HCTNet: A Hybrid ConvNet-Transformer Network for Retinal Optical Coherence Tomography Image Classification


Abstract
:1. Introduction
2. Materials and Methods
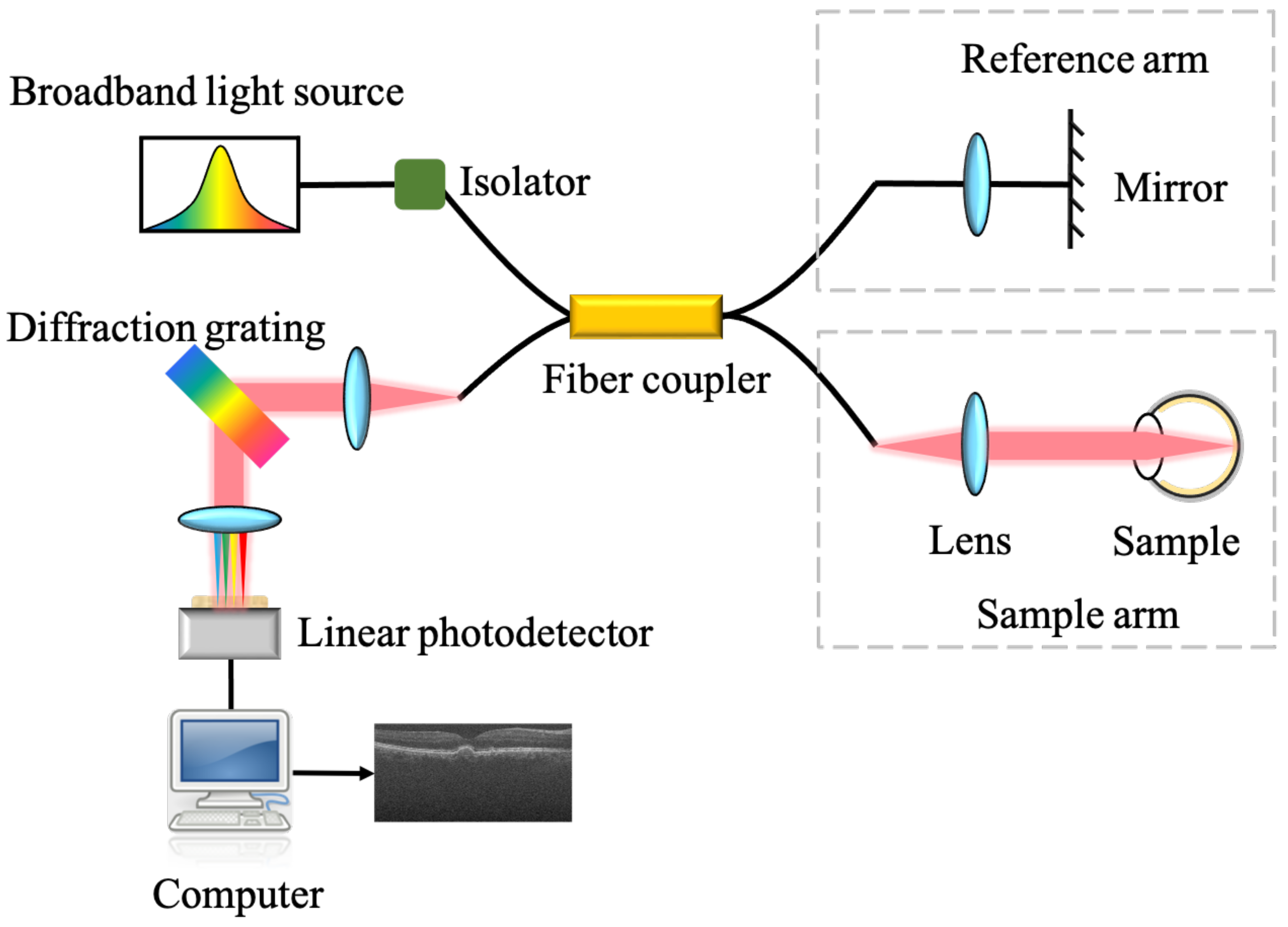
2.1. OCT Datasets
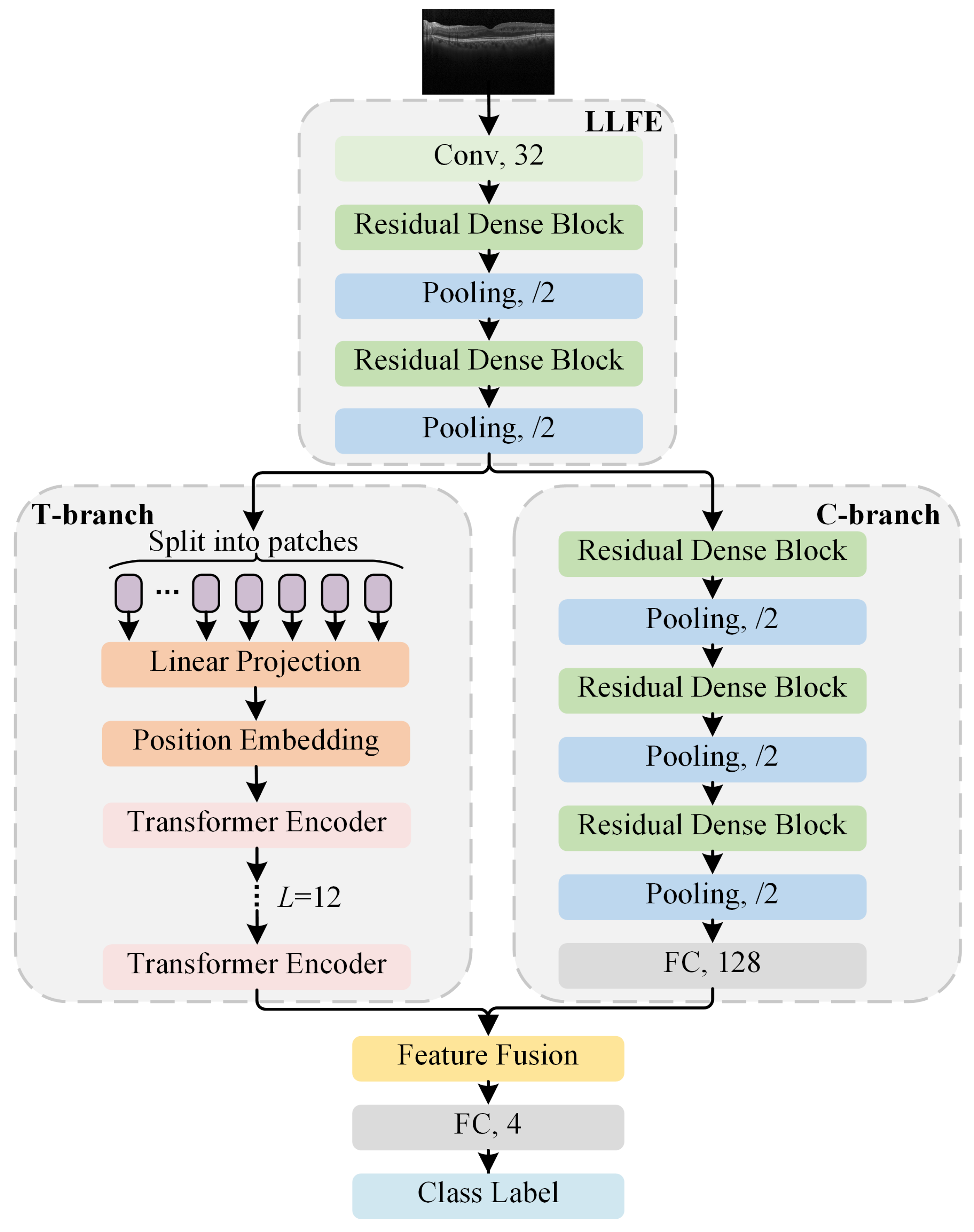
2.2. Proposed HCTNet Method
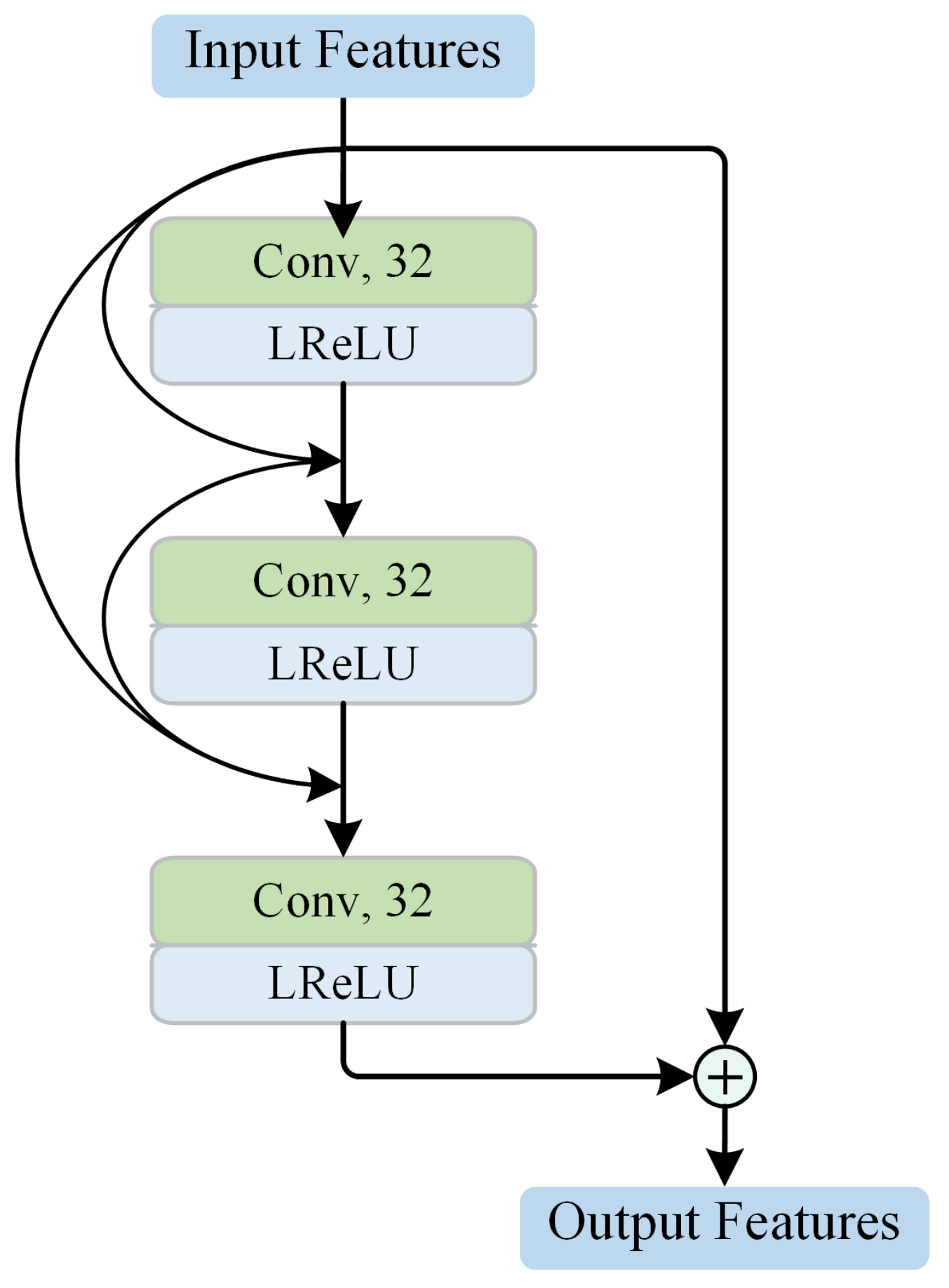
2.2.1. Residual-Dense-Block-Based Low-Level Feature Extraction
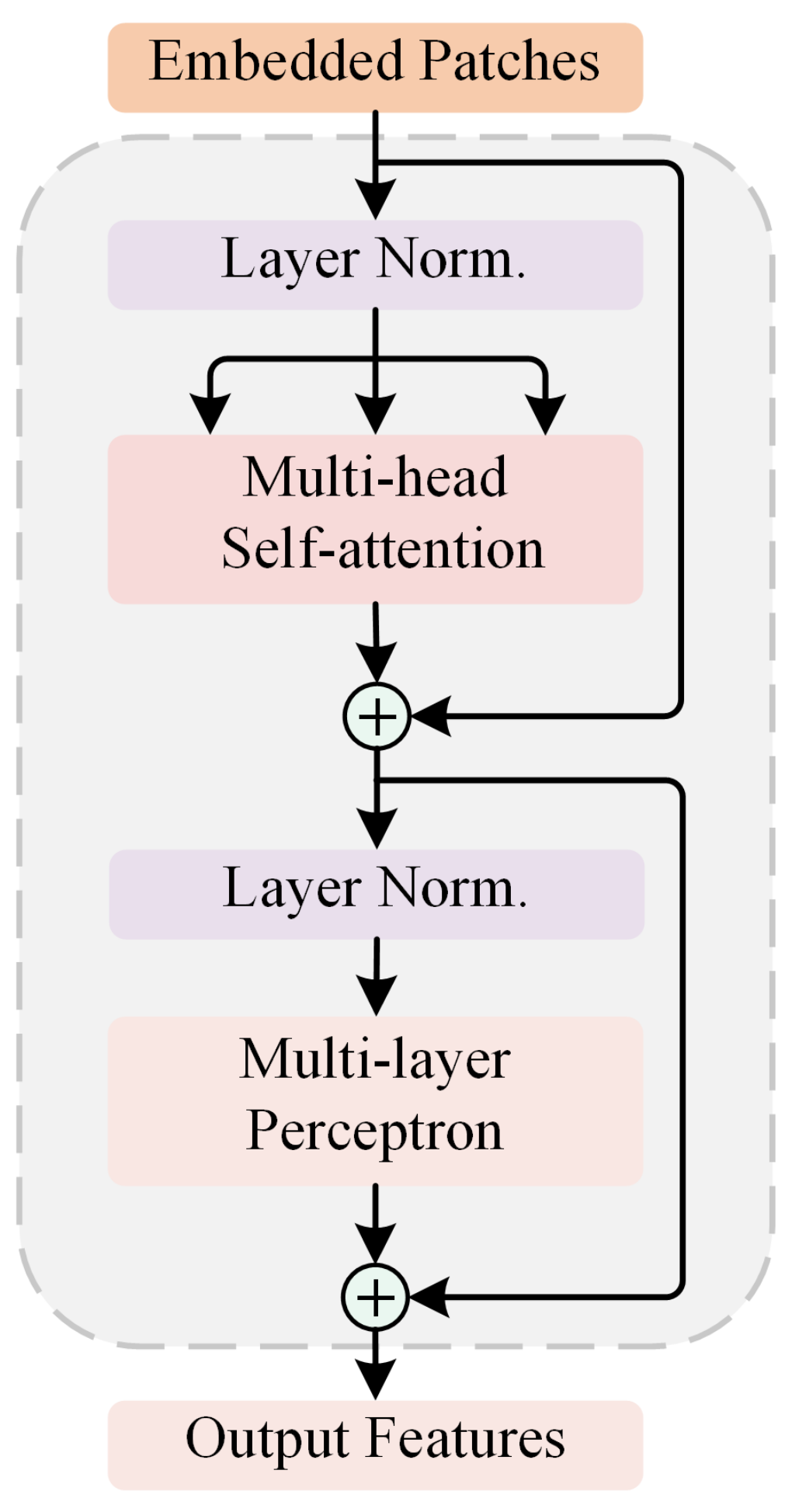
2.2.2. Transformer Branch for Global Sequence Analysis
2.2.3. ConvNet Branch for High-Level Local Feature Extraction
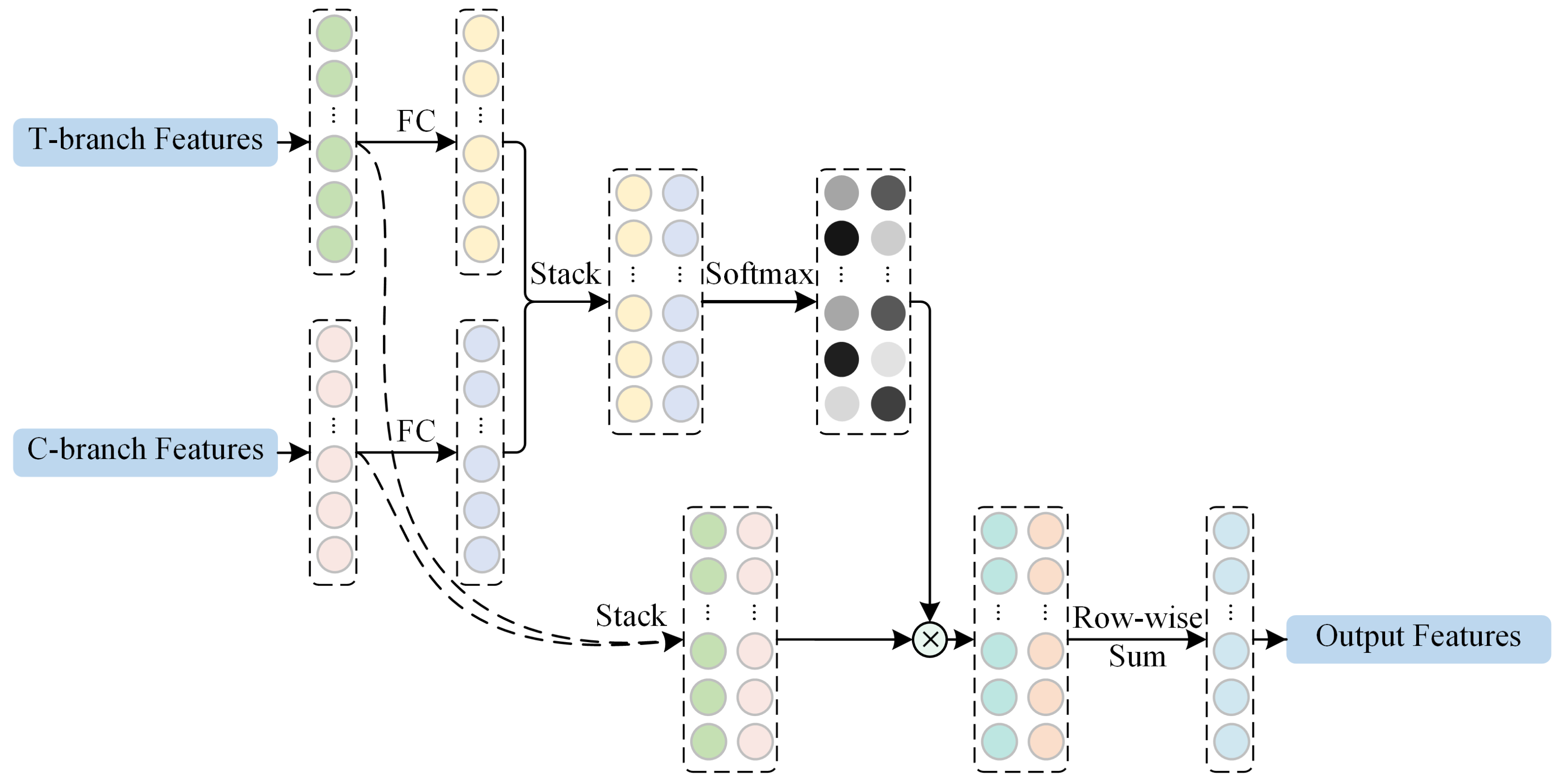
2.2.4. Adaptive Re-Weighting-Based Feature Fusion
2.3. Loss Function
2.4. Experimental Protocol
2.5. Evaluation Metrics
3. Results and Discussion
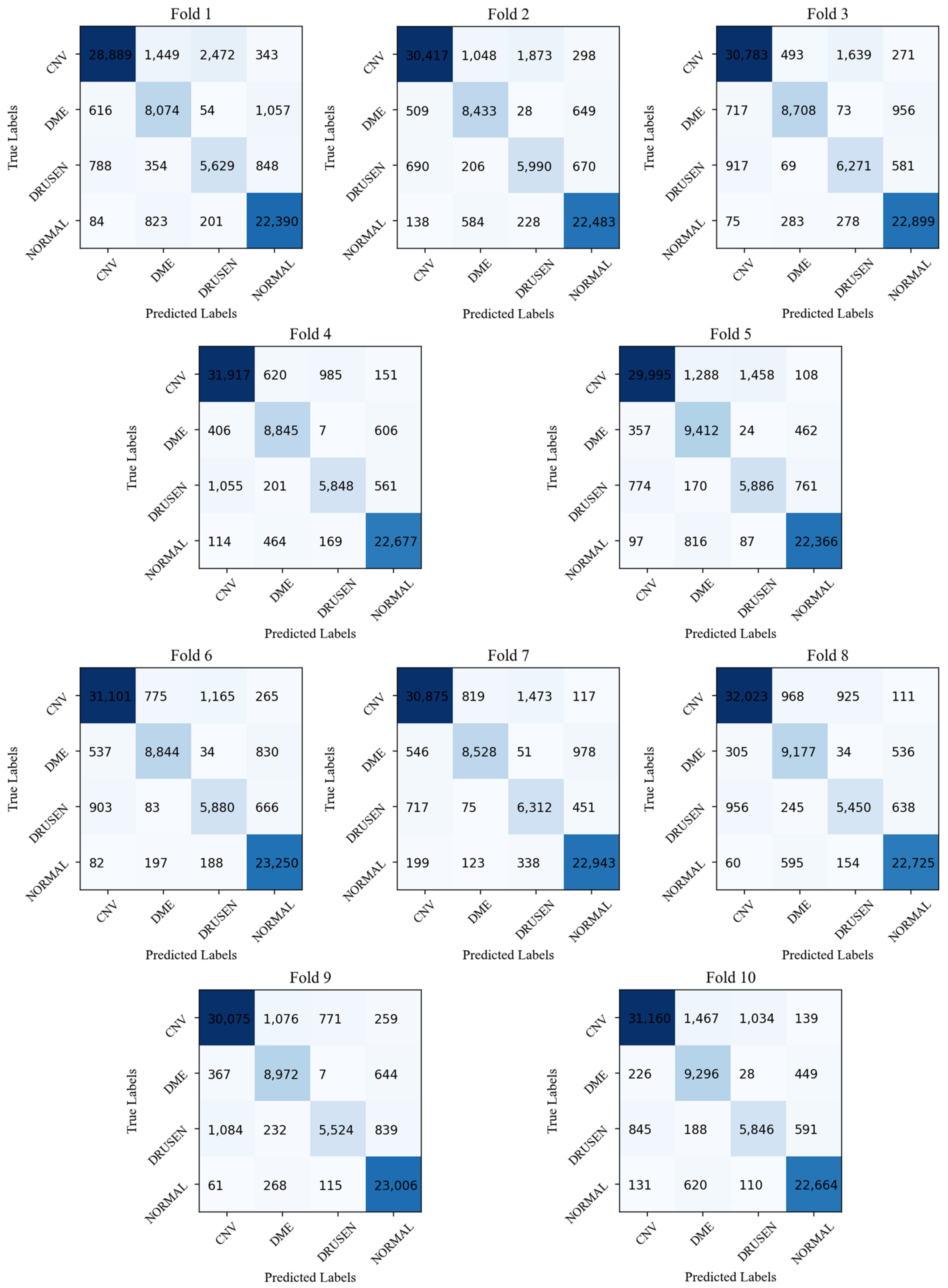
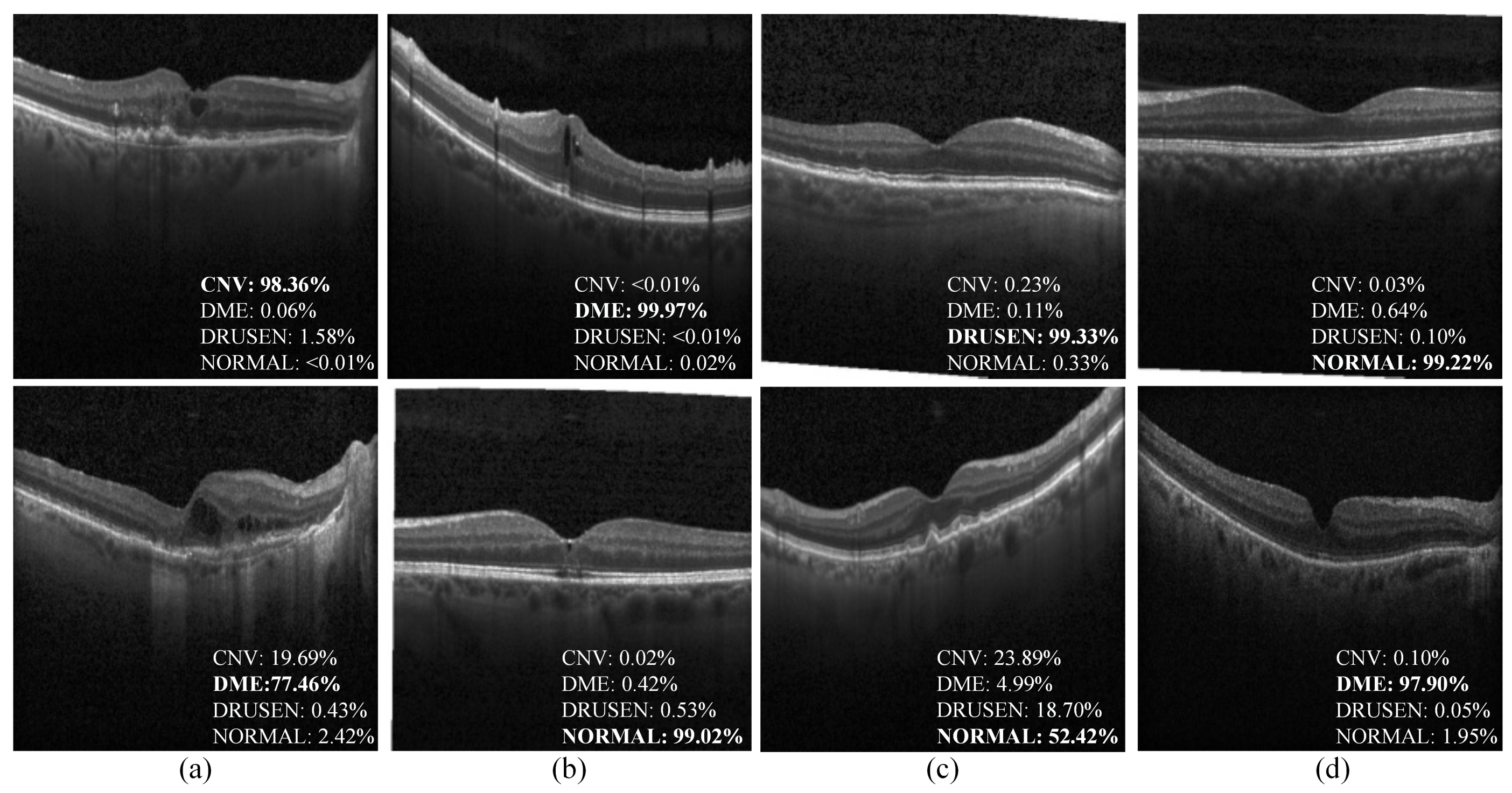
3.1. Validation of the Proposed HCTNet
3.2. Applicability to Srinivasan2014 Dataset
3.3. Robustness to Noise
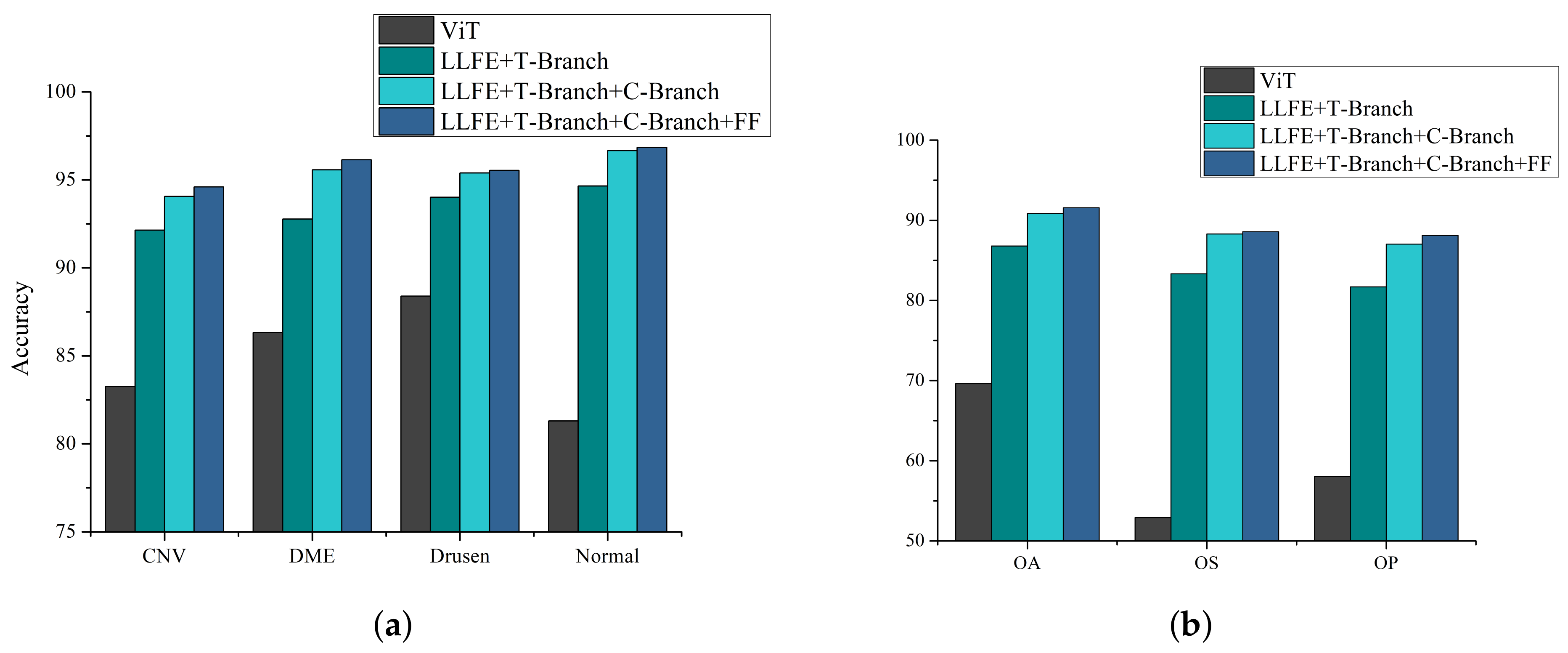
3.4. Ablation Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, Y.; Xiang, X.; Chen, T.; Mao, G.; Deng, L.; Zeng, L.; Zhang, J. In vivo monitoring the dynamic process of acute retinal hemorrhage and repair in zebrafish with spectral-domain optical coherence tomography. J. Biophotonics 2019, 12, e201900235. [Google Scholar] [CrossRef] [PubMed]
- Lim, L.S.; Mitchell, P.; Seddon, J.M.; Holz, F.G.; Wong, T.Y. Age-related macular degeneration. Lancet 2012, 379, 1728–1738. [Google Scholar] [CrossRef]
- Attebo, K.; Mitchell, P.; Cumming, R.; BMath, W.S. Knowledge and beliefs about common eye diseases. Aust. N. Z. J. Ophthalmol. 1997, 25, 283–287. [Google Scholar] [CrossRef]
- Yorston, D. Retinal diseases and vision 2020. Community Eye Health 2003, 16, 19–20. [Google Scholar]
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Gregory, K.; Puliafito, C.A.; et al. Optical coherence tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Drexler, W.; Fujimoto, J.G. (Eds.) Optical Coherence Tomography: Technology and Applications; Springer: Berlin/Heidelberg, Germany, 2015; Volume 2. [Google Scholar]
- Sun, Y.; Li, S.; Sun, Z. Fully automated macular pathology detection in retina optical coherence tomography images using sparse coding and dictionary learning. J. Biomed. Opt. 2017, 22, 016012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Venhuizen, F.G.; van Ginneken, B.; van Asten, F.; van Grinsven, M.J.; Fauser, S.; Hoyng, C.B.; Theelen, T.; Sánchez, C.I. Automated staging of age-related macular degeneration using optical coherence tomography. Investig. Ophthalmol. Vis. Sci. 2017, 58, 2318–2328. [Google Scholar] [CrossRef] [PubMed]
- Lemaître, G.; Rastgoo, M.; Massich, J.; Cheung, C.Y.; Wong, T.Y.; Lamoureux, E.; Milea, D.; Mériaudeau, F.; Sidibé, D. Classification of SD-OCT volumes using local binary patterns: Experimental validation for DME detection. J. Ophthalmol. 2016, 2016, 3298606. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.Y.; Chen, M.; Ishikawa, H.; Wollstein, G.; Schuman, J.S.; Rehg, J.M. Automated macular pathology diagnosis in retinal OCT images using multi-scale spatial pyramid and local binary patterns in texture and shape encoding. Med. Image Anal. 2011, 15, 748–759. [Google Scholar] [CrossRef] [Green Version]
- Hussain, M.A.; Bhuiyan, A.; Luu, C.D.; Smith, T.; Guymer, R.H.; Ishikawa, H.; Schuman, J.S.; Ramamohanarao, K. Classification of healthy and diseased retina using SD-OCT imaging and Random Forest algorithm. PLoS ONE 2018, 13, e0198281. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, X.; Fang, L.; Rabbani, H.; Chen, X.; Liu, Z. Retinal optical coherence tomography image classification with label smoothing generative adversarial network. Neurocomputing 2020, 405, 37–47. [Google Scholar] [CrossRef]
- Tsuji, T.; Hirose, Y.; Fujimori, K.; Hirose, T.; Oyama, A.; Saikawa, Y.; Mimura, T.; Shiraishi, K.; Kobayashi, T.; Mizota, A.; et al. Classification of optical coherence tomography images using a capsule network. BMC Ophthalmol. 2020, 20, 114. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Deng, Y.; Fang, L.; Peng, Q. Multi-Modal Retinal Image Classification with Modality-Specific Attention Network. IEEE Trans. Med. Imaging 2021, 40, 1591–1602. [Google Scholar] [CrossRef]
- Lee, C.S.; Baughman, D.M.; Lee, A.Y. Deep learning is effective for classifying normal versus age-related macular degeneration OCT images. Ophthalmol. Retin. 2017, 1, 322–327. [Google Scholar] [CrossRef]
- Rasti, R.; Rabbani, H.; Mehridehnavi, A.; Hajizadeh, F. Macular OCT classification using a multi-scale convolutional neural network ensemble. IEEE Trans. Med. Imaging 2017, 37, 1024–1034. [Google Scholar] [CrossRef] [PubMed]
- Fang, L.; Wang, C.; Li, S.; Rabbani, H.; Chen, X.; Liu, Z. Attention to lesion: Lesion-aware convolutional neural network for retinal optical coherence tomography image classification. IEEE Trans. Med. Imaging 2019, 38, 1959–1970. [Google Scholar] [CrossRef]
- Fang, L.; Jin, Y.; Huang, L.; Guo, S.; Zhao, G.; Chen, X. Iterative fusion convolutional neural networks for classification of optical coherence tomography images. J. Vis. Commun. Image Represent. 2019, 59, 327–333. [Google Scholar] [CrossRef]
- Thomas, A.; Harikrishnan, P.; Ramachandran, R.; Ramachandran, S.; Manoj, R.; Palanisamy, P.; Gopi, V.P. A novel multiscale and multipath convolutional neural network based age-related macular degeneration detection using OCT images. Comput. Methods Programs Biomed. 2021, 209, 106294. [Google Scholar] [CrossRef]
- Karri, S.P.K.; Chakraborty, D.; Chatterjee, J. Transfer learning based classification of optical coherence tomography images with diabetic macular edema and dry age-related macular degeneration. Biomed. Opt. Express 2017, 8, 579–592. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yoo, T.K.; Choi, J.Y.; Seo, J.G.; Ramasubramanian, B.; Selvaperumal, S.; Kim, D.W. The possibility of the combination of OCT and fundus images for improving the diagnostic accuracy of deep learning for age-related macular degeneration: A preliminary experiment. Med. Biol. Eng. Comput. 2019, 57, 677–687. [Google Scholar] [CrossRef] [PubMed]
- Saha, S.; Nassisi, M.; Wang, M.; Lindenberg, S.; Sadda, S.; Hu, Z.J. Automated detection and classification of early AMD biomarkers using deep learning. Sci. Rep. 2019, 9, 10990. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, Z.; Wang, W.; Yang, J.; Zhao, J.; Ding, D.; He, F.; Chen, D.; Yang, Z.; Li, X.; Yu, W.; et al. Automated diagnoses of age-related macular degeneration and polypoidal choroidal vasculopathy using bi-modal deep convolutional neural networks. Br. J. Ophthalmol. 2021, 105, 561–566. [Google Scholar] [CrossRef]
- Hwang, D.K.; Hsu, C.C.; Chang, K.J.; Chao, D.; Sun, C.H.; Jheng, Y.C.; Yarmishyn, A.A.; Wu, J.C.; Tsai, C.Y.; Wang, M.L.; et al. Artificial intelligence-based decision-making for age-related macular degeneration. Theranostics 2019, 9, 232. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image Transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–14 August 2021; pp. 10347–10357. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture Transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5791–5800. [Google Scholar]
- Yuan, K.; Guo, S.; Liu, Z.; Zhou, A.; Yu, F.; Wu, W. Incorporating convolution designs into visual Transformers. arXiv 2021, arXiv:2103.11816. [Google Scholar]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 2018, 172, 1122–1131. [Google Scholar] [CrossRef]
- Srinivasan, P.P.; Kim, L.A.; Mettu, P.S.; Cousins, S.W.; Comer, G.M.; Izatt, J.A.; Farsiu, S. Fully automated detection of diabetic macular edema and dry age-related macular degeneration from optical coherence tomography images. Biomed. Opt. Express 2014, 5, 3568–3577. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Class | Accuracy (%) | Sensitivity (%) | Precision (%) | OA (%) | OS (%) | OP (%) | Time (ms) |
|---|---|---|---|---|---|---|---|---|
| Transfer learning [36] | CNV | 83.86 | 92.64 | 76.52 | 76.26 | 57.34 | 73.47 | 6.31 |
| DME | 89.53 | 36.00 | 74.61 | |||||
| Drusen | 90.13 | 18.56 | 65.22 | |||||
| Normal | 88.99 | 92.18 | 77.55 | |||||
| VGG16 [28] | CNV | 92.92 | 91.37 | 92.83 | 86.68 | 79.79 | 81.29 | 1.08 |
| DME | 94.20 | 78.79 | 78.43 | |||||
| Drusen | 92.34 | 55.45 | 65.89 | |||||
| Normal | 93.90 | 93.57 | 88.02 | |||||
| ResNet [29] | CNV | 93.74 | 90.92 | 94.92 | 89.87 | 86.11 | 85.82 | 3.92 |
| DME | 95.88 | 85.23 | 84.60 | |||||
| Drusen | 94.36 | 72.21 | 72.74 | |||||
| Normal | 95.75 | 96.08 | 91.01 | |||||
| IFCNN [20] | CNV | 93.45 | 91.09 | 94.16 | 88.67 | 83.84 | 84.42 | 1.46 |
| DME | 95.06 | 83.68 | 80.97 | |||||
| Drusen | 93.95 | 65.80 | 72.92 | |||||
| Normal | 94.8 | 94.78 | 89.63 | |||||
| HCTNet | CNV | 94.60 | 92.23 | 95.53 | 91.56 | 88.57 | 88.11 | 3.74 |
| DME | 96.14 | 87.96 | 84.42 | |||||
| Drusen | 95.54 | 77.36 | 79.00 | |||||
| Normal | 96.84 | 96.73 | 93.50 |
| Method | OA | OS | OP |
|---|---|---|---|
| HCTNet & Transfer learning [36] | < | < | < |
| HCTNet & VGG16 [28] | < | < | 0.0002 |
| HCTNet & ResNet [29] | 0.0139 | 0.0038 | 0.0363 |
| HCTNet & IFCNN [20] | 0.0001 | < | 0.0022 |
| Method | Class | Accuracy (%) | Sensitivity (%) | Precision (%) | OA (%) | OS (%) | OP (%) | Time (ms) |
|---|---|---|---|---|---|---|---|---|
| Transfer learning [36] | AMD | 90.90 | 68.37 | 89.40 | 79.41 | 76.25 | 84.01 | 6.82 |
| DME | 81.45 | 76.88 | 79.10 | |||||
| Normal | 86.47 | 83.49 | 83.54 | |||||
| VGG16 [28] | AMD | 92.76 | 77.12 | 86.90 | 83.69 | 81.96 | 85.20 | 1.30 |
| DME | 84.83 | 79.76 | 81.23 | |||||
| Normal | 89.79 | 88.99 | 87.45 | |||||
| ResNet [29] | AMD | 92.35 | 71.73 | 90.28 | 84.55 | 82.13 | 86.92 | 4.02 |
| DME | 87.48 | 81.41 | 86.12 | |||||
| Normal | 89.28 | 93.26 | 84.36 | |||||
| IFCNN [20] | AMD | 92.46 | 71.71 | 92.49 | 84.62 | 81.86 | 87.47 | 1.60 |
| DME | 86.54 | 82.09 | 83.10 | |||||
| Normal | 90.24 | 91.78 | 86.82 | |||||
| HCTNet | AMD | 95.94 | 82.60 | 95.08 | 86.18 | 85.40 | 88.53 | 3.81 |
| DME | 86.61 | 80.22 | 85.29 | |||||
| Normal | 89.81 | 93.39 | 85.22 |
| Datasets | OA (%) | OS (%) | OP (%) |
|---|---|---|---|
| Noisy OCT2017 | 91.52 | 88.57 | 88.20 |
| Original OCT2017 | 91.56 | 88.57 | 88.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Xie, Q.; Xie, P.; Fan, F.; Gao, X.; Zhu, J. HCTNet: A Hybrid ConvNet-Transformer Network for Retinal Optical Coherence Tomography Image Classification. Biosensors 2022, 12, 542. https://doi.org/10.3390/bios12070542
Ma Z, Xie Q, Xie P, Fan F, Gao X, Zhu J. HCTNet: A Hybrid ConvNet-Transformer Network for Retinal Optical Coherence Tomography Image Classification. Biosensors. 2022; 12(7):542. https://doi.org/10.3390/bios12070542
Chicago/Turabian StyleMa, Zongqing, Qiaoxue Xie, Pinxue Xie, Fan Fan, Xinxiao Gao, and Jiang Zhu. 2022. "HCTNet: A Hybrid ConvNet-Transformer Network for Retinal Optical Coherence Tomography Image Classification" Biosensors 12, no. 7: 542. https://doi.org/10.3390/bios12070542