
Low-Resolution Steel Surface Defects Classification Network Based on Autocorrelation Semantic Enhancement

Abstract
:1. Introduction
- This paper proposes a new autocorrelation semantic enhancement method (ASE), which enhances the base features and extracts important local area features through CS attention and autocorrelation modules.
- By combining the backbone network and the autocorrelation semantic enhancement module, our model ASENet can solve the problems of information loss, feature ambiguity, and confusion that traditional neural network models would have when dealing with low-resolution steel defect images.
- Significant classification accuracies are achieved on the NEU-CLS-64 and CIFAR-100 datasets, and comparisons with several benchmark models demonstrate the effectiveness and superiority of the method.
2. Related Work
2.1. Classification of Steel Defects
2.2. Attention Mechanism
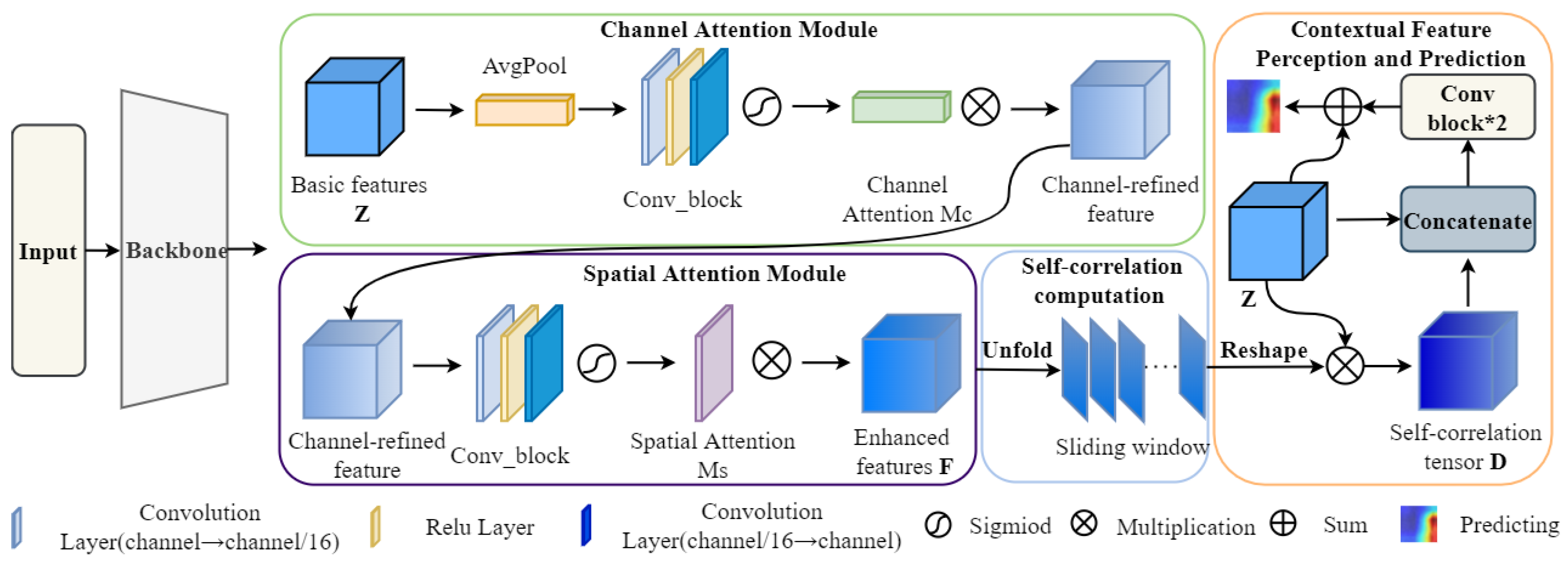
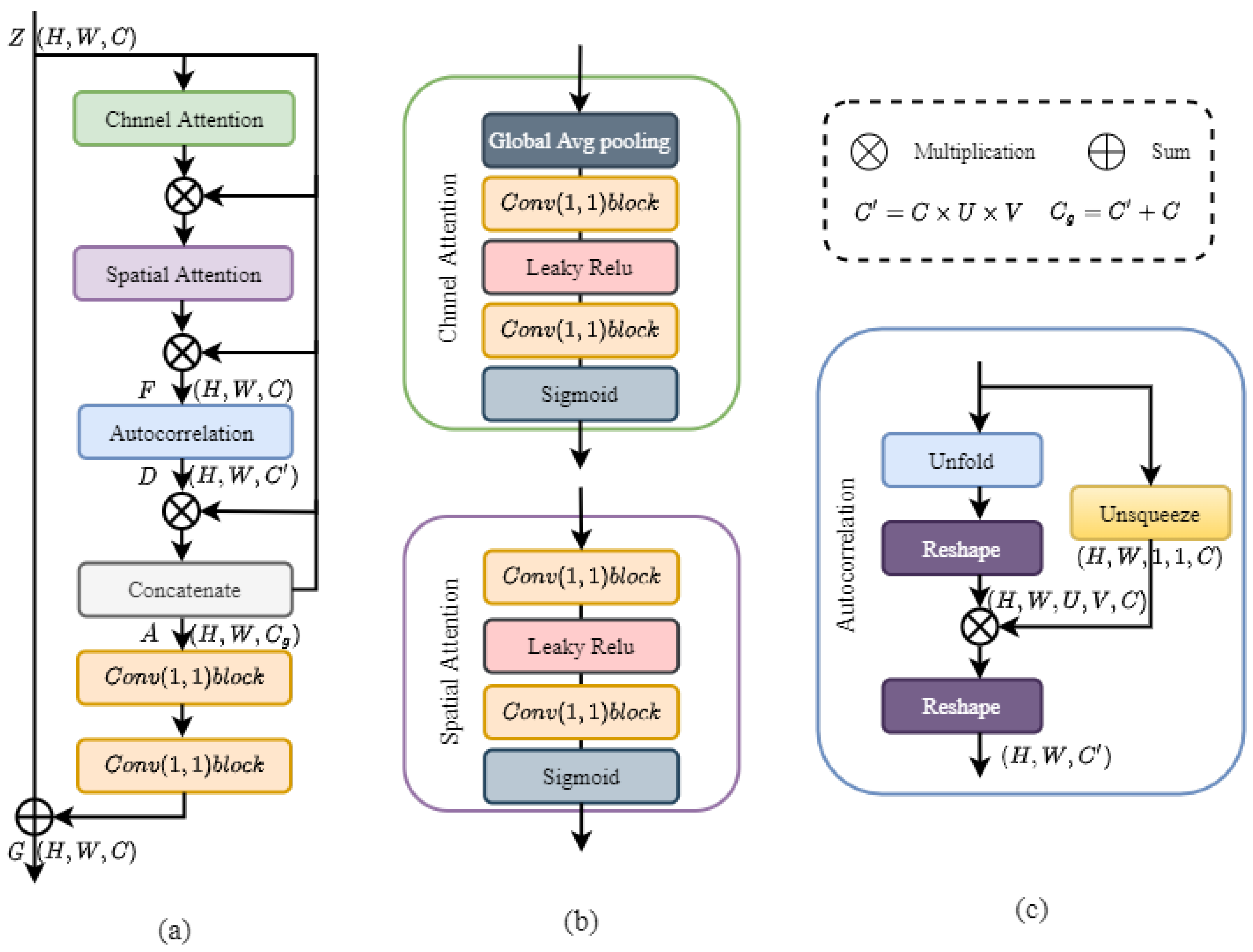
3. Our Approach
3.1. Overall Architecture
3.2. CS Attention Module
3.3. Autocorrelation Computation Calculation
3.4. Contextual Feature Perception
4. Experimental Results
4.1. Dataset
4.2. Experimental Details
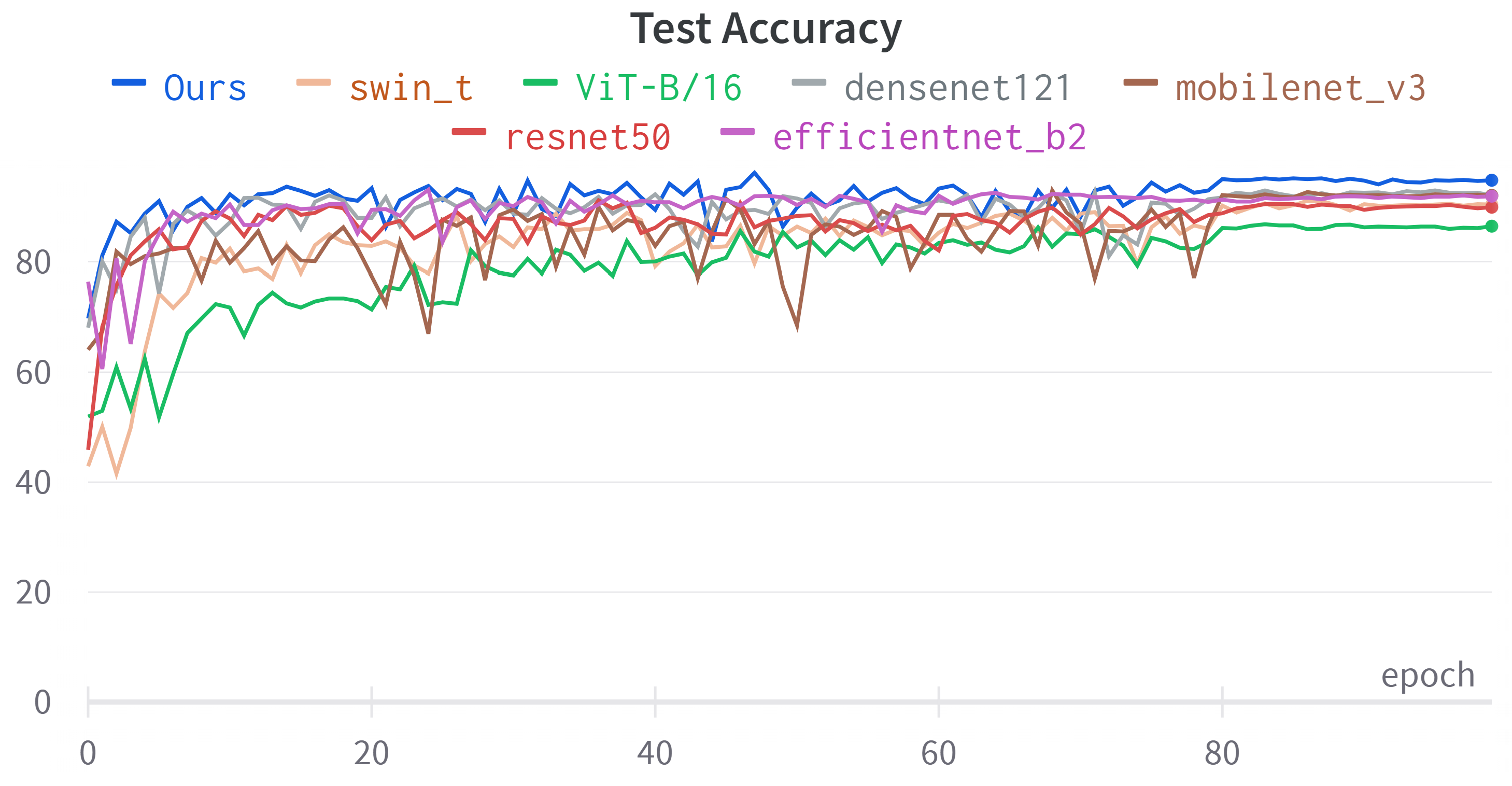
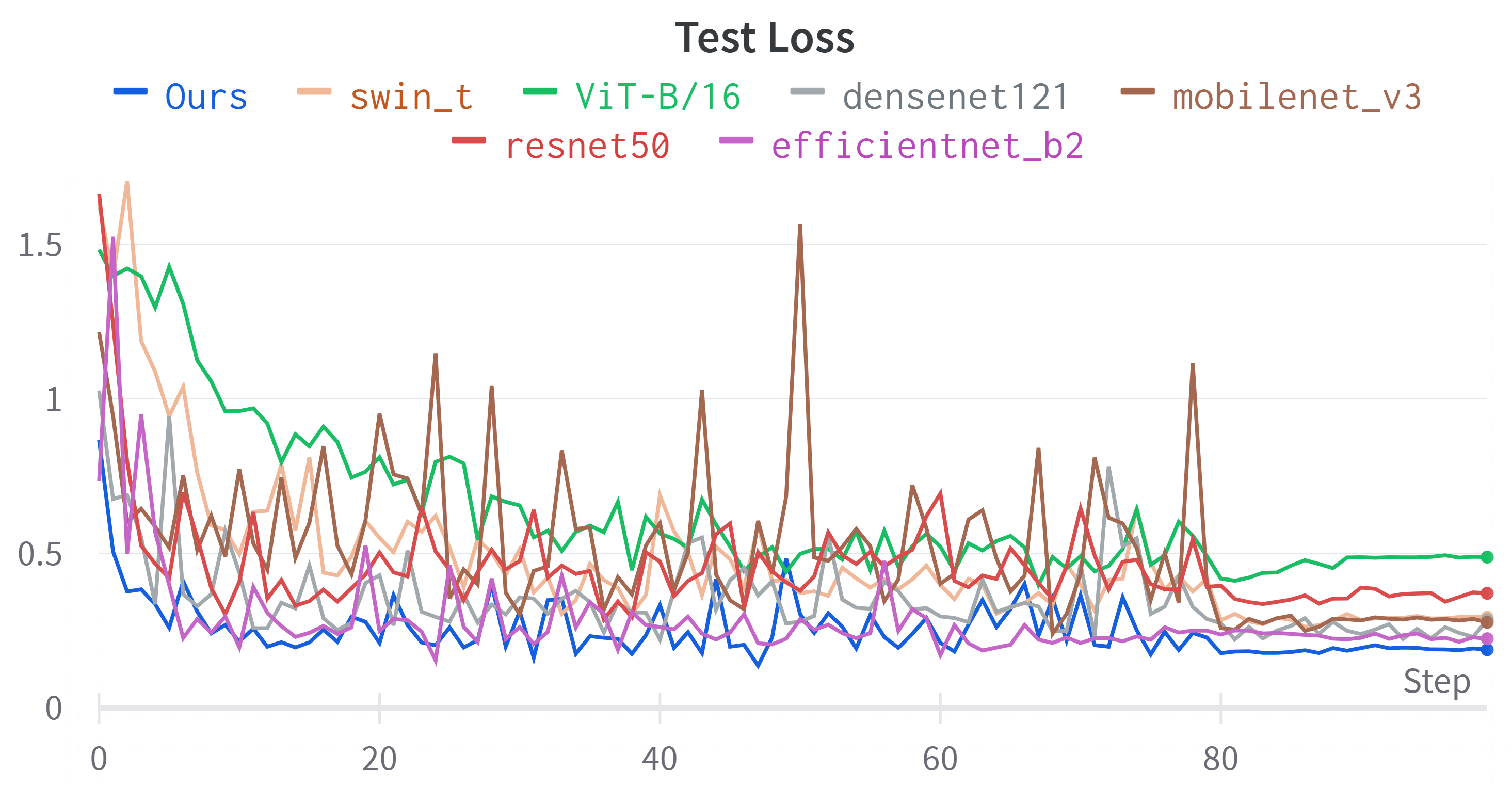
4.3. Results
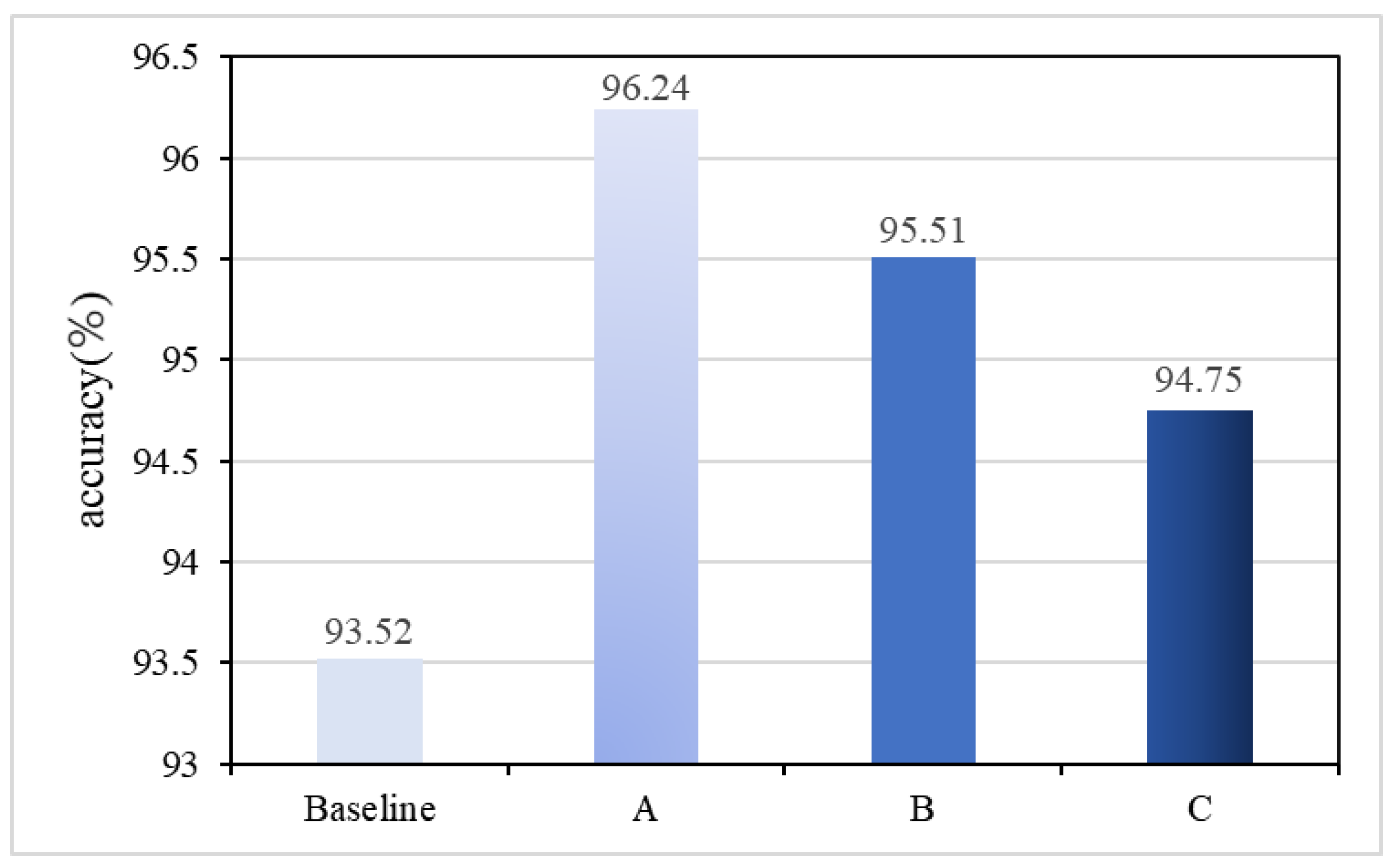
4.4. Ablation Studies
4.5. Comparison with Other Attention Modules
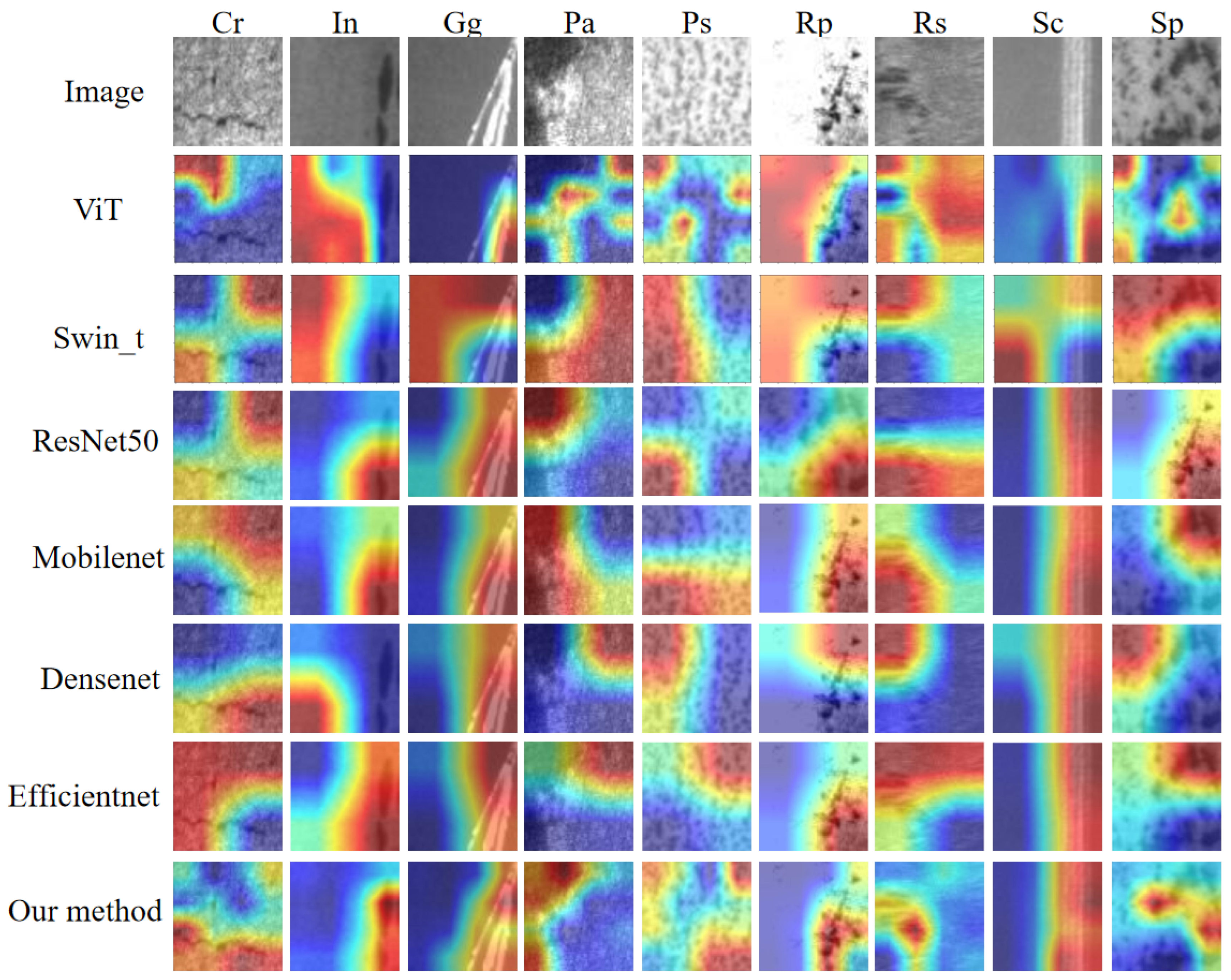
4.6. Visualisation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gardner, L. The use of stainless steel in structures. Prog. Struct. Eng. Mater. 2010, 7, 45–55. [Google Scholar] [CrossRef]
- Wen, X.; Shan, J.; He, Y.; Song, K. Steel surface defect recognition: A survey. Coatings 2022, 13, 17. [Google Scholar] [CrossRef]
- Chu, M.; Zhao, J.; Liu, X.; Gong, R. Multi-class classification for steel surface defects based on machine learning with quantile hyper-spheres. Chemom. Intell. Lab. Syst. 2017, 168, 15–27. [Google Scholar] [CrossRef]
- Park, J.K.; Kwon, B.K.; Park, J.H.; Kang, D.J. Machine learning-based imaging system for surface defect inspection. Int. J. Precis. Eng.-Manuf.-Green Technol. 2016, 3, 303–310. [Google Scholar] [CrossRef]
- Tang, B.; Chen, L.; Sun, W.; Lin, Z.k. Review of surface defect detection of steel products based on machine vision. IET Image Process. 2023, 17, 303–322. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 8–22 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar] [CrossRef]
- Song, K.; Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar] [CrossRef]
- Zhang, S.; Karim, M. A new impulse detector for switching median filters. IEEE Signal Process. Lett. 2002, 9, 360–363. [Google Scholar] [CrossRef]
- Wu, X.y.; Xu, K.; Xu, J.w. Application of Undecimated Wavelet Transform to Surface Defect Detection of Hot Rolled Steel Plates. In Proceedings of the 2008 Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; Volume 4, pp. 528–532. [Google Scholar] [CrossRef]
- Senthikumar, M.; Palanisamy, V.; Jaya, J. Metal surface defect detection using iterative thresholding technique. In Proceedings of the Second International Conference on Current Trends In Engineering and Technology—ICCTET 2014, Coimbatore, India, 8 July 2014; pp. 561–564. [Google Scholar] [CrossRef]
- Yun, J.P.; Kim, D.; Kim, K.; Lee, S.J.; Park, C.H.; Kim, S.W. Vision-based surface defect inspection for thick steel plates. Opt. Eng. 2017, 56, 053108. [Google Scholar] [CrossRef]
- Aghdam, S.R.; Amid, E.; Imani, M.F. A fast method of steel surface defect detection using decision trees applied to LBP based features. In Proceedings of the 2012 7th IEEE Conference on Industrial Electronics and Applications (ICIEA), Singapore, 18–20 July 2012; pp. 1447–1452. [Google Scholar] [CrossRef]
- Jian, L.; Wei, H.; Bin, H. Research on inspection and classification of leather surface defects based on neural network and decision tree. In Proceedings of the 2010 International Conference On Computer Design and Applications, Qinhuangdao, China, 25–27 June 2010; Volume 2, pp. V2-381–V2-384. [Google Scholar] [CrossRef]
- Mukhopadhyay, S.; Chanda, B. Multiscale morphological segmentation of gray-scale images. IEEE Trans. Image Process. 2003, 12, 533–549. [Google Scholar] [CrossRef] [PubMed]
- Podulka, P. Application of image processing methods for the characterization of selected features and wear analysis in surface topography measurements. Procedia Manuf. 2021, 53, 136–147. [Google Scholar] [CrossRef]
- Ravimal, D.; Kim, H.; Koh, D.; Hong, J.H.; Lee, S.K. Image-based inspection technique of a machined metal surface for an unmanned lapping process. Int. J. Precis. Eng. Manuf. Green Technol. 2020, 7, 547–557. [Google Scholar] [CrossRef]
- Li, Z.; Wu, C.; Han, Q.; Hou, M.; Chen, G.; Weng, T. CASI-Net: A novel and effect steel surface defect classification method based on coordinate attention and self-interaction mechanism. Mathematics 2022, 10, 963. [Google Scholar] [CrossRef]
- Hao, Z.; Li, Z.; Ren, F.; Lv, S.; Ni, H. Strip steel surface defects classification based on generative adversarial network and attention mechanism. Metals 2022, 12, 311. [Google Scholar] [CrossRef]
- Zhang, J.; Li, S.; Yan, Y.; Ni, Z.; Ni, H. Surface Defect Classification of Steel Strip with Few Samples Based on Dual-Stream Neural Network. Steel Res. Int. 2022, 93, 2100554. [Google Scholar] [CrossRef]
- Li, S.; Wu, C.; Xiong, N. Hybrid architecture based on CNN and transformer for strip steel surface defect classification. Electronics 2022, 11, 1200. [Google Scholar] [CrossRef]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Hu, D. An introductory survey on attention mechanisms in NLP problems. In Proceedings of the Intelligent Systems and Applications: Proceedings of the 2019 Intelligent Systems Conference (IntelliSys), London, UK, 3–4 September 2020; Volume 2, pp. 432–448. [Google Scholar] [CrossRef]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10705–10714. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Rocco, I.; Cimpoi, M.; Arandjelović, R.; Torii, A.; Pajdla, T.; Sivic, J. Neighbourhood consensus networks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Hassani, A.; Walton, S.; Li, J.; Li, S.; Shi, H. Neighborhood attention transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6185–6194. [Google Scholar] [CrossRef]
- Kang, D.; Kwon, H.; Min, J.; Cho, M. Relational embedding for few-shot classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 8822–8833. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual Conference, 5–9 January 2021; pp. 3139–3148. [Google Scholar] [CrossRef]
- Zhang, Q.L.; Yang, Y.B. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar] [CrossRef]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar] [CrossRef]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Mehta, S.; Rastegari, M. Separable self-attention for mobile vision transformers. arXiv 2022, arXiv:2206.02680. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NEU-CLS-64 | CIFAR-100 | Params Size (M) | FLOPs (G) |
|---|---|---|---|---|
| ViT-B/16 [36] | 86.81 | 56.19 | 326.74 MB | 93.09 GFLOPs |
| Swin_t [37] | 91.09 | 58.24 | 71.94 MB | 47.33 GFLOPs |
| ResNet50 [38] | 91.37 | 61.08 | 89.75 MB | 21.59 GFLOPs |
| Mobilenet_v3_small [39] | 92.90 | 59.44 | 5.83 MB | 0.38 GFLOPs |
| Densenet121 [40] | 92.96 | 66.30 | 31.01 MB | 15.13 GFLOPs |
| Efficientnet_b2 [41] | 93.23 | 60.32 | 34.75 MB | 3.74 GFLOPs |
| ASENet (Ours) | 96.24 | 71.66 | 3.04 MB | 17.61 GFLOPs |
| Id | CS Attention | Autocorrelation Computation | Contextual Feature | Accuracy (%) |
|---|---|---|---|---|
| (a) | × | × | × | 93.52 |
| (b) | × | ✓ | ✓ | 95.30 |
| (c) | ✓ | × | ✓ | 95.47 |
| (d) | ✓ | ✓ | × | 95.68 |
| (e) | ✓ | ✓ | ✓ | 96.24 |
| Method | Accuracy (%) | Params Size (M) | FLOPs (G) |
|---|---|---|---|
| Baseline | 93.52 | 0 MB | 0 GFLOPs |
| TripletAttention [42] | 95.03 | 0.06 MB | 0.14 GFLOPs |
| ShuffleAttention [43] | 95.37 | 0.05 MB | 0.01 GFLOPs |
| PSA [44] | 95.44 | 0.78 MB | 10.10 GFLOPs |
| CoTAttention [45] | 95.45 | 1.08 MB | 18.56 GFLOPs |
| MobileViTv2Attention [46] | 95.51 | 1.17 MB | 20.14 GFLOPs |
| Coord_attention [47] | 95.65 | 0.07 MB | 0.13 GFLOPs |
| SE [30] | 95.68 | 0.08 MB | 1.39 GFLOPs |
| CBAM [32] | 95.76 | 0.10 MB | 0.02 GFLOPs |
| ASE (Ours) | 96.24 | 1.27 MB | 1.32 GFLOPs |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Gong, K.; Lu, C. Low-Resolution Steel Surface Defects Classification Network Based on Autocorrelation Semantic Enhancement. Coatings 2023, 13, 2015. https://doi.org/10.3390/coatings13122015
Guo X, Gong K, Lu C. Low-Resolution Steel Surface Defects Classification Network Based on Autocorrelation Semantic Enhancement. Coatings. 2023; 13(12):2015. https://doi.org/10.3390/coatings13122015
Chicago/Turabian StyleGuo, Xiaoe, Ke Gong, and Chunyue Lu. 2023. "Low-Resolution Steel Surface Defects Classification Network Based on Autocorrelation Semantic Enhancement" Coatings 13, no. 12: 2015. https://doi.org/10.3390/coatings13122015