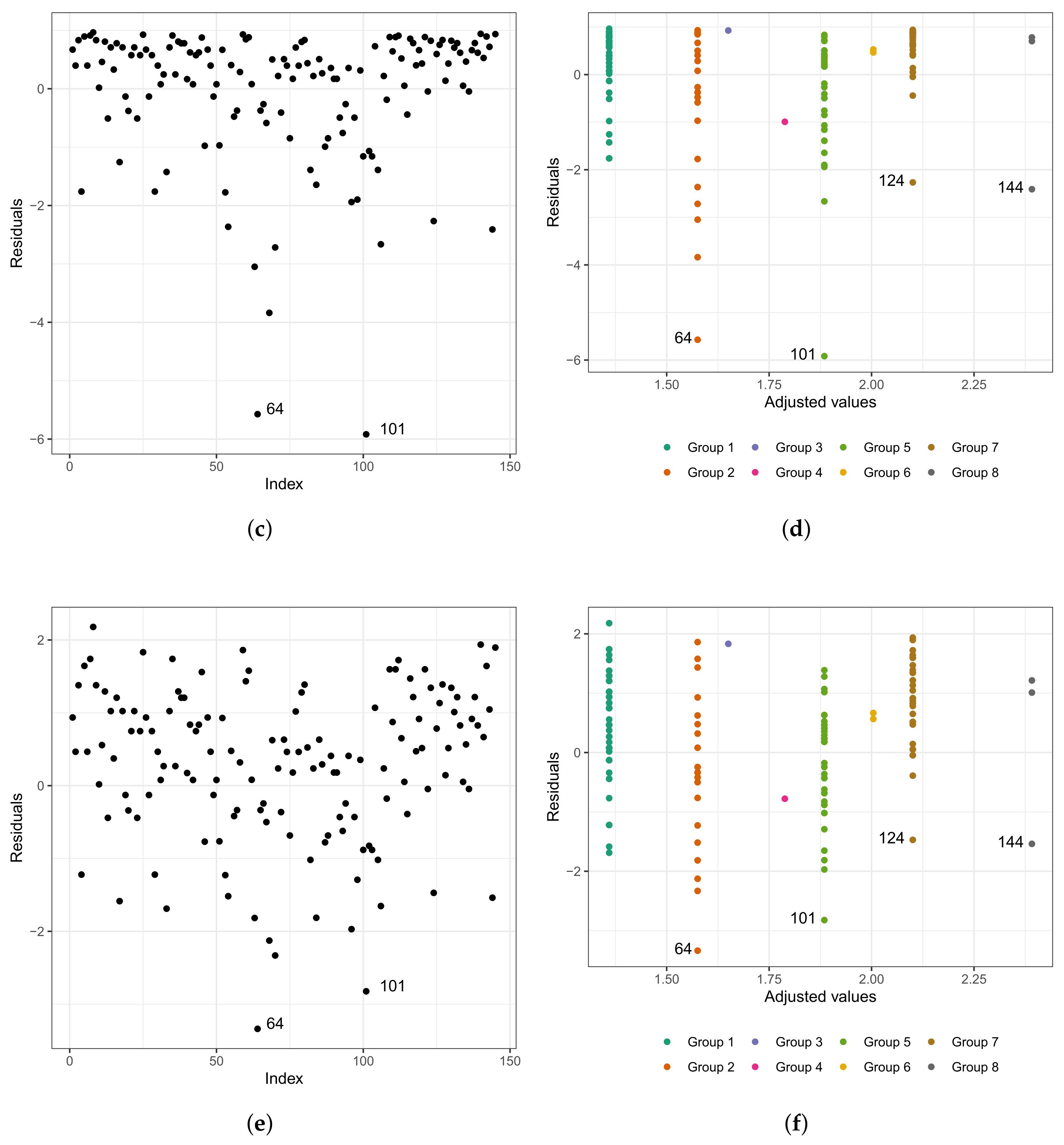
- Group 2: white and congenital patients in the conventional care protocol. Here, the highlight is for patient , 1 year old, female, and the time spent in the surgical ward is longer than 6.67 h; that is, the exact time is unknown. In this group, the longest stay in the surgical ward is that of patient (6.75 h), aged 0.6 (approximately 7 months), and female. The highest age for this group is 49 years, and the minimum is 0.3 (approximately 3 and a half months). The youngest is patient , with 4.50 h of length of stay.
- (iii)
- Group 3: patients in the fast-track care protocol, black, and congenital (only patient ).
- (iv)
- Group 4: patients in the fast-track care protocol, Asian, and coronary (only patient ).
- (v)
- Group 5: patients in the fast-track care protocol, white and coronary. Here, we highlight patient , aged 60 years, male, and 9.92 h of length of stay. In this group, patient is the one with the longest length of stay. Patient has the same characteristics as patient . However, their length of stay is 7.50 h, approximately 24% less than that of patient .
- (vi)
- Group 6: patients in the conventional care protocol, Asian, and coronary (patients and ).
- (vii)
- Group 7: patients in the conventional care protocol, white and coronary. The highlight here is for patient , aged 60 years, male, and with 10.50 h of length of stay. In this group, patient has the longest length of stay. The oldest patient in this group is 81 years old, male, with 7.33 h of length of stay.
- (viii)
- Group 8: patients in the conventional care protocol, black, and coronary (patients , , and ). Patient is 58 years old, male, and with 8.45 h of length of stay; patient is 47 years old, male, and with 7.92 h of length of stay; and patient is 59 years old, male, and with 14.17 h of length of stay. We must highlight that patient , even with close similarities to patient , had a longer stay of 40% than the latter.
- (i)
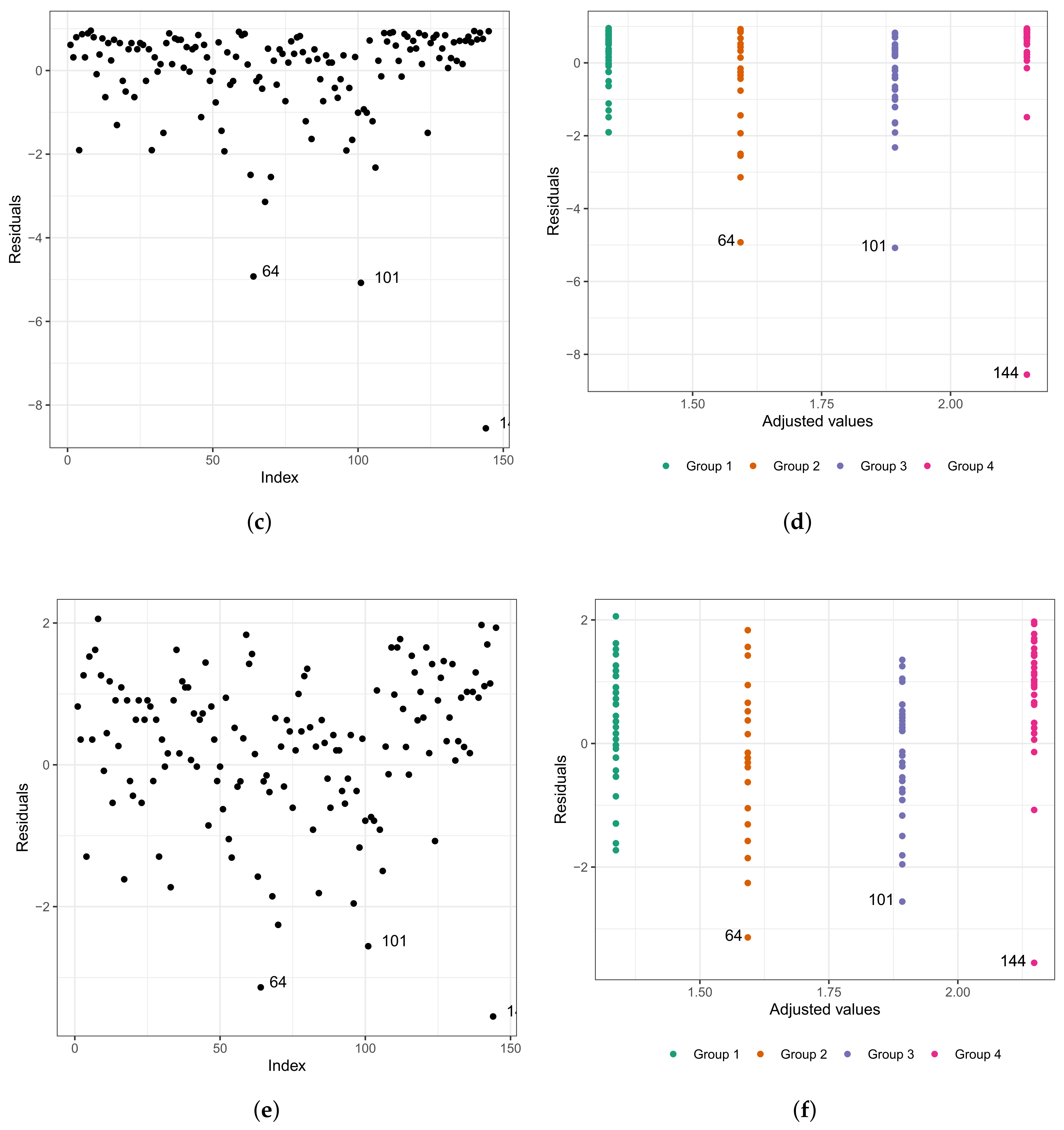
- Group 1: congenital patients in the fast-track care protocol.
- (ii)
- Group 2: congenital patients in the conventional care protocol.
- (iii)
- Group 3: coronary patients in the fast-track protocol.
- (iv)
- Group 4: coronary patients in the conventional care protocol.
5.3. Analysis Using Machine Learning Algorithms
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pluta, K.; Porębska, K.; Urbanowicz, T.; Gąsecka, A.; Olasińska-Wiśniewska, A.; Targoński, R.; Krasińska, A.; Filipiak, K.J.; Jemielity, M.; Krasiński, Z. Platelet–leucocyte aggregates as novel biomarkers in cardiovascular diseases. Biology 2022, 11, 224. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Cardiovascular Diseases (CVDs). 2021. Available online: https://www.who.int/news-room/fact-sheets/detail/cardiovascular-diseases-(cvds) (accessed on 23 September 2022).
- Klein, J.P.; Moeschberger, M.L. Survival Analysis: Techniques for Censored and Truncated Data; Springer: New York, NY, USA, 2005. [Google Scholar]
- Lee, E.T.; Wang, J. Statistical Methods for Survival Data Analysis; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Ishwaran, H.; Kogalur, U.B. randomForestSRC: Fast Unified Random Forests for Survival, Regression, and Classification. 2021. R Package. Available online: https://cran.r-project.org/package=randomForestSRC (accessed on 7 March 2023).
- Casella, G.; Berger, R.L. Statistical Inference; Cengage Learning: Stamford, CA, USA, 2002. [Google Scholar]
- Alkadya, W.; ElBahnasy, K.; Leiva, V.; Gad, W. Classifying COVID-19 based on amino acids encoding with machine learning algorithms. Chemom. Intell. Lab. Syst. 2022, 224, 104535. [Google Scholar] [CrossRef] [PubMed]
- Sardar, I.; Akbar, M.A.; Leiva, V.; Alsanad, A.; Mishra, P. Machine learning and automatic ARIMA/Prophet models-based forecasting of COVID-19: Methodology, evaluation, and case study in SAARC countries. Stoch. Environ. Res. Risk Assess. 2023, 37, 345–359. [Google Scholar] [CrossRef]
- Chaouch, H.; Charfeddine, S.; Aoun, S.B.; Jerbi, H.; Leiva, V. Multiscale monitoring using machine learning methods: New methodology and an industrial application to a photovoltaic system. Mathematics 2022, 10, 890. [Google Scholar] [CrossRef]
- Leao, J.; Leiva, V.; Saulo, H.; Tomazella, V. Birnbaum-Saunders frailty regression models: Diagnostics and application to medical data. Biom. J. 2017, 59, 291–314. [Google Scholar] [CrossRef] [PubMed]
- Leao, J.; Leiva, V.; Saulo, H.; Tomazella, V. Incorporation of frailties into a cure rate regression model and its diagnostics and application to melanoma data. Stat. Med. 2018, 37, 4421–4440. [Google Scholar] [CrossRef] [PubMed]
- Meshref, H. Cardiovascular disease diagnosis: A machine learning interpretation approach. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 258–269. [Google Scholar] [CrossRef] [Green Version]
- Ishwaran, H.; Kogalur, U.B.; Blackstone, E.H.; Lauer, M.S. Random survival forests. Ann. Appl. Stat. 2008, 2, 841–860. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Ehrlinger, J.; Blackstone, E.H. ggRandomForests: Survival with Random Forests. 2019. Package Vignette. Available online: http://cran.r-project.org (accessed on 7 March 2023).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rytgaard, H.C.; Gerds, T.A. Random forests for survival analysis. In Wiley StatsRef: Statistics Reference Online; Wiley: New York, NY, USA, 2014; pp. 1–8. [Google Scholar]
- Ishwaran, H.; Kogalur, U.B. Random survival forests for R. R News 2007, 7, 25–31. [Google Scholar]
- Ishwaran, H.; Kogalur, U.B. Consistency of random survival forests. Stat. Probab. Lett. 2010, 80, 1056–1064. [Google Scholar] [CrossRef] [Green Version]
- Efron, B. Bootstrap methods: Another look at the jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Chen, X.; Ishwaran, H. Random forests for genomic data analysis. Genomics 2012, 99, 323–329. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ishwaran, H.; Gerds, T.A.; Kogalur, U.B.; Moore, R.D.; Gange, S.J.; Lau, B.M. Random survival forests for competing risks. Biostatistics 2014, 15, 757–773. [Google Scholar] [CrossRef] [Green Version]
- Nasejje, J.B.; Mwambi, H.; Dheda, K.; Lesosky, M. A comparison of the conditional inference survival forest model to random survival forests based on a simulation study as well as on two applications with time-to-event data. Bmc Med Res. Methodol. 2017, 17, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hothorn, T.; Hornik, K.; Zeileis, A. Unbiased recursive partitioning: A conditional inference framework. J. Comput. Graph. Stat. 2006, 15, 651–674. [Google Scholar] [CrossRef] [Green Version]
- Hothorn, T.; Hornik, K.; Zeileis, A. ctree: Conditional inference trees. Compr. R Arch. Netw. 2015, 8. Available online: http://bioconductor.statistik.tu-dortmund.de/cran/web/packages/partykit/vignettes/ctree.pdf (accessed on 7 March 2023).
- Wang, H.; Zhou, L. Random survival forest with space extensions for censored data. Artif. Intell. Med. 2017, 79, 52–61. [Google Scholar] [CrossRef]
- Zhang, X.; Tang, F.; Ji, J.; Han, W.; Lu, P. Risk prediction of dyslipidemia for Chinese han adults using random forest survival model. Clin. Epidemiol. 2019, 11, 1047–1055. [Google Scholar] [CrossRef] [Green Version]
- Imani, F.; Chen, R.; Tucker, C.; Yang, H. Random forest modeling for survival analysis of cancer recurrences. In Proceedings of the 15th International Conference on Automation Science and Engineering, Vancouver, BC, Canada, 22–26 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 399–404. [Google Scholar]
- Oliveira, T.A.; da Silva, P.A.F.; de Albuquerque Martins, H.J.A.; Pereira, L.C.; de Lima Brito, A.; de Mendonça, E.B. Comparaçao de random survival forest e modelo de Cox com relaçao a performance de previsao: Um estudo de caso. Sigmae 2019, 8, 490–508. [Google Scholar]
- Cox, D.R. Regression models and life-tables. J. R. Stat. Soc. 1972, 34, 187–202. [Google Scholar] [CrossRef]
- Harrell, F.E.; Califf, R.M.; Pryor, D.B.; Lee, K.L.; Rosati, R.A. Evaluating the yield of medical tests. JAMA 1982, 247, 2543–2546. [Google Scholar] [CrossRef] [PubMed]
- Shah, A.; Mullins, C.; Robbins, J. Comparing the Weibull and Cox proportional hazards models in pharmacoepidemiologic studies. J. Clin. Epidemiol. 2018, 98, 20–27. [Google Scholar]
- Elsäßer, A.; Regierer, A. The choice of a parametric survival model in health economic evaluations: Empirical application and software implementation of seven popular models. Med. Decis. Mak. 2017, 37, 840–852. [Google Scholar]
- Kalbfleisch, J.D.; Prentice, R.L. The Statistical Analysis of Failure Time Data; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Kaplan, E.L.; Meier, P. Nonparametric estimation from incomplete observations. J. Am. Stat. Assoc. 1985, 53, 457–481. [Google Scholar] [CrossRef]
- Mantel, N. Evaluation of survival data and two new rank order statistics arising in its consideration. Cancer Chemother Rep. 1966, 50, 163–170. [Google Scholar]
- Aalen, O. Nonparametric inference for a family of counting processes. Ann. Stat. 1978, 6, 701–726. [Google Scholar] [CrossRef]
- Nelson, W. Theory and applications of hazard plotting for censored failure data. Technometrics 1972, 14, 945–966. [Google Scholar] [CrossRef]
- Borgan, Ø. Nelson–Aalen Estimator. In Wiley StatsRef: Statistics Reference Online; Wiley: New York, NY, USA, 2014. [Google Scholar]
- Hallinan, A.J., Jr. A review of the Weibull distribution. J. Qual. Technol. 1993, 25, 85–93. [Google Scholar] [CrossRef]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Cox, D.R.; Snell, E.J. A general definition of residuals. J. R. Stat. Soc. 1968, 30, 248–265. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman and Hall/CRC: New York, NY, USA, 1984. [Google Scholar]
- Segal, M.R. Regression trees for censored data. Biometrics 1988, 44, 35–47. [Google Scholar] [CrossRef]
- Udzik, J.; Waszczyk, A.; Safranow, K.; Biskupski, A.; Majer, K.; Kwiatkowski, S.; Kwiatkowska, E. Assessment and prognosis in CSA-AKI using novel Kidney injury biomarkers: A prospective observational study. Biology 2021, 10, 823. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, S.C.; Korones, S.B.; Berendes, H.W. Congenital heart disease in 56,109 births incidence and natural history. Circulation 1971, 43, 323–332. [Google Scholar] [CrossRef] [Green Version]
- Cox, D.R.; Hinkley, D.V. Theoretical Statistics; CRC Press: New York, NY, USA, 1979. [Google Scholar]
- Hosmer, D.W.; Lemeshow, S. Applied Survival Analysis: Regression Modelling of Time-to-Event Data; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Ishwaran, H.; Kogalur, U.B. randomSurvivalForest. 2013. R Package. Available online: https://cran.r-project.org/src/contrib/Archive/randomSurvivalForest/ (accessed on 7 March 2023).
- Fernes, A.M.; Mansur, A.J.; Canêo, L.F.; Lourenço, D.D.; Piccioni, M.A.; Franchi, S.M.; Afiune, C.M.; Gadioli, J.W.; Oliveira, S.d.A.; Ramires, J.A. The reduction in hospital stay and costs in t-he care of patients with congenital heart diseases undergoing fast-track cardiac surgery. Arq. Bras. Cardiol. 2004, 83, 18–26. [Google Scholar]
- Wilmore, D.; Kehlet, H. Management of patients in fast track surgery. BMJ 2001, 322, 473–476. [Google Scholar] [CrossRef]
- Wang, S.; Wang, J.; Liu, Z.; Zhang, B. Unraveling diverse survival strategies of microorganisms to vanadium stress in aquatic environments. Water Res. 2022, 221, 118813. [Google Scholar] [CrossRef] [PubMed]
- Szopa, D.; Mielczarek, M.; Skrzypczak, D.; Izydorczyk, G.; Mikula, K.; Chojnacka, K.; Witek-Krowiak, A. Encapsulation efficiency and survival of plant growth-promoting microorganisms in an alginate-based matrix–A systematic review and protocol for a practical approach. Ind. Crop. Prod. 2022, 181, 114846. [Google Scholar] [CrossRef]
- McCormick, B.J.J.; Richard, S.A.; Murray-Kolb, L.E.; Kang, G.; Lima, A.A.M.; Mduma, E.; Kosek, M.N.; McQuade, E.T.R.; Houpt, E.R.; Bessong, P.; et al. Full breastfeeding protection against common enteric bacteria and viruses: Results from the MAL-ED cohort study. Am. J. Clin. Nutr. 2022, 115, 759–769. [Google Scholar] [CrossRef]
- Ospina, R.; Leite, A.; Ferraz, C.; Magalhaes, A.; Leiva, V. Data-driven tools for assessing and combating COVID-19 out-breaks based on analytics and statistical methods in Brazil. Signa Vitae 2022, 18, 18–32. [Google Scholar]
- Lu, W.; Yu, S.; Liu, H.; Suo, L.; Tang, K.; Hu, J.; Shi, Y.; Hu, K. Survival analysis and risk factors in COVID-19 patients. Disaster Med. Public Health Prep. 2022, 16, 1916–1921. [Google Scholar] [CrossRef] [PubMed]
- Rahman, M.Z.; Akbar, M.A.; Leiva, V.; Tahir, A.; Riaz, M.T.; Martin-Barreiro, C. An intelligent health monitoring and diagnosis system based on the internet of things and fuzzy logic for cardiac arrhythmia COVID-19 patients. Comput. Biol. Med. 2023, 154, 106583. [Google Scholar] [CrossRef] [PubMed]
- Bustos, N.; Tello, M.; Droppelmann, G.; Garcia, N.; Feijoo, F.; Leiva, V. Machine learning techniques as an efficient alternative diagnostic tool for COVID-19 cases. Signa Vitae 2022, 18, 23–33. [Google Scholar]
- Dohlman, A.B.; Klug, J.; Mesko, M.; Gao, I.H.; Lipkin, S.M.; Shen, X.; Iliev, I.D. A pan-cancer mycobiome analysis reveals fungal involvement in gastrointestinal and lung tumors. Cell 2022, 185, 3807–3822. [Google Scholar] [CrossRef]
- Carboni, A.L.; Hanson, M.A.; Lindsay, S.A.; Wasserman, S.A.; Lemaitre, B. Cecropins contribute to Drosophila host defense against a subset of fungal and Gram-negative bacterial infection. Genetics 2022, 220, iyab188. [Google Scholar] [CrossRef] [PubMed]
- Gabelica, M.; Bojčić, R.; Puljak, L. Many researchers were not compliant with their published data sharing statement: A mixed-methods study. J. Clin. Epidemiol. 2022, 150, 33–41. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Age | Congenital | Coronary | ||
|---|---|---|---|---|
| Conventional Care | Fast-Track Care | Conventional Care | Fast-Track Care | |
| Total | 20 | 50 | 37 | 38 |
| Mean | 8.5 | 12.2 | 60.5 | 58.4 |
| Standard deviation | 13.4 | 11.1 | 12.9 | 8.8 |
| Minimum | 0.3 | 0.8 | 18.0 | 38.0 |
| Median | 4.0 | 10.0 | 63.0 | 58.0 |
| Maximum | 49.0 | 38.0 | 81.0 | 79.0 |
| Heart Disease | Care Protocol | Sex | |||
|---|---|---|---|---|---|
| Female | % | Male | % | ||
| Congenital | Conventional Care | 13 | 65 | 7 | 35 |
| Fast-track Care | 21 | 42 | 29 | 58 | |
| Coronary | Conventional Care | 11 | 30 | 26 | 70 |
| Fast-track Care | 8 | 21 | 30 | 80 | |
| Total | 53 | 37 | 92 | 63 | |
| Heart Disease | Care Protocol | Race | |||||
|---|---|---|---|---|---|---|---|
| White | % | Black | % | Yellow | % | ||
| Congenital | Conventional Care | 20 | 100 | 0 | 0 | 0 | 0 |
| Fast-track Care | 49 | 98 | 1 | 2 | 0 | 0 | |
| Coronary | Conventional Care | 32 | 87 | 3 | 8 | 2 | 5 |
| Fast-track Care | 37 | 97 | 0 | 0 | 1 | 3 | |
| Total | 138 | 95 | 4 | 3 | 3 | 2 | |
| Parameter | Covariates | Estimate | Standard Error | p-Value |
|---|---|---|---|---|
| intercept | 1.6020 | 0.0412 | <0.0001 | |
| age | −0.0004 | 0.0017 | 0.8110 | |
| type of protocol - fast-track care | −0.2065 | 0.0392 | <0.0001 | |
| race - black | 0.3125 | 0.1123 | 0.0054 | |
| race - Asian | −0.0918 | 0.1244 | 0.4606 | |
| sex - male | −0.0583 | 0.0399 | 0.1433 | |
| type of patient - coronary | 0.5599 | 0.0931 | <0.0001 | |
| - | −1.5626 | 0.0637 | <0.0001 | |
| - | 0.2100 | - | - | |
| - | 4.5872 | - | - |
| Parameter | Covariates | Estimate | Standard Error | p-Value |
|---|---|---|---|---|
| intercept | 1.5775 | 0.0330 | <0.0001 | |
| type of protocol - fast-track | −0.2158 | 0.0391 | <0.0001 | |
| race - black | 0.2907 | 0.1127 | 0.0099 | |
| race - Asian | −0.0963 | 0.1252 | 0.4414 | |
| type of patient - coronary | 0.5250 | 0.0382 | <0.0001 | |
| - | −1.5517 | 0.0634 | <0.0001 | |
| - | 0.2120 | - | - | |
| - | 4.7170 | - | - |
| Removed Observation | Parameter Estimates | ||||
|---|---|---|---|---|---|
| 1.5538 (<0.0001) | −0.1995 (<0.0001) | 0.3046 (0.0057) | −0.0958 (0.4347) | 0.5364 (<0.0001) | |
| 1.5856 (<0.0001) | −0.2291 (<0.0001) | 0.3053 (0.0048) | −0.0077 (0.5175) | 0.5074 (<0.0001) | |
| 1.5693 (<0.0001) | −0.2024 (<0.0001) | 0.3085 (0.0063) | −0.0872 (0.4850) | 0.5134 (<0.0001) | |
| 1.5776 (<0.0001) | −0.2140 (<0.0001) | −0.0535 (0.6700) | −0.0962 (0.4300) | 0.5227 (<0.0001) | |
| {, , } | 1.5605 (<0.0001) | −0.1971 (<0.0001) | −0.0180 (0.8800) | −0.0668 (0.5600) | 0.5027 (<0.0001) |
| Parameter | Covariates | Estimate | Standard Error | p-Value |
|---|---|---|---|---|
| intercept | 1.5928 | 0.0356 | <0.001 | |
| type of protocol - fast-track care | −0.2557 | 0.0396 | <0.001 | |
| type of patient - coronary | 0.5552 | 0.0383 | <0.001 | |
| - | −1.5010 | 0.0621 | <0.001 | |
| - | 0.2230 | - | - | |
| - | 4.4843 | - | - |
| Removed Observation | Parameter Estimates | ||
|---|---|---|---|
| 1.5720 | −0.2414 | 0.5683 | |
| 1.6036 | −0.2713 | 0.5412 | |
| −1.5753 | −0.2107 | 0.5172 | |
| , | 1.5658 | −0.2103 | 0.5120 |
| Model | Error Rate | C-Index | Most Predictive Variables |
|---|---|---|---|
| RSF (training data) | 23.55% | 0.76 | age, type of patient, type of protocol |
| RSF (testing data) | 20.31% | 0.79 | age, type of patient, type of protocol |
| Weibull regression | 23.82% | 0.76 | type of patient, type of protocol |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cavalcante, T.; Ospina, R.; Leiva, V.; Cabezas, X.; Martin-Barreiro, C. Weibull Regression and Machine Learning Survival Models: Methodology, Comparison, and Application to Biomedical Data Related to Cardiac Surgery. Biology 2023, 12, 442. https://doi.org/10.3390/biology12030442
Cavalcante T, Ospina R, Leiva V, Cabezas X, Martin-Barreiro C. Weibull Regression and Machine Learning Survival Models: Methodology, Comparison, and Application to Biomedical Data Related to Cardiac Surgery. Biology. 2023; 12(3):442. https://doi.org/10.3390/biology12030442
Chicago/Turabian StyleCavalcante, Thalytta, Raydonal Ospina, Víctor Leiva, Xavier Cabezas, and Carlos Martin-Barreiro. 2023. "Weibull Regression and Machine Learning Survival Models: Methodology, Comparison, and Application to Biomedical Data Related to Cardiac Surgery" Biology 12, no. 3: 442. https://doi.org/10.3390/biology12030442