
WFRE-YOLOv8s: A New Type of Defect Detector for Steel Surfaces
Abstract
:1. Introduction
- The WIoU is employed as the loss function of WFRE-YOLOv8s. It effectively balances the gap between high-quality and low-quality data in steel surface defect datasets.
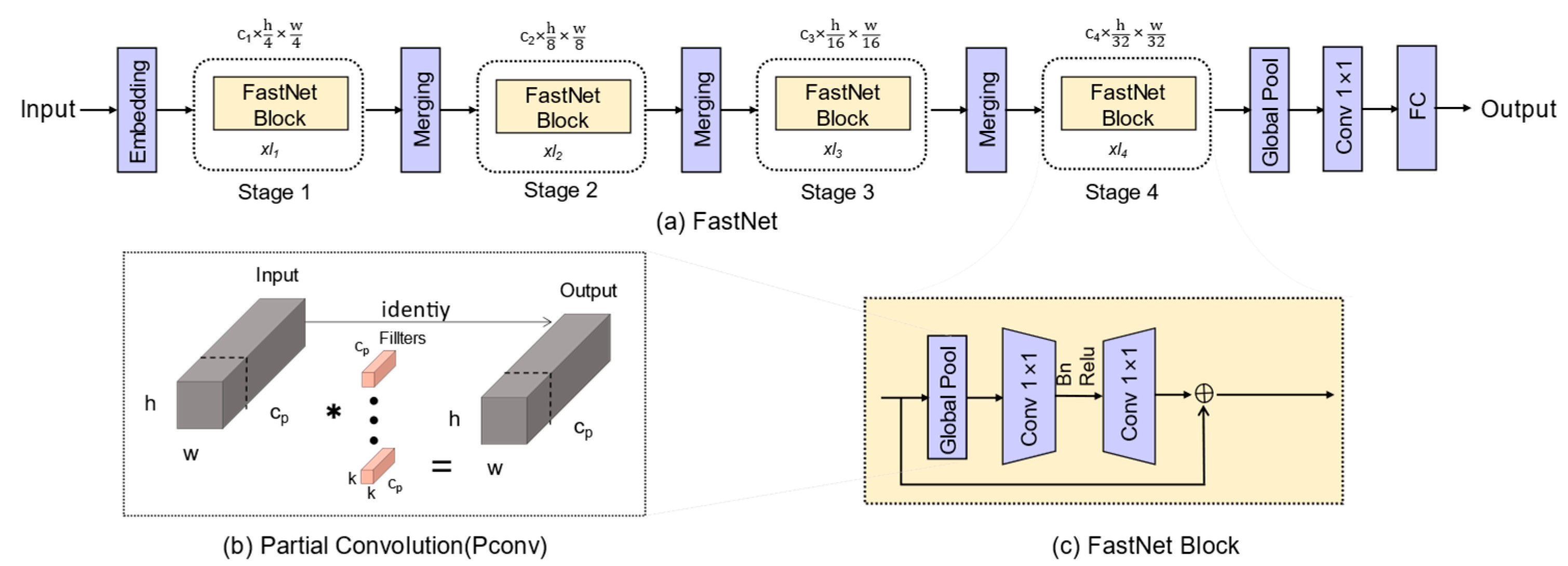
- We have developed a CFN module that replaces the C2f module in the backbone, enhancing network detection accuracy and detection speed. Additionally, it minimizes the number of parameters and FLOPs within the entire network.
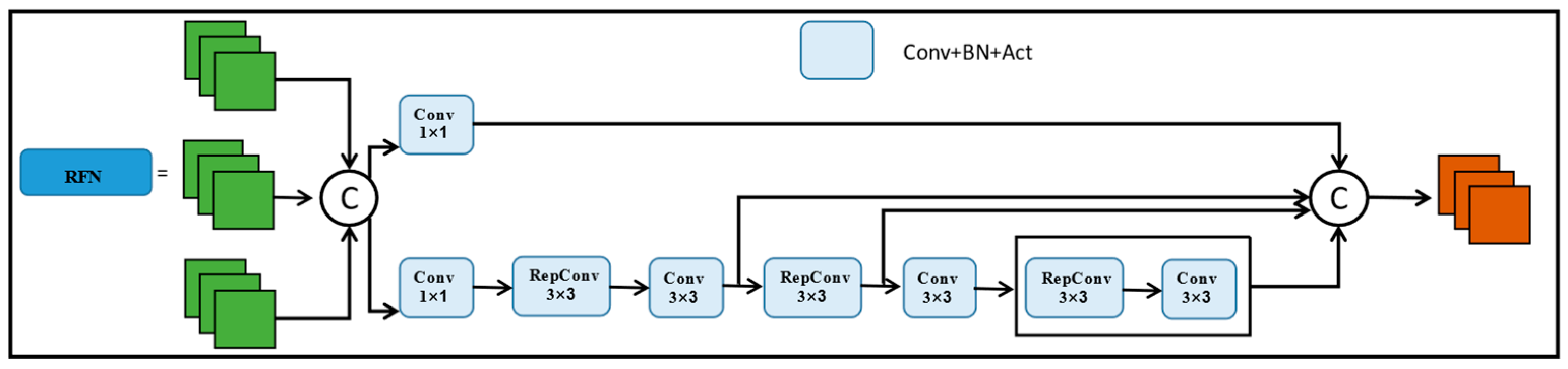
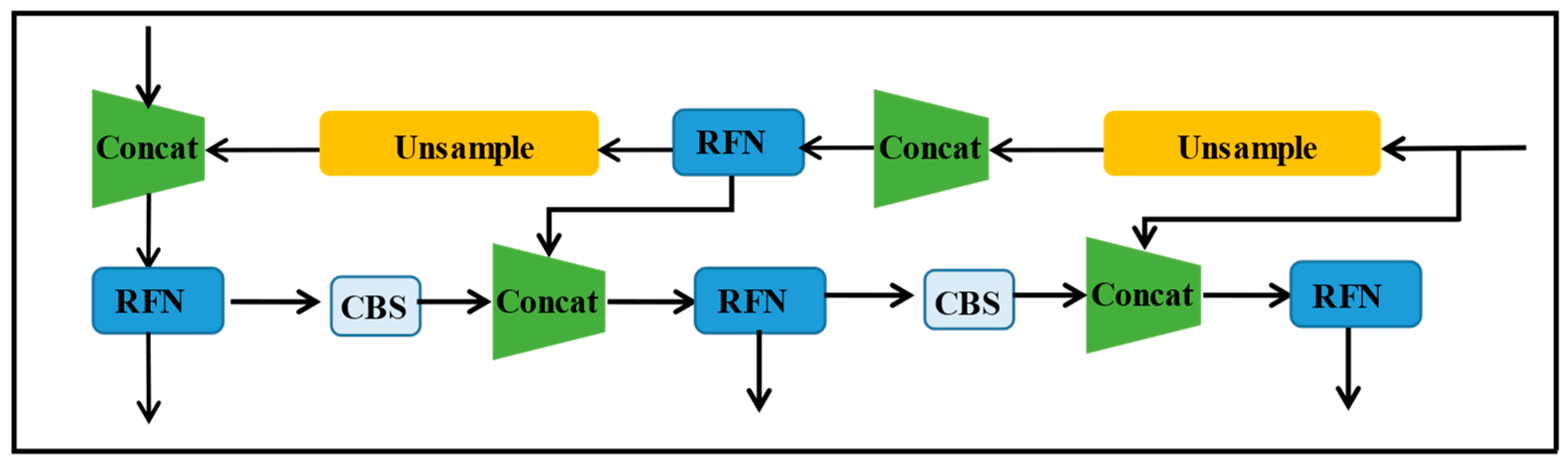
- We have newly designed a neck, named RFN, to reduce the computational overhead. It can fuse different scale features, thus improving the accuracy of the whole detection network.
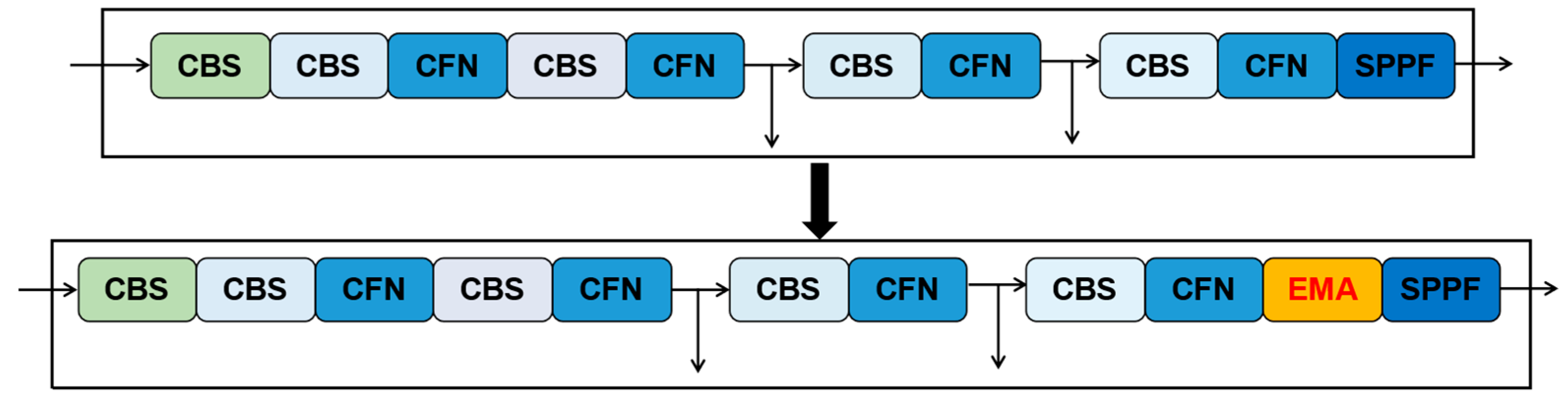
- We have incorporated the EMA into the backbone to optimize the capacity for the extraction of valuable features for steel surface defects. This enhancement has been introduced without any additional load on the network, resulting in increased accuracy in defect detection.
- We carry out a series of experiments primarily on NEU-DET and GC10-DET. The experimental outcomes demonstrated that our proposed methodology yields superior detection results.
2. Related Works
2.1. Conventional Machine Learning Methods
2.2. Deep Learning Approaches
3. Methods
3.1. The YOLOv8 Algorithm
3.1.1. YOLO Algorithm
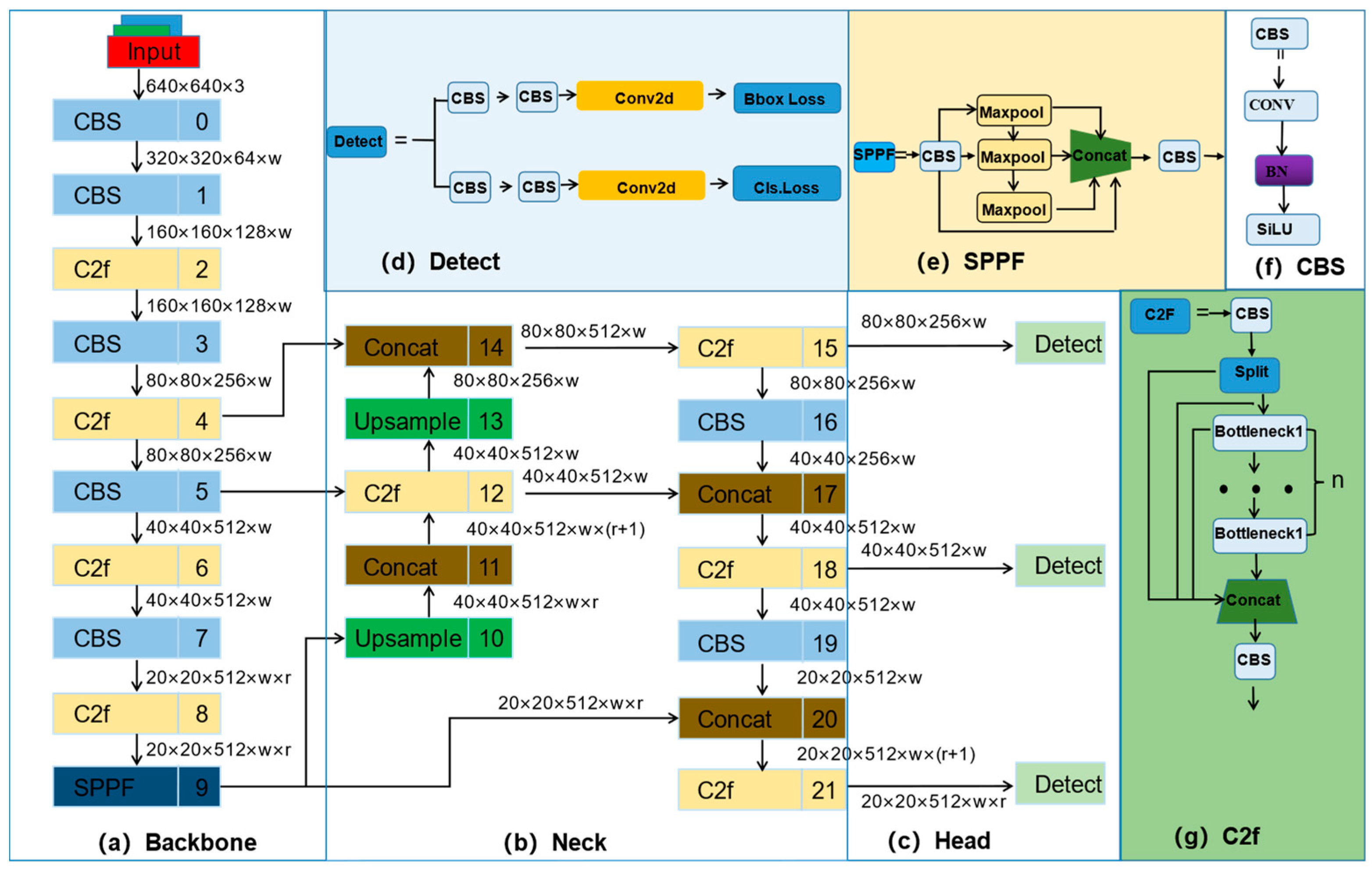
3.1.2. The Structure of YOLOv8
- The backbone is utilized for feature extraction and consists of the CBS, C2f, and SPPF modules. The CBS makes a convolution operation on the input information, applies batch normalization, and activates the information stream by SiLU activation. C2f module replaces the C3 module in YOLOv5 for residual feature learning, which enriches the information stream of the feature extraction network while maintaining a lighter weight compared to C3. The SPPF module is the same as in YOLOv5, which converts arbitrary feature maps into fixed-size feature vectors.
- The neck adopts the structure of FPN + PAN to realize the fusion between multi-scale information. Compared to YOLOv5, C3 was updated to C3.
- The head is utilized to output the coordinates of the predicted box and the confidence of each category. Compared with YOLOv5, this part adopts a more advanced decoupled head (decoupled head). The decoupled head makes use of two independent branches to complete the task of object classification and location prediction and uses different loss functions in these two branches.
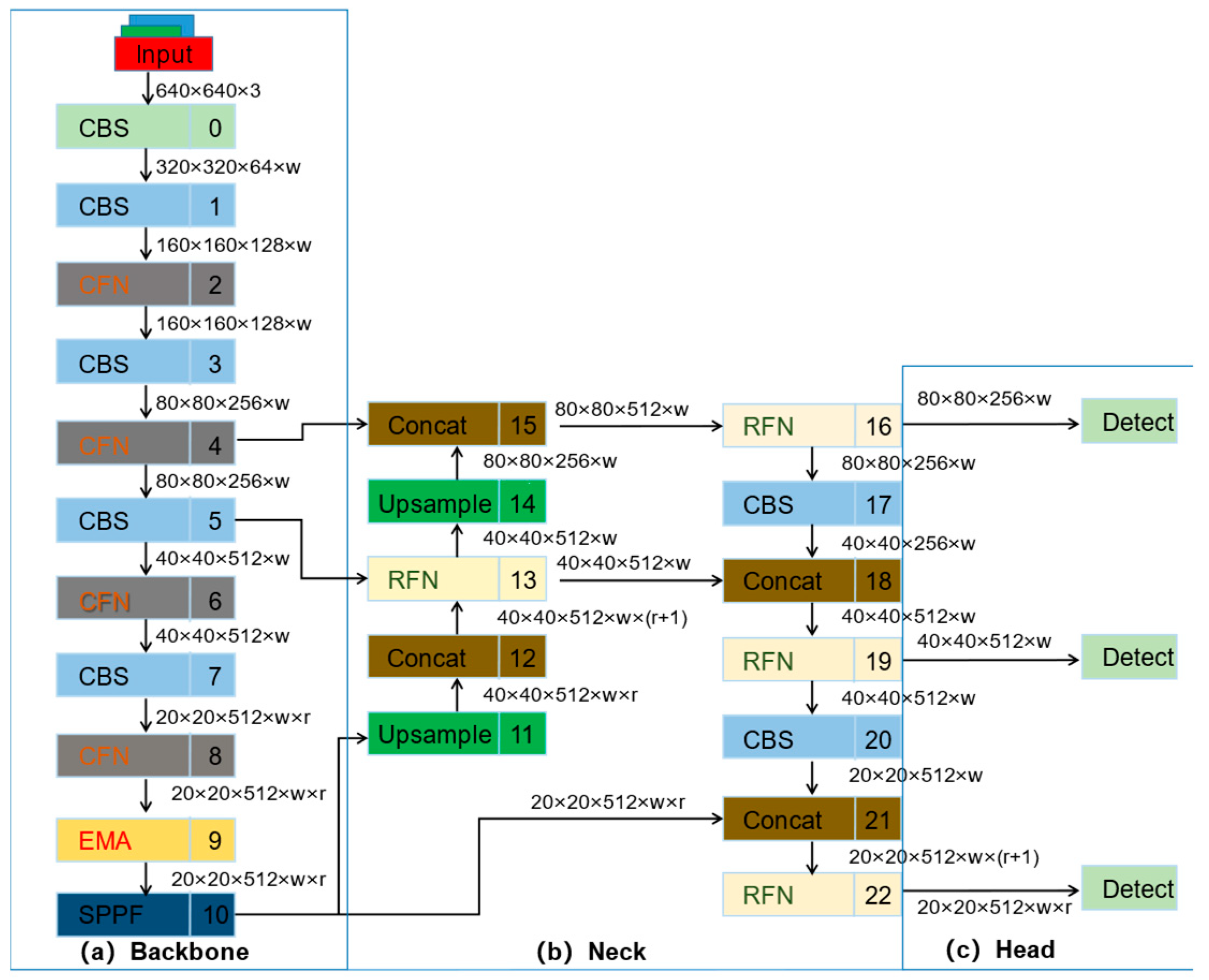
3.2. Improvement of YOLOv8s Network
3.2.1. Improvement of the Loss Function
3.2.2. Improvement of the Backbone
3.2.3. Improvement of the Neck
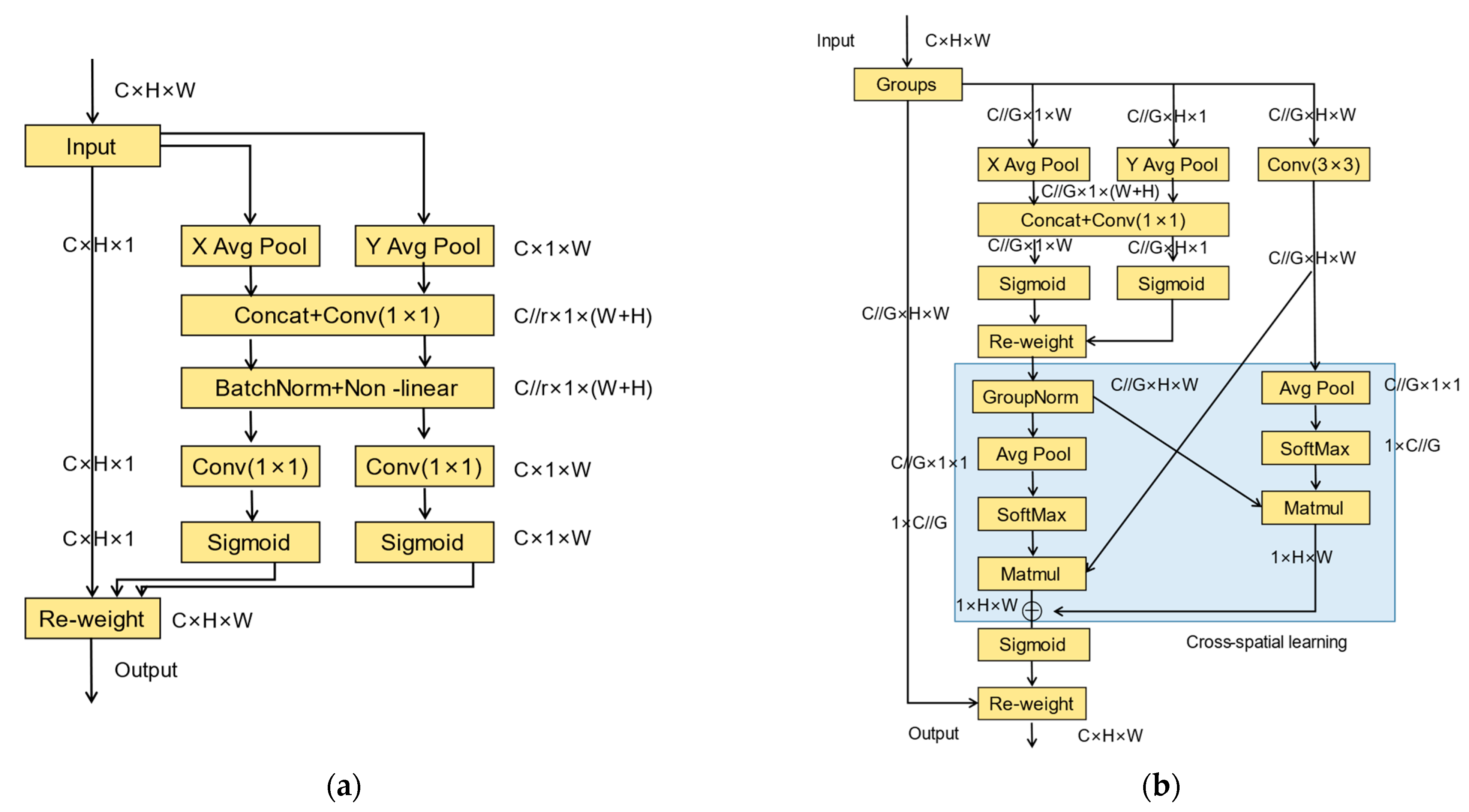
3.2.4. Integration of EMA
4. Experiments
4.1. Experimental Introduction
4.1.1. Experimental Setup
4.1.2. Evaluation Indicators
4.1.3. Dataset
4.1.4. Experimental Datum Processing
4.2. Comparisons with Related Methods
4.2.1. Comparisons with Prevailing Methods on NEU-DET
4.2.2. Comparisons with Prevailing Methods on GC10-DET
4.2.3. Experimental Comparison on Different Datasets
4.3. Ablation Experiments
4.3.1. The Performance of WIoU
4.3.2. The Performance of RFN
4.3.3. The Performance of CFN
4.3.4. The Performance of EMA Attention
4.4. Comprehensive Performance of the Proposed Model
4.5. Discussion
4.5.1. Findings
4.5.2. Limitations and Future Works
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Di, H.; Ke, X.; Peng, Z.; Dongdong, Z. Surface defect classification of steels with a new semi-supervised learning method. Opt. Lasers Eng. 2019, 117, 40–48. [Google Scholar] [CrossRef]
- Lee, S.Y.; Tama, B.A.; Moon, S.J.; Lee, S. Steel surface defect diagnostics using deep convolutional neural network and class activation map. Appl. Sci. 2019, 9, 5449. [Google Scholar] [CrossRef]
- Xu, Y.; Li, D.; Xie, Q.; Wu, Q.; Wang, J. Automatic defect detection and segmentation of tunnel surface using modified Mask R-CNN. Measurement 2021, 178, 109316. [Google Scholar] [CrossRef]
- Zhou, A.; Zheng, H.; Li, M.; Shao, W. Defect Inspection Algorithm of Metal Surface Based on Machine Vision. In Proceedings of the 2020 12th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Phuket, Thailand, 28–29 February 2020; pp. 45–49. [Google Scholar]
- Tang, J.; Liu, S.; Zhao, D.; Tang, L.; Zou, W.; Zheng, B. PCB-YOLO: An Improved Detection Algorithm of PCB Surface Defects Based on YOLOv5. Sustainability 2023, 15, 5963. [Google Scholar] [CrossRef]
- Liao, X.; Lv, S.; Li, D.; Luo, Y.; Zhu, Z.; Jiang, C. Yolov4-mn3 for pcb surface defect detection. Appl. Sci. 2021, 11, 11701. [Google Scholar] [CrossRef]
- Liu, Z.; Qu, B. Machine vision based online detection of PCB defect. Microprocess. Microsyst. 2021, 82, 103807. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, J.; Zhu, L.; Zhang, K.; Liu, T.; Wang, D.; Wang, X. An improved MobileNet-SSD algorithm for automatic defect detection on vehicle body paint. Multimed. Tools Appl. 2020, 79, 23367–23385. [Google Scholar] [CrossRef]
- Kieselbach, K.K.; Nöthen, M.; Heuer, H. Development of a visual inspection system and the corresponding algorithm for the detection and subsequent classification of paint defects on car bodies in the automotive industry. J. Coat. Technol. Res. 2019, 16, 1033–1042. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. Stoken Yolov5. Available online: https://github.com/ultralytics/yolov5/releases/tag/v6.0 (accessed on 26 October 2022).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards Real-time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection Via Region-Based Fully Convolutional Networks. Adv. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar]
- Pernkopf, F. Detection of surface defects on raw steel blocks using Bayesian network classifiers. Pattern Anal. Appl. 2004, 7, 333–342. [Google Scholar] [CrossRef]
- Yun, J.P.; Choi, S.; Kim, S.W. Vision-based defect detection of scale-covered steel billet surfaces. Opt. Eng. 2009, 48, 037205. [Google Scholar] [CrossRef]
- Song, K.; Hu, S.; Yan, Y.; Li, J. Surface Defect Detection Method Using Saliency Linear Scanning Morphology for Silicon Steel Strip under Oil Pollution Interference. ISIJ Int. 2014, 54, 2598–2607. [Google Scholar] [CrossRef]
- Tian, S.; Xu, K. An algorithm for surface defect identification of steel plates based on genetic algorithm and extreme learning machine. Metals 2017, 7, 311. [Google Scholar] [CrossRef]
- Wang, Y.; Xia, H.; Yuan, X.; Li, L.; Sun, B. Distributed defect recognition on steel surfaces using an improved random forest algorithm with optimal multi-feature-set fusion. Multimed. Tools Appl. 2018, 77, 16741–16770. [Google Scholar] [CrossRef]
- Gong, R.; Wu, C.; Chu, M. Steel surface defect classification using multiple hyper-spheres support vector machine with additional information. Chemom. Intell. Lab. Syst. 2018, 172, 109–117. [Google Scholar] [CrossRef]
- Chu, M.; Liu, X.; Gong, R.; Liu, L. Multi-class classification method using twin support vector machines with multi-information for steel surface defects. Chemom. Intell. Lab. Syst. 2018, 176, 108–118. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, H.; Tian, Y.; Liu, K. An accurate fuzzy measure-based detection method for various types of defects on strip-steel surfaces. Comput. Ind. 2020, 122, 103231. [Google Scholar] [CrossRef]
- Ji, Y.; Liu, S.; Zhou, M.; Zhao, Z.; Guo, X.; Qi, L. A machine learning and genetic algorithm-based method for predicting width deviation of hot-rolled strip in steel production systems. Inf. Sci. 2022, 589, 360–375. [Google Scholar] [CrossRef]
- Bulnes, F.G.; Garcia, D.F.; Javier De la Calle, F.; Usamentiaga, R.; Molleda, J. A non-invasive technique for online defect detection on steel strip surfaces. J. Nondestruct. Eval. 2016, 35, 1–18. [Google Scholar] [CrossRef]
- Guan, S.; Lei, M.; Lu, H. A steel surface defect recognition algorithm based on improved deep learning network model using feature visualization and quality evaluation. IEEE Access 2020, 8, 49885–49895. [Google Scholar] [CrossRef]
- Xiao, L.; Wu, B.; Hu, Y. Surface defect detection using image pyramid. IEEE Sens. J. 2020, 20, 7181–7188. [Google Scholar] [CrossRef]
- Zhao, W.; Chen, F.; Huang, H.; Li, D.; Cheng, W. A new steel defect detection algorithm based on deep learning. Comput. Intell. Neurosci. 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Zhao, C.; Shu, X.; Yan, X.; Zuo, X.; Zhu, F. RDD-YOLO: A modified YOLO for detection of steel surface defects. Measurement 2023, 214, 112776. [Google Scholar] [CrossRef]
- Wang, L.; Liu, X.; Ma, J.; Su, W.; Li, H. Real-Time Steel Surface Defect Detection with Improved Multi-Scale YOLO-v5. Processes 2023, 11, 1357. [Google Scholar] [CrossRef]
- Li, M.; Wang, H.; Wan, Z. Surface defect detection of steel strips based on improved YOLOv4. Comput. Electr. Eng. 2022, 102, 108208. [Google Scholar] [CrossRef]
- Liu, G.H.; Chu, M.X.; Gong, R.F.; Zheng, Z.H. DLF-YOLOF: An improved YOLOF-based surface defect detection for steel plate. J. Iron Steel Res. Int. 2023, 1–10. [Google Scholar] [CrossRef]
- Wang, R.-J.; Liang, F.-L.; Mou, X.-W.; Chen, L.-T.; Yu, X.-Y.; Peng, Z.-J.; Chen, H.-Y. Development of an Improved YOLOv7-Based Model for Detecting Defects on Strip Steel Surfaces. Coatings 2023, 13, 536. [Google Scholar] [CrossRef]
- Shao, Y.; Fan, S.; Sun, H.; Tan, Z.; Cai, Y.; Zhang, C.; Zhang, L. Multi-Scale Lightweight Neural Network for Steel Surface Defect Detection. Coatings 2023, 13, 1202. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. arXiv 2020, arXiv:2006.04388. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Chen, J.; Kao, S.-H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t walk: Chasing higher FLOPs for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. DAMO-YOLO: A Report on Real-Time Object Detection Design. arXiv 2022, arXiv:2211.15444. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, New York, NY, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-maximization attention networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9167–9176. [Google Scholar]
- Available online: http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list/index.html (accessed on 12 December 2022).
- Lv, X.; Duan, F.; Jiang, J.-J.; Fu, X.; Gan, L. Deep Metallic Surface Defect Detection: The New Benchmark and Detection Network. Sensors 2020, 20, 1562. [Google Scholar] [CrossRef]
- Available online: https://tianchi.aliyun.com/competition/entrance/231682/information (accessed on 15 August 2018).
- Huang, W.; Wei, P. A PCB Dataset for Defects Detection and Classification. arXiv 2019, arXiv:1901.08204. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Size (Pixels) | mAP (0.5:0.95) | Parameters (M) | FLOPs (G) | Speed (ms) |
|---|---|---|---|---|---|
| YOLOv8n | 640 × 640 | 37.3 | 3.2 | 8.7 | 0.99 |
| YOLOv8s | 640 × 640 | 44.9 | 11.2 | 11.2 | 1.20 |
| YOLOv8m | 640 × 640 | 50.2 | 25.9 | 25.9 | 1.83 |
| YOLOv8L | 640 × 640 | 52.9 | 43.7 | 43.7 | 2.39 |
| YOLOv8x | 640 × 640 | 53.9 | 68.2 | 68.2 | 3.53 |
| Model | mAP (0.5) | mAP (0.5:0.95) | Recall | Precision | Parameters | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv3s | 51.9% | 21.8% | 45.4% | 49.5% | 9322387 | 23.4 |
| YOLOv4 | 69.4% | 33.8% | 79.3% | 53.1% | 63964611 | 142 |
| YOLOV5s | 69.5% | 34.8% | 72.7% | 60.8% | 7026307 | 15.8 |
| YOLOv7 | 73.7% | 34.4% | 68.6% | 66.3% | 37223526 | 105.2 |
| YOLOv8s (baseline) | 74.7% | 39.4% | 69.0% | 69.1% | 11127906 | 28.4 |
| YOLOv8m | 76.7% | 41.1% | 69.2% | 74.5% | 25843234 | 78.7 |
| YOLOv8L | 78.2% | 41.1% | 71.0% | 75.8% | 43611234 | 164.8 |
| WFRE-YOLOv8s (ours) | 79.4% | 42.5% | 75.9% | 73.6% | 13775472 | 32.6 |
| Model | mAP (0.5) | mAP (0.5:0.95) | Recall | Precision | Parameters | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv3s | 55.0% | 27.3% | 58.0% | 51.4%% | 9333175 | 23.4 |
| YOLOv4 | 60.5% | 30.4% | 68.0% | 46.1% | 8081831 | 20.6 |
| YOLOv5s | 63.3% | 33.0% | 54.7% | 69.2% | 7037095 | 15.8 |
| YOLOv7 | 64.2% | 32.1% | 57.8% | 69.3% | 37245102 | 105.3 |
| YOLOv8s (baseline) | 65.6% | 34.9% | 61.6% | 29.9% | 11129454 | 28.5 |
| YOLOv8m | 67.0% | 35.0% | 55.5% | 81.0% | 25845550 | 78.7 |
| YOLOv8L | 68.6% | 36.5% | 73.0% | 60.7% | 43637550 | 165.48 |
| WFRE-YOLOv8s (ours) | 69.4% | 35.7% | 62.6% | 64.8% | 13775472 | 32.6 |
| Model | Model | mAP (0.5) | mAP (0.5:0.95) |
|---|---|---|---|
| NEU-DET | YOLOv8s | 74.7% | 39.4% |
| WFRE-YOLOv8s | 79.4% | 42.5% | |
| GC10-DET | YOLOv8s | 65.6% | 34.9% |
| WFRE-YOLOv8s | 69.4% | 35.7% | |
| Lv-DET | YOLOv8s | 56.4% | 34.5% |
| WFRE-YOLOv8s | 59.2% | 35.4% | |
| PCB | YOLOv8s | 82.0% | 42.7% |
| WFRE-YOLOv8s | 85.3% | 44.0% |
| Model | mAP (0.5) | mAP (0.5:0.95) | Recall | Precision | Parameters | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv8s | 74.7% | 39.4% | 69.0% | 69.1% | 11127906 | 28.4 |
| W-YOLOv8s | 75.6% | 40.6% | 70.7% | 69.8% | 11127906 | 28.4 |
| WF-YOLOV8s | 76.6% | 41.2% | 71.4% | 71.1% | 9434466 | 23.5 |
| WFR-YOLOv8s | 78.1% | 41.8% | 72.8% | 73.2% | 13644386 | 32.2 |
| WFRE-YOLOv8s | 79.4% | 42.5% | 75.9% | 73.6% | 13775472 | 32.6 |
| Model | mAP (0.5) | Crazing | Inclusion | Patches | Pitted Surface | Rolled-in Scale | Scratches |
|---|---|---|---|---|---|---|---|
| YOLOv8s (baseline) | 74.7% | 43.6% | 82.2% | 94.0% | 78.1% | 66.8% | 83.3% |
| WFRE-YOLOv8s (ours) | 79.4% | 60.0% | 81.4% | 93.8% | 82.5% | 73.8% | 84.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Tan, W.; Li, L.; Wu, L. WFRE-YOLOv8s: A New Type of Defect Detector for Steel Surfaces. Coatings 2023, 13, 2011. https://doi.org/10.3390/coatings13122011
Huang Y, Tan W, Li L, Wu L. WFRE-YOLOv8s: A New Type of Defect Detector for Steel Surfaces. Coatings. 2023; 13(12):2011. https://doi.org/10.3390/coatings13122011
Chicago/Turabian StyleHuang, Yao, Wenzhu Tan, Liu Li, and Lijuan Wu. 2023. "WFRE-YOLOv8s: A New Type of Defect Detector for Steel Surfaces" Coatings 13, no. 12: 2011. https://doi.org/10.3390/coatings13122011